
.png)


_logo%201.svg)


AI Summary
- Data labeling has shifted from pre-training preparation to post-training refinement, preference tuning, and continuous production oversight.
- Supervised fine-tuning, reward modeling, and reinforcement learning each depend on expert-labeled data to steer LLM behavior reliably.
- The highest-leverage labels are expert labels because they encode tacit domain judgment that raw text cannot provide.
- LLMs can accelerate labeling through pre-annotation, but human validation remains essential to catch confidence-correctness gaps.
- Modern evaluation stacks combine automated checks, LLM-as-a-judge screening, and targeted human review for high-impact cases.
- Kili Technology provides the collaborative platform and managed labeling services to build production-ready LLM datasets from first annotation to final evaluation.
For those not well-versed in machine learning, large language models like GPT-3.5 (which ChatGPT is based on) can look self-sufficient. These models are trained with unsupervised or self-supervised learning. Simply put, it requires minimal manual intervention to produce a model capable of conversing like humans.
This begs the question – is data labeling still relevant for large language models?
It's unwise for machine learning teams, project managers, and organizations to dismiss the importance of data labeling. On the surface, large language models (LLMs) seem capable of taking on any task, but reality paints a different picture.
In this article, we'll explore the mutually beneficial relationship between data labeling and large language models—and what has changed since 2024 as enterprises adopt agentic workflows, stricter oversight expectations, and production-grade evaluation.
What is data labeling?
Data labeling (or data annotation) is a process of identifying, describing, and classifying specific elements in raw data to train machine learning models. The labeled data then serve as a ground truth for the foundational model to process, predict, and respond to real-life data.
For example, a document imaging system needs to identify personally identifiable information in raw data. To do that, labelers annotate the name, ID, and contact details on a training sample. Then, machine learning engineers train the model with the dataset to enable entity recognition and extract personal details from stored documents.
Data labeling seems straightforward, but various parameters affect annotation outcomes and model performance: label definitions, edge cases, reviewer consistency, sampling strategy, and how the labeled data is used downstream. Accurate labeling reduces hallucinations and increases accuracy in model performance metrics such as F1 scores—which is why the data labeling process demands precision at every stage.
Data labeling use cases
Data labeling has been pivotal in training machine learning models long before the emergence of LLMs or generative AI. For example:
- Natural language processing (NLP): ML engineers label data to support NLP tasks such as named entity recognition, translation, text classification, and sentiment analysis.
- Computer vision: Annotation is helpful in training image recognition systems to detect and classify objects across multiple categories.
- Healthcare: Healthcare systems train neural networks with annotated data to diagnose diseases from imaging data, where human expertise is essential to validate results.
- Finance: The finance industry trains ML models with diverse datasets to perform fraud detection and credit scoring—tasks where data privacy and accuracy are non-negotiable.
- Autonomous vehicles: Self-driving cars depend on accurate datasets to train models capable of analyzing multiple sensor data in real-time.
What's new in 2026
What's new in 2026 is not the existence of labeling—it's where it shows up in the lifecycle:
- Post-training (instruction tuning + preference tuning) is where labeled data becomes the steering wheel. Supervised fine-tuning requires high-quality, task-specific examples that guide the model toward a desired output.
- Evaluation has become continuous (not a one-time benchmark) because production failure modes are different from lab failure modes. Regular evaluation of labeled data against benchmarks is necessary to maintain quality and accuracy.
- Human oversight is now a design choice (HITL vs HOTL vs LLM-as-a-judge) rather than a generic "add a reviewer." Labeling is an ongoing process requiring specialized, trained personnel to avoid low-quality data issues.
What are Large Language Models?
Large language models (LLMs) are linguistic neural network models trained with massive amounts of text data. They are mostly based on the transformer architecture.
LLMs can converse with users and construct answers in natural languages. However, their intelligence comes at a steep cost: large training corpora, expensive compute, and complex post-training pipelines.
Most importantly, LLMs inherit their behavior from the distribution of their training data—and that distribution rarely matches your domain, your policy constraints, your tone, or your risk tolerance. LLMs achieve stronger accuracy and consistency in downstream tasks by learning complex patterns from large datasets, surpassing what traditional rule-based systems can deliver. Yet that capability is only as reliable as the data quality underpinning it.
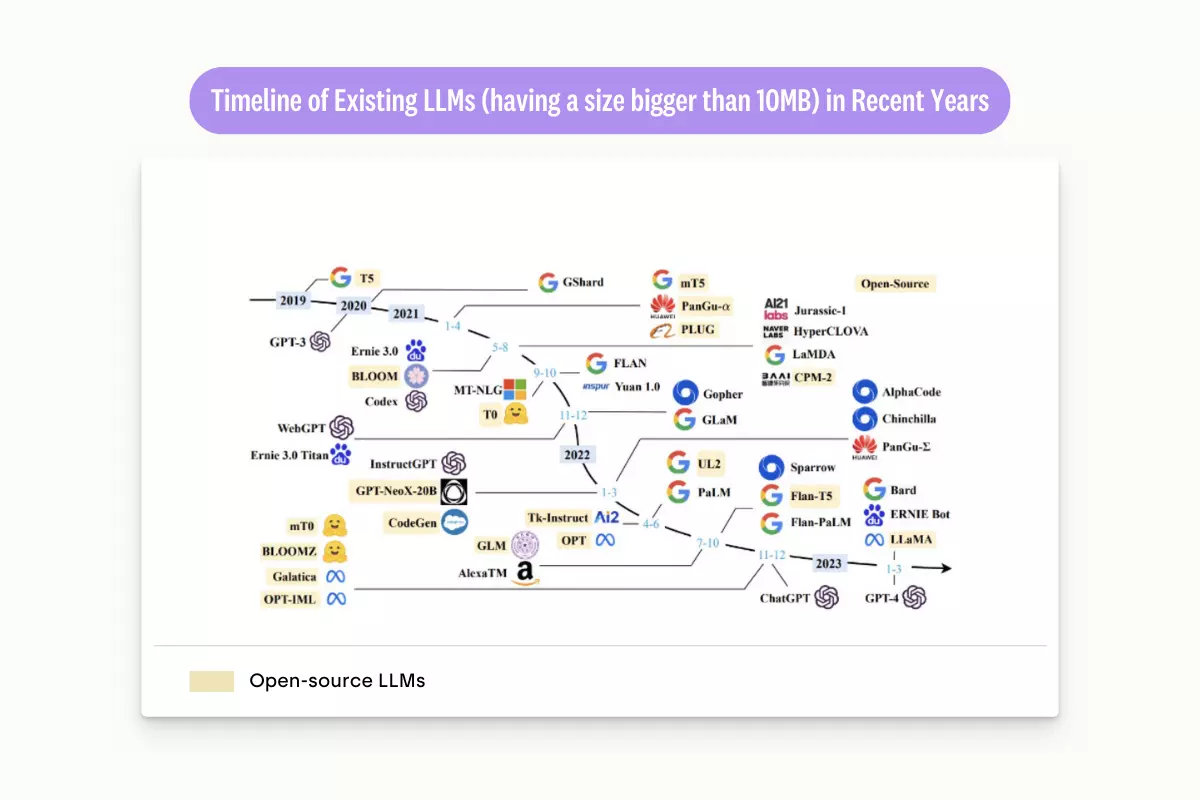
How are Large Language Models Trained?
Before we move further, let’s look at how machine learning engineers train LLMs like GPT-3.
Preparation and preprocessing
First, data scientists curate large amounts of raw textual data from various sources, including the internet, books, and public datasets. Then, teams clean the data to reduce noise and remove obvious issues. Data should be cleaned and preprocessed to remove noise and inconsistencies before labeling—this step is fundamental to building a high-quality training dataset.
This is followed by converting raw data into formats the model understands with preprocessing steps like tokenization. Tokenization turns text into smaller units consisting of words or subwords.
What's changed in recent LLM programs: preprocessing is increasingly treated as a data engineering system, not a one-off script. Teams care about:
- Coverage across domains and languages (to reduce blind spots in the entire dataset)
- Deduplication (to reduce memorization and evaluation leakage)
- Quality filtering (to reduce garbage-in / garbage-out)
- Documentation of dataset lineage (to support audits and debugging)
Training and optimization
Large language models use objectives like next-token prediction or masked language modeling to develop a statistical understanding of language.
This process is iterative: the model compares its output with the target signal, measures loss, updates parameters, and repeats until performance stabilizes. LLMs offer meaningful scalability advantages, efficiently handling large datasets and maintaining performance across varying volumes of data throughout this training cycle.
Model evaluation and continued training
Finally, the model undergoes evaluation testing. Depending on the result, teams might adjust training settings or proceed to continued training (often called "post-training") for specific purposes.
This last step is where labeled data becomes central.
The Significance of Data Labeling in Training Large Language Models
Theoretically, large language models can become useful without labeled data. Self-supervised learning enables them to develop broad linguistic competence.
But LLMs are imperfect and often unsuitable for practical applications out of the box:
- A general-purpose model cannot reliably perform specialized or business-specific labeling tasks.
- LLMs are prone to bias and inconsistency, especially in ambiguous or high-stakes contexts.
- Pre-trained models can respond with outdated information, made-up facts, or policy violations without additional alignment and guardrails. Inaccurate labels can lead to hallucinations and unreliable outputs in LLMs.
Generally, LLMs are dependent on the datasets they're trained on and their ability to self-supervise. Unfortunately, there are gaps between desired output and real-world performance—which brings data labeling into play.
Below, we share how the annotation process benefits an LLM's overall performance, correctness, and practicality.

Pre-training (indirectly)
While large language models don't use annotated data directly during pre-training, humans still matter. Human annotators, reviewers, and domain specialists influence what makes it into the corpus (and what gets filtered out). That matters because pre-training sets the default behavior the model will later be asked to unlearn.
In practice, pre-training data work is about preventing avoidable failures:
- Removing low-quality, duplicated, or misleading text data
- Balancing coverage so niche domains aren't dominated by internet noise
- Reducing contamination risks for evaluation and downstream tasks
Fine-tuning (where labeled data becomes the steering wheel)
Data annotation is critical to tailoring large language models for specific applications. This is where organizations can fine-tune LLMs to serve domain-specific data requirements and produce practical applications that align with business objectives.
In 2026, "fine-tuning" usually includes multiple dataset types:
- Instruction tuning (supervised fine-tuning): Prompts paired with ideal responses. Supervised fine-tuning (SFT) involves creating high-quality, task-specific examples for LLMs and is essential for specialized training.
- Preference datasets: Multiple candidate answers ranked by human annotators against a rubric.
- Corrections and edits: Experts revise model outputs; those edits become high-value training signals.
- Tool and agent traces: Step-by-step trajectories that show how to use additional tools (and when to stop).
A key point for enterprise teams: the highest leverage labels are often expert labels—because they encode tacit judgment that is hard to scrape from raw text. Human labelers play an essential role in curating and cleaning datasets, which improves the reliability of LLMs.
Model evaluation (no longer just benchmarks)
Annotated data provides a ground truth for evaluating the performance of LLMs, allowing for comparisons of metrics like precision and recall.
But evaluation has shifted from "one benchmark score" to a more realistic question:
Is this output acceptable to act on in this context, with these constraints, and with this level of risk?
That's why modern evaluation looks like a stack:
- Automated checks for formatting, citations, and policy rules
- LLM-as-a-judge for fast, rubric-based screening
- Targeted human review for the ambiguous, high-impact cases
Quality assurance (QA) processes are critical to ensure the accuracy and consistency of labeled data. The labeling process should include validation steps to confirm the accuracy of the annotations required at each stage.
Context understanding (and long-context reality)
Many LLM failures are not about grammar—they are about context discipline: what to use, what to ignore, and what to cite.
Annotation helps here too:
- Labeling what counts as "in scope" vs "out of scope" so models can identify the right information
- Building datasets that reward grounding and citation behavior
- Creating counterexamples where the model must refuse, ask clarifying questions, or defer to a human
Three steps to fine-tune LLMs using data labeling: ChatGPT’s example
A pre-trained GPT model can string sentences together coherently but requires further refinement to fit specific purposes. ChatGPT was fine-tuned using reinforcement learning from human feedback (RLHF) to improve alignment.
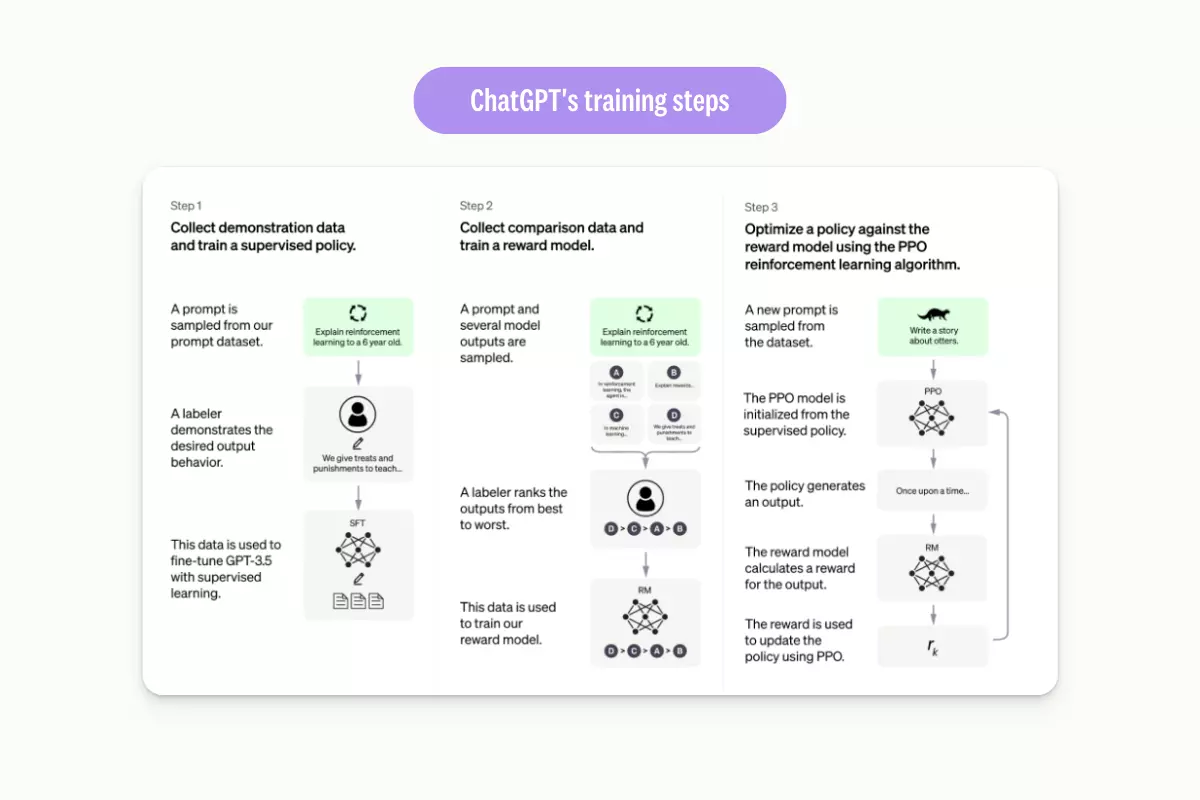
To fine-tune ChatGPT, OpenAI’s engineers went through these steps.
To fine-tune ChatGPT, OpenAI's engineers broadly went through these steps.
Step 1: Supervised fine-tuning (SFT)
SFT involves a team of human annotators creating a set of prompts and expected outputs. Engineers train the foundation model with these prompt-output pairs.
SFT is powerful, but it is also expensive and hard to scale if your labeling strategy is "write everything from scratch." In practice, teams typically focus SFT on:
- Core behaviors (tone, refusal style, citation expectations)
- Domain formats (contracts, medical notes, incident reports)
- Edge cases that matter disproportionately in production
Creating clear guidelines and standards for annotators helps reduce variability in the labeling process—a principle that applies directly to building SFT datasets.
Step 2: Reward model (preference data)
The reward model overcomes SFT's scalability limits. Instead of creating all answers manually, engineers use the SFT model to generate several candidate answers. Then annotators rank those answers according to a rubric.
This is where labeling quality becomes more important than labeling volume:
- Do reviewers share a definition of "best"?
- Are they trained on edge cases?
- Is there adjudication for disagreements?
- Are rubrics updated as failures are discovered?
Best practices for LLM data labeling include establishing clear guidelines and employing multiple annotators for consistency checks. Quality assurance measures in data labeling—such as inter-annotator agreement and random auditing of labeled data—are what keep the reward signal clean.
Step 3: Reinforcement learning (e.g., PPO)
In the final stage, engineers create a reinforcement learning mechanism that optimizes the model against the reward signal.
One practical way to think about this: RL is a data labeling problem with expensive labels. If the reward signal is noisy or inconsistent, the model learns the wrong lesson.
What's new in 2026: from "labeling data" to "running oversight"
The biggest shift since this article was first published is that many teams are no longer using LLMs as standalone chatbots. They are building layered applications: retrieval-augmented generation (RAG), tool-using agents, and workflow automation.
This changes the labeling problem.
Instead of only labeling "final answers," teams increasingly label:
- Whether the system used the right sources
- Whether it followed a policy / checklist
- Whether it stopped at the right time
- Whether it escalated to a human when uncertain
Two common layered use cases where HITL is most prominent
1. Document intelligence for regulated workflows (HITL approval gate)
Example: contract review, compliance screening, claims processing, or due diligence.
- The model drafts a summary or extracts key fields.
- An expert reviews and approves (or corrects) the output.
- Corrections become labeled data for improving extraction, reasoning, and formatting.
This is a classic Human-in-the-Loop pattern: outputs do not "count" until a human signs off.
2. Security and operations triage (HOTL + selective HITL)
Example: SOC alert triage, fraud investigations, or incident response support.
- The system runs with partial autonomy and classifies or routes cases.
- Humans supervise via alerts and audits (HOTL).
- High-risk or low-confidence cases are escalated for expert review (HITL).
This hybrid structure keeps humans focused on the decisions where they add the most value.
Automating Data Labeling with LLMs
ChatGPT’s use of data labeling highlights the latter’s importance in aligning LLMs for practical purposes. On the same note, it also shows that LLMs can help scale labeling tasks.
Companies are under cost and resource pressure to create large and accurate datasets for increasingly complex deep learning systems. Using LLMs for data labeling can lead to significant time and cost savings for organizations. By enabling ML-assisted labeling, they can improve throughput while keeping humans focused on review and edge cases.
LLMs can perform certain manual labeling tasks without lengthy preparation due to their zero-shot or few-shot learning capabilities—but that speed advantage must be paired with human validation.
How machine learning can help automate data labeling
LLMs are capable of comprehending natural language, structuring data, supporting active learning, and generating synthetic data.
In practice, LLM-assisted labeling works best when you treat the model as a draft generator, not an authority:
- Use the LLM to propose labels or spans.
- Route uncertain cases to human experts.
- Sample "high confidence" cases for audit (because confidence is not correctness).
- Track error patterns and update guidelines.
Using active learning algorithms can optimize the workload for human annotators by identifying data points that need attention, making the entire labeling process more efficient.
Tools and techniques for automating data labeling
You can leverage LLMs to assist in pre-annotation tasks. For example, in a named entity recognition (NER) workflow, the model can be asked to return specific entities in a JSON structure that is imported into your labeling tool.
LLM-assisted labeling becomes more reliable when you add lightweight checks:
- Schema validation (does the output match the expected format?)
- Constraint checks (are labels mutually consistent?)
- Reference checks (does the output cite the right evidence?)
LLMs continuously improve their performance by updating with new data and feedback, ensuring they remain effective over time. Many data labeling platforms offer AI-assisted prelabeling to create initial labels and identify important words and phrases, reducing manual effort while maintaining accuracy.

This enables a gapless integration of LLM with an existing automated labeling pipeline. For example, we demonstrate how to apply named entity recognition tags on the CoNLL2003 dataset with GPT and export the pre-annotated data to Kili Technology in this guide.
Human-in-the-loop, human-on-the-loop, and LLM-as-a-judge: how they fit together
Modern LLM products need oversight. The question is not whether you need humans—it's where you place them.
- Human-in-the-loop (HITL): Humans approve or correct outputs before they count.
- Human-on-the-loop (HOTL): Humans supervise a mostly automated system and intervene when needed.
- LLM-as-a-judge: An LLM scores or ranks outputs against a rubric to scale evaluation and triage.
A practical evaluation stack often combines all three:
- LLM-as-a-judge screens large volumes and flags uncertainty.
- HOTL audits the system through sampling and monitoring.
- HITL handles the high-risk outputs and produces the highest value labels (corrections, adjudications, gold standards).
Using Kili Technology to label data with LLMs and Foundation Models
Kili Technology is the collaborative AI data platform where industry leaders build expert AI data. Unlike traditional data labeling tools built solely for ML engineers, Kili empowers cross-functional teams to work together autonomously—from initial labeling through validation and iteration—ensuring AI models are built on domain expertise, not just technical assumptions.
For teams building LLM datasets specifically (instruction tuning, preference data, and RLHF-style datasets), Kili provides configurable ontologies and review workflows designed around:
- Prompt + response labeling for supervised fine-tuning
- Ranking and comparison for preference-based training
- Correction and rewriting where experts revise model outputs directly
- Adjudication for disagreements using consensus metrics and multi-step review workflows
Kili Technology supports collaboration, quality control, and security for data annotation processes—all within a secure, auditable environment that satisfies organizations in healthcare, defense, financial services, and manufacturing.
Collaboration at scale
Traditional AI development treats domain expertise as a final checkpoint—something to validate after the model is built. Kili flips this model. The platform enables radiologists, underwriters, quality engineers, and other subject matter experts to shape AI from the first annotation, embedding their expertise directly into training data. The result? Models that understand your domain from the ground up, not through post-hoc corrections.
Uncompromised speed and quality
Speed without quality is just fast failure. Kili delivers both by embedding domain validation throughout the development lifecycle, not as an afterthought. When experts validate early and often, you eliminate the costly iteration cycles that plague traditional approaches—achieving up to 30% faster delivery without sacrificing data quality.
Enterprise-grade security and flexibility
When data is too sensitive for the cloud—whether in banking, insurance, or defense—Kili delivers on-premise deployment options, complete audit trails, and security standards that satisfy the world's most demanding organizations. The platform integrates with Amazon, Google, and Microsoft cloud storage, and connects with any ML stack through its Python SDK and GraphQL API for seamless integration.
Data labeling platforms can help manage the quality and consistency of labeled data through validation and quality assurance processes. Kili's platform exports labeled data in various formats, such as JSON, CSV, or TSV, for further use in model training—providing the flexibility organizations need to optimize their workflows.
Production-ready data, delivered: Kili's labeling services
For enterprises that need end-to-end support beyond the platform, Kili's data labeling services deliver production-ready datasets built to the highest standards. From niche domain experts to enterprise-scale project management, Kili handles the entire data pipeline from kickoff to delivery.
Kili's services are designed for organizations working on frontier model training, multilingual post-training, domain-specific fine-tuning, and model evaluation—all powered by:
- Specialized talent networks: Access to domain experts that traditional providers can't source—from Lean 4 theorem provers and math olympiad champions to native linguists across 40+ languages. Every expert is rigorously tested before joining a project, ensuring the people behind your data bring the depth of knowledge your model requires.
- Data science-led project management: Every project is orchestrated by experienced ML engineers and data scientists who understand technical requirements. Dedicated project managers handle workforce coordination, quality workflows, and iteration cycles so your team can focus on model development.
- Quality at scale without tradeoffs: Traditional providers force a choice between speed and quality. Kili eliminates that tradeoff with comprehensive data quality workflows and curation methodology built for GenAI. Multi-step validation processes and inter-annotator agreement metrics ensure every dataset meets specifications.
- Custom AI evaluation frameworks: Move beyond generic benchmarks. Kili builds evaluation datasets tailored to specific business objectives—combining domain expertise with automated testing to measure what actually matters for your model.
Commercial data labeling platforms like Kili offer comprehensive AI-assisted prelabeling, project management tools, and analytics dashboards—bringing together the capabilities that data scientists need to ship reliable models faster.
Transparency and auditability
AI model failures often trace back to data quality issues—but without documentation, you can't diagnose them. Kili provides complete traceability for every data decision: who labeled each asset, who reviewed it, what consensus was reached, and how quality evolved over time. When a model behaves unexpectedly in production, you can trace it back to the training data and understand whether the issue was labeling inconsistency, reviewer disagreement, or insufficient domain expert involvement.
Wrapping Up
The emergence of large language models has shifted data labeling's traditional role in supervised machine learning.
While LLMs can train on massive unlabeled datasets, humans remain central—but concentrated at high-leverage points:
- Defining rubrics and acceptable behavior
- Producing expert corrections
- Adjudicating ambiguity
- Monitoring production drift and updating gold standards
At the same time, LLMs can help scale labeling by generating drafts and pre-annotations—as long as humans remain responsible for correctness. Future LLMs are expected to further enhance adaptability, enabling them to handle a wider range of data types including text, images, and audio—while upcoming advancements will continue to focus on reducing inherent biases in models. Personalized learning models for LLMs are also expected to become more prevalent, allowing them to adapt to specific industry needs, and more diverse and comprehensive datasets will become available to further improve training data quality.
For enterprises ready to build production-ready AI systems with expert-level data, Kili Technology provides the collaborative platform and professional services to make it happen—from first annotation to final evaluation.
References
https://www.assemblyai.com/blog/how-chatgpt-actually-works/
https://openai.com/blog/chatgpt
https://huggingface.co/learn/nlp-course/chapter1/4
https://lambdalabs.com/blog/demystifying-gpt-3
https://smartdesignworldwide.com/ideas/train-gpt-on-proprietary-data-for-business/
https://huggingface.co/blog/rlhf
https://bdtechtalks.com/2023/01/16/what-is-rlhf/
FAQ on data labeling and LLMs
Data labeling for large language models: what is it?
In the context of LLMs, data labeling often applies to post-training (instruction tuning, preference tuning, and evaluation). Teams use labeled data to refine behavior and align the model for a specific purpose. The annotation process encompasses everything from defining label categories to conducting quality checks on the entire dataset.
Zero-shot learning with large language models: what is it, and how to do it?
Zero-shot learning is an LLM's ability to make useful predictions when exposed to tasks it has never seen explicitly labeled examples for. LLMs can perform certain labeling tasks without lengthy preparation due to their zero-shot or few-shot learning capabilities. In practice, high-quality training data and strong post-training help models generalize more reliably—especially in domains with strict formats and risk constraints.
How does ChatGPT work?
ChatGPT is a transformer-based assistant trained on large-scale text, then post-trained to improve usefulness and safety through supervised fine-tuning and human preference signals (often described as RLHF-style training).
How can organizations optimize the data labeling process for LLMs?
Organizations can optimize their labeling process by combining ML-assisted labeling with expert human review, using active learning to focus annotators on the most impactful data points, and deploying platforms like Kili Technology that enable seamless integration between data scientists, domain experts, and automated quality checks. The potential new applications of LLMs in data labeling include cross-domain labeling and real-time data annotation, which will further expand the capabilities available to users.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
