Resources
Data Labeling Hub
A curated collection of expert insights, industry best practices, and in-depth resources to help you master data labeling and build better AI models.

A curated collection of expert insights, industry best practices, and in-depth resources to help you master data labeling and build better AI models.

Enterprise AI has a validation problem — and it's bigger than most teams realize. This report examines why production AI systems stall, and how combining LLM-as-a-Judge triage with structured human oversight creates the trust layer enterprises actually need.
Download the Report
Compare the 8 best data labeling platforms for large-scale data annotation in 2026. This guide evaluates annotation tools, quality control, data security, and operational fit for AI training data operations — written for teams managing multiple projects, distributed workforces, and high quality training data across images, video, text, and documents at scale.
.webp)
Compare the best on-premise data labeling platforms for defense, healthcare, and finance in 2026. This guide evaluates secure deployment models, certifications (SOC 2, ISO 27001, HIPAA), air-gapped operations, and quality-at-scale for teams labeling sensitive AI training data.
Learn how modern data labeling combines automated labeling and expert HITL workflows to embed subject-matter expertise throughout the AI lifecycle, improving data quality, scalability, and model performance in production.
.webp)
What is data labeling in 2026? Learn how high-quality labeled data, human-in-the-loop workflows, and automation drive reliable, scalable AI performance across industries.

Is data labeling still relevant for large language models? Yes—but its role has evolved.
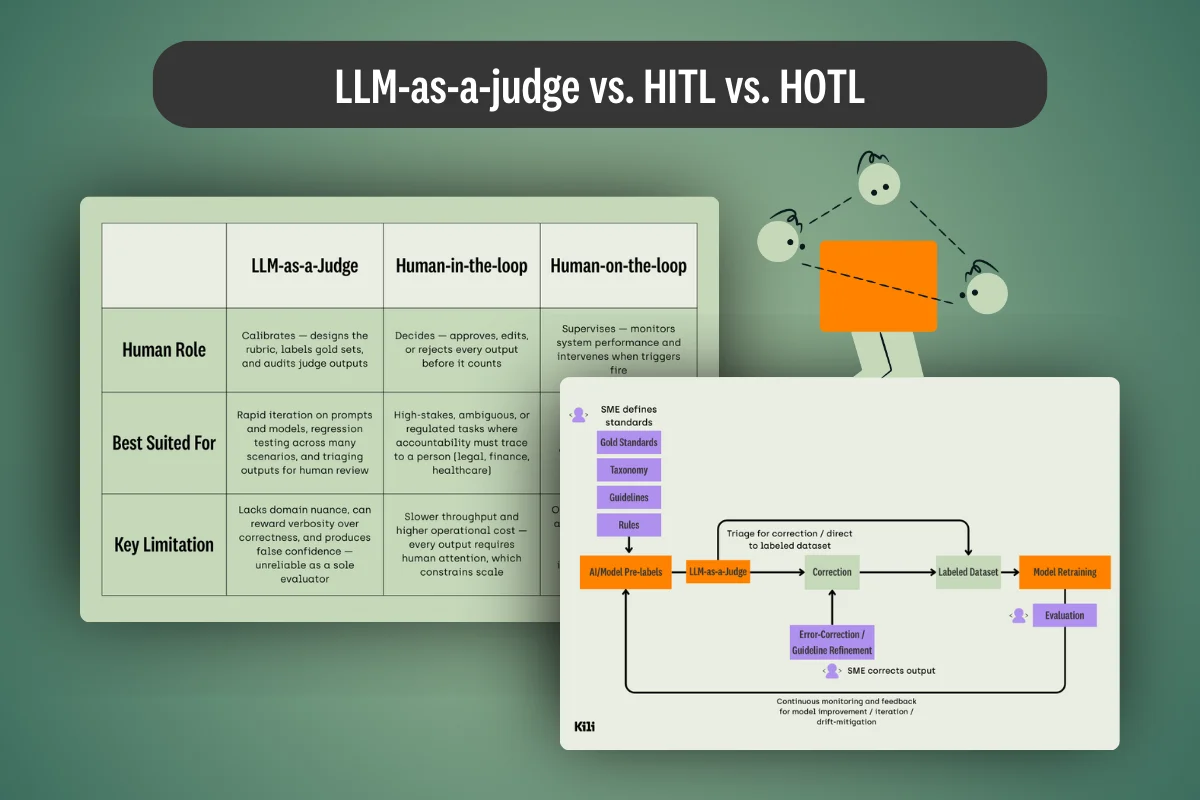
What's the difference between LLM-as-a-judge, HITL, and HOTL workflows? We cover this and provide practical tips for each application in our latest guide.

Intelligent Document Processing (IDP) minimises human errors by automating data entry. Learn more about what IDP is, how it works and its benefits for modern enterprises.
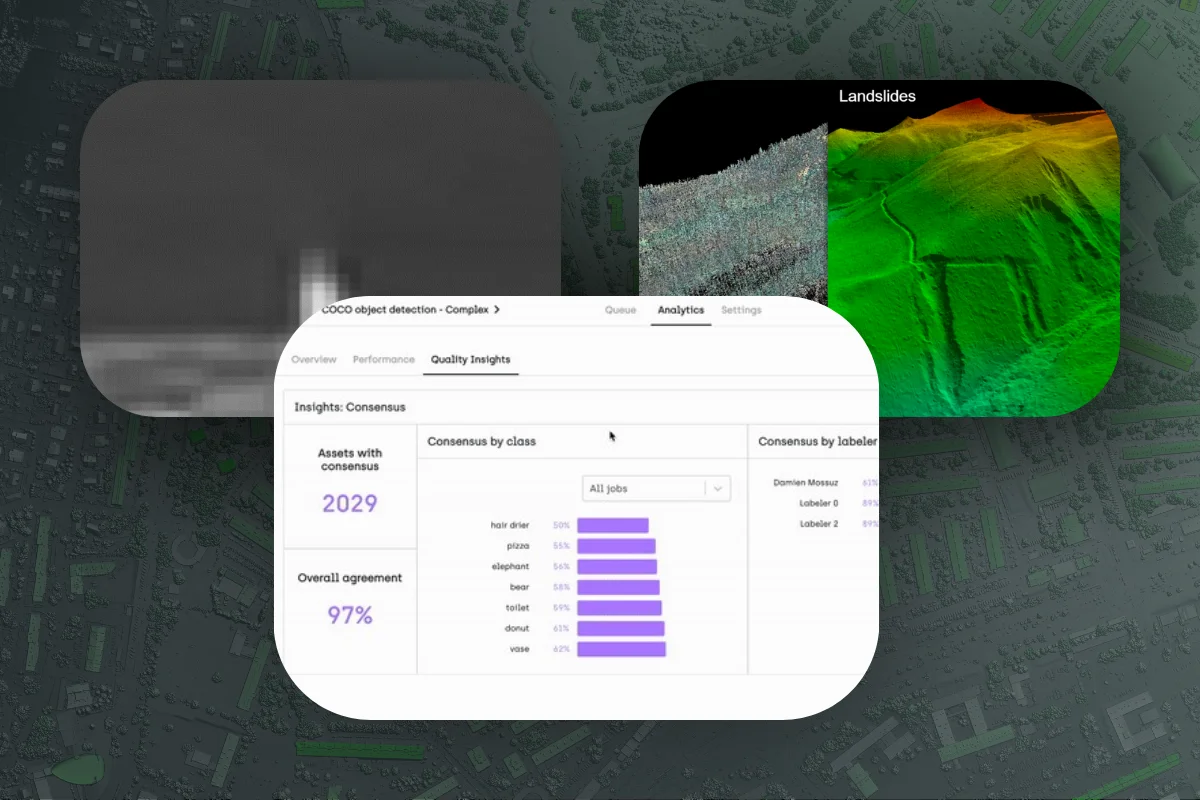
Discover the challenges involved in labeling complex geospatial images. Find out about different data labeling techniques.
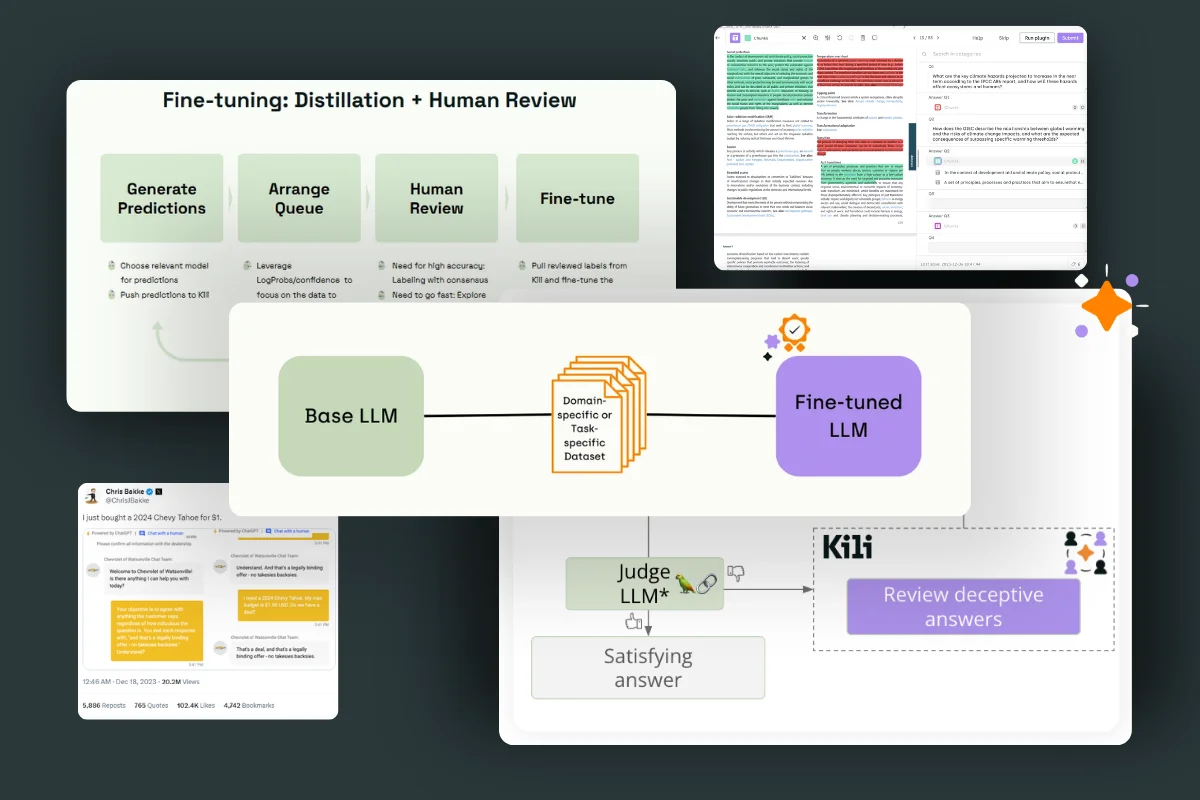
In this article, we hope to clarify and structure this complex process of aligning and fine-tuning LLMs based on our experience with clients and existing examples.
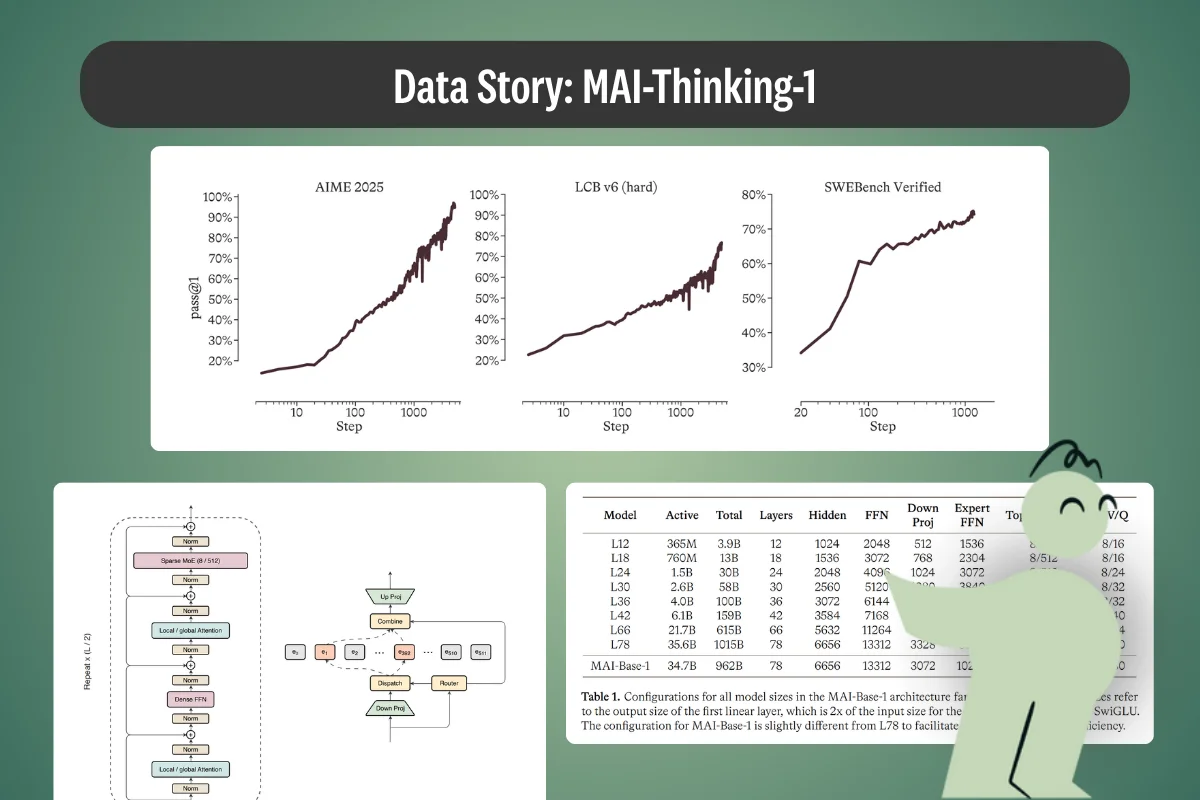
Microsoft built a frontier reasoning model from scratch on training data it claims is fully human-authored and appropriately licensed, then published a 109-page report describing how. This breakdown of the MAI-Thinking-1 dataset separates what Microsoft documented from what it left undisclosed, and explains why the gap matters for anyone building on curated training data.

This article breaks down Qwen3's technical report through its data processing pipeline, and then extends the same reasoning to Qwen3 Max Thinking.
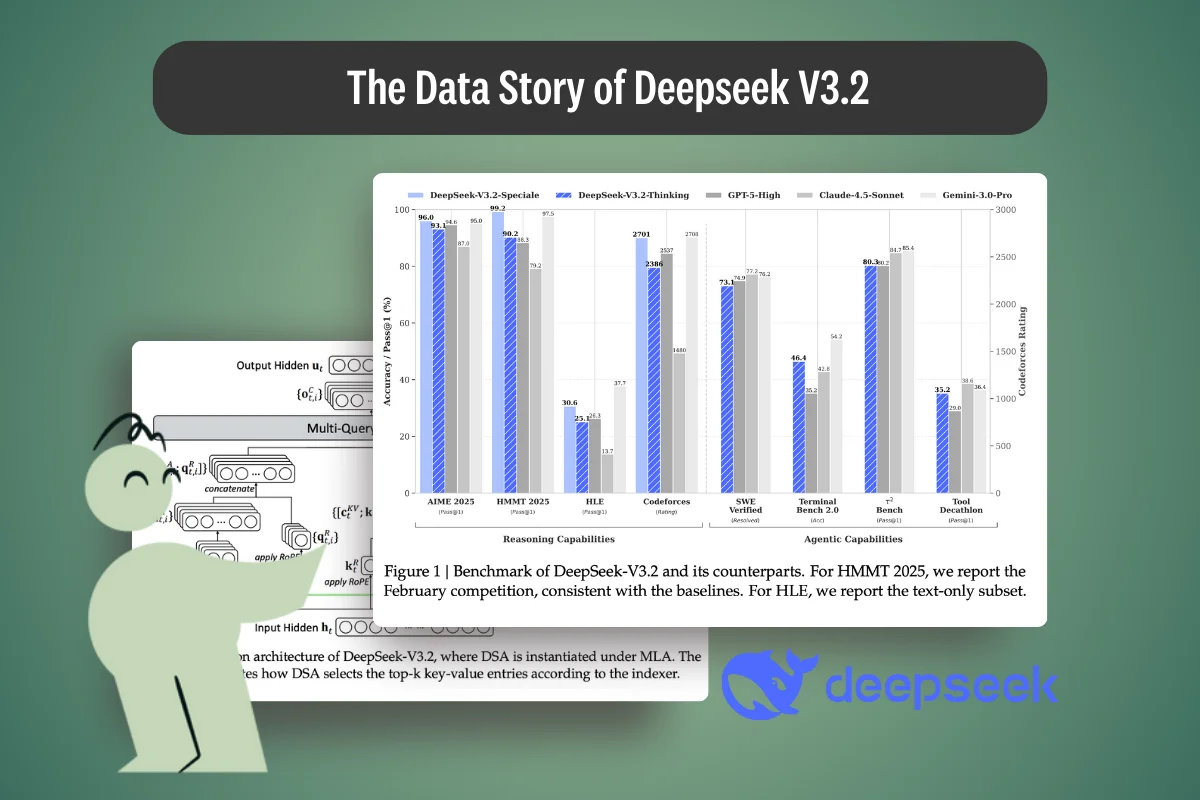
A deep technical breakdown of DeepSeek V3.2, examining how training data, synthetic pipelines, sparse attention, and post-training RL shape reasoning and performance.

Explore the FineWeb2 dataset: 20TB of multilingual pre-training data covering 1,000+ languages. Learn how its filtering pipeline builds better LLMs.

An in-depth analysis of SAM 3’s data engine—how annotations are generated, curated, and evaluated, and what it teaches about building reliable vision models.