
.png)


_logo%201.svg)


AI Summary
Falcon-40B marked another milestone as data engineers seek to democratize large language models (LLMs) for non-commercial research and use cases. Since ChatGPT has catapulted LLMs to the public, OpenAI has made subsequent versions of GPT3.5 and GPT4.0 commercial. In other words, they are not publicly available for download.

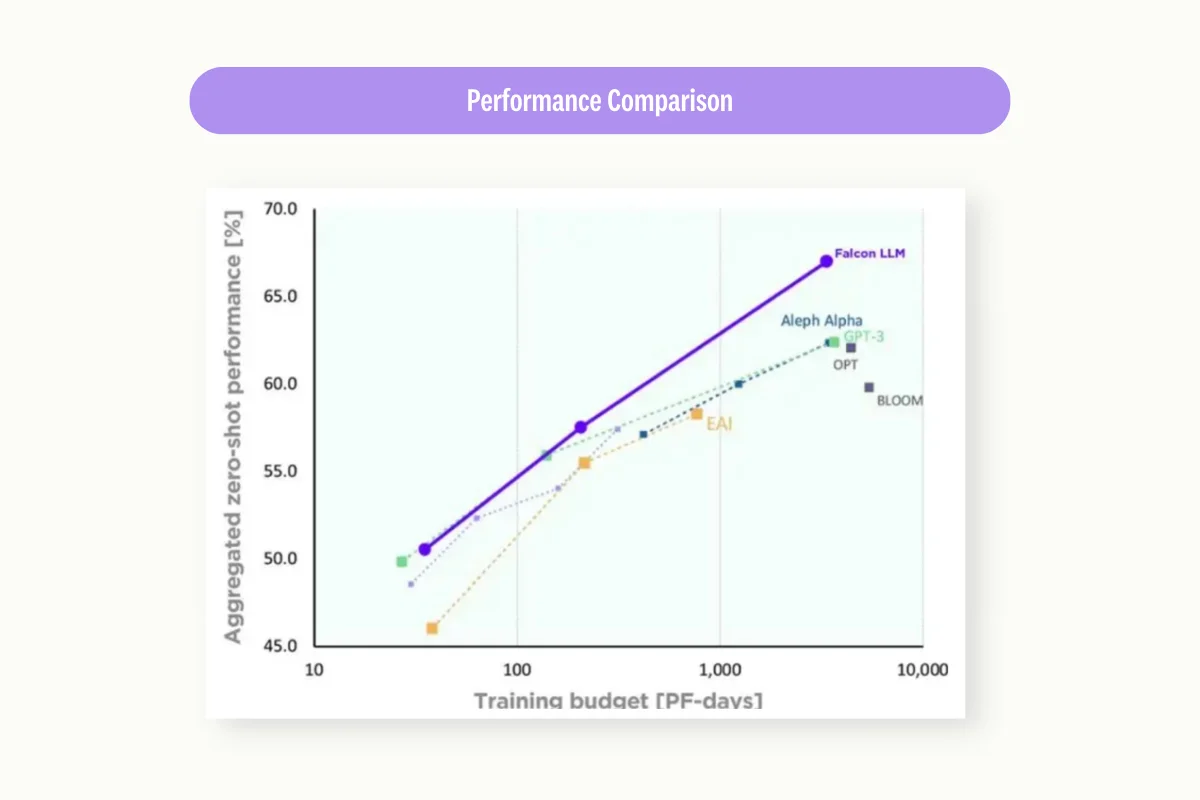
Leaderboard screenshot source: https://huggingface.co/blog/falcon
The release of Falcon-40B balances the scale. Designed for scalability, performance, and resource efficiency, Falcon-40B once topped the Hugging Face ranking list that compares various open-source LLMs. It performed remarkably well in multiple aspects, including AI2 Reasoning Challenge, HellaSwag, MMLU, and TruthfulnessQA.
Now, researchers have access to one of the most powerful deep learning models they can fine-tune for various downstream tasks. At the moment, Technology Innovation Institute (TII) in Abu Dhabi, the organization that developed Falcon-40B, is calling for research papers on prospective industry use cases for the model.
In this article, we’ll explore the possibility of using Falcon-40B in machine learning development. Specifically, we’ll explain how Falcon-40B can improve data labeling efficiency and accuracy for training better machine learning models.
Understanding Falcon-40B
Falcon-40B was developed with a stunning 40 billion parameters, making it one of the largest LLMs available publicly. When the model was launched, it outperformed many competing LLMs, including Llama, MPT, and Platypus. Researchers attributed Falcon’s performance to the refined deep learning architecture and the quality of datasets it trained on.
Source: https://falconllm.tii.ae/
The Falcon model was made available under the Apache 2.0 license, allowing deployment and production use in commercial use cases without requiring royalties or any forms of financial reimbursement. To support lightweight use cases, TTI has released a Falcon-7B version, consisting 7 billion parameters. This variant also outperforms many of its peers in the same parameter category.
Both versions also are available in their original and instruct variants. Use the original variants (Falcon-40B, Falcon-7B) if you want to repurpose and finetune Falcon for specific applications. Meanwhile, the instruct variants (Falcon-40B-instruct, Falcon-7B-instruct) are fine-tuned for conversational tasks, allowing you to experiment with the model’s ability as chatbots and virtual assistants.
What is Falcon-40B’s neural network architecture?
Falcon-40B is a causal decoder-only model. During training, the model predicts the subsequent tokens with a causal language modeling task. Here, the left-side token is visible, while the right-side token is masked. Much of its architecture was derived from the GPT-3, but TTI made several tweaks that enhanced its performance.
Rotational positional embeddings
Falcon-40B applies rotational positional embeddings in its transformer model. The model encodes the absolution positional information of the tokens into a rotation matrix. This differs from conventional positional embeddings, where LLMs use static matrices to store the positional value. With rotational positional embeddings, Falcon-40B can process token sequences more flexibly. Researchers found rotational positional embeddings outperform other methods in various architectures. Moreover, the overhead of this method is largely insignificant, despite being applied to each layer in the LLM.
Multi query attention
Multi-query attention is a modification of the transformer’s multi-attention heads. In a typical transformer architecture, The conventional multi-head layer shares one query, key, and value for every head. However, the multi-query attention scheme shares the same keys and values across all heads. This method greatly reduces the memory capacity the model needs when decoding information. Moreover, equipping Falcon-40B with multi-query attention enables the model to process complex linguistic data more efficiently. The model uses an internal variant of the multi-query attention, which supports independent keys and values per tensor parallel degree.
FlashAttention
FlashAttention is another novel discovery allowing transformer models to compute longer sequences with less time and resources. It reduces the number of memory operations when transferring data between the GPU’s high bandwidth memory and SRAM. Falcon-40B incorporates FlashAttention in its architectural design, allowing the model to outperform existing baselines by up to 15%.
Parallel attention decoder block
Falcon-40B applies parallel attention and multilayer perceptrons with two layer norms in its decoder block. The parallel attention mechanism allows the model to extract different features from the sequence more efficiently. Meanwhile, having a two layer norms MLP enables the model to overcome challenges in training, such as preventing overfitting and enabling faster convergence.
How was Falcon-40B trained?
The Falcon-40B features the following architectural specifications.
- Layers: 60
- Embedding attention: 8192
- Attentions Heada: 64
- Vocabulary: 65,024
- Sequence Length: 2048
TTI took 2 months to train the 60-layer deep large language model with 1 trillion tokens. They trained the model on AWS SageMaker, utilizing 384 powerful A100 40GB GPUs. The model was trained in Dec 2022 with the following hyperparameters:
- Precision: bfloat16
- Optimizer: AdamW
- Learning rate: 1.85e-4
- Weight decay: 1e-1
- Z-loss: 1e-4
- Batch size: 1152
Because of its architectural enhancement, training Falcon-40B took 75% of the compute resources GPT-3 required. The model also proves more efficient when predicting tokens in production, consuming only 20% of the processing power compared to GPT-3.
To train Falcon-40B, TTI compiled a large dataset comprising web-crawled textual data. Then it trains the model on a custom distributed training codebase. The Falcon-40B training dataset largely contains tokens extracted from RefinedWeb, a high-quality web dataset curated by TTI. It also learns from books, codes, and technical and conversational resources. While Falcon-40B is primarily trained in English, it was also trained in several other languages, including German, Spanish, French, Portuguese, Polish, Dutch, Romanian, Czech, Swedish and limited capabilities in Italian.
Lastly, TTI validates Falcon-40B against benchmarks such as EAI Harness, HELM, and BigBench to ensure achieved the desired performance.
How much computational power does Falcon-40B need?
Falcon-40B is a scalable and high-performing deep learning model that could rival many of its peers. Not only does it score impressive points in key comparison metrics, but Falcon-40B also uses fewer compute resources than similar models. TTI attributed this to the model’s distinguished features, such as multi-query attention and FlashAttention.
To run a full-fledged Falcon-40B model smoothly, you’ll need at least 85-100 GB of memory. It’s comparably lesser than LLaMa, which comprises 65 billion parameters, thus occupying more memory spaces. The compute requirements breakthrough by Falcon-40B open up new possibilities for deploying LLMs in a broader range of hardware.
What is Falcon-40B Instruct?
Falcon-40B Instruct is a specially-finetuned version of the Falcon-40B model to perform chatbot-specific tasks. It takes generic instructions in a chat format. TTI trained Falcon-40B Instruct with a mixture of Baize, GPT4all, GPTeacher, and WebRefined dataset. It’s important to note that Baize consists of hundreds of thousands of sample conversations generated by ChatGPT. Due to the legal terms stipulated by OpenAI, using text generated by its tools to compete against itself is prohibited. Therefore, Falcon-40B Instruct is more suitable for experimental works rather than developing commercial generative AI systems.
Based on Hugging Face’s open-source LLM ranking, the instruct version of Falcon-40B fares better on average than its foundational model. You can imagine the instruct model like the popular ChatGPT, except you can deploy them for free on your machines. Despite its superior performance, it’s more feasible to use TTI’s foundational model, Falcon-40B, for building downstream applications. Besides avoiding legal complications, Falcon-40B is a highly-capable model that excels in conversational tasks in various domains.
The Role of Data Curation and Data Quality in Falcon-40B
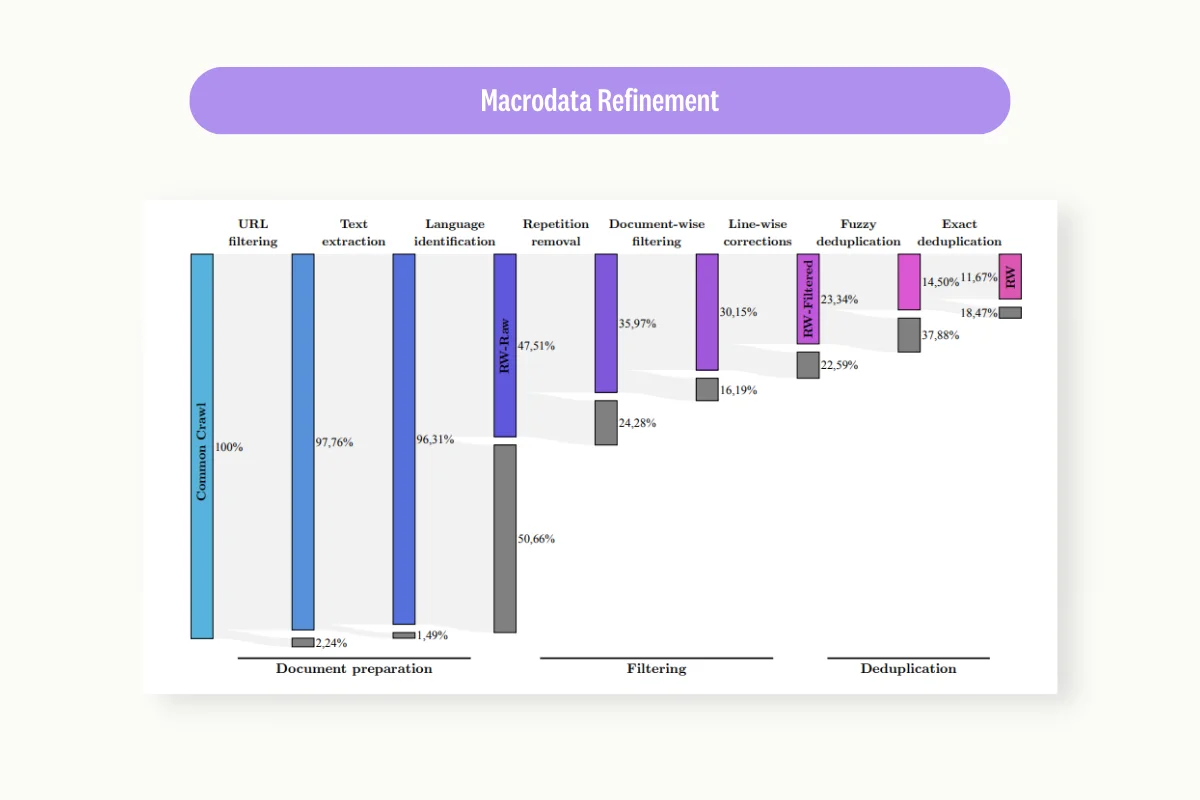
Source: https://arxiv.org/pdf/2306.01116.pdf
Falcon-40B’s success in dislodging several established models from their ranks isn’t coincidental. It was a culmination of research to produce an LLM that surpasses industry expectations. Besides focusing on the underlying model, TTI paid equal attention to curating high-quality training data. When designing the model, the company intended to create a data pipeline capable of extracting and filtering high-quality data from the web.
Led by exceptional data scientists, TTI was well aware that LLMs are highly-sensitive to the data they were trained on. For example, bias might be a severe issue compromising the model’s suitability when deployed in healthcare, finance, and other industries. Therefore, TTI took great care when preparing the training datasets, including filtering out inappropriate text and removing duplicate or redundant content. Even that, it might still produce biases commonly encountered online, although to a lesser degree.
These are the major sources that form Falcon-40B’s training samples.
RefinedWeb English
TTI meticulously prepared the datasets required to train a performance-driven model. Most training samples that Falcom-40B used were derived from the RefinedWeb English dataset. RefinedWeb filters information from CommonCrawl with a MacrodataRefinement Pipeline to improve the dataset’s quality.
RefinedWeb Europe
Like RefinedWeb English, RefinedWeb Europe is a dataset created by TTI. However, it consists of multilingual data tokens representing languages commonly used in European nations. This augments the language capability of Falcon-40B. At the moment of writing, the model doesn’t support Chinese, Korean, or other foreign languages.
Other curated corpora
Besides relying on the RefinedWeb dataset, TTI curated datasets from several sources to enable the model to perform more robustly. The move was inspired by The Pile, an extensive collection of high-quality datasets derived from both newly-generated and existing sources. Training Falcon-40B with conversational, technical books and code curated in this manner enables the model to perform better in specific situations, such as academic writing.
Falcon-40B in Data Labeling Tasks
Falcon-40B was created by training a deep learning model with high-quality datasets. On its own, Falcon-40B is already an all-rounded model, excelling in performance while consuming lesser computing power than other models in the same range. And this places it in an ideal position to help ML teams train machine learning models for downstream applications.
Machine learning models train either in supervised, unsupervised, or semi-supervised modes. For practical applications, the deep learning model requires a certain degree of supervised training, where the model trains on labeled datasets. For example, you must finetune a pre-trained model like GPT by training it with specific product data before it can function as a virtual assistant for your company.
What are the challenges in data labeling?
Data labeling is fundamental for developing high-performing machine learning systems. Yet, the process itself is tedious and costly. Organizations need to assemble a team of project managers, labelers, and reviewers to label potentially tens of thousands of data samples. In complex applications, they need a larger pool of data to work on. On top of that, data labeling involves collaboration with domain experts to ensure that the training samples are accurate.
Given the nature of data labeling, organizations face several obstacles when developing training datasets.
- Labeling bias. Human labelers are subjected to their personal belief and option when annotating raw data. For example, they might categorize certain words as inappropriate based on their specific preference for what constitutes hate speech.
- Scalability. When implemented manually, data labeling is hard to scale to meet the projected growth. Even if you can engage a larger team of labelers, ensuring the datasets meet the stipulated quality requirements takes time and effort.
- Resources. It takes time to train human labelers before they are up to the task. Some organizations lack the time and a sizeable budget to engage a professional labeling team.
- Human errors. As competent as they are, humans eventually make mistakes when labeling or reviewing the datasets. Labeling mistakes, left unaddressed, may impact the model’s performance.
How can Falcon-40B help in data labeling?
Falcon-40B is arguably one of the best open-source models trained to process natural language tasks, including text generation and machine translation. It learned from high-quality web-crawled and curated data and was designed with architectural features capable of performing accurate inference at scale.
Therefore, you can finetune Falcon-40B to support various textual labeling tasks. When fine-tuning the Falcon-40B to assist in annotation, the model retains its preexisting weights. It then learns from the given datasets without overriding its original linguistic capabilities.
We share several practical labeling tasks that Falcon-40B is capable of below.
Text classification
You can finetune Falcon-40B to classify textual data according to their categories. For example, labelers annotate several news articles as ‘sports, entertainment, and politics’. Then, ML teams use the annotated datasets to train Falcon-40B. Once trained, the model can automatically annotate the remaining documents.
Sentiment analysis
Falcon-40B can support human annotators in identifying particular sentiments associated with textual data. To do that, you train the model to append a sentiment score to words like ‘satisfied, unhappy, or regret’. Based on the score, Falcon-40B would annotate the sentiment of a specific text document accordingly.
Named entity recognition
Named entity recognition (NER) is an important preprocessing task when developing natural language processing systems. You can train Falcon-40B to identify specific entities by first labeling them on the sample. The model then learns to recognize tags like people, places, dates, monetary value, and distance from the annotated samples. Then, it can repeat the feat on its own on new textual sources.
Data augmentation
Another possible use of Falcon-40B is to generate synthetic data to increase the size of an existing dataset. This is helpful in use cases where training datasets are naturally limited. For example, ML teams might have difficulties developing machine translators for foreign languages because of the limited digital sources. Here, they use Falcon-40B to expand the dataset composition.
Learn More
Discover how foundation models are revolutionizing AI development and how you can overcome their limitations in real-life applications. Join us for an insightful webinar where we'll delve into the common mistakes and challenges of models like GPT-4 and SAM.
Employing Falcon-40B with Kili Technology
Kili Technology is a data labeling platform that allows organizations to streamline their MLOps. We provide data scientists with powerful tools to produce high-quality datasets for training or finetuning foundational models. Rather than being a standalone product, Kili enables an end-to-end machine learning pipeline, supporting various infrastructures and frameworks for AI development.
One of Kili’s advanced features is its ability to leverage LLMs like Falcon-40B for pre-annotating textual data. Instead of overwhelming human labelers with annotation tasks, ML teams can use Falcon-40B to complement the data labeling workflow in various ways.
- ML teams can use Falcon-40B to classify text into pre-defined categories. They create the appropriate prompt, which triggers the model to interpret the underlying textual sources and determine the best-suited category. Then, they import the pre-annotated datasets to Kili for review.
- Similarly, labelers can use Falcon-40B for sentiment analysis and feed the results to our data labeling platform. This increases labeling efficiency and reduces human bias.
- Falcon-40B is also helpful for automating named entity recognition tasks. Through zero-shot or few-shot learning, the model helps Kili users easily identify pre-determined entities in documents.
- Falcon-40B is capable of generating synthetic data to augment existing ones. Meanwhile, Kili provides tools like advanced filtering and automated QA to manage and distribute the expanded datasets to teams of labelers.
Besides the above enhancements, ML teams have access to Kili’s active learning feature, which automates data labeling with LLMs like Falcon-40B. Active learning uses trains a machine learning model to perform labeling tasks. With this method, human labelers label a few samples and train the model with them. Then, the model can automatically annotate with strong confidence, leaving the labelers to review the results. In our test, this method demonstrated up to 50% of performance improvement in specific labeling tasks.
Build high-quality LLM fine-tuning datasets
The best LLM for your team is one fine-tuned with your data. Our platform empowers start-ups and enterprises to craft the highest-quality fine-tuning data to feed their LLMs. See for yourself.
Conclusion
Falcon-40B has caused much excitement in the machine-learning community. With its improvised architecture, exceptional performance, and emphasis on quality datasets, the model brings tremendous potential to various downstream applications, including data labeling. In its design, Falcon-40B underscores the importance of training with high-quality datasets. And it has way more to offer by enabling the development of better-performing machine learning models.
Trained to perform natural language capabilities, Falcon-40B supports various annotation tasks, including text classification, sentiment analysis, NER, and data augmentation. The model is also lightweight and open-source, allowing ML teams to deploy it for annotation tasks more effortlessly. When paired with Kili, Falcon-40B adds value to traditional labeling workflow by working seamlessly with our platform’s advanced features.
Watch video
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

