
.png)


_logo%201.svg)


AI Summary
Welcome to this webinar digest on advanced labeling automation with LLMs –namely: GPT and SAM! Paul and I have had a great deal of fun hosting this live session! As we wanted to help you leverage the power of these models for your data labeling, we’ve prepped this summary.
We’ll explore in practice how we can leverage the power of foundation models to improve both the efficiency and the quality of our quality labeling.
Let’s go!
Getting Started
About a month from the webinar, a paper named ChatGPT outperforms Crowd-Workers for Text-Annotation Tasks has been released.

In this paper, the authors demonstrated that:
- ChatGPT does better than people hired to label data for tasks such as topic or frame detection.
- Without any prior training, ChatGPT is more accurate than most people for 4 out of the 5 tasks tested
- ChatGPT is 20 times cheaper per label than using crowdsourcing from Mechanical Turk.
In a nutshell: Foundation models have a big potential to improve the accuracy and the efficiency of data annotation, at least for text annotation.
Behind this catchy research paper title, what we will do with this article is to help understanding where the value of foundation models lies, and how to best leverage them.
Will Foundation Models be the end or Data Labeling Services?
At this point, if you’re a data labeling service provider, or labeler or an ML engineer, you might wonder how these results are likely to impact the labeling services industry.
Well, be ensured that all is not lost. Of course, data labeling, for some perception tasks, tends to be be commoditized. As a result, offering data labeling service naively is no longer possible. More than ever, running a successful data annotation service will require to be equipped with the state of the art data labeling solution.
What you can expect from this Digest
During the last webinar on Foundation Models, we shared an introduction on what they, how do they work, how ChatGPT was trained from data annotation, what is prompt engineering, what are the best practices in prompt engineering. We’ve also shared with you some potential use cases for foundation models and data annotation. What we will do today, is to implement together foundation models that will help your saving both time and money data-annotation wise.
To do so, we will tackle natural language processing (nlp) and computer vision, and gauge the impact of our experiment on the two main KPIs of data labeling: productivity and quality.
Quick Catch-Up on ML State of the Art: SAM

Just a few weeks before we hosted this webinar, a lot has happened. But the main event was that Meta released one model named SAM, standing for Segment Anything Model.
Why does SAM matter?

This model is critical, because it can identify and segment any object within an image or video. Cherry on the cake: it does properly, both accurately and robustly.
For Meta, of course, this model critical is critical due to their AR and VR product, since –as you can imagine, this will help their VR headset to understand its environment better.
But this technology is also super important for us, as labelers. Indeed, it has the power to remove a lot of the time-consuming parts of data labeling. So namely, with interactive segmentation, you can accelerate a lot of delivering of semantic masks.
This model is now available within Kili Technology’s platform. You’ll see it in action later on.
The importance of quality data volume
Whats makes SAM a better model that previous models because it was trained on a larger piece of data.

The number of images was six times bigger than other datasets used to train similar models, and this dataset has 400 times more labels than others. The amazing capabilities of segment anything (SAM) comes from its dataset size and quality.
We can also share another takeaway on how this big dataset was built: Meta used the model itself to label more data programmatically, as well as a human in the loop process implying 3 steps:
- Image labeling performed by annotators assisted by a model.
- Mix pre-annotation and human review.
- Use only the model to massively label images.
Overall, this project show that to label a large model of data, human in the loop with human review is key.
Labeling with ChatGPT and Foundation Models in Practice
Labeling Text with GPT4
Foundation Model as a labeler
Our starting point will be this simple labeling workflow from interface to data upload, all the way from creating the dataset.

As you can see, we don’t have any automation going on. What want to do now, is to integrate GPT in the pre-labeling step.
The first step before integrating GPT is to design our prompt.
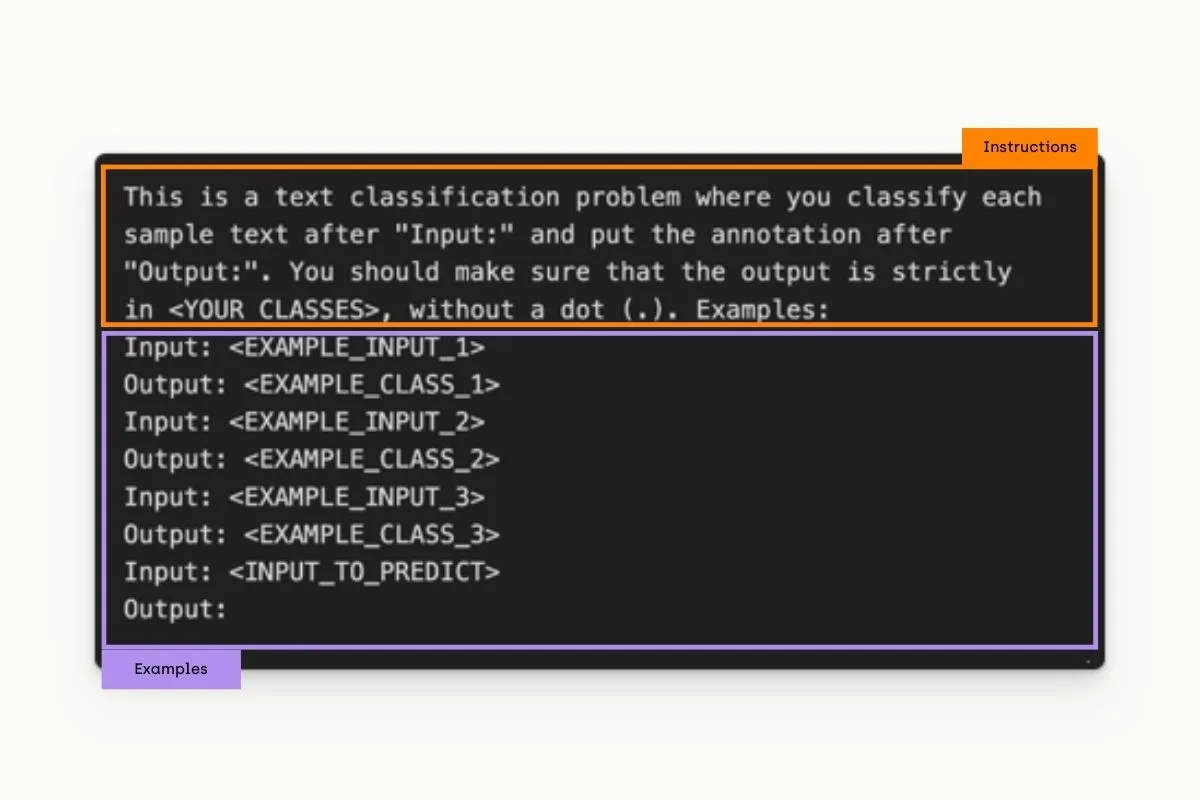
As you probably know, a prompt is the input you’ll have to give GPT in order for it to generate text.
Here, we will focus on prompts capable to help us with classification of NER tasks. We will build. a base prompts, that will induce GPT into resolving this classification task.
You can see in our example that the prompt is twofold. On the one hand, the orange section tells GPT what is the task expected from it. On the other and, the violet section illustrates the expected outcome. Later in the webinar we will compare the effect of few shot vs zero shot predictions.
We will discuss prompt engineering (basically what we’ve just did) further later on.
Note that prompts we will use can be used to perform tasks such as classification and named entity recognition. Let’s now go back to our workflow.
Labeling workflow
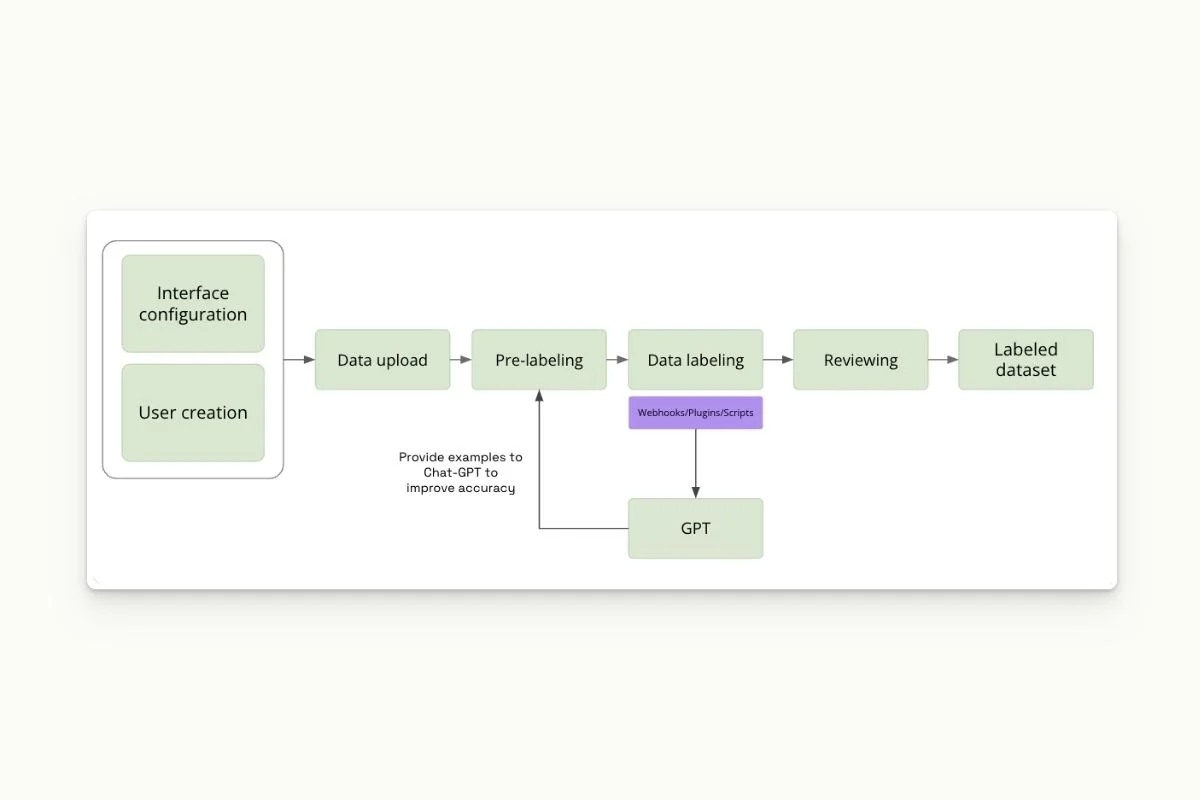
From now on, we’ll build a prompt for GPT to pre-annotate our dataset. As displayed in the diagram, we want to use a human in the loop model.
To do so, we will :
- pre-annotate data using ChatGPT;
- have these annotations reviewed by humans;
- correct these annotations where mistakes have been made (by humans);
- use these corrections to improve ChatGPT’s output.
Let's go through the workflow in more detail:
- We use GPT to label data (using a base prompt).
- We have human in the loop, who will be monitoring GPT’s predictions and correcting them.
- We query corrected examples and select one per category using random sampling.
- We build few shot prompt.
- And update with new predictions on the next batch.
Let’s look at what it looks like in Kili Technology.
Prompts for classification & NER
Before we jump onto the demo itself, allow us to share our results with zero-shot prompting vs. few-shot prompting experiment.
Zero-shot is equivalent to asking GPT to classify a text without providing examples of the classes. On the other hand, few-shot prompting includes examples of texts for the different classes.
You can see examples of each displayed below.


Here is the project we will work with. It has been populated by pre-annotations from the CoNLL dataset using GPT and the prompt for NER we’ve mentioned earlier.
By clicking on the label, I can now access the labeling queue and correct predictions from GPT.
The following view is what a labeler would see when opening my project: the data that was pre-annotated by ChatGPT 3.5.

You can edit the pre-annotation to correct potential mistakes directly from the interface. For example, here, Germany has been wrongly labeled as a location whether it should have been labeled as miscellaneous.

On similar task the gain in productivity is around 3x the throughput
On a second project, we corrected all the pre-annotation of GPT manually.

When navigating these annotations from our Explore Interface, we can see what’s the overlap of GPT’s predictions and manually created corrections.
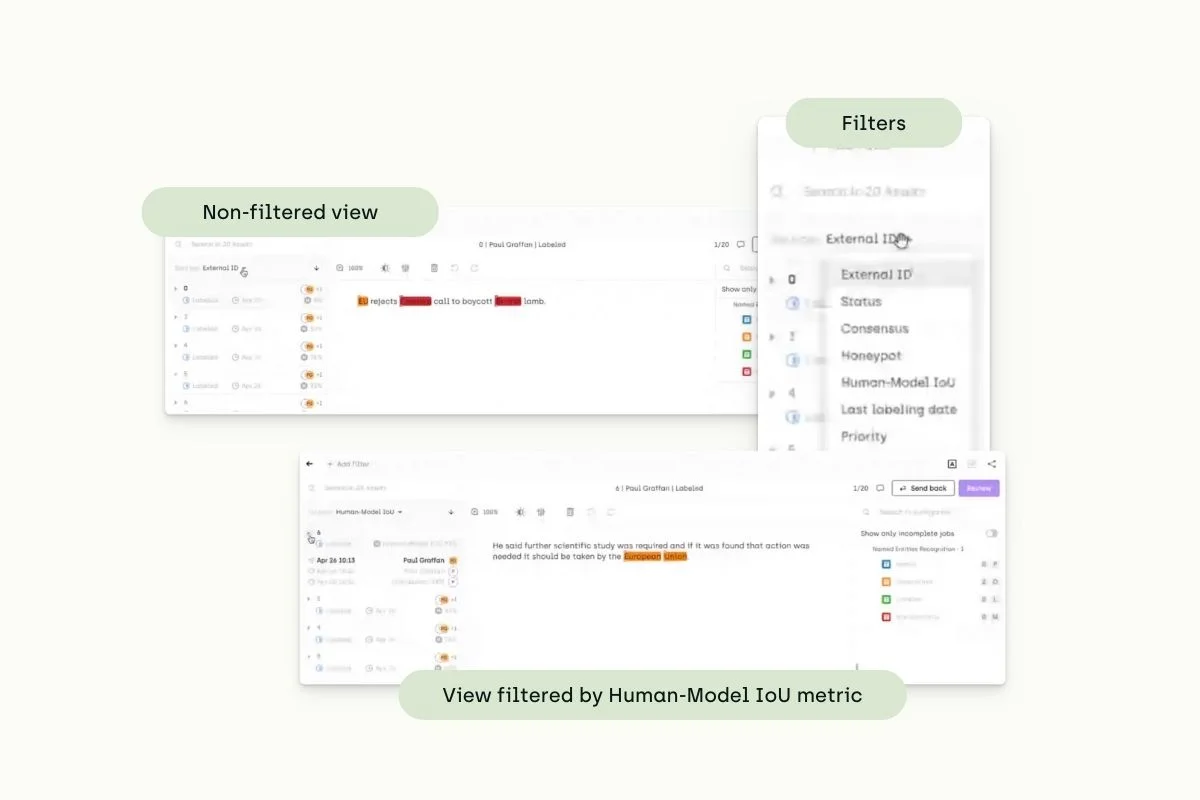
In this last example, you’ll see a document annotation ChatGPT is not mastering yet: a text is missing context and predictability.
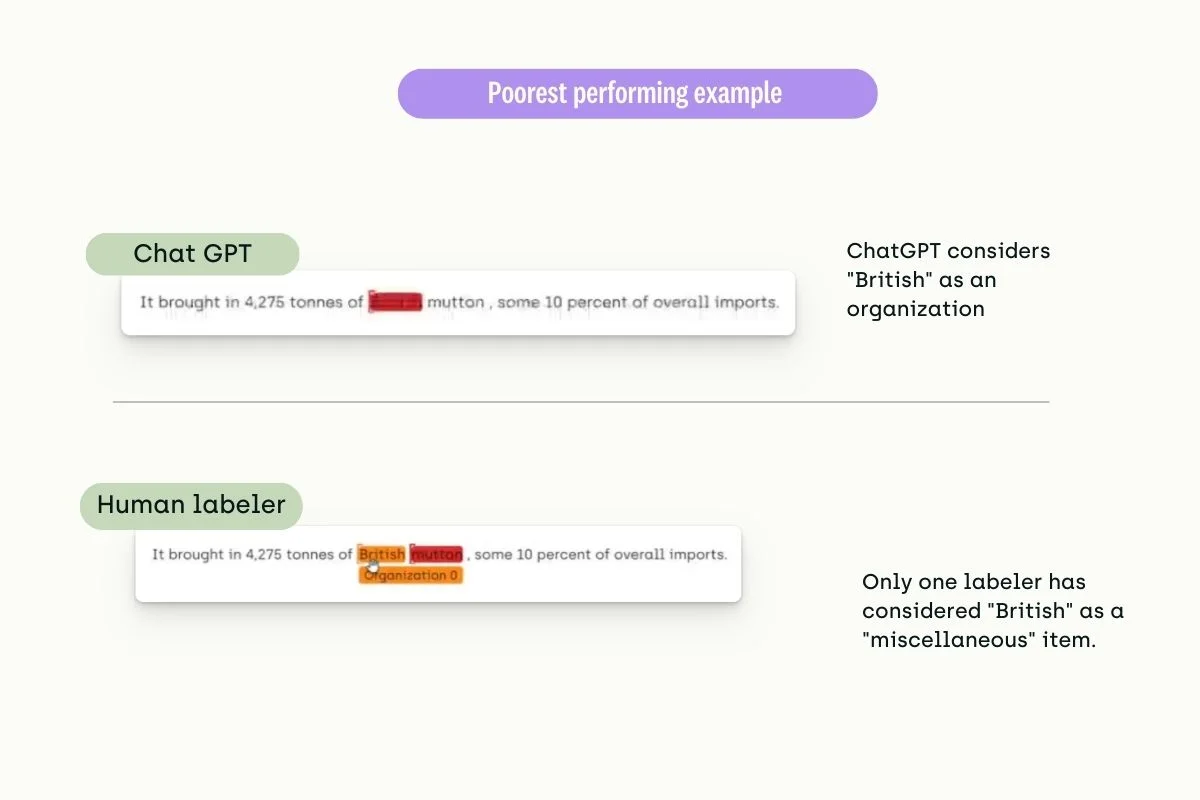
In summary, LLMs can expedite classification and named entity recognition labeling. However, GPT still makes many mistakes (with an accuracy rate of 50-90%), particularly when adapting to domain-specific data such as legal, medical, or manufacturing predictive maintenance. It's important to note that GPT's training data comes from publicly available sources, so information specific to your company or industry might be outside the scope of GPT, leading to erroneous results. Prompting needs to be expanded to other tasks, such as entity linking or layout analysis.
Tips on prompting: Few-shot and Zero-shot prediction
In this context, zero-shot asks GPT to make predictions (classifications) without providing examples in the prompt. Few-shot provides GPT with a few examples in the prompt. As you've seen, we've included examples of our tasks to be performed in our prompt. And to understand whether this has an impact, we ran an experiment comparing zero-shot and few-shot predictions.
For our experiment, we used the DBPedia dataset. The task was to predict the topic of Wikipedia articles, which had nine classes.
We made predictions using a zero-shot prompt and a few-shot approach, with only 1 example per class. We achieved a 12% improvement in accuracy with the few-shot approach, suggesting that providing examples to ChatGPT is a method worth considering.
Doing QA on text with GPT4
In this part, we will see how we can use LLMs, and specifically today, ChatGPT, to prioritize our quality assurance process and make it more efficient.
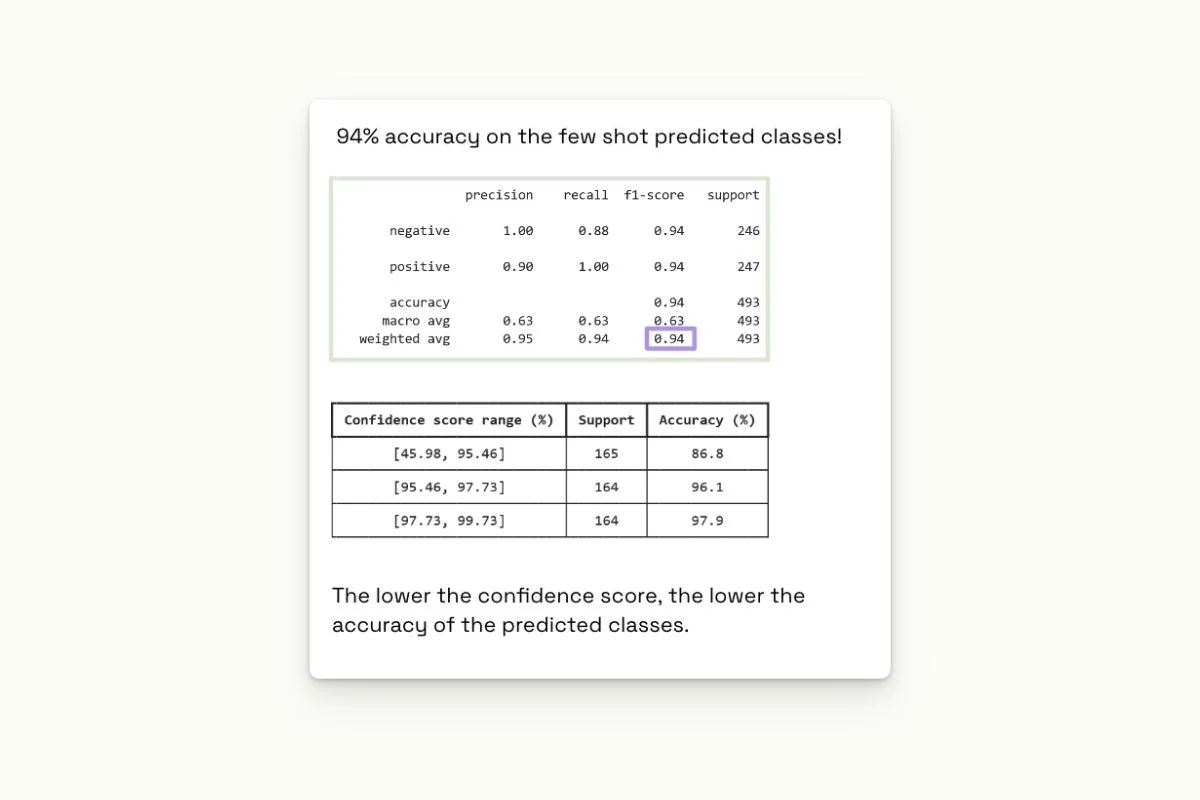
We’ve used the IMDb Movie Reviews dataset on a subset of about 500 samples for this experiment. We then prompted GPT to predict the review's sentiment with only two categories “positive” or “negative.”
We took the five tokens with the highest probability to estimate the model's confidence and multiplied their scores to estimate confidence in ChatGPT’s predictions.
Looking at the table below, we can see that where we get the highest confidence score is where GPT seems to perform better. Using this, we can know to prioritize or QA process to focus on data with the lowest score.
Building a QA workflow
This QA workflow allows prioritizing the data that most likely needs to be reviewed.
The idea is to find the right heuristics for detecting where we should invest our effort in the dataset.
It notably allows MLEs and subject experts to focus their precious time where their expertise matters most.

Here is a representation of what it looks like when integrated using Kili Technology:
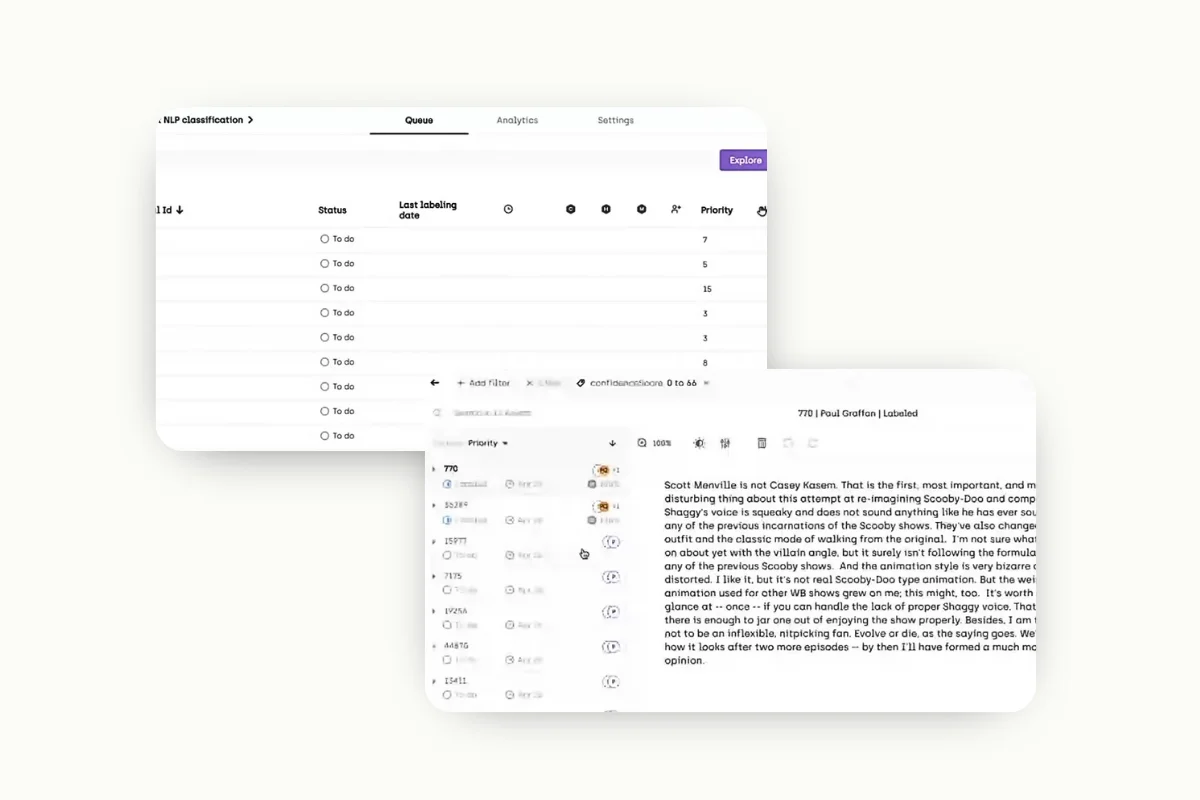
In this dataset, the priority is scored according to the confidence score of GPT, so our data labeling team can be smart with their queue and focus on the more ambiguous data that GPT had low confidence on. The queue is now reduced to 13 after filtering according to priority levels and confidence scores.

Labeling images and videos with SAM
In this second part of the webinar we are going to look at how we can leverage another amazing model Segment Anything or SAM to accelerate labeling for images and videos.
First, let's explore how to use SAM for labeling. What are the pain points of segmentation?
Time efficiency - extensive pixel by pixel object annotation means a strong time investment
Experience and focus - need to maintain attention and focus during long time periods because of the high level of consistency and accuracy demanded
Quick reminder on SAM:
Segment Anything Model (SAM) is a project led by Meta to build a foundation model for image segmentation.
The model enables zero-shot generalization & draws inspiration from NLP foundation models. They allow mask prediction from several input types: bounding boxes, points and text.
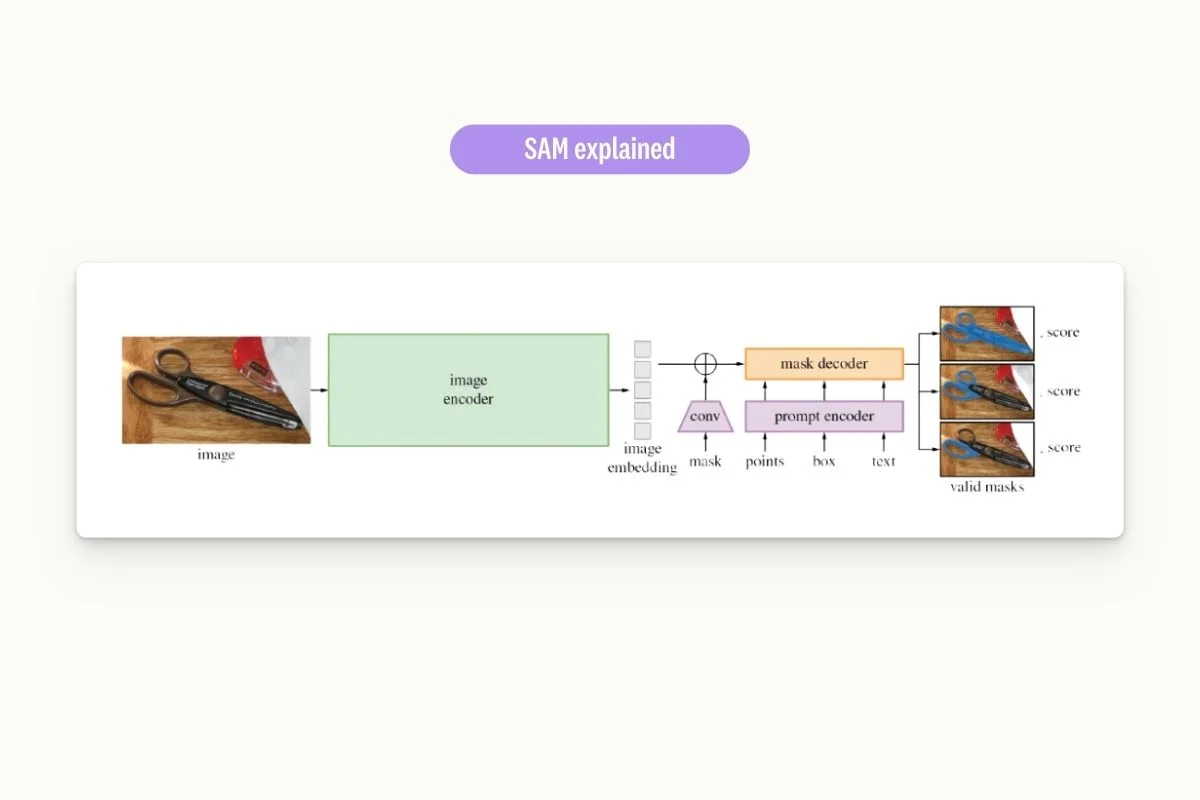
SAM and segmentation: the best of both worlds?
SAM is a model for instance and semantic segmentation, which are among the most tedious tasks to perform on images and videos. Accurately drawing masks takes time and requires focus, making it a time-consuming process. Furthermore, when a team of labelers is implied, the variance in the annotation will be greater than when drawing bounding boxes, simply because more options are available.
SAM helps us in multiple ways:
- It accelerates the labeling process.
- It reduces fatigue for labelers.
- It makes the labeling more homogeneous and reduces noise in the data. In other words, it improves the quality of the labeling.
SAM is great for labeling purposes. It can help on (at least) 4 aspects:
- Ambiguity solving
- From the first ambiguous input, SAM is able to produce one mask. The ambiguous input can then be reworked by adding other points to refine the area.
- Speed
- Once image embeddings have been computed, prediction takes 50ms. This allows an interactive process with fast prediction from prompt inputs.
- Zero-shot learning: The task has been defined to enable zero-shot generalization. This allows the detection of a wide range of objects and categories, even ones it hasn't seen before.
- Mask quality
- SAM outperforms previous models for low number of input points in terms of mask quality rated by humans. An annotator can focus on understanding the image context rather than defining object boundaries pixel by pixel.
How do we leverage SAM at Kili Technology?
We added integrated directly the model in our interfaces for labelers to use it. Allowing them to segment any object in only a few clicks.

Let’s see this in action now:
Watch video
We are going to be using an image from the CSSK dataset. Prior to SAM, we would have to draw a polygon manually, which is tedious to obtain a high level of accuracy.
With SAM, we can just select the category, activate the tool, and start inputting points. In two points, we can fully select the car with good accuracy.
One limitation, however, is when we need to start labeling items that are blurry in the photo. For example, SAM cannot accurately label the person sitting in the background. And attempts to fix it can be difficult.
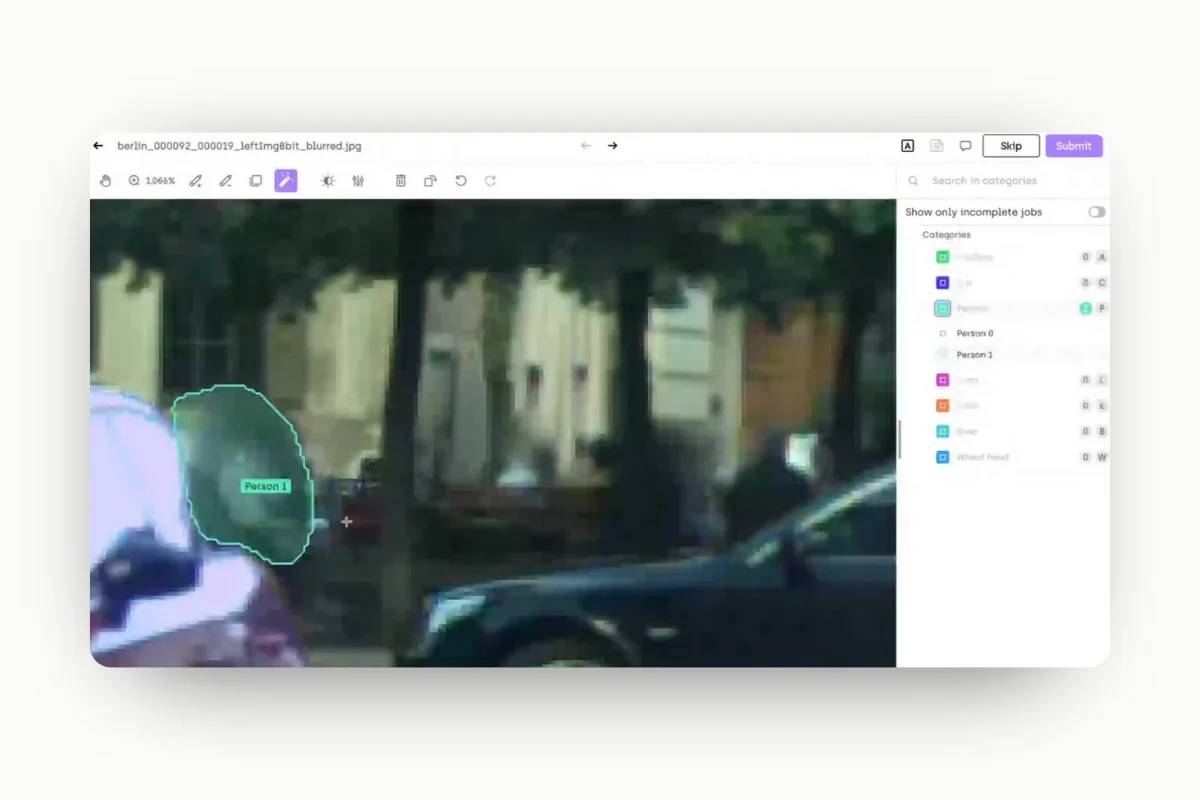
This means that SAM can label the larger and sharper elements of the image while your image annotation team can focus on the smaller, low-resolution elements of the image.
Since SAM is a zero-shot learning model, we can use it directly on many use cases such as X-rays, aerial imagery, and more. SAM can still obtain pretty good results in some use cases when labeling smaller objects in photos.
To conclude, SAM outperforms traditional stacks in
- Labeling objects that are clearly visible in the foreground
- Speeding up the labeling time by 5
Limitations of labeling with SAM include:
- Labeling low-resolution images
- Detecting small objects in the background
- SAM can create artifacts that pollute the segmentation masks
Monitoring quality with a QA bot
Knowing the limitations of SAM, we can still further improve the productivity and quality of image annotations by using a QA bot with Kili Technology. To illustrate this, we will apply this to a case where SAM produces artifacts.
What is programmatic QA?
The idea behind programmatic quality assurance is to define rules in a programmatic way, which can be applied to the labels created in the labeling process to obtain and detect potential errors, have real-time feedback, and improve the quality assurance we can do. So we can do this in large datasets with hundreds of thousands of data points without involving more resources.
This is what the improved workflow with SAM and a plugin would look like:

As a review, a plugin, in this case, is a Python script that can be written to contain business rules or error detection methods and can be triggered by actions in Kili. In reality, plugins can do a lot more than error detection. Plugins can customize your labeling workflows through consensus resolution, selecting assets for review based on metrics, custom webhooks, and, as we mentioned earlier, automatic error spotting and programmatic QA, which will be the center of this demo.
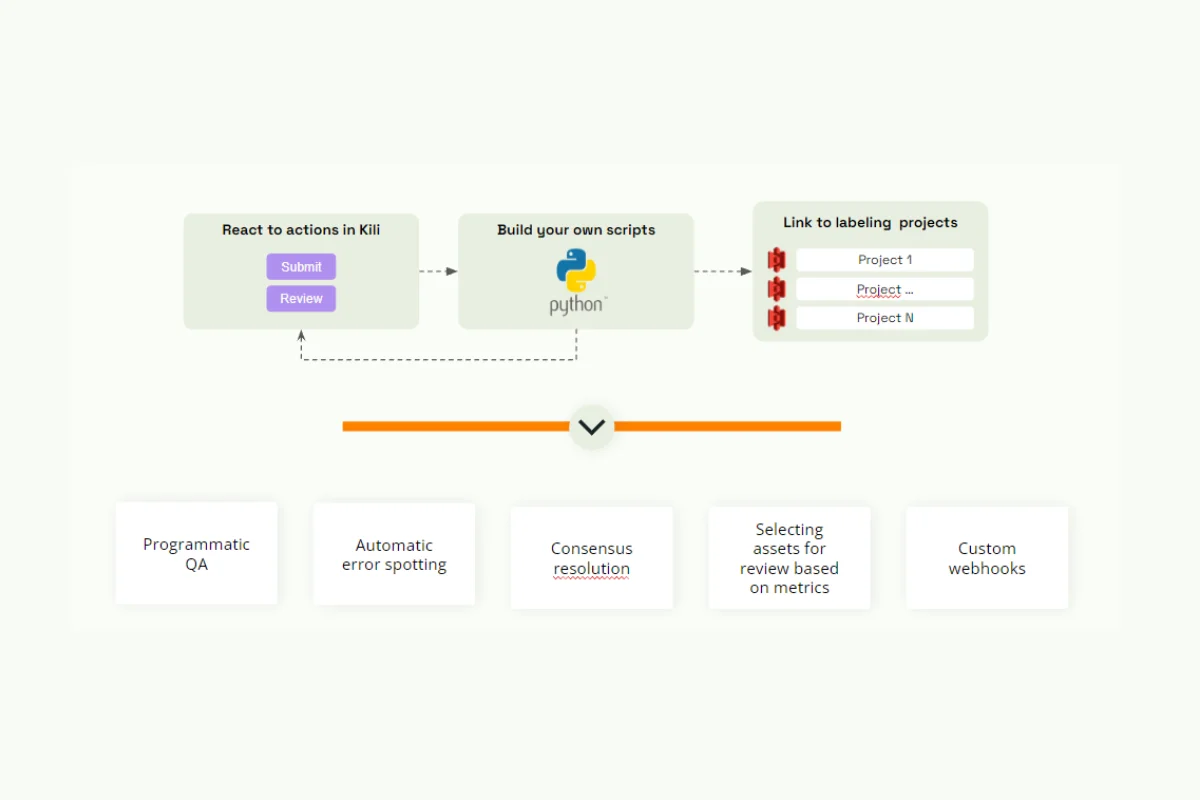
Programmatic QA in Action
In the example below, we built a Python script with a simple rule: every time an image is submitted, the area of each polygon stated in the image will be analyzed, and if the polygon has an area of less than five square pixels, it will be flagged for review by a reviewer or a subject matter expert to check that the item is properly labeled or if it is just an unwanted artifact.
You can also write the Python plugin to directly delete the polygons depending on how you want to implement this. All of this depends on your use case.
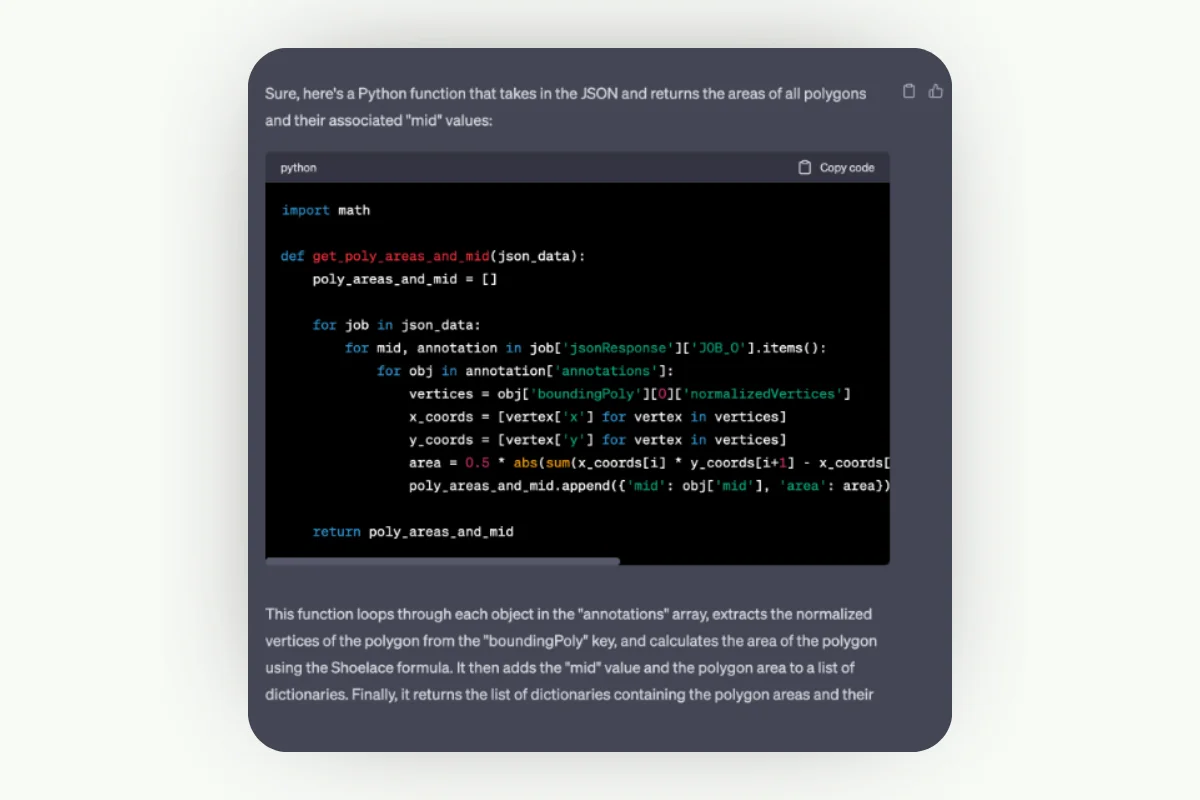
As a side note, we developed this plugin using chatGPT, reducing our work time to 50%, which is quite helpful. That said, there’s still some need to fine-tune the code itself. Like automating the data labeling process, humans still need to be in the loop to make it work. So, let’s see how this works in the demo:

We have this image that has artifacts created by SAM. We won’t be making any changes, and we will click Submit.
Our plugin will be triggered by this submission, and we will see this because we have an alert in our queue. A reviewer can then manually confirm if this is an artifact that we need to remove.
In this case, with the plugin detecting several artifacts, it will run the reviewer through the entire set of sections that fit the plugin’s rules to confirm or delete the artifacts.
Watch video
Again, this is just an example of what you can do with a plugin. You can apply different rules depending on your use cases. For example, instead of looking at the number of pixels, you can direct it to look at the average value of the color of the pixels in a segmentation mask to assess whether or not it was categorized correctly.
Key Takeaways
Foundation models like GPT and SAM have impressive performances in various use cases in NLP and computer vision. However, when we use them, it requires careful consideration based on the nature of the data we want to label and the complexity of the task.
We also want to consider two things:
- Task complexity - The foundation models we discussed have size and specificity limits. For instance, if you use GPT 3.5, know that it has a limit of 4,000 tokens. Meaning you might not be able to label or segment larger data points thoroughly. In satellite imagery, you may struggle to segment smaller images, and in NLP tasks, it might be difficult for you to classify documents of more than eight pages fully.
- Know that GPT was also trained in data available on the internet, such as online books and Wikipedia, so if you are working on a very specific and verticalized use case, it may not work as well as you would hope.
- Data sensitivity - It’s important to ensure that your foundation models comply. GPT, for example, is on the cloud and may not be the safest option if you have private data. However, SAM is not used on a cloud, so we can have this instance that complies with data safety and privacy standards on the Kili platform.
Our second takeaway is to think about how much we can trust LLMs, and more broadly, foundation models, when they give an answer. For this, we can say not much. LLMs can still give false positives and false negatives. When reviewing your data, we recommend that you prioritize the items where the model was not confident but also not neglect the data where the model was super confident.
We understand the value of these foundation models, but it’s still important to keep a human review and build a test set to assess the performance of those models. This is where Kili excels.
We provide three lines of defense to ensure the high quality of your dataset: the review workflow, the dashboards, the search engine on advanced quality KPIs, and the plugin systems that we just looked at.
Overall, Kili Technology and foundation models provide a robust set of tools to accelerate the delivery of your machine learning projects and help to focus the human effort where it matters most.
That’s it for our webinar! We invite you to watch the full video here and to start diving into how you can adapt foundation models to reach high accuracy for your machine learning tasks with our next webinar. Finally, we invite you to jump-start your data labeling project on our data labeling tool for free so you can discover the combined power of foundation models and Kili technology!
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

