
.png)


_logo%201.svg)


AI Summary
Introduction
Many applications, such as chatbots and content generators, are using Large Language Models (LLMs) to create human-like text. Despite their impressive demonstrations, there is a noticeable contrast between controlled scenarios and real-life situations. The true potential of LLMs is tested when they are deployed in dynamic, real-world environments.
This article will recap our recent webinar on building conversational engines with LLMs. This edition will analyze the effectiveness and viability of LLMs in practical applications and how to leverage Kili Technology for their evaluation.
Watch the Full Webinar
LLMs show promise in accelerating the building of text-based applications such as chatbots and question-answering interfaces. But evaluating, knowing when to fine-tune, and fine-tuning LLMs is no small feat. Our recent webinar covers these topics to help you build your LLM apps successfully.

The Reality vs. Demonstrations
Every time an impressive LLM demonstration surfaces, it invariably raises the bar of expectations. These demos are often cherry-picked for maximum impact and portray perfection. However, the journey from a controlled demo to a robust application is fraught with unexpected complexities.
One of the foremost challenges is genuine language understanding. While LLMs excel at mimicking human-like text generation, genuine comprehension remains elusive. This becomes evident when the model encounters ambiguities, nuances, or context-specific details.
To illustrate, one of the more popular LLM applications, ChatGPT, was tested on common health questions. For some basic questions, it responded accurately. However, it also gave unclear, misleading, or potentially harmful advice. In one example, the LLM did not differentiate the two types of diabetes and even mixed up their symptoms when advising on the disease. The inability of LLM apps, such as ChatGPT, to fully comprehend the implications of their responses in sensitive realms like health underscores the challenges in bridging the gap between mimicking human-like text and understanding the true essence of the language and its context.
Production of large language models (LLMs) also raises security concerns due to their potential to generate misleading or harmful content, requiring robust checks and safeguards. For example, Google's demo of Bard made a factual error on the origin of the first image of a planet outside the solar system. ChatGPT has also been used to conjure up fake news and research, such as the ones unearthed by The Guardian.
Lastly, the versatility of LLMs can also be a double-edged sword. While they are generalists and can cater to a wide array of domains, they might not be specialists in any. For instance, while an LLM might perform well in general conversational tasks, it may fall short in a specialized domain like autonomous vehicle control, where domain-specific knowledge and contextual adaptability are crucial.
Take, for instance, the research study detailed in this article, which delves into complex details about stem cell differentiation and gene regulation. If an LLM, such as GPT-3, is used to summarize or provide a layman's explanation of this article, it may struggle to convey the intricate scientific concepts and jargon involved accurately. The LLM, being a generalist model, might oversimplify or misinterpret the nuanced details critical to understanding this specialized field of stem cell research.
Deep Dive into Evaluations
Evaluation is the compass that guides the development and refinement of LLMs. To understand the true capabilities of an LLM, it's imperative to evaluate its performance meticulously. At the heart of this lies the question: "How well does the model cater to specific tasks?"
The essence of evaluations transcends mere accuracy metrics. It delves into the model's comprehension, its responsiveness, and its ability to generate content that's both relevant and factually sound. For instance, while an LLM might generate a coherent and grammatically correct response, it's equally important for the response to be contextually appropriate and factually accurate.
Furthermore, evaluations serve as the bedrock during various stages of model deployment. Be it during the developmental phase, where metrics like accuracy, precision, and recall offer insights into the model's performance, or during the production phase, where real-time metrics can offer glimpses into the model's real-world efficacy. Evaluations not only help in measuring the effectiveness of a system but also in identifying areas of improvement, potential bugs, and ensuring that system upgrades don't inadvertently introduce regressions.
Importance of Evaluations

Evaluations, often considered the backbone of refining and perfecting Large Language Models (LLMs), play a pivotal role in ensuring these models meet and exceed the standards set for them. But why are they so crucial?
- Measuring System Effectiveness: The need to measure the system's effectiveness is at the forefront of evaluations. Does the model understand the task at hand? Does it generate accurate, relevant, and context-aware outputs? These evaluations ensure the LLM's performance is up to par and the outputs align with the set objectives.
- Identifying Bugs or Regressions: With their vast architectures and intricate neural networks, LLMs can occasionally have unforeseen issues. Evaluations act as a diagnostic tool, highlighting anomalies, bugs, or regressions in the model. Identifying these early on ensures that potential shortcomings are addressed, making for a more robust and reliable LLM.
- Monitoring System Changes at Scale: As LLMs learn and adapt, their performance can drift, especially when scaled up and exposed to vast and varied datasets. Evaluations provide a mechanism to monitor these changes, ensuring that the model remains consistent in its outputs, even as it scales.
Where Evaluations Take Place
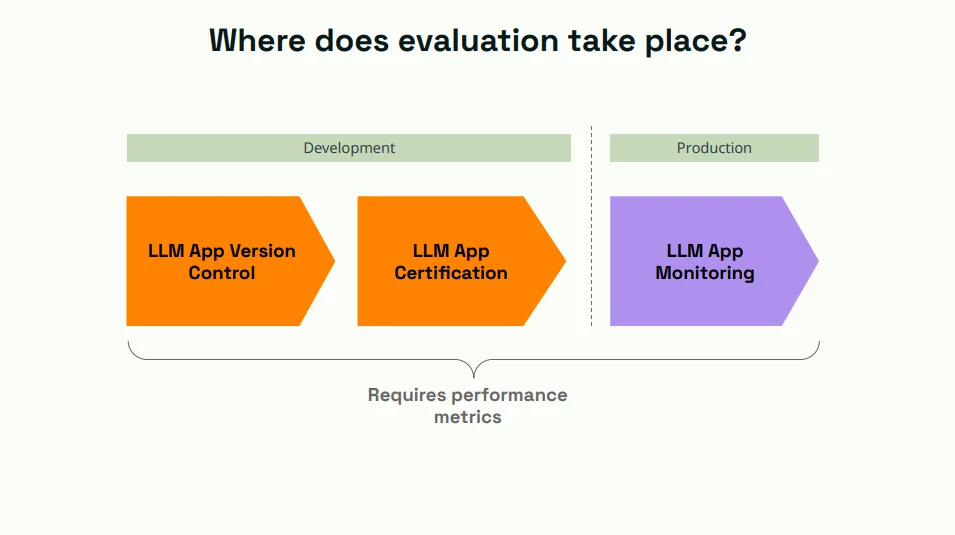
But where do these evaluations transpire? The journey of an LLM from development to production is marked by continuous evaluations, each serving a specific purpose.
- LLM App Version Control (Development): During the development phase, the LLM undergoes what is termed as 'version control.' Here, every iteration of the model is meticulously tracked. This not only allows developers to ensure that each version meets the set standards but also offers the flexibility to revert to previous versions if needed. This process requires stringent performance metrics, ensuring that every version of the LLM is consistent and reliable.
- LLM App Certification (Development): Before making the leap to production, the LLM must be certified. This certification process assures stakeholders that the LLM has met predefined standards and is ready for real-world applications. Like version control, this too is anchored in rigorous performance metrics, ensuring that the model is both accurate and efficient.
- LLM App Monitoring (Production): Once deployed, the LLM's journey doesn't end. In the production environment, the model is continuously monitored. This real-time and long-term tracking analyzes the LLM's outputs, ensuring they align with the expected results. Any deviations can be quickly identified and rectified, making sure that the LLM remains effective in its real-world applications.
Challenges in Evaluating Generative AI Models
Generative AI models, especially Large Language Models (LLMs), have revolutionized the field of artificial intelligence with their ability to generate human-like text. However, evaluating these models poses unique challenges.
- Complexity of Outputs: Unlike traditional models that might predict a single value or a label, generative models produce complex textual outputs. This could range from a single word to paragraphs of coherent text. Ensuring these outputs' accuracy, relevancy, and coherence across diverse prompts becomes challenging.
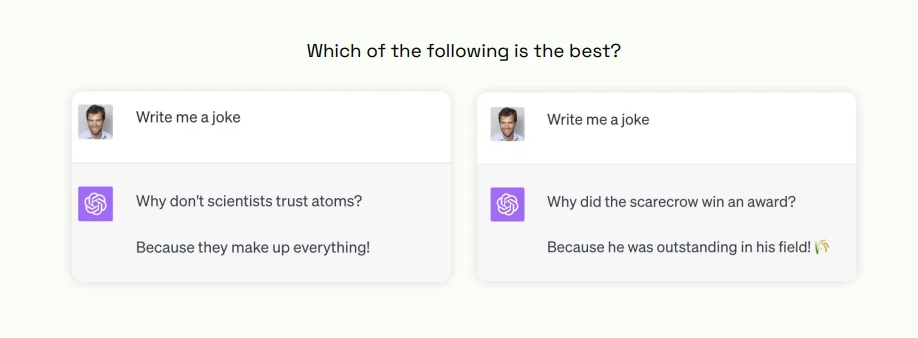
- Subjectivity in Outputs: Generative models might be tasked with producing inherently subjective outputs. For instance, how does one evaluate which joke is 'better' if tasked to tell a joke? Such subjective outputs, influenced by cultural, personal, or contextual factors, are hard to evaluate objectively.
Desirable Properties of Metrics for Evaluating LLMs
For the evaluation to be effective, the metrics used need to have certain properties.
- Multi-domain Aspect: LLMs can generate content spanning multiple domains, from casual conversations to technical content. Hence, metrics should be able to evaluate the model's output across various domains, ensuring consistency and accuracy.
- Multi-dimensional Aspect: Evaluations should not be limited to just one facet of the output. They should assess comprehension, relevance, creativity, logic, and factuality, among others. This ensures a holistic assessment of the model.
- Accuracy in Relation to Human Judgments: While numerical metrics are essential, they should correlate well with human judgments. If a metric rates an output highly, but human evaluators find it lacking, the metric's utility is questionable.
- Scalability: Given the vast amounts of data LLMs can process and the numerous outputs they can generate, evaluation metrics need to be scalable. They should provide quick and accurate evaluations without extensive manual intervention.
Evaluation Techniques
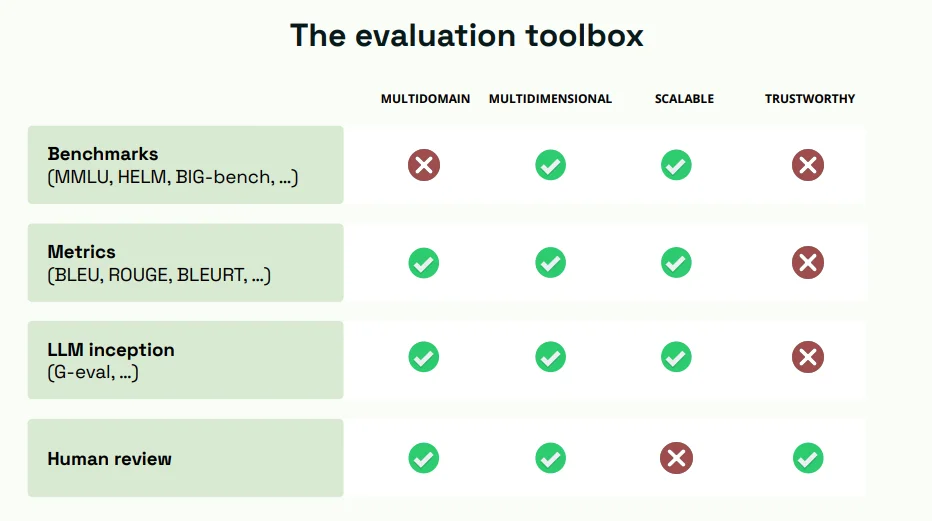
a. Benchmarks:
Benchmarks provide standardized tasks that models can be tested against. While they offer a structured way to assess models, their relevance might be limited to specific domains. Additionally, while they might be trustworthy for certain tasks, they may not capture the nuances of real-world applications.
b. Traditional NLP Metrics (e.g., Blue, Rouge):
These metrics, developed for natural language processing tasks, can be applied to evaluate LLMs. However, their correlation with human judgments has been found lacking at times. For instance, while they might focus on string matches, they might miss out on evaluating semantic correctness or relevancy.
c. LLM-Based Techniques (LLM Inception):
An emerging technique involves using other large language models to evaluate the outputs. An example is Gval by Microsoft, which leverages powerful LLMs to assess outputs. While this method offers scalability, it's only as accurate as the evaluating model.
d. Human Review:
Human evaluators provide a layer of subjective assessment, ensuring the model's output aligns with human expectations. While it's arguably the most trustworthy method, finding experts across diverse domains can be challenging. Additionally, it might not be scalable, especially for vast datasets.
Start building high quality datasets in 48 hours
Our Kili Simple offer is the quickest and easiest way way to have your dataset labeled by a professional workforce with 95% quality assurance.
Practical Evaluation in a Software like Kili
When it comes to practical evaluation of LLMs, platforms like Kili Technology play a crucial role in streamlining the process.
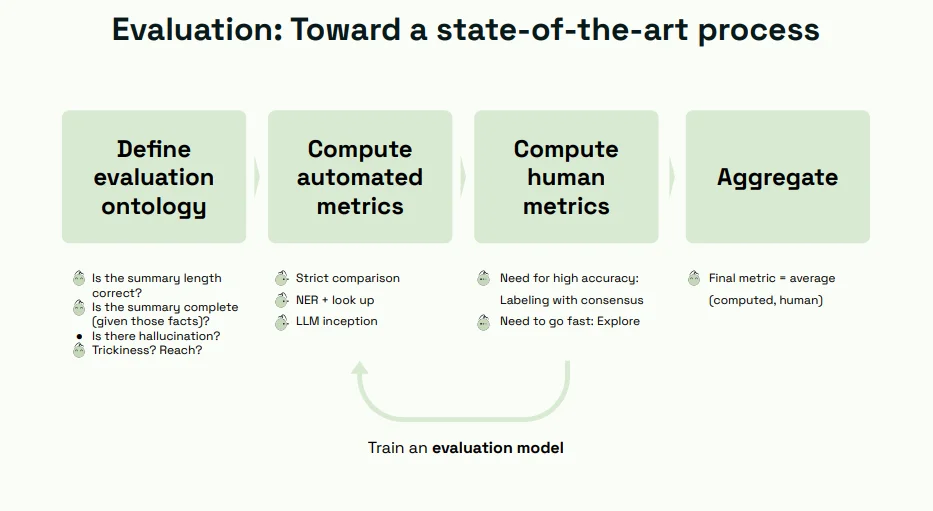
- Defining an Evaluation Ontology:
One of the initial steps in practical evaluation is to define an evaluation ontology. This framework outlines the criteria on which the model will be assessed. It includes summary length, completeness, absence of hallucinations, and overall quality. An ontology ensures that evaluations are consistent and aligned with the objectives.
- Computing Automated Metrics:
Automated metrics provide a quick way to assess the LLM's outputs at scale. These metrics can include quantitative measurements of correctness, relevance, and coherence. In conjunction with the evaluation ontology, automated metrics offer a structured approach to assessment.
- Manual Reviews and Consensus:
Human reviews are indispensable in evaluating LLMs, especially tasks requiring subjective judgment. Expert reviewers assess outputs for accuracy, relevance, and overall quality. A consensus approach can be employed to mitigate individual biases, where multiple reviewers evaluate the same output. This ensures a more balanced and fair assessment.
- Aggregating Stats and Training Models:
As evaluations progress, the insights gained can be used to aggregate statistics and even train models specifically for evaluations. This iterative process improves the accuracy and efficiency of evaluations over time.
Demo: How to Evaluate LLMs with Kili Technology

Watch video
Conclusion
In Large Language Models, evaluations stand as the litmus test, the yardstick against which their capabilities are measured. These evaluations, however, are far from straightforward due to the complexity of the outputs and the inherent subjectivity in assessing creative tasks.
While various evaluation techniques exist, no single method can capture all aspects effectively. A balanced approach that combines the strengths of different techniques, including benchmarks, traditional NLP metrics, LLM-based assessments, and human reviews, provides a more comprehensive evaluation.
Use Kili to Evaluate LLMs
Kili Technology is a pivotal tool in practical evaluation, offering tools and frameworks that streamline the process. Request a demo from our team to learn how Kili Technology can speed up your LLM evaluation and fine-tuning for your domain-specific needs.
As we navigate the evolving landscape of LLMs, it becomes clear that a comprehensive evaluation approach, balancing automated metrics with human judgment, is the key to harnessing the full potential of these remarkable models.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
