
.png)

_logo%201.svg)


AI Summary
Large language models that power ChatGPT-like chatbots are pivotal to further advancing modern natural language processing (NLP) technologies. When developing language models for downstream applications, machine learning teams use annotated datasets to fine-tune their behavior and domain specificity.
However, data labeling, which produces annotated datasets, is potentially costly and tedious. Conventionally, organizations engage large teams of human labelers and commit substantial resources to coordinate the effort. Data labeling is a potential bottleneck in the machine-learning pipeline if it’s entirely dependent on humans.
In this article, we explore the potential of using open-source large language modes to improve data labeling efficiency and reduce costs.
A Brief Overview of LLMs and Data Labeling
An LLM is a statistical model that predicts the next token based on the probability distribution of previous words. Tokens in the context of textual data refer to individual pieces or units of a text, such as words, numbers, or punctuation. They are the building blocks of language that can be analyzed or processed in natural language processing tasks.
LLMs can perform text generation, machine translation, speech recognition, and other linguistic tasks more robustly than traditional models like recurrent neural networks. Such a language modeling approach enables AI chatbots like ChatGPT to converse like humans. Yet, general language models can only infer accurately within the data they were trained on.
For example, you can’t use a general language model as a customer service chatbot without further fine-tuning the model with specific company information. To do that, you must annotate datasets consisting of product guides, marketing copies, and helpdesk conversations, which you use as training data for the model.
Data labeling is an activity that identifies and classifies specific text in the training data for neural language models to learn from. A probabilistic language model trains itself from the patterns found in the dataset and applies them to unseen real-world data. For example, labelers tag customer feedback as positive, neutral, and negative to train a model for sentiment analysis.
Challenges of Evaluating LLMs for Data Labeling Tasks
ChatGPT isn’t the only LLM available to assist with data labeling tasks. Besides the popular chatbot, various open-source LLMs are publicly available on data science platforms like HuggingFace.
The question is, how do you decide which LLM is suitable for data labeling?
To produce high-quality labels, you need good language command, attention to detail, and reasonable expertise in the subject matter. While LLMs are capable of accomplishing NLP tasks, not all can replicate the traits that human labelers possess. ML teams face these challenges when choosing an LLM for data labeling, particularly as there’s a lack of standardized benchmarks.
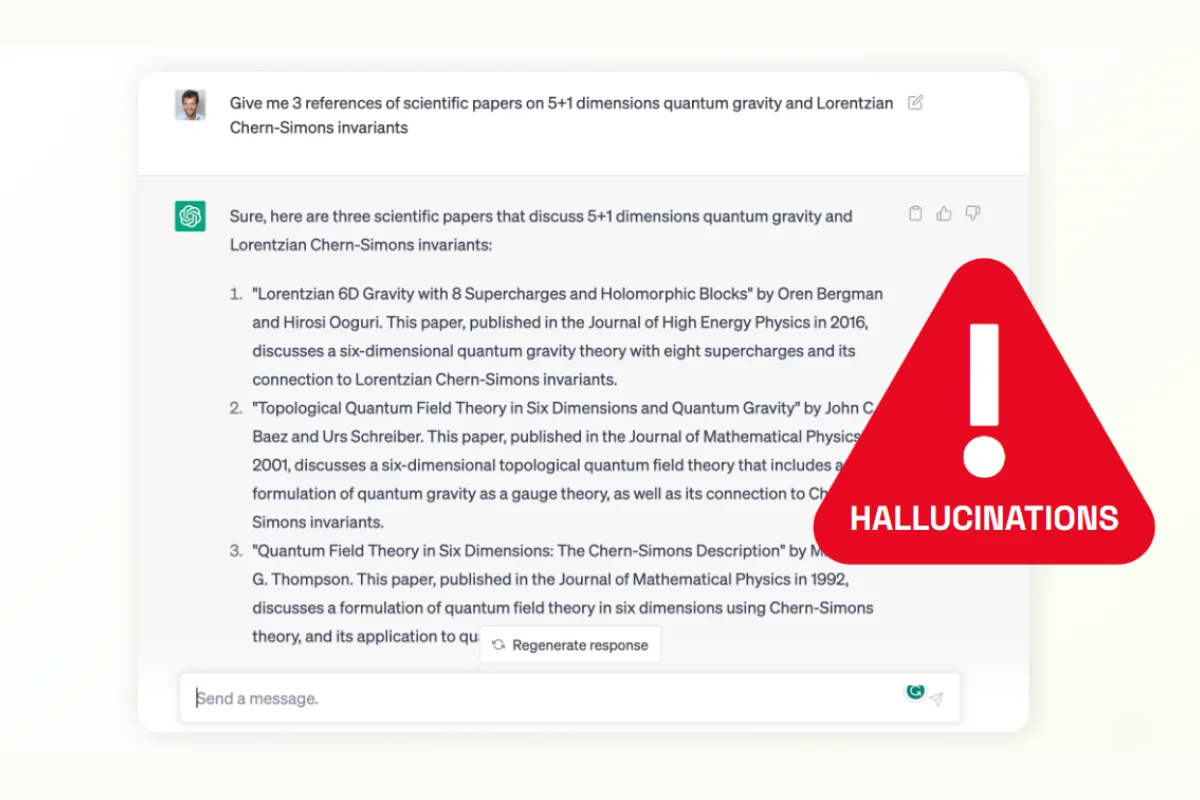
Hallucination
LLMs are good predictors of word sequences, but they sometimes struggle with factual accuracy. When presented with less-known facts, large language models might hallucinate and return inaccurate results. There are risks that hallucinations might impact the datasets annotated by such models, requiring additional safeguards to spot such discrepancies.
Lack of Ground truth
ML teams must ascertain a ground truth or high-quality evaluation dataset to compare different LLMs. However, creating ground truth datasets is time-taxing and often requires the input of domain experts. Without ground truth data, ML teams will not be able to properly evaluate the LLM for domain specific tasks.
Domain specificity
Pre-trained models like GPT-4, LlaMa, and BERT excel at NLP tasks like text generation, machine translation, and word prediction. Repurposing them for annotating datasets for a specific industry requires such models to learn new knowledge. Hence, ML teams need domain-specific benchmarks to ensure the models consistently perform as they would in general tasks. Unfortunately, some downstream tasks lack a benchmark to evaluate the LLM.
Time and cost
Evaluating LLM models for specific data labeling tasks requires ample preparation. ML teams must curate datasets, set up compute infrastructure, and fine-tune the model before they can conduct experiments to gauge the model’s performance. Not all organizations can afford these, as these steps can take up valuable time and costs.
Ethical challenges
LLMs are neural networks architectured like black boxes. They lack explainability and might inherit biases from pre-trained datasets. These qualities make it harder for ML teams to determine the 'thought-pattern' of an LLM, leading to significant challenges in identifying biases and inconsistencies when applying LLMs for data labeling. For example, the Federal Trade Commission is investigating OpenAI’s ChatGPT in the United States for its potential to generate inaccurate, offensive, and harmful content. The model’s lack of explainability is cited as an additional challenge in addressing the harmful content it generates.
Evaluate LLMs with Kili’s evaluation tool
Need help evaluating your LLM? Use our interface to simplify your evaluation process today.
Current practices in evaluating LLMs
Organizations can evaluate LLMs with existing benchmarks, but none are yet tailored for data labeling tasks. Still, by combining several methods, you can gain a strong understanding of a model’s inference capabilities for data annotation.
Benchmark tasks
Several data science platforms develop frameworks to provide a relative comparison of LLMs. On these platforms, models are scored on different NLP tasks and ranked according to performance. By referring to these leaderboards, you can shortlist models for data labeling based on how they performed in relevant linguistic tasks.
Hugging Face
Hugging Face is an AI community providing open-source transformer models and machine learning resources. Its highly popular leaderboard ranks transformer architecture LLMs with the Eleuther AI LM Evaluation Harness framework. Hugging Face evaluates models with 4 key benchmarks – AI2 Reasoning Challenge, HellaSwag, MMLU, and TruthfulQA.
Stanford HELM
Holistic Evaluation of Language Model (HELM) is a language evaluation framework developed by Standford’s Center for Research on Foundation Models. It evaluates language models on various scenarios, such as accuracy, bias, efficiency, and toxicity. Toxicity refers to the likelihood of a language model to generate text that is offensive, harmful, or discriminatory. This can include text that is racist, sexist, homophobic, or otherwise hateful. HELM rates and ranks models for each scenario based on their performance on different evaluation datasets.
Paper With Codes
Paper With Codes is a community-driven hub consolidating research papers, tools, and methods applicable to machine learning. It also ranks models for specific use cases and tasks. Each leaderboard consists of its respective evaluation method, criteria, and datasets.
Ground truth comparison
Another way to evaluate LLMs is to compare the model’s annotation against a ground truth dataset. Here, ML teams engage human labelers and domain experts to create a high-quality dataset that forms the ground truth. Then, they evaluate if the model can predict with reasonably good accuracy like human experts do when performing annotation tasks.
Quantitative evaluation
Evaluating an LLM with measurable metrics enables an objective oversight of the model’s performance. These are metrics that machine learning engineers commonly use to assess LLMs.
- Perplexity measures the model’s confidence in predicting new words.
- Bilingual Evaluation Understudy (BLEU) compares text generated in machine translation and evaluates their similarities.
- Recall-Oriented Understudy for Gissing Evaluation (ROUGE) evaluates an AI-generated summary based on its precision, recall, and F1 score. Recall is the fraction of words in the reference summary that are also in the AI-generated summary. The F1 score is a weighted harmonic mean of precision and recall.
- Diversity evaluates if the model-generated output is consistently unique.
- Cross-entropy loss evaluates a model’s performance in classification tasks by comparing its predictions with ground truth probability distribution.
Remember that a model’s score against these metrics might not reflect how it would fare in domain-specific labeling. For example, a model that performed remarkably well on AGNews might not repeat the feat when labeling medical records. So, testing the model on a small fraction of the dataset is essential before scaling it for the entire dataset.
Qualitative evaluation
Qualitative evaluation allows LM teams to observe a model’s behavior that couldn’t be scored against existing benchmarks. For example, you can evaluate if the language model exhibits creativity or bias, which might affect its reliability in annotation tasks. Due to its subjective nature, qualitative evaluation relies heavily on human reviewers and might be hard to scale.
Data Labeling Scenarios and Benchmarking
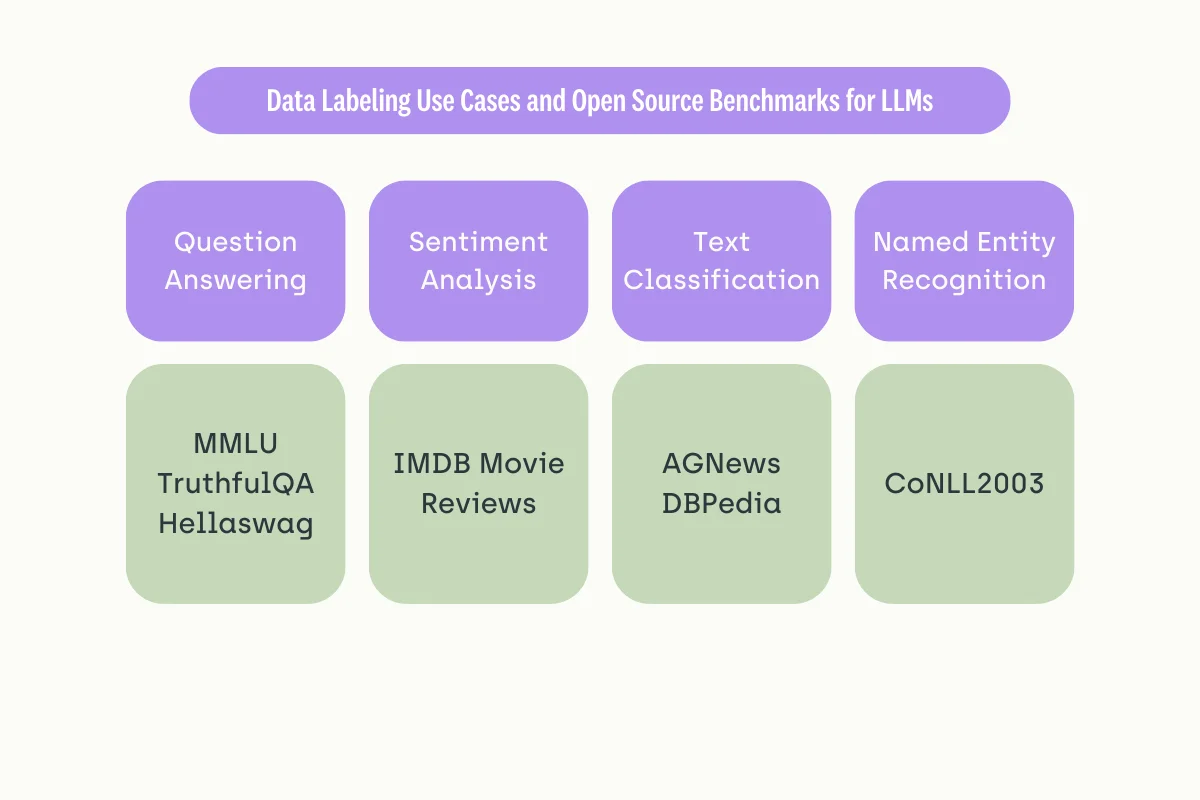
As mentioned, there is no perfect way to determine if a language model is suitable for data annotation. However, certain benchmarks reflect the model’s competencies in specific linguistic tasks. By referring to the evaluated scores, you can apply a model with strong confidence after fine-tuning them for annotation.
Question answering
Question-answering annotation enables a model to perform versatile conversational tasks like information retrieval, customer support, and interactive assessment. Models must demonstrate good reasoning abilities, domain understanding, and natural language understanding before they are deployed in real-life applications.
When annotating question-answering datasets, ML teams commonly use these benchmarks to assess a model’s base performance.
- MMLU (Massive Multitask Language Understanding) is a dataset curated to assess a model’s inferences accurately through zero-shot or few-shot learning. It consists of subjects spanning the science, technology, engineering, and mathematics spectrum with varying degrees of difficulty.
- TruthfulQA contains questions that assess a model’s truthfulness when answering questions. Within the datasets, there are questions humans would answer wrongly because of misconceptions or personal beliefs.
- HellaSwag compares language models with a dataset of multiple-choice questions to evaluate their common sense when inferencing. The model picks the answer that best predicts the next event to score well in this benchmark.
Sentiment analysis
Sentiment annotation requires labelers to classify the text of phrases as positive, negative, or neutral by assigning them a sentiment score. The annotated dataset helps NLP models extract and analyze opinions from news, feedback, conversation, and other sources. ML teams may use the IMDB Movie Reviews dataset to evaluate a model's performance in measuring sentiment.
IMDB dataset consists of over 50 thousand reviews with equal numbers of positive and negative labels. It allows ML teams to evaluate a model’s precision, recall, and F1 score in sentiment analysis tasks.
Text classification
Text classification involves annotating a sentence, phrase, or word with a specific label that broadly describes its category. The annotated dataset enables a language model to apply the contextual relationship it learns on unseen data. This is helpful in product categorization, document search queries, and survey analysis solutions.
These benchmarking datasets help ML teams evaluate a model for text classification.
- AGNews curates titles and descriptions of news articles covering the world, sports, business, and sci/tech of the AG corpus. It was curated by the data science community to support classification, ranking search, and other related NLP tasks.
- DBPedia is a structured collection of textual information derived from Wikipedia. Language models are benchmarked against DBPedia in several evaluation tasks. For example, they predict the topic of the given content and title from the extracted information.
Named Entity Recognition
Annotation for named entity recognition (NER) requires tagging specific textual entities, such as people’s names, buildings, countries, and dates. The model then learns from the annotated entity and identifies similar instances in real-world data. CoNLL2003 is a popular benchmarking dataset to evaluate a language model’s performance in NER.
CoNLL2003 is a NER dataset focusing on people, organizations, locations, and miscellaneous entities. It arranges news articles extracted from Reuters Corpus and Frankfurter Rundschau and organizes them in files for training and evaluating NER models.
Popular Open Source Large Language Models
Numerous large language models were published to fuel further research and development in the artificial intelligence space. Many of such models are downloadable from AI resource hubs like HuggingFace. However, not all open-source LLMs are licensed for commercial purposes nor tested on all aspects relevant to domain-specific annotation.
So, evaluate each model carefully before adopting and fine-tuning them for data labeling use cases. We share several popular LLMs that charted impressive scores in one or multiple benchmarks.
Falcon 40b
Falcon 40B is a large language model inspired by the GPT–3 architecture. It spots several variations, particularly including rotary positional embeddings, multi-query attention, and a two-layer MLP decoder block. The model was trained with multi-lingual corpora, enabling it to infer in different languages.
Since its launch, Falcon-40b has topped HuggingFace’s leaderboard and remains one of the top-performing LLMs. Its chat variant, Falcon-40B-instruct, charted a decent 84.3 in the common-sense reasoning benchmark, HellaSwag.
GPT-NeoX
GPT-NeoX is a 20-billion-transformer decoder model inspired by the GPT-3 architecture. Few variations, including rotary positional embeddings and parallel computation of the model’s layers, enable above-average reasoning and language understanding performance.
GPT-NeoX had a good score of 0.948 in Stanford Helm’s accuracy benchmark with the IMDB dataset for sentiment analysis evaluation. Also, the model topped WeightWatcher AI’s LLM leaderboard.
LLaMa 2
LLaMa 2 is Meta’s latest effort to compete with Google PaLM2 and OpenAI GPT-4. Like its predecessor, LLaMa 2 inherits the generative pre-trained transformer (GPT) architecture with several improvements. LLaMa 2 features a 4,096 context window, 40 billion parameters and is fine-tuned with 2 trillion tokens. A context window is a specified range of tokens surrounding a target token within a text or sequence. It is a core concept in NLP tasks, such as language modelling, word embeddings, and machine translation. The context window helps capture the contextual information of a target token by considering the neighbouring tokens. Meta AI also introduced LLaMa 2 Chat, a variant fine-tuned with 1 trillion human-annotated tokens.
Several variants of LLaMa 2 dominate the HuggingFace Open LLM leaderboard, posing impressive HellaSwag and TruthfulQA scores. Llama-2-70b-instruct-v2 topped the leaderboard with an average score of 73. The model was also evaluated by Paper With Code, ranking 2nd for question answering with TriviaQA in a chart dominated by PaLM.
MPT-30b
MPT-30b is MosaicML’s 30-billion-parameter language model that builds upon the success of MPT-7B. It uses Attention with Linear Biases to improve context understanding and FlashAttention to reduce training time. The model proves more powerful than GPT-3 despite having only 17% of the latter’s parameters.
MPT-30b excels at common sense reasoning, as evidenced by the high HellaSwag score charted on HuggingFace’s leaderboard. On the LMSYS.org leaderboard, MPT-30b’s chat variant ranks among the top LLMs.
OPT
Open Pre-trained Transformer (OPT) is a large language model featuring 125 million to 175 billion parameters. Released by Meta AI, OPT was trained with 180 billion tokens. The model is configurable to perform NLP tasks such as multi-label classification and question answering.
Stanford HELM rates OPT favorably in several information retrieval benchmarks, including efficiency, accuracy, robustness, and fairness. Multiple OPT variants were also benchmarked and ranked on Hugging Face’s Open LLM leaderboard.
Vicuna
Vicuna is a 13-billion-parameter large language model with conversational capability developed by LMSYS. The model was trained with chat data from ShareGPT, enabling it to rival models like ChatGPT and Bard. Based on the LlaMa architecture, Vicuna features a larger 2,048 context window and memory optimization measures. A 33-billion-parameter version of the model was recently released.
Vicuna performed strongly in LMYS’s leaderboard, charting commendable performance against proprietary models like GPT-4. The model also showed strong alignment with human values on the InstructEval leaderboard.
Fine-tuning LLMs for your Data Labeling Needs
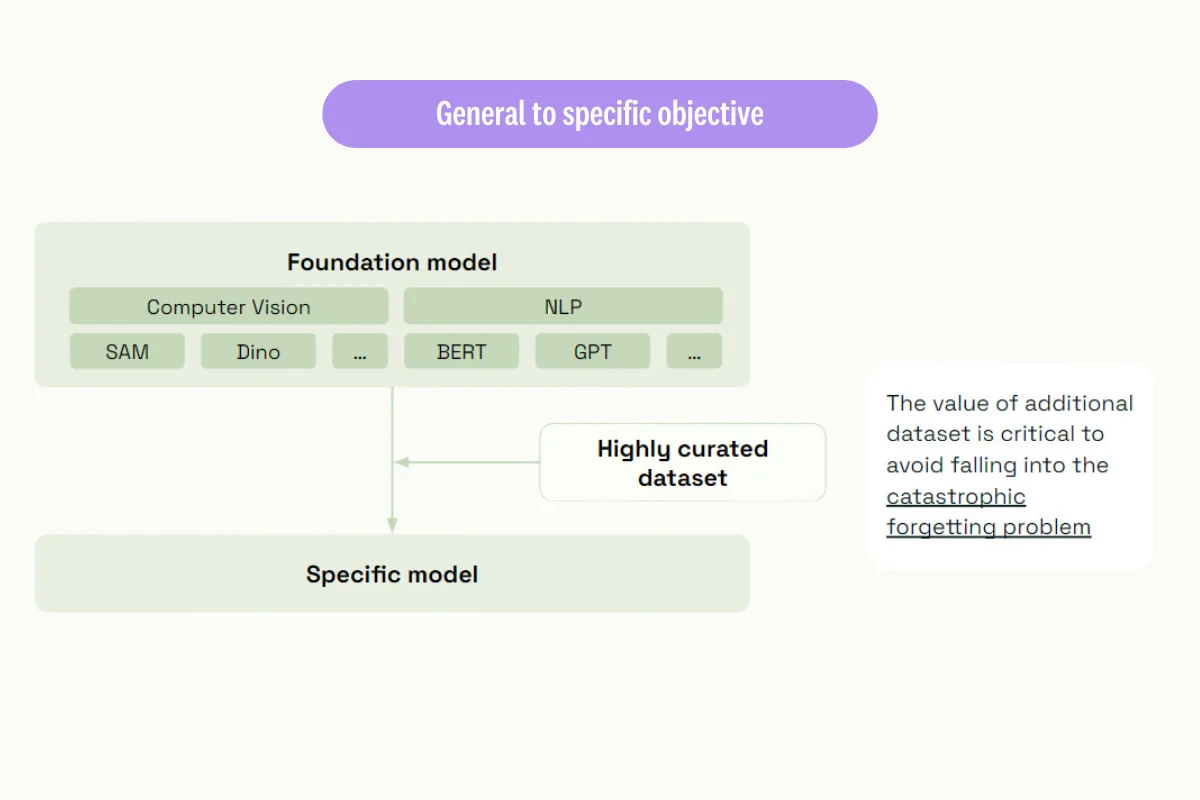
Data labeling requirements differ according to the application. Some teams require a model capable of annotating legal documents with different categories, while others might train a model for sentiment annotation. Regardless of your annotation needs, these steps will help you fine-tune a language model for specific annotation tasks.
1. Choose a pre-trained language model
Large language models can easily understand human language as they have been trained with large linguistic corpora. Start by choosing a pre-trained model with relatively decent performance on well-known benchmarks. Also, consider if it’s a good fit for the annotation task it was meant for.
2. Prepare the datasets
To fine-tune a language model for annotation tasks, you must prepare human-annotated datasets for it to learn from. Divide the annotated datasets into training and validation sets. When doing so, be mindful of the dataset’s size and diversity to ensure the model can generalize well with real-world data. Provide clear instructions to ensure that your labeling workforce can annotate smoothly. Also, ensure that the datasets are converted into formats the model supports.
3. Fine-tune the LLM
Use the training dataset to fine-tune the LLM. This might involve transfer learning, which freezes the model’s hidden layer and trains a new layer added to the top with the annotation-specific dataset. Or you can use other methods we share in this guide. The new layer will learn new information about the task, while the LLM's hidden layer will retain its pre-trained knowledge.
4. Evaluate the LLM’s performance
Compare the LLM’s performance with the valuation dataset. If the model performs short of expectations, you might need to try different weights, learning rates, and other parameter adjustments until it achieves satisfactory results. Remember that fine-tuning an LLM is an iterative process.
5. Annotate with the LLM
Once trained, you can use the LLM to annotate other similar datasets. The LLM now augments human labelers by automating the labeling process. This improves labeling efficiency, reduces mistakes, and frees up annotation resources for more complex tasks.
Kili Technology allows ML teams to use ChatGPT to augment their labeling workforce. As a large language model, ChatGPT performs exceptionally well in natural language processing tasks, providing ideal support for human labelers. We integrate ChatGPT with our data labeling software to automate annotation for text classification and named entity recognition (NER) tasks.
The best tool for building fine-tuning datasets
Build smarter LLMs for your domain-specific needs. Learn how our tool can help you build the best dataset for fine-tuning LLMs.
Conclusion
The emergence of large language models unveils new possibilities in automating data labeling tasks. LLMs are trained with large corpora, giving them innate capabilities to annotate datasets for question answering, sentiment analysis, and other labeling tasks. However, the AI community lacks common standards to determine which LLM is the best candidate for data labeling.
We’ve shared descriptions of several popular open-source LLMs that might prove helpful to your data labeling projects. They were evaluated and ranked according to accuracy, reasoning, truthfulness, and other benchmarks. More than that we’ve discussed challenges in evaluating LLMs as well as provided you with a list of current practices the ML community is using for evaluating LLMs. We’ve also described the steps ML teams follow to train a language model for annotation tasks. Hopefully, our guide helps you to build your own annotation-capable language model.
Additional Reading
Understanding LLM Hallucinations and how to mitigate them
Webinar Recap: Evaluating Large Language Models (LLMs) Using Kili Technology
Data Labeling and Large Language Models Training: A Deep Dive
Using Meta's Llama 2 for Data Labeling Tasks
Using Falcon-40B to build high quality training datasets
How to fine-tune large language models (LLMs) with Kili Technology
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

