
.png)


_logo%201.svg)


AI Summary
Foundation Models and Large Language Models (LLMs): Definition
What characterized the modern renaissance of AI systems over the last decade was the ability to match/outperform human capabilities in a narrow domain when performing model training on broad data. Taking this approach has obviously enabled us to make considerable progress in embedding AI in many applications. However, this has also led to a lot of work replication and limitations when solving tasks requiring some form of higher-order common knowledge. To overcome these limitations and provide a base layer of common AI knowledge, Foundation Models have been created. Foundation Models represent, in fact, a new generation of models trained on a large corpus of labeled/unlabeled data, providing all the groundwork to enable the model to perform a wide variety of different tasks with minimal fine-tuning efforts. One of the most common approaches used nowadays to create Foundation Models are Transformers-based model architectures. If you want to learn more about Transformers, additional info is available in our previous article on Synthetic Data.
Foundation models
What distinguishes Foundation Models from other traditional machine learning model architectures is that they are not created to excel at a specific task in mind but just to provide the best base possible to build great specific AI models on top of them. This approach takes, in fact, traditional Transfer Learning methods used, for example, in Image Classification tasks, a step ahead. Creating much more general models and reducing drastically the need to update the weights associated with the last few layers of the model architecture as part of the fine-tuning process to specialize our model in domain-specific tasks. For example, a Large Language model can be first trained on broad data to capture the essence of language understanding and then be fine-tuned to answer specific questions about medical records, math exams, etc. These models are created through self-supervised learning, creating labels directly from the input and training data (e.g., artificially removing a word from a sentence and asking the foundation model to predict it).
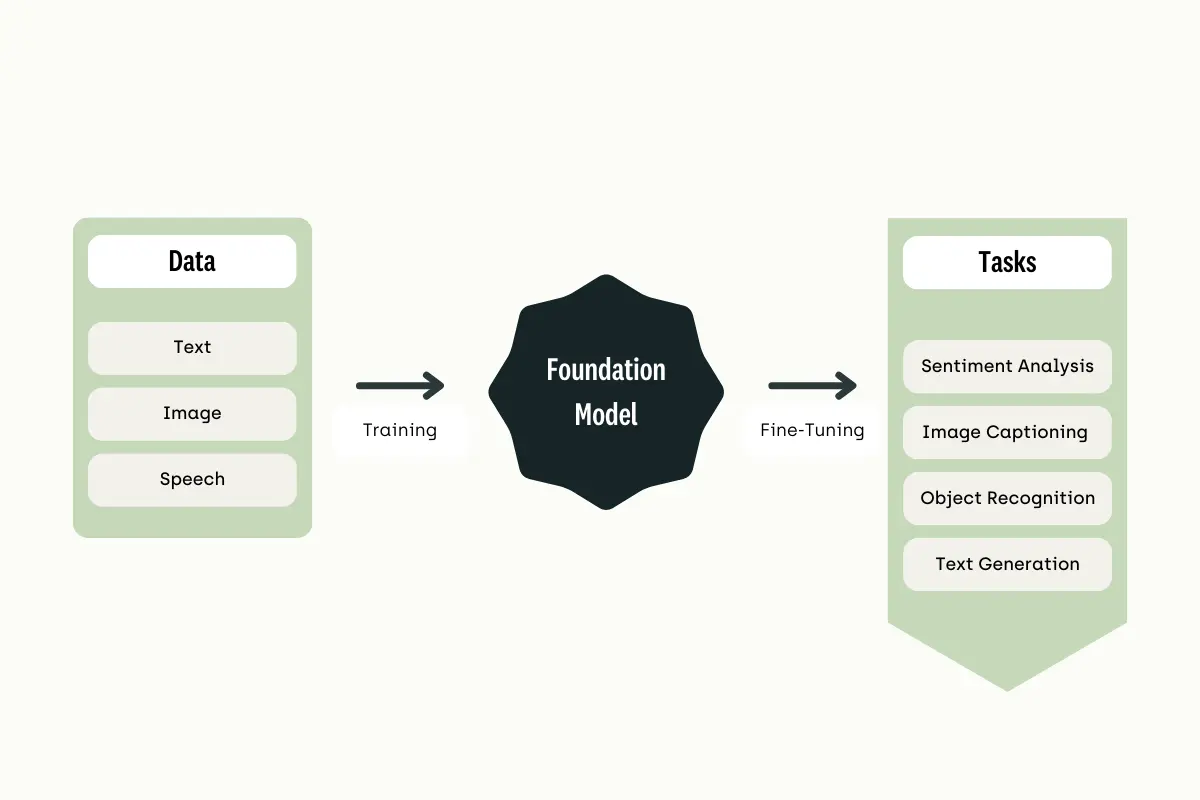
From data to tasks with foundation model
Foundation Model Landscape
Existing Foundation Models have been demonstrated to be particularly effective in fields such as Natural language processing and Computer vision with foundation models such as GPT-3, Stable Diffusion, DALL-E 2, BERT, etc.
The Stanford Center for Research on Foundation Models
The term Foundation model was coined after a critical research study carried out by the Stanford Institute for Human-Centered Artificial Intelligence. Stanford has then developed also a Center for Research on Foundation Models in order to try better to understand these types of models and ensure they can be deployed responsibly, also creating a new benchmark for their evaluation and the instruction-following model Alpaca.
Following the creation of Foundation models, another term particularly captured the attention of public interest: Generative AI. Generative AI is another term used to encompass all the different types of AI models (e.g., transformers, diffusion models, etc.) able to create new forms of content (e.g., text, music, code, images, etc.).
LLMs
Large Language models are an application of the wider research area of Language Modelling. Conversational models' main focus is calculating probabilities to predict what should be the next word in a sentence. Repeating this process in a loop, we can then be able to create large chunks of text given an initial prompt.
Language Modelling can be divided into 4 key development areas:
- Statistical Language Models: based on predicting words using Markov models (e.g., the most recent previous input should be used as guiding context). Varying the context length, different types of models can then be created (e.g., bigram, trigram, etc.). One of the key issues associated with these models is the curse of dimensionality (e.g., by increasing the order, the number of transition probabilities increases by an exponential factor).
- Natural Language Models: based on using artificial neural networks (ANNs) to accomplish various language processing tasks. Two of the most notable contributions from using this approach are the creation of neural network architectures to generate word embeddings (e.g., word2vec, Glove, Skip-Gram) and using Recurrent Neural Networks to create longer dependencies between current and previous input characters.
- Pre-trained language models: with the popularization of the first attention-powered transform-based models, such as BERT by Google, it was then possible to successfully create context-aware word representations. Pre-trained models, such as BERT, RoBERTa, etc., could then be used as a base for other application-specific models going through lengthy fine-tuning processes (initiating a paradigm shift with respect to previous standalone model architectures applications).
- Large Language Models: starting from the success of pre-trained language models, the research community began exploring the effects of creating bigger deep learning transformer models trained on even bigger datasets. This led to the creation of Large Language Models, which, thanks to their greater scale, managed to acquire new emergent capabilities compared to smaller pre-trained language models.
Two of the most interesting finding from Large Language Models are their inherent scaling laws and emergent abilities.
Scaling Laws
- According to OpenAI researchers, in fact, model performance can be mathematically estimated in advance by considering just 3 key factors: model size, dataset size, and amount of training compute.
- Google DeepMind team demonstrated instead that also the amount of computing budget relative to model and data size could be optimized in advance by following numerical equations.
New emergent capabilities:
- In-context learning: large scale models can be able to learn new specific tasks by just showing them some examples (few-shots approach) or providing specific instructions without needing to update the model gradients or requiring additional training. Early studies, show in fact that these types of models could potentially be able to create small neural network architectures inside of them to quickly learn new tasks without requiring the main external architecture to be updated.
- Instruction following: these models can be fine-tuned on a wide range of applications by providing them with collections of tasks outlined via a series of instructions. These datasets of instructions can then be generated by programmatically applying templates to existing datasets. Breaking down problems into a series of instructions will then make it easier for models to be able to combine their pre-existing knowledge with the instruction to solve previously unseen tasks.
How to help LLM to solve previously unseen tasks
- Step-by-step reasoning (chain of thoughts): in the same way, we humans can find really difficult to tackle complex problems simultaneously. Also, LLMs might struggle when asked to calculate directly a solution. To alleviate this type of issue, we can then try to explicitly ask our model to provide its reasoning step by step instead of returning direct computations. Taking this approach consistently demonstrated improved performance by the LLMs when approaching multi-step tasks such as mathematical tricks.
Following the success of applications such as ChatGPT, to easily interact with GPT-based models in a chat environment, prompt engineering has become more and more important. In order to formulate clear prompts to present a model for human interaction, there are 2 key principles to keep in consideration:
- Specifying clear and specific instructions (e.g., formulating questions within delimiters, requiring structured outputs, asking to explicitly validate assumptions before making conclusions, providing the model an example before asking him to complete a task).
- Ask the model not to rush directly to conclusions (e.g., forcing the model to explicitly work out its solution rather than just answering, including in the prompt all the intermediary steps we expect to see in the output).
Making use of these two principles, we can then try to iteratively improve the quality of our prompt to get back from the model the best results possible. If looking for more various predictions, we can then also specify a temperature value to make the results more random.
Some of the key tasks chat-based LLMs can be asked to solve are:
- Expanding: increasing sections of pre-existing texts following some user-provided context for guidance (e.g., to tailor user experience in a response)
- Summarizing: extracting key points from long texts, condensation of long texts within some specific character/word/sentence limit, and creating summaries with a specific focus on some parts of the text.
- Inferring: asking the model to predict the overall sentiment of some text (e.g., positive, negative), what emotions some text expresses, and the topics it can represent.
- Transforming: converting text from one language to another (e.g., English -> Italian), from one format to another (e.g., XML -> JSON), or style of writing (informal -> formal).
Considering the current need to have human operators carefully crafting prompts to models to make the most out of them, different projects have started in the open-source community to make these bot interfaces more autonomous. With Autonomous AI agents, we can, in fact, create a loop to run a conversation between two different bots to accomplish a specified task. In this case, one bot would play the assistant role and the other the human trying to accomplish a task. Leaving the two interacting with each other, we can then just wait on our side until they converge on a suitable solution, therefore reducing the importance of having to craft a perfect prompt to get the right answer. Some examples of Autonomous AI Agents are AutoGPT and BabyAGI.
Opportunities and Risks of Foundation Models and LLMs
Application of these types of model architectures can potentially lead to many different advantages, such as:
- Reduction of costs and human labor.
- Increases in productivity and saving time when executing tasks.
- Improved accuracy in execution.
- Customized customer interaction and on-demand support.
On the other hand, legal and ethical considerations should always be kept in mind when deploying these types of models for sensitive applications.
Use cases
Further development of foundation models could possibly impact a broad class of applications such as content creation, text generation/summarization, virtual assistants, machine translation, computer science code generation, fraud detection, etc. Let's take a closer look at image segmentation, labeling, and the healthcare industry.
SAM for interactive segmentation
Segment Anything Model (SAM) by Meta is a promptable foundation model for image segmentation that achieves zero-shot performance comparable to fully supervised deep neural networks. Learn more about using SAM as part of your code workflow to create segmentation masks.
Additionally, SAM can also be used for automatizing labeling your processes, especially if integrated with fully fledge data labeling solutions such as Kili. Check free hands-on tutorial.
GPT as a Labeler
Foundation models such as GPT is mostly trained on unlabeled datasets, making them, therefore, much easier to train on vast amounts of data and naturally excel at tasks such as data labeling. For an end-to-end explanation of how a large language model such as GPT can be included in this type of workflow, feel free to explore this webinar.
Learn More
Did you know that Large Language Models such as ChatGPT and GPT can be used to reduce your data labeling time by 50%? Or that they can be leveraged for asset creation or QA engineering? Enroll in our on-demand session to explore the potential of these models for data labeling.

LLMs for the Healthcare Industry
Finally, Foundation models and responsible development of LLMs can lead to substantial repercussions in the healthcare space with a broad range of applications potentially affected, such as: virtual assistants for telemedicine, medical translation, disease surveillance, clinical trials recruitment, triaging patients, enhancing medical education, monitoring remotely patients, drug discovery, etc.
Foundation Models and LLMs: Caveats
Security and Privacy
As Foundation models can be improved and developed just by using new training data, providers such as OpenAI have quite strict policies to try to use user input to improve their products. Conversely, this can potentially cause many side effects and create security vulnerabilities. For example, if raw data sharing is enabled, and a developer pastes some security code for the model to debug, then that code might in the future be shared by the model to other users outside the company, therefore, resulting in a cybersecurity vulnerability.
Legal and Ethical Considerations
Foundation models are, at the very core, "black boxes." Therefore, it's really difficult to interpret when something might go wrong. This can therefore be a huge limiting factor when working in highly regulated sectors such as banking. These models might also suffer from systematic bias toward specific classes and types of users. They should therefore be thoroughly evaluated and tested before being deployed to ensure any legal and ethical considerations are met.
The generation of AI content finally also sparked the interest of many regulators concerning the definition of ownership. Is the AI model the true author or the human crafting the prompt? This same question was also asked in the last century after the creation of the camera (is the camera or the operator the author?). In that case, the French court opted for creating copyright protection for photography.
Challenges to FM Adoption in Enterprises
One of the main problems of today's LLMs is hallucinations. Hallucinations take place every time an LMM returns a statement which at first can look sensible but, in reality, is not factually true. Additionally, hallucinations can be divided into 2 key categories: intrinsic and extrinsic.
With intrinsic hallucinations, the model performs some form of wrong logical reasoning, contradicting the user's input. In contrast, with extrinsic hallucinations, misunderstanding can be caused by the model not correctly interpreting the input from the user with respect to the context of the question.
As a result, hallucinations can therefore end up providing the users not accurate information, which could be biased towards some class or no longer valid, or just based on popular beliefs rather than actual facts.

To try to avoid hallucinations when using text-based LLMs, we can then try to design a prompt that requires the model first to find all the relevant information and then create an answer based only on the relevant information.
During training time, one of the most commonly used approaches to try to reduce hallucinations from occurring is Reinforcement Learning with Human Feedback. This has, for example, been implemented by having human operators check the outputs of prompts and rank them to provide feedback to the model about its predictions. Other approaches currently used in order to limit hallucination effects are domain-specific fine-tuning, adversarial training, and multimodal models.
Finally, another point to also keep in mind is that foundation models such as ChatGPT still have quite limited memory (context window), and their inputs are limited by a maximum number of characters which might not be optimal for some applications. One possible approach in order to try to overcome this type of limit is to use LangChain and leverage embeddings and vector stores to store more information. If interested, additional info can be found in this article.
Cost-effective Use
Highly performant foundation models are, at the moment, incredibly costly to prepare, train and maintain once in production (both in economic and environmental impact terms). Therefore, their use can be justifiable only if compared with a valid return on the original investment. For example, using ChatGPT for searching rather than more traditional approaches can result in a 10x potential increase in costs for search engines like Google and Bing. On the other hand, developing applications on top of big LLMs through APIs can potentially drastically reduce costs and times of development for many small to medium organizations.
Data Quality
- Models are mostly trained on English-speaking texts, so their performance will likely be degraded when switching to another language.
- Models are mainly trained on data freely available on the internet, and this data might, in some cases, not align with a company/person's values.
- Data used as part of the training process might not be a good representation of the actual data distributions in the real world (e.g., parts of the population might be under-represented).
- LLMs are mostly trained on unlabeled data.
- Therefore, this data is not balanced by human annotators, leading LLMs to be prone to bias since the data they are trained on conveys bias.
- This also tends to decrease the accuracy of the code generated by LLMs, as it has been trained on code containing errors, which will likely output inaccurate data.
Foundation Models: The future isn't happening fast enough — Better tooling will make it happen faster
Running these large models can be quite challenging. They require expensive clusters and long training times. Fortunately, the tech industry is now starting to focus also on how to make these models more efficient and further optimize these versions. For example, in February 2023, Meta released LLaMA, and its optimized versions are now even possible to run on a single machine! (or any type of device). Some open-source examples are this port of the LLaMA model in C/C++ and its wrapper for Python.
Following the LLaMA announcement, also Standford decided to create its fine-tuned version of it, announcing the Instruction-Following Model Alpaca. The introduction of Alpaca demonstrated then how these models can still yield considerable performance in even smaller formats (performing on a similar level compared to the much bigger OpenAI text-DaVinci-003 and costing only about 600$ to create!).
In terms of tooling, this type of project(s) allows small organizations/researchers who have limited resources to work on future foundation models and create other products/tools, therefore concretely democratizing access to AI.
Key research and resources on Foundation models and LLMs
- On the Opportunities and Risks of Foundation Models
- Holistic Evaluation of Language Models
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- A Survey of Large Language Models
- Introducing LLaMA: A foundational, 65-billion-parameter large language model
- Alpaca: A Strong, Replicable Instruction-Following Model
- Aligning language models to follow instructions
- Introducing FLAN: More Generalizable Language Models with Instruction Fine-Tuning
- ChatGPT Prompt Engineering for Developers
- Introducing Segment Anything: Working toward the first foundation model for image segmentation
FAQ on Foundation Models and LLMs
What are examples of foundational models?
Some examples of Foundation Models are:
- BERT
- RoBERTa
- GPT-3/4
- DALL-E
- Stable Diffusion
- SAM
Who coined the term foundation model?
The Stanford Institute for Human-Centered Artificial Intelligence proposed first the use of this term as part of their research publication "On the Opportunities and Risks of Foundation Models".
Is clip a foundational model?
Yes, CLIP is a Foundational Model designed to understand visual concepts from natural language and can be used for any common type of visual classification task.
What is the center for research on foundation models?
It is an initiative started by Stanford Institute for Human-Centered Artificial Intelligence focusing on studying and developing responsible Foundation Models.
Can LLMs help with data labeling?
As LLMs are trained on unlabeled data, they have a good understanding of how to perform labeling tasks. They can therefore be of great help to speed up labeling processes for specific applications, especially if used in conjunction with data labeling toolkits such as Kili Technology.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
