
June 8, 2026
Agentic AI Benchmarks Guide: What They Are, How They Work, and Why They Aren't Enough
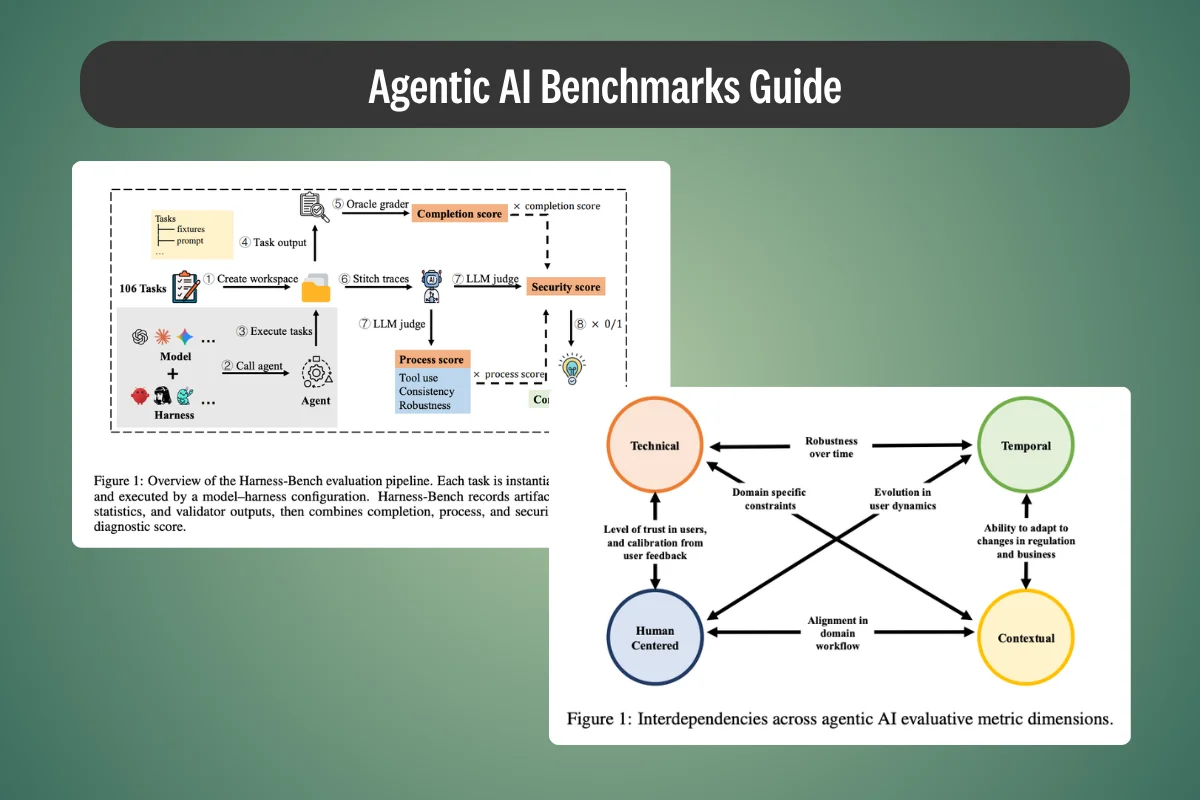
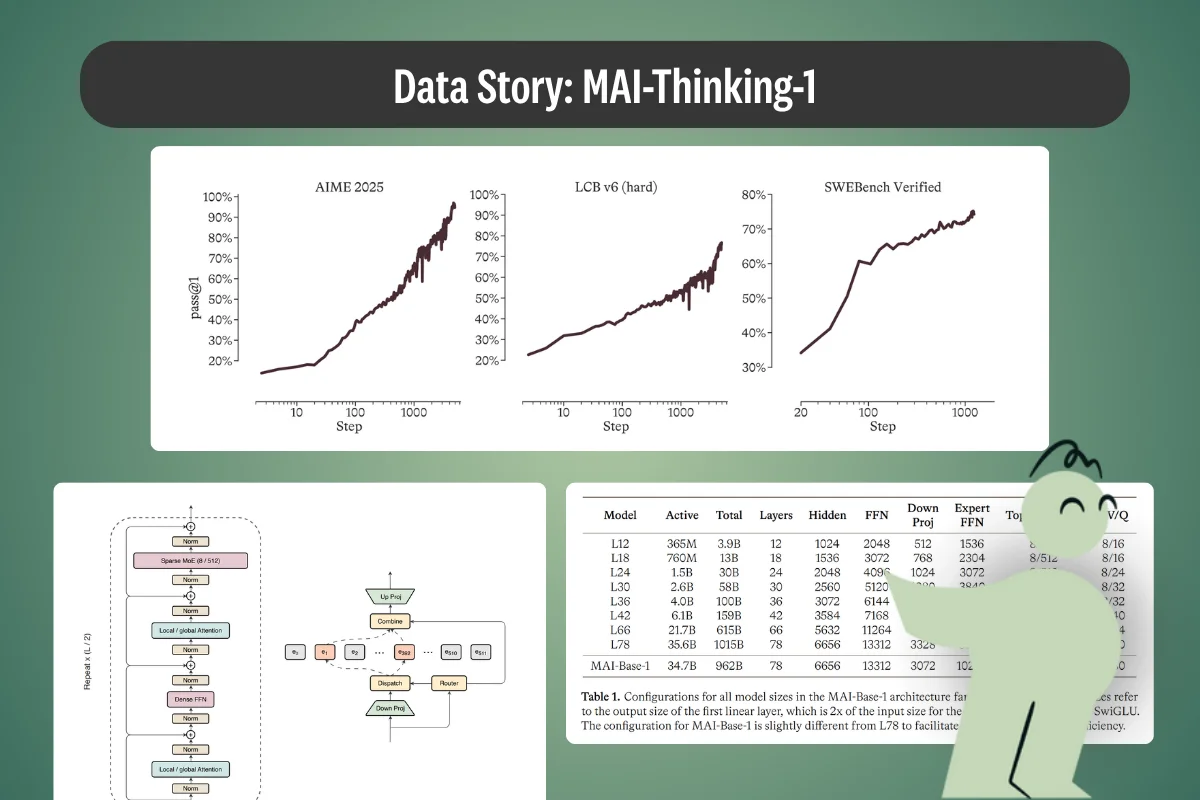
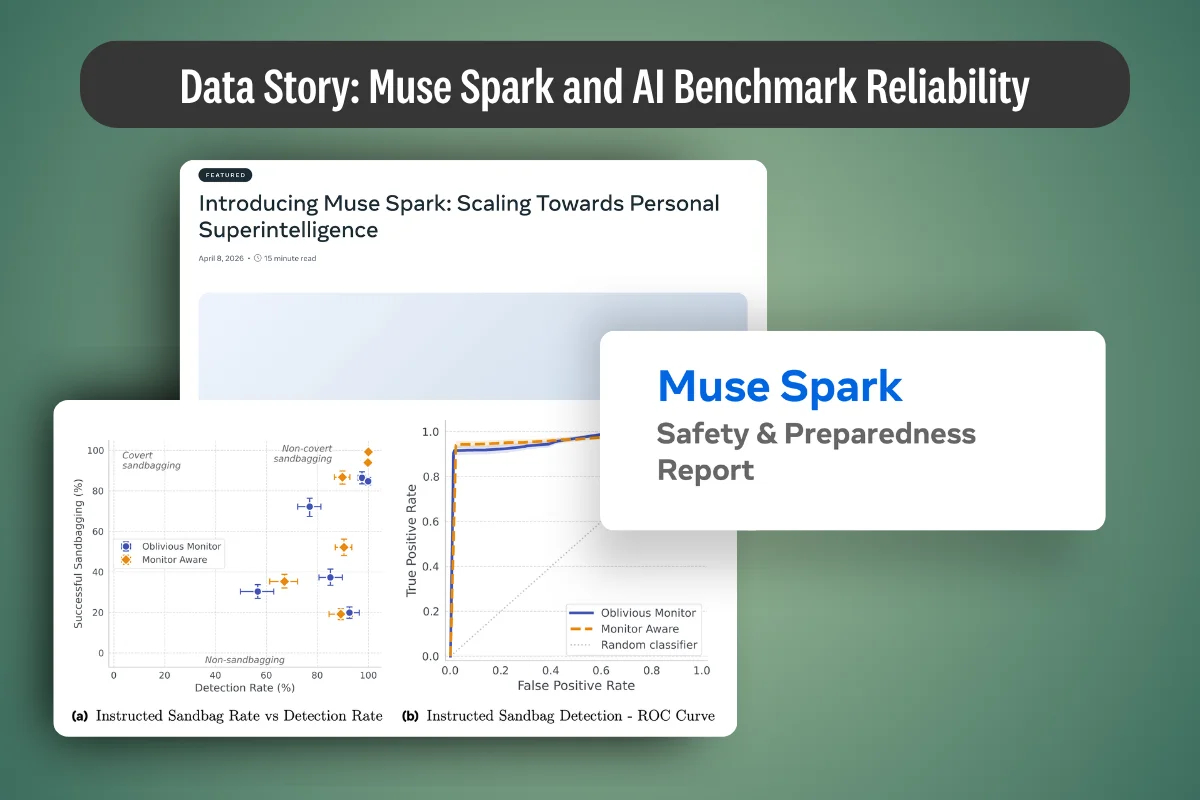
Agentic AI benchmarks rank how AI agents perform on tasks, but top scores rarely survive production. This article breaks down what they measure, how they work, and why they fall short.
.png)








.webp)


.webp)

.webp)