
.png)

_logo%201.svg)


AI Summary
- 30 trillion pre-training tokens, 54.6% code, with no open-source or HuggingFace data in the mix.
- Every tool is named; no data provider is — including the vendors behind the human preference data that trains safety behavior.
- "No synthetic data" holds for pre-training but breaks in RL, where both SWE problems and tool-use environments are synthesized.
- Agentic RL kept 265,617 verified SWE environments from 102M GitHub pull requests — a 5.5% survival rate.
- Qwen, a competitor's open model, did the deduplication embedding and code-quality judging.
Why Does the MAI-Thinking-1 Dataset Deserve a Close Read?
Most model launches describe their training data in a sentence or two. Microsoft AI's technical report devotes an appendix and a long methods section to provenance, and the launch announcement leads with a specific claim: the model was trained "exclusively on clean, enterprise-grade data, without distillation." That is a claim about data, not architecture, and it invites the kind of scrutiny data claims usually escape.
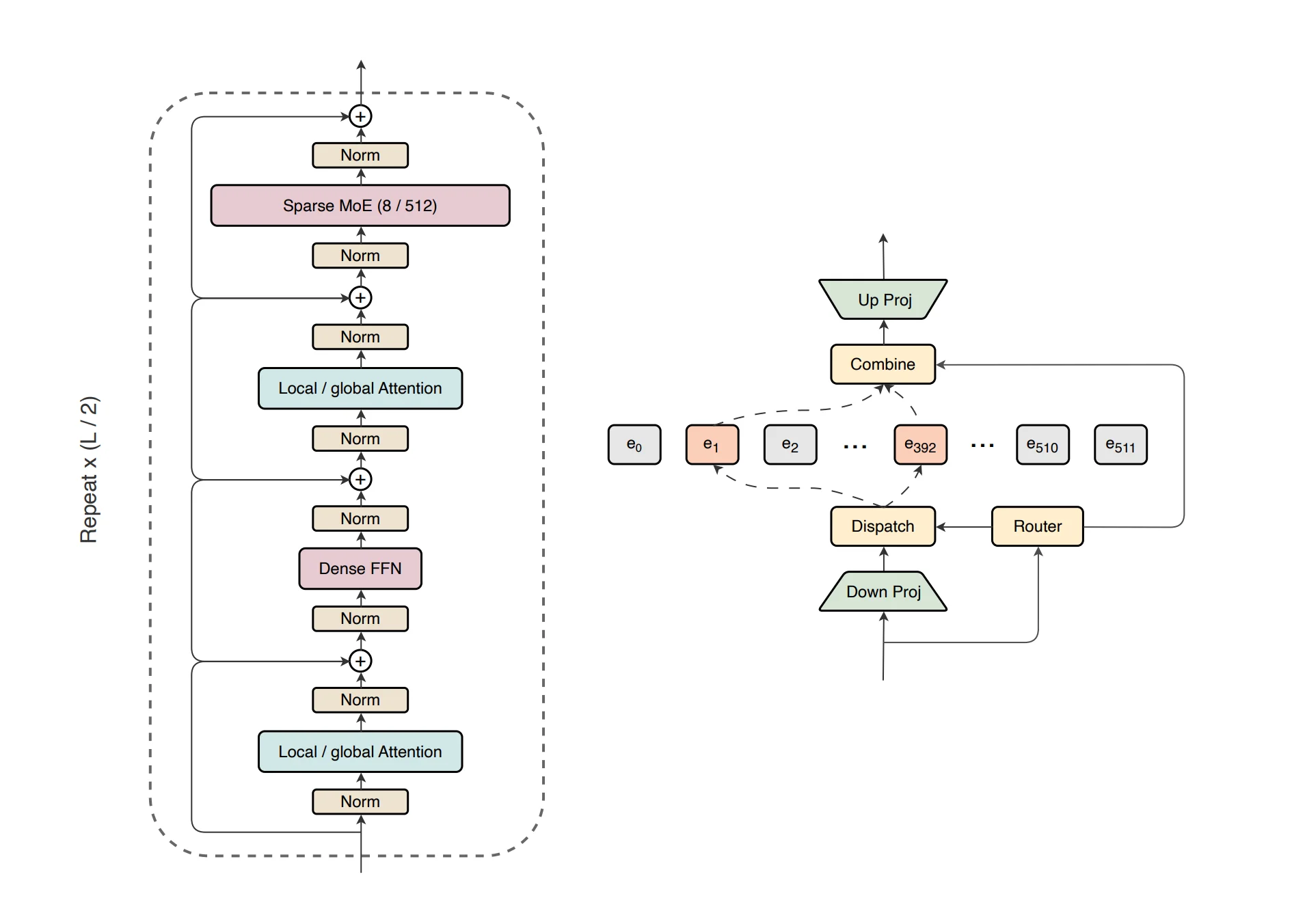
The model itself is a 35-billion-active, roughly one-trillion-total-parameter sparse Mixture-of-Experts reasoning system that supports long context. What matters here is not the parameter count but the fact that Microsoft tied its differentiation to dataset purity and then documented the pipeline in enough detail to be checked against its own marketing.
This is a Data Story, so the model's benchmark scores are background. The question is narrower: what is actually in the MAI-Thinking-1 training data, how was it cleaned, and where do the documented mechanics diverge from the one-line pitch?
What Went Into Pre-Training?
Pre-training consumed 30 trillion tokens drawn from publicly available and appropriately licensed human-generated data, processed entirely in-house. Microsoft states plainly that it used no open-source training datasets and removed all data from huggingface.co and its mirror domains. The sourcing categories are web HTML, web PDFs, public GitHub code, books and journals, news, multilingual text, and domain-specific material.
The final mixture is heavily weighted toward code. Code makes up 54.6% of the tokens, about 16.4 trillion. STEM accounts for 15.8%, general web text 14.9%, and math 5.4%, roughly 300 billion tokens but sampled 5.28 times over, a deliberate up-weighting of the slice most relevant to reasoning. A reasoning model trained more than half on code is making a bet about where chain-of-thought ability comes from.
Each source carries its own knowledge cutoff. Web HTML stops at September 2025, web PDFs at December 2025, GitHub code at June 2025, and books and journals run to March 2026. That staggering reflects how the pipelines were built rather than a single ingestion date.
The web pipeline
The web HTML corpus starts from a proprietary crawl of roughly 1.2 trillion pages, with Common Crawl processed through the same path. Microsoft used Trafilatura for HTML-to-text extraction and the public UT1 blocklist to strip adult and piracy domains. Policy, adult-content, and blocklist filtering cut the 1.2 trillion pages to 794 billion; exact and fuzzy deduplication then took that to 423 billion documents, and after the bottom 70% of English documents were dropped by attribute and quality models plus Gopher-style heuristics, roughly 4.6 billion English documents survived from the proprietary crawl and 2.8 billion from Common Crawl. Deduplication and embedding work ran on Qwen3-Embedding-0.6B, a third-party open model, a detail worth returning to. On top of the broad pipeline, Microsoft pulled a human-curated subset of long-form prose, sourcing candidate domains from magazine and long-form reading aggregators and from reference links shared on social platforms. Here, "quality" meant human editorial judgment, not just classifier scores.
Then there is the AI-content question. Microsoft says it scored pages with a proprietary AI-content detection model and dropped flagged domains, supplemented by manual inspection, so that AI-generated content was excluded from the corpus. The method is described. Its effectiveness is not. There is no reported recall or precision figure for that detector, which means the claim that AI-generated content was kept out is backed by a mechanism whose accuracy the report does not quantify.
PDFs, books, and code
Web PDFs went from about 10 billion crawled documents down to 620 million kept, converted with Azure Document Intelligence OCR, yielding roughly 3.65 trillion tokens across English and multilingual text. Books and journals were acquired through direct agreements with publishers, with per-provider ingestion pipelines built to respect each provider's usage limits. No publisher is named.
Public GitHub supplied a 7.4-trillion-token code corpus, split into files (1.26 trillion tokens), commits (4.5 trillion), and pull requests (1.19 trillion), each run through SHA-512 exact dedup, MinHashLSH fuzzy dedup, and semantic dedup over Qwen3 embeddings. The PR set was decontaminated against SWE-bench Verified by removing every PR used in that benchmark. A dedicated STEM pipeline with seven topic classifiers and custom MathML/LaTeX-to-Markdown extraction carved out 680 billion English STEM tokens and 760 billion multilingual ones.
Mid-training and the long-context climb
The 30 trillion pre-training tokens are not the whole of MAI-Base-1. Microsoft ran two further mid-training phases totaling 3.55 trillion tokens, drawn entirely from the same in-house corpus rather than any new or synthetic source. The phases exist mainly to extend context. Pre-training ran at a 16,384-token window, mid-training phase 1 added 3.4 trillion tokens at 65,536 tokens, and a short phase 2 added 150 billion tokens at the full 262,144-token (256K) target. Microsoft also tried up-weighting long-context documents and shifting domain ratios for the extension, and found none of it helped; the simplest option, re-packing the existing mid-training mixture at the longer sequence length, worked as well as anything, so that is what shipped. It is a small but honest negative result, and the long-context capability rests on the same human-authored corpus, not on a special long-context dataset.
Where Does the "Clean Data" Claim Hold, and Where Does It Strain?
Here is the tension at the center of the MAI-Thinking-1 training data. Microsoft names its tools generously and its data sources hardly at all.
The report freely identifies Trafilatura, Azure Document Intelligence, Qwen3-Embedding-0.6B, Qwen3-30B as a code-quality judge, GEPA/DSPy for prompt optimization, SymPy for math verification, the UT1 blocklist, and the PyRIT, PAP, and TAP adversarial frameworks. What it withholds, citing privacy, legal, safety, and competitive reasons, is every licensed data provider: the book and journal publishers, the STEM and coding-problem vendors, the human-preference-data vendors.
The cleanliness pillar — human-authored and appropriately licensed with no AI slop — rests on agreements that are deliberately undisclosed. You can verify which OCR engine ran. You cannot verify which publishers' catalogs entered the corpus or on what terms. The slogan is checkable at the level of tooling and opaque at the level of sourcing, which is precisely the level the slogan is about.
None of this implies bad faith. Competitive and legal caution around licensing is normal. But a "clean data" claim is a claim about provenance, and provenance is the one thing the report asks readers to take on trust.
Is It Really "No Synthetic Data"?
Mostly, with exceptions the report states clearly. Pre-training and mid-training are synthetic-free; the 3.55 trillion mid-training tokens come entirely from the pre-training corpus, as covered above. Post-training is where synthetic data enters, in two places, both confined to RL.
The first is agentic software engineering. Microsoft reused valid-but-quality-rejected executable environments to generate synthetic SWE problems and tests, using methods inspired by BugPilot, SWE-Smith, and SWE-Mirror. The second is general tool use, where an LLM pipeline (following the FunReason-MT line of work) synthesizes entire closed-world environments such as seeded databases, tool definitions, and verifiable tasks from plain-English descriptions, producing more than 150 environments and 130,000 tasks. So the accurate phrasing is not "no synthetic data" but "no synthetic data in pre-training, two acknowledged synthetic sources in post-training." Repeating the blanket version misstates what Microsoft actually documented.
How Was the RL Data Built?
The reinforcement learning data is the part the announcement mostly skipped, and it is where the dataset work gets most concrete. Microsoft's RL climb starts from a checkpoint with no prior reasoning traces, learning chain-of-thought from scratch under a modified GRPO objective with adaptive entropy control and an outer ratio clip for stability. This is not a single run. Three specialist models are RL-trained separately — a STEM and competitive-coding climb, an agentic coding and tool-use climb, and a helpfulness-and-safety climb — then merged through SFT trace distillation and given a final RL climb. Each climb has its own data recipe, and the data work is the substance of all three.
STEM Mix: more than five million pairs, aggressively filtered
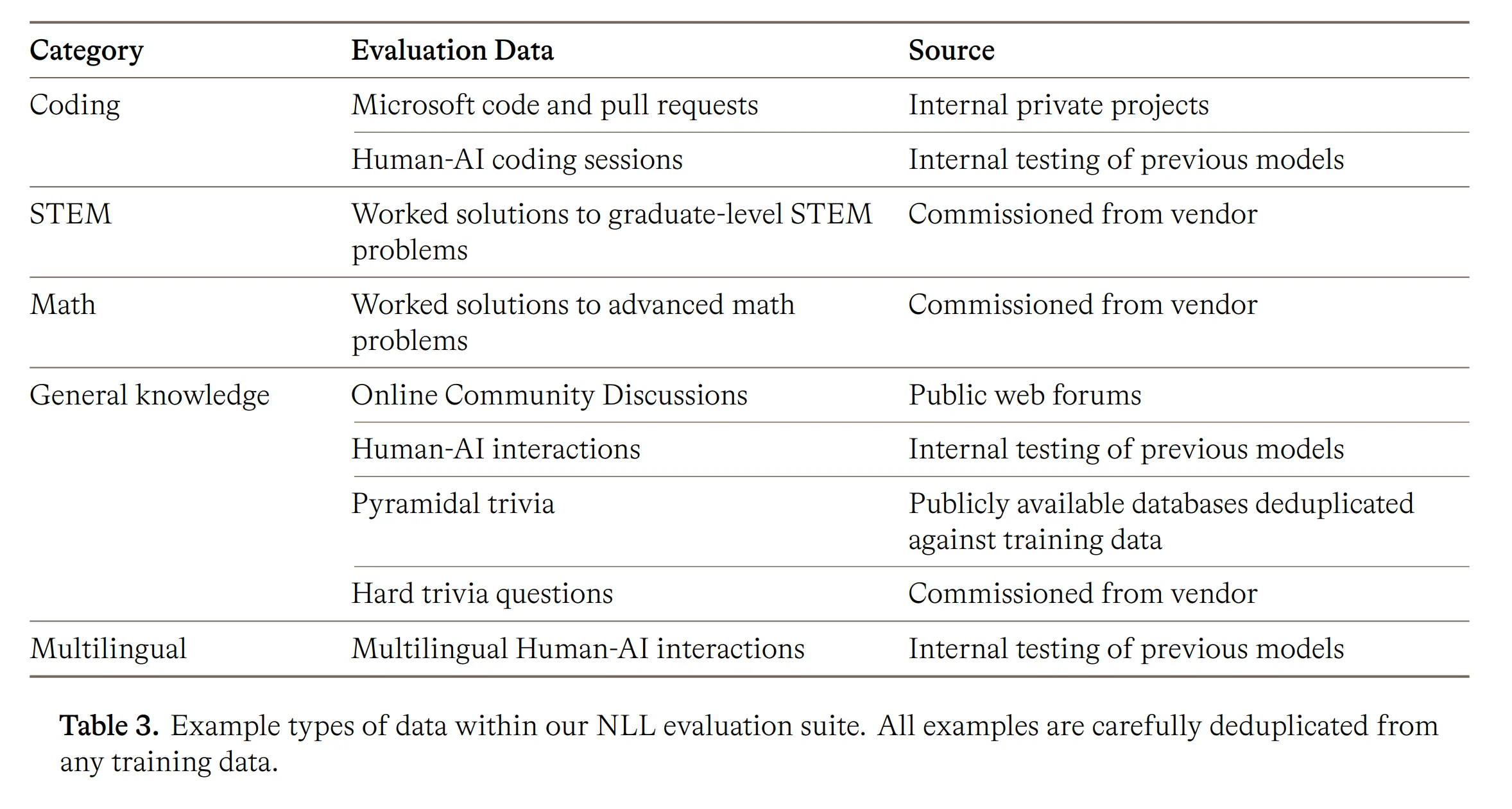
The STEM climb is the longest of the three and runs entirely on verifiable pairs: either a query with a checkable ground-truth answer, or a query with a set of test cases. STEM Mix holds more than 5 million verifiable question-answer pairs, with a hardest subset above 550,000 pairs, sourced from textbooks, academic PDFs, forum discussions, competition archives, and vendor-acquired problems. The ingestion pipeline runs in four phases: hierarchical parsing of long-form PDFs, question-answer pairing, curation, and scoring, with the noise-sensitive stages run multiple times under consensus voting.
The curation is where the rejection logic lives. Items with no checkable answer are dropped as non-verifiable; a PII classifier drops flagged items; pairs where the answer is trivially contained in the question are dropped for answer leakage. Multiple-choice and proof questions are rewritten into open-ended form — multiple choice because it can be solved by guessing, proofs because they are hard to verify without leaning on a stronger AI judge — and the rewrite is run three times under consensus, with any item that fails to converge dropped as not reliably convertible. Answers are then checked with SymPy, an AI judge, or test-case execution. The final scoring phase has each problem solved repeatedly by four model tiers (calibrated against AIME 2025 ability), and a blind-grading stage drops any item where a judge, shown the model's consensus answer and the stated ground truth in randomized order, prefers the model's answer, an explicit defense against training on wrong answer keys.
Competitive coding and the two agentic domains
Competitive coding uses a separate pipeline, because comprehensive test cases rarely exist in unstructured PDFs. Microsoft drew on targeted and vendor-acquired sources for 160,000 problems across 17 programming languages, each with reference solutions verified to pass, plus runtime and memory limits.
The agentic climb then splits into two domains. The first is software engineering, the headline funnel. Microsoft started from 102 million public GitHub pull requests and ran them through a multi-stage pipeline: PRs had to be merged, touch fewer than 15 files, and carry both code and test changes, with issue linkage from GitHub, Jira, Bugzilla, YouTrack, Phabricator, Launchpad, or Linear. That yielded 4.87 million PRs with linked issues, 2.08 million (42.8%) that built into executable container images, 745,452 (15.3%) that passed reference grading, and finally 265,617 (5.5%) verified environments across 94,044 repositories. Each runs in a network-isolated sandbox and is graded by fail-to-pass tests (the issue-resolution signal) and pass-to-pass tests (the regression signal); problems with no surviving fail-to-pass test are discarded.
The second agentic domain is general tool use. These are stateful environments backed by mocked API or MCP-style backends such as inventory management, scheduling, and customer support, often exposing more than 50 tools in a single environment, mixing human-curated environments with the 150-plus synthetic ones described above. This is the data behind the model's tool-calling ability, and it is a distinct corpus from the SWE environments.
The reward-hacking exploits, and the data RL dedup throws out
Microsoft documents three reward-hacking vectors it caught in the SWE environments and patched: models searching the internet for the original PR, mining local git history for the fix, and tampering with test files. The fix for git-history mining scrubs every commit, reference, and branch after the problem's base commit to produce a "time-traveled" version of the repository so the answer cannot be found in the log. Test files modified by the agent are reset before grading, and test changes are hidden during inference and applied only at grading time. A team that documents the exploits it had to close is making a more credible claim than one that simply asserts clean environments.
The RL data is also deduplicated and decontaminated in its own right, not just the pre-training corpus. Both STEM Mix and the competitive-coding set go through three-stage dedup — SHA-256 exact hashing, MinHash lexical fuzzy matching, and vector-similarity matching — and are deduplicated against the reported benchmarks plus internal Olympiad and graduate-level evaluations, with hyperparameters tuned to keep as much data as possible while strictly excluding benchmark leakage.
The reward models: named methods, unnamed annotators
The helpfulness-and-safety climb is where the dataset story closes its loop. Performance here is not machine-verifiable, so the reward comes from three layered signals: a trained reward model, AI-judge rubrics, and verifiable rewards (for checkable constraints like "respond in a single paragraph"). The reward model is a fine-tuned MAI-Base-1 that predicts 1-to-5 preference scores, and it is trained, the report's word, exclusively on human preference data collected with human annotators from several vendors. Safety prompts come from human red-teaming and automated adversarial generation via PyRIT, PAP, and TAP, scored on policy compliance, with unsafe compliance and over-refusal both treated as defects.
That single sentence is the cleanliness thesis in miniature. The adversarial frameworks are named; the preference-data vendors are not. What counts as helpful and what counts as safe is shaped by human judgments whose source the report withholds. This is also not Microsoft's first model to lean on heavily curated human-labeled safety data: its earlier MAI-DS-R1 used 110,000 safety examples in training and added multilingual examples to address reported biases, with that data collection not continuing after deployment.
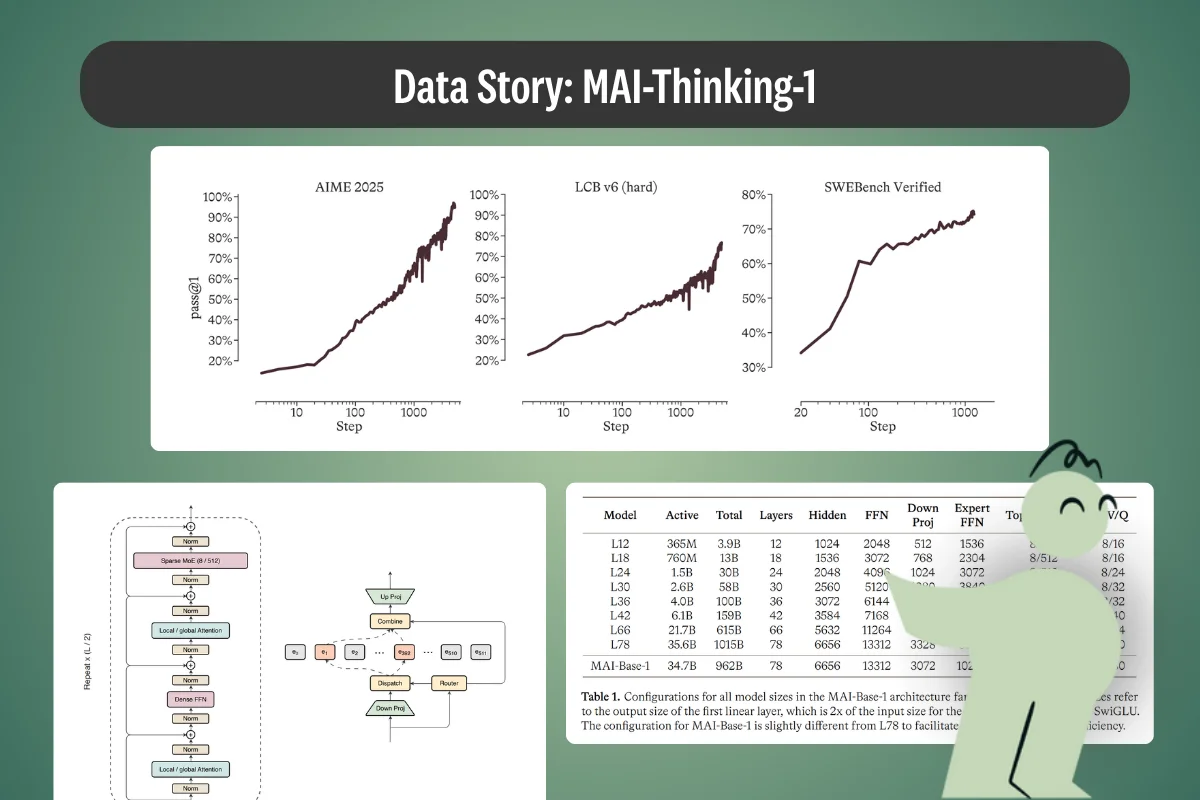
How Was the Model Evaluated?
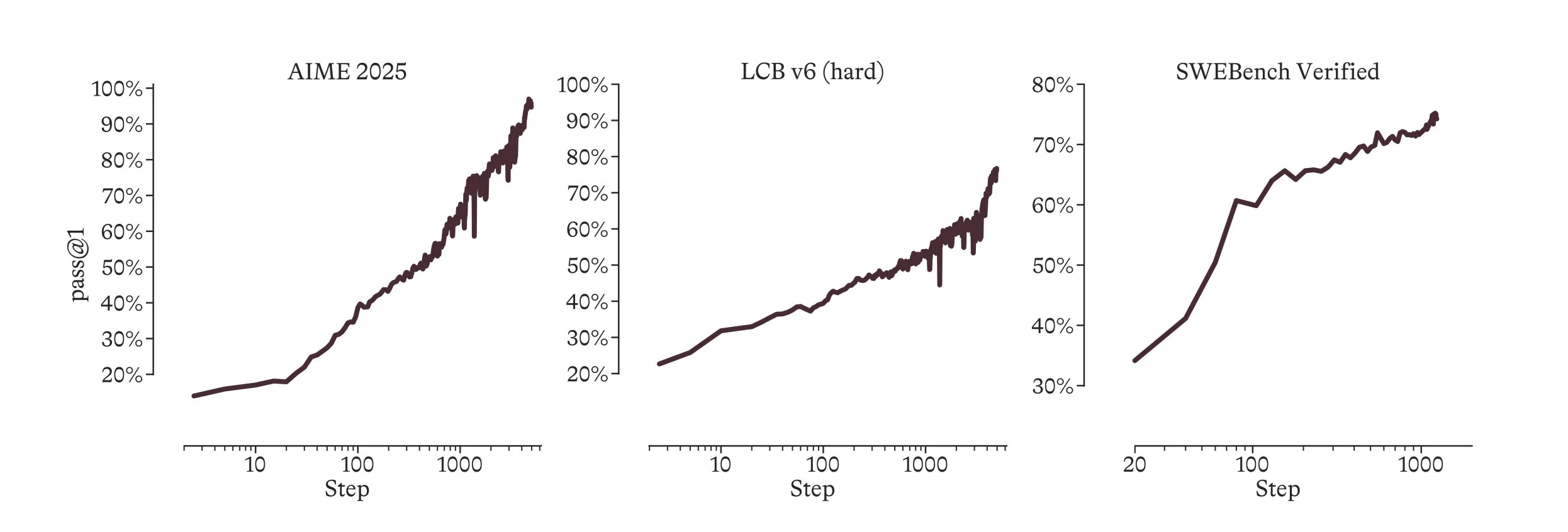
Microsoft leaned away from public multiple-choice benchmarks for its base-model evaluation, and the reasoning is a data-contamination argument. The team used roughly 40 internal negative-log-likelihood benchmarks across five categories, scored by tokenizer-invariant bits-per-byte, comparing MAI-Base-1 against models including DeepSeek and Kimi-K2. Public benchmarks were decontaminated with 20-gram fuzzy deduplication at an 80% similarity threshold, and private internal benchmarks were built specifically to avoid web leakage.
On public reasoning benchmarks the reported headline figures are 97.0% on AIME 2025, 94.5% on AIME 2026, 87.7% on LiveCodeBench v6, and 52.8% on SWE-Bench Pro. Human evaluation ran through the vendor Surge across 1,276 single- and multi-turn tasks, with raters reportedly preferring MAI-Thinking-1 over Claude Sonnet 4.6.
Every one of the MAI-Thinking-1 numbers above is first-party. The report is Microsoft's own, not peer-reviewed and not independently verified, so the benchmark leads and the human-preference result are vendor claims pending outside scrutiny, as is the dataset-cleanliness story itself.
What Does the Qwen Dependency Reveal?
One detail cuts against the from-scratch framing. For deduplication embeddings and for code-quality judging, Microsoft used Qwen models (Qwen3-Embedding-0.6B and Qwen3-30B), which are open models from a competitor.
This does not contradict the no-distillation claim, which concerns training the model's weights rather than curating its data. But it complicates the clean-room image. The MAI-Thinking-1 training data was shaped, in part, by another lab's models acting as filters and judges. The pipeline that produced "exclusively clean, enterprise-grade data" used a competitor's tools to decide what counted as clean. That describes the weights as from-scratch, not the toolchain.
Why Does Inspectable Provenance Matter for Training Data?
The most valuable thing Microsoft published is not the cleanliness claim. It is the documentation that lets you test it. The funnel numbers, the decontamination steps, the named reward-hacking exploits, and the blind-grading drop of suspect ground truths all describe a team that treated data quality as an engineering problem with measurable failure modes, not a slogan.
That is the distinction that matters for anyone building reasoning models. The 265,617 surviving environments are valuable because of the 102 million that were filtered, built, graded, and mostly discarded. The STEM Mix is trustworthy in proportion to the items it threw out for having suspect answer keys. Data quality is defined by what a pipeline rejects and why, and by whether someone with domain judgment verified that "correct" actually means correct. The models that hold up in production are rarely the ones trained on the most data. They are the ones trained on data someone took the trouble to validate, and to keep validating as the dataset evolves.
What Microsoft did not disclose, the providers behind the licensed corpus, is exactly where the cleanliness claim becomes unfalsifiable. The lesson is not that the claim is false. It is that provenance you cannot inspect is provenance you have to trust, and trust is a poor substitute for documentation in a field that is finally learning to document.
What Verifiable Training Data Actually Requires
Microsoft's report makes a quiet point louder than its headline does: a model is only as accountable as the records behind its data. Where the report is strong, in funnel survival rates, named exploits, and blind-grading drops, it earns confidence; where it goes silent on sourcing, confidence has to be borrowed.
Closing that gap is a question of who validates the data and whether their judgment is traceable. This is the work Kili Technology is built for: human-in-the-loop pipelines staffed by named, verified domain specialists such as Lean 4 theorem provers, math olympiad champions, and practicing attorneys, rather than an anonymous crowd, with evaluation treated as a first-class service and annotator-level decisions auditable in real time. For frontier teams whose reasoning models depend on training data they can actually account for, that traceability is what turns "clean data" from a claim into a record.
Resources
Primary Sources
- MAI-Thinking-1: Building a Hill-Climbing Machine – Microsoft AI's full 109-page technical report covering datasets, training, RL, and evaluation
- https://microsoft.ai/wp-content/uploads/2026/06/main_20260602_2.pdf
- Introducing MAI-Thinking-1 – Microsoft AI's launch announcement
- https://microsoft.ai/news/introducing-mai-thinking-1/
Data Processing Tools Referenced
- Trafilatura – open-source HTML-to-text extraction library used in the web pipeline
- https://trafilatura.readthedocs.io/
Further Reading
- Kili Technology – human-in-the-loop data labeling and validation for enterprise AI
- https://kili-technology.com/data-labeling-services
Frequently Asked Questions
What is MAI-Thinking-1?
MAI-Thinking-1 is Microsoft AI's frontier reasoning model — a 35-billion-active, roughly one-trillion-total-parameter sparse Mixture-of-Experts system. Microsoft built it from scratch on training data it claims is fully human-authored and appropriately licensed, without distillation from other models.
How much training data was used for MAI-Thinking-1?
Pre-training consumed 30 trillion tokens, with code making up 54.6% of the total. Two additional mid-training phases added 3.55 trillion tokens to extend the context window from 16K to 256K tokens, drawn entirely from the same in-house corpus.
Does MAI-Thinking-1 use synthetic data?
Pre-training and mid-training are synthetic-free. Synthetic data enters only during reinforcement learning in two places: synthesized software engineering problems and tests, and synthesized closed-world tool-use environments with over 150 environments and 130,000 tasks.
What does "clean data" mean in the context of MAI-Thinking-1?
Microsoft claims the model was trained exclusively on human-authored, appropriately licensed data with no AI-generated content. However, while every processing tool is named in the technical report, no data provider — including book publishers, STEM vendors, and human-preference-data vendors — is identified. The cleanliness claim is verifiable at the tooling level but opaque at the sourcing level.
How was the reinforcement learning data built?
Microsoft trained three specialist RL models separately — STEM and competitive coding, agentic coding and tool use, and helpfulness and safety — then merged them through SFT trace distillation. The agentic SWE pipeline started from 102 million GitHub pull requests and filtered down to 265,617 verified environments, a 5.5% survival rate.
Why were Qwen models used in the MAI-Thinking-1 pipeline?
Microsoft used Qwen3-Embedding-0.6B for deduplication embeddings and Qwen3-30B as a code-quality judge. This does not contradict the no-distillation claim, which concerns training the model's weights, but it means the pipeline that produced the training data was shaped in part by a competitor's open models.
How was MAI-Thinking-1 evaluated?
Microsoft used roughly 40 internal negative-log-likelihood benchmarks scored by tokenizer-invariant bits-per-byte, alongside public reasoning benchmarks including AIME 2025 (97.0%) and SWE-Bench Pro (52.8%). Human evaluation ran through the vendor Surge across 1,276 tasks. All reported numbers are first-party and have not been independently verified.
Need Verifiable Training Data for Your AI Models?
Kili Technology provides the human-in-the-loop annotation and evaluation infrastructure that enterprise AI teams need to build training data they can actually account for. From verified domain specialists — including mathematicians, software engineers, and practicing attorneys — to auditable quality workflows with full annotator-level traceability, Kili delivers the data provenance that turns "clean data" from a marketing claim into an engineering record.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

