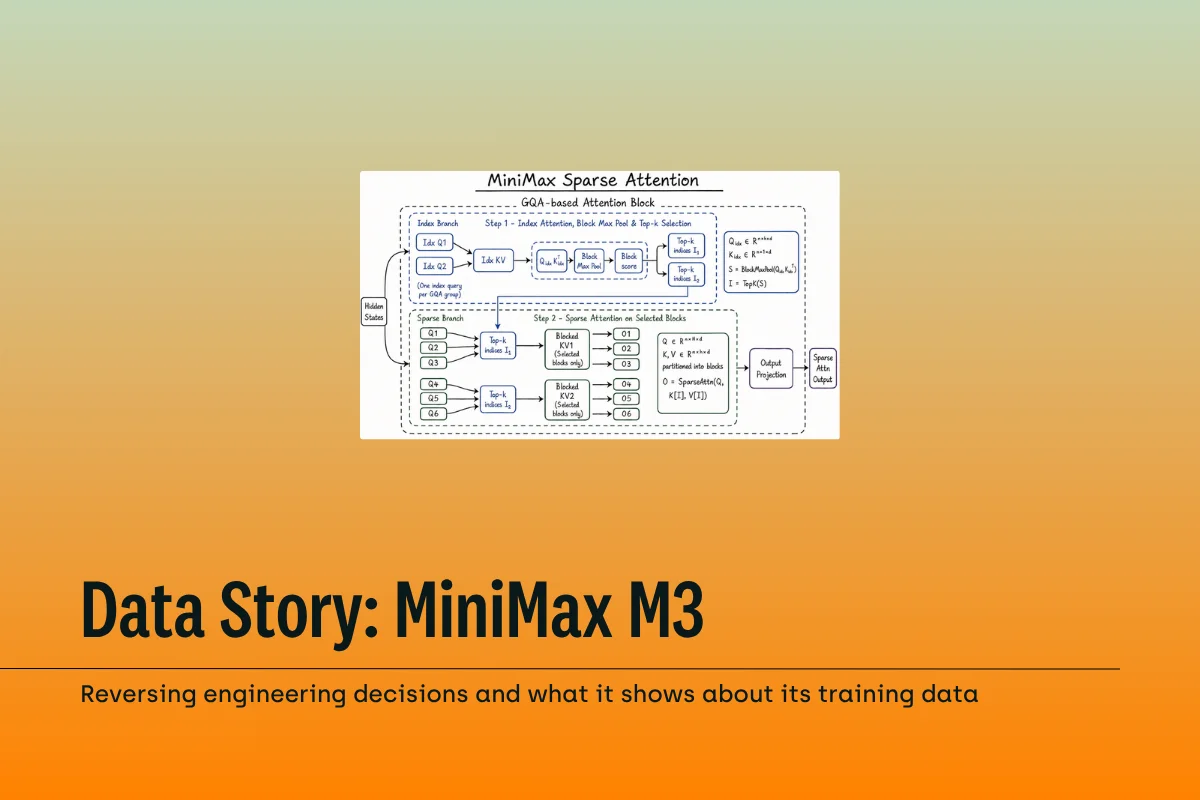
.png)

_logo%201.svg)


AI Summary
- Start with 20–50 test cases drawn from real production failures, not synthetic data.
- A systematic review of 445 public benchmarks found that nearly half lacked a clear definition of the construct they claimed to measure.
- Seven of ten agentic benchmarks audited in a recent study overestimate model performance, with some inflating scores by close to 100%.
- Production agents that score around 60% on a single attempt drop to roughly 25% when the same task is run eight times in a row, exposing a reliability gap that single-shot evaluation scores hide.
- Rubric clarity, not chain-of-thought reasoning or larger judge models, is what drives reliable LLM-as-a-judge evaluation across criteria.
- Kili Technology provides the secure, multi-project platform where enterprises run all five phases of custom benchmark development — from expert task authoring (Phase 2) through rubric calibration (Phase 3) to ongoing maintenance (Phase 5) — with project-level data isolation, configurable QA workflows, and workforce performance tracking across every evaluation program.
Introduction
The case for building custom benchmarks instead of relying on public leaderboards has been made elsewhere. This is the next page. If you are still weighing whether off-the-shelf options cover your domain, our guide to domain-specific benchmarks maps what the public vertical evaluations do and do not measure.
The stakes are not theoretical. MIT Project NANDA's State of AI in Business 2025 found that only 5% of integrated enterprise AI pilots produce measurable P&L impact, with workflow integration and evaluation gaps cited as the binding constraints. The teams shipping the other 95% are mostly not failing on model quality. They are failing on whether anyone can tell, in advance, whether the LLM system will work on real world tasks in production.
If you have already accepted that public benchmarks are insufficient for the LLM application you actually ship, the next question is procedural: where do you start, what do you produce at each step, and how do you know when you can trust the result? The research answers each of those questions, but it answers them across roughly fifteen separate papers and engineering blogs published between mid-2024 and early 2026. No single source gives you the sequence.
This playbook is the sequence. Five phases — scope the construct, source the test set, design the rubric and grader, pilot run and validate, operationalize and maintain — each with a clear input, a clear deliverable, a worked example drawn from a public benchmark, and the failure mode the phase exists to prevent. The benchmark itself is the byproduct; the deliverables are the artifact.
A note on what this guide is not. The governance angle (NIST AI RMF, EU AI Act TEVV, ISO/IEC 42001) is a separate piece for compliance officers auditing custom evals in regulated industries. This is for the practitioner building the LLM evaluation framework. The same five-phase method applies when the construct under test is adversarial robustness rather than capability, which is the subject of our guide to LLM red teaming in 2026.
Phase 1: How Do You Define What You're Actually Measuring?
Phase 1 takes a vague capability statement as input ("our agent should handle support tickets well", "the model needs to reason about contracts") and produces a one-page construct spec: a paragraph defining the construct, the success criteria that distinguishes good from bad model outputs, three or four chosen evaluation metrics with reasons, and the business decision the score will inform. The phase exists to prevent three failure modes: optimizing for an undefined construct, single-metric tunnel vision, and building a research benchmark when you needed a downstream-developer benchmark.
The case for spending real time on Phase 1 sits in Reuel et al.'s 2025 systematic review of 445 LLM benchmarks, which reported that nearly half of widely cited benchmarks had no consensus definition of the phenomenon they claimed to measure, around a quarter relied on convenience sampling, and only just over half provided any construct-validity evidence at all. The benchmarks were not measuring what their names implied. The names implied "reasoning" or "instruction-following" or "safety"; the test set measured something narrower, less defined, or different.
The fix is to write the construct before writing any test cases. What is the capability? What does success look like in your specific deployment context? What decisions will the score inform — go/no-go on a release, A/B between two different models, regression detection, or capability ceiling tracking?
The metric set follows from the decision. Princeton's AI Agents That Matter makes the most useful distinction in the literature: model-developer benchmarks and downstream-developer benchmarks have systematically different requirements. Benchmarks built for model developers need reproducibility and capability ceilings. Downstream-developer benchmarks need cost control, holdout test sets, and reliability under variance. The paper showed that simple baseline agents — just calling the underlying model multiple times — outperformed complex agent architectures on HumanEval at roughly 50× lower cost. A benchmark that ignored cost would have ranked the wrong LLM system first.
The CLEAR framework from Mehta et al. extends this to enterprise agents: Cost, Latency, Efficacy, Assurance, Reliability. Across six leading agents on 300 enterprise tasks, accuracy-only optimization produced LLM systems that ran roughly 4 to 11 times more expensive than cost-aware alternatives with comparable performance. Cost variations of around 50× for similar precision were common. The CLEAR multi-metric score correlated with expert-judged production success at roughly ρ=0.83, while accuracy alone correlated at only ρ=0.41 — a reminder that the choice of metrics matters more than any single accuracy score.
For a usable template, Stanford's HELM reports seven evaluation metrics across 16 scenarios: accuracy, calibration, robustness, fairness, bias, toxicity, efficiency. You probably don't need all seven. You almost certainly need more than one — relying on a single number is one of the most common failure modes in evaluating LLMs.
The construct spec ends Phase 1. Three or four evaluation metrics, defined and justified. One paragraph saying what the construct is. One sentence saying what the score decides. If you cannot write that page, you do not yet know what you are building.
Phase 2: Where Do the Test Cases Come From, and How Many Do You Need?
Phase 2 takes the construct spec as input and produces a task pool of 200 to 500 items with provenance tags, balanced positive and negative cases, reference solutions where applicable, and the test/train/holdout split defined upfront. The failure modes this phase prevents are synthetic tasks that do not reflect real production failures, one-sided test sets that train models to over-trigger or under-trigger, and holdout leakage that inflates evaluation scores.
Anthropic's engineering team gives the most useful starting heuristic in Demystifying evals for AI agents: begin with 20 to 50 test cases drawn from real production failures, then grow from there. The same article makes the diagnostic point that a 0% pass@100 score is most often a signal of a broken task rather than an incapable agent — which only becomes visible if you know where the test cases came from and can read the transcripts when something looks wrong.
Real production failures are the best provenance for evaluation datasets. Synthetic tasks generated by an LLM tend to cluster around the model's existing capabilities and miss the long-tail edge cases that actually break production. The task pool should be tagged: which items came from real user traffic, which from expert authoring, which from synthetic augmentation, and which adapted from public benchmarks for the construct.
Two public benchmarks anchor the upper end of the design space.
SWE-bench mined 2,294 real GitHub issues across 12 popular Python repositories. Every test case is a real bug or feature request that a real developer filed, with a real test suite that actually has to pass. The provenance is the strongest possible signal that the tasks reflect production work. The cost is selection bias toward Python and toward repos that have well-maintained test suites, but the task population was real.
HealthBench shows what expert authoring looks like at scale. OpenAI worked with 262 physicians from 60 countries to author 5,000 multi-turn conversations and over 48,000 unique rubric criteria. Each conversation has its own rubric of typically 10 to 40 criteria, weighted by clinical importance. Most teams will not commission this much expert content. The reusable lesson is the protocol: subject matter experts write tasks, different subject matter experts validate, and the rubric is authored alongside the task.
GPQA Diamond's authoring pipeline is the cleanest reusable protocol for hard test cases. Domain experts write a question. Other domain experts attempt it and revise it. Non-experts with full internet access then attempt the same question. Only items that experts can solve and non-experts cannot are kept. The protocol filters for "actually requires the target capability" without relying on the writer's intuition — a discipline that matters most when the capability under test is something like common sense reasoning, where surface plausibility is easy to fake.
The size question gets less attention than it deserves. 20 to 50 test cases is enough to start finding failure modes. 200 to 500 is roughly where statistical separation between different models becomes reliable for most use cases. HealthBench at 5,000 is exceptional, and most teams should not aim there in v1. The right answer is "enough to discriminate between the LLM systems you actually compare, with the metric you actually report." That is usually a few hundred items, expert-curated, balanced across positive and negative cases.
The balance point is worth flagging. Anthropic's web-search evaluation case study describes the discipline: every "should search" example is paired with a "should not search" example. Without the negative cases, the benchmark rewards over-triggering — false positives go uncounted — and a model that searches on every query scores well. The same pattern recurs for safety filters, refusal behaviors, and tool selection. If you only test cases where the right answer is "do the thing," you have built a benchmark that is silent on the false negatives that probably matter more.
This is the phase where annotation infrastructure earns its place. Multi-annotator validation, inter-rater agreement tracking, and the expert-authored-and-non-expert-tested workflow are not optional add-ons; they are the work. The rubric you write in Phase 3 is only as reliable as the test set you author in Phase 2, and the test set is only as reliable as the domain expertise behind it. Crowdworkers without subject matter expertise produce noisy training data, mislabeled data, and ambiguous reference answers — the kinds of issues that will silently corrupt every evaluation that follows.
Running this at enterprise scale — where multiple evaluation domains are in flight simultaneously — requires platform infrastructure that can manage concurrent evaluation projects with separate test sets per domain, enforce role-based access so evaluators only see their assigned data, automatically distribute tasks to annotators while tracking per-person performance, and maintain audit trails for every task decision. Kili's automatic workload distribution handles the task-routing problem, honeypot and consensus quality metrics surface unreliable annotators before their work corrupts the test set, and project-level data isolation ensures that evaluators working on one domain never see items from another.
Phase 3: How Do You Grade Model Outputs Reliably?
Phase 3 takes the task pool as input and produces a graded rubric with calibration data showing at least 75% agreement with human consensus on a golden subset, plus a grader-priority decision for each task type. The failure mode this phase prevents is the most common one in shipped benchmarks: a vague rubric, an unreliable judge, and noise dominating the score. The numbers move, but the movement does not correspond to actual capability differences.
The headline finding in the recent literature is consistent across multiple papers: rubric clarity dominates LLM-as-a-judge reliability. Autorubric, RULERS, and earlier work on LLM-as-judge configurations all converge on the same point. Chain-of-thought prompting, larger judge models, and prompt template variations matter far less than whether the evaluation criteria are atomic, unambiguous, and evidence-anchored. RULERS specifically demonstrates that smaller judge models with rigorous rubrics outperform larger judge models with vague rubrics. The rubric is the operationalization of the construct.
Analytic rubrics dominate holistic ones. A holistic rubric asks the judge to score 1–5 for "overall quality" — a setup closer to logistic regression on a vague label than to a structured assessment. An analytic rubric breaks the task into specific criteria — did the response cite the correct regulation, did it acknowledge the patient's stated allergies, did it propose a next action — and the judge scores each criterion separately. Analytic rubrics let you compute Cohen's κ per criterion and identify which criteria are unreliable. Holistic rubrics give you one number that hides the failure modes inside it.
HealthBench is the cleanest worked example at scale. Each of the 5,000 conversations has its own bespoke rubric with 10 to 40 criteria, weighted by clinical importance. The model-based grader (GPT-4.1) reaches macro-F1 around 0.71 with the physician panel, comparable to inter-physician agreement on the same items. The model is as reliable as the human experts because the rubric is precise enough to make the judgment well-defined.
Anthropic's three-tier grader stack is the right priority order for most teams. Code-based graders first: when the task has a programmatically checkable answer (a unit test passes, a JSON output validates, a number is within tolerance), use code. Code is fast, deterministic, and does not drift. Model-based graders second: when judgment is required but is well-specified by a rubric, use an LLM judge with the analytic rubric and run calibration. Human review last and sparingly: when the judgment is genuinely subjective or the stakes require it, use named human evaluators with the same rubric.
The calibration step is non-negotiable. Before declaring the rubric ready, take a golden subset (50 to 100 items is typically enough), have human experts grade it independently to establish ground truth, then have the LLM judge grade the same items with the rubric. Compute agreement. If you are below 75% on the criteria you care about, the rubric is not yet ready. Either the criteria are ambiguous, the scale anchors are missing, or the construct itself is underspecified — and Phase 3 has just told you which.
Scaling that calibration across a large evaluator pool introduces its own operational requirements: multi-step review workflows with configurable sampling rates so that not every item needs full review but enough do to maintain quality, step-separation enforcement so the same person cannot both write and validate a given rubric item, and per-annotator quality scoring so you can identify and retrain underperforming evaluators. Kili's Workflow V2 supports custom review steps with configurable sampling rates between steps and an enforce-step-separation toggle that prevents contamination between authoring and validation stages.
This is also where named domain experts matter most. A radiologist and a generalist physician will disagree on what counts as a complete radiology report. A securities lawyer and a generalist counsel will disagree on what counts as adequate disclosure. The rubric is only useful to the extent that the people calibrating it understand the construct in the production context, which is why crowd-sourced calibration tends to fail on technical domains. The expert-authoring protocol from Phase 2 carries through to Phase 3: same subject matter experts, or at least the same expertise level, doing the calibration work.
The deliverable is a rubric template (criteria, scale anchors, weights), a calibration sheet (with the per-criterion agreement numbers), and a one-line grader-priority decision for each task type in the pool.
Phase 4: How Do You Validate the Pilot Run Before Trusting It?
Phase 4 takes the rubric and grader from Phase 3, runs them against three to five baseline systems, and produces a first leaderboard with a full validity audit attached: pass@k separated from pass^k, cost-per-task tracked, and a "do-nothing" baseline included. The failure mode this phase prevents is shipping a benchmark that overestimates performance by 30% or more due to grader bugs, ambiguous specs, harness gaming, or gameable shortcuts. The benchmark gets cited, results compound, and the corrections only surface a year later.
Zhu et al.'s NeurIPS 2025 paper Establishing Best Practices for Building Rigorous Agentic Benchmarks gives the most concrete artifact in the literature: the Agentic Benchmark Checklist, organized around task validity (does the task actually require the target capability), outcome validity (does the grader correctly identify success), and reporting. Applied to ten popular benchmarks, seven had outcome-validity flaws, seven had task-validity flaws, and all had reporting limitations. The specific failure modes are sobering: SWE-Lancer can be scored 100% without solving any tasks, KernelBench overestimates by 31 percentage points absolute due to incomprehensive fuzz testing, and WebArena overestimates by around 5 percentage points from string-matching issues in the grader. The checklist exists because every team that ships a benchmark thinks they have already considered these failures, and the audit usually finds at least one.
SWE-bench Verified is the most public worked example of the audit process. OpenAI's expert audit of the original SWE-bench removed roughly a third of the original tasks as ambiguous or infeasible. A third of the original score was noise rather than signal. The benchmark did not improve because the systems improved. It improved because someone read every task and asked whether it actually tested what the benchmark claimed to test.
Anthropic's CORE-Bench example is similar. Opus 4.5 went from 42% to 95% on CORE-Bench after fixing grader bugs and scaffold constraints, meaning the benchmark had been understating model performance by 53 percentage points. Either direction of error is fatal in production decision-making.
Four specific checks belong in Phase 4.
Read the transcripts. Anthropic's engineers list this as Step 6 in their roadmap and emphasize that it is non-negotiable. Run baseline systems against the benchmark, then read what they actually produced. Tasks that score 0% across all systems are usually broken: either the grader rejects valid solutions, or the task is genuinely impossible. Tasks that score 100% across all systems often test something other than what the construct claimed. There is no substitute for human review at this stage — automated scoring will not catch issues that only a reader can see.
Separate pass@k from pass^k. The CLEAR framework's reliability finding — where roughly 60% pass@1 drops to about 25% pass^8 — only becomes visible when you run each task multiple times and report both metrics. Pass@k tells you the ceiling. Pass^k tells you what production will actually see. Reporting only one is reporting half the story, a point our data story on open-weight coding models illustrates with a single model's scores swinging across run configurations. Princeton's Towards a Science of AI Agent Reliability extends this further with 12 metrics across consistency, robustness, predictability, and safety, and reports that capability gains tend to yield only small reliability improvements.
Include a "do-nothing" baseline. Princeton's Holistic Agent Leaderboard documents that simple baselines — calling the underlying model multiple times with no agent scaffold — beat purpose-built agents on several published benchmarks. A do-nothing agent passes around 38% of τ-bench airline tasks. If your benchmark cannot distinguish your system from a do-nothing baseline, the benchmark is not yet measuring agent-specific capability.
Probe for contamination. If any task in the pool came from public sources, run a contamination check. Models trained on web crawls have likely seen public benchmarks. The fix is not perfect, but date-stamped private holdouts and canary strings are a start. Red teaming — deliberately constructing adversarial test cases against the benchmark itself — also belongs here as a way to surface gameable shortcuts before adversaries find them in production.
The output of Phase 4 is the validity audit report. Without it, the leaderboard is a number that may or may not mean what you think.
Phase 5: How Do You Keep the Benchmark Useful Over Time?
Phase 5 takes the validated v1 benchmark and produces a versioned, contamination-resistant artifact with a maintenance schedule, a private holdout split, a canary string, a production-failure feedback loop, and a regression-suite policy. The failure modes this phase prevents are slow-burn ones: the benchmark expires inside a year, saturates silently, gets contaminated, or loses ownership when the original team moves on.
The capability-versus-regression-eval framing from Anthropic is the core operational concept. Capability evals start at low pass rates of 5% to 30%; they give the team a hill to climb. Regression evals run at near 100%; they protect against backsliding. The same article reports SWE-Bench Verified going from 30% to over 80% in twelve months. As capability evals saturate, they graduate to regression suites — automated unit tests for evaluating LLMs that catch issues before a new model ships. The v1 benchmark that took eight weeks to build is not the eval the team will be running in a year. Plan for the transition.
Three specific operational deliverables belong in Phase 5.
Versioning policy. Every eval run is tagged with the model version, prompt template version, rubric version, and benchmark version. Without this, you cannot attribute score movements to capability changes versus benchmark changes. Document the software/hardware environment and pin dependency versions so the benchmarking harness produces consistent results across runs. The cost of doing this correctly from the start is small. The cost of reconstructing it later is large.
Contamination defense. The pattern across LiveCodeBench (date-stamped problems), GPQA Diamond (canary GUIDs), and BIG-Bench (canary strings) is consistent: hold a portion of the benchmark fully private, embed unique tokens that flag if the data appears in future training corpora, and date-stamp problems so you can track which items predate which model release. ConTAM and similar surveys document the techniques in detail.
Production-failure feedback loop. The benchmark is a living artifact. New failure modes show up in production every week. The discipline is to feed those failures back into the evaluation dataset, re-annotated, calibrated, and added to the task pool. User feedback on real-world model outputs becomes the next iteration's test cases. This is where the upstream annotation work compounds. A team with a working labeling pipeline turns each production incident into a permanent regression test. A team without one accumulates incidents they cannot systematically prevent from recurring.
Continuous re-annotation at this cadence requires a persistent platform with versioned projects so you can track how the test set evolves across evaluation rounds, API-driven data pipelines for feeding production failures back into the task pool without manual file transfers, and programmatic project creation so new evaluation rounds can be spun up automatically as production surfaces new failure classes. Kili's Python SDK and GraphQL API handle the data-pipeline integration, webhooks trigger downstream processes when annotation is complete, and project versioning preserves the full history of each evaluation round for auditability.
The ownership model also belongs in Phase 5. Anthropic's pattern — eval teams own the infrastructure, product teams contribute the tasks — works because it separates the people who care about benchmark quality from the people who know what tasks should be in it. For the maintenance discipline itself, BetterBench (NeurIPS 2024 Spotlight) gives the most rigorous published checklist: 46 best practices spanning the benchmark lifecycle, with the weakest areas across 24 surveyed benchmarks being implementation and maintenance. The closest open-source analogs are the HAL Reliability Dashboard for the metric set and Inspect AI for the eval framework, alongside Hugging Face's Evaluation Guidebook and Lighteval for teams who want a practitioner-oriented toolchain. All four reflect the same lesson: a maintained benchmark is an institution, not a one-off project.
Model Evaluation vs. LLM System Evaluation: Why the Distinction Matters
The playbook above describes how to evaluate an LLM system — the full application including prompts, retrieval, tool calls, and post-processing — rather than how to evaluate a foundation model in isolation. The two are different disciplines.
LLM model evals measure foundational capability on a broad range of tasks: math competitions, multiple choice question answering, common sense reasoning, factual accuracy. Public benchmarks such as MMLU, GPQA, and SWE-bench are designed for this. They tell you how newly released LLMs compare against each other, and model developers depend on them.
LLM system evals measure whether your specific LLM application — a particular prompt template, retrieval setup, tool stack, and post-processing layer wrapped around a chosen model — produces the model outputs your business requirements call for, on the open-ended generation patterns your users actually send. A model that scores well on key benchmarks can still fall short in your LLM system because the prompts, the context, or the orchestration layer fail. The construct spec from Phase 1, the test cases from Phase 2, and the rubric from Phase 3 are all built around the system, not the model alone.
Both evaluations matter. Model evaluation tells you whether to adopt a new model at all. System evaluation tells you whether your application built on that model is shippable. For enterprises running system evaluation across multiple AI products or business units simultaneously, the evaluation platform itself needs to support multi-project management with data isolation between workstreams — the same operational requirements that apply to large-scale data labeling. The five-phase playbook is for the second.
The Playbook is the Artifact
Five phases, five deliverables. Construct spec. Task pool with provenance. Rubric with calibration. Validity audit. Versioning and maintenance plan. The benchmark itself is the byproduct of producing those deliverables in sequence.
The upstream data work — task authoring, rubric design, multi-annotator calibration, and production-failure mining — is what makes the playbook executable rather than aspirational. Every phase from 2 onward depends on having access to named domain experts who understand the construct in your production context, on annotation infrastructure that lets you track inter-rater agreement, and on a workflow that turns production incidents into evaluable items. The 445-benchmark review and the agentic benchmark audit converge on the same finding: most teams ship benchmarks that overestimate performance because the upstream work was rushed or skipped.
The teams that ship benchmarks they can trust treat evaluation as a first-class engineering discipline with first-class data infrastructure behind it. That is the work this playbook describes.
Resources
Methodology and Best Practices
- Demystifying evals for AI agents (Anthropic Engineering) — Eight-step roadmap from no-evals to trustable evals
- Establishing Best Practices for Building Rigorous Agentic Benchmarks (Zhu et al., NeurIPS 2025) — The Agentic Benchmark Checklist
- Measuring what Matters: Construct Validity in Large Language Model Benchmarks (Reuel et al., 2025) — Systematic review of 445 benchmarks
- BetterBench: Assessing AI Benchmarks (Reuel et al., NeurIPS 2024) — 46-item assessment framework
Public Benchmarks Referenced
- HealthBench (Arora et al., OpenAI, 2025) — 5,000 expert-authored conversations with instance-specific rubrics
- GPQA Diamond (Rein et al., 2023) — Expert-write, expert-validate, non-expert-test pipeline
- SWE-bench — Real GitHub issues with executable test suites
- SWE-bench Verified (OpenAI) — Human-filtered subset methodology
- Stanford HELM — Multi-metric evaluation across 16 scenarios
- LiveCodeBench — Date-stamped problems for contamination defense
- BIG-Bench — Canary string contamination defense pattern
Production and Reliability
- Beyond Accuracy: A Multi-Dimensional Framework for Evaluating Enterprise Agentic AI Systems (Mehta et al., 2025) — The CLEAR framework
- AI Agents That Matter (Kapoor, Stroebl, Siegel, Nadgir, Narayanan, Princeton, 2024) — Model-developer vs. downstream-developer benchmarks
- Towards a Science of AI Agent Reliability (Rabanser et al., Princeton, 2026) — 12 metrics across consistency, robustness, predictability, safety
- Holistic Agent Leaderboard (Princeton, ICLR 2026) — Standardized agent evaluation infrastructure
Rubric and Judge Design
- Autorubric (Wei et al., 2026) — Analytic rubrics with per-criterion atomic evaluation
- RULERS (Hong et al., 2026) — Locked rubrics and evidence-anchored scoring
Tooling and Frameworks
- Inspect AI (UK AI Security Institute) — Open-source eval framework
- Hugging Face Evaluation Guidebook & Lighteval — Practitioner-oriented eval framework
Contamination Defense
- ConTAM Survey on Benchmark Contamination Defenses (2025) — Canary strings, private benchmarks, date-stamping
Industry Context
- MIT Project NANDA — The GenAI Divide: State of AI in Business 2025 — Enterprise AI deployment gap analysis
- Kili Technology — Secure, multi-project platform for custom benchmark development with configurable QA workflows and workforce performance tracking
Frequently Asked Questions
How many test cases do I need in a custom AI benchmark to get statistically reliable results?
Start with 20 to 50 test cases drawn from real production failures to surface the first round of failure modes. Scale to 200–500 items for reliable statistical separation between the LLM systems you are comparing. The exact number depends on the granularity of the metrics you report and how close the systems are in performance — tighter margins require larger test sets to distinguish signal from noise.
Can I use LLM-as-a-judge instead of human evaluators for grading benchmark outputs?
Yes, but with guardrails. LLM-as-a-judge works well when paired with an analytic rubric that has atomic, evidence-anchored criteria and calibrated scale anchors. The research consistently shows that rubric clarity matters more than judge model size. You still need human experts to calibrate the rubric against a golden subset of 50–100 items and to verify at least 75% agreement before trusting automated grading at scale.
How do I prevent my custom benchmark from becoming contaminated by model training data?
Three defenses work in practice: hold a portion of the benchmark fully private and never publish it, embed canary strings or unique tokens that flag if the data appears in future training corpora, and date-stamp test cases so you can track which items predate which model release. Refreshing the test set with new production failures on a regular cadence also limits the window of contamination exposure.
What platform capabilities do I need to run a custom benchmark program at enterprise scale?
At minimum, you need multi-project management with data isolation between evaluation domains, role-based access control so evaluators only see their assigned workstreams, configurable multi-step review workflows for rubric calibration, automatic workload distribution with per-annotator performance tracking, and API-driven data pipelines for feeding production failures back into the test set. Kili's platform provides all of these, along with SOC 2, ISO 27001, and GDPR compliance for regulated industries.
How often should I update my custom AI benchmark after the initial launch?
Treat the benchmark as a living artifact with a defined maintenance cadence. Capability evals that start at low pass rates will saturate within months as models improve; when they do, graduate them to regression suites and build the next capability eval. Production-failure feedback should flow into the test set continuously, with formal re-calibration of the rubric at least quarterly. Version every component — model, prompt template, rubric, and benchmark — so you can attribute score changes to capability shifts rather than benchmark drift.
Ready to Build a Custom AI Benchmark You Can Trust?
Building a custom benchmark is an ongoing operations discipline. Kili provides the platform infrastructure — multi-project management, configurable QA workflows, project-level data isolation, API automation, and workforce performance tracking — that makes that discipline executable at enterprise scale, with the security and compliance (SOC 2, ISO 27001, GDPR) that regulated industries require.
The five phases in this playbook each impose specific operational requirements: concurrent evaluation projects with role-based access in Phase 2, multi-step review workflows with step-separation enforcement in Phase 3, and versioned projects with API-driven data pipelines in Phase 5. Kili's platform is built to meet those requirements across the full benchmark lifecycle. For teams that need to scale evaluator capacity quickly, Kili's managed expert workforce provides surge capacity with named domain specialists who integrate directly into the platform's annotation and calibration workflows.