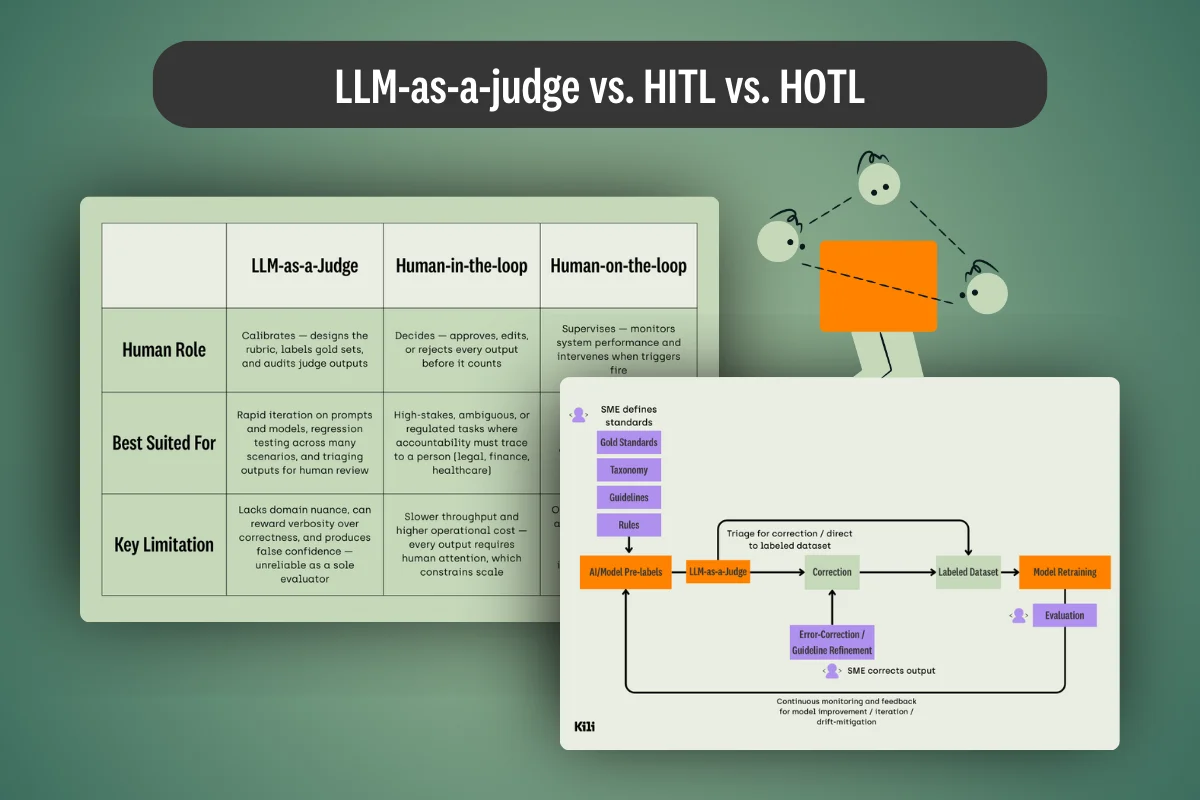
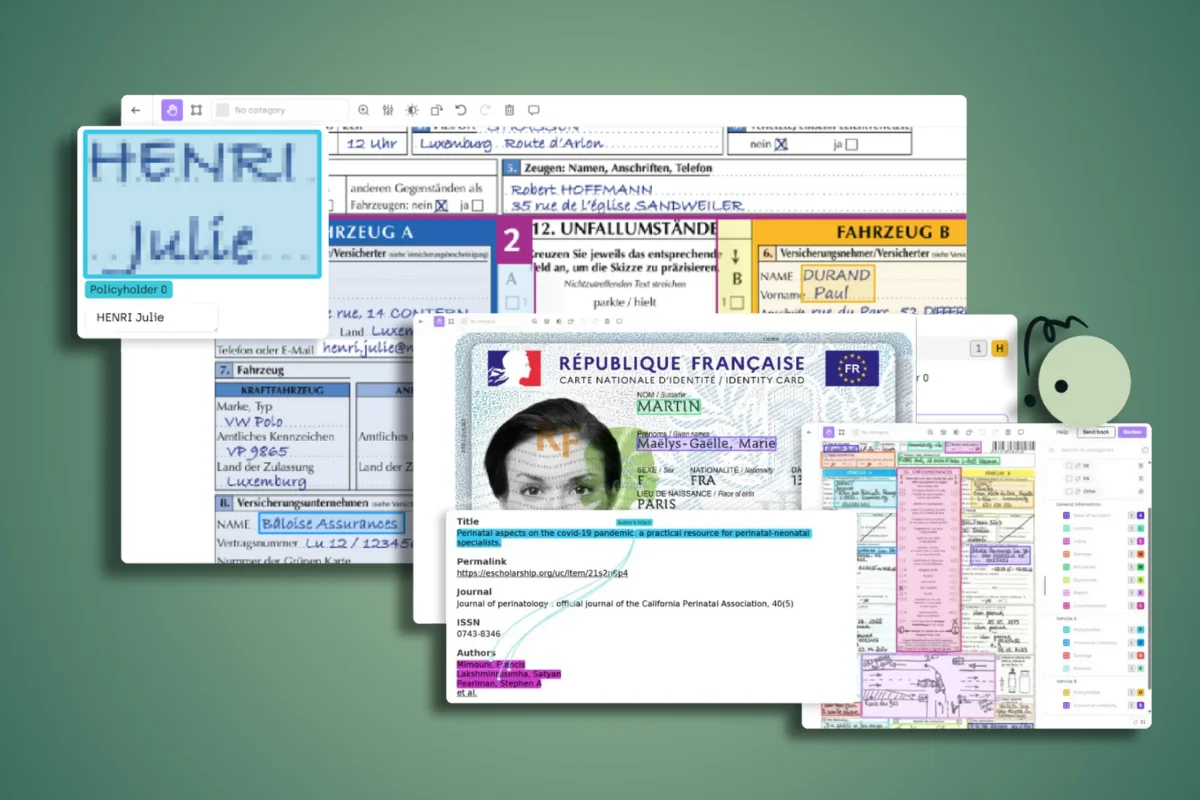
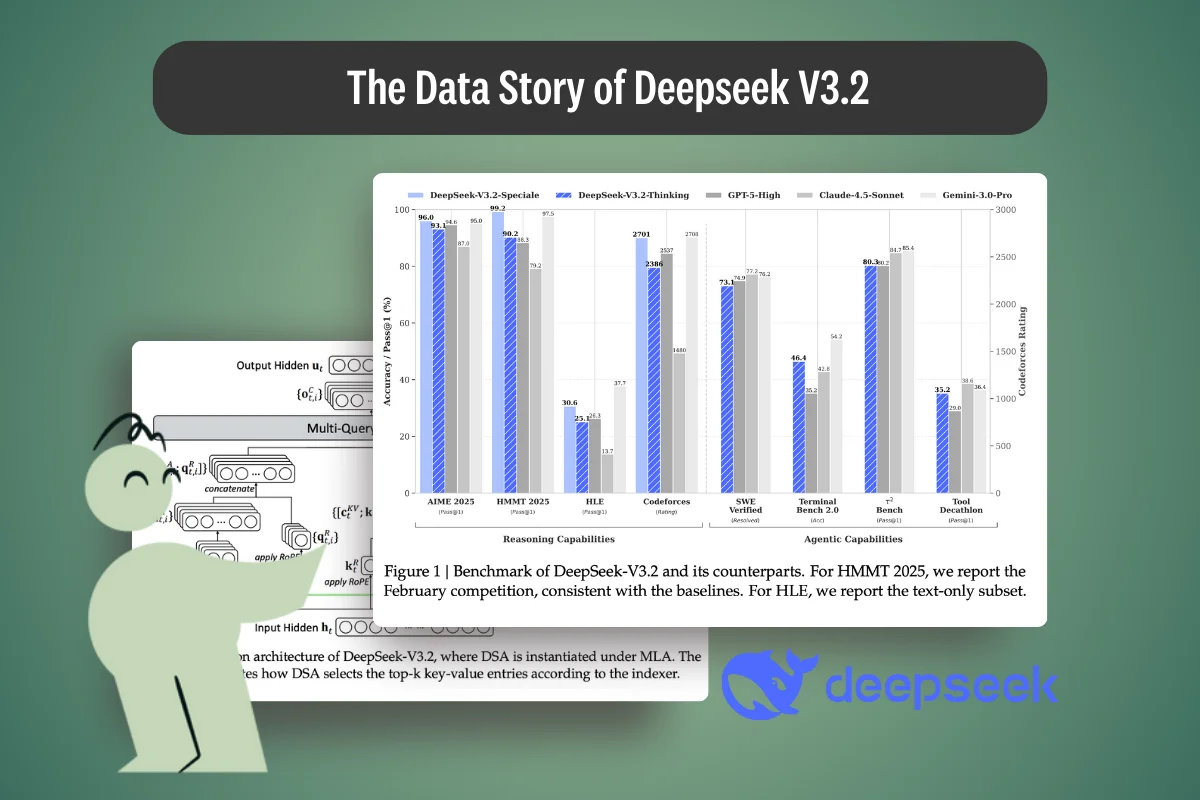
.webp)
April 2, 2026
AI Model Evaluation Guide: Methods, Metrics, and Why It Determines Production Success
AI model evaluation is the discipline that separates prototype AI from production AI. Learn the methods, metrics, and data quality principles that make evaluation reliable.
.png)



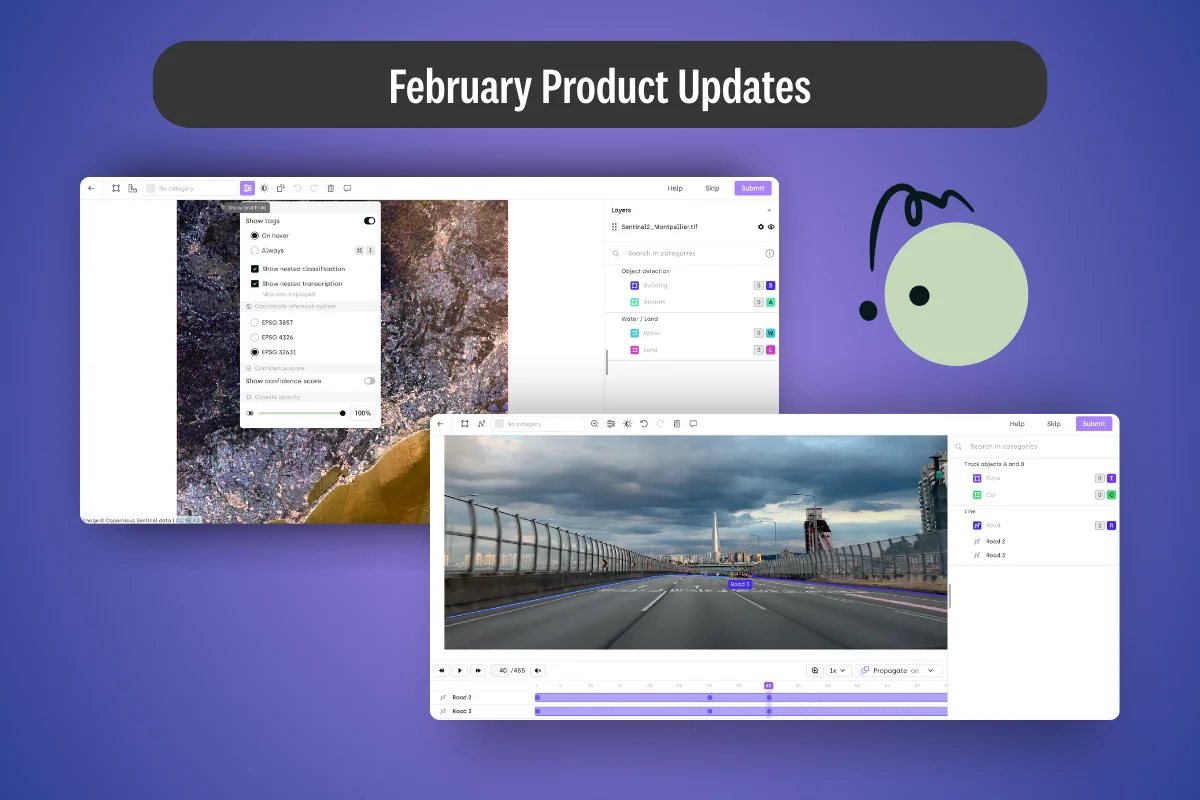
.webp)

.webp)