
.png)

_logo%201.svg)


AI Summary
- The difference between good and bad annotation programs is visible before a single label is produced - in how much time is spent defining the task upfront.
- Domain knowledge matters, but the ability to understand a task, calibrate to the required precision, and hold the right speed is what separates reliable annotators from unreliable ones.
- Automation accelerates annotation only when a rigorous human correction layer follows - pre-annotation without it propagates model errors directly into training data.
- Handling mid-project ambiguity with a clear process - including the ability to remediate previously labeled data - keeps annotation programs from compounding early mistakes at scale.
- PFAI retains annotators on permanent contracts with below 5% turnover, building institutional knowledge that transient crowd-sourced workforces cannot replicate.
- End-to-end AI data services require infrastructure, automation, and human judgment working as a single system - stress-tested in a POC before full production.
- Kili Technology provides the platform infrastructure that makes expert-led annotation scalable and auditable across the full data production lifecycle.
The conversation about AI data quality has shifted. For years, the default assumption was that more data — and cheaper data — was the path to better models. Crowd-sourced platforms, low-cost annotation pipelines, and sheer volume were the levers teams pulled. The results were predictable: high error rates, model failures in production, and a growing realization that data labeling quality, not just data quantity, is the actual constraint on AI performance.
What that shift looks like in practice is what this article is about. We sat down with People for AI (PFAI), one of Kili Technology's strategic annotation service partners,¹ to talk through how they build, train, and retain the annotation teams that enterprise AI projects depend on — and what makes the difference between a labeling operation that produces reliable training data and one that doesn't.
¹ Kili Technology was named a G2 Momentum Leader for Spring 2026, recognized based on verified user reviews for its trajectory in the data labeling category.
Why Does What Happens Before Annotation Begin Matter More Than the Annotation Itself?
The case for prioritizing throughput is intuitive: faster labeling means faster model iteration. But PFAI's experience building annotation programs for complex enterprise datasets points to a different bottleneck entirely — one that appears before a single label is produced.
Their first questions when onboarding a new client are about the data itself: what kind of data needs to be annotated, whether annotated examples already exist, and whether annotation guidelines have been written. They also ask directly about the precision the project requires. Some projects demand extremely tight annotations; others are more tolerant and can trade some precision for speed. Understanding that tradeoff early is not a formality — it shapes every downstream decision about team composition, training, and QA.
Whenever possible, PFAI runs a small test on sample data before committing to production. They review the results with the client together: what worked, what could be improved, what could be simplified without sacrificing the expected quality level. If the client has a model capable of generating pre-annotations, PFAI asks about it at this stage — not as an afterthought, but as part of how they design the workflow from the start.
What distinguishes PFAI from a standard labeling operation is visible right here. If you watched their team set up a project compared to a traditional operation, you would see more time spent asking questions and defining annotation guidelines before production starts, and more feedback loops in the first stages to ensure quality matches what the client actually needs. The annotations themselves may look similar. The conditions that determine whether they stay consistent across thousands of assets are built — or not built — in this phase.
The payoff is compounding. When guidelines are tight and ambiguities are resolved before scale, the data reaching the model training pipeline carries consistent signal. When they're not, the model learns the noise alongside the pattern.
How Does PFAI Match the Right Annotators to Complex Projects?
Not every project requires domain experts. But when one does, PFAI's ability to staff it correctly depends on institutional knowledge they've been building since the first annotator they hired.
PFAI maintains a detailed, continuously updated map of annotator competencies: who specializes in text annotation, 3D data, microscopy images, food classification, and so on. They also track tool familiarity. When a complex project arrives requiring very specific skills, they don't post a job — they go to the annotators who already have relevant experience in that domain and have demonstrated they perform well on similar work.
This matters for a reason that isn't obvious: domain knowledge and annotation ability are not the same thing. PFAI is candid about this. Some annotators with deep domain expertise struggle with the specific demands of annotation work — the required precision, the pace, the consistency across long sessions. Others with no domain background adapt quickly, internalize guidelines rapidly, and hold quality better under production conditions. What matters most, in PFAI's experience, is that annotators clearly understand the task, the expected precision level, and the appropriate speed required to achieve that level of quality. Domain knowledge is an asset. It doesn't substitute for annotation craft.
Once the right people are identified, onboarding is structured and iterative. PFAI prepares training material with clear guidelines and examples drawn from the client's own dataset wherever possible. If the client doesn't have guidelines yet, PFAI helps build them from the questions they asked during project setup. Training typically includes a presentation of the guidelines, a live demonstration of how annotations should be performed, and then hands-on exercises with direct feedback on both quality and speed. Depending on project complexity, this process runs from a few hours to several weeks — and PFAI doesn't shortcut it, because the cost of misaligned annotators at scale is orders of magnitude higher than the cost of a longer onboarding.
How Does PFAI Combine Automation and Human Review Without Sacrificing Quality?
Speed and quality are usually framed as a tradeoff in annotation. PFAI's approach is more precise: automation and human expertise are applied at different stages of the same workflow, and the right sequencing is what determines whether you get both.
When Automation Enters the Pipeline
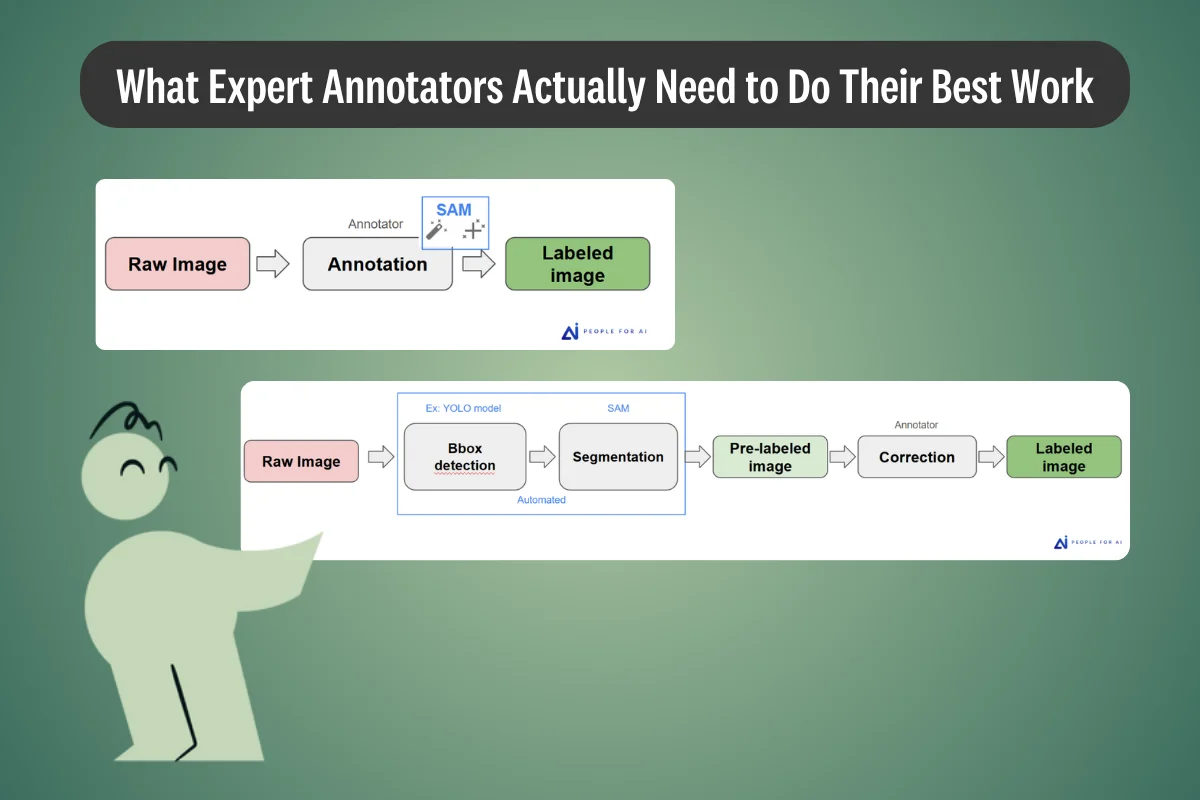
PFAI's technical team builds pre-annotation pipelines when the task and available models justify it. The baseline workflow without automation is direct: a raw image goes to the annotator, who uses SAM as an interactive segmentation assistant where relevant, and produces a labeled image.
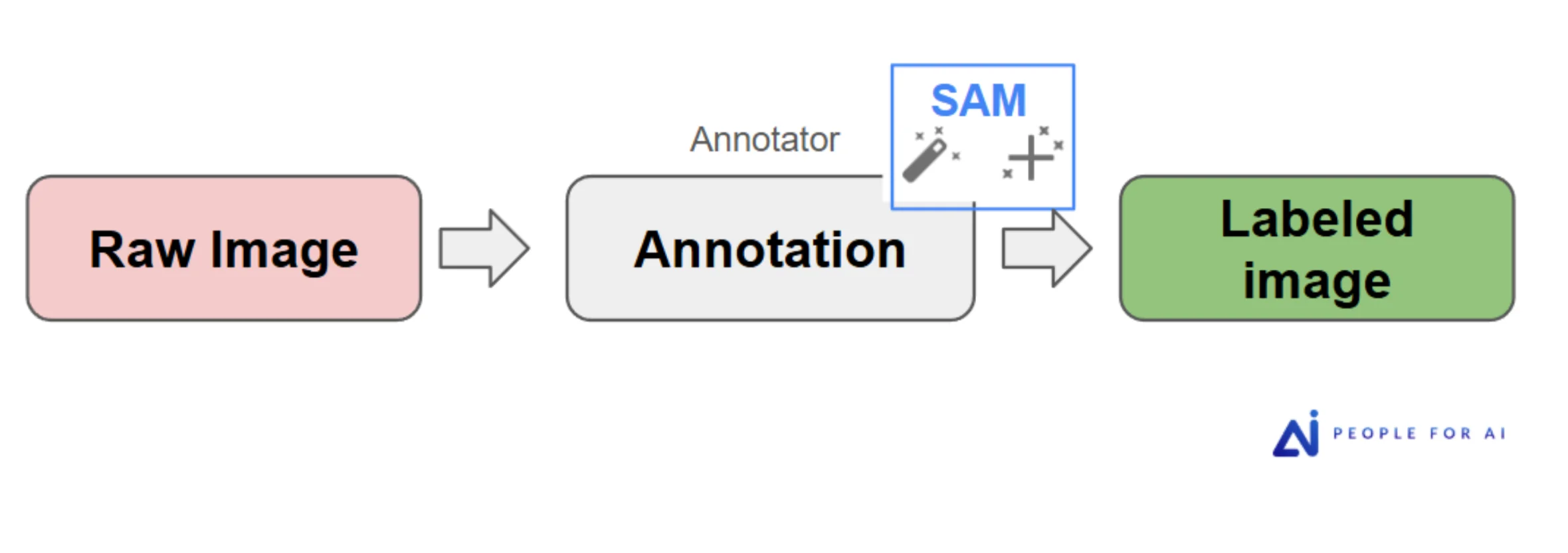
When pre-annotation is viable, the pipeline extends upstream. For a project requiring person segmentation across a large image corpus, PFAI built a two-stage automated pipeline: a YOLO model for bounding box detection, followed by SAM for segmentation. Images arrived to annotators already pre-labeled — the human role shifted from producing annotations from scratch to correcting what the models got wrong.
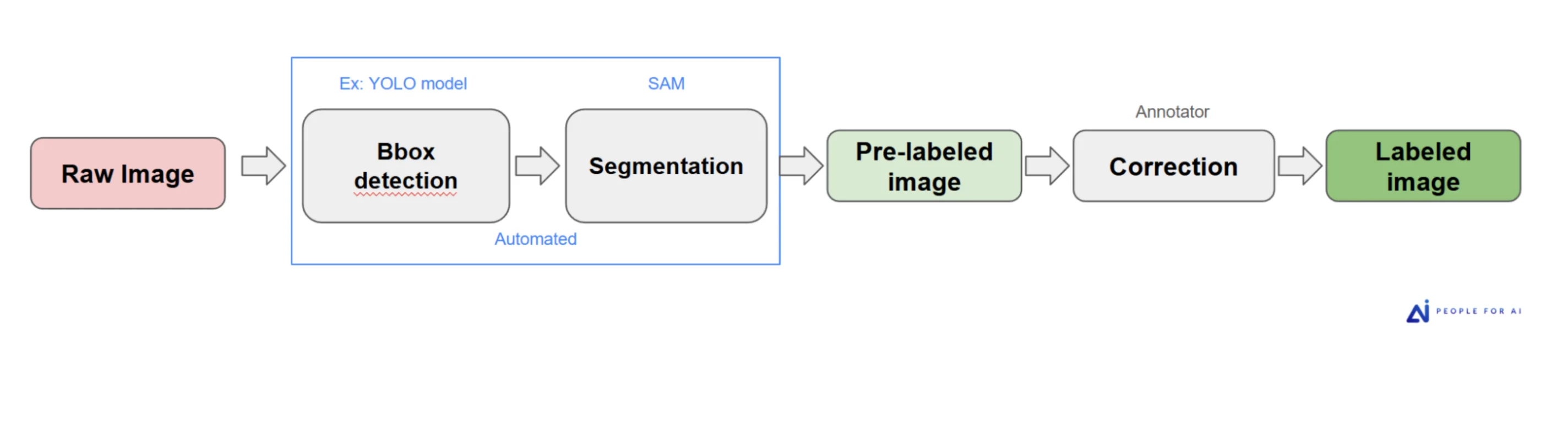
The throughput gain was significant. The quality held because the correction step remained human-driven — annotators weren't rubber-stamping model output, they were applying judgment to it. That distinction matters: pre-annotation without a rigorous human correction layer tends to propagate model errors into the training set, which then re-trains the next model on those same errors.
Most projects don't start with pre-annotations at all. When a client's model exists and is capable, pre-labels may come directly from it. When no model exists yet, annotation begins from zero. Automation is a tool in the workflow, not a default assumption — and PFAI applies it where it genuinely accelerates work, not as a way to reduce the human expertise involved.
How the QA Layer Is Structured
At project launch, PFAI reviews 100% of annotations through their QA team. The purpose is twofold: validate label quality and validate annotation speed — both need to be demonstrated before the project scales. Once consistency is established across the early batches, they shift to sampling-based reviews. Samples can be drawn randomly, but PFAI also targets specific annotators, specific classes, or specific time windows when patterns in the error data suggest a focus is warranted.
This tiered approach only works in practice when the underlying platform makes filtering and reviewing fast enough to keep pace with production output. PFAI is direct about this dependency: Kili's review filters and quality tooling are what make their QA workflow efficient at scale. Without platform-level infrastructure — label filtering by confidence or disagreement, annotator performance tracking, targeted review queues — the manual overhead of meaningful QA becomes a ceiling on how much volume you can actually manage without letting quality slip.
Automated Error Detection as a Third Layer
Beyond human review, PFAI builds automated validation checks specific to each dataset's domain logic. An ice hockey player-tracking dataset carries a hard rule: no two players on the same team can share a jersey number. PFAI's technical team writes automated checks that run regularly against the labeled data, generating lists of potential violations for reviewers to verify and correct. Errors that visual spot-checks would miss surface systematically, before they accumulate into a retraining problem.
Automation also handles project management overhead that would otherwise consume the attention of the people responsible for quality. Task assignment, statistics generation, workflow follow-ups — when these run automatically, project managers can focus on the work that actually requires their judgment rather than on administration. Kili's API is what makes this kind of programmatic project management possible at scale, and PFAI treats it as a core part of how they operate, not a nice-to-have integration.
How Does PFAI Handle It When the Ground Shifts Mid-Project?
Even well-prepared annotation programs encounter ambiguity mid-project. What separates operations that handle it well from those that don't is whether there's a clear process for surfacing, resolving, and propagating guideline changes — including back through data that was labeled before the change.
PFAI's approach starts with questions and concrete examples. When an ambiguity surfaces, they document it, propose examples that illustrate the edge case, and ask the client for clarification. If the answer contradicts the current guidelines, they assess whether the guidelines need to change — and if so, they organize a meeting to ensure both sides have the same understanding before any correction begins, and to evaluate the scope of impact on previously labeled assets.
A real example: midway through a product classification project, PFAI noticed that the client answered one of their clarifying questions differently from what the existing guidelines specified. The rule in question was whether to classify a product as "not sure" when less than 50% of it was visible. The client's answer implied a different threshold — the product should be classified as long as it could be recognized, even if only a small portion was visible.
PFAI flagged it, confirmed the discrepancy, and the client realized the instructions needed to be updated for the specific dataset. PFAI updated the guidelines, briefed the annotation team, and went back through the previously labeled data using class-level filters in the annotation tool to identify and correct the affected labels.
This kind of mid-project catch is only possible if the workflow includes the right combination of active communication and platform tooling. The shared Q&A document PFAI maintains throughout every project — where any team member can log questions as they arise — is part of what creates the surface area for these issues to be seen before they compound. Catching a guideline misalignment early, before it's replicated across thousands of assets, is significantly less expensive than discovering it when the model fails to generalize.
What Does the Client Relationship Actually Look Like Day to Day?
PFAI's position is that client involvement isn't a nice-to-have — it's a structural requirement for annotation quality. The closer the feedback loop between the annotation team and the people who understand what the model actually needs, the faster misalignments get caught and the better the data gets over time.
In practice, this means clients have direct access to the annotation environment throughout the project. They can review annotations in real time whenever they want. PFAI also exports annotated data on a regular cadence — typically weekly — so clients can review outputs on their own systems and provide structured feedback on what needs adjustment.
The communication layer is intentionally flexible. PFAI maintains a shared Q&A document where all questions and clarifications are tracked. They also maintain a direct channel — Teams, Slack, Zoom — for questions that need fast answers. Some clients prefer to answer questions synchronously as they arise; others prefer to consolidate discussions into a weekly meeting. PFAI adapts to whichever rhythm works for the client's team.
For long-term projects, the relationship evolves beyond QA and feedback. Clients actively select the new data they send to PFAI based on where their models are currently weakest — new use cases, edge cases that caused failures in production, underrepresented classes. This turns the annotation program into a direct input to model improvement strategy, rather than a background operation running on autopilot. Timelines and priorities shift as models evolve, and PFAI explicitly designs for that agility rather than treating each data batch as a fixed-scope project.
What Makes PFAI's Annotator Model Different from the Crowd?
PFAI's annotators are full-time employees on permanent contracts, working in a shared office environment, grouped by project. Turnover is below 5%.
In an industry where crowd-sourced annotation platforms routinely contend with transient workforces — high churn, inconsistent training, variable output — a sub-5% turnover rate means the same person who annotated your dataset in month one is still annotating and improving in month six. The knowledge of the dataset, the domain, and the edge cases accumulates in that person. It doesn't have to be rebuilt with every new batch of workers.
When a project needs to scale, PFAI doesn't simply open up the queue to more workers. They keep the core team intact and bring in new annotators in small groups — two, five, or ten at a time depending on project size. New annotators are trained by the project manager and spend time observing experienced team members before touching production data. Once they start, their work is closely monitored for both quality and speed until they demonstrate they meet the same standards as the rest of the team. The consistency of the existing team is treated as an asset to be protected, not a baseline to be diluted.
The organizational structure reinforces this over time. PFAI has built a formal career progression: annotator → reviewer → project manager, each level with three internal sub-levels. Half of their current project managers started as Level 1 annotators. This is not a commodity workforce — it's a professional pipeline where expertise compounds with tenure, and where the people managing quality were once the people producing it. Each project also has Subject Matter Experts — either senior annotators or managers — who are the first point of contact when questions arise and are brought into client meetings when the complexity warrants it.
What this produces, over time, is institutional knowledge embedded in the annotation team. An annotator six months into a complex computer vision dataset understands the visual edge cases of that domain in ways a generalist worker cannot replicate. The models trained on that annotator's work inherit that understanding.
What Does a Real Outcome Look Like?
PFAI's long-term engagement with Stathletes (formerly Reap Analytics), a sports data analytics company specializing in ice hockey tracking, illustrates what this model produces in practice.
Before engaging PFAI, Stathletes had worked with multiple data labeling vendors. None had delivered the consistency their models required to perform at production standards. After transitioning to PFAI's model — stable teams, structured onboarding, tiered QA, domain-specific validation rules, and a close client feedback loop — the improvement in data quality was material enough that the Stathletes data science team could stop managing annotation problems and redirect their time toward building new models and features.
This is the actual outcome end-to-end AI data services should deliver: not just labeled assets, but a reliable data pipeline that frees the data science team to do data science. The annotation operation becomes infrastructure — consistent, auditable, improvable — rather than a recurring source of rework.
Is the Role of Human Annotators Shrinking or Shifting?
PFAI has watched the "data labeling is dying" narrative circulate for years. Their response is grounded in what their clients are actually asking for.
Technology is evolving fast. But based on the complexity of the projects coming through their pipeline, PFAI's view is clear: data labeling has a future — one that increasingly looks like expert annotation at smaller, higher-quality volumes, rather than basic annotation at massive scale. As more companies build AI products, demand for labeled data remains high. What's changing is the standard.
The annotation work that automated pipelines cannot reliably perform — nuanced domain judgments, adversarial evaluation, complex reasoning tasks, edge cases where model failures originate — is precisely where human annotators are becoming more important, not less. As models improve at handling straightforward, high-volume labeling, the work that remains is harder. PFAI's answer to this is deliberate: ensuring annotators grow and evolve alongside the projects they work on, so that their teams are capable of handling increasingly complex tasks as the baseline rises.
For enterprise AI teams, the implication is direct: annotation requirements don't get simpler as models improve. The gap between what a standard pipeline produces and what a production-quality model actually requires is filled by annotators who have been developed — not just hired — for the work.
Conclusion: What End-to-End Really Means
"End-to-end data labeling services" appears in a lot of vendor positioning. What PFAI's approach makes clear is what it actually requires in practice: not just a workforce and a tool, but a continuous operational loop — task definition, annotator selection and training, pre-annotation pipeline design, tiered QA, mid-project ambiguity handling, client feedback integration, and iteration as models evolve — managed by people who understand both the data and the models it feeds.
PFAI is also candid about what this takes: it requires time. Building high-quality data requires the right combination of guidelines, capable tooling, and structured process working together. That's why they recommend starting every engagement with a Proof of Concept. By the end of a POC, PFAI and the client are fully aligned on instructions, quality, and speed. Once that foundation is set, productivity scales without quality eroding — because the system is already stress-tested before it's running at full volume.
Kili's role in that loop is the infrastructure layer that makes it scalable and auditable. The platform's review tooling, API accessibility, and audit trails are not features in isolation — they're the connective tissue between what PFAI's annotators produce and what a client's model training pipeline can reliably consume. On the services side, Kili staffs every project with experienced ML engineers and data scientists rather than operations managers — a deliberate choice that keeps the technical judgment close to the data decisions.
The organizations building reliable AI in 2026 are not choosing between good annotators and good tooling. They're investing in both, together, as a single system. That's what makes the data production side of the AI lifecycle something a data science team can actually depend on — rather than something they have to manage around.
Resources
Partner and Platform
People for AI (PFAI) — Annotation services partner specializing in expert-led, permanent annotator teams
Kili Technology Platform — Collaborative AI data platform for enterprise annotation workflows
Kili Managed Data Labeling Services — Data science-led, end-to-end annotation and AI evaluation services
Kili Python SDK Documentation — API and plugin reference for workflow automation
Background Reading
Data Labeling for Machine Learning: A Guide — Kili Technology
Data-Centric AI: From the Lens of a Data Labeling Platform — Kili Technology
G2 Spring 2026 Reports Overview — G2
Kili Technology on G2 — Verified user reviews
Stathletes (formerly Reap Analytics) — Ice hockey data analytics
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

