
.png)


_logo%201.svg)


AI Summary
- FineWeb2 covers 1,000+ languages across ~20TB and 5B documents, but its real product is the language-adaptive pipeline — not the static dataset.
- Language identification with GlotLID and per-language confidence thresholds replace the one-global-cutoff approach that breaks for low-resource languages.
- MinHash deduplication preserves cluster size as metadata, turning dedup from destructive removal into a sampling signal used during rehydration.
- Filter thresholds are derived per language using distribution-based rules, with reference corpora like Wikipedia themselves cleaned to avoid English contamination of stopword lists.
- Hundreds of ablation training runs across nine canary languages select pipeline configurations — filter design becomes an optimization problem against downstream model behavior.
- Native-speaker audits validate precision filtering for low-resource languages, reinforcing that automated pipelines handle volume while domain experts validate quality at decision points.
FineWeb2 was first released publicly as v2.0.0 on December 8, 2024. It was launched for a straightforward reason: the community had started to converge on more repeatable ways to curate high-quality English web text, while multilingual pretraining still depended on processing pipelines that didn't transfer cleanly across languages and scripts.
FineWeb2 takes the FineWeb idea—web extraction, deduplication, and quality filtering validated through training—and extends it to multilingual datasets by making the pipeline language-adaptive. The research paper describing the full approach was published on June 2025.
In terms of scale, FineWeb2 is built from 96 Common Crawl snapshots spanning the summer of 2013 to April 2024. The processed release comprises approximately 20 terabytes of diverse text data across about 5 billion documents, covering more than 1,000 languages and many language–script pairs. FineWeb2 also publishes what its filters removed (per-language _removed subsets), which makes the filtering decisions inspectable and easier to iterate on.
This article breaks down FineWeb2 as a data system:
- how the raw data was assembled
- what was filtered out (and why)
- how thresholds were adapted across languages
- what "rehydration" is doing and what it implies
- how teams actually use FineWeb2 in model training
We'll also make light comparisons to the original FineWeb (2024) where it clarifies what changed, but FineWeb2 is the focus. The dataset is released under the Open Data Commons Attribution License (ODC-By) v1.0, making it accessible for both research and commercial applications.
1) What FineWeb2 Is (and What It Is Not)
FineWeb2 is a multilingual pre-training dataset built from Common Crawl snapshots spanning roughly 2013–2024, processed with a pipeline designed to scale across languages and scripts.
A few boundaries matter immediately:
- FineWeb2 is primarily non-English. The dataset is built from the portion of Common Crawl that did not pass FineWeb's English-identification threshold. In practice, you should treat FineWeb2 as the non-English complement to an English-heavy corpus (often FineWeb itself).
- FineWeb2 is a dataset and a pipeline. The dataset is the artifact, but the pipeline is the product. FineWeb2 is closer to "a reproducible recipe to produce per-language web corpora" than a single monolithic dump.
- FineWeb2 is curated via heuristics and downstream training signals. It uses heuristic filters (ratios, repetitions, punctuation, stopwords), but their thresholds are not treated as universal constants. They are automatically adapted per language using distribution-based rules and validated through model training and evaluation.
If you are familiar with FineWeb (2024), the key shift is simple: FineWeb made high-quality English web data reproducible at scale; FineWeb2 attempts to make that reproducibility extend to every language, including low-resource languages where "basic assumptions" (word boundaries, classifier coverage, benchmark availability) can break.
2) Where the Raw Data Comes From (and How It Becomes Text)
Before getting into filtering and deduplication pipelines, it helps to be clear about what "multilingual web data" looks like at this scale.
- Coverage is wide, but highly uneven. A small set of languages dominates the byte distribution.
- Many low-resource languages exist mostly as UI fragments, copied boilerplate, or misclassified content.
- Script matters almost as much as language, because script shifts change tokenization and filter behavior.
FineWeb2 embraces that reality by treating language–script pairs as first-class citizens in the pipeline.
FineWeb2 starts from the same underlying source most web-scale corpora start from: Common Crawl.
Common Crawl provides "snapshots" of the public web as WARC files. FineWeb2 processes almost 100 snapshots over a long time window. That time depth matters because it increases language coverage and diversity, but it also increases duplication, boilerplate, and distribution drift across years.
2.1 The Key Design Choice: Start from "Non-English" Common Crawl
FineWeb2's starting point is a practical reuse decision:
- The FineWeb pipeline already processed Common Crawl and separated out a large set of documents that were not confidently English.
- FineWeb2 takes that remaining pool (the majority of extracted documents) and treats it as the raw material for multilingual curation.
This does two things:
- It saves computation compared to re-processing all raw WARC content from scratch.
- It makes FineWeb and FineWeb2 naturally complementary: FineWeb covers English-heavy data, FineWeb2 covers the rest.
This also introduces a caveat: the "non-English pool" is still full of English. Some of it is misclassified; some is genuinely multilingual content; some is English boilerplate wrapped around another language. FineWeb2's processing pipeline is built around the idea that language identification and precision filtering are not optional for multilingual web data.
2.2 Turning WARC Files into Text
The first transformation step is the one most people skip over, but it sets constraints on everything that follows.
2.2.1 URL Filtering and Early Safety Controls
Before extracting text, FineWeb2 applies URL filtering using a blocklist approach intended to remove adult content. The dataset also includes automated PII anonymization features to help developers create compliant artificial intelligence tools.
Two practical implications:
- URL filtering is cheap compared to deep content classifiers. At large scale, cheap matters.
- URL filtering is imperfect: it misses pages that should be excluded, and it removes some pages you might want. What matters is whether the remaining pipeline can still produce a usable distribution.
2.2.2 HTML-to-Text Extraction
FineWeb2 uses an HTML extraction tool (trafilatura) to pull the "main text" from crawled pages.
This choice has downstream consequences:
- Some filters assume access to paragraph structure, headings, or clean line boundaries. Extraction tools differ in how much structure they preserve.
- Table-heavy pages, navigation-heavy pages, and templated pages can produce extraction artifacts (e.g., repeated cells, duplicated lines, strange punctuation patterns).
FineWeb2's pipeline includes practical fixes for extraction issues (including table artifacts) and encoding issues.
This is a recurring theme: if you use heuristic filters, your filters implicitly assume a particular format of text. If the extractor changes, your filter behavior changes.
3) Language Identification (LID): The Foundation for "Multilingual"
If FineWeb2 has a single core dependency, it's language identification.
A multilingual dataset does not start with multilingual text. It starts with a large pile of unlabeled text where language boundaries are ambiguous.
3.1 Why LID Breaks in Low-Resource Settings
Web corpora have extreme class imbalance: there is a lot of English, a lot of a handful of high-resource languages, and a long tail of languages with very small real presence.
This leads to predictable failure modes:
- Out-of-coverage errors: if your LID model does not have a label for a language, it will shove it into a nearby label.
- Cousin confusion: languages that are close (or share script and vocabulary) are hard to separate.
- Boilerplate dominance: navigation, cookie banners, and templated UI strings can dominate short pages and skew predictions.
- Mixed-language pages: many pages are genuinely multilingual; forcing one label means you either keep noise or discard useful material.
FineWeb2 addresses this by using a language identifier with very large label coverage and explicit script handling.
3.2 GlotLID: More Labels, Scripts, and "Noise" Classes
Language identification was performed using GlotLID, a classifier that covers a wider variety of languages compared to other classifiers. GlotLID supports a very large number of language labels and distinguishes different scripts.
The practical benefits are not just academic:
- Script separation lets you treat, for example, "the same language in different scripts" as different distributions.
- "Noise" labels reduce the chance that corrupted content gets misclassified as a real language.
- Large coverage reduces cousin confusion caused by unsupported languages.
This is one of FineWeb2's core upgrades relative to FineWeb (2024), which used a much smaller-coverage LID approach oriented around English filtering.
3.3 Per-Language Confidence Thresholds Instead of One Global Cutoff
A common pattern in older multilingual corpora is: pick a confidence threshold (say 0.5 or 0.7) and apply it to every language.
FineWeb2 avoids that. Instead, different minimum language classifier confidence scores were defined to keep a document for each language, using a distribution-based formula.
Why does this matter?
- Confidence scores are not calibrated equally across languages.
- Some languages will have a tight, high-confidence distribution; others will be broad and right-skewed.
- If you apply one global threshold, you either:
- keep too much noise for hard languages, or
- delete most data for easy languages.
FineWeb2's straightforward and principled approach is pragmatic: for a set of "canary languages," it trains models at multiple confidence thresholds (chosen to remove data in consistent increments), evaluates them, and uses that evidence to define a per-language threshold rule.
This turns LID from a fixed preprocessing step into a tunable data quality knob.
4) Deduplication (and Rehydration): Reducing Redundancy Without Flattening the Distribution
Deduplication is a standard move in large-scale corpora: remove near-duplicate documents to improve training efficiency and reduce overfitting to templated content.
FineWeb2 performs global, per-language deduplication using MinHash-based clustering to remove highly similar documents, which increases training efficiency. It clusters similar documents and keeps only one representative.
4.1 What Changed Relative to FineWeb
FineWeb (2024) made an argument for per-snapshot deduplication in some settings, partly to avoid strange distribution shifts created by global deduplication.
FineWeb2 deduplicates globally per language, rather than per CommonCrawl snapshot.
The reason is practical: FineWeb2 runs extensive filtering ablations. If deduplication happens at the end, deduplication changes the effective dataset every time you tweak filters, which makes it hard to attribute improvements.
So FineWeb2 moves deduplication earlier in the pipeline.
4.2 The Key Detail: Keep the Duplicate Cluster Size
FineWeb2 does something important: while it removes duplicates, the deduplication process saved the size of each duplicate cluster in the metadata of the kept document (minhash_cluster_size).
This turns deduplication from a destructive step into a step that produces a useful signal.
Cluster size is a proxy for:
- how templated or mass-reposted a document is
- how likely it is to be boilerplate
- how "webby" it is
But duplication count is not a pure quality measure. Some valuable documents are widely mirrored; some spam is unique.
That's why FineWeb2 does not treat cluster size as an exclusion rule by itself. It uses it as a later sampling and rebalancing signal.
4.3 Rehydration: Using Dedup Metadata as a Sampling Signal
After deduplication, you usually have a single decision: keep one document per cluster.
FineWeb2 makes a second decision: how much should we reintroduce duplicated content through upsampling?
This is what it calls "rehydration."
4.3.1 Why Rehydration Exists
Deduplication improves efficiency, but it also changes the dataset distribution.
If a document has many duplicates across the web, removing them all can:
- reduce exposure to very common phrasing and patterns
- shift the distribution toward more unique, sometimes noisier content
FineWeb2's position is pragmatic: deduplication is useful, but some duplicated content is worth keeping more than once.
4.3.2 The Key Idea: Cluster Size Correlates with Quality in a Non-Linear Way
FineWeb2 observes an interesting pattern: both extremes can be lower quality.
- cluster size = 1 can include genuinely unique text, but also high-entropy junk
- very large clusters often correspond to boilerplate or spam
So it is not as simple as "more duplicates = worse" or "more duplicates = better."
4.3.3 How FineWeb2 Chooses Upsampling Weights
Rather than choosing fixed weights globally, the 'rehydration' approach in FineWeb2 selectively upsamples documents based on their original duplication counts and quality signals to optimize performance.
- compute how often each cluster size gets filtered out
- assign higher upsampling to cluster sizes that look higher-quality
- downweight cluster sizes that exceed the global removal rate
This is an engineering move:
- it is scalable
- it ties upsampling to the same filter logic already validated through model training
- it avoids hand-tuned weights that may not transfer across other languages
The result is a duplication-aware sampling strategy that is still grounded in the pipeline's quality signals.
5) Filtering and Thresholding: Keep the Rules, Adapt Them Per Language
FineWeb2's filtering stage is where most of the work lives.
Instead of inventing an entirely new filter set per language, FineWeb2 largely inherits the filtering philosophy from FineWeb and related web-corpus pipelines:
- FineWeb-style quality filters
- Gopher-style quality and repetition filters
The main problem is not writing filters. The main problem is that filter thresholds are language-dependent.
A filter like "average word length must be below X" is meaningless if X is tuned for English.
5.1 The Filtering Rules Are Heuristics, but They Are Not Arbitrary
FineWeb2's filters are largely based on measurable criteria and surface signals:
- ratio of symbols to words
- fraction of lines that do not end in punctuation
- fraction of duplicate lines
- n-gram repetition concentration
- stopword presence
These heuristics are trying to remove content that tends to correlate with worse downstream model quality:
- gibberish
- templated boilerplate
- spam and SEO blocks
- broken extraction artifacts
- extremely repetitive content
This is a familiar set. The novel selection process is how FineWeb2 adapts thresholds using language-specific statistics.
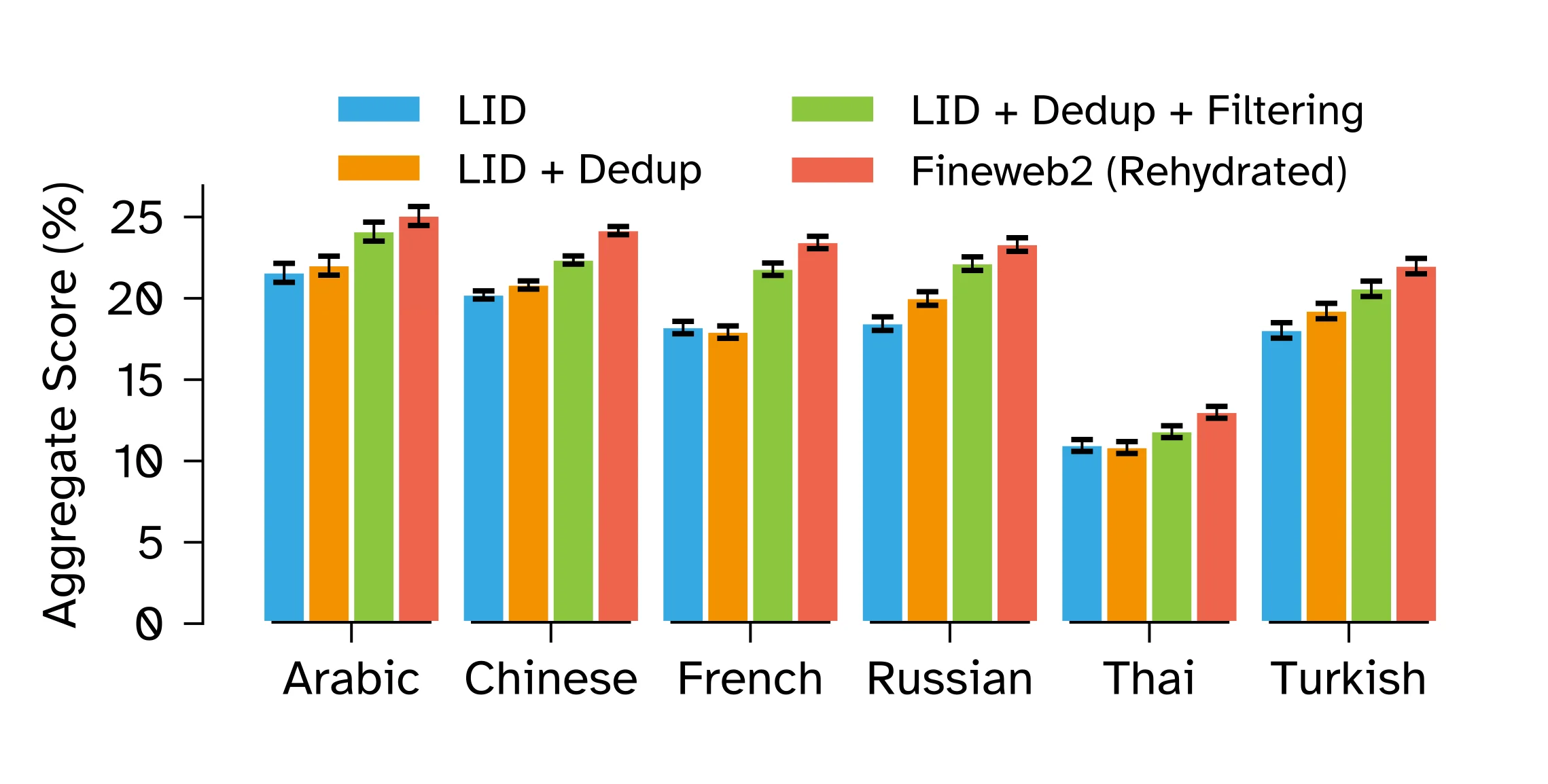
5.2 Word Boundaries Are a Multilingual Filtering Bottleneck
Many heuristic filters operate on "words": average word length, ratios of alphabetic words, stopword counts, repetition measured as word n-grams, and so on.
That assumes you can segment text into words. For many different scripts and languages, that is not a given.
If you define "word" incorrectly:
- average word length becomes meaningless
- stopword filters collapse
- repetition filters either over-trigger or never trigger
FineWeb2 addresses this by assigning word tokenizers using a mix of native tokenizers where available and proxy assignments where they are not.
5.2.1 Proxy Tokenizers via Language Families
FineWeb2 uses language family information to propagate tokenizers:
- If a language has a native tokenizer, it uses it.
- If not, it assigns a tokenizer from a closely related language within the same family and script.
- Tokenizers are propagated within subfamilies, not across top-level family branches.
This is a compromise. It gives the pipeline a way to compute word-level metrics for thousands of languages without building thousands of bespoke tokenizers.
It also introduces a practical limitation: some individual languages will receive tokenizers that do not match their real morphology or segmentation rules. The pipeline is designed to still be better than "no word model at all," but it does not eliminate the need for language expertise when quality matters.
5.3 The Threshold Adaptation Problem
Suppose a filter says "remove the tail of documents with very high average word length."
In German, words are longer on average.
In Chinese, "word length" depends entirely on segmentation.
In a language with limited tokenizer quality, word length might be noisy.
So you need a rule that says: for this metric, in this language, where should the cutoff be?
FineWeb2 uses an adaptive curation pipeline that tailors quality filtering, deduplication, and data balancing strategies to each language's specific characteristics. It collects metric distributions per language from reference datasets and chooses language-specific thresholds based on distribution-derived rules.
5.4 Reference Corpora: Why Wikipedia Shows Up Everywhere
FineWeb2 relies on three major sources for per-language statistics:
- Wikipedia (when available)
- GlotLID-Corpus (used to train the LID classifier)
- the language-filtered Common Crawl data itself
Wikipedia is common here for a reason:
- it is relatively clean
- it exists in many languages
- it is easy to access at scale
But Wikipedia is not "ground truth" for language purity, and FineWeb2 runs into a real issue: low-resource Wikipedias can contain substantial English content.
That becomes important when you use Wikipedia to derive stopwords.
5.5 Stopwords: A Small Component with a Large Impact
Stopword filtering is a classic trick: if a document in a language contains none of the language's common words, it is likely not real text in that language.
FineWeb2 uses stopwords as part of the Gopher-quality filter recipe.
5.5.1 How Stopwords Are Derived
Instead of selecting a fixed number of stopwords per language, FineWeb2 defines stopwords as words exceeding a frequency threshold in reference datasets.
That matters because languages distribute frequency differently:
- English has "the" as a dominant frequent word.
- German distributes that function across "der/die/das".
Using frequency thresholds lets the stopword list adapt naturally.
5.5.2 The Hidden Dependency: Your Reference Corpus Must Be Clean
FineWeb2 found a failure mode that is easy to miss:
- For some low-resource languages, their Wikipedia contains many untranslated English pages.
- If you derive stopwords from that Wikipedia, your stopword list will include English.
- Then stopword filtering fails to remove misclassified English.
FineWeb2 responds by "cleaning" Wikipedias with processing steps like:
- removing sections that frequently contain foreign-language references
- dropping pages whose script does not match the expected main script
- dropping pages predicted as English with high confidence
Then it recomputes stopwords.
This is a strong reminder that filters are only as good as the data you use to calibrate them.
In a multilingual pipeline, even your reference datasets need their own data quality checks.
5.6 Choosing Thresholds: Evidence-Driven, but Expensive
FineWeb2 compares several threshold adaptation strategies.
Rather than only reporting "we picked method X," it builds an evaluation framework where methods are tested by training and scoring models using different metrics.
Here are the core strategies FineWeb2 considers:
- English thresholds: keep the English thresholds unchanged as a baseline.
- Mean/Std shifting: map an English cutoff to a cutoff at the same standardized distance from the mean (or median) of the target language distribution.
- Quantile matching: choose the threshold that removes the same fraction of data as the English threshold removes in English.
- Tail removal (e.g., 10Tail): remove a fixed tail proportion (such as 10%) of the reference distribution.
- Median-ratio mapping: scale thresholds based on the ratio of medians between English and the target language.
These are not arbitrary. They represent different assumptions about what makes a metric comparable across languages.
The important part is how FineWeb2 chooses among them.
5.6.1 "Canary Languages" and Model-Based Ablations

FineWeb2 uses a set of nine diverse "canary languages" spanning scripts and resource availability levels.
For each language and each threshold method, it trains models and evaluates them on a suite of informative evaluation tasks.
This is not a small effort. FineWeb2 runs hundreds of ablation trainings to extensively ablate and compare pipeline variants.
The point is worth underlining:
FineWeb2 treats filter selection as an optimization problem where the objective is downstream model behavior, not proxy cleanliness metrics.
That is a very different mindset from building a dataset by eyeballing examples and shipping.
5.6.2 Evaluation Tasks as an Engineering Constraint
Evaluating multilingual models is messy. Some tasks are poorly translated, overly difficult, or noisy.
FineWeb2 explicitly tries to find tasks that provide "early signal" during training.
It defines key criteria such as:
- monotonic improvement as training progresses
- low noise and consistent ordering between model variants
- non-random performance early enough to differentiate data
This matters because the entire pipeline selection process depends on getting reliable feedback. If your evaluation codebases are garbage, you will optimize your dataset toward noise.
6) Precision Filtering for Low-Resource Languages: Fixing the Worst Failure Mode
Low-resource languages suffer from a specific version of LID failure: you can end up with a corpus that is mostly a high-resource cousin language.
This happens because:
- the true amount of content for the low-resource language is small
- the model's measured accuracy on balanced benchmarks does not reflect real-world precision in imbalanced web data
FineWeb2 adds a targeted "precision filtering" step for languages where contamination is high, aiming to improve the representation of lower-resource languages that have historically been underserved in natural language processing.
6.1 High-Affinity Wordlists
The idea is straightforward:
- build a list of words that are common in a language and uncommon elsewhere
- measure contamination as the fraction of documents that contain none of these words
- filter documents that fail the affinity test
This is more language-sensitive than stopwords. Stopwords catch "non-text" and generic noise; affinity wordlists target cousin confusion.
6.2 A Simple but Important Escape Hatch: URL Hints
Wordlists can be too strict for some languages (especially English-based pidgins or mixed varieties).
FineWeb2 keeps some documents that fail the wordlist test if the URL includes language-related hints:
- language codes
- language names
- domain hints
This is a good example of a real pipeline principle: if your precision filter is brittle, you add alternate weak signals and keep candidates for later analysis.
6.3 Where Humans Enter the Loop
FineWeb2 validates this step by manual audits of low-resource languages using native speakers who label sampled documents as in-language or not.
This is one of the clearest examples of human expertise being unavoidable:
- you can measure contamination automatically
- you still need people to label what "in-language" means for difficult edge cases
At web scale, the role of humans shifts. They do not label billions of documents. They label small, carefully chosen samples that validate high-leverage pipeline steps.
This reflects a broader principle in machine learning data curation: automated pipelines handle volume, but domain experts validate quality at critical decision points. Whether you're building multilingual corpora or training specialized AI systems, the combination of scalable automation and targeted expert review consistently produces more performant models than either approach alone.
7) Using FineWeb2 in Practice: What's Released and How Teams Train on It
FineWeb2 is released in a way that supports both model training and analysis, making it suitable for multilingual research and practical applications.
7.1 Languages, Subsets, and "Why Is There a Removed Split?"
FineWeb2 is organized by language (often language–script). The dataset's organization into language-script pairs enhances its utility for multilingual research. For many languages you'll see multiple subsets, typically including a filtered subset (what the heuristics keep) and a removed subset (what the heuristics rejected).
Two practical reasons this design is valuable:
- It makes filtering decisions auditable. You can sample the removed side and understand what your model would have seen otherwise.
- It supports pipeline iteration. If you want stricter or looser filters, you can start from the globally deduplicated pool and re-run threshold logic without rebuilding everything from raw WARC.
FineWeb2's dataset documentation also notes that the filtered + removed subsets for a given language represent the full post-deduplication pool for that language, which means you generally do not need to re-deduplicate unless you are mixing multiple sources.
7.2 Metadata Fields You Can Actually Use
FineWeb2 is released with metadata that makes it more usable than "text-only dumps."
Typical fields include:
- extracted text
- a document identifier
- the Common Crawl snapshot ("dump") and crawl date
- the URL
- language and script labels
- language confidence score
- top predicted language labels
- MinHash cluster size
This is not just bookkeeping.
It enables real workflows:
- sampling and filtering by confidence
- diagnosing contamination via top language confusion
- rehydration or curriculum sampling via cluster size
- building per-language train/validation splits based on snapshot or domain patterns
FineWeb2 also releases a "preliminary" version before filtering, explicitly encouraging further multilingual research into alternative filtering methods.
That stance is useful: heuristic filtering is not the final word, and releasing pre-filtered material lets other teams test different tradeoffs.
7.3 Specialized Subsets for Faster Training
Specialized subsets of FineWeb2, such as FineWeb2-HQ, enable pre-training models significantly faster while achieving the same or better performance than the larger base dataset. This allows teams to iterate more quickly during development while maintaining data quality standards.
7.4 How FineWeb2 Is Used in Training AI Models
FineWeb2 is primarily a pretraining corpus, but the way it is used depends on what you are building. The dataset is designed to be used as a research artifact for pretraining datasets for large language models.
7.4.1 Training Multilingual Foundation Models
The most direct use case is training performant multilingual LLMs.
A practical recipe looks like:
- choose a tokenizer and model architecture
- decide on a data mixture (FineWeb2 + an English corpus + code, then instruction data later)
- sample per language using a chosen weighting scheme
- train with careful monitoring of multilingual evaluation
FineWeb2 helps with steps (2) and (3) because it provides:
- broad language coverage across most languages
- consistent processing across individual languages
- metadata needed to control sampling
If you already have an English-heavy dataset (often FineWeb or other datasets), FineWeb2 slots in as the multilingual component. In practice, the mixing question becomes: how aggressively do we upweight low-resource languages versus training on the web's natural distribution?
Many teams handle this with some form of "temperature" sampling or capped per-language upweighting to rebalance datasets. FineWeb2's per-language organization and language confidence scores make those strategies easier to implement.
The "rehydration" idea also introduces a choice: you can train on the deduplicated data, or you can train on a rehydrated distribution that repeats certain cluster sizes for additional performance uplift.
7.4.2 Continued Pretraining and Language Adaptation
FineWeb2 is also useful for teams who already have a model and want to:
- improve non-English performance
- add coverage for specific languages
- reduce reliance on proprietary multilingual corpora
In this setting, you might not want "everything." You may want:
- a subset of languages
- higher LID thresholds for quality
- stricter filtering for your application domain
FineWeb2's pipeline and per-language configs make this feasible without scalability issues.
7.4.3 Data Analysis and Filter Research
Another realistic use case is not training a model at all.
FineWeb2 can be used to:
- study how filtering changes distributions
- test new multilingual quality heuristics
- evaluate LID behaviors on real-world data
The release of the pre-filtered corpus supports this kind of computer science research.
7.4.4 Training-Time Controls That Matter in Practice
FineWeb2's metadata enables controls that are hard to implement with prior datasets:
- confidence-based curricula: start with high-confidence documents and relax thresholds later
- script-aware sampling: treat language-script pairs as separate distributions
- dedup-aware weighting: use minhash_cluster_size to avoid overtraining on templated duplicate clusters
- domain filtering: URLs and snapshot metadata help build domain-based exclusions or inclusions
These are "data engineering" levers. They often matter more than small architecture tweaks when you are trying to improve multilingual behavior.
8) Comparisons to FineWeb (2024)
FineWeb and FineWeb2 share DNA:
- both are Common Crawl derived
- both rely on web-text extraction and large-scale deduplication
- both use heuristic quality filters validated through training ablations
The differences are mostly about what breaks when you go multilingual.
8.1 FineWeb's Core Challenge: Quality at English Scale
FineWeb's main problem was: given English-heavy web data at massive scale, which filters and dedup strategies actually improve downstream model performance?
It produced not only FineWeb, but also subsets like FineWeb-Edu that represent more targeted quality distributions.
8.2 FineWeb2's Core Challenge: Comparability Across Languages
FineWeb2's main problem is: how do we apply one pipeline to scale processing across languages where:
- LID coverage differs dramatically
- word segmentation is not universal
- reference corpora can be contaminated
- evaluation tasks may not be reliable
That forces FineWeb2 to invest in:
- a large-coverage, script-aware LID system
- per-language confidence threshold rules
- distribution-based threshold adaptation for filters
- precision filtering targeted to the long tail
The final dataset is bigger and broader, but the more interesting change is that the pipeline becomes explicitly adaptive.
8.3 Concrete Filter and Pipeline Differences That Show Up in Practice
FineWeb2 reuses much of FineWeb's filter logic but makes several practical changes.
A few are worth calling out because they show how extraction and multilinguality force filter redesign:
- some filters that depend on paragraph structure are disabled because the extraction tool does not preserve paragraphs reliably
- some global thresholds are changed (for example, the duplicate-line character ratio threshold)
- some filter groups (like certain C4-style filters) are excluded because they appear to degrade model performance in the multilingual setting
These are the kinds of details that often get treated as "implementation noise," but they are the mechanism that determines what text your model sees.
9) Where Human Expertise Still Matters (Even in an Automated Pipeline)
FineWeb2 is a good illustration of how "automation" actually works in dataset curation.
You can automate the bulk processing. You cannot automate the definition of "good data" without human judgment.
In FineWeb2, humans show up in high-leverage ways:
- choosing canary languages that stress the pipeline
- inspecting failure cases in LID and stopword derivation
- designing and selecting evaluation tasks that provide early signal
- running native-speaker audits for low-resource language contamination
This is a pattern we keep seeing in modern dataset work:
- the pipeline is automatic
- the validation is selective and expert-driven
Why Expert Validation Matters for AI Data Quality
The FineWeb2 approach reflects a fundamental principle that extends beyond pre-training data: careful curation by domain experts consistently produces more performant models. While automated processing pipelines can handle the volume demands of large language models, the quality decisions that matter most—what constitutes "good" data for a given language or domain—require human expertise.
This principle applies whether you're curating multilingual web corpora or building enterprise AI systems. In healthcare, radiologists validate diagnostic AI labels. In manufacturing, quality engineers review inspection datasets. In financial services, underwriters assess fraud detection training data. In each case, the pattern is the same: automation handles scale, experts ensure quality.
For organizations building production AI systems, platforms that enable collaboration between technical teams and subject matter experts can significantly accelerate development cycles. When domain experts can directly validate and refine AI data—rather than waiting for data science teams to interpret requirements—models reach production faster and perform better in the real world.
If you are building on FineWeb2 inside an organization, this is the part to copy.
Not "train 200 ablation models," but:
- pick a small set of representative languages for your product
- define a small evaluation suite that reflects real use
- have language experts review samples where your pipeline is likely to fail
- treat filters as hypotheses that need validation, not as inherited constants
10) Limitations and Practical Gaps
FineWeb2 is unusually transparent compared to many web corpora, but there are still constraints worth naming.
10.1 Web Data Is Still Web Data
Even after filtering:
- bias and toxicity remain
- misinformation and low-trust content remains
- domain skew remains (some languages are dominated by certain site types)
FineWeb2 improves average quality for training, but it does not turn the internet into a curated encyclopedia.
10.2 Long-Tail Languages Remain Long-Tail
Supporting 1,000+ languages does not mean uniform coverage.
Many language-script pairs have very little data. Training a model to be usable in those languages may require:
- targeted collection outside Common Crawl
- community data partnerships
- synthetic data generation with careful validation
FineWeb2 helps, but it does not solve data scarcity for low-resource languages.
10.3 Proxy Tokenizers Are a Compromise
Assigning word tokenizers by language family is a scalable solution, but it can misrepresent morphological boundaries.
That can affect:
- stopword lists
- word-length filters
- repetition metrics
For high-stakes language quality, this is where experts should get involved.
10.4 Evaluation Is Still Fragile
FineWeb2 invests in task selection, but multilingual evaluation remains a moving target.
Tasks can be misaligned with real use, and some test languages have limited high-quality benchmarks.
This is why FineWeb2's emphasis on "early-signal tasks" is important: it is trying to reduce noise, not claim perfect measurement.
11) Closing Synthesis: FineWeb2 Is a Dataset, but the Pipeline Is the Lesson
FineWeb2 is better understood as a multilingual extension of the FineWeb philosophy, with the extra machinery needed to keep that philosophy working when language, script, and evaluation become unstable variables.
It is a case study in what happens when you try to scale pre-training data processing to every language:
- the weakest link becomes language identification and precision
- filter thresholds stop being constants and become per-language functions
- reference datasets become part of the pipeline and can themselves be contaminated
- deduplication stops being a one-way removal step and becomes a sampling signal
- humans remain necessary, but concentrated on pipeline validation rather than bulk labeling
If we want to build more performant multilingual LLMs that behave predictably, we shouldn't start by asking which architecture is best.
We should start with a simpler debugging question:
What kinds of text does our pipeline reliably include for each language, and what kinds of mistakes does it make?
FineWeb2 represents a significant step forward because it gives the community both an artifact and a working answer to that question—plus the code to modify it. The dataset allows for the development of more accurate and fluent AI models across a wide array of languages, including those typically underserved by English-centric datasets.
The substantial recent progress in multilingual language modeling demonstrated by FineWeb2 reinforces what practitioners have long understood: better training data leads to better models. As organizations increasingly deploy artificial intelligence systems across diverse linguistic contexts, resources like FineWeb2—and the careful curation processes they exemplify—will become ever more valuable.
Resources
- FineWeb2 paper: FineWeb2: One Pipeline to Scale Them All — Adapting Pre-Training Data Processing to Every Language (arXiv:2506.20920)
- FineWeb2 dataset (Hugging Face): HuggingFaceFW/fineweb-2
- FineWeb2 pipeline repository (GitHub): huggingface/fineweb-2
- FineWeb paper (2024): The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale (arXiv:2406.17557)
- FineWeb dataset: HuggingFaceFW/fineweb
- Kili (2024) reference on FineWeb: What can we learn from Hugging Face's FineWeb dataset
Frequently Asked Questions
What is FineWeb2?
FineWeb2 is a multilingual pre-training dataset built from 96 Common Crawl snapshots spanning 2013 to 2024. It comprises approximately 20 terabytes of text across about 5 billion documents, covering more than 1,000 languages. It is released under the Open Data Commons Attribution License (ODC-By) v1.0 for both research and commercial use.
How does FineWeb2 differ from the original FineWeb?
FineWeb (2024) focused on making high-quality English web data reproducible at scale. FineWeb2 extends that reproducibility to multilingual data by making the pipeline language-adaptive — treating language–script pairs as first-class citizens, using a wider-coverage language identifier (GlotLID), and applying per-language confidence thresholds instead of a single global cutoff.
What is GlotLID and why does FineWeb2 use it?
GlotLID is a language identification classifier with very large label coverage that distinguishes different scripts for the same language. FineWeb2 uses it because standard classifiers with smaller label sets produce frequent misclassification errors for low-resource languages, confuse closely related languages, and lack explicit noise labels for corrupted content.
How does FineWeb2 handle deduplication?
FineWeb2 performs global per-language deduplication using MinHash-based clustering, removing highly similar documents while keeping one representative. Importantly, the pipeline preserves the duplicate cluster size in metadata, turning deduplication from a destructive step into a useful quality signal — since cluster size acts as a proxy for how templated or mass-reposted a document is.
What does “rehydration” mean in FineWeb2?
Rehydration is a technique where duplicate cluster sizes are used to upsample unique or low-duplication content and downsample highly duplicated content. Rather than simply discarding duplicates, rehydration adjusts the effective training distribution to favor diverse, original text while reducing the influence of boilerplate and templated pages.
How are quality filters adapted across languages in FineWeb2?
Instead of applying one global threshold for all languages, FineWeb2 uses a distribution-based formula to set per-language thresholds for each heuristic filter. For a set of canary languages, models are trained at multiple threshold levels and evaluated, with the results used to define a principled per-language filtering rule. This makes quality filtering a tunable knob rather than a fixed preprocessing step.
Can I use FineWeb2 to train commercial LLMs?
Yes. FineWeb2 is released under the Open Data Commons Attribution License (ODC-By) v1.0, which permits commercial use with attribution. The dataset also publishes what its filters removed as per-language _removed subsets, making filtering decisions inspectable and easier to iterate on for teams building their own training pipelines.
Building Multilingual Training Data That Goes Beyond Web Scraping?
FineWeb2 shows what’s possible with careful filtering and deduplication of public web data. But production AI systems in specialized domains need training data that web corpora alone can’t provide — expert-labeled datasets with verified accuracy across languages and domains. Kili Technology supports 40+ languages with verified domain specialists and structured quality workflows, giving enterprise teams the labeled data layer that sits on top of pre-training.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

