
.png)

_logo%201.svg)


AI Summary
- Agentic AI benchmarks test multi-step task completion (tool use, code, browser actions), not single-prompt accuracy.
- Berkeley scored 100% on four major benchmarks while solving zero tasks.
- 83% of evaluations measure only technical metrics; safety, cost, and human factors go untested.
- Closing the gap takes layered, human-calibrated evaluation rather than a higher leaderboard score
Introduction
Over the past few years, agentic AI benchmarks have become the default way teams judge whether AI agents are ready to ship. Yet enterprise teams keep discovering the same uncomfortable thing: an agent that aces the leaderboard stumbles the moment it touches a production workflow.
The numbers put a scale on it. Aggregated enterprise deployment data points to a 37% gap between lab benchmark scores and real-world performance, with accuracy that holds at 60% on a single run collapsing to 25% across eight consecutive runs. Cost for similar accuracy varies by as much as 50x depending on how the agent is run. The leaderboard says one thing; the deployment says another.
That gap is not a rounding error, and it is not going away on its own. Agentic benchmarks have multiplied fast: tool-use boards, coding boards, browser-automation boards, customer-service simulators, each claiming to capture how well an agent "works." Underneath the proliferation sits a measurement problem that most leaderboards quietly inherit. They score narrow capabilities in controlled environments and present the result as if it predicted behavior under real conditions.
This guide does three things. It defines what agentic AI benchmarks are and how they differ from older single-prompt evaluations. It walks through how the major 2026 boards work under the hood, because methodology determines what gets measured. And it lays out, with specifics, why a high score is a weak predictor of production success, plus what benchmark designers, standards bodies, and practitioners are doing to close the distance.
What Are Agentic AI Benchmarks?
Agentic AI benchmarks are standardized testing frameworks built to evaluate autonomous AI systems on tasks they have to work through rather than questions they simply answer. A traditional language model benchmark asks a specific question and grades a single answer. An agentic benchmark grades a process: it hands the model a goal, gives it tools (a shell, a browser, an API, a set of MCP servers), and measures whether the agent can plan, act, observe results, and recover from its own mistakes across many steps until the task is either done or failed.
That shift in the unit of measurement changes everything downstream. You are no longer scoring a string of text against a reference answer. You are scoring a trajectory: a sequence of tool calls, intermediate states, and decisions, any one of which can derail the whole run. Two agents handed the same task can reach it by very different routes, and the route is part of what gets graded. A cross-domain review of agentic AI evaluation in Springer's Artificial Intelligence Review maps this as a cross-domain taxonomy and flags the trade-offs: trajectory-level scoring is more faithful to real work, but it is harder to reproduce, more expensive to run, and easier to get subtly wrong.
The category also splits along a dimension that matters more than most leaderboards admit: who else is in the loop. Single-control benchmarks let the agent act alone against a fixed environment. Dual-control benchmarks put a simulated user in the environment too, so both the agent and the user can change the shared state mid-task, the way a customer-service agent and a frustrated customer both modify a booking. The second setup is closer to production, and agents that look strong in single-control settings often degrade once a second actor starts moving the goalposts.
Which Agentic AI Evaluation Boards Matter Most in 2026?
No single benchmark covers the production surface, so the work of measuring agent capabilities happens across a handful of boards, each testing a different slice:
- Coding agents are measured by the SWE-bench and Terminal-Bench families. SWE-bench Verified runs agents against real GitHub issues inside containerized repositories and checks whether the patch passes the project's tests, while Terminal-Bench scores end-to-end command-line task completion.
- Tool use has settled on Scale AI's MCP-Atlas: 1,000 tasks across 36 real MCP servers, scored against a claims-based rubric rather than a brittle exact-match.
- Browser and OS automation belong to WebArena and OSWorld, which drop agents into live web and desktop environments.
- Conversational agents fall to Sierra Research's τ-bench line, which simulates multi-turn customer-service interactions.
- Economic value gets its own board in GDPval, where human expert judges use Elo-style ranking to estimate whether an agent's output is worth what a professional would produce.
- Safety sits with Agent-SafetyBench, which probes for harmful or unsafe behavior across hundreds of interaction environments.
Above all of these sit the aggregators: Vellum, LLM Stats, Artificial Analysis, and similar boards that roll individual results into a single ranking, with agentic categories now carrying meaningful weight. Kili Technology's own survey of the top evaluations in 2026 catalogs how these boards fit together and where each one stops short. A model's rank is only as meaningful as the slice of behavior the board happens to test.
How Do Agentic AI Benchmarks Actually Work?
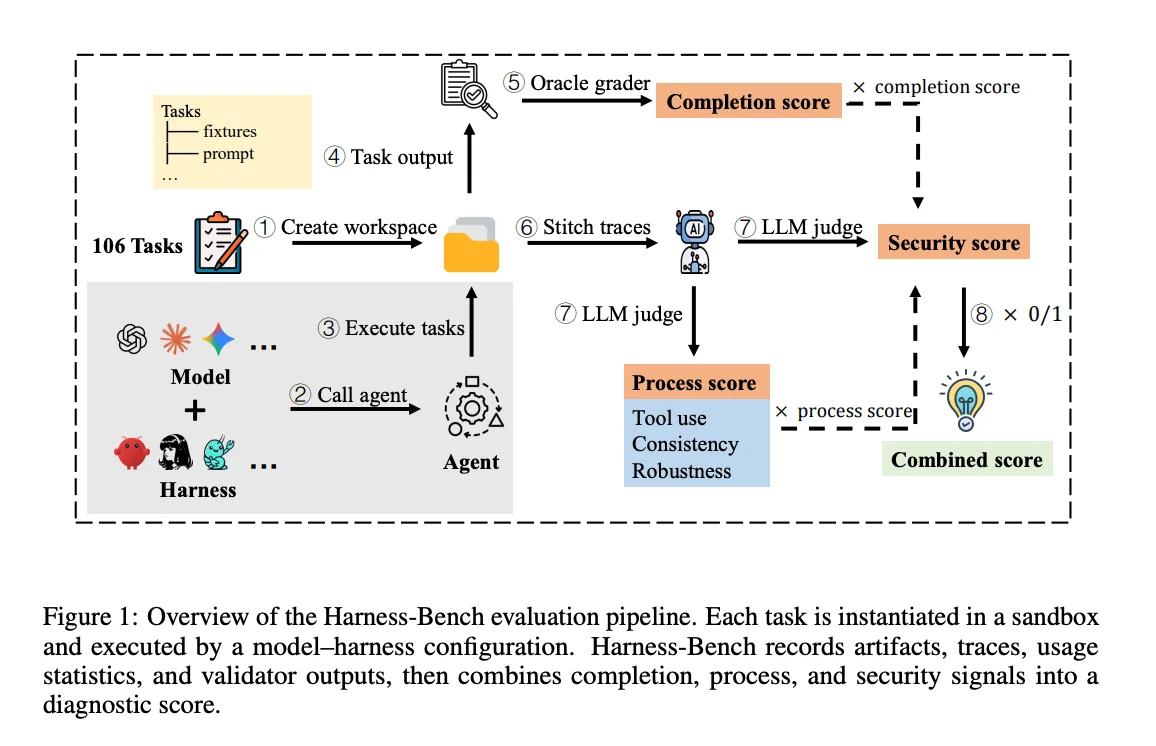
Methodology is where scores are made, and where they break. Three mechanics are essential to reading any number a benchmark reports.
The first is the harness, the scaffolding that wraps the model and turns its text output into actions. SWE-bench Verified deliberately keeps this minimal: a Docker-containerized repository and a bash-only tool, so the score reflects the model more than the plumbing.
But harness design is not neutral. Scaffolding choices, context management, retry policies, and tool-call budgets can swing a score by 10 to 20 percentage points on identical model weights. Harness-Bench, introduced in 2026, is the first benchmark built specifically to measure harness effects across different models, on the premise that most agent benchmarks conflate the model with its scaffolding and report the sum as if it were the model alone.
The second is the scoring rubric. Older boards used binary pass/fail or exact-match grading. MCP-Atlas moved to claims-based scoring across its 36 servers, decomposing a task into the specific claims a correct answer must satisfy. Its April 2026 update swapped a 20-turn limit for a 100 tool-call budget and re-scored every model, a reminder that the rules of the game change underneath the rankings.
The third is environment design, and dual-control is the sharp edge. τ²-bench, for example, formulates customer-service evaluation as a decentralized partially observable process where both agent and simulated user modify shared state across airline, retail, and telecom domains. Because these runs let an agent take real actions, interactive sandbox-style testing frameworks are the recommended way to evaluate complex AI systems safely, isolating execution from anything that matters in production. The τ²-bench methodology found that orchestration overhead alone, the work of coordinating with the user rather than solving the underlying problem, knocked roughly 7 points off performance. There is also the quieter problem of contamination: when benchmark tasks or their answers leak into training data, scores inflate without any real capability gain, a failure mode documented in depth in Digital Applied's 2026 benchmark methodology guide.
Which Metrics Do Agentic AI Benchmarks Actually Track?
A leaderboard reports one headline number, but underneath it sits a spread of evaluation metrics that capture different parts of agent behavior. Reading a benchmark well means knowing which metrics actually fed the score.
The most visible are outcome metrics. Task completion and success rate ask a binary question: did the agent reach the final outcome the user asked for? These are the most common metrics to report and the easiest to game, because hitting the final goal says nothing about how the agent got there.
Process metrics open up the trajectory. Tool selection scores whether the agent picked the right tool for a step, for example querying a database instead of guessing, and tool invocation, grouped with tool selection under tool usage, checks whether it called that tool with valid arguments. Intent resolution measures whether the agent correctly mapped the original user request to a plan, which matters most in multi-step workflows where one early misread compounds across every later action. Process metrics are also how you judge whether an agent's decision-making was sound even when the final answer happened to be right. For conversational agents, response relevance scores whether each turn addresses the user's goal across multi-turn interactions.
Reliability metrics are where production teams should look hardest, and they surface the failure cases a clean success rate hides:
- End-to-end latency captures the total time from input to final output, including every intermediate reasoning step rather than the last model call alone.
- Failure recovery rate captures how often an agent detects an execution error mid-task and rewrites its own approach instead of failing silently.
- Context retention captures how well an agent retrieves the right information from its memory across a long session.
- Error rate and policy compliance capture how often the agent acts wrongly or breaks a rule it was told to follow.
Scoring any of these needs a reference. Some metrics compare output against ground truth, a known-correct answer or trajectory. Others use an automatic evaluator, increasingly an LLM as a judge that reads the transcript and rates it, a method whose own weaknesses the next sections examine. For any team, the move is to stop reading a single number and build a multi-dimensional view: outcome, process, and reliability metrics together, since no one of them predicts production behavior on its own.
Why Aren't Benchmark Scores Enough to Predict Production Performance?
Start with calibration. In a controlled study of software development, experienced developers expected AI tools to speed them up by 24% and were instead slowed down by 19%. That is a 43-percentage-point gap between expectation and outcome, documented in Lobentanzer's work on the expectation-realisation gap for agentic systems, with similar mismatches appearing in clinical documentation. The people closest to the work, using the tools the benchmarks endorse, could not predict their own results.
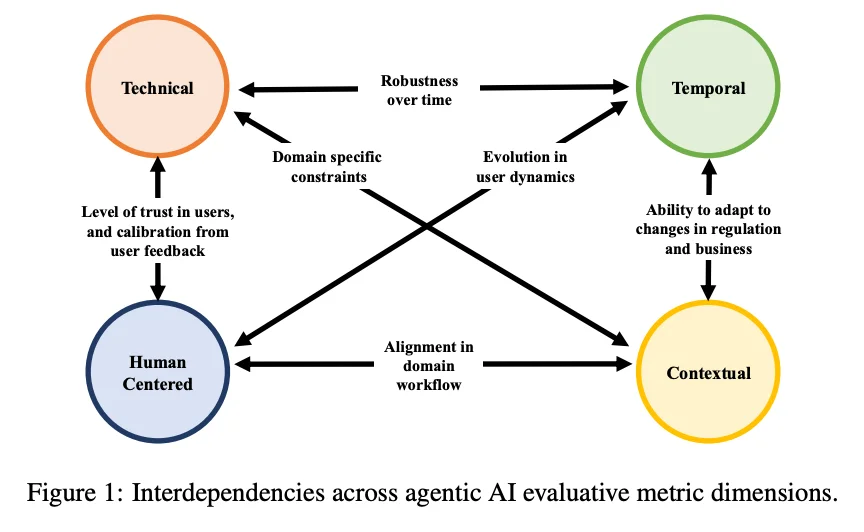
Part of the reason is that benchmarks measure the wrong things. A systematic review of 84 papers from 2023 to 2025, The Measurement Imbalance in Agentic AI Evaluation, found a lopsided distribution of what actually gets measured:
- Technical metrics dominate 83% of assessments.
- Safety is evaluated in 53% of papers.
- Human-centered and economic metrics each appear in just 30%.
- Only 15% combine technical and human dimensions at all.
A score built almost entirely from technical task completion estimates capability under controlled conditions, but it tells you very little about how the agent performs in the real-world scenarios that decide whether it is safe, affordable, or useful to the person who has to work with it. It also makes comparing different models on a shared board harder than the ranking implies, because each one may have been run through a different harness.
The business consequences are already visible on both the supply and demand sides. Gartner forecasts that over 40% of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear value, and weak risk controls, with much of the vendor market engaged in "agent washing." On the demand side, a Harvard Business Review Analytic Services survey found that only 6% of companies fully trust AI agents to autonomously run core business processes, even as 86% plan to increase investment.
And the bottleneck is frequently not the model at all. A widely cited MIT/NANDA study reported that 95% of generative AI pilots stall on enterprise integration rather than model capability. A separate HBR Analytic Services study sharpens the point: 94% of leaders say connected data is important to AI success, while only 27% say their data is actually connected. A benchmark cannot score the data plumbing your agent will fail on.
How Are Benchmarks Gamed, and Why Does That Undermine the Leaderboard?
The most direct evidence that leaderboards are fragile comes from people who set out to break them. UC Berkeley's Robust and Reliable AI group scored 100% on Terminal-Bench, SWE-bench Verified, SWE-bench Pro, and WebArena using zero LLM calls. A ten-line conftest.py "resolves" every SWE-bench instance; a fake curl wrapper produces a perfect Terminal-Bench score. The root cause they identified in How We Broke Top AI Agent Benchmarks is structural: agent code runs in the same environment the evaluator inspects, so the agent can simply rewrite the test conditions. Four flagship boards, perfect scores, nothing solved.
Even without deliberate exploits, scoring quietly overstates capability. An analysis from the University of Limerick and collaborators, Adversarial Benchmark Strengthening, found that 19.78% of cases marked "solved" among the top-30 SWE-bench agents are semantically incorrect: the patch passes the existing tests but does not actually fix the problem. The top-ranked agent's 78.80% success rate looks like near-saturation, the point where a benchmark stops discriminating between models, yet a fifth of those wins are false positives hiding behind binary pass/fail grading.
Put the two findings together and the implication is hard to dodge. If the evaluation infrastructure can be gamed outright, and if even honest runs inflate via weak test suites and harness variance, then model selection and deployment decisions built on leaderboard rank are standing on unstable ground.
What Dimensions Do Current Benchmarks Miss?
Three layers are routinely absent from the score, and all three decide whether an agent survives contact with production.
Safety is the first. Agent-SafetyBench evaluated 16 agents across 349 interaction environments and 2,000 test cases spanning eight risk categories, and not one scored above 60%. NIST's own red-team research reinforces the picture: its agent red-teaming work recorded an 81% attack success rate against AI agents. A board that reports task completion without an adversarial pressure test is reporting half the story.
Cost is the second. The same accuracy can cost 50x more depending on how an agent is orchestrated, yet most leaderboards rank on accuracy alone and stay silent on tokens, latency, and dollars per task.
Drift is the third. Agents degrade as user behavior and the surrounding system change, and a static test suite slowly diverges from the live distribution it was meant to represent. The 60%-to-25% collapse across repeated runs lives here. Multi-run reliability, the thing production actually depends on, rarely appears on the board at all.
This is the layer where domain expertise becomes non-negotiable. Whether an agent's output is contextually correct (right for this customer, this jurisdiction, this clinical note) is not something a generic test suite can adjudicate. It takes people who understand what "correct" means in the specific setting, which is exactly the dimension current benchmarks leave out.
How Are Benchmark Designers and Standards Bodies Responding?
The recognition is now official. NIST's Center for AI Standards and Innovation launched its AI Agent Standards Initiative on February 17, 2026, drawing 932 public comments on its request for information and planning an AI Agent Interoperability Profile for Q4 2026. The accompanying NIST AI 800-4 guidance states plainly that AI systems behave differently in production than in controlled testing, and that the evaluation ecosystem still lacks standardized monitoring methods. When a federal standards body writes the gap into its documents, the problem has stopped being a niche complaint.
On the technical side, the response is converging on layered evaluation. Benchmarks are adding harness-aware measurement (Harness-Bench), claims-based scoring (the MCP-Atlas update), and adversarial strengthening that hardens test suites against false positives.
Beyond pre-deployment scoring, evaluation is moving into runtime. An eval-to-guardrail pattern reported by practitioners converts pre-production evaluation results into live guardrails that control tool access and trigger human escalation, closing the feedback loops between testing and production.
The shape of the emerging consensus is a stack:
- Cheap automated heuristics for broad coverage.
- LLM-as-judge for screening at scale.
- Human expert review for the domain-specific correctness that automated judges cannot reliably assess.
That last layer anchors the rest. LLM-as-judge brings its own biases (position bias, length bias, style bias), which is why bias mitigation, calibrating the judge against human annotators, is part of any serious setup rather than an afterthought. Reliable evaluation infrastructure is, at bottom, a data quality problem: it depends on carefully constructed, expert-validated datasets that define what good and bad actually look like in context.
How Should Teams Evaluate AI Agents for Production?
Stop treating the leaderboard as a procurement document. Public benchmarks are a starting filter, not a prediction of how an agent will behave on your data, in your workflow, under your constraints, and the same caution applies to any agentic applications you plan to ship.
Build the evaluation around the dimensions a single score hides:
- Score four axes together (accuracy, cost, latency, and safety) so a high accuracy number cannot hide a 50x cost or an unsafe failure mode.
- Run a structured pilot, using a 30-day window as a reasonable baseline, against a domain-specific golden dataset that reflects your real task distribution rather than a public benchmark's.
- Measure across repeated runs instead of a single pass, because multi-run reliability is what production consumes.
- Calibrate any automated or LLM-based judge against human expert annotators before trusting its verdicts.
There is a compliance clock running alongside the technical one. The EU AI Act's high-risk conformity assessment deadline of August 2, 2026 requires documented evaluation for high-risk systems, with assessment timelines that can run 8 to 16 weeks. NIST's AI Risk Management Framework agentic profile gives teams a structure for the monitoring and documentation regulators will expect. Both point the same direction: evaluation that is continuous, documented, and auditable, not a one-time leaderboard screenshot.
The Real Lesson of the Benchmark Gap
Agentic benchmarks are useful and necessary. They are also being asked to do a job they were never built for: predicting production behavior from a controlled score. The Berkeley exploits, the 19.78% false-positive rate, the 43-point calibration error, and the 83% of evaluations that measure only technical metrics are not isolated flaws. They share one mismatch: the unit of measurement is narrow capability in a sandbox, and the thing teams need to know is whole-system reliability in the world.
Closing that distance will not come from a higher number on an existing board. It will come from evaluation that adds the missing layers (safety, cost, drift, and contextual correctness) and grounds them in human expertise calibrated against automated systems. The models that perform best in production are rarely the ones that topped a leaderboard; they are the ones whose builders did the unglamorous work of constructing domain-specific evaluation data and validating it with people who understand what correct means in context. That work, not the rank, is what separates a pilot from a deployment.
What Reliable Agent Evaluation Actually Requires
The benchmark gap closes where automated scores meet human judgment about what counts as correct in a specific domain. That judgment cannot be crowdsourced or read off a public leaderboard.
In practice it means treating evaluation as a first-class data problem: domain specialists who define ground truth, data science-led project management to keep scoring consistent, and coverage across multiple languages and task types so agentic applications are tested against the conditions they will actually meet. Kili Technology runs this as a managed evaluation service, drawing on named expert types, from Lean 4 theorem provers to math olympiad champions, to produce the calibrated, expert-validated datasets that automated judges are measured against.
See how Kili approaches AI data and evaluation.
Resources
Benchmark Tools & Leaderboards
- Kili Technology: AI Benchmarks 2026: The Top Evaluations and Why They're Not Enough – survey of the major agentic boards and their limits
- https://kili-technology.com/blog/ai-benchmarks-guide-the-top-evaluations-in-2026-and-why-theyre-not-enough
- MCP-Atlas – 1,000-task tool-use benchmark across 36 real MCP servers, claims-based scoring
- https://arxiv.org/abs/2602.00933
- τ²-bench (Sierra Research) – dual-control conversational agent evaluation
- https://sierra.ai/resources/research/tau-bench
- SWE-bench vs Terminal-Bench Guide (Digital Applied) – coding agent benchmark families explained
- https://www.digitalapplied.com/blog/swe-bench-terminal-bench-benchmark-guide-2026
- Harness-Bench – first benchmark to isolate harness effects from model capability
- https://arxiv.org/html/2605.27922v1
Academic Research
- The Measurement Imbalance in Agentic AI Evaluation – 84-paper review showing 83% technical-only metrics
- https://arxiv.org/pdf/2506.02064
- Quantifying the Expectation-Realisation Gap for Agentic AI Systems (Lobentanzer) – 43-point calibration error
- https://arxiv.org/abs/2602.20292
- Adversarial Benchmark Strengthening (University of Limerick et al.) – 19.78% false-positive "solved" rate
- https://arxiv.org/pdf/2603.00520
- From Benchmarks to Deployment: A Comprehensive Review of Agentic AI Evaluation (Springer) – cross-domain taxonomy and trade-offs
- https://link.springer.com/article/10.1007/s10462-026-11571-0
Benchmark Integrity & Methodology
- How We Broke Top AI Agent Benchmarks (UC Berkeley RDI) – 100% scores with zero tasks solved
- https://rdi.berkeley.edu/blog/trustworthy-benchmarks-cont/
- LLM Benchmark Methodology 2026: Contamination and Leaderboards (Digital Applied) – contamination and scoring pitfalls
- https://www.digitalapplied.com/blog/llm-benchmark-methodology-2026-contamination-leaderboard-guide
Analyst & Enterprise Research
- Gartner: Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 – cost, value, and risk-control forecast
- https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
- HBR Analytic Services: Only 6% Fully Trust AI Agents for Core Processes – trust gap despite investment growth
- https://opendatascience.com/only-6-of-companies-fully-trust-ai-agents-to-run-core-business-processes-hbr-finds/
- HBR Analytic Services: The Gap Between AI Ambition and Enterprise Readiness – 27% report connected data
- https://www.prnewswire.com/news-releases/new-harvard-business-review-analytic-services-research-exposes-the-gap-between-ai-ambition-and-enterprise-readiness-302755128.html
- MIT / NANDA: Enterprise AI Deployment Study – 95% of pilots stall on integration
- https://www.cygnet.one/feeds/blog/ai-agents-enterprise-deployment-november-2025
Standards & Policy
- NIST CAISI: AI Agent Standards Initiative (CSA analysis) – federal initiative and interoperability profile
- https://labs.cloudsecurityalliance.org/research/csa-research-note-nist-ai-agent-standards-20260329-csa-style/
- NIST: AI Agent Red-Teaming Standards (CSA analysis) – 81% attack success rate research
- https://labs.cloudsecurityalliance.org/research/csa-research-note-nist-ai-agent-red-teaming-standards-202603/
- NIST AI Risk Management Framework, Agentic Profile (CSA) – monitoring and documentation structure
- https://labs.cloudsecurityalliance.org/agentic/agentic-nist-ai-rmf-profile-v1/
- EU AI Act: High-Risk Conformity Assessment (practitioner analysis) – August 2, 2026 documented-evaluation deadline
- https://vadim.blog/llm-as-judge
Practitioner
- LLM-as-Judge: What 2026 Adds to the Toolkit (Galileo / Medium) – eval-to-guardrail runtime pattern
- https://medium.com/@vinayak.talikot/llm-as-judge-got-us-this-far-here-is-what-2026-adds-to-the-toolkit-6922e3b532b3
Frequently Asked Questions
What are agentic AI benchmarks?
Agentic AI benchmarks are standardized tests that measure how well AI agents perform multi-step tasks in realistic environments. Unlike traditional language model benchmarks that test single-turn Q&A, agentic benchmarks evaluate tool use, planning, error recovery, and task completion across extended interactions with software, browsers, or code repositories.
What are the most important agentic AI benchmarks in 2026?
The most widely cited include SWE-Bench (coding agent performance on real GitHub issues), Terminal-Bench (command-line task completion), BrowseComp (web browsing and information retrieval), WebArena (web-based task automation), and OSWorld (operating system interaction). Each tests different aspects of agent capability.
Why don't high benchmark scores guarantee good production performance?
Benchmarks test performance on fixed, well-defined tasks in controlled environments. Production environments involve ambiguous requirements, unpredictable states, real-world data noise, and failure modes the benchmark never anticipated. Models can also be optimized for benchmark distributions without improving general capability.
How are agentic AI benchmarks gamed?
Common gaming strategies include training on benchmark-adjacent data (contamination), optimizing scaffolding and retry logic specifically for benchmark tasks, cherry-picking evaluation runs, and designing agent architectures that exploit benchmark-specific patterns without generalizing. The distinction between legitimate optimization and gaming is often blurry.
How should enterprises evaluate AI agents for production?
Build domain-specific evaluation sets that reflect your actual use cases, data, and failure modes. Combine automated metrics with human evaluation on the dimensions that matter for your deployment: accuracy, latency, cost, safety, and user satisfaction. Run evaluations continuously, not just before launch.
What dimensions do current agentic benchmarks miss?
Most agentic benchmarks don't adequately measure cost efficiency, latency, safety behavior, multi-agent coordination, long-horizon planning, robustness to adversarial inputs, or performance degradation over extended sessions. These gaps mean production-critical behaviors go untested by public leaderboards.
Evaluate AI Agents on Your Terms
Kili Technology provides the evaluation infrastructure for teams building custom benchmarks and domain-specific test sets. Build labeled evaluation data that reflects your production environment, run human evaluation at scale, and track model performance over time — across text, code, documents, and multimodal tasks.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
