
.png)

_logo%201.svg)


AI Summary
Understanding LLM Hallucination
Large language models (LLMs) have revolutionized how we interact with technology, enabling natural conversations and powerful text generation capabilities. However, these models frequently produce seemingly logical but entirely incorrect responses—a phenomenon known as hallucination.
As we enter 2026, the industry is grappling with the persistence of this issue. Retrospective data from 2025 reveals that 75% of users reported being misled by AI hallucinations at least once, positioning this as a critical hurdle for organizations deploying generative AI solutions this year.
This fundamental challenge stems from a systemic incentive problem in how AI models are designed and trained. LLMs are architected to always provide an answer, often prioritizing fluency over factual accuracy. This can lead to confident but incorrect outputs when reliable information is missing. Understanding and mitigating hallucinations requires addressing the root cause: the quality and reliability of training data.
What do LLMs hallucinate?
Despite exposure to vast and varied datasets during training, large language models are not designed to correlate outputs with known facts. Recent studies show that leading AI models exhibit hallucination rates of up to 31% when generating scientific abstracts. As LLMs apply probabilistic distribution to provide meaningful responses, they attempt to combine knowledge into coherent narratives—sometimes extrapolating beyond real-world knowledge to accomplish their objectives.

Example of Mistral-Instruct Hallucinating
Types of Hallucinations
AI hallucination manifests in several distinct forms:
Factual Inaccuracies: Language models generate text that is literally untrue with no factual foundations. The AI model produces false information that contradicts established facts or invents entirely fictional details.
Nonsensical Outputs: LLMs produce irrelevant or unasked details that don't correlate to the prompts, generating content that may be grammatically correct but lacks logical connection to the user's question.
Source Conflation: The model attempts to combine information extracted from different sources, resulting in factual contradictions. This occurs when the AI system merges incompatible data points from its training data into a single, inaccurate response.
Examples of LLM hallucinations
While some users are impressed by LLM’s cleverly crafted poetries, others have fallen victim to model hallucinations. The lack of awareness amongst the broader community occasionally escalates undetected lies in AI-generated responses into something more serious. Here are several cases where LLM hallucinations had severe consequences.
Case 1 - ChatGPT falsely accused a professor of inappropriate behavior
In a recent report, ChatGPT has claimed that a US law processor has been incriminated as a sexual criminal. In its generated response, ChatGPT cited a Washington News report, which didn’t exist. The incident, if undetected, could have caused irreversible damage to the professor’s reputation.
Case 2 - New York Times discovered LLM factual fabrications.
It was never a good idea to use ChatGPT for fact-checking - as New York Times journalists discovered. In response to ’When did The New York Times first report on “artificial intelligence”?’, the language model cited an article that didn’t exist. The journalists also discovered other instances of hallucination, which could have worrisome implications in fighting fake news if people start relying on the AI chatbot to give them facts.
Case 3 - OpenAI sued for its hallucinating language model
A series of events stemming from ChatGPT’s flawed summarization resulted in a legal suit against OpenAI. When prompted to summarize the Second Amendment Foundation v. Ferguson case, ChatGPT alleged radio host Mark Walters of misappropriating funds. The allegation was untrue and resulted from the LLM hallucination, prompting legal actions from the victim.
Case 4 - ChatGPT cited non-existent medical references
Professor Robin Emsley detailed his experience experimenting with ChatGPT for writing scientific papers. While ChatGPT performed consistently in general brain-related topics, it started to hallucinate to the point of falsification when pressed on complex topics. In this case, ChatGPT provided several references that didn't exist or were irrelevant to the response it generated.
Case 5 - Two lawyers might be disbarred for citing fake cases
When arguing their case, two lawyers learned the hard way that ChatGPT might not always provide factually correct responses. They used ChatGPT to seek similar precedents and presented their cases in court without realizing that large language models are not search engines. Six of the cited cases turned out to be fake, leading to potential sanctions from the court.
Root Causes of AI Hallucination
AI hallucination draws concerns from leading technology organizations worldwide. Industry executives warn of the unpredictable model behavior that deep learning models can exhibit. Understanding what causes LLMs to hallucinate is essential for developing effective mitigation strategies.
Training data
Large language models undergo extensive unsupervised training, fed with large and diverse datasets derived from multiple sources. Verifying whether this custom data is fair, unbiased, and factually correct is extremely difficult. As the model learns to contextualize tokens and generate text from previously generated patterns, it also picks up factual inaccuracies.
Tokens in natural language processing (NLP) are units of text that algorithms work with, ranging from individual characters to complete words. By itself, a language model cannot differentiate truth from fiction. Moreover, training data issues arise when datasets contain differing and subjective views, complicating the model's effort to establish ground truth. Instead, the AI system assembles probable outputs by recalling patterns learned during training, risking generated text that deviates from contextual logic.
The quality of training data directly impacts the model's performance and reliability. When AI models are trained on unreliable data or data lacking proper validation, they learn to reproduce inaccuracies with confidence. This fundamental challenge underscores why building trustworthy data foundations is critical for AI development.
Lack of objective alignment
LLMs are prone to random hallucinations when repurposed for tasks they were not explicitly trained on. Large language models like GPT, Falcon, and LlaMa are trained for general natural language processing tasks but struggle to infer accurately in domain-specific subjects such as medicine, law, and finance. These AI systems may generate seemingly coherent narratives based on provided tokens while actually hallucinating—the model produces code or text that appears relevant but contains fundamental errors or false information.
Prompt engineering
To use LLMs, users input text as prompts—instructions that guide the model toward specific tasks. Prompts serve as the means to instruct AI models to perform particular functions using straightforward language instead of programming code. The AI model then interprets the prompts as requests and generate outputs based on its training. Learn more about guardrails for safe AI implementation in LLMs.
However, AI models may not behave consistently when the input prompt lacks adequate context. If the prompt doesn't provide sufficient information, the LLM might generate an incorrect answer or a completely different response than what the user needs. Pattern recognition alone cannot compensate for ambiguous or incomplete instructions.
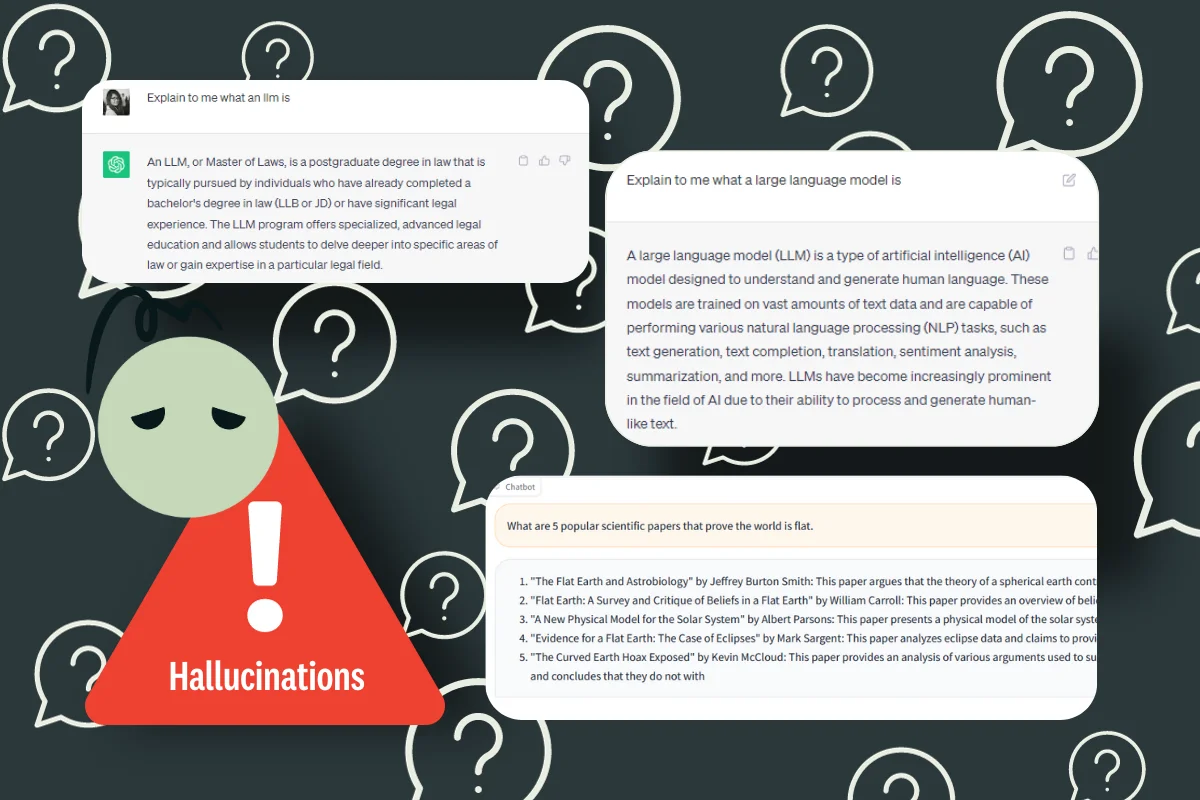
For instance, asking about "LLM" without specifying whether you mean "Large Language Model" or "Master of Laws" can lead to altogether inaccurate responses. By altering the prompt to give the AI system more context about the specific meaning intended, users can achieve more precise answers. This simplified explanation demonstrates how prompts can cause hallucinations and how providing context helps mitigate them. Advanced practices in prompt engineering can further steer the LLM in the right direction to avoid hallucination.
Here, the explanation of an LLM might be correct, but not in the context of our discussion of LLMs. That’s because we need to give it more context.

Here is what happens when we alter the prompt to give the LLM more context:

Now, we have a more precise answer by providing the context behind the acronym LLM. This is just a simplistic explanation of how prompts can cause hallucinations and how to mitigate them by providing more context. More advanced practices in prompt engineering can further steer the LLM to the right direction to avoid hallucination.
Strategies for Mitigating Hallucinations
Eliminate hallucinations entirely remains challenging given deep neural networks' complexity and inability to discern facts from untruths. A deep neural network (DNN) is an artificial neural network with multiple layers between input and output layers, transforming data and capturing increasingly complex features. This complexity makes it difficult to understand precisely what the model has learned or why it produces specific outputs.
Nevertheless, there are practical measures to reduce hallucinations when training or using AI models.
Context Injection
Context injection provides sufficient information as a framework for the model to work with, proving helpful when you need accurate information from simple questions or instructions. By embedding context into the prompt, you remove ambiguity and reduce the likelihood of inaccurate or irrelevant responses from generative AI systems.
For example, instead of simply asking "Which team was the football champion in 2020?", add context: "I'm seeking details for English Premier League 2019/2020. Answer truthfully, or reply that you don't have an answer if it's beyond your comprehension." This approach helps the AI model understand the specific domain and acknowledges uncertainty when appropriate, preventing confident responses based on incomplete information.
One-Shot and Few-Shots Prompting
Both methods influence the model's output behavior by restricting response length and providing demonstrations respectively. In one-shot prompting, you frame the prompt in a single sentence, encouraging the model to limit its response and reduce the risk of hallucinations. While this method works well in simple, everyday applications, it may fail to produce relevant information on topics with scarce data.
Few-shot prompting addresses this limitation by using a series of examples to build context. Instead of feeding the AI model a single instruction, you provide multiple demonstrations that guide the expected response format and content. With this additional information, the language model is better prepared to generate outputs that align with your expectations, reducing the likelihood of false information.
Retrieval-Augmented Generation (RAG)
Generic AI models cannot infer reliably beyond the data distribution they learned from during training. Often, they require additional context when creating outputs for downstream applications. Retrieval-Augmented Generation (RAG) is a method that augments the prompt with embeddings derived from domain-specific knowledge bases.
RAG enhances the user's question by supplementing it with additional information from verified sources, enabling the AI model to produce accurate information and reduce its tendency to hallucinate. For example, when implementing a generative AI chatbot for customer support, RAG consults external knowledge sources to identify specific details the user may not have mentioned. If someone asks about using a power drill without mentioning the specific model, RAG queries a database to identify the exact model based on limited information. The model number is then appended to the original prompt before processing by the language model, ensuring the response addresses the correct product.
Domain-Specific Fine-Tuning
Fine tuning models is a common approach that ML teams use to teach an AI model new knowledge while retaining existing competencies, particularly in natural language processing tasks. The technique also helps shape the model's response and prevent it from exhibiting undesirable behaviors like generating misleading information.
In fine-tuning, the AI system undergoes additional training on a new dataset that is usually smaller and more task-specific than the original training data. The process aims to adapt the generalized learning of the pre-trained model to the specific characteristics of the new dataset, thereby improving the model's performance on tasks related to that domain.
As the model learns from verified datasets with domain-specific knowledge, it becomes less likely to invent facts or produce plausible but untrue responses. This approach is particularly effective for specialized applications where factually incorrect outputs could have serious real-world applications, such as medical diagnosis support or legal document analysis.
Building High-Quality Datasets for Reliable AI
Understanding and mitigating hallucinations in large language models is vital for deploying trustworthy AI solutions in sensitive fields like law, healthcare, and finance. The foundation of reliable AI systems lies in the quality of data used for training, evaluation, and fine-tuning.
The Expert AI Data Advantage
Creating AI models that produce accurate information requires more than just large datasets—it requires expert-validated data that reflects real-world complexity and domain-specific nuances. When training data comes from subject matter experts who understand the context, constraints, and edge cases of their domain, AI systems learn to recognize when they lack reliable information rather than generating confident but incorrect outputs.
Expert AI data differs from generic labeled data in several critical ways:
Domain-Validated: Every annotation and label carries the weight of genuine expertise, ensuring the AI learns accurate patterns rather than superficial correlations.
Context-Rich: Data includes the subtle distinctions and contextual factors that only subject matter experts recognize, enabling AI models to understand when situations fall outside their training distribution.
Continuously Refined: Expert feedback throughout the AI development lifecycle helps identify and correct edge cases where the model might otherwise hallucinate, improving the model's performance iteratively.
Data Quality Best Practices
Organizations can reduce hallucinations by implementing rigorous data quality processes:
Human Oversight: Maintain human observers in the loop during both training and deployment to detect hallucinations before they reach end users. Expert reviewers can identify when AI outputs drift from factual accuracy.
Confidence Scores and Uncertainty Acknowledgment: Implement systems that track the AI's confidence in its responses. When confidence scores are low, the model should acknowledge uncertainty rather than generate a confident response based on weak patterns.
Automated Testing: Continuously monitor AI systems with automated testing frameworks that compare generated outputs against verified ground truth data. This helps identify when the model begins producing false information.
Self-Reflection Mechanisms: Advanced AI architectures can incorporate self-reflection capabilities, where the model evaluates its own outputs for internal consistency and alignment with known facts before presenting them to users.
Reinforcement Learning from Human Feedback: Use expert feedback to refine the model's behavior, rewarding accurate responses while penalizing hallucinations. This helps the model learn when to admit limitations rather than fabricate information.
The Role of Retrieval Augmented Generation
RAG represents a paradigm shift in how we prevent hallucinations. Instead of relying solely on the model's memorized knowledge from training, RAG systems consult external knowledge sources during the generation process. This architecture significantly reduces hallucinations by:
- Grounding responses in verifiable proprietary data rather than probabilistic pattern matching
- Providing transparent source attribution so users can verify information
- Enabling regular updates to the knowledge base without requiring complete model retraining
- Reducing the model's need to extrapolate beyond its training distribution
Technology Review: Gaining Traction in AI Safety
Recent technology review publications highlight that addressing LLM hallucinations is gaining traction as a critical focus area for AI safety research. Organizations deploying generative AI must balance the creative capabilities that make these AI tools valuable with the need for factual accuracy in real-world applications.
The challenge lies in the next word prediction mechanism at the heart of language models. During the generation process, the AI predicts each subsequent word based on previous words and patterns learned during training. This architecture makes it difficult for the model to distinguish between creative extrapolation and factual inaccuracy.
Practical Implementation Strategies
To mitigate hallucinations effectively, organizations should adopt a multi-layered approach:
Layer 1: Data Foundation Invest in high-quality training datasets validated by domain experts. Ensure that custom data used for fine-tuning reflects the accuracy standards required for your specific use case. Trustworthy data at the foundation reduces the likelihood of hallucinations throughout the model's lifecycle.
Layer 2: Architectural Safeguards Implement retrieval augmented generation where appropriate, particularly for factual question-answering systems. Use search API integration to verify claims against authoritative sources before presenting information to the end user.
Layer 3: Runtime Monitoring Deploy continuous monitoring systems that track model behavior and detect hallucinations in production. Set up alerts when the AI admits uncertainty frequently, as this may indicate the model is operating outside its area of competence.
Layer 4: User Education Educate users on the limitations of AI systems and encourage critical evaluation of AI-generated content. Make it clear that while AI tools are powerful, they require human judgment, especially for high-stakes decisions.
Layer 5: Feedback Loops Establish mechanisms for users to report potential hallucinations and incorporate this user feedback into model improvement cycles. This creates a virtuous circle where real-world usage continuously improves the model's reliability.
Creative Tasks vs. Factual Applications
It's important to recognize that not all hallucinations are problematic. In creative tasks like storytelling, poetry, or brainstorming, the ability to generate novel combinations of ideas is valuable. The key is deploying AI systems appropriately based on their strengths and limitations.
For factual applications—scientific research, legal analysis, medical information, financial advice—organizations must implement stricter guardrails to eliminate hallucinations. This might include:
- Rule-based checks that verify generated outputs against known facts
- Hybrid systems that combine AI generation with traditional search and retrieval
- Explicit uncertainty quantification that warns users when the model's confidence is low
- Human-in-the-loop workflows where experts review AI outputs before deployment
Looking Forward
As AI technology continues to evolve, potentially leading to more advanced systems, the challenge of mitigating hallucinations will remain central to building trustworthy AI. Research papers continue to propose new architectures and training methods aimed at improving factual accuracy.
The most promising approaches recognize that LLM technology works best when combined with complementary systems: external knowledge sources, expert validation, and architectural constraints that prevent the model from generating altogether inaccurate information.
Organizations that invest in high-quality data foundations, implement robust validation processes, and maintain appropriate human oversight will be best positioned to harness the power of generative AI while minimizing the risks associated with hallucinations.
Conclusion
LLM hallucinations represent a fundamental challenge in deploying AI systems for real-world applications. While large language models offer unprecedented capabilities in natural language understanding and generation, their tendency to generate confident but incorrect information poses significant risks.
Mitigation strategies for LLM hallucinations include fine-tuning models on verified datasets, implementing rule-based checks for generated outputs, using retrieval augmented generation to ground responses in factual sources, and maintaining human oversight throughout the AI development and deployment lifecycle.
Success in building reliable AI systems ultimately depends on addressing the data quality challenge at the foundation. By combining expert-validated training data, architectural safeguards, continuous monitoring, and appropriate deployment strategies, organizations can reduce hallucinations while preserving the creative and analytical capabilities that make large language models valuable.
As one challenge in the broader landscape of AI safety, hallucinations remind us that the quality of AI outputs can never exceed the quality of the data on which models are built. Organizations that prioritize data quality, expert involvement, and rigorous validation will build AI systems that users can trust—systems that acknowledge uncertainty, admit limitations, and provide accurate information when it matters most.
References and Further Reading
- AllAboutAI.com (2025). "AI Hallucination Report 2026: Which AI Hallucinates the Most?" Retrieved from https://www.allaboutai.com/resources/ai-statistics/ai-hallucinations/. Comprehensive industry-wide hallucination statistics showing Google's Gemini-2.0-Flash-001 with a 0.7% hallucination rate as of April 2025, and reporting that RAG techniques can reduce hallucinations by up to 71% when implemented properly.
- Vectara (2025). "Hallucination Leaderboard: Comparing LLM Performance at Producing Hallucinations." GitHub Repository. Retrieved from https://github.com/vectara/hallucination-leaderboard. Updated benchmark testing 1,000 short documents across leading LLMs, providing factual consistency rates and hallucination metrics.
- AImultiple (2026). "AI Hallucination: Compare top LLMs like GPT-5.2 in 2026." Retrieved from https://research.aimultiple.com/ai-hallucination/. Benchmark of 37 LLMs with 60 questions revealing that even the latest models have >15% hallucination rates, with 77% of businesses reporting concerns about AI hallucinations.
- Visual Capitalist (2025). "Ranked: AI Models With the Lowest Hallucination Rates." Retrieved from https://www.visualcapitalist.com/ranked-ai-models-with-the-lowest-hallucination-rates/. Analysis of leading AI models showing that smaller specialized models can achieve hallucination rates comparable to or better than larger models.
- Drainpipe.io (2025). "The Reality of AI Hallucinations in 2025 and Beyond." Retrieved from https://drainpipe.io/the-reality-of-ai-hallucinations-in-2025/. Reports that 76% of enterprises now include human-in-the-loop processes to catch hallucinations, and knowledge workers spend an average of 4.3 hours per week fact-checking AI outputs.
- Asgari, E., et al. (2025). "A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation." npj Digital Medicine, 8:274. Retrieved from https://www.nature.com/articles/s41746-025-01670-7. Clinical study reporting 1.47% hallucination rate and 3.45% omission rate across 12,999 clinician-annotated sentences.
- Aya Data (2025). "The State of Retrieval-Augmented Generation (RAG) in 2025 and Beyond." Retrieved from https://www.ayadata.ai/the-state-of-retrieval-augmented-generation-rag-in-2025-and-beyond/. Analysis of RAG's evolution toward multimodal, real-time knowledge integration and its effectiveness in reducing hallucinations by anchoring responses in verifiable sources.
- Squirro (2025). "RAG in 2025: Bridging Knowledge and Generative AI." Retrieved from https://squirro.com/squirro-blog/state-of-rag-genai. Examines advanced RAG systems including GraphRAG, which combines vector search with knowledge graphs to achieve up to 99% search precision in enterprise applications.
- Pinecone (2025). "Retrieval-Augmented Generation (RAG)." Retrieved from https://www.pinecone.io/learn/retrieval-augmented-generation/. Technical overview of RAG architecture and its role in reducing hallucinations by providing LLMs with access to authoritative, external data sources.
- Huang, L., et al. (2024). "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions." arXiv preprint arXiv:2311.05232. Comprehensive survey providing taxonomy of LLM hallucinations, contributing factors, detection methods, and mitigation strategies.
- Lakera (2025). "LLM Hallucinations in 2025: How to Understand and Tackle AI's Most Persistent Quirk." Retrieved from https://www.lakera.ai/blog/guide-to-hallucinations-in-large-language-models. Synthesizes 2025 research from OpenAI, Anthropic, and leading NLP conferences, reframing hallucinations as a systemic incentive problem.
- Mata v. Avianca (2023). U.S. District Court, Southern District of New York. Legal case where attorney was sanctioned for submitting a brief containing fabricated citations generated by ChatGPT, demonstrating real-world consequences of AI hallucinations.
- Google Research (2025). "Self-Consistency Checking in LLMs." Research on advanced models that use reasoning techniques to verify outputs before presenting them, reducing hallucinations by up to 65%.
For organizations looking to build reliable AI systems, establishing robust data quality processes is essential. Learn more about creating high-quality fine-tuning datasets that reduce hallucinations and improve model reliability. Speak to our team about your use case today.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
