
.png)
.webp)

_logo%201.svg)


AI Summary
- Data labeling in 2026 is the structured transformation of unlabeled data into supervised signals — not a preprocessing chore but a core part of AI system design.
- Modern labeling spans image, video, text, OCR, and audio modalities, each with distinct task structures that determine how raw data becomes usable training signal.
- Subject matter experts now define labeling logic and arbitrate edge cases, while data scientists design the quality metrics and feedback loops that scale that judgment.
- High-quality data cannot be defined by inter-annotator agreement alone in ambiguous domains — it requires SME-governed thresholds, audit trails, and treatment of quality as a continuous process.
- Enterprise case studies from Covéa, LCL Bank, and Enabled Intelligence show the same patterns recur: domain experts define quality first, automation accelerates throughput, and labeling stays aligned with model evolution.
- Kili Technology operationalizes these patterns through role-based collaboration, quality management, and traceability for governed labeling at enterprise scale.
Introduction: Why Data Labeling Still Defines AI Performance in 2026
As artificial intelligence systems continue to expand across industries, one foundational reality has not changed: machine learning models are only as good as the data they are trained on. At the center of that reality sits data labeling, a critical step in developing high-performance machine learning models, often requiring human involvement to ensure accuracy.
This article answers a deceptively simple question — what is data labeling — while reflecting how the practice has evolved by 2026. Drawing on insights from Kili Technology's 2026 Data Labeling Guide for Enterprises, we explore how modern data labeling combines human expertise, automation, and governance to produce high quality data that drives reliable AI outcomes.
Whether you are a data scientist, business stakeholder, or subject matter expert contributing to AI initiatives, understanding the data labeling process is now essential to building scalable and trustworthy systems.
What Is Data Labeling?

Data labeling is the process of assigning meaningful tags, annotations, or structured labels to raw data so it can be used as training data for machine learning algorithms. These labels provide the ground truth that allows a machine learning model to learn patterns, make predictions, and improve performance over time. High-quality, accurate labels are essential; poor labels lead to biased, unreliable, or wrong AI outcomes.
In simple terms, when we label data, we translate human understanding into a form that machines can learn from.
So when asking what is data labeling, the most accurate definition in 2026 is this:
Data labeling is the structured transformation of unlabeled data into supervised signals that enable machine learning, deep learning models, and artificial intelligence systems to learn reliably and at scale.
Why Data Labeling Matters for Machine Learning
Modern machine learning applications — from autonomous vehicles to document intelligence — depend on massive volumes of accurate data labeling. Without it:
- Supervised learning fails to converge
- Models inherit bias or ambiguity
- Predictions degrade in real-world deployment
High-quality training data enables:
- Faster model training
- Better generalization to new data points
- More stable performance across edge cases
This is why data labeling work is no longer treated as a mechanical preprocessing step, but as a core part of AI system design.
Labeled vs. Unlabeled Data: A Practical Example
To understand what is an example of labeled data, consider a computer vision model trained for object detection.
- Unlabeled data: Raw images of street scenes
- Labeled data: The same images annotated with bounding boxes around cars, pedestrians, and traffic signs

Each bounding box represents a labeled data point that helps the model learn how to identify objects in new images. This same principle applies across text data, audio files, and video.
The Modern Data Labeling Process (Step by Step)
A typical data labeling process in 2026 includes multiple interconnected stages. A hybrid approach that combines automation with human oversight is often the most effective strategy for labeling data.
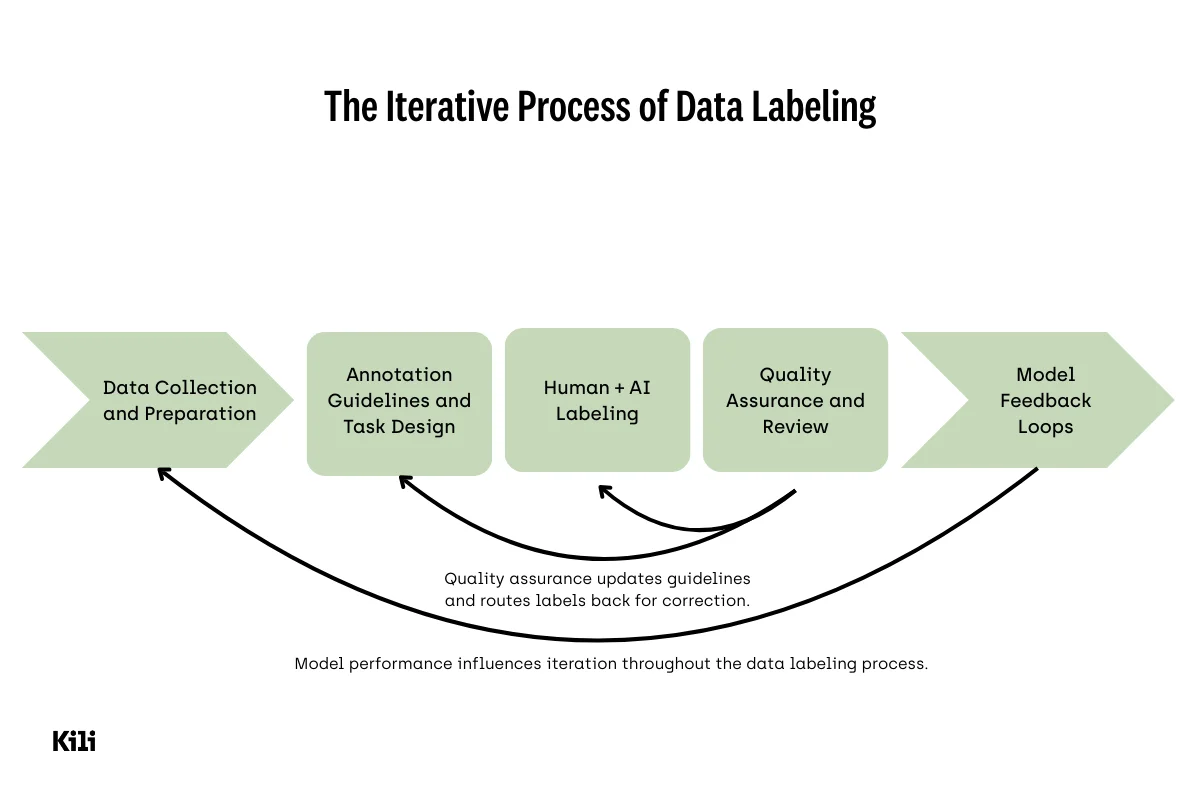
1. Data Collection and Preparation
Organizations gather real data, synthetic data, or pre existing datasets relevant to the problem domain. This phase emphasizes the need to collect diverse data that reflects real-world variation. Collecting diverse data helps minimize dataset bias and improves model performance.
2. Annotation Guidelines and Task Design
Clear annotation guidelines reduce ambiguity and cognitive load for human labelers, improving consistency across labeling tasks.
3. Labeling Execution
Depending on the use case, labels are applied by:
- Internal subject matter experts
- Managed data labeling teams
- Crowdsourced data labeling
- Or systems that automatically apply labels using heuristics or models
4. Quality Assurance and Review
A structured quality assurance process validates labels against ground truth standards, often through consensus review or expert adjudication
5. Model Feedback Loops
Through active learning, models surface uncertain data points for human review, reducing labeling effort while improving data quality.
Types of Data Labeling in 2026
In 2026, data labeling spans multiple data modalities and supports a wide range of machine learning applications. Each modality relies on well-defined data labeling tasks and data annotation techniques that determine how raw data is transformed into training data for supervised learning.
Understanding the types of data labeling used across modalities is necessary to design effective labeling workflows, select appropriate labeling tools, and ensure that labeled data supports reliable machine learning model performance.
Image and Computer Vision Labeling
Image data labeling prepares visual raw data for computer vision systems. These labeling tasks allow machine learning algorithms to identify patterns, objects, and spatial relationships within images.
Object Detection
Object detection is a computer vision data labeling task that involves identifying objects and assigning their location within an image. Objects are labeled using bounding boxes, which specify both the object category and its position.
This form of data labeling is used when models must detect and localize objects such as vehicles, products, or people.
Image Classification
Image classification assigns one or more labels to an entire image. The label applies globally rather than to individual regions or objects.
This task is commonly used to automatically categorize images for content moderation, dataset organization, and medical imaging triage.
Automatically Categorize Images
Automatically categorizing images relies on supervised data labeling projects where humans label data to define category boundaries. These labeled data points become high quality training data used to train machine learning models that later classify new images automatically.
Segmentation and Shape-Based Annotation (Pixel-Level Labeling)
Some computer vision applications require pixel-level data labeling, where each pixel in an image is assigned a class label.
Pixel-level data annotation includes:
- Semantic segmentation, where all pixels belonging to a class (e.g. road, building, vegetation) share the same label
- Instance segmentation, where pixels are labeled by both class and object instance
- Polygons, which outline object boundaries with near pixel-level precision
- Segmentation masks, which store dense pixel-level labels used directly during model training
Bounding boxes, by contrast, provide coarse localization and are used when approximate object location is sufficient.
Pixel-level labeling is essential for computer vision models used in medical imaging, geospatial imagery, autonomous systems, and industrial inspection.
Video Labeling
Video data labeling extends image annotation across time, introducing temporal dependencies into the data labeling process.
Video Object Detection and Tracking
Objects are labeled and tracked across frames so that a machine learning model can identify the same object over time.
Temporal Classification
Temporal classification assigns labels to time segments rather than individual frames, enabling models to recognize actions, events, or scene changes.
Video labeling supports applications such as autonomous driving, surveillance, and activity recognition.
Text and NLP Labeling
Text data labeling supports natural language processing (NLP) and natural language processing models, including document intelligence systems and large language models.
Sentiment Analysis
Sentiment analysis labels text data based on expressed emotion or opinion, such as positive, negative, or neutral sentiment.
Named Entity Recognition (NER)
Named entity recognition identifies and labels spans of text that represent entities such as people, organizations, locations, dates, or monetary values.
Machine Translation
Machine translation relies on labeled parallel text data, where source and target language sentences are aligned to train supervised learning models.
Text data annotation is critical for training NLP systems used in search, analytics, and LLM fine-tuning.
Document Processing and OCR Data Labeling
Document processing and OCR (Optical Character Recognition) data labeling focuses on extracting structured information from documents such as invoices, contracts, forms, and reports.
OCR Transcription
OCR labeling converts scanned documents or images of text into machine-readable text. Human labelers validate OCR outputs to create accurate ground truth for machine learning models.
Document Classification
Documents are labeled by type (e.g. invoice, receipt, contract), enabling models to route documents to appropriate downstream workflows.
Layout and Structure Annotation
Layout labeling identifies document elements such as headers, tables, paragraphs, signatures, and key-value pairs. These data labeling tasks preserve spatial and semantic structure.
Entity and Field Extraction
Specific fields (e.g. invoice number, total amount, dates, names) are labeled to train models for information extraction and document intelligence.
Document and OCR data labeling is foundational for enterprise automation, compliance, and financial processing systems.
Audio and Speech Labeling
Audio data labeling prepares sound-based raw data for speech recognition and audio processing systems.
Speech Transcription
Speech transcription converts spoken language in audio recordings into text, often including timestamps and speaker segmentation.
Speaker Identification and Diarization
Speaker labeling assigns speaker identities to segments of audio, while diarization determines who spoke when in multi-speaker recordings.
Intent and Event Labeling
Audio segments may be labeled for intent, emotion, or acoustic events to support conversational AI systems.
Audio Segmentation
In audio labeling, the data labeling process involves dividing audio files into time-based segments and attaching labels to each segment.
Who Does Data Labeling Work?
Why Expert Human-in-the-Loop (HITL) Workflows Are No Longer Optional
A common question is: what are data labeling jobs?
In 2026, data labeling work has moved far beyond generic annotation. As machine learning systems are deployed in higher-stakes and more complex environments, labeling increasingly requires contextual judgment, not just pattern recognition. Human-in-the-loop (HITL) leverages the judgment of human data labelers to create, train, fine-tune, and test machine learning models.
Examples of today's data labelers could be:
- Subject matter experts (SMEs) validating edge cases and resolving ambiguity where labels are not directly observable
- Linguists working on natural language processing tasks such as sentiment analysis, entity disambiguation, and intent modeling
- Medical professionals annotating clinical notes, imaging data, and diagnostic signals under strict regulatory constraints
- Geospatial analysts labeling satellite and aerial imagery, where interpretation depends on domain-specific visual cues and temporal context
What unites these roles is not annotation speed, but decision-making authority. Many modern labeling tasks require inference rather than direct observation — for example, determining intent in text data, crop health in geospatial imagery, or risk level in compliance documents.
This is why expert human-in-the-loop (HITL) workflows have become central to scalable data labeling strategies. Rather than labeling everything manually, SMEs are embedded at critical control points:
- defining labeling logic and annotation guidelines
- validating low-confidence or high-impact data points surfaced by models
- arbitrating disagreements in multi-pass review workflows
Meanwhile, data scientists design labeling strategies, quality metrics, and feedback loops that ensure expert decisions translate into measurable improvements in machine learning model performance. In this structure, human expertise is used where it creates the most value — not as a bottleneck, but as a governing layer over automation.
.webp)
Automation, Programmatic Labeling, and Human-in-the-Loop
Modern data labeling platforms increasingly rely on:
These approaches automatically apply labels at scale, but still treat them as probabilistic signals rather than absolute truth. Human experts review, correct, and validate these labels — a hybrid approach documented in model-based workflows. Programmatic labeling uses rules or pre-trained algorithms to automatically assign labels, minimizing human intervention.
These approaches automatically apply labels at scale, but still treat them as probabilistic signals rather than absolute truth. Human experts review, correct, and validate these labels — a hybrid approach documented in model-based workflows.
Data Quality, Ground Truth, and Governance
Why "High-Quality Data" Is Harder to Define Than It Sounds
High-performing AI systems require more than labeled data — they require shared agreement on what "correct" means.
At a minimum, this includes:
- clear definitions of ground truth
- continuous monitoring of label drift as data distributions change
- versioned datasets with full audit trails linking labels to decisions
However, the real challenge lies in defining high quality data in domains where labels are inherently ambiguous or probabilistic.
In many enterprise use cases:
- the "correct" label may depend on context
- multiple interpretations may be reasonable
- edge cases may dominate real-world error rates
For example, in document intelligence or NLP tasks, intent or sentiment may not be explicitly stated. In medical or geospatial imagery, visual signals often require expert interpretation rather than binary classification.
As a result, high-quality data labeling is rarely defined purely by inter-annotator agreement or accuracy scores. Instead, quality definitions are typically guided by SMEs, who:
- establish domain-specific labeling thresholds
- decide how uncertainty should be represented or escalated
- define which errors are acceptable and which are critical
Best practices therefore emphasize multi-step review, hierarchical labeling, and expert validation workflows that evolve over time. Quality is treated as a governed process, not a static property of a dataset.
This governance-oriented view of ground truth is essential for maintaining trust in machine learning systems as they scale across teams, geographies, and regulatory environments.
Common Data Labeling Challenges
Why Cost, Time, and Cognitive Load Persist at Scale
Despite advances in automation and tooling, data labeling remains one of the most resource-intensive components of machine learning development. This is not just anecdotal — it is well supported by research across human–computer interaction and applied machine learning.
Time and Cost Constraints Are Structural
Multiple studies show that data preparation and labeling consume a disproportionate share of AI project resources. Research on AI-assisted human labeling demonstrates that even with intelligent interfaces and automation, annotation remains inherently time-intensive due to the need for human judgment, verification, and rework at scale.
Industry analyses further note that labeling costs grow non-linearly as task complexity increases, particularly when expert validation is required. This makes labeling one of the primary bottlenecks in deploying supervised learning systems in production environments.
Cognitive Load Directly Impacts Label Quality
Beyond time and cost, cognitive load is a critical — and often underestimated — challenge. Recent research into interactive and LLM-assisted annotation workflows shows that poorly designed interfaces and unclear annotation logic significantly degrade annotation consistency, especially for non-trivial tasks.
As cognitive load increases, annotators are more likely to:
- default to superficial patterns
- drift from annotation guidelines
- introduce inconsistency over time
This effect is amplified in long-running labeling projects, where fatigue and task switching further reduce reliability.
Ambiguity Without Expert Input Leads to Silent Failure
Finally, studies consistently show that ambiguous labeling tasks converge on plausible but incorrect labels when expert input is absent. In domains such as natural language processing, compliance, healthcare, and geospatial imagery, labels often require inference rather than direct observation. Without domain expertise, models may train successfully — but on fundamentally flawed ground truth.
Taken together, these findings reinforce a central conclusion: labeling challenges are systemic, not incidental. They cannot be solved through scale or automation alone, but require deliberate workflow design and expert oversight.
Best Practices for Data Labeling in 2026
What Enterprise Case Studies Show Works in Practice
Across enterprise deployments, several best practices consistently emerge as effective. These are patterns observed in production-grade AI systems supported by Kili Technology.
Embed Domain Experts Early and Continuously
In large-scale NLP deployments, Covéa labeled over 1.5 million customer feedback comments by combining automated pipelines with expert-defined taxonomies and structured review stages. This approach ensured that sentiment and intent labels aligned with real business meaning rather than surface-level text patterns.
Design Collaborative, Auditable Workflows
In regulated environments, LCL Bank implemented collaborative document labeling workflows that integrated business experts directly into the annotation and validation loop. By combining secure infrastructure, versioned datasets, and expert review, the bank enabled scalable model training while maintaining governance and traceability.
Combine Automation With Expert Quality Gates
For high-stakes geospatial applications, Enabled Intelligence layered automated preprocessing with expert validation and multi-step quality checks. This hybrid approach achieved accuracy levels exceeding 95 %, a requirement for operational use in defense, disaster response, and infrastructure monitoring contexts.
Patterns Across Successful Projects
Across these cases, the same principles recur:
- domain experts define what quality means before labeling begins
- automation accelerates throughput but does not replace judgment
- quality metrics focus on error severity and drift, not just agreement
- labeling is treated as a continuous process aligned with model evolution
These practices align with enterprise-grade quality frameworks and reinforce a broader lesson: beyond just volumes of data, high-performing machine learning systems are built on governed, expert-validated data.
The Strategic Role of Data Labeling Platforms
As machine learning systems scale in volume, complexity, and organizational reach, dedicated data labeling platforms are required to manage labeling operations effectively. Manual coordination, disconnected tools, and informal review processes do not support the levels of consistency, traceability, and quality control expected in production AI systems.
A modern data labeling platform provides the operational structure needed to coordinate people, workflows, and models throughout the data labeling lifecycle. Platforms such as Kili Technology illustrate how these requirements are addressed in practice.
Coordinating Human Expertise and Technical Teams
Data labeling increasingly involves multiple contributors with different roles, including human labelers, subject matter experts, reviewers, and data scientists. A centralized platform is necessary to:
- manage role-based access and responsibilities
- route data to the appropriate level of expertise
- ensure expert validation is applied where ambiguity or risk is highest
Kili supports these collaboration patterns by enabling structured review stages and expert oversight directly within labeling workflows, ensuring that domain knowledge is consistently applied across datasets.
Managing Complex Labeling Workflows
Many labeling tasks now require multi-step or hierarchical workflows, particularly in domains such as computer vision, geospatial imagery, and document intelligence. A modern platform is required to:
- define and enforce workflow stages
- support multiple annotation passes and review loops
- track progress and decisions across labeling iterations
Kili's workflow configuration capabilities allow teams to formalize these processes, reducing ambiguity and minimizing rework as datasets evolve.
Enforcing Quality Assurance at Scale
Quality assurance cannot be applied reliably through spot checks or manual reviews once datasets reach production scale. Data labeling platforms provide:
- built-in quality metrics
- reviewer comparison and disagreement tracking
- auditability of labeling decisions over time
Kili's quality management features enable teams to monitor labeling consistency and detect deviations as new data is introduced or labeling guidelines change.
Integrating Labeling With Model Development
Data labeling must remain connected to model performance to be effective. Modern platforms support:
- exporting labeled data in formats compatible with machine learning pipelines
- model-based pre-annotation and active learning workflows
- feedback loops between model outputs and labeling priorities
By supporting these integrations, platforms like Kili allow teams to adjust labeling efforts based on observed model behavior, rather than treating datasets as static assets.
Operationalizing the Labeling Lifecycle
Modern data labeling platforms provide the infrastructure required to:
- maintain dataset versioning and traceability
- align labeling outputs with governance and compliance requirements
- support continuous iteration as models and data distributions change
In practice, platforms such as Kili Technology enable organizations to operationalize data labeling as a repeatable, governed process rather than an ad hoc activity. This operational structure is necessary to sustain model performance, data quality, and organizational accountability as AI systems scale.
Conclusion: Why Data Labeling Is Still the Foundation of AI
In 2026, data labeling defines how machine learning systems learn, generalize, and perform in real-world environments. Labeled data determines which patterns models recognize, how edge cases are handled, and how uncertainty is resolved during inference.
Data labeling encodes human judgment, domain expertise, and governance into datasets used for supervised learning. These decisions shape model behavior long after training is complete and influence reliability, fairness, and operational risk across deployments. Data labeling can enhance accuracy, quality, and usability in multiple contexts across industries.
Organizations that invest in accurate data labeling, expert oversight, and scalable labeling workflows — whether through internal teams or professional data labeling services — achieve more stable model performance and faster iteration cycles. Labeling strategies that integrate quality assurance, expert review, and continuous improvement enable teams to adapt datasets as data distributions and business requirements evolve. Choosing the right data labeling approach can significantly impact the success of a project.
As AI systems increasingly influence decisions in regulated, safety-critical, and customer-facing contexts, high-quality labeled data remains a prerequisite for trustworthy machine learning. Data labeling is therefore not a supporting task, but a foundational capability in the development and operation of AI systems. For teams evaluating external providers, our reviewed guide to the best data labeling services in 2026 covers the full competitive landscape.
Frequently Asked Questions
What is data labeling in simple terms?
Data labeling is the process of adding meaningful tags or annotations to raw data — images, text, audio, or video — so that machine learning models can learn from it. Every supervised AI model depends on labeled examples to understand what correct output looks like for a given input.
What is the difference between data labeling and data annotation?
The terms are often used interchangeably. In practice, "data labeling" typically refers to assigning a category or classification to an entire data point, while "data annotation" can include more granular tasks like drawing bounding boxes on images or highlighting named entities in text. Both fall under the same discipline.
Why is data labeling important for AI?
Without high-quality labeled data, machine learning models cannot generalize reliably. Poor labels introduce noise that compounds through training — leading to models that perform well on benchmarks but fail in production. Data labeling is the foundation that determines whether an AI system actually works.
What are the most common types of data labeling?
The most common types include image classification, object detection with bounding boxes, semantic segmentation, text classification, named entity recognition, sentiment analysis, audio transcription, and video frame-by-frame annotation. The right approach depends on the modality and the use case.
How much does data labeling cost?
Costs vary widely depending on data type, task complexity, required expertise, and volume. Simple image classification can cost fractions of a cent per label, while specialized medical or legal annotation requiring domain experts can cost several dollars per data point. Platform tooling, workforce management, and quality control all factor into total cost.
Can data labeling be automated?
Partially. Pre-labeling with model-assisted annotation can accelerate the process by 2-5x, but human review remains essential for quality-critical tasks. The most effective workflows combine automated pre-annotation with human-in-the-loop validation to balance speed and accuracy.
What tools are used for data labeling?
Data labeling platforms like Kili Technology provide annotation interfaces, workforce management, quality analytics, and automation features in one system. Teams can also use open-source tools, but these typically lack the collaboration, QA workflows, and enterprise security features that production-scale projects require.
Start Labeling Smarter, Not Harder
Kili Technology gives you the annotation platform, quality controls, and workforce management tools to build production-grade training data at scale. Whether you're labeling images, text, video, or documents, the platform supports every modality with configurable workflows and enterprise-grade security.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
