
.png)

_logo%201.svg)


AI Summary
- The GLM model family treats training as continuous data engineering rather than architecture innovation alone.
- GLM-5 pre-trains on ~28.5 trillion tokens with dedicated classifiers extracting signal from noisy web, code, and STEM pools.
- Long-context training in the GLM-5 model extends progressively from 32K to 200K tokens as a staged curriculum.
- GLM-5's agentic capabilities are taught through executable environments — real issue-PR pairs, Dockerized terminals, and web knowledge graphs.
- Reinforcement learning in GLM models uses human-authored responses as style anchors to prevent reward hacking.
- Organizations building reliable AI in 2026 should treat data quality as continuous engineering with embedded domain experts and verifiable standards.
The lineage that matters is data and feedback
Most model-family narratives start with parameter counts and end with benchmark charts. For GLM, the more durable story is how the data pipeline—collection, filtering, deduplication, mixture design, synthetic data, and feedback loops—becomes more explicit and more instrumented over time.
This write-up follows that thread from the original GLM paper to GLM-5. Architecture is context. Data and feedback are the mechanism.
1) What makes the GLM family different from other open-source model lineages
There are many strong open-weight families. GLM stands out less for a single architectural trick and more for how training is framed as a program of data engineering:
- Bilingual-first lineage. Large-scale releases repeatedly treat Chinese and English as first-class pre-training data targets.
- A pipeline that gets more concrete over time. By GLM-4.5, the team describes source-specific quality scoring, semantic deduplication to address template-like near-duplicates, and stagewise mixture shifts.
- Post-training described as infrastructure, not a black box. GLM-5's report goes further: it treats alignment as a sequence of dataset factories—SFT datasets, verifiable RL environments, and filtering rules—running inside an asynchronous RL system.
None of this guarantees better outcomes. But it does change what outsiders can reasonably infer: you can explain behavior in terms of observable pipeline mechanisms (filters, sampling, verifiers, environments), not only in terms of branding or benchmark deltas.
This is also the premise behind data-centric AI platforms like Kili Technology: that model quality is governed by data decisions—who labels, how quality is measured, which samples are admitted or excluded—and that those decisions should be visible, auditable, and engineerable. GLM's public record is one of the clearest illustrations of why that philosophy matters at scale.
2) Timeline: what changes in the data story
2021 — GLM (paper)
- Data story: Controlled pre-training corpora for fair comparisons (BooksCorpus + English Wikipedia in core experiments), rather than a web-scale crawl.
2022 — GLM-130B
- Data story: Explicit bilingual scaling and large upstream corpora. Source lists become clearer, but cleaning details remain high-level.
2023 — ChatGLM-6B / ChatGLM2 / ChatGLM3
- Data story: Dialogue and product behaviors become more visible than the pre-training recipe. Tool use starts to matter because it makes tool traces representable and therefore supervisable.
2024 — GLM-4 (report + open 9B series)
- Data story: A clearer, canonical pipeline emerges (deduplication, filtering, reweighting toward educational sources, very large token scale).
2025 — GLM-4.5 (technical report)
- Data story: The "blueprint" moment: source-specific scoring (web vs multilingual vs code vs STEM), explicit stagewise mixture shifts, and post-training described as filtering + verification.
2026 — GLM-5 (technical report)
- Data story: The GLM-5 report adds what was missing in most blog/model-card narratives: concrete pre-training selection mechanisms (e.g., DCLM/world-knowledge classifiers), explicit long-context mid-training schedules, and detailed post-training data construction for agentic environments. GLM-5 delivers significant improvement compared to GLM-4.7 across a wide range of academic benchmarks, achieving best-in-class performance among all open-source models in the world on reasoning, coding, and agentic tasks.
3) Performance over time: what benchmarks can and cannot explain
Across this lineage, improvements often track data shifts more than "one new module":
- More tokens + broader sources (web + books + papers + code) are necessary but not sufficient.
- Mixture design becomes deliberate: later stages upsample code, reasoning, and long-context/agentic traces.
- Post-training becomes a data factory: repeated generation, scoring, filtering, and replay decisions matter as much as the base corpus.
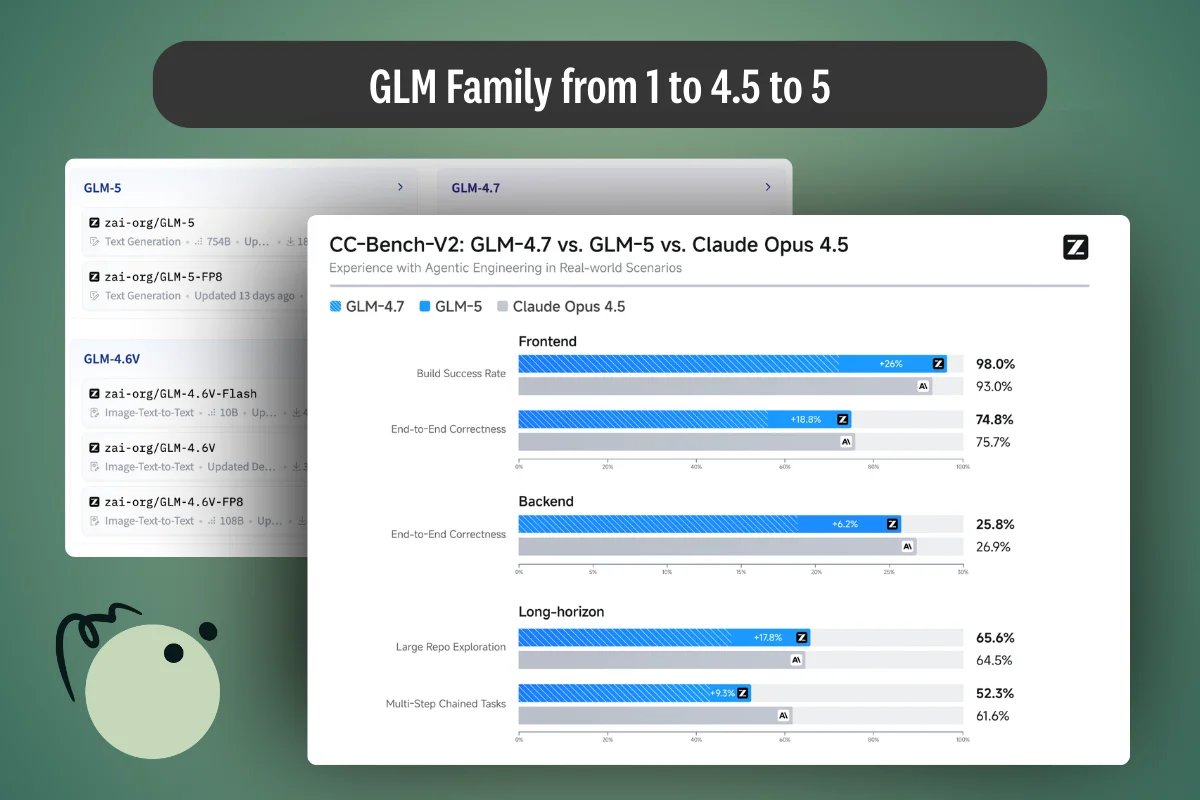
A practical caution: benchmark tables are only as meaningful as their evaluation datasets and harnesses. GLM-5 is useful here because it often describes how evaluations were run (agent frameworks, context windows, judge models, verified variants), not just the scores. GLM-5 increases performance on benchmarks such as Humanity's Last Exam by 7.6% and BrowseComp by 8.4%. It ranks #1 among open-source models on Vending Bench 2, demonstrating strong long-term planning and resource management. It significantly outperforms GLM-4.7 across frontend, backend, and long-horizon tasks on the internal evaluation suite CC-Bench-V2.
These results are expected to match the performance of proprietary models released recently—a signal that data engineering at scale, not just compute, is what closes the gap between open-source and proprietary models.
For enterprise teams, the evaluation story matters as much as the training story. Building evaluation datasets with verifiable outcomes—not just subjective preference ratings—is what lets you measure model improvement rather than estimate it. This is one reason why organizations working with domain expert annotation services increasingly treat evaluation data construction as a first-class concern: the same score-filter-verify loop that drives frontier model training also drives reliable enterprise AI.
4) GLM-4.5 as the "blueprint": the data mechanisms GLM-5 builds on
GLM-4.5 is the pivot where the team starts describing training quality as a measurable, engineerable pipeline. This matters because GLM-5 repeatedly says it "builds on" GLM-4.5 components (especially the web pipeline and quality-aware sampling). So it's worth being explicit about what those components are.
4.1 The GLM-4.5 web pipeline: from web-scale crawl to a controllable mixture
GLM-4.5's web story is not "we crawled the web." It's "we turned the web into buckets we can reliably sample from." The key steps, in plain terms:
- Aggressive hygiene filters before scoring
- Remove obvious junk (spam, boilerplate-heavy pages, broken encoding).
- Language ID and script filtering to avoid accidental mixing and to stabilize downstream classifiers.
- URL / host-level heuristics to reduce repeated templates and navigation pages.
- Deduplication at multiple levels
- Exact dedup removes identical documents.
- Fuzzy dedup catches near-duplicates (e.g., minor edits or mirror sites).
- Semantic dedup addresses the modern pathology of the web: template-generated pages that look different but say the same thing.
- Quality scoring is source-aware Instead of one "good vs bad" classifier for everything, GLM-4.5 describes domain-aware scoring (web vs multilingual vs code vs STEM). In practice this means the signal for "high quality" differs:
- for web: clarity, low boilerplate, educational density, fewer SEO artifacts
- for code: compilable/parsable structure, meaningful identifiers, repository metadata consistency
- for STEM: conceptual explanations, correct structure, fewer formula extraction errors
- Bucketization: quality becomes a sampling handle The outcome of the above is not just a cleaned corpus—it's a corpus partitioned into quality tiers/buckets.
Why buckets matter: once you have buckets, you can control training by deciding how much each bucket appears at each stage.
The same principle underlies enterprise data labeling workflows: you don't treat every data point equally. You score, tier, and prioritize—directing expert review toward the cases that matter most for model performance, while using automation for clearer-cut decisions. What GLM-4.5 does at the corpus level with classifiers, a well-designed annotation pipeline does at the project level with consensus metrics, quality dashboards, and active learning.
4.2 What "quality-aware sampling" means in practice
GLM-4.5 uses the term "quality-aware sampling" in multiple domains (web, code, multilingual, STEM). The simple operational definition is:
- Assign each document a quality score or tier.
- Sample documents with probabilities that favor higher-quality tiers.
- Adjust that weighting over time (stagewise), depending on what the model needs.
A useful mental model is:
- early training: broader coverage, more diversity (but still filtered)
- later training: more concentration on high-quality or high-signal domains (code, reasoning-heavy text, educational material)
This is the bridge to GLM-5: GLM-5 adds better selectors (DCLM / world-knowledge classifiers), but it's still using the same underlying lever—score → bucket → sample.
4.3 Why GLM-4.5 emphasizes semantic dedup (and why GLM-5 inherits it)
The biggest "data leak" in web-scale corpora is not only benchmark contamination. It's distribution collapse from repetition:
- scraped copies of the same article
- templated "how-to" pages
- SEO farms that paraphrase the same content
Semantic dedup matters because it preserves effective novelty—the diversity of ideas and phrasing the model actually learns from.
GLM-5 later reports a "fuzzily deduplicated unique token" increase in its code corpus; that metric only makes sense if you accept the GLM-4.5 premise: novelty after dedup is the real currency, not raw token count.
For enterprise AI teams, the equivalent insight is that annotating a thousand variations of the same easy case teaches a model nothing new. The value lies in identifying and labeling the hard, ambiguous, edge-case data that pushes model performance forward—which is why active learning workflows that surface uncertain or high-impact data points for expert review are the enterprise-scale version of what frontier labs call deduplication and curriculum design.
4.4 GLM-4.5 code data: tiers, formats, and why that improves downstream agent behavior
GLM-4.5's code pipeline is where "quality-aware sampling" becomes very concrete:
- Multi-source code collection (repositories + code-like web pages).
- Tiering (high / medium / low) based on signals like repository credibility, file structure, language identification, and text cleanliness.
- Format-preserving parsing so code snippets scraped from HTML don't lose indentation, symbols, or block structure.
- Fill-in-the-middle (FIM) applied broadly to teach editing and completion behaviors.
The downstream importance is straightforward: if you want code agents and tool users, you need training data where format is truth. A "mostly correct" code snippet that loses indentation is not "mostly useful"—it's broken.
4.5 GLM-4.5 STEM data: scalable scoring, then distillation for production filtering
GLM-4.5 describes a common pattern for expensive quality signals:
- Use a strong model / expensive heuristic to score a large candidate pool.
- Distill that signal into a cheaper classifier.
- Run the cheap classifier at scale to filter new data.
This is an important philosophical point that GLM-5 continues:
- The best data signals are often too expensive to run everywhere.
- So you build approximators (distilled classifiers) to turn "quality judgment" into a scalable system.
The same trade-off plays out in enterprise annotation: expert review is expensive, so you embed it strategically—on gold standards, calibration batches, and edge cases—while using programmatic quality checks and AI-assisted pre-annotation to handle the volume. Kili Technology's professional services model is built around this exact pattern: expert-guided project setup and quality anchoring, with scalable annotation workflows that sustain that quality level across large datasets.
4.6 Stagewise mixture is the hidden curriculum
GLM-4.5 is explicit that mixture changes by stage. This is easy to overlook, but it is the training curriculum:
- Earlier: broad web + multilingual coverage (still filtered)
- Later: higher weight on code, reasoning-heavy content, long-context candidates, and "educational" slices
This is why GLM-5's later "mid-training" (long context + agentic traces) is not a new idea—it's a continuation of the same curriculum logic, made more explicit.
4.7 Post-training in GLM-4.5: verification and filtering as first-class data work
GLM-4.5 already frames post-training as:
- constructing SFT datasets with filtering rules
- verifying answers where possible
- applying multi-stage filtering for tool trajectories
GLM-5 expands the tool/agent portion dramatically, but it's the same pattern: turn behavior into data, then control that data with filters and verifiers.
Why this expanded GLM-4.5 section matters: GLM-5's new classifiers and environments are not "magic add-ons." They're upgrades to the same control surface GLM-4.5 introduced: score, bucketize, sample, verify.
5) Slime and asynchronous RL: why "data quality" becomes trajectory admission control
Slime is easy to misread as "an RL framework." In practice, it's closer to an online dataset generator:
- A rollout system continuously produces trajectories.
- Verifiers/reward models score them.
- A buffer filters and samples them for training.
In GLM-5's report, several choices are framed explicitly as data integrity controls:
- Token-in-Token-out (TITO): preserve the exact token stream and metadata produced during rollouts.
- Filtering off-policy and noisy samples: drop trajectories that are too stale relative to the current policy or failed for non-model reasons (environment issues, resource limits, premature user termination).
- Tail-latency optimizations (PD disaggregation, FP8 rollouts, MTP): these look like systems details, but they change which long-horizon samples successfully complete—and therefore what "experiences" the model learns from.
The novel asynchronous RL infrastructure substantially improves training throughput while also functioning as a quality gate: by reducing RL training inefficiency, it ensures the model trains on representative trajectories rather than an artifact of compute bottlenecks.
The key shift: in offline pre-training, data quality is mostly "remove bad documents." In online agent RL, data quality is admission control for trajectories. This parallels how enterprise AI teams must approach data labeling for LLM fine-tuning and RLHF: the quality of the human feedback loop—who provides it, how it's verified, what gets admitted and what gets discarded—directly determines the model behavior you get.
6) GLM-5: what the new paper discloses about data
The GLM-5 report describes a base-model program of roughly 28.5T tokens across two phases: a general/coding pre-training stage (~27T tokens) and a mid-training stage for long-context + agentic data that progressively extends context length to a maximum context length of 200K tokens. GLM-5 is designed for long context reasoning across complex systems engineering tasks.
6.1 Pre-training data: "build on GLM-4.5, but refine selectors"
The report organizes pre-training data improvements by domain:
Web
- Builds on GLM-4.5's web pipeline, but adds:
- an additional DCLM classifier (sentence-embedding based) to identify and aggregate high-quality data beyond standard classifiers
- a World Knowledge classifier optimized using Wikipedia entries and LLM-labeled data to extract long-tail knowledge from medium/low-quality content
Code
- Expands the corpus with refreshed snapshots from major code hosting platforms + more code-containing web pages.
- Reports a 28% increase in fuzzily deduplicated unique tokens, a proxy for "effective novelty."
- Fixes metadata alignment issues in Software Heritage code files and adopts a more accurate language classification pipeline.
- Keeps GLM-4.5's quality-aware sampling, and adds dedicated classifiers for more low-resource languages (e.g., Scala, Swift, Lua).
Math & Science
- Collects high-quality STEM data from webpages, books, and papers.
- Refines webpage extraction and PDF parsing to improve data quality.
- Uses large language models to score candidate documents and retains the most "educational" content.
- Adds a chunk-and-aggregate scoring algorithm for long documents.
- States that filtering pipelines strictly avoid synthetic/AI-generated or template-based data in this STEM slice.
6.2 Mid-training: long context as a distribution shift (not a switch)
GLM-5 extends context in three stages, preserving long-context capacity through progressive curriculum rather than a single switch:
- 32K: ~1T tokens
- 128K: ~500B tokens
- 200K: ~50B tokens
Two parts of this mid-training program matter for the data story.
Software engineering sequences
- Concatenate repo-level files, commit diffs, issues, PRs, and relevant source files into unified training sequences.
- Relax repository-level filtering to broaden coverage (~10M issue–PR pairs), then tighten filtering at the issue level.
- After filtering, the issue–PR portion comprises ~160B unique tokens.
Long-context documents (natural + synthetic)
- Natural long-context data is curated from books, papers, and long documents inside the general corpus, using multi-stage filtering and upsampling knowledge-intensive domains.
- Synthetic long-context data uses techniques inspired by NextLong and EntropyLong, including interleaved packing of highly similar texts to build long-range dependencies and mitigate "lost-in-the-middle."
- At the 200K stage, adds a small portion of MRCR-like multi-turn recall data.
6.3 SFT: the "interface" changes because the dataset changes
The SFT corpus is described as three major categories:
- General Chat: QA, writing, role-play, translation, multi-turn, long-context interactions
- Reasoning: mathematical, programming, scientific reasoning
- Coding & Agent: frontend/backend code, tool calling, coding agents, search agents, general agents
Notable data decisions:
- Role-play data curated via named dimensions (instruction following, expressiveness, creativity, coherence, long-dialogue consistency), using both automatic and human filtering.
- Reasoning data emphasizes verifiability: rejection sampling from verifiable problems; difficulty filtering around tasks GLM-4.7 fails.
- Agent/coding SFT grounded in execution environments and long-horizon trajectories.
- Error segments retained but masked in loss to encourage correction without reinforcing wrong actions.
The human filtering component here is critical and often under-discussed. When the GLM team describes curating role-play data across named quality dimensions, or filtering reasoning data by what earlier models fail on, they're describing exactly the kind of structured, expert-guided data work that separates reliable AI from brittle prototypes. Enterprise teams building domain-specific SFT and RLHF datasets face the same challenge: you need annotators who understand the domain well enough to judge correctness, catch subtle errors, and maintain consistency across thousands of samples. Generic crowd labeling cannot do this work reliably.
6.4 Reasoning RL: a mixed-domain pipeline with external human input
Reinforcement learning aims to bridge the gap between competence and excellence in pre-trained models. GLM-5's reasoning RL runs across math, science, code, and tool-integrated reasoning (TIR).
- Data sources include open datasets and co-developed collections with external annotation vendors.
- Difficulty filtering targets the right frontier (hard for the current model, solvable by stronger teachers).
- Rewards are largely binary outcome rewards from verifiers/judge models.
The collaboration with external annotation vendors is a notable detail. Deploying reinforcement learning at scale for LLMs remains a challenge due to RL training inefficiency, but data sourcing is equally critical—you need problems calibrated to the model's current ability, verified by people or systems that can confirm correctness. This is the same challenge enterprise teams face when building evaluation and fine-tuning datasets: finding the right level of difficulty, sourcing domain experts who can verify outcomes, and maintaining quality at scale.
6.5 Agentic RL: environment scaling and verifiable tasks
GLM-5 scales verifiable environments across multiple domains, targeting long-horizon agentic tasks:
Software engineering
- Real issue–PR pairs.
- Executable environments (RepoLaunch-style).
- Reports 10k+ verifiable environments.
Terminal
- Synthesized structured tasks with Dockerized execution.
- Web-grounded tasks admitted only if automated self-verification passes.
Search
- Build a Web Knowledge Graph from deduplicated URLs.
- Generate multi-hop questions from subgraphs.
- Filter out questions solvable without web tools or solvable by early-stage agents; add bidirectional consistency checks.
The result: GLM-5 ranks #1 among open-source models on Vending Bench 2, which measures long-term operational capability. It is compatible with various coding agent frameworks including Claude Code, OpenCode, Kilo Code, Roo Code, and Cline. GLM-5 also supports OpenClaw, a framework that allows it to operate across apps and devices.
6.6 General RL: hybrid rewards, plus a clear human "anchor"
General RL decomposes optimization into correctness, emotional intelligence, and task-specific quality.
- Rewards are hybrid (rules + outcome RMs + generative RMs).
- Expert human-authored responses serve as style/quality anchors to avoid convergence to "model-like" patterns.
That last point deserves emphasis. Without human anchors, RL-trained models tend to drift toward outputs that satisfy the reward model without actually being good—a form of reward hacking. The human anchor is a data quality mechanism, not a cosmetic one.
This maps directly to how Kili Technology's managed annotation services approach quality for enterprise AI: expert-authored gold standards anchor the annotation process, calibration batches align annotator teams to those standards, and continuous quality monitoring prevents drift. The same discard-all strategy that GLM-5 uses for off-policy trajectories has an enterprise equivalent: filtering out low-agreement labels, reviewing edge cases with domain experts, and iterating guidelines to close quality gaps.
6.7 Evaluation as data: internal sets, rubrics, and cross-checks
GLM-5 treats evaluation as dataset design:
- Expert-designed task suites + checklists (e.g., frontend agent judge model) with human cross-checking.
- Badcase sets built from production failures, then human-reviewed to remove ambiguity.
- Translation scenarios curated and verified by trained graduate students.
- Decontaminated SWE evaluation framed as a refreshable test program. More evaluation details on the SWE Bench suite, SWE Bench Verified, and SWE Bench Multilingual are reported in the paper, with results marked by model name and configuration (including think mode settings and maximum generation length).
The badcase-set methodology is particularly instructive: you find where the model fails in production, convert those failures into labeled evaluation data, then have domain experts clean that data to remove ambiguity. This is a continuous feedback loop that treats evaluation not as a one-time gate but as an evolving dataset that tracks the model's real weaknesses.
Enterprise teams building production AI need the same loop. A leading European insurer demonstrated this when scaling AI from a single-use-case pilot to a portfolio of nine AI projects across sixty users: by embedding subject matter experts in the labeling process—with measured inter-annotator agreement, structured review stages, and continuous feedback between annotators and model iterations—the team built datasets that tracked and resolved model failures iteratively, not just at deployment checkpoints. The collaborative workflows that made this possible—consensus measurement, multi-stage review, programmatic error detection—are the enterprise equivalent of GLM-5's evaluation-as-data philosophy.
7) What's still not fully disclosed (and why it matters)
Even with GLM-5's report, several details remain hard to reason about externally:
- Full pre-training mixture inventory (exact source lists, language breakdowns, domain proportions).
- Licensing and provenance detail for web-scale sources.
- Exact dedup parameters and contamination controls.
- Full human feedback protocol (guidelines, audits, disagreement handling) beyond high-level descriptions.
This is worth noting because it reflects a broader challenge across AI development: even when organizations are transparent about their pipeline architecture, the operational details of data quality—annotation guidelines, annotator qualifications, disagreement resolution, quality drift monitoring—are often the hardest things to document and the most consequential for outcomes. It's one reason why enterprises building AI in regulated industries (finance, insurance, healthcare, defense) increasingly need transparent, auditable data platforms that provide complete traceability for every data decision: who labeled each asset, who reviewed it, what consensus was reached, and how quality evolved over time.
8) The data-quality lesson that runs through the GLM lineage
GLM's public record shows an arc from "train on a controlled corpus" to "treat training as continuous data engineering." GLM-4.5 made that legible; GLM-5 makes it explicit across the entire pipeline:
- selectors (classifiers) to extract signal from noisy pools
- dedup strategies that address modern web pathologies
- long-context training as a distribution shift with staged curricula
- agentic performance taught through executable environments
- RL reframed as feedback data quality: verifiers, admission control, and human anchors
Scaling is one of the most important ways to improve the intelligence efficiency of artificial general intelligence (AGI)—but the GLM lineage shows that scaling data quality mechanisms matters as much as scaling compute. GLM-5 is open-sourced under the MIT License, available on Hugging Face and ModelScope, accessible through Z.ai offering both Chat and Agent modes, and can be served locally using high-quality open-source inference engines like vLLM and SGLang with support for local deployment on non-NVIDIA chips including Huawei Ascend and Moore Threads.
If you want to understand GLM-5, don't start with its attention mechanism. Start with the question:
What kinds of tasks and trajectories does the pipeline repeatedly admit into training—and what does it systematically exclude?
That's where model behavior comes from. And it's the same question every enterprise AI team should be asking about their own data. The organizations building the most reliable AI in 2026—whether frontier model labs or enterprises deploying domain-specific systems—are the ones that treat data quality not as a labeling task but as continuous engineering, with domain experts, quality metrics, feedback loops, and verifiable standards embedded at every stage.
Platforms like Kili Technology exist because this lesson is not just theoretical. When enterprises need to embed subject matter experts—compliance officers, radiologists, manufacturing engineers, underwriters—directly into the AI data lifecycle, they need infrastructure that makes the score-bucket-sample-verify loop operational at enterprise scale: collaborative annotation with consensus measurement, managed expert workforces spanning hundreds of domains and dozens of languages, professional services for project design and quality anchoring, and secure, auditable deployment trusted by defense contractors, healthcare providers, and financial institutions.
The same data-pipeline discipline that drives GLM's quality gains translates directly into enterprise AI operations. For teams managing human oversight at scale, our guide on scaling HITL AI evaluation covers the core operational challenges—and our breakdown of LLM-as-a-judge and HITL workflows explains how to combine automated and human evaluation reliably.
Resources
Technical papers
- GLM: General Language Model Pretraining (arXiv:2103.10360)
- GLM-130B: An Open Bilingual Pre-trained Model (arXiv:2210.02414)
- ChatGLM: A Family of Large Language Models (arXiv:2406.12793)
- GLM-4.5 Technical Report (arXiv:2508.06471)
- GLM-5: from Vibe Coding to Agentic Engineering (arXiv:2602.15763)
Post-training infrastructure
- Slime (RL post-training framework)
Model release artifacts
- GLM-5 repository
Related long-context references cited by GLM-5
- NextLong (arXiv)
- EntropyLong (arXiv)
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

