
.png)


_logo%201.svg)


AI Summary
Large Language Models (LLMs) like GPT-3 have emerged as groundbreaking tools capable of generating human-like text. However, deploying these models in real-world applications often requires a crucial step: fine-tuning. This blog post delves into the essence of fine-tuning LLMs, drawing insights from a recent webinar and presentation on the subject.
Build your own GPT
LLMs perform best when they are fine-tuned on your data. We can optimize and simplify your data labeling ops through our platform and services. See for yourself!
Book a Demo
Why Fine-Tuning is Essential
LLMs are incredibly versatile at their core, but this versatility can be a double-edged sword. While they can generate creative and diverse content, they often lack the domain-specific knowledge needed in business applications and can produce inconsistent or inaccurate results. Fine-tuning addresses these issues by tailoring the model to specific tasks, languages, or tones, enhancing their relevance and accuracy in specific contexts.
Supervised Fine-tuning (SFT) and Retrieval-Augmented Generation (RAG)
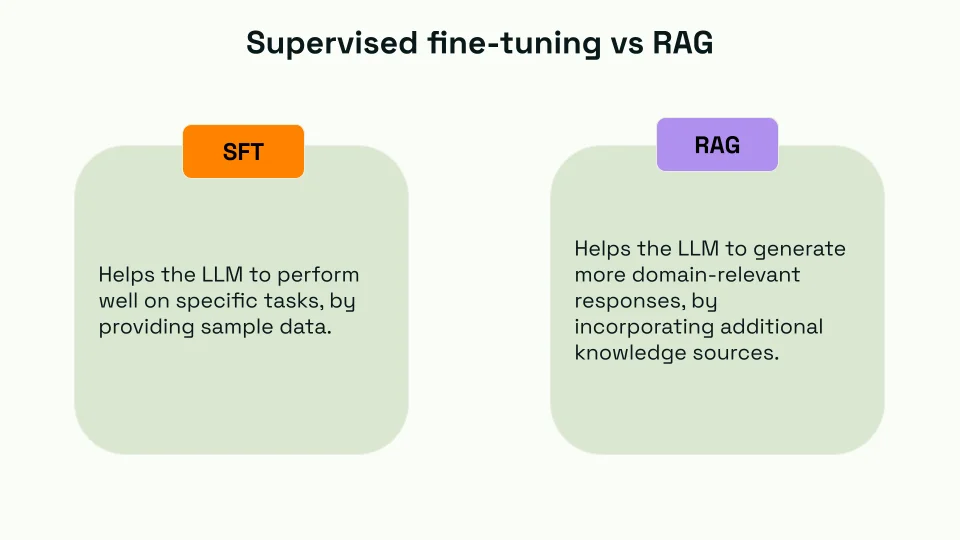
In the webinar, we highlighted two pivotal methods of fine-tuning LLMs: Supervised Fine-Tuning (SFT) and Retrieval-Augmented Generation (RAG). These approaches, each with unique strengths and applications, are critical in refining LLMs for specialized tasks and domains.
What is SFT?
- Definition: SFT involves training an LLM on a specific, labeled dataset. This dataset is tailored to the task or domain for which the model is optimized.
- Application: SFT is particularly effective when the goal is to enhance the model's performance on a specific type of task, such as sentiment analysis, specific domain question answering, or text classification.
What is RAG?
- Definition: RAG is a technique where the LLM is augmented with an external knowledge retrieval step. This allows the model to dynamically pull in relevant information from a database or a set of documents.
- Application: RAG is helpful in scenarios where the model must incorporate and reference external, up-to-date information, like answering fact-based questions or incorporating recent data.
How SFT and RAG work together
While SFT and RAG are distinct approaches, they can be complementary. SFT can fine-tune the LLM for a specific task, while RAG can augment this by accessing and integrating external, current information.
In practice, a model might be fine-tuned for a particular domain and then use RAG to enhance its responses with the latest information or data from external sources. This combination allows the model to be both specialized and informative.
When is fine-tuning an LLM beneficial?
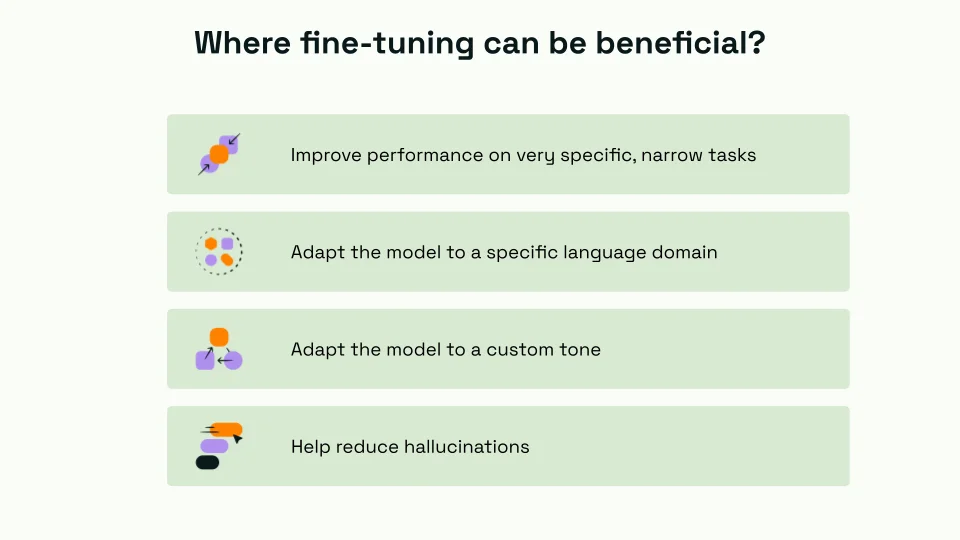
Fine-tuning can be advantageous in the following ways:
- Improving Performance on Very Specific, Narrow Tasks: Fine-tuning allows LLMs to excel in specialized tasks. Fine-tuning sharpens the model's ability to handle such narrow tasks with higher accuracy and relevance, whether analyzing legal documents, writing code, or creating specific types of content.
- Adapting the Model to a Specific Language Domain: Different fields have unique terminologies and ways of expression. Fine-tuning LLMs for a specific language domain, like medical, legal, or technical language, enables the model to understand and generate text that aligns accurately with the nuances of these domains.
- Helping Reduce Hallucinations: Hallucinations – instances where LLMs generate incorrect or nonsensical information – are a significant challenge. Fine-tuning helps mitigate this by training the model on high-quality, accurate data, reducing the likelihood of such errors.
- Building a Domain-Specific LLM: For industries requiring deep domain expertise, like finance or law, fine-tuning creates LLMs that are not just generalists but specialists. These domain-specific models are more adept at handling industry-specific queries and tasks.
- Building a Custom Tone for Chatbot Applications: In chatbot applications, the way responses are framed is as important as the accuracy of the information provided. Fine-tuning enables the creation of chatbots with a custom tone that resonates with the intended audience, enhancing user engagement and satisfaction.
- Translations of Specific Text: When dealing with translations, context and nuances matter. Fine-tuning LLMs for translation tasks ensures that they can handle not just the language conversion but also respect the cultural and contextual nuances of the text, leading to more accurate and appropriate translations.
Fine-tuning LLMs is a transformative process that significantly enhances their utility and effectiveness. By tailoring these models to specific tasks, domains, tones, and languages, fine-tuning ensures that LLMs are more accurate and reliable, and more aligned with their applications' specific needs and objectives.
The challenges of fine-tuning an LLM
Fine-tuning Large Language Models (LLMs) is a complex process fraught with several challenges. These challenges can significantly impact the fine-tuned model's effectiveness when not adequately addressed. Let’s explore these challenges:
- Datasets Must Be Task-Relevant and Diverse: One of the primary challenges in fine-tuning LLMs is the need for high-quality, relevant, and diverse datasets. The dataset used for fine-tuning must closely align with the specific task or domain the model is being trained for. Additionally, it must be sufficiently diverse to cover the various scenarios and nuances the model might encounter. This requires a large volume of data and varied and comprehensive data, ensuring the model can handle a wide range of inputs effectively.
- Subject Matter Expertise Is Usually Required: Fine-tuning a model for specific domains often necessitates a deep understanding of that domain. Subject matter experts are crucial in guiding the fine-tuning process, from selecting and preparing the correct training data to evaluating the model's outputs. Their insights ensure the model accurately reflects the domain's complexities and subtleties. However, accessing such expertise can be challenging, especially in more niche or specialized fields.
- Ambiguous Tasks Make Labeling Hard: Labeling data for fine-tuning can be particularly challenging when tasks are ambiguous or subjective. This ambiguity can lead to inconsistencies in training data, affecting the model's learning process. Moreover, evaluating the performance of an LLM post-fine-tuning is not straightforward. It often involves subjective judgments, especially when assessing the model's ability to handle nuanced or context-dependent tasks. The evaluation process must consider multiple dimensions – accuracy, relevancy, tone, and style – making it a complex and multifaceted challenge.
Key Principles for Collecting High-Quality Datasets in LLM Fine-Tuning

The success of fine-tuning Large Language Models (LLMs) heavily depends on the datasets' quality. These principles are fundamental to ensuring that the fine-tuning process yields an accurate, reliable, and effective model in its designated tasks.
- Iterative Process with Human-in-the-Loop: One of the most effective strategies in dataset collection is adopting an iterative process that incorporates a human-in-the-loop approach. This involves continuously evaluating the model's responses and iteratively adjusting the training data to address any shortcomings or errors identified. By actively involving human judgment in the loop, the model's learning and response quality can be significantly enhanced. This human involvement is crucial in identifying nuances and subtleties the model might miss or misinterpret.
- Leveraging Human Expertise When Needed: The role of subject matter experts cannot be overstated in the dataset collection process. Their expertise is vital in ensuring that the data is relevant, diverse, accurate, and representative of real-world scenarios. Experts can provide valuable insights into the subtleties of the domain, helping to refine the dataset to ensure it covers a broad spectrum of realistic and relevant scenarios and includes correct and nuanced responses.
- Quality-First Team Organization and Workflow: The organizational structure and workflow of the team responsible for dataset collection and model training should be oriented towards a 'quality-first' approach. This means prioritizing the integrity and relevance of the data over mere quantity. It involves establishing rigorous standards for data selection and validation and a workflow that facilitates continuous quality checks and balances. A quality-first approach ensures that the dataset is not just large but is also a true reflection of the quality and diversity needed to train an effective LLM.
In conclusion, collecting high-quality datasets for fine-tuning LLMs is a nuanced and multifaceted task. It requires a careful balance of technology and human expertise, emphasizing quality at every step. By adhering to these principles, organizations can ensure that their fine-tuned LLMs are well-equipped to handle the complexities and challenges of their intended applications.
Fine-Tuning Workflow: Combining Model Distillation and Human Review
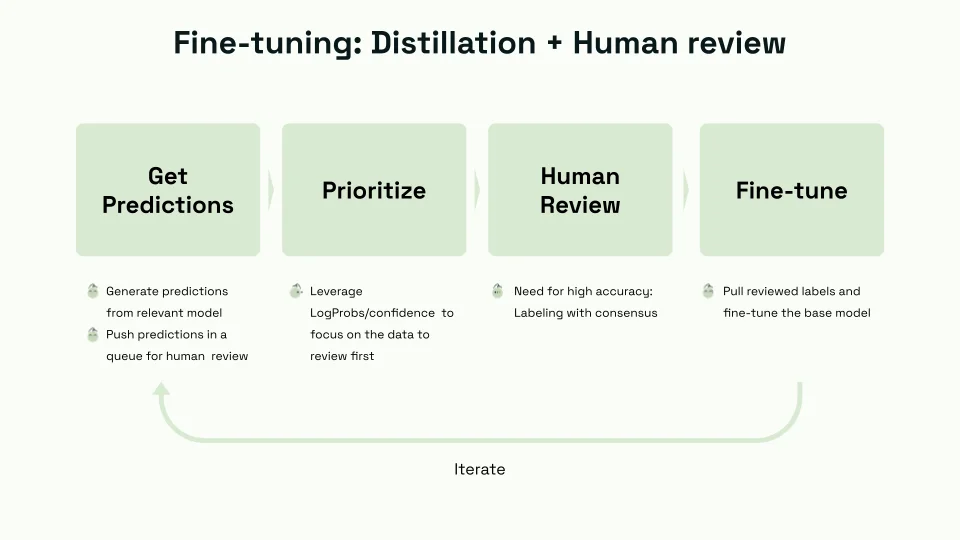
Based on the insights from the webinar and the provided notes, a robust workflow for fine-tuning Large Language Models (LLMs) emerges, integrating model distillation and human review. This workflow is designed to enhance the model's accuracy and reliability, leveraging human expertise to refine and improve the model iteratively. Here's an overview of the critical steps in this workflow:
- Generating Predictions from the Base Model:
- The process begins with the base LLM model generating predictions. This model serves as the foundation upon which further fine-tuning will be built.
- These predictions are then collated and placed in a queue for subsequent human review.
- Prioritizing the Review Queue:
- The queued predictions are organized based on specific criteria, such as the model's confidence in its responses.
- This prioritization ensures that predictions that the model is less certain about, or those deemed crucial for the model's performance, are reviewed first.
- Conducting Human Review:
- Ideally, human reviewers with subject matter expertise evaluate the model's predictions.
- To ensure a comprehensive and unbiased review process, it is beneficial to involve multiple reviewers. This collective approach helps to create a consensus on the model's outputs, addressing potential biases and ensuring a more balanced and accurate evaluation.
- Extracting and Using Reviewed Labels for Fine-Tuning:
- The insights and corrections obtained from the human review are used to fine-tune the base model.
- This involves adjusting the model based on the reviewed labels, ensuring that the model learns from its mistakes and enhances its understanding and accuracy.
- Iterative Testing, Learning, and Improvement:
- The workflow is iterative. After each round of fine-tuning, the model generates new predictions, which are again queued for human review.
- This cycle of prediction, review, and fine-tuning continues, allowing for continuous learning and improvement of the model. It's a dynamic process where each iteration aims to refine the model's capabilities further.
- Ongoing Evaluation and Refinement:
- Throughout this process, ongoing evaluation is critical. The effectiveness of the fine-tuning is assessed regularly to ensure that the model is moving towards the desired level of performance.
- Adjustments to the workflow, such as changes in the review process or the criteria for prioritizing the queue, can be made based on this continuous evaluation.
In conclusion, this fine-tuning workflow effectively marries the advanced capabilities of LLMs with the nuanced understanding of human experts. By iteratively refining the model through a process of generation, review, and adjustment, the model progressively becomes more adept, accurate, and aligned with the specific requirements of its intended application. This workflow exemplifies a holistic approach to LLM fine-tuning, balancing the strengths of AI with the irreplaceable insights of human intelligence.
Customer Demo: Human feedback loop for a more robust banking chatbot
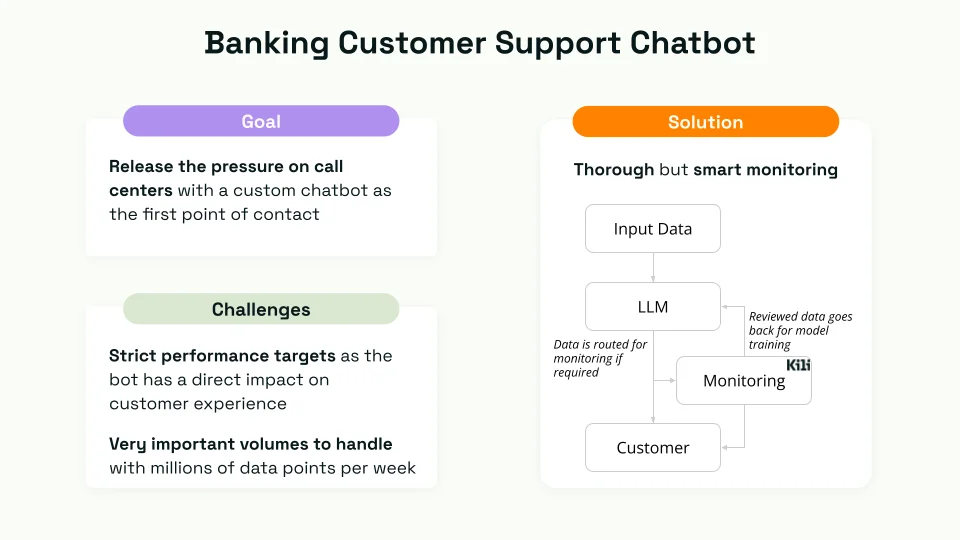
The banking sector, known for its stringent performance and compliance requirements, poses a unique challenge when integrating AI solutions like chatbots. In this context, a chatbot isn't just a tool for automation; it's the first point of contact for customers seeking assistance. Therefore, the performance of these chatbots doesn't just impact operational efficiency; it directly influences customer satisfaction and trust. Achieving high-performance targets is imperative to ensure these digital assistants can handle customer inquiries effectively and empathetically.
In this demonstration, the fine-tuning process involves a detailed workflow where customer requests are initially fed into the model. The model's responses are then monitored, and data is prioritized for further review if needed. This step is critical in identifying areas where the chatbot may need additional training or adjustments.
Kili’s role was primarily in creating and managing training data for fine-tuning the chatbot used in the banking sector. Kili could be employed to expand and enhance the training dataset, allowing for more comprehensive fine-tuning of the chatbot. Our platform's ability to manage and streamline the creation of labeled examples or training data is essential for improving the AI model's performance, particularly in scenarios requiring specific and accurate responses, as in the case of the banking sector chatbot.
Customer Use Case:

Watch video
Second Demo: Domain Adaptation
With its complex data and nuanced decision-making processes, the financial sector presents a unique challenge for artificial intelligence applications. In this demo, we underscored the potential of domain adaptation in AI, turning a generic model into a custom agent tailored for the financial sector.
The fine-tuning process employed 800 data points, each a question framed within a particular financial context. These questions were designed to elicit straightforward, direct responses, ensuring the model's output would be relevant and valuable in real-world financial scenarios.
Fine-tuning Dataset
A significant aspect of this fine-tuning process was the creation of examples and data points. Here, Kili facilitates the generation of additional data points and examples, which are crucial for fine-tuning. This capability allows for expanding and refining the model's understanding and response accuracy within the financial domain.
QLORA: A Technique for Efficient Fine-Tuning
The core of the fine-tuning process utilized a technique called QLORA (Quantization Low-Rank Adapter), a method tailored for efficiently fine-tuning large language models. QLORA leverages the principles of low-rank adaptation, which helps refine the model's capabilities, making it more adept at handling complex queries in the financial sector.
Domain Adaptation Case:
Watch video
Key Takeaways
Key takeaways stood out, each essential for anyone looking to harness the power of LLMs in their operations:
- Pick the Right Approach:
- Tailored to Needs: The success of fine-tuning largely depends on choosing an approach that aligns with the specific requirements of the task or domain. Whether it's Supervised Fine-Tuning (SFT), Retrieval-Augmented Generation (RAG), or a combination, selecting the right method is crucial.
- Understanding Model Capabilities: A deep understanding of the model's capabilities and limitations is necessary. This helps determine which fine-tuning approach will effectively address the specific challenges and objectives.
- Adapting to Goals: Different approaches have their strengths and weaknesses. The choice should be based on the goals, whether improving accuracy, reducing biases, enhancing domain-specific performance, or adapting the model to a particular style or tone.
- Rely on Quality Data:
- Foundation of Fine-Tuning: The quality of the data used in fine-tuning cannot be overstated. High-quality, relevant, and diverse datasets are fundamental to the model's learning process and performance.
- Data Reflects Output Quality: The adage 'garbage in, garbage out' holds in machine learning. The dataset's quality directly impacts the fine-tuned model's outputs. Ensuring data accuracy, relevance, and diversity is paramount.
- Continuous Data Assessment: Regularly evaluating and updating the dataset is essential. As the model learns and evolves, the data should be refined to maintain relevance and quality.
- Go Step by Step:
- Iterative Process: Fine-tuning is not a one-off process but an iterative one. It involves continuous testing, evaluation, and refinement.
- Learning from Feedback: Each step in the process provides feedback, which should be used to make incremental improvements to the model. This includes adjusting training data, tweaking fine-tuning parameters, and reassessing the model's performance.
- Patience and Persistence: Effective fine-tuning requires patience and a willingness to experiment and learn from each iteration. A step-by-step approach ensures a thorough and careful model enhancement, leading to more reliable and effective outcomes.
Wrap-Up
The fine-tuning of Large Language Models like GPT-3 is essential in harnessing their full potential. We can significantly improve their performance in specific tasks and domains by customizing these models through methods like Supervised Fine-Tuning and Retrieval-Augmented Generation. While the process involves challenges, particularly in dataset collection and the need for expertise, the rewards are substantial. Kili Technology provides data teams with the best platform to build high-quality fine-tuning datasets more efficiently. Fine-tuning enables us to create AI tools that are more accurate, reliable, and more aligned with the nuanced needs of businesses and consumers. As we continue to advance in AI, fine-tuning is a critical bridge between the raw power of LLMs and their practical, effective application in our daily lives and industries.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

