



_logo%201.svg)


AI Summary
- Geospatial AI models show wide performance variation across regions, with mAP scores ranging from 0.57 to 0.91 in Omdena building detection projects.
- Human-in-the-loop evaluation bridges the gap between automated predictions and real-world correctness in complex geospatial environments.
- Two-stage pipelines combining detection and segmentation models outperform single-model approaches for building footprint extraction.
- Segmentation remains a major bottleneck, with boundary IoU scores as low as 0.009 in densely packed environments.
- Foundation models like DINOv3 achieve strong results with as little as 5 percent of labeled data, reducing annotation dependency.
- Regional specialization and data quality matter more than model complexity for reliable geospatial AI systems.
Geospatial AI is transforming how organizations understand and act on the physical world. It combines satellite and aerial imagery with machine learning. This allows teams to map infrastructure, monitor environmental changes, optimize agriculture, and support urban planning at scale. Today, these systems are used to analyze land use, track climate impact, detect infrastructure risks, and enable faster disaster response.
Advances in computer vision and foundation models have made it easier to process large volumes of Earth observation data. What once required manual effort can now be done automatically.
However, building reliable geospatial AI systems is still difficult. Data varies across regions and conditions. In this article, I'll explore these challenges and show how human-in-the-loop evaluation helps improve real-world geospatial AI systems. Let's get started.
Why Evaluating Geospatial AI Models Is Difficult
Evaluating geospatial AI models is fundamentally more complex than traditional computer vision tasks. Satellite imagery introduces additional spatial, temporal, and environmental variability that directly impacts model performance.
Key challenges include:
- Geographic diversity: Buildings, terrain, and land patterns vary widely across regions, making it difficult for a single model to perform consistently everywhere.
- Data quality variability: Differences in resolution, sensors, weather, and lighting conditions introduce inconsistencies that affect both training and evaluation.
- Limited labeled datasets: High-quality geospatial annotations require expert effort, and labeled data is often scarce or unevenly distributed.
- Model generalization problems: Models trained on one region or dataset often fail when applied to new geographies due to domain shifts.
These challenges make reliable evaluation difficult and highlight the need for human-in-the-loop approaches, which I'll explore next.
The Role of Human-in-the-Loop Evaluation in Geospatial AI
Human-in-the-loop (HITL) evaluation plays a critical role in making geospatial AI systems reliable in real-world conditions. Instead of relying solely on automated outputs, HITL integrates human expertise at key stages of the AI lifecycle to improve accuracy, reduce errors, and ensure meaningful results.
In geospatial AI workflows, this typically includes:
- Dataset labeling: Experts annotate satellite imagery to create high-quality training data.
- Prediction validation: Human reviewers assess model outputs to verify correctness.
- Error correction: Incorrect detections or segmentations are manually fixed.
- Feedback loops for retraining: Corrected outputs are fed back into the model to improve future performance.
Human expertise remains essential because geospatial data is complex and context-dependent. Tasks like validating segmentation masks, correcting boundary errors, or identifying mislabeled structures often require domain knowledge that models lack.
This combination of machine efficiency and human judgment creates more reliable systems - something I've seen firsthand in real-world projects at Omdena, which I'll explore next.
Lessons from Real Satellite AI Projects from Omdena
In real-world geospatial AI projects at Omdena, the gap between model performance in controlled settings and actual deployment becomes very clear. Across multiple projects, our teams have worked on tasks such as building detection, infrastructure mapping, rooftop material classification, and environmental monitoring using satellite and aerial imagery. While the use cases vary, the underlying challenges and lessons remain surprisingly consistent.
One of the most important findings is that a single global model rarely works well across different geographic regions. In our building detection pipelines, we observed significant variation in performance depending on location.

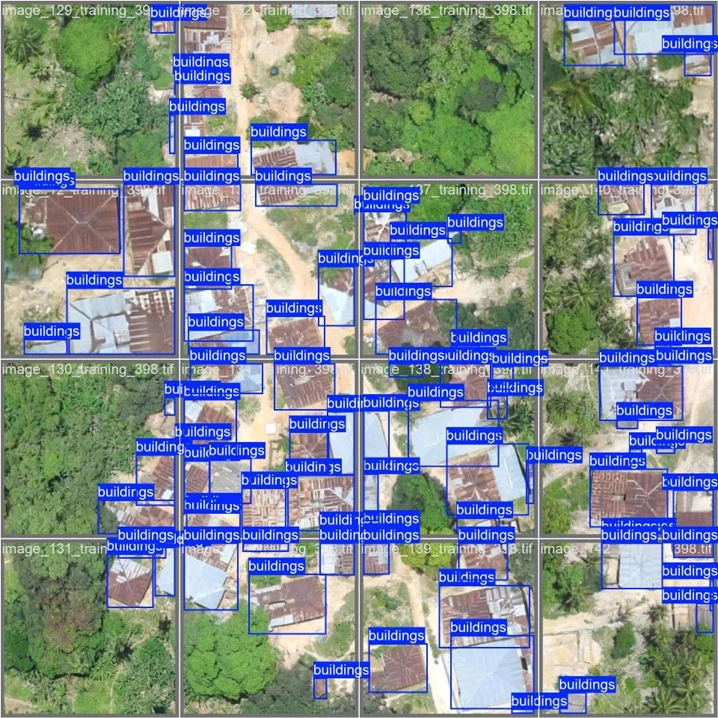

For example, mAP scores ranged from 0.57 to 0.91 across regions, highlighting how differences in architecture, density, and image quality directly impact results.
Regional Performance Variation
training_364 - mAP@0.5: 0.819 / mAP@0.5:0.95: 0.616 / Mean IoU: 0.441
training_397 - mAP@0.5: 0.570 / mAP@0.5:0.95: 0.382 / Mean IoU: 0.499
training_399 - mAP@0.5: 0.896 / mAP@0.5:0.95: 0.763 / Mean IoU: 0.534
training_386 - mAP@0.5: 0.672 / mAP@0.5:0.95: 0.486 / Mean IoU: 0.542
training_403 - mAP@0.5: 0.869 / mAP@0.5:0.95: 0.660 / Mean IoU: 0.613
training_404 - mAP@0.5: 0.916 / mAP@0.5:0.95: 0.835 / Mean IoU: 0.448
training_385 - mAP@0.5: 0.624 / mAP@0.5:0.95: 0.423 / Mean IoU: 0.278
training_389 - mAP@0.5: 0.865 / mAP@0.5:0.95: 0.737 / Mean IoU: 0.625
training_398 - mAP@0.5: 0.652 / mAP@0.5:0.95: 0.479 / Mean IoU: 0.401
A model trained on dense urban areas struggled in rural or coastal regions, and vice versa.
Another key insight came from pipeline design. A two-stage architecture combining detection and segmentation models proved far more effective than relying on a single model. Detection models like YOLO provided fast and reliable building localization, while segmentation models like SAM2 refined these detections into precise footprints.
.webp)
However, segmentation performance remained inconsistent, with IoU scores varying between 0.15 and 0.59, especially in complex or densely packed environments where boundary detection is difficult.

Key Segmentation Metrics
training_364 - IoU: 0.590 / Dice: 0.665 / Pixel Accuracy: 0.943 / Boundary IoU: 0.143
training_385 - IoU: 0.258 / Dice: 0.322 / Pixel Accuracy: 0.838 / Boundary IoU: 0.024
training_386 - IoU: 0.250 / Dice: 0.345 / Pixel Accuracy: 0.622 / Boundary IoU: 0.018
training_389 - IoU: 0.152 / Dice: 0.216 / Pixel Accuracy: 0.589 / Boundary IoU: 0.009
training_397 - IoU: 0.370 / Dice: 0.473 / Pixel Accuracy: 0.696 / Boundary IoU: 0.034
training_398 - IoU: 0.257 / Dice: 0.331 / Pixel Accuracy: 0.825 / Boundary IoU: 0.045
training_399 - IoU: 0.396 / Dice: 0.472 / Pixel Accuracy: 0.873 / Boundary IoU: 0.055
training_403 - IoU: 0.162 / Dice: 0.219 / Pixel Accuracy: 0.803 / Boundary IoU: 0.024
training_404 - IoU: 0.235 / Dice: 0.290 / Pixel Accuracy: 0.841 / Boundary IoU: 0.027
We also explored rooftop material classification, which introduced additional complexity. Initial attempts to classify cropped building images using classification models performed poorly, particularly on multi-class datasets. Switching to detection + segmentation approaches improved results, but performance still plateaued around 65% mAP, largely due to dataset limitations and class imbalance.
Some of the most promising results came from experimenting with foundation models. By adapting models like DINOv3 with minimal labeled data (as little as 5% of the dataset), we achieved up to 70% IoU and 82% Dice scores, showing strong potential for reducing dependency on large annotated datasets.

Key lessons from these projects:
- Regional specialization significantly improves performance over global models
- Data quality and consistency matter more than model complexity
- Segmentation remains a major bottleneck, especially for boundary precision
- Foundation models can accelerate performance with limited data
These insights highlight a critical reality: building geospatial AI systems is not just about choosing the right model, but about designing robust pipelines, adapting to regional variability, and continuously evaluating outputs.
To make this work in practice, teams need a structured approach that connects data, models, and evaluation into a cohesive system. Let's look at what a reliable geospatial AI pipeline actually looks like.
Building a Reliable Geospatial AI Pipeline
Building a reliable geospatial AI system requires more than just strong models. It depends on a well-structured pipeline that connects data, training, and evaluation seamlessly.
A typical workflow includes:
- Satellite imagery collection: Gathering data from satellites, drones, or sensors to capture large-scale geographic information.
- Dataset labeling and preprocessing: Creating high-quality annotations and preparing image-label pairs for training.
- Model training: Training detection or segmentation models on labeled geospatial datasets.
- Human evaluation of predictions: Validating outputs against ground truth to assess accuracy and reliability.
- Error analysis: Identifying failure cases and performance gaps across regions or scenarios.
- Model refinement: Iteratively improving models using corrected data and insights.
Continuous evaluation pipelines ensure models remain reliable as data evolves. As these systems mature, new innovations are shaping how geospatial AI is built and scaled.
Emerging Trends in Geospatial AI
Geospatial AI is evolving rapidly, driven by advances in data, models, and system design.
Key emerging trends include:
- Agentic AI for geospatial workflows: Agentic AI can coordinate multiple models and data sources to solve geospatial tasks end-to-end.
- Foundation models for remote sensing: Large geospatial models trained on massive satellite datasets can now adapt to multiple tasks. They improve generalization and reduce the need for large labeled datasets.
- Multimodal Earth observation systems: Modern systems combine optical imagery, radar, elevation data, and text. This leads to richer insights and more accurate predictions.
- Automated infrastructure monitoring: AI systems can track changes in roads, buildings, and land use at scale. This enables near real-time decision-making across industries.
- AI-assisted mapping platforms: New platforms automate large parts of the mapping workflow. This reduces manual effort and speeds up geospatial analysis.
These advancements will expand what geospatial AI systems can achieve across industries. However, their real-world impact will depend on how reliably they are evaluated and improved over time.
What It Takes to Build Reliable Geospatial AI
Geospatial AI has the potential to transform how we understand and manage the physical world. But building reliable systems requires more than just advanced models.
At its core, success depends on three key elements:
- High-quality datasets that reflect real-world diversity
- Strong models that can adapt across regions and conditions
- Human evaluation workflows that ensure accuracy and reliability
This is where human-in-the-loop AI becomes critical. It bridges the gap between automated predictions and real-world correctness, especially in complex geospatial environments.
The future of geospatial AI will not be defined by models alone, but by how well we design systems that combine data, models, and human judgment into a continuous learning loop.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
.png)

