
.png)

_logo%201.svg)


AI Summary
- DeepSeek V3.2's continued pre-training distribution is aligned with the 128K long-context data — sparse attention only delivers efficiency gains when the model repeatedly sees meaningful long-range dependencies.
- The two-stage continued pre-training (2.1B-token dense warm-up, then 943.7B-token sparse training) teaches the indexer and main model on long sequences where curation quality directly shapes attention behavior.
- Specialist distillation builds domain experts in math, code, and agentic tasks and uses them as data generators, making prompt design and rejection sampling more important than raw corpus breadth.
- The agentic synthesis pipeline produces 1,800+ environments and 85,000+ prompts, with code agent data accepted only when patches pass tests without regressions — verification defines the dataset.
- Mixed RL combines rule-based rewards on verifiable tasks with rubric-driven generative reward models on general tasks, blurring the line between training data and evaluation data.
- The technical report's Data Annotation roster signals what's understated in the main text: human experts remain in the loop for rubric auditing, edge-case adjudication, and catching reward hacking.
DeepSeek V3.2 is often described in terms of architecture—especially its DeepSeek Sparse Attention (DSA) design for 128K-context inference efficiency and high computational efficiency in long context scenarios. But the paper's more interesting story is about data. Not just "how many tokens," but what kinds of tokens, how they're structured into long sequences, how post-training data is systematically generated and filtered, and how evaluation data is selected to make sure improvements are real rather than an artifact of leakage or style bias.
This article breaks DeepSeek V3.2 down end-to-end—from continued pre-training to specialist distillation to mixed RL to evaluation—focusing on how training data is built, curated, and used as a control surface for model behavior, reasoning capabilities, and model performance. We'll use the DeepSeek V3 technical report as a comparison point, because V3 is where the DeepSeek team is much more explicit about pre-training corpus design choices, instruction-tuning structure, and reward construction.
1) A Quick Map: What V3.2 Is Actually Building On
DeepSeek V3.2 is not trained "from scratch" in the way many base models are. The V3.2 report states that it starts from a DeepSeek-V3.1-Terminus base checkpoint whose context length has already been extended to 128K, then does continued pre-training and post-training to reach V3.2.
Two consequences follow immediately:
- The continued pre-training data distribution is not a generic web-scale mix. It is "totally aligned with the 128K long context extension data used for DeepSeek-V3.1-Terminus."
- Most of the capability differentiation (especially agentic tasks and tool use scenarios) is pushed into post-training, where DeepSeek invests heavily in RL compute and synthetic task generation. The report explicitly highlights a large-scale agentic task synthesis pipeline (1,800+ environments and 85,000+ prompts) as a driver of generalization in tool-use contexts.
So the data story of DeepSeek V3.2 is less about "14.8T tokens of diverse pretraining data" (that's DeepSeek V3) and more about:
- Long-context-aligned continued pre-training, and
- Post-training data factories (specialist distillation + agent environment construction + mixed RL with rubrics).
2) Pre-Training as Data Engineering: What V3 Tells Us (and What V3.2 Inherits)
The DeepSeek V3 report is direct about several corpus and tokenization decisions. It says that, compared with DeepSeek-V2, they optimized the pre-training corpus by:
- Increasing the ratio of mathematical and programming samples,
- Expanding multilingual coverage beyond English and Chinese, and
- Refining the processing pipeline to minimize redundancy while maintaining diversity.
It also describes multiple "under-the-hood" data mechanics that are easy to overlook but matter a lot in practice:
Document Packing
DeepSeek V3 uses a document packing method "for data integrity." Packing improves GPU utilization (fewer padding tokens), but it's also a data semantics decision: you're deciding how different documents share a sequence window. V3 notes this is inspired by prior work and emphasizes packing for integrity, even stating they do not incorporate cross-sample attention masking during pre-training (though they later use masking during SFT packing).
Fill-in-the-Middle (FIM)
V3 incorporates Fill-in-the-Middle using a Prefix–Suffix–Middle structure (PSM) at the document level, applied at a rate of 0.1. This is a data transformation that directly targets code editing and infilling behaviors. If you're wondering why a model exhibits better performance at "patching" code or completing missing sections, FIM is often a major reason.
Tokenizer Training Data and Token Boundary Bias
DeepSeek V3 uses a byte-level BPE tokenizer with 128K vocab, modifies the tokenizer's pretokenizer/training data to improve multilingual compression, and introduces combined punctuation+linebreak tokens. But they also acknowledge a risk: those combined tokens can create a token boundary bias in multi-line prompts without terminal line breaks—particularly relevant for few-shot evaluation prompts. Their mitigation is explicitly data-based: randomly split a proportion of those combined tokens during training, exposing the model to more boundary cases.
Why this matters for V3.2: V3.2 is a continuation of this lineage. Even when the V3.2 paper doesn't restate these steps, the base checkpoint and its training culture carry these assumptions: the model has already been shaped by a corpus optimized for math/code ratio, multilingual compression, packing, and FIM.
3) Long Context Isn't Just an Architecture Feature—It's a Data Distribution
DeepSeek V3 extends context length after pre-training using YaRN and two additional training phases (4K→32K, then 32K→128K). That is already a "data distribution shift": the model is suddenly trained on much longer sequences with different batching constraints (notably smaller batch size at 128K).
DeepSeek V3.2 goes further by saying its continued pre-training data is totally aligned with the 128K long-context extension data used for V3.1-Terminus, explicitly targeting long context scenarios without degrading reasoning proficiency.
This is a crucial (and under-discussed) point:
- A large language model can have a 128K context window and still be bad at using it if its long-sequence training data is mostly "stitched" fragments, repetitive boilerplate, low-information pages, or artificial padding.
- Conversely, long-context performance often comes from high-signal long documents (books, technical manuals, multi-file codebases, long conversations, structured records), combined with training objectives that force retrieval and synthesis across distance.
DeepSeek doesn't fully disclose the composition of the "128K long context extension data," so we should not invent specifics. But the commitment to "aligned distribution" signals that long-context behavior in V3.2 is as much about what kinds of long sequences it keeps seeing as it is about sparse attention.
4) Continued Pre-Training in V3.2: The Data Is Shaped Around Teaching Sparse Attention
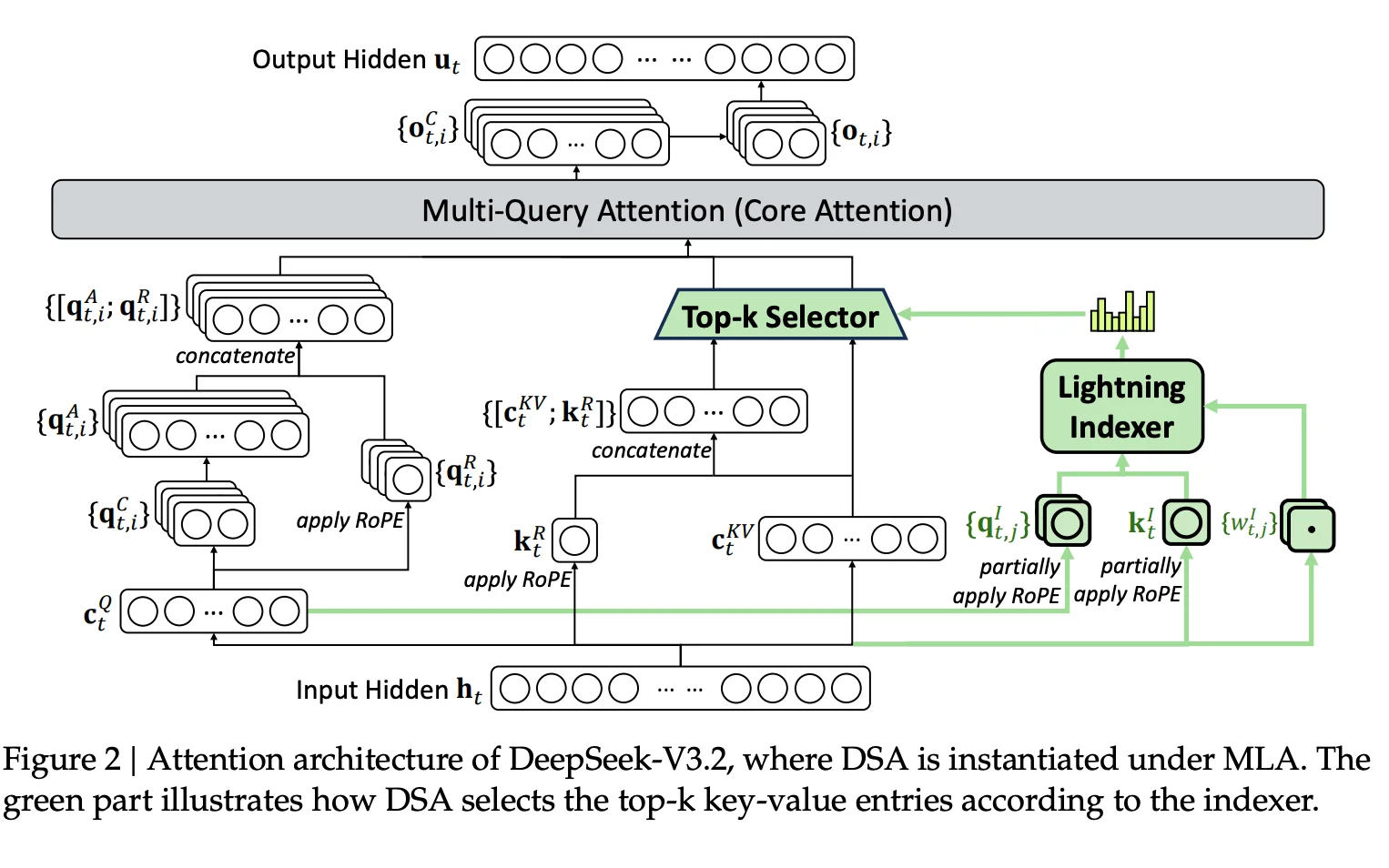
V3.2 introduces DeepSeek Sparse Attention via continued training, an efficient attention mechanism designed to substantially reduce computational complexity while preserving model performance. The continued pre-training has two stages, and both stages are built on long sequences.
Stage A: Dense Warm-up (2.1B Tokens)
DeepSeek uses a short warm-up stage to initialize the lightning indexer. They keep dense attention and freeze all model parameters except the indexer. They create a target distribution from the model's existing attention scores (summed across heads and L1-normalized) and train the indexer using a KL-divergence loss. This warm-up runs for 1000 steps, each with 16 sequences of 128K tokens, totaling 2.1B tokens.
Data implication: This stage is not about new knowledge. It's about forcing a new component (indexer) to imitate attention patterns on realistic 128K sequences. If your long-sequence data is noisy, duplicated, or low-structure, you're teaching the indexer to prioritize the wrong tokens.
Stage B: Sparse Training (943.7B Tokens)
After warm-up, they introduce DSA token selection and train both the main model and indexer for 15000 steps, each step consisting of 480 sequences of 128K tokens, totaling 943.7B tokens. They select 2048 key-value tokens per query token and use a learning rate of 7.3×10⁻⁶.
They also note a structural choice: they detach the indexer input from the computational graph so the indexer is optimized only by the indexer loss, while the main model is optimized only by language modeling loss.
Data implication: The sparse training stage is where the model adapts to the new attention sparsity pattern. That adaptation depends on the model repeatedly encountering long-range dependencies worth attending to. If the long context data is dominated by shallow patterns (templates, repeated headers, "SEO sludge"), sparsity training can teach the model that nothing far away matters—undermining the very efficiency gains that DeepSeek Sparse Attention is designed to deliver.
5) Post-Training in V3.2: "Data Factories" Rather Than Static Datasets
DeepSeek V3.2 keeps the same architecture as prior versions but introduces significant updates to post-training: specialist distillation combined with a scalable reinforcement learning framework.
This is where V3.2 becomes a data engineering paper, centered on a scalable reinforcement learning approach that systematically generates training data rather than relying on static datasets.
5.1 Specialist Distillation: Building Experts, Then Distilling Their Outputs
DeepSeek describes a framework where each domain has a specialist model, all fine-tuned from the same V3.2 base checkpoint. Domains include writing + general QA plus six specialized areas: mathematics, programming, general logical reasoning, general agentic tasks, agentic coding, and agentic search. All support both thinking and non-thinking modes.
They also make an important procedural point:
- Specialists are trained with large-scale RL compute—a key aspect of scaling post-training compute.
- Different models are used to generate training data for long chain-of-thought ("thinking mode") vs direct response ("non-thinking mode").
- Specialists are then used to produce domain-specific data for the final model checkpoint.
- Models trained on distilled data are "only marginally below" specialists, and subsequent RL training closes the gap.
What's the data story here? Specialist distillation is essentially a controlled synthetic data pipeline:
- Train experts to high performance in narrow domains using a robust RL protocol.
- Use them as data generators.
- Distill their behaviors into a general model.
The quality of the final model's training data depends less on raw corpus breadth and more on:
- Specialist competence,
- The prompts and rubrics used to elicit desired behaviors, and
- The filtering/rejection rules used to discard low-quality generations.
The paper is light on filtering specifics for distillation outputs, which is a gap. But we can compare to V3, where DeepSeek is explicit about curating reasoning data.
6) Comparison: DeepSeek V3's Instruction Data Curation and Why It Matters for V3.2
DeepSeek V3 states that its supervised fine-tuning (SFT) uses 1.5M instruction-tuning instances spanning multiple domains, with different creation methods per domain.
Reasoning Data: Generated from an Internal DeepSeek-R1 Model
V3 generates reasoning datasets using an internal DeepSeek-R1 hybrid reasoning model, while noting the raw R1 generations have issues: overthinking, poor formatting, and excessive length. Their goal is to balance R1's accuracy with clearer, more concise reasoning—a challenge that exhibits reasoning proficiency priorities over raw output volume.
They then describe a multi-step pipeline:
- Build an expert model for a domain using SFT + RL.
- For each instance, generate two types of SFT samples:
- <problem, original response>
- <system prompt, problem, R1 response> where the system prompt guides reflection/verification.
- Use RL with high-temperature sampling so the model learns to integrate reasoning patterns from both sources even without explicit system prompts.
- After RL, use rejection sampling to curate high-quality SFT data for the final model.
That's a clear example of data curation affecting capability: you're not just collecting "math problems," you're shaping the style and structure of reasoning traces to enable strong reasoning and superior reasoning on benchmarks.
Non-Reasoning Data: Humans Verifying Model-Generated Content
For non-reasoning tasks (creative writing, role-play, simple QA), DeepSeek V3 uses DeepSeek-V2.5 to generate responses and then enlists human annotators to verify accuracy and correctness.
This is one of the few explicit human-in-the-loop (HITL) points in the V3 report. It matters because "general helpfulness" failures are often not solvable by scale alone; they require human judgment about what is misleading, unsafe, off-tone, or subtly incorrect.
The role of human expertise here cannot be overstated. While automated pipelines can generate vast quantities of synthetic data, the verification step—where domain experts assess whether outputs actually meet real-world standards—remains essential for achieving model performance that translates to production environments.
Packing and Isolation During SFT
V3 also notes that during SFT, each sequence is packed from multiple samples but uses a masking strategy so examples remain isolated and "mutually invisible." That's another data-structure decision: it prevents accidental cross-example leakage within a packed sequence.
Why bring this up for V3.2? Because V3.2 leans even harder on synthetic and automated post-training data. The V3 report is a reminder that, when you automate data generation, you still need:
- Explicit constraints (system prompts, tags, rubrics),
- Hard filters (rejection sampling, heuristics), and
- Human verification where automated checks are weak.
7) Agentic Training Data in V3.2: Environments, Prompts, Verification, and Rubrics
DeepSeek V3.2's post-training emphasizes agent tasks and deep reasoning tasks. The report describes a "cold-start" mechanism where different task prompts are paired with different system prompts using a jinja format chat template, enabling tool calling functionality in complex interactive environments, including explicit reasoning tags like <think></think>, toolcall guidance, and prompts instructing multiple tool calls within the reasoning process.
The idea is to unify "reasoning" and "tool-use" in single trajectories—to integrate reasoning with action—even if early trajectories are not robust, so RL has something to improve and can improve efficiency over iterations.
The Agent Task Mix (Scale and Sources)
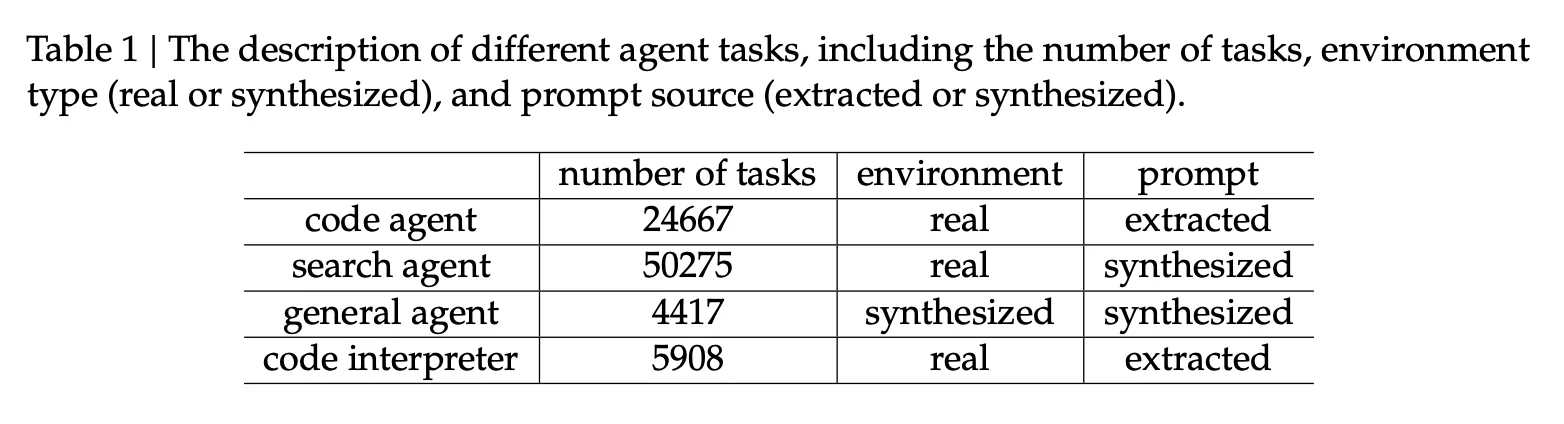
The paper lists agent tasks and their sourcing via a novel synthesis pipeline:
- Code agent: 24,667 tasks, real environment, prompts extracted
- Search agent: 50,275 tasks (for search agent scenarios), real environment, prompts synthesized
- General agent: 4,417 tasks, synthesized environment, prompts synthesized
- Code interpreter: 5,908 tasks, real environment, prompts extracted
In the broader framing, DeepSeek also reports using a scale agentic task synthesis approach to generate over 1,800 environments and 85,000 complex prompts to drive RL and improve agent performance and generalization in agent contexts.
This is data curation at the system level: you're deciding what kinds of tasks exist, what tools are available, what "success" looks like, and how the model gets rewarded.
8) How V3.2 Builds and Filters Agent Data
8.1 Search Agent: Multi-Agent Generation + Verification + Rubrics
The agentic task synthesis pipeline for search agent tasks is one of the clearest examples of "data built with filters":
- Sample informative long-tail entities from large-scale web corpora.
- A question-construction agent explores each entity using search tools and consolidates findings into QA pairs.
- Multiple answer-generation agents produce diverse candidate responses (heterogeneous checkpoints/sampling parameters).
- A verification agent with search validates all answers through multiple passes, keeping only samples where:
- The ground truth is correct, and
- All candidates are verifiably incorrect.
Then they augment with filtered instances from existing helpful RL datasets (where search measurably helps), develop detailed evaluation rubrics, and use a generative reward model to score responses against the rubrics—optimizing for both factual reliability and practical helpfulness.
What's notable here: They're not trusting raw web data or raw model generations. They're building a pipeline where verification is part of the dataset definition—a principle that aligns with data-centric AI approaches where the focus shifts from model architecture to data quality.
8.2 Code Agent: Mining GitHub + Heuristic and LLM-Based Filtering + Executable Environment Constraints
For coding, they mine millions of issue–PR pairs from GitHub and filter with heuristic rules and LLM judgments, requiring:
- A reasonable issue description,
- A correlated gold patch, and
- A test patch for validation.
Then an automated environment-setup agent builds executable environments (package install, dependency resolution, test execution), with tests output in JUnit format. Environments are accepted only if applying the gold patch produces:
- Non-zero false-to-positive (F2P) tests (issue fixed), and
- Zero pass-to-fail (P2F) tests (no regressions).
They report building tens of thousands of reproducible issue resolution environments across many languages (Python, Java, JS/TS, C/C++, Go, PHP).
This is an interesting filter: Instead of "looks correct," it's "runs and fixes tests without breaking others." That kind of curation tends to produce big real-world improvements because it closes the gap between "code that compiles" and "code that actually patches a system"—improvements that matter for complex tasks in production.
8.3 Code Interpreter Agent: Curated Problems That Require Execution
They use Jupyter Notebook as a code interpreter and curate problems across math, logic, and data science that require code execution to solve. Even though additional details are light, the direction is clear: data is selected to force tool use, not just allow it.
8.4 General Agent: Synthetic Environments Designed to Be "Hard to Solve, Easy to Verify"
To scale agent environments through scalable agentic post-training approaches, they synthesize 1,827 task-oriented interactive environments, emphasizing tasks that are hard to solve but easy to verify, and describe a workflow involving environment/toolset construction, task synthesis, and solution generation.
This design principle matters because verification cost is one of the biggest constraints in RL data. If success is cheap to check, you can scale training without drowning in noisy rewards.
9) Mixed RL Training in V3.2: The "Evaluation Data" Becomes the Training Data
DeepSeek V3.2 merges reasoning, agentic tasks, and human alignment into a single scalable reinforcement learning stage (using GRPO), explicitly to balance performance and avoid catastrophic forgetting common in multi-stage pipelines.
They use:
- Rule-based outcome reward, length penalty, and language consistency reward for reasoning and agent tasks, and
- A generative reward model for general tasks, where each prompt has its own rubrics—improving compliance with expected outputs while enabling the high compute variant of their training to achieve gold medal performance on reasoning benchmarks.
This is where the boundary between "training data" and "evaluation data" blurs:
- In RL, your prompts and environments are your inputs, and your reward signal is your label.
- If your rubrics are vague or misaligned, you train the model to satisfy the rubric, not the user.
- If your verification is strong (tests, deterministic checks, multi-pass search validation), you can scale reward with confidence.
DeepSeek V3 provides a useful comparison: it describes using rule-based reward where validation is possible (math format checks, LeetCode compilers/tests for ICPC World Finals-style problems) and model-based reward elsewhere, and it explicitly says they construct preference data that includes not only the final answer but also chain-of-thought leading to the reward to mitigate reward hacking.
Even though V3.2 phrases things differently (rubrics per prompt; generative reward model), the core data lesson is the same:
RL success is mostly about the quality of feedback data—how reliably "good" and "bad" are separated.
10) Evaluation Data: What They Measure, and How They Try to Avoid Fooling Themselves
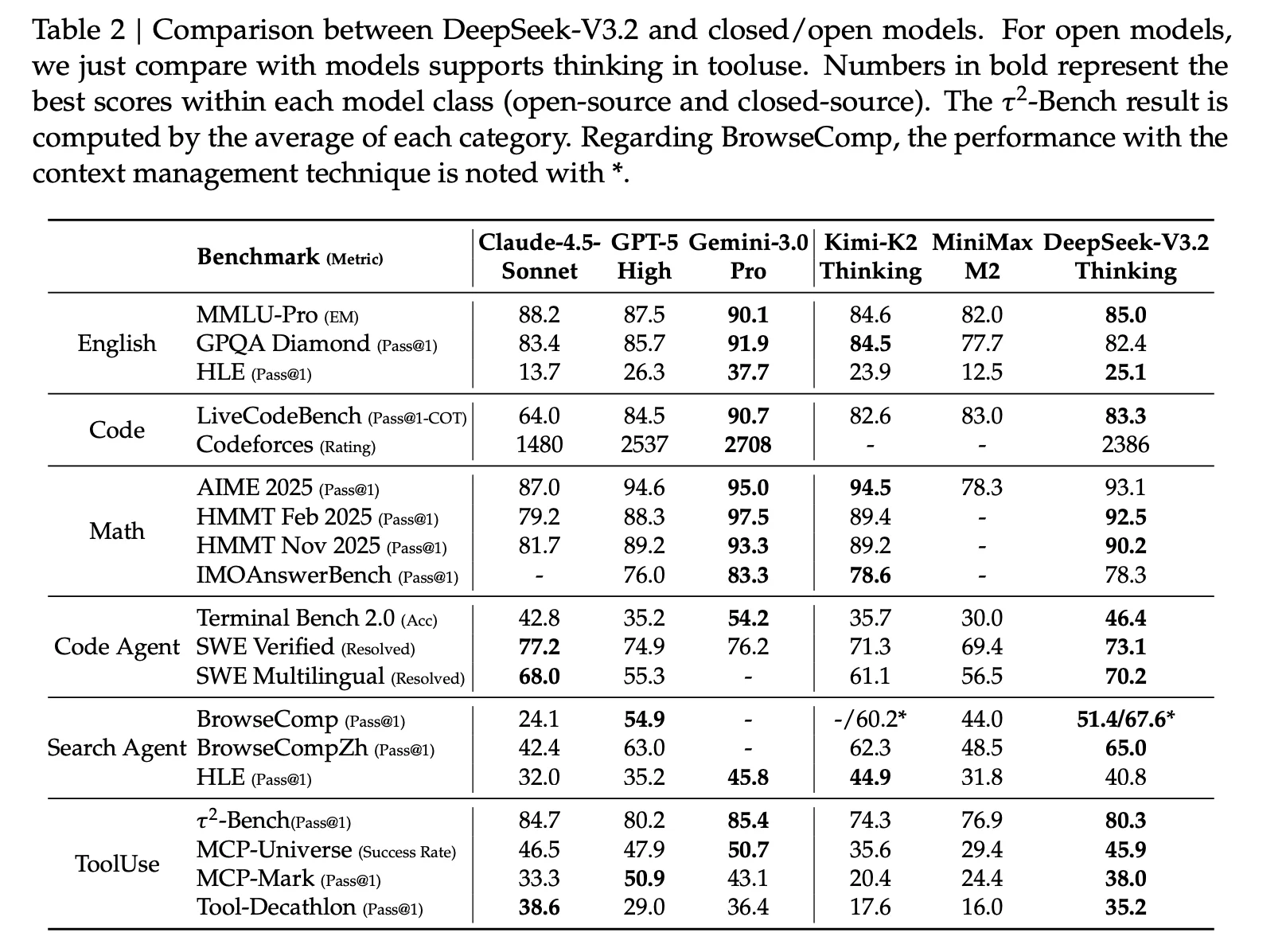
V3: Broad Benchmark Suite + Prompt Standardization
DeepSeek V3 describes a wide evaluation suite and notes that for standard benchmarks like MMLU, DROP, GPQA, and SimpleQA it uses evaluation prompts from OpenAI's simple-evals framework; other datasets follow original protocols. It also calls out time-sliced evaluation for LiveCodeBench (questions from Aug 2024 to Nov 2024).
These details matter because evaluation data is easily contaminated—especially coding benchmarks that resemble public repositories or training data.
V3.2: Parity Evaluation + Indirect Human Preference + Long-Context External Sets
DeepSeek V3.2 (available via the official API and for local deployment) reports:
- Standard benchmark evaluation (September 2025) showing similar performance to V3.1-Terminus using a revised format for the chat template compared to prior versions—near parity results that validate preserving model performance.
- Human preference approximation using ChatbotArena, noting Elo scores (10 Nov 2025) are closely matched between V3.1-Terminus and DeepSeek V3.2-Exp, suggesting no preference regression despite sparse attention.
- Long-context evaluation by independent groups using previously unseen test sets. It cites AA-LCR3 (V3.2-Exp scoring four points higher in reasoning mode) and Fiction.liveBench (V3.2-Exp outperforming across metrics), arguing the base checkpoint does not regress on long-context tasks.
Data takeaway: V3.2 leans on external, newly created long-context test sets as a credibility move. That's valuable because long-context contamination risk is high: many long-context benchmarks are constructed from public corpora that frontier models may have seen.
11) How the Data Choices Show Up in Behavior and Performance
A) Math and Code Performance Is a Corpus Mix Decision, Not Magic
DeepSeek V3 explicitly attributes improvements to increasing math and programming sample ratios and to adding FIM. In practice, these changes tend to produce:
- Better competitive programming and structured reasoning (including International Olympiad-level problems), and
- Better editing/patching behaviors (because the model repeatedly practices "fill the missing span" tasks).
B) Long-Context Performance Depends on Long-Context-Aligned Training Data
V3.2's commitment to using a training distribution aligned with long-context extension data is one of its most important data decisions. Sparse attention is an efficiency mechanism that harmonizes high computational efficiency with strong reasoning, but the model still needs repeated exposure to meaningful long-range dependencies to learn what to retrieve from far away.
C) Distillation Is Trading "Raw Diversity" for "Expert-Shaped Signal"
Both V3 and V3.2 use distillation logic, but V3 is explicit about distilling long-CoT reasoning patterns from DeepSeek-R1 while controlling verbosity/format through system prompts, RL mixing, and rejection sampling. V3 even shows that R1 distillation improves math and coding benchmarks but increases response length, forcing a tradeoff between accuracy and efficiency.
V3.2 generalizes this idea: build specialists, distill their outputs, then use RL to eliminate gaps. This tends to produce models that are "expert-like" in targeted domains, because the training data is no longer a passive scrape—it's actively generated from high-performing policies using specifically optimized approaches.
D) Agentic Robustness Comes from Verifiable Tasks and Strict Filters
The search pipeline's "keep only cases where ground truth is correct and candidates are verifiably incorrect" is a strong filter that should reduce noisy labels. The code pipeline's executable-environment acceptance criteria are even stronger: the dataset is defined by tests passing/failing under patches.
Those are exactly the kinds of data constraints that usually translate into real improvements in tool use and other tasks requiring precision.
E) Benchmark Performance: Preserving Model Performance Under Sparse Attention
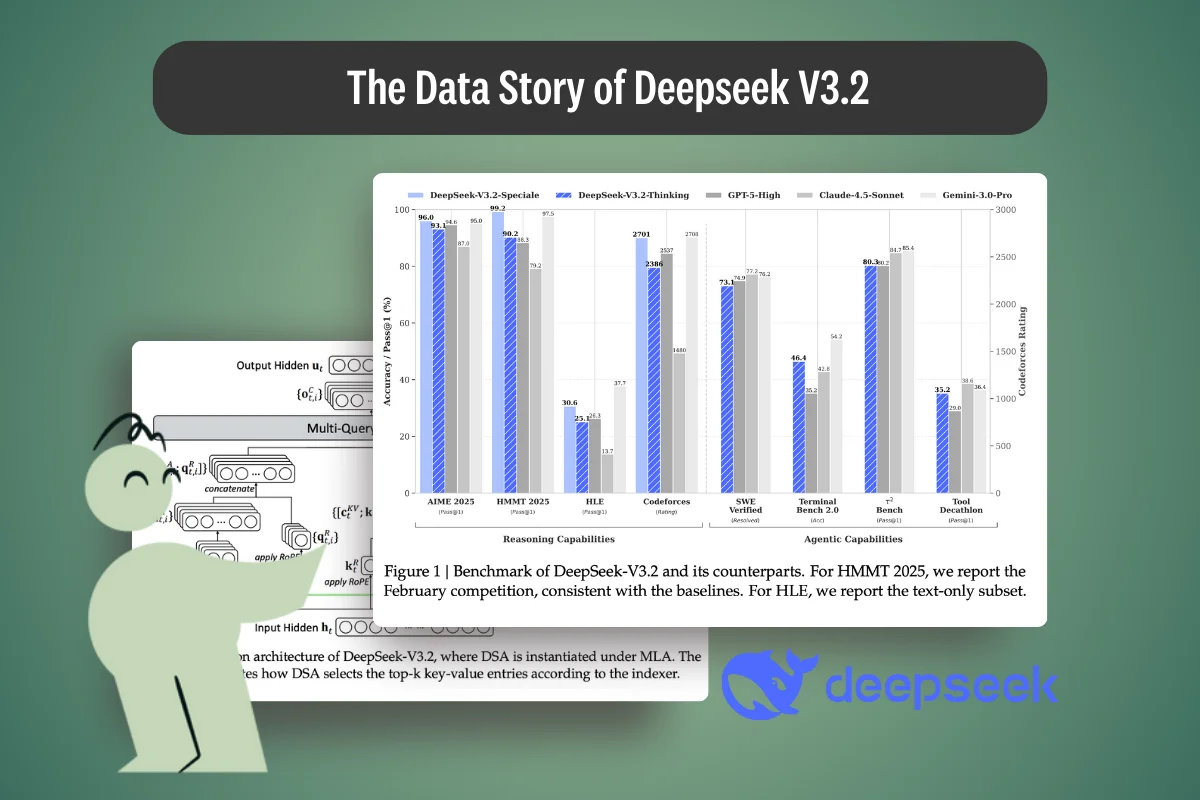
Public evaluations of DeepSeek V3.2-Exp (also referred to as DeepSeek V3.2 Speciale in some contexts) show that introducing DeepSeek Sparse Attention substantially reduces computational complexity without degrading benchmark results. Across standard reasoning benchmarks and coding benchmarks, V3.2 exhibits near-parity with the dense-attention DeepSeek-V3.1-Terminus model.
Reported results indicate:
- MMLU-Pro scores remain essentially unchanged (≈85), suggesting no loss in broad reasoning proficiency.
- Advanced math benchmarks (including AIME-style evaluations) show marginal improvements, consistent with strong deep reasoning task performance.
- Code-focused benchmarks such as competitive programming and LiveCodeBench display small gains or neutral shifts, indicating that sparse attention does not harm complex code reasoning.
Importantly, these results suggest that the efficiency gains from sparse attention come without sacrificing model performance. In other words, V3.2 preserves reasoning capabilities while enabling high computational efficiency in long context scenarios—a key technical breakthrough for open large language models.
This benchmark parity is itself a data result: it reflects careful alignment between long-context training data, post-training reinforcement learning, and evaluation protocols designed to detect regressions rather than mask them.
12) Where Humans Matter (and Where the Papers Are Quiet)
DeepSeek V3 is one of the clearer reports (among frontier-scale models) about explicit human involvement in post-training: for non-reasoning tasks like creative writing, role-play, and simple QA, it describes using model-generated responses and then having human annotators verify accuracy and correctness.
DeepSeek V3.2, by contrast, emphasizes automated and semi-automated pipelines—verification agents, rubric-driven reward models, and executable tests for code tasks—and it doesn't dwell on manual labeling in the main text. But the appendix tells a more grounded story: it includes a "Data Annotation" section listing many individual contributors. That detail matters, because even when a project is framed as "mostly automated," a named annotation roster strongly implies that human expertise is still part of the quality control loop, just not fully described.
In practice, humans are often needed for the kinds of judgments automated checks struggle with:
- Gold-standard validation when automated checks are weak (nuanced helpfulness, ambiguous questions, partially correct answers).
- Rubric design and auditing: deciding what "good" looks like for agentic tasks, tool-use, and long-form reasoning—and updating rubrics once models learn to optimize for the letter rather than the spirit.
- Spot checks and rejection sampling: reviewing slices of synthetic/model-generated data to catch systematic issues (format drift, hallucination patterns, unsafe behaviors, reward hacking).
- Edge-case adjudication where multiple "valid" answers exist and policy, tone, or user intent matters.
So even if DeepSeek V3.2 doesn't specify the operational details (how many items were reviewed, which domains used humans vs automated validators, inter-annotator agreement, escalation policies), the presence of a substantial Data Annotation team suggests a key reality: high-performing post-training pipelines still depend on human experts to keep the data distribution aligned with the intended behavior.
This supports the broader point of the article: scalable synthetic data factories are powerful, but they remain fragile without periodic, expert human intervention—especially in evaluation and curation steps where silent dataset drift can otherwise masquerade as "model improvement."
The Critical Role of Human-in-the-Loop in Data Quality
The DeepSeek V3.2 story reinforces a fundamental principle that organizations building AI systems must grapple with: the gap between automated data generation at scale and genuinely useful training data is bridged by human expertise.
Consider the verification loops DeepSeek describes—multi-agent validation, executable tests, rubric-driven scoring. These are sophisticated automated systems. Yet even with all this machinery, the presence of dedicated data annotators signals that human judgment remains irreplaceable for:
- Defining success criteria that align with real-world use cases rather than proxy metrics
- Catching failure modes that automated validators systematically miss
- Ensuring domain validity where subject matter expertise (radiologists for medical imaging, engineers for technical documentation, underwriters for financial assessments) cannot be approximated by general-purpose models
This isn't a limitation of DeepSeek's approach—it's a reflection of where AI data quality actually comes from. The models that perform best in production are rarely those trained on the most data; they're trained on the most carefully curated data, validated by people who understand what "correct" actually means in context.
For enterprise AI teams, this has practical implications. Building effective data pipelines isn't just about scale or automation—it's about creating systems where domain experts can efficiently validate and refine AI outputs. The collaboration between technical teams (who build the infrastructure) and subject matter experts (who verify the outputs) is what transforms raw data into expert AI data that drives real model performance gains.
13) The Biggest Open Gap: Data Transparency
Both reports disclose many methods (packing, FIM, synthetic task generation, verification), but they do not fully disclose:
- Detailed source composition of corpora,
- Deduplication and contamination audits at the benchmark level, or
- The distributional breakdown of post-training prompts beyond the agent task table.
That's not a moral critique; it's just a practical limitation for anyone trying to reproduce results or reason about risk. When a model's performance is increasingly driven by synthetic pipelines, the details of filtering and rubric design become as important as "14.8T tokens" ever was.
Closing: The V3.2 Lesson Is That "Data" Now Means Pipelines
DeepSeek V3.2 is a good example of where frontier models and open large language models are going, as demonstrated by the DeepSeek team:
- Pre-training still matters, and V3 shows careful corpus mix design (math/code ratio, multilingual compression) and data transformations (FIM, packing, token-boundary mitigation).
- But V3.2's differentiator is post-training data engineering: specialists, distillation, agent environments, strict verification loops, and rubric-driven reward models—all products of a scalable reinforcement learning framework.
- Evaluation increasingly depends on fresh, external test sets (especially for long context) and indirect human preference signals like ChatbotArena.
If you want to understand why V3.2 behaves the way it does, don't start with sparse attention. Start with the question:
What experiences did the model repeatedly live through—what tasks, what filters, what rewards—and how reliable were those signals?
That's the real data story of DeepSeek V3.2.
And at the heart of reliable signals is a truth the AI industry is still learning to operationalize: synthetic data pipelines can scale, but human expertise in the loop—whether designing rubrics, validating edge cases, or ensuring domain accuracy—is what separates training data that merely exists from training data that actually improves model performance.
Resources
Below are key primary sources and public references used when analyzing DeepSeek V3 and DeepSeek V3.2. These include original technical papers, model cards, and public benchmark discussions.
Technical Papers
- DeepSeek V3: Technical Report (arXiv: 2412.19437v2)
- DeepSeek V3.2: Technical Report (arXiv: 2512.02556v1)
Model Releases and Documentation
- DeepSeek V3.2-Exp model card (Hugging Face)
- DeepSeek API & release notes
Benchmark Discussions and Independent Analyses
- Skywork AI – Overview of DeepSeek V3.2 and sparse attention
- Chatbot Arena (LMSYS) – Human preference benchmarking
These resources provide additional context on benchmark performance, long-context evaluation, sparse attention efficiency, and post-training reinforcement learning design choices discussed throughout the article.
Other Data Stories:
SAM 3 Explained: Breaking Down the Training, Fine-tuning, and Evaluation Data of SAM 3
Qwen 3: A Deep Dive into Its Data Pipeline
FineWeb2 Dataset Guide: How It's Built, Filtered, and Used for Training LLMs
Frequently Asked Questions
What is DeepSeek V3.2?
DeepSeek V3.2 is a large language model that builds on a DeepSeek-V3.1-Terminus base checkpoint with 128K context length. Rather than training from scratch, V3.2 applies continued pre-training and extensive post-training — including specialist distillation and mixed reinforcement learning — to achieve strong performance on long-context, coding, and agentic tasks.
How does DeepSeek V3.2 differ from DeepSeek V3?
V3 was trained from scratch on 14.8 trillion tokens with a diverse pre-training corpus. V3.2 starts from a V3.1 checkpoint and focuses on continued pre-training aligned with 128K long-context data, plus a heavier investment in post-training through specialist distillation and a large-scale agentic task synthesis pipeline producing 1,800+ environments and 85,000+ prompts.
What is DeepSeek Sparse Attention?
DeepSeek Sparse Attention (DSA) is V3.2's attention mechanism designed for efficient 128K-context inference. It only delivers efficiency gains when the model has been trained on meaningful long-range dependencies, which is why the continued pre-training data distribution is specifically aligned with long-context data.
How does specialist distillation work in V3.2?
V3.2 trains separate domain experts in math, code, and agentic tasks, then uses them as data generators for the unified model. These specialists produce high-quality outputs through rejection sampling, making prompt design and filtering more important than raw corpus breadth. The quality of each specialist directly determines what the final model learns.
How was the agentic training data built?
V3.2 uses a large-scale agentic task synthesis pipeline that produces 1,800+ environments and 85,000+ prompts. Code agent data is only accepted when the generated code passes execution verification. This pipeline is a key driver of V3.2's generalization in tool-use contexts.
How does V3.2 handle evaluation contamination?
The report describes evaluation sets specifically designed to limit contamination on coding and long-context benchmarks. Evaluation data is treated as a curated distribution — not just a set of test cases — with selection criteria intended to ensure that measured improvements reflect real capability gains rather than artifacts of leakage or style bias.
Need Domain Specialists for Your AI Post-Training Pipeline?
DeepSeek V3.2 shows that post-training data quality — from specialist distillation to agentic environment design — determines model capability more than raw pre-training scale. Kili Technology provides the verified domain experts and structured quality workflows that specialist training pipelines require, with full traceability from rubric design to final annotation.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
