.png)


_logo%201.svg)


AI Summary
- Qwen3 trains on 36T tokens across 119 languages, but the real lever is a multilingual annotation system labeling 30T tokens by educational value, domain, and safety to optimize the data mixture.
- Earlier Qwen models become the data factory — Qwen2.5-VL extracts text from PDFs, Qwen2.5-Math synthesizes problems — making generator quality a direct constraint on student model performance.
- Long-CoT cold-start data is built around verifiable answers and tests, with two-phase filtering that removes both unverifiable prompts and reasoning traces with inconsistent or low-quality content.
- Thinking and non-thinking modes are trained as two curated distributions, not toggled by a switch — preserving brevity and instruction compliance while adding controllable reasoning.
- Strong-to-weak distillation transfers expensive post-training supervision into smaller models, with Qwen reporting distillation outperforming RL for an 8B student at a fraction of the GPU cost.
- Even at frontier scale, human experts adjudicate accuracy when automated solvers fail, label preferences for reward models, and design the rubrics that define what good actually means.
Qwen3 is a family of dense and MoE large language models (0.6B up to 235B total parameters) with a "hybrid" interface that can either think (produce long reasoning traces) or not think (respond quickly) inside a single model. Developed by Alibaba Cloud, Qwen represents one of the most significant open weight models in the current landscape—with downloads exceeding 40 million.
However the more useful way to understand Qwen3 is as a sequence of data decisions:
- What "experiences" the base model gets during pre-training (and how those experiences are labeled and mixed)
- What kinds of verified reasoning problems it sees during post-training (and how those problems are filtered)
- How "thinking mode" is taught without collapsing the model's ability to answer normally
- How human preferences and human judgments appear—sometimes explicitly (preference data, human annotators), sometimes implicitly (rubric design, reward definitions)
This article breaks down Qwen3's technical report with that lens, and then extends the same reasoning to Qwen3 Max Thinking, which Qwen describes as scaling up model parameters and leveraging substantial computational resources "beyond its limits."
1) Lineage: What Qwen3 Inherits Before Any "New" Technique Starts
The Qwen3 technical report is explicit that a lot of the "new capability" story is not a single trick—it's the accumulation of more data, more languages, more controlled synthetic generation, and a post-training pipeline that treats reasoning as something you can manufacture with verification.
Two inheritance points matter for how you interpret later results:
1.1 Qwen2.5 as a Data Factory
Qwen3 repeatedly uses earlier Qwen models to create or process training data:
- Text recognition from documents: Qwen2.5-VL is used for text recognition from PDF-like documents, then Qwen2.5 refines the recognized text
- Synthetic generation at scale: Qwen2.5 / Qwen2.5-Math / Qwen2.5-Coder are used to synthesize very large volumes of tokens in multiple formats (textbook-like, QA, instructions, code snippets)
This is not just a convenience. It is an explicit strategy: the best available model becomes the pipeline component that turns messy sources into usable training examples.
This approach directly mirrors enterprise data challenges. Organizations building production AI systems face the same fundamental problem: raw data requires transformation, refinement, and quality assurance before it becomes valuable training material. The difference between a model that performs well in benchmarks and one that fails in production often traces back to this data engineering phase—specifically, how carefully the transformation pipeline preserves domain knowledge while removing noise.
1.2 Thinking as a Controllable Behavior, Not a Separate Model
The project goal is not "build a reasoning model and a chat model." It is "build one model that can be steered between the two," including a "thinking budget."
That assumption—reasoning as a steerable mode—shows up in later stages where the data is constructed to teach both modes and the ability to follow mode-control signals. This thinking mode control represents a significant advancement in instruction following alignment, enabling users to dynamically adjust the model's inference behavior based on task requirements.
2) Pre-Training as Data Engineering: What Qwen3 Says It Trained On
2.1 Scale and Diversity, with Labeled Mixture Control
Qwen3 reports training on 36 trillion tokens spanning 119 languages and dialects, with content across coding, STEM, reasoning, books, multilingual text, and synthetic data.
The more important point than raw token count is the control mechanism: Qwen says it built a multilingual data annotation system that labels over 30T tokens across dimensions like educational value, fields/domains, and safety. Those labels are then used to optimize the data mixture at the instance level, using ablations on small proxy models.
Even without full disclosure of label definitions or exact sampling weights, this implies pre-training is treated as mixture optimization rather than "crawl and train."
This is where the gap between frontier labs and enterprise AI becomes apparent. Alibaba Cloud can build a custom annotation system to label 30 trillion tokens. Most organizations cannot. Yet the underlying principle—that data quality depends on systematic labeling, domain classification, and mixture optimization—applies equally to a 36T token pre-training run and a 50,000-sample enterprise fine-tuning dataset.
2.2 "Found Data" Expansion: OCR + Refinement
A concrete intervention described in the report is how Qwen expands high-quality text:
- Run Qwen2.5-VL for OCR-like extraction on large volumes of PDF-like documents
- Then run Qwen2.5 to refine recognized text
- The output becomes an additional set of high-quality text tokens, amounting to trillions
This is a common pattern at frontier scale: convert difficult corpora (scanned PDFs, complex layouts) into plain text, then clean the noise before feeding it to the model. The presence of a refinement step signals that raw extraction is assumed too noisy to ingest directly.
2.3 Synthetic Data at Trillion-Token Scale (and Why the Generator Matters)
Qwen3 leans heavily on synthesis (see how data quality and evaluation are handled in Qwen2):
- Qwen2.5 for general synthesis
- Qwen2.5-Math for math content
- Qwen2.5-Coder for code data
The paper describes formats like textbooks, QA, instructions, and code snippets across many domains.
Data quality depends on two things here:
- Generator limitations: If the teacher model has systematic errors, they can be amplified
- Filtering and verification: The report later demonstrates a clear preference for verifiable tasks in post-training, suggesting at least some synthetic slices likely use correctness checks
3) The Three-Stage Pre-Training Strategy: Shifting the Data Distribution on Purpose
Qwen3 pre-trains in three stages. The stages are not described as "more of the same"; they change the composition and sequence-length distribution.
Stage S1: General Foundation
- 30+ trillion tokens
- 4,096 sequence length
- Goal: language proficiency + general world knowledge across 119 languages
Stage S2: A "Reasoning Stage" by Changing the Mix
- Additional ~5T higher-quality tokens
- Still 4,096 sequence length
- Increased proportion of STEM, coding, reasoning, and synthetic data
This is a data-mix intervention. "Reasoning improvement" is not attributed purely to architecture; it's also attributed to spending more compute on data that demands those skills. The focus shifts toward knowledge-intensive content that enables deeper reasoning capabilities.
Stage S3: Long-Context Training with an Explicit Length Distribution
To extend usable context length, Qwen collects "high-quality long context corpora" and pre-trains on hundreds of billions of tokens at 32,768 sequence length.
They specify a length mix:
- 75% of long-context text is 16,384–32,768 tokens
- 25% is 4,096–16,384 tokens
This matters because long context isn't just an inference feature; it's a training distribution choice. The main risk is that long documents are easier to contaminate with boilerplate and scraped junk, so curation quality becomes more important as length grows.
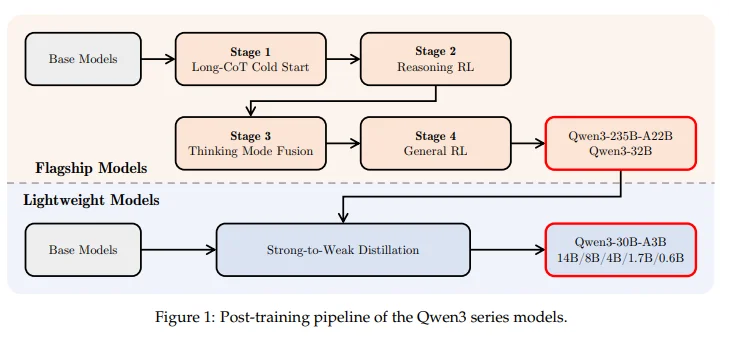
4) Post-Training as a Data Factory: Qwen3's Four-Stage Pipeline
Qwen's release framing describes four stages:
- Long-CoT cold start
- Reasoning RL
- Thinking mode fusion
- General RL
The technical report is where you see the data mechanics that make those stages work.
Two objectives guide post-training:
- Thinking control (thinking vs non-thinking, plus a budget)
- Strong-to-weak distillation (so smaller models can benefit without repeating the full expensive pipeline)
These objectives imply data reuse: expensive supervision is created once (with verification and RL) and then transferred.
5) Stage 1 — Long-CoT Cold Start: Verification-Defined Reasoning Data (with Human Fallback)
5.1 The Dataset is Built Around Verifiability
Qwen3 starts with a dataset covering math, code, logical reasoning, and general STEM, where each problem is paired with verified reference answers or code-based test cases.
This is a major data quality lever. If you can cheaply check correctness, you can filter aggressively and reduce label noise. The emphasis on verifiable tasks directly improves model performance by ensuring the training signal is unambiguous.
5.2 Two-Phase Filtering: Query Filtering and Response Filtering
Qwen applies a rigorous two-phase filtering process: query filtering and response filtering.
Query filtering: remove what can't be checked (or doesn't require reasoning)
They use a large instruction model to remove:
- Prompts that are not easily verifiable (e.g., open-ended generation, multi-subquestion prompts that can't be verified cleanly)
- Prompts the model can answer correctly without CoT reasoning (to avoid teaching fake or unnecessary reasoning)
They also annotate each query's domain to keep representation balanced.
This is an unusually explicit attempt to prevent a common failure mode: models that learn to "write reasoning" after guessing.
Response generation + human-in-the-loop fallback
After holding out a validation query set, they generate N candidate responses using a reasoning-capable model.
If the model consistently fails to produce correct solutions, human annotators manually assess accuracy.
This is one of the clearest explicit human-in-the-loop points in the report: humans are used selectively when automated generation fails. It's a practical approach to scaling—use verification where possible, reserve human effort for hard cases.
Response filtering: remove low-quality reasoning traces, not just wrong answers
For queries where at least one correct candidate exists, Qwen filters out responses that:
- Have incorrect final answers
- Contain substantial repetition
- Indicate guesswork without adequate reasoning
- Show inconsistencies between thinking and summary
- Have inappropriate language mixing or style shifts
- Appear overly similar to potential validation items
That last step matters: it acts as contamination control so evaluation isn't inadvertently trained on.
5.3 Cold Start Goal: Teach Reasoning Patterns, Not Maximize Scores
Qwen states the cold start aims to "instill foundational reasoning patterns" without over-optimizing immediately; they prefer to minimize samples and steps here. The idea is to get the model into the right basin, then let RL push performance.
6) Stage 2 — Reasoning RL: Feedback Quality via Rules and Verifiers
The reasoning RL stage is described as using rule-based rewards to scale RL compute on verifiable tasks.
A key reported result is that for a large MoE model, AIME'24 improves substantially over RL steps (the report provides an example trajectory).
From a data perspective, what matters is the kind of feedback:
- If tasks are verifiable (final answers, unit tests), rule-based rewards can be precise
- Precision reduces reward noise and makes RL less fragile
This is why Qwen's insistence on verifiable reasoning data in Stage 1 is foundational: it enables a cleaner RL signal in Stage 2.
7) Stage 3 — Thinking Mode Fusion: Teaching "Think" and "Don't Think" Without Destroying Either
This stage is where Qwen3's "hybrid model" becomes real, and it's heavily data-dependent.
7.1 The Core Risk: Too Much CoT Can Degrade Normal Responses
A known practical risk is that pushing too much chain-of-thought style supervision can hurt brevity, instruction compliance, and sometimes even correctness on short tasks.
Fusion is Qwen's answer: treat "think" and "no-think" as two distributions and deliberately preserve both.
7.2 SFT Data Construction: "Thinking" via Rejection Sampling; "Non-Thinking" via Curated Diversity
Qwen describes:
- "Thinking" data is generated via rejection sampling on Stage 1 queries using the Stage 2 model, retaining high-quality reasoning traces
- "Non-thinking" data is carefully curated to cover coding, math, instruction following, multilingual tasks, creative writing, QA, and role-playing
- They use automatically generated checklists to assess response quality for non-thinking data
- They increase the proportion of translation tasks to support low-resource languages
This is important: they do not treat non-thinking mode as "whatever chat data we have." It is curated to preserve breadth and multilingual performance.
7.3 Chat Template Design: Mode Switching as Supervised Behavior
They introduce explicit flags such as /think and /no think. For non-thinking samples they keep an empty thinking block to maintain internal format consistency.
This is a subtle data design choice: consistent formatting reduces accidental distribution shifts between modes.
7.4 Thinking Budget Control: "Stop Thinking" as a Learned Pattern
After fusion, Qwen describes a budget mechanism where the thinking trace can be halted and the model instructed to stop thinking and produce a final answer from partial reasoning.
Whether you call this emergent or learned, it is enabled by training the model on a format where thinking and answering are separate segments.
8) Stage 4 — General RL: Where Preference Data and Human-in-the-Loop Become More Visible
General RL is described as improving broad capabilities and stability across scenarios, using a reward system spanning 20+ tasks.
Qwen describes three reward types:
- Rule-based reward (correctness, formatting, instruction adherence)
- Model-based reward with reference answers (a strong judge model compares against references)
- Model-based reward without reference answers, using a reward model trained from human preference data
This is the closest the report comes to a classic RLHF story: human preferences label responses; a reward model learns those preferences; RL optimizes behavior.
Human-in-the-Loop Interpretation: Humans Appear at Multiple Leverage Points
Even when not framed as "human-in-the-loop," humans are embedded:
- Humans adjudicate accuracy for hard problems when automated solvers fail
- Humans provide preference labels to train reward models
- Humans design rubrics, task definitions, and what counts as "good" behavior
That last point is often the most important: reward design is human judgment formalized. The alignment of model outputs with human preferences depends entirely on how carefully those preferences are captured, validated, and scaled.
Agentic RL Includes Environment Feedback
For agent capabilities and tool use, Qwen describes RL rollouts that can include multi-turn interaction cycles with real environment execution feedback, improving long-horizon stability.
This shifts supervision from "human says it looks good" to "the environment confirms it worked," but it increases the burden on environment design and evaluation harnesses. The model's ability to leverage tools like a code interpreter or perform deep research depends on this feedback loop quality.
9) Strong-to-Weak Distillation: Turning Expensive Post-Training into Reusable Supervision
Qwen3 does not want to run the full four-stage pipeline for every smaller model. Instead, it uses distillation:
- Off-policy distillation: Combine teacher outputs from both think and no-think modes
- On-policy distillation: The student generates; the student's logits are aligned to a teacher via KL divergence
Qwen reports that distillation can outperform RL for an 8B student in their comparison while using far fewer GPU hours.
From a data standpoint, distillation is a way to:
- Reuse good trajectories and style decisions
- Transfer mode-following behavior
- Potentially reduce label noise versus raw preference data at scale
This efficient approach to knowledge transfer demonstrates how investing in high-quality supervision once can enable scaled deployment without proportionally scaled costs.
10) Evaluation as Data: What Qwen3 Chooses to Measure (and What It Might Miss)
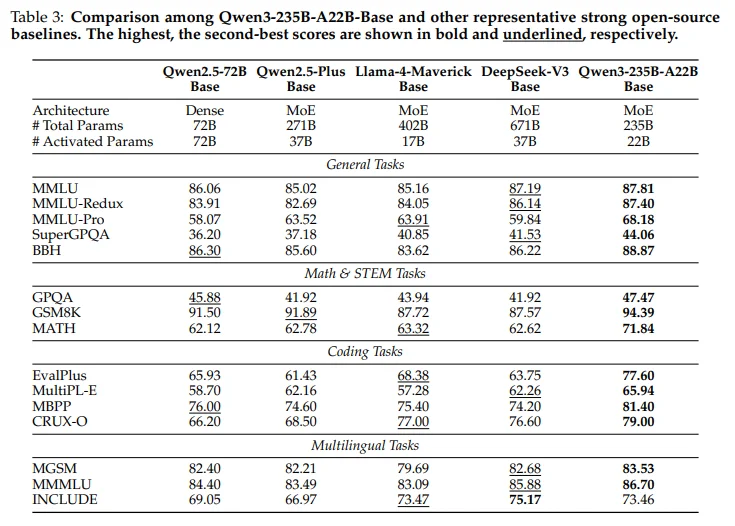
10.1 Base Model Evaluation: General + Math + Code + Multilingual
The report evaluates base models across a broad benchmark suite spanning general knowledge, reasoning, math, coding, and multilingual tasks. Qwen3 has been reported to outperform other foundation models such as GPT-4o and Claude 4 Opus Non-thinking in certain benchmarks.
The key thing to remember is that benchmarks are themselves datasets with assumptions and leakage risks. The report includes at least one explicit anti-contamination filtering step in Stage 1 (removing responses suspected to be overly similar to validation items), but full contamination controls are not exhaustively described in the excerpted sections.
10.2 Post-Training Evaluation Includes Internal Behavioral Tests
Qwen also introduces internal tests designed around their product goals:
- Hallucination avoidance on counterfactual prompts
- Length control
- Think/no-think compliance
- Tool usage stability
This is evaluation aligned with what they are trying to ship: controllable reasoning and stable agent/tool use behavior.
10.3 Thinking Budget Scaling is Explicitly Evaluated
Qwen reports smooth performance improvements as thinking budget increases and suggests further improvements may be possible with even larger thinking budgets.
When thinking about Qwen3 Max Thinking: scaling inference-time compute is part of the capability story, not just parameter count.
11) What Likely Carries Over to Qwen3 Max Thinking (and What We Shouldn't Assume)
Qwen3 Max Thinking is Alibaba's most capable reasoning model yet, trained with massive scale and advanced reinforcement learning. The Qwen team frames it as pushing the model "beyond its limits," achieved by scaling up model parameters and leveraging substantial computational resources.
Given Qwen3's published pipeline, the conservative, defensible inference is:
Likely Shared Principles
- Verification-first reasoning data: Qwen3's strongest data machinery is built around verifiable tasks and aggressive filtering. A flagship reasoning model is unlikely to abandon that
- Multi-stage post-training rather than "just RLHF": The cold-start + reasoning RL + fusion + general RL scaffold is central to Qwen3's controllable thinking story
- Human preferences and rubric design remain crucial: Longer reasoning increases opportunities for verbosity, drift, and unsafe or unhelpful content. Preference alignment tends to become more important as "thinking" scales
Key Capabilities of Qwen3 Max Thinking
According to available documentation:
- The model utilizes advanced test-time scaling techniques that significantly boost reasoning performance, surpassing Gemini 3 Pro on key reasoning benchmarks
- Qwen3 Max Thinking features adaptive tool-use capabilities that autonomously select and leverage built-in tools like Search, Memory, and Code Interpreter during conversations
- The model employs a test-time scaling strategy that enables multi-round self-reflection
- It demonstrates performance comparable to leading models such as GPT-5.2-Thinking and Claude-Opus-4.5 on 19 established benchmarks
- The model's adaptive tool-use capabilities help mitigate hallucinations and provide access to real-time information through deep research capabilities
What We Should Not Assume
- Exact dataset composition changes versus Qwen3
- Exact human preference pipeline details
- Exact mixture weights, language emphasis, or synthetic vs real proportions
Unless the Max Thinking documentation provides these specifics in plain terms, the safest stance is: Max Thinking appears to scale the Qwen3 blueprint, but the precise data deltas are not clearly stated in the accessible excerpt.
12) Practical Synthesis: Why Qwen3's Data Choices Matter
If you strip away branding ("hybrid thinking"), Qwen3's training story is a set of repeatable lessons about data quality:
Reasoning Improves When Correctness is Cheap to Check
Qwen3's long-CoT dataset is built around verified answers and tests, plus filtering that removes unverifiable prompts and low-quality reasoning traces.
"Thinking" is a Distribution You Must Train, Not a Switch You Flip
Fusion works because Qwen constructs and filters two distributions ("think" and "no-think"), then supervises the model to follow flags consistently.
RL is Only as Good as the Reward Data—and Reward Data is Still a Human Design Problem
Even with rule-based and reference-based scoring, broad helpfulness relies on human preference data and reward modeling.
Long Context Isn't an Inference Feature; It's a Corpus Choice
Qwen3 specifies a long-context length distribution and trains heavily on truly long examples.
Human Experts Show Up Where Automation Breaks
The report's most explicit human-in-the-loop moment is also the most pragmatic: when automated solvers fail to produce correct solutions, humans adjudicate accuracy.
13) The Enterprise Imperative: Why Data Infrastructure Determines AI Success
Qwen3's technical report reveals a fundamental truth that extends far beyond frontier model development: the quality of AI systems is determined by the quality of data decisions made throughout the development lifecycle.
Every stage of Qwen3's pipeline—from pre-training mixture optimization to post-training verification to human preference alignment—represents a data quality intervention. The difference between a model that performs well on benchmarks and one that performs well in production is often traceable to these decisions:
- Who labeled the data? Domain experts or general annotators?
- How was quality verified? Rule-based validation, model-based scoring, or human review?
- How were disagreements resolved? Consensus mechanisms, expert adjudication, or majority vote?
- How was the data audited? Complete traceability or opaque pipelines?
For organizations building production AI systems, these questions are not academic. They determine whether AI models understand domain nuances, comply with regulatory requirements, and deliver reliable performance.
The Qwen3 report demonstrates that even with computational resources that most enterprises cannot match, data quality remains the binding constraint. Alibaba Cloud invested in:
- Systematic annotation across 30+ trillion tokens
- Domain labeling for mixture optimization
- Human-in-the-loop adjudication for difficult cases
- Multi-stage validation and filtering
- Complete traceability for contamination control
These practices—scaled appropriately—are precisely what enterprises need to build AI systems that work reliably in production.
Bridging the Gap: Enterprise Data Infrastructure for AI
The challenge for most organizations is not understanding that data quality matters—it's operationalizing that understanding at scale. This requires:
- Collaboration at Scale: Domain experts (radiologists, underwriters, quality engineers) must be embedded throughout the AI development lifecycle, not just at the final validation checkpoint
- Verification-First Workflows: Data pipelines should be built around verifiable tasks wherever possible, with clear feedback mechanisms for ambiguous cases
- Human-in-the-Loop by Design: Human judgment should be systematically captured and scaled, not treated as an afterthought when automation fails
- Complete Traceability: Every data decision—who labeled each asset, who reviewed it, what consensus was reached—should be documented and auditable
- Flexible Quality Metrics: Consensus, honeypot validation, and review scoring should be configurable to match domain requirements
This is where purpose-built data infrastructure becomes essential. The same principles that enable frontier labs like Alibaba Cloud to build models like Qwen3—systematic annotation, domain expertise integration, verification workflows, and complete auditability—apply to enterprise AI at any scale.
Organizations that treat data labeling as a commodity task, disconnected from domain expertise and quality assurance, will continue to struggle with AI systems that underperform in production. Those that invest in collaborative data infrastructure—enabling technical and non-technical teams to work together throughout the AI development lifecycle—will build AI systems that reflect genuine domain understanding, not just statistical patterns.
Resources
- Qwen3 Technical Report (arXiv:2505.09388)
- "Pushing Qwen3-Max-Thinking Beyond its Limits" (Qwen blog)
- Qwen3 model cards and release notes (Hugging Face)
- Qwen3 models are available through chat.qwen.ai and can be downloaded via Hugging Face
Frequently Asked Questions
What is Qwen 3?
Qwen 3 is a family of dense and Mixture-of-Experts large language models developed by Alibaba Cloud, ranging from 0.6B to 235B total parameters. It features a hybrid thinking interface that can produce long reasoning traces or respond quickly within a single model, trained on 36 trillion tokens across 119 languages.
How much training data was used for Qwen 3?
Qwen 3 was pre-trained on 36 trillion tokens in three stages: over 30 trillion in the general foundation stage at 4,096 sequence length, approximately 5 trillion additional higher-quality tokens in a reasoning-focused stage, and hundreds of billions more at 32,768 sequence length for long-context training.
How does Qwen 3 use earlier Qwen models in its data pipeline?
Earlier Qwen models serve as data factory components. Qwen2.5-VL handles text recognition from PDF-like documents, Qwen2.5 refines the recognized text, Qwen2.5-Math synthesizes math content, and Qwen2.5-Coder generates code data. This means the quality of the generator model directly constrains the quality of the student model’s training data.
What is the thinking mode in Qwen 3 and how is it trained?
Qwen 3 supports controllable thinking and non-thinking modes within a single model, toggled by explicit flags. Rather than a simple switch, these are two separately curated data distributions: thinking data is generated via rejection sampling with verified reasoning traces, while non-thinking data is carefully curated to preserve breadth across coding, math, multilingual tasks, and creative writing.
How does Qwen 3’s post-training pipeline work?
Post-training follows four stages: Long-CoT cold start with verification-defined reasoning data, reasoning RL with rule-based rewards on verifiable tasks, thinking mode fusion that teaches both think and non-think distributions, and general RL using a mix of rule-based, reference-based, and human-preference-based reward signals across 20+ task types.
Where do human annotators appear in the Qwen 3 pipeline?
Humans appear at multiple leverage points: adjudicating accuracy when automated solvers fail to produce correct solutions, providing preference labels to train reward models, and designing the rubrics and task definitions that formalize what counts as good behavior. The report’s most explicit human-in-the-loop moment is when human annotators manually assess accuracy for problems that models consistently fail to solve.
What is strong-to-weak distillation in Qwen 3?
Qwen 3 uses distillation to transfer expensive post-training supervision into smaller models without repeating the full four-stage pipeline. This combines off-policy distillation from teacher outputs and on-policy distillation aligning student logits to the teacher via KL divergence. Qwen reports that distillation outperforms RL for an 8B student model at a fraction of the GPU cost.
Need Expert Data Infrastructure for Your AI Training Pipeline?
Qwen 3’s pipeline demonstrates that even at 36 trillion tokens, data quality remains the binding constraint — from systematic annotation and domain labeling to human-in-the-loop adjudication for hard cases. Kili Technology provides the same principles at enterprise scale: verified domain specialists, configurable quality workflows, and full traceability across every labeling decision.