
.png)


_logo%201.svg)


AI Summary
Building Domain-Specific LLMs: Examples and Techniques
ChatGPT has successfully captured the public’s attention with its wide-ranging language capability. Shortly after its launch, the AI chatbot performs exceptionally well in numerous linguistic tasks, including writing articles, poems, codes, and lyrics. Built upon the Generative Pre-training Transformer (GPT) architecture, ChatGPT provides a glimpse of what large language models (LLMs) are capable of, particularly when repurposed for industry use cases.
As popular as it is, foundational models like GPT, LlaMa, and Falcon are only suitable for downstream tasks with further fine-tuning. While foundational models can perform remarkably well in a broader context, they lack the domain-specific knowledge to be helpful in most industrial or business applications.
In this article, we’ll explore domain-specific LLMs in detail, including possible use cases and ways to create your own custom LLMs.
What is a domain-specific LLM
Domain-specific LLM is a general model trained or fine-tuned to perform well-defined tasks dictated by organizational guidelines. Unlike a general-purpose language model, domain-specific LLMs serve a clearly-defined purpose in real-world applications. Such custom models require a deep understanding of their context, including product data, corporate policies, and industry terminologies.
One major differentiating factor between a foundational and domain-specific model is their training process. Machine learning teams train a foundational model on unannotated datasets with self-supervised learning. Meanwhile, they carefully curate and label the training samples when developing a domain-specific language model via supervised learning.
Why build a domain-specific LLM?
General LLMs are heralded for their scalability and conversational behavior. Everyone can interact with a generic language model and receive a human-like response. Such advancement was unimaginable to the public several years ago but became a reality recently.
Yet, foundational models are far from perfect despite their natural language processing capabilites. It didn’t take long before users discovered that ChatGPT might hallucinate and produce inaccurate facts when prompted. For example, a lawyer who used the chatbot for research presented fake cases to the court.
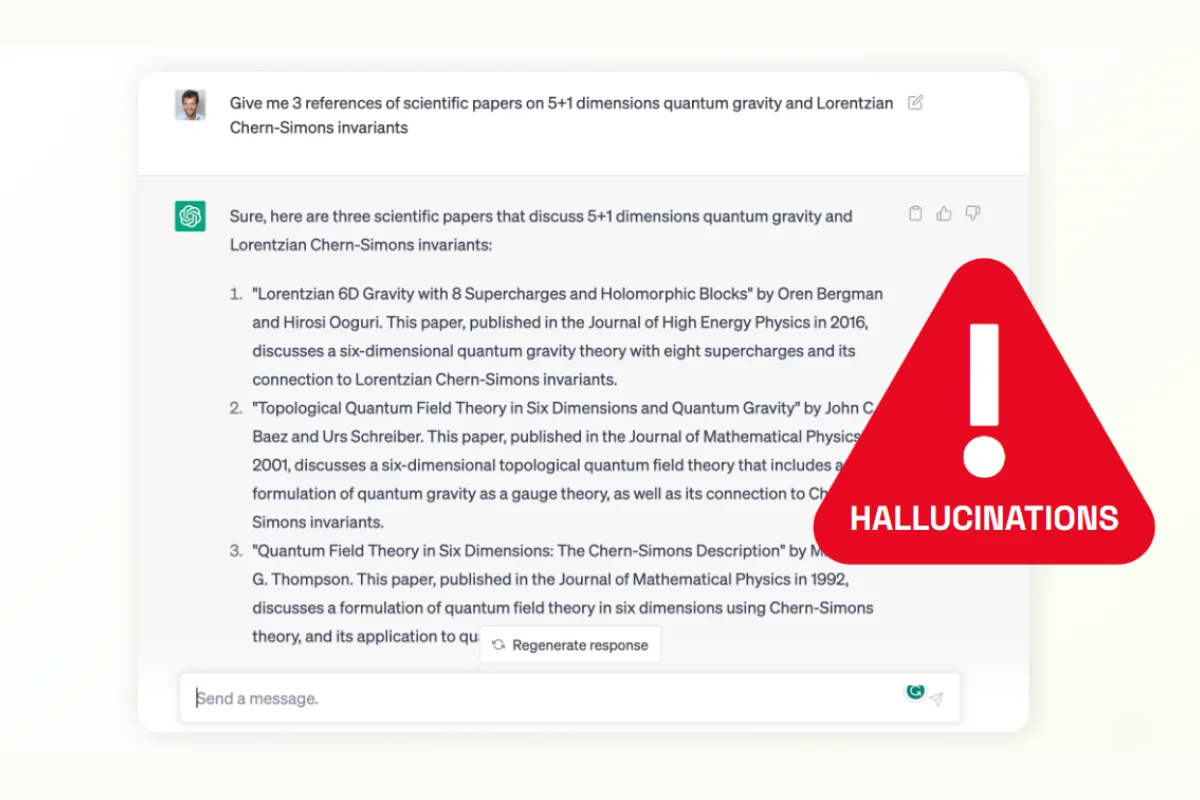
The fact is – foundational models cannot understand the specific context beyond the massive datasets it was trained with. If you didn’t train a language model with legal corpus and apply safeguards to check for fake results, it could concoct made-belief stories or misunderstand the context in court cases.
As we marvel at how LLMs can interact naturally, let’s recall what they truly are. LLMs are powered by neural networks trained to predict linguistic patterns. As such, they can’t differentiate truths in the sense that humans can. Nor can language models associate textual concepts with objects in the real world.
Moreover, some LLMs have difficulty dealing with long contexts. For example, GPT-4 can only handle 4K tokens, although a version with 32K tokens is in the pipeline. An LLM needs a sufficiently large context window to produce relevant and comprehensible output.
So, we need custom models with a better language understanding of a specific domain. A custom model can operate within its new context more accurately when trained with specialized knowledge. For instance, a fine-tuned domain-specific LLM can be used alongside semantic search to return results relevant to specific organizations conversationally.
Examples of Domain-Specific LLMs
Industry leaders were aware of the limitations of general LLMs. So, they set forth to create custom LLMs for their respective industries. These are some examples.
BloombergGPT
BloombergGPT is a causal language model designed with decoder-only architecture. The model operated with 50 billion parameters and was trained from scratch with decades-worth of domain specific data in finance. BloombergGPT outperformed similar models on financial tasks by a significant margin while maintaining or bettering the others on general language tasks.
Med-PaLM 2
Med-Palm 2 is a custom language model that Google built by training on carefully curated medical datasets. The model can accurately answer medical questions, putting it on par with medical professionals in some use cases. When put to the test, MedPalm 2 scored an 86.5% mark on the MedQA dataset consisting of US Medical Licensing Examination questions.
ClimateBERT
ClimateBERT is a transformer-based language model trained with millions of climate-related domain specific data. With further fine-tuning, the model allows organizations to perform fact-checking and other language tasks more accurately on environmental data. Compared to general language models, ClimateBERT completes climate-related tasks with up to 35.7% lesser errors.
KAI-GPT
KAI-GPT is a large language model trained to deliver conversational AI in the banking industry. Developed by Kasisto, the model enables transparent, safe, and accurate use of generative AI models when servicing banking customers.
ChatLAW
ChatLAW is an open-source language model specifically trained with datasets in the Chinese legal domain. The model spots several enhancements, including a special method that reduces hallucination and improves inference capabilities.
FinGPT
FinGPT is a lightweight language model pre-trained with financial data. It provides a more affordable training option than the proprietary BloombergGPT. FinGPT also incorporates reinforcement learning from human feedback to enable further personalization. FinGPT scores remarkably well against several other models on several financial sentiment analysis datasets.
The potential of LLMs in different industries
Large language models marked an important milestone in AI applications across various industries. LLMs fuel the emergence of a broad range of generative AI solutions, increasing productivity, cost-effectiveness, and interoperability across multiple business units and industries.
Banking
The banking industry is well-positioned to benefit from applying LLMs in customer-facing and back-end operations. Training the language model with banking policies enables automated virtual assistants to promptly address customers’ banking needs. Likewise, banking staff can extract specific information from the institution's knowledge base with an LLM-enabled search system.
Retail
In retail, LLMs will be pivotal in elevating the customer experience, sales, and revenues. Retailers can train the model to capture essential interaction patterns and personalize each customer’s journey with relevant products and offers. When deployed as chatbots, LLMs strengthen retailers' presence across multiple channels. LLMs are equally helpful in crafting marketing copies, which marketers further improve for branding campaigns.
Pharmaceutical
Pharmaceutical companies can use custom large language models to support drug discovery and clinical trials. Medical researchers must study large numbers of medical literature, test results, and patient data to devise possible new drugs. LLMs can aid in the preliminary stage by analyzing the given data and predicting molecular combinations of compounds for further review.
Education
LLMs will reform education systems in multiple ways, enabling fair learning and better knowledge accessibility. Educators can use custom models to generate learning materials and conduct real-time assessments. Based on the progress, educators can personalize lessons to address the strengths and weaknesses of each student.
How to Create a Domain-specific LLM
It’s increasingly evident that domain-specific language models are the answer to drive positive changes in various sectors. Industry leaders have repurposed foundation models for specific use cases. The question is – how can you build a large language model tailored to your needs?
There are two ways to develop domain-specific models, which we share below.
Build an entire domain-specific model from scratch
You can train a foundational model entirely from a blank slate with industry-specific knowledge. This involves getting the model to learn self-supervised with unlabelled data. During training, the model applies next-token prediction and mask-level modeling. The model attempts to predict words sequentially by masking specific tokens in a sentence.
Once trained, the ML engineers evaluate the model and continuously refine the parameters for optimal performance. BloombergGPT is a popular example and probably the only domain-specific model using such an approach to date. The company invested heavily in training the language model with decades-worth of financial data.
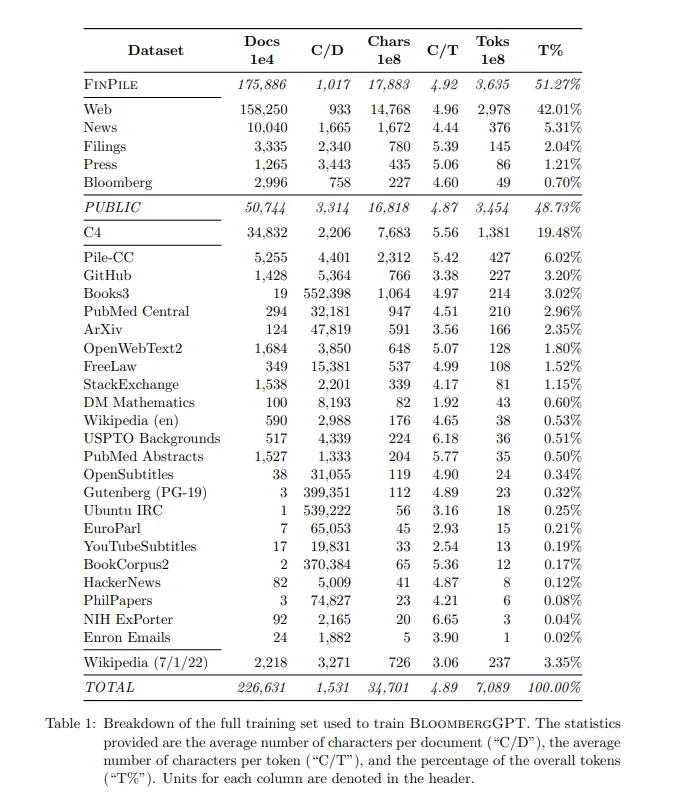
Bloomberg spent approximately $2.7 million training a 50-billion deep learning model from the ground up. The company trained the GPT algorithm with NVIDIA GPU-powered servers running on AWS cloud infrastructure. It took Bloomberg 53 days to complete the training process.
Besides significant costs, time, and computational power, developing a model from scratch requires sizeable training datasets. Curating training samples, particularly domain-specific ones, can be a tedious process. Here, Bloomberg holds the advantage because it has amassed over forty years of financial news, web content, press releases, and other proprietary financial data.
Bloomberg compiled all the resources into a massive dataset called FINPILE, featuring 364 billion tokens. On top of that, Bloomberg curates another 345 billion tokens of non-financial data, mainly from The Pile, C4, and Wikipedia. Then, it trained the model with the entire library of mixed datasets with PyTorch. PyTorch is an open-source machine learning framework developers use to build deep learning models.
If you opt for this approach, be mindful of the enormous computational resources the process demands, data quality, and the expensive cost. Training a model scratch is resource attentive, so it’s crucial to curate and prepare high-quality training samples. As Gideon Mann, Head of Bloomberg’s ML Product and Research team, stressed, dataset quality directly impacts the model performance.
Fine-tune an LLM for domain-specific needs
Notably, not all organizations find it viable to train domain-specific models from scratch. In most cases, fine-tuning a foundational model is sufficient to perform a specific task with reasonable accuracy. This approach requires lesser datasets, computation, and time.
When fine-tuning an LLM, ML engineers use a pre-trained model like GPT and LLaMa, which already possess exceptional linguistic capability. They refine the model’s weight by training it with a small set of annotated data with a slow learning rate. The principle of fine-tuning enables the language model to adopt the knowledge that new data presents while retaining the existing ones it initially learned. It also involves applying robust content moderation mechanisms to avoid harmful content generated by the model.
Usually, ML teams use these methods to augment and improve the fine-tuning process.
Transfer learning
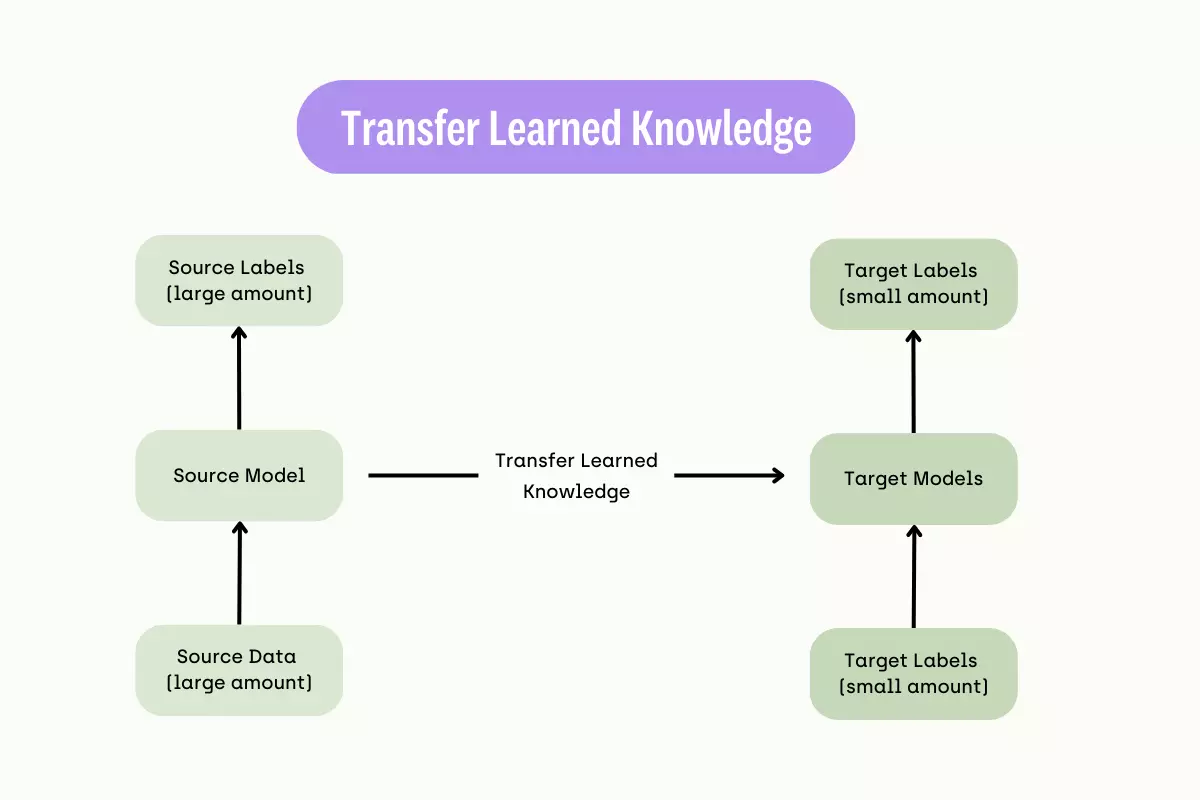
Transfer learning is a unique technique that allows a pre-trained model to apply its knowledge to a new task. It is instrumental when you can’t curate sufficient datasets to fine-tune a model. When performing transfer learning, ML engineers freeze the model’s existing layers and append new trainable ones to the top.
MedPaLM is an example of a domain-specific model trained with this approach. It is built upon PaLM, a 540 billion parameters language model demonstrating exceptional performance in complex tasks. To develop MedPaLM, Google uses several prompting strategies, presenting the model with annotated pairs of medical questions and answers.
With just 65 pairs of conversational samples, Google produced a medical-specific model that scored a passing mark when answering the HealthSearchQA questions. It outscored similar models by a large margin. Google’s approach deviates from the common practice of feeding a pre-trained model with diverse domain-specific data.
While there is room for improvement, Google’s MedPalm and its successor, MedPalm 2, denote the possibility of refining LLMs for specific tasks with creative and cost-efficient methods.
Retrieval-augmented generation
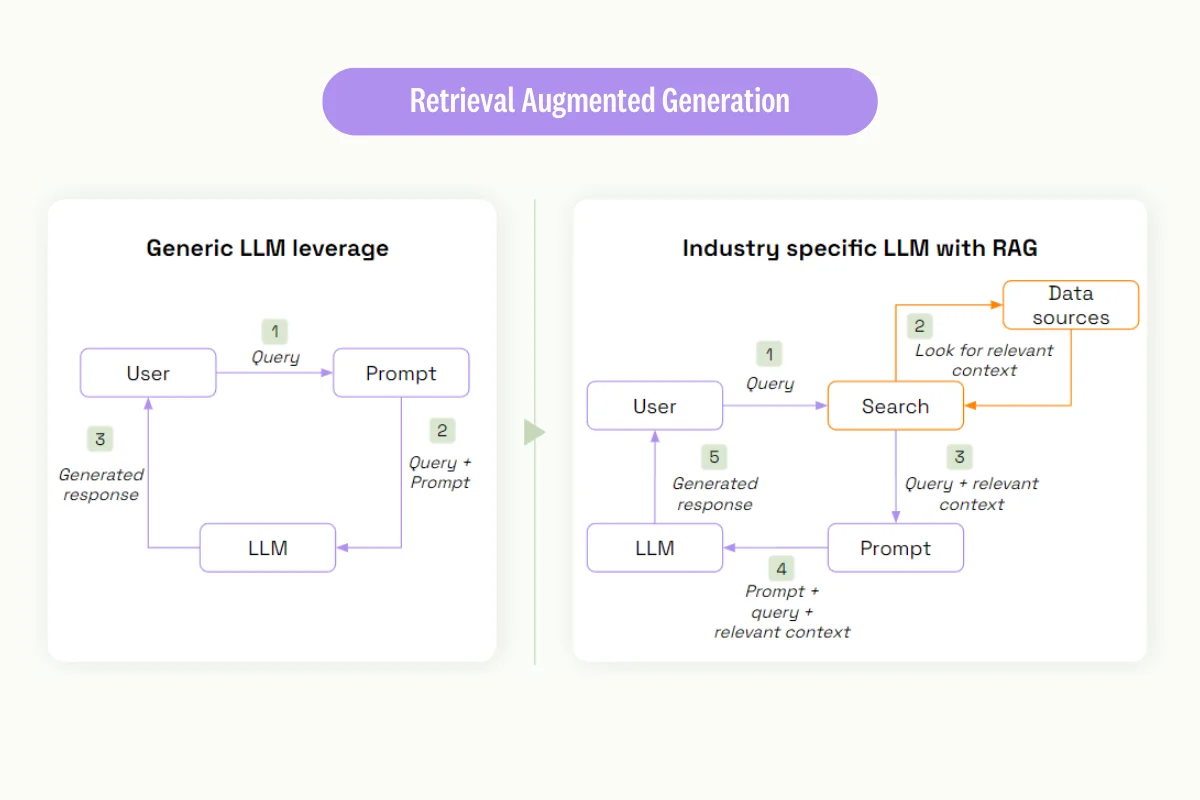
Retrieval-augmented generation (RAG) is a method that combines the strength of pre-trained model and information retrieval systems. This approach uses embeddings to enable language models to perform context-specific tasks such as question answering. Embeddings are numerical representations of textual data, allowing the latter to be programmatically queried and retrieved.
When implemented, the model can extract domain-specific knowledge from data repositories and use them to generate helpful responses. This is useful when deploying custom models for applications that require real-time information or industry-specific context. For example, financial institutions can apply RAG to enable domain-specific models capable of generating reports with real-time market trends.
Build the best domain-specific LLM for your team
The best LLM for your team is one fine-tuned with your data. Our platform empowers start-ups and enterprises to craft the highest-quality fine-tuning data to feed their LLMs. See for yourself.
Best practices for training an LLM
Training and fine-tuning large language models is a challenging task. ML teams must navigate ethical and technical challenges together, computational costs, and domain expertise while ensuring the model converges with the required inference. Moreover, mistakes that occur will propagate throughout the entire LLM training pipeline, affecting the end application it was meant for.
So, use these recommendations to guide your effort in training an LLM.
Start small
Don’t be over-ambitious when training a model. Rather than building a model for multiple tasks, start small by targeting the language model for a specific use case. For example, you train an LLM to augment customer service as a product-aware chatbot. Deploy the custom model, and scale only when it is successful.
Understand scaling laws
Scaling laws in deep learning explores the relationship between compute power, dataset size, and the number of parameters for a language model. The study was initiated by OpenAI in 2020 to predict a model’s performance before training it. Such a move was understandable because training a large language model like GPT takes months and costs millions.
The findings reveal that:
- A larger model will outperform a smaller one when trained on a similar dataset. It takes lesser time for a larger model to achieve the desired performance.
- As you increase the compute budget, expanding the model’s architecture has a more significant impact on model performance than increasing dataset size.
However, DeepMind debunked OpenAI’s results in 2022, where the former discovered that model size and dataset size are equally important in increasing the LLM’s performance.
Prioritize data quality
It’s vital to ensure the domain-specific training data is a fair representation of the diversity of real-world data. Otherwise, the model might exhibit bias or fail to generalize when exposed to unseen data. For example, banks must train an AI credit scoring model with datasets reflecting their customers' demographics. Else they risk deploying an unfair LLM-powered system that could mistakenly approve or disapprove an application.
Data preparation is critical to ensuring fair and accurate LLM. Whether training a model from scratch or fine-tuning one, ML teams must clean and ensure datasets are free from noise, inconsistencies, and duplicates. This is where Kili Technology proves helpful.
Our data labeling platform provides programmatic quality assurance (QA) capabilities. ML teams can use Kili to define QA rules and automatically validate the annotated data. For example, all annotated product prices in ecommerce datasets must start with a currency symbol. Otherwise, Kili will flag the irregularity and revert the issue to the labelers.
Enforce data security and privacy
The amount of datasets that LLMs use in training and fine-tuning raises legitimate data privacy concerns. Bad actors might target the machine learning pipeline, resulting in data breaches and reputational loss. Therefore, organizations must adopt appropriate data security measures, such as encrypting sensitive data at rest and in transit, to safeguard user privacy. Moreover, such measures are mandatory for organizations to comply with HIPAA, PCI-DSS, and other regulations in certain industries.
Monitor and evaluate model performance
Upon deploying an LLM, constantly monitor it to ensure it conforms to expectations in real-world usage and established benchmarks. If the model exhibits performance issues, such as underfitting or bias, ML teams must refine the model with additional data, training, or hyperparameter tuning. This allows the model remains relevant in evolving real-world circumstances.
Conclusion
Domain-specific LLMs are a better fit for knowledge-specific tasks. Leading AI providers have acknowledged the limitations of generic language models in specialized applications. They developed domain-specific models, including BloombergGPT, Med-PaLM 2, and ClimateBERT, to perform domain-specific tasks. Such models will positively transform industries, unlocking financial opportunities, improving operational efficiency, and elevating customer experience.
The insights from various industry-specific LLMs demonstrate the importance of targeted training and fine-tuning. By leveraging high-quality, domain-specific data, organizations can significantly enhance the capabilities and accuracy of their AI models.
Kili Technology excels in providing top-tier data solutions tailored for LLM training and evaluation. Our platform ensures that your models are built and assessed using the finest datasets, removing data quality barriers and enabling the deployment of high-performing LLMs. Consult with our experts to elevate your AI projects today.
Additional Reading and Resources:
- Data Labeling and Large Language Models Training: A Deep Dive
- Foundation Models and LLMs: a Complete Guide
- Exploring Reinforcement Learning from Human Feedback (RLHF): A Comprehensive Guide
- How to fine tune large language models (LLMs) with Kili Technology
FAQs on Domain-Specific LLMs
What types of data do domain-specific large language models require to be trained?
Domain-specific LLMs need a large number of training samples comprising textual data from specialized sources. These datasets must represent the real-life data the model will be exposed to. For example, LLMs might use legal documents, financial data, questions, and answers, or medical reports to successfully develop proficiency in the respective industries.
How do we measure the performance of our domain-specific LLM?
We compare the domain-specific to ground truth data. Ground truth is annotated datasets that we use to evaluate the model’s performance to ensure it generalizes well with unseen data. It allows us to map the model’s FI score, recall, precision, and other metrics for facilitating subsequent adjustments.
What are the challenges of building a domain-specific LLM?
Unlike a general LLM, training or fine-tuning domain-specific LLM requires specialized knowledge. ML teams might face difficulty curating sufficient training datasets, which affects the model’s ability to understand specific nuances accurately. They must also collaborate with industry experts to annotate and evaluate the model’s performance.
Does Kili Technology facilitate fine-tuning an LLM?
Yes. Kili Technology provides features that enable ML teams to annotate datasets for fine-tuning LLMs efficiently. For example, labelers can use Kili’s named entity recognition (NER) tool to annotate specific molecular compounds in medical research papers for fine-tuning a medical LLM. Kili also enables active learning, where you automatically train a language model to annotate the datasets. Learn more about fine-tuning an LLM with Kili here.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

