
.png)

_logo%201.svg)


AI Summary
- Large language models often appear credible while being incorrect, making structured AI output validation essential in regulated domains.
- Human-in-the-loop provides accountability through approval gates where experts review every consequential output before it counts.
- Human-on-the-loop reserves expert bandwidth for exceptions by automating routine cases with defined risk triggers and drift monitoring.
- LLM-as-a-judge scales evaluation coverage through rubric-based scoring but cannot replace human judgment on domain-specific correctness.
- A five-layer oversight stack combining automated checks, LLM scoring, HITL review, HOTL monitoring, and feedback loops delivers the strongest reliability.
- Kili Technology provides the collaborative platform and expert annotation services to operationalize HITL, HOTL, and evaluation workflows at enterprise scale.
Large language models often look "right" even when they are wrong. In high-stakes settings—law, finance, healthcare, software engineering—that is a reliability problem, not just a quality problem. The question is rarely "Is this answer fluent?" It is "Is this answer acceptable to act on in this context, with these constraints, and with this level of risk?"
This article explains three common oversight patterns used to validate AI outputs:
- Human-in-the-loop (HITL): humans approve or correct outputs before they count.
- Human-on-the-loop (HOTL): humans supervise a mostly automated system and intervene when needed.
- LLM-as-a-judge: an LLM scores or ranks another model's outputs against a rubric.
It also covers where each approach fits best—and how to combine them into a practical evaluation stack that keeps human judgment at the center of the process.
Why "Lab Evaluation" Often Fails in Production
Before we get into definitions, one useful framing: HITL and HOTL are not new concepts invented for modern AI. They come from decades of work on human–automation systems (aviation, robotics, teleoperation), where teams had to decide what to automate, how humans supervise automation, and how humans take over when automation becomes uncertain or unsafe. In that sense, today's LLM oversight patterns are largely repurposed human–computer interaction design problems applied to probabilistic, language-based systems.
Many AI systems look strong in controlled tests but break in reality. A common reason is mismatch:
- The test set does not reflect real world inputs (formatting messiness, incomplete fields, unusual language, edge cases).
- Benchmarks measure a narrow slice (accuracy on a dataset) while production demands more (robustness, integration, trust, compliance).
- Real workflows introduce new failure modes (tool integrations, multi-step chains, unclear objectives, changing environments and policies).
The practical lesson: evaluation is not a one-time report. It is an ongoing prediction about how the system will behave under future conditions—so you need monitoring, audits, and escalation paths. HITL aims to close exactly this gap by creating a continuous feedback loop where humans strategically guide the computer to make better decisions during the model-building process.
This is where data quality becomes critical. Inconsistent data quality for training or fine-tuning specialized models leads to unreliable production behavior. Organizations need comprehensive data quality workflows and curation methodology throughout the AI lifecycle—not as a final checkpoint, but as a continuous discipline. When the labeled data that trains or evaluates a model is itself noisy or inconsistent, no amount of architectural sophistication will compensate.
The Three Patterns: What They Are, and What They Are For
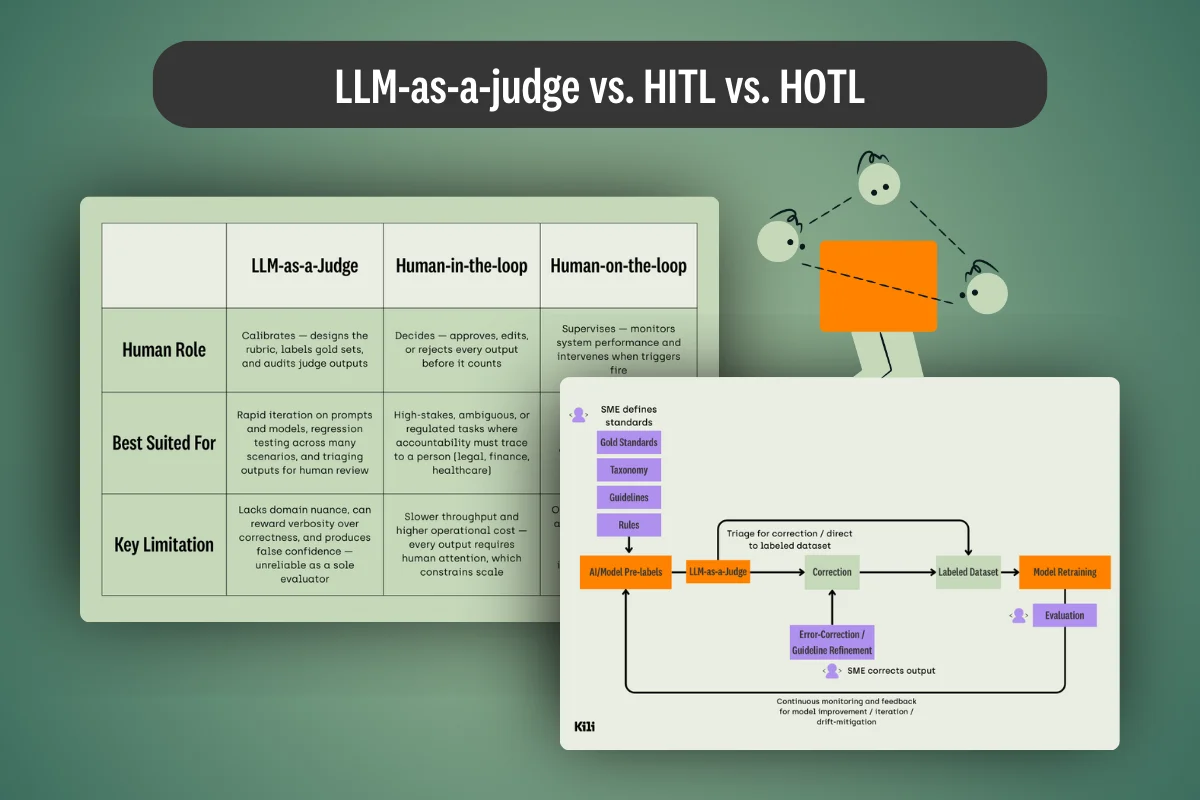
1. Human-in-the-Loop (HITL)
Definition: a human must actively approve, edit, or reject the model output before it is treated as valid or used for consequential actions.
HITL emphasizes active human involvement in developing, training, and operating AI systems to ensure accuracy and ethical decision-making. It reframes the automation problem as a human-computer interaction design problem—asking not "how do we remove people from the process?" but "how do we incorporate human curation into the loop at the junctures where it matters most?"
What HITL is good for:
- Accountability: Regulated or high-liability decisions require a responsible human. Human-in-the-loop systems enhance accountability by ensuring that responsibility for decisions does not rest solely on AI models or their developers. AI regulations, such as the EU AI Act, mandate that high-risk AI systems must be designed to allow effective human oversight during their operation.
- Nuanced correctness: Subject matter experts catch failures that are subtle but high impact (wrong legal reasoning, policy violations, unsafe advice). Incorporating human intelligence into AI systems helps identify and mitigate bias that is embedded in the data and algorithms themselves, promoting fairness in AI outputs.
- Ambiguity: When there is no single correct answer, human judgment is the evaluation target. Incorporating human input into complex tasks that require cultural context and moral reasoning is something that supervised learning algorithms alone cannot reliably handle.
Typical HITL workflows:
- Approval gate: the model drafts; the expert signs off.
- Correction gate: the expert edits; corrections become labeled data and training signals.
- Adjudication: a senior reviewer resolves disagreements between reviewers.
Example situations (high-stakes):
- Legal drafting or summaries where citations and reasoning must be defensible.
- Financial recommendations that must follow policy and regulation, including fraud detection where AI monitors networks for threats but security analysts validate anomalies and handle complex breaches to prevent false positives.
- Security or compliance tasks where a mistake can create real harm to sensitive data.
- Code changes where review and testing remain mandatory.
A useful mental model: treat the model as a capable junior colleague—fast and helpful, but not automatically trusted. The success of any HITL system hinges on the quality of human input, requiring training and clear guidelines for the human team.
However, incorporating human workers in HITL introduces significant operational costs due to the need for training, management, and labor. Human intervention can also slow down decision-making compared to fully automated systems, introducing latency. This is precisely where the difficulty of scaling annotation operations while maintaining quality becomes apparent—and why organizations need hybrid workforce solutions that combine specialized human expertise with automation to optimize cost structure, faster throughput, and consistent quality at scale.
2. Human-on-the-Loop (HOTL)
Definition: the system runs with partial autonomy, while humans monitor, audit, and intervene. Humans are not approving every output. They supervise the system using alerts, random sampling, and stop/override controls.
HOTL systems can continuously learn and adapt their behavior without human input on every decision, making them more autonomous than HITL systems. But this autonomy only works if "monitor and intervene" is real. Passive logging without action paths is not oversight—it is theater.
What HOTL is good for:
- Scale: reviewing every output is too slow or expensive, so using a hybrid approach helps manage high-confidence tasks with AI while reserving human intervention for low-confidence or high-risk cases.
- Stable workflows: you can define reliable risk triggers and handle most routine cases automatically.
- Operational control: humans can pause the system, change thresholds, or route cases to experts.
Typical HOTL mechanisms:
- Risk triggers: route to human review when uncertainty is high, sources are missing, or certain topics appear. Humans monitor real-time outputs and intervene in high-stakes decisions when AI indicates low confidence.
- Sampling audits: review a percentage of outputs continuously (not just at launch).
- Incident response: if error rates rise, roll back and investigate.
- Drift monitoring: watch for changes in input patterns and output quality over time in changing environments.
Example situations:
- Customer support copilots where most responses are low risk, but policy-sensitive topics escalate.
- Document processing where most cases are routine, but exceptions require expert validation.
- Content moderation where platforms use AI to flag content, while human moderators evaluate contextual nuances like satire versus hate speech, at a large volume that needs triage.
3. LLM-as-a-Judge
Definition: you use an LLM to score, rank, or critique another model's outputs against a rubric.
There are two common variants:
- Reference-based: compare output to a ground truth answer (when one exists).
- Reference-free: judge style, helpfulness, policy compliance, reasoning quality, etc.
What LLM-as-a-judge is good for:
- Speed: evaluate many outputs quickly during prompt/model iteration.
- Coverage: test more scenarios than humans can label, expanding the reach of your evaluation beyond what manual review alone allows.
- Triage: flag risky outputs for human review, acting as a first-pass filter that routes the most critical items to expert attention.
Where it fails if used alone:
- Domain nuance: judges may miss domain-specific errors (legal defensibility, clinical appropriateness). This is the challenge in evaluating model performance against specific business objectives—and why customized evaluation frameworks combining human expertise and automated testing outperform either approach in isolation.
- Bias and artifacts: judges can be sensitive to wording, verbosity, ordering, and other superficial cues.
- False confidence: a judge can sound authoritative while being wrong.
The most reliable way to use LLM judges is as measurement and triage, anchored by human calibration:
- Subject matter experts design the rubric and label a smaller "gold" set.
- The LLM judge expands evaluation coverage.
- Humans audit disagreements and drift.
Creating reliable benchmarks for specialized use cases is itself a complex task. Domain-specific benchmark creation with deep expertise in generative AI applications provides objective measurement of improvements, competitive analysis, and a clear roadmap for model enhancement. Without this rigor, teams cannot distinguish genuine capability gains from benchmark artifacts. For teams ready to operationalize this, our practitioner guide on what the best public evals teach you about building your own benchmark distils the design choices behind HELM, GPQA Diamond, and SWE-bench into a methodology you can adapt.
When to Use Which Approach
Choose HITL when:
- The downside of an error is high (legal exposure, financial loss, safety risk, security risk).
- The task requires accountable professional judgment.
- The output must be defensible in an audit.
A good test: if you would not accept a junior employee's work without review, you should not accept the model's output without review. HITL can be strategically integrated at different points in a workflow, depending on specific goals and current automation levels. Human-in-the-loop design strategies can improve the performance of AI systems compared to fully automated systems by leveraging human interaction at critical decision points.
Choose HOTL when:
- You can define clear escalation triggers and have real intervention controls.
- Most cases are routine, and experts should focus on exceptions.
- You can invest in monitoring and continuous audits.
Choose LLM-as-a-judge when:
- You are iterating on ML models and prompts and need fast feedback.
- You want regression tests across many scenarios.
- You want to triage outputs (what should experts see first?).
The integration of HITL, HOTL, and automated evaluation models can significantly impact the development and deployment of AI systems, influencing their effectiveness and ethical considerations. The key is understanding that these are not competing ideologies but complementary layers in a robust oversight architecture.
A Practical Enterprise Pattern: Use All Three Together
An example of HOTL and LLM-as-a-judge put together in a data labeling workflow.
For most real deployments, the best answer is not "pick one." It is a layered evaluation and oversight stack:
- Cheap automated checks (fast filters): formatting rules, policy keyword checks, unit tests for code, citation presence checks.
- LLM-as-a-judge (scalable scoring): rubric scoring + critique; risk tagging; pairwise comparisons for A/B tests.
- HITL review on high-risk cases: subject matter experts approve, correct, and assign severity.
- HOTL monitoring for everything else: audits, drift monitoring, incident response, rollback plans.
- Feedback → data: corrected outputs and reviewer notes become evaluation sets and training data signals.
Incorporating human feedback into AI workflows creates a continuous feedback loop that enhances model accuracy and efficiency over time. The human-in-the-loop design allows for significant gains in transparency by requiring the system to be understandable to humans at each interaction point, reducing the "black box" effect that undermines trust. Systems that include human review are often more trusted by users, as transparency is required by regulations in high-risk applications.
This structure matches how strong teams reduce cost while keeping expert judgment where it matters most:
- Automation handles volume.
- Experts handle ambiguity and accountability.
- Monitoring prevents silent degradation.
What "Good Oversight" Looks Like in Practice
If you want a simple checklist, strong oversight tends to include the following.
1. Clear Rubrics and Error Taxonomies
Define what counts as: acceptable, needs revision, unsafe, non-compliant. Use severity levels (for example, critical vs. minor) so the team focuses on what matters. Data scientists and domain experts should collaborate to set initial parameters for these rubrics, because the taxonomy shapes what your intelligent systems can actually learn from human corrections.
2. Consensus and Arbitration for Labels and Reviews
When experts disagree, you need a structured resolution method:
- Majority vote for low-impact labels.
- Expert arbitration for high-impact or ambiguous cases.
This reduces noisy "ground truth" and avoids training the system on inconsistent feedback. Involving humans involved in the arbitration process helps identify and mitigate biases that may be embedded in data and algorithms, bringing the kind of human expertise that deep learning alone cannot replicate.
3. Traceability and Multi-Step Validation
For high-stakes evaluation data (and training data), keep records of:
- Who reviewed it, when, with which guideline version.
- What changes were made, and why.
Multi-step validation (review gates) catches errors early and prevents them from becoming "accepted truth." Human-in-the-loop approaches can provide a record of decision-making processes, supporting compliance auditing and internal accountability reviews. This addresses the lack of transparency in AI model development lifecycle that many organizations struggle with—comprehensive project management and documentation practices are what enable full auditability, easier troubleshooting, and improved knowledge transfer across teams.
4. Continuous Monitoring, Not Launch-and-Leave
Real inputs drift. Policies change. Edge cases appear. Good systems:
- Detect drift in changing environments.
- Sample and audit regularly.
- Trigger re-evaluation and retraining when needed.
Human oversight in AI systems is essential for ethical decision-making, especially in complex scenarios that require cultural context and moral reasoning. The integration of human feedback into AI workflows can improve the transparency and explainability of AI systems across every stage—from writing the annotation guidelines to reviewing the final model outputs.
5. SME-Friendly Workflows
Experts are not machine learning engineers. If the review process is slow or unclear, experts disengage, and the system degrades—introducing unintended consequences that compound over time.
Practical design patterns:
- Show evidence alongside claims (sources, excerpts, tool traces).
- Make it easy to correct and annotate.
- Capture structured feedback (not just free-text comments).
Difficulty sourcing domain experts for niche fields—mathematics, legal reasoning, medical imaging, and other highly technical domains—is one of the most persistent bottlenecks in building reliable AI. Access to a specialized talent network with deep domain expertise reduces time-to-market for domain-specific generative AI solutions and improves model accuracy for specialized use cases.
Two Layered Use Cases Where HITL Is the Main Control Point
An example of HITL as the main control point with AI pre-annotation for automation
Below are two practical patterns where HITL is the most prominent layer—not as a token "review step," but as the decision gate that makes the system safe to use.
Use Case 1: Contract Review and Redlining Assistant (Legal)
Goal: speed up review of NDAs, MSAs, and SOWs while keeping legal defensibility.
Why HITL is dominant: contract language has high liability and is often context-dependent (jurisdiction, internal playbooks, risk tolerance). The organization needs an accountable legal approver. This is a particular case where no form of purely automated evaluation can substitute for human judgment.
Layered workflow:
- Automated checks: document parsing; clause detection; required-section checklist; obvious policy flags (for example, prohibited governing law, missing limitation of liability section).
- LLM-as-a-judge (triage): score the model's clause interpretations against a rubric (coverage, citation-to-text, "no invention"); tag risk areas (assignment, indemnity, IP, data processing).
- HITL decision gate (primary): counsel reviews the highlighted clauses and proposed edits, accepts/rejects changes, and adds rationale.
- HOTL monitoring: sample audits by senior counsel; track recurring failure modes (for example, misreading indemnity carve-outs) and escalation rates by contract type.
- Feedback → data: accepted redlines and rationale become gold examples; disagreements become "edge-case" tests; the rubric is refined.
What you evaluate: not just correctness, but defensibility (does the output align with policy and risk posture) and traceability (can the reviewer see where each claim came from in the source text). Security concerns when handling sensitive data in legal contexts demand end-to-end secure infrastructure and compliance-focused workflows that minimize regulatory risks and enhance data protection.
Use Case 2: Credit Memo / Risk Narrative Copilot (Finance)
Goal: help analysts draft internal credit memos, risk narratives, or compliance summaries faster.
Why HITL is dominant: these documents can influence lending decisions, disclosures, or regulatory posture. Even small factual errors (numbers, dates, ratios, sources) can create material risk. HITL is particularly beneficial in such high-stakes applications, where human oversight can prevent negative outcomes from AI decisions.
Layered workflow:
- Automated checks: schema validation for required fields; numeric consistency checks (totals match, ratios recompute); source coverage checks (every key claim must link to a source).
- LLM-as-a-judge (triage): rubric scoring for factuality-with-evidence, consistency, and appropriate uncertainty; flag "unsupported claims" and "too-confident language."
- HITL decision gate (primary): a qualified analyst/controller verifies the key statements and approves the final memo; edits are captured as structured feedback (error type + severity).
- HOTL monitoring: trend dashboards for common errors (hallucinated figures, mis-cited sources, stale data); alerts when risk flags spike.
- Feedback → data: corrections become regression tests and evaluation data; high-severity failure cases are prioritized for rework and policy updates.
What you evaluate: factual grounding, numerical integrity, and policy alignment—and whether the workflow makes it easy for reviewers to verify claims. HITL can be applied across industries including healthcare, finance, and manufacturing to enhance the quality of AI-driven solutions, but the benefits are most visible in contexts where a single wrong output carries material consequences.
Quick Mapping: Common Situations and Recommended Oversight
- Legal, finance, healthcare recommendations → HITL by default; LLM judge for triage; HOTL for monitoring.
- Enterprise copilots (email drafting, summaries) → HOTL + sampling audits; HITL for escalations (sensitive topics).
- AI coding assistants → automated tests + mandatory human code review; HOTL monitoring for regressions.
- Document extraction / compliance processing → programmatic rules + LLM judge scoring + HITL for exceptions; continuous drift monitoring.
Across all these contexts, the human-in-the-loop approach emphasizes the importance of human judgment in AI systems, ensuring that technology aligns with human values and ethical standards. It means that machines handle volume and pattern recognition, while people provide the contextual control, ethical reasoning, and accountability that powerful systems require.
How Kili Technology Supports HITL, HOTL, and Evaluation Workflows
The oversight patterns described above—HITL review gates, HOTL monitoring, LLM-as-a-judge scoring—all depend on the same foundation: high-quality, expert-curated data that flows through a structured, auditable process. Without the right infrastructure, even the best-designed oversight architecture collapses under operational friction.
This is where Kili Technology fits. Kili is a collaborative AI data platform that enables enterprises to build production-ready AI systems faster and with higher quality by enabling data science teams to easily embed business and subject matter experts throughout the AI development lifecycle. Unlike traditional data labeling tools built solely for ML engineers, Kili empowers cross-functional teams to work together autonomously—from initial labeling through validation and iteration—ensuring AI models are built on domain expertise, not just technical assumptions. All within a secure, auditable environment for trustworthy AI.
Collaboration at scale. Traditional AI development treats domain expertise as a final checkpoint—something to validate after the model is built. Kili reverses this. By enabling radiologists, underwriters, quality engineers, and other domain specialists to shape AI from the first annotation, Kili embeds human expertise directly into training data. The result is models that understand your domain from the ground up, not through post-hoc corrections. Designing these human-in-the-loop systems means asking how to incorporate human curation into the loop at various junctures—and Kili provides the interface and workflow orchestration to make this practical at enterprise scale.
Uncompromised speed and quality. Speed without quality is just fast failure. Kili delivers both by embedding domain validation throughout the development lifecycle, not as an afterthought. When experts validate early and often, you eliminate the costly iteration cycles that plague traditional approaches. Active learning strategies, where human-generated labels are fed back to improve model predictions, further accelerate the process—enabling higher model performance with fewer iterations, reduced hallucinations, and better compliance with set client standards.
Enterprise-grade security. When your data is too sensitive for the cloud, when compliance isn't optional, when security audits are routine—Kili delivers. On-premise deployment, complete audit trails, and security standards satisfy the world's most demanding organizations, from intelligence agencies to healthcare leaders.
Transparency and auditability. AI model failures often trace back to data quality issues—but without documentation, you cannot diagnose them. Kili provides complete traceability for every data decision: who labeled each asset, who reviewed it, what consensus was reached, and how quality evolved over time. When a model behaves unexpectedly in production, you can trace it back to the training data and understand whether the issue was labeling inconsistency, reviewer disagreement, or insufficient domain expert involvement. This level of explainable AI infrastructure is what separates organizations that can debug production failures from those that simply retrain and hope.
Flexible, customizable workflows. Every enterprise has unique requirements. Unlike rigid labeling tools that force you to adapt to their workflows, Kili adapts to yours—including multi-step review workflows configurable to match your existing QA processes, plugin functionality for custom extensibility, and customizable labeling interfaces adaptable to any industry.
Hybrid workforce solutions. For organizations struggling to scale annotation operations while maintaining quality, Kili's platform supports hybrid workforce solutions combining specialized human expertise with automation—including model-based pre-annotation, consensus mechanisms, honeypot quality checks, and programmatic QA bots. This means optimized cost structure, faster throughput, and consistent quality at scale.
Closing Thought
HITL, HOTL, and LLM-as-a-judge are not competing ideologies. They are tools for different constraints:
- HITL decides. It provides the human oversight and accountability that critical applications demand.
- HOTL supervises. It keeps powerful systems under control without bottlenecking every output.
- LLM-as-a-judge scales measurement. It extends evaluation reach beyond what manual review can cover.
When the goal is real-world reliability, the best systems embed expert judgment structurally—from rubrics and review gates to continuous monitoring—rather than treating human oversight as a last-minute add-on. Human-out-of-the-loop (HOOTL) approaches, where AI operates with minimal or no human intervention, remain appropriate only for well-bounded, low-risk tasks where the cost of error is negligible.
The future of AI oversight is not about choosing between humans and machines. It is about designing the right interaction between them—structuring where human intelligence provides the most value, where algorithms handle scale, and where the feedback loop between the two drives continuous improvement. That is the design problem worth solving.
Resources
Oversight and supervisory control
- EU AI Act Service Desk — Article 14: Human oversight.
- NASA Technical Reports Server — Sheridan & Verplank (1978), Human/computer control of undersea teleoperators (supervisory control framing).
- Wiley — Sheridan (2002), Humans and Automation: System Design and Research Issues (human–automation system design and supervisory control).
LLM-as-a-judge
- Zheng et al. (2023), Judging LLM-as-a-judge with MT-Bench and Chatbot Arena (LLM judging, biases, mitigations).
- Wang et al. (2023), Large Language Models are not Fair Evaluators (order/position bias; calibration strategies).
- Stureborg et al. (2024), Large Language Models are Inconsistent and Biased Evaluators (biases and instability in LLM evaluators; mitigation recipes).
Evaluation gap and expert data loops
- Kili Technology (Nov 20, 2025), The Evaluation Gap: Why AI Breaks in Reality Even When It Works in the Lab.
- Kili Technology (2026), 2026 Data Labeling Guide for Enterprises: Build High Performing AI with Expert Data (SME-led standards, review, guideline refinement, and feedback loops; active learning concepts).
Frequently Asked Questions
What is the difference between human-in-the-loop and human-on-the-loop?
Human-in-the-loop (HITL) means a person reviews and approves every AI output before it takes effect. Human-on-the-loop (HOTL) means the AI operates autonomously while a person monitors aggregate performance and intervenes only when metrics drift or anomalies appear. HITL controls individual outputs; HOTL controls system-level behavior.
What is LLM-as-a-judge?
LLM-as-a-judge is a pattern where a large language model evaluates the outputs of another model against defined criteria — scoring for accuracy, relevance, safety, or style. It scales automated evaluation beyond what rule-based checks can catch, but inherits the biases and failure modes of the judge model itself.
When should I use human-in-the-loop vs. LLM-as-a-judge?
Use HITL when errors carry high consequences — medical, legal, financial, or safety-critical decisions. Use LLM-as-a-judge for high-volume, lower-stakes outputs where human review of every item isn't feasible, such as content moderation at scale or bulk translation quality scoring. The most robust systems use both: LLM-as-a-judge for triage and HITL for the cases that matter most.
Can LLM-as-a-judge fully replace human evaluators?
No. LLM judges can miss domain-specific errors, exhibit systematic biases, and fail on tasks that require real-world knowledge or cultural context. They are most effective as a first-pass filter that surfaces edge cases for human review, not as a standalone replacement for human judgment.
What is the best way to combine all three approaches?
A practical pattern is to use LLM-as-a-judge for automated first-pass evaluation, HOTL monitoring to track system-level performance over time, and HITL review for high-stakes outputs, edge cases flagged by the LLM judge, and periodic audits of the automated pipeline. This layered approach balances cost, speed, and accuracy.
How does Kili Technology support these workflows?
Kili Technology provides the annotation and evaluation infrastructure for all three patterns: HITL review interfaces with multi-reviewer consensus, quality analytics dashboards for HOTL monitoring, and evaluation project templates for comparing model outputs. The platform supports text, image, video, and document modalities across all workflow types.
Build Evaluation Workflows That Scale With Your AI
Kili Technology provides the infrastructure for human-in-the-loop review, quality monitoring, and model evaluation — all in one platform. Whether you're validating LLM outputs, running HITL annotation, or building custom evaluation pipelines, Kili supports the full lifecycle from labeling to production oversight.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
