
.png)

_logo%201.svg)


AI Summary
Over the last year, the Artificial Intelligence (AI) industry has undergone significant changes due to the widespread adoption of advanced Large Language Models (LLMs), such as GPT-3, BERT, and LlaMA. Large language models can generate output indistinguishable from what a human would create and engage with users’ queries in a contextualized setting. Out-of-the-box they can perform some of the tasks previously reserved only for humans, like creative content generation, summarization, translation, code generation, and more.
Due to their versatility, many business domains are currently adopting LLMs as a critical strategic component to streamline workflows and improve productivity. For instance, in e-commerce, companies use LLMs to build virtual assistants that help visitors search for items they want; in healthcare, LLMs help generate and interpret medical reports; and in marketing, LLMs help generate relevant ad content such as ad copy and creatives.
Though standard LLMs can perform well on generalized tasks, real-world applications require much more robust and domain-specific models. Therefore, practitioners must fine-tune them on domain-specific data to make them suitable for downstream real-world tasks. This post discusses the concept of fine-tuning LLMs, its benefits and challenges, approaches, and the steps involved in the fine-tuning process.
Build high-quality LLM fine-tuning datasets
The best LLM for your team is one fine-tuned with your data. Our platform empowers start-ups and enterprises to craft the highest-quality fine-tuning data to feed their LLMs. See for yourself.
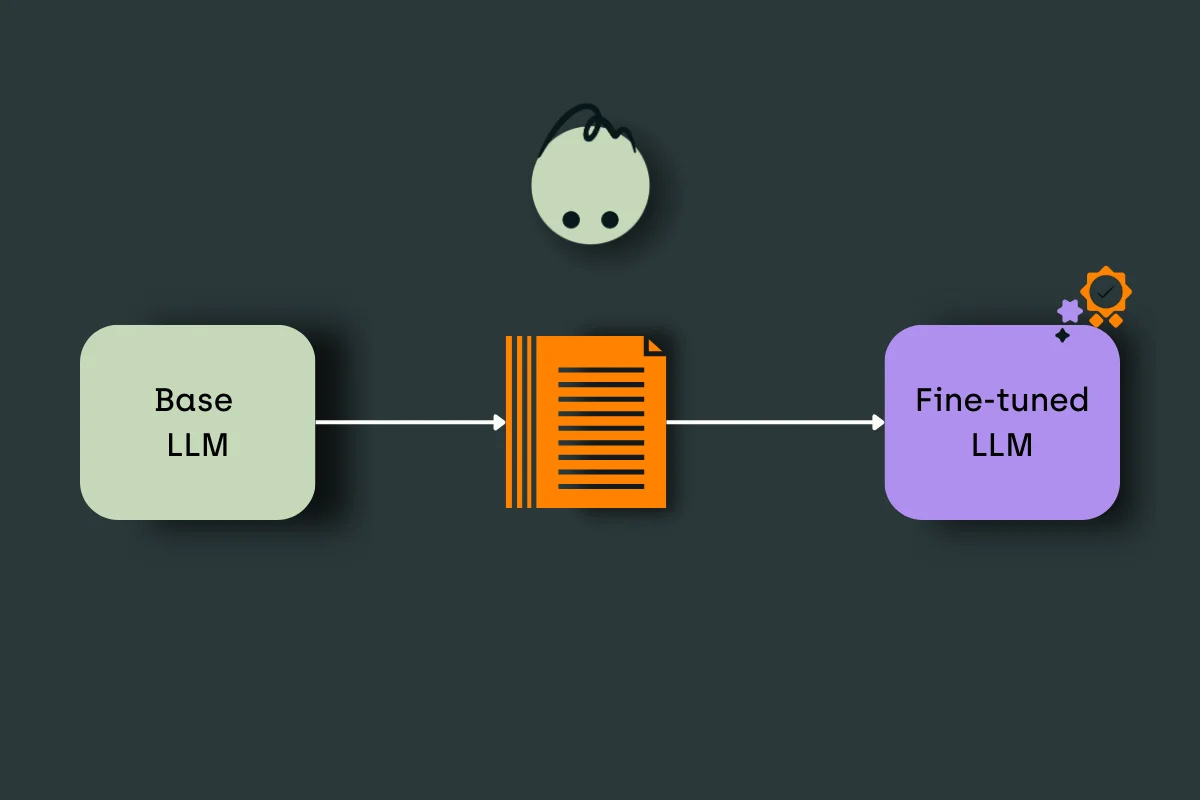
What is LLM Fine-Tuning?
A Large Language Model, like GPT-3 or BERT, is a general-purpose tool trained on an extensive text corpus consisting of various text sequences from diverse sources. Using it directly to perform a specific job, such as generating a summary of a medical document, can lead to sub-optimal outputs.
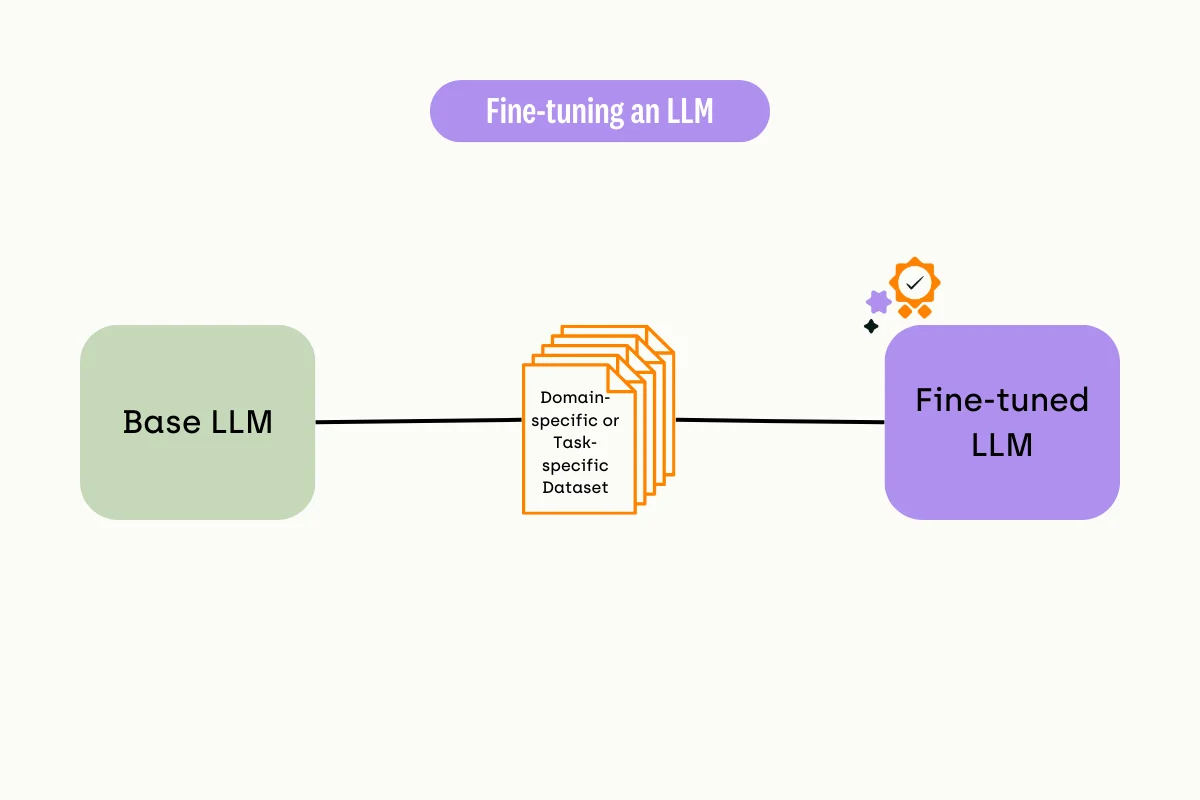
LLM fine-tuning is essentially adapting a pre-trained LLM to suit a particular task or application by further training it on a domain-specific dataset. This adjusts the LLM's parameters to suit the new domain-specific data and improves the model performance for a better user experience.
Common misconceptions of LLM fine-tuning
While the concept of LLM fine-tuning is straightforward, a few misconceptions make fine-tuning challenging to understand. Let’s go over them one by one.
Fine-tuning vs. Retrieval-augmented Generation (RAG)
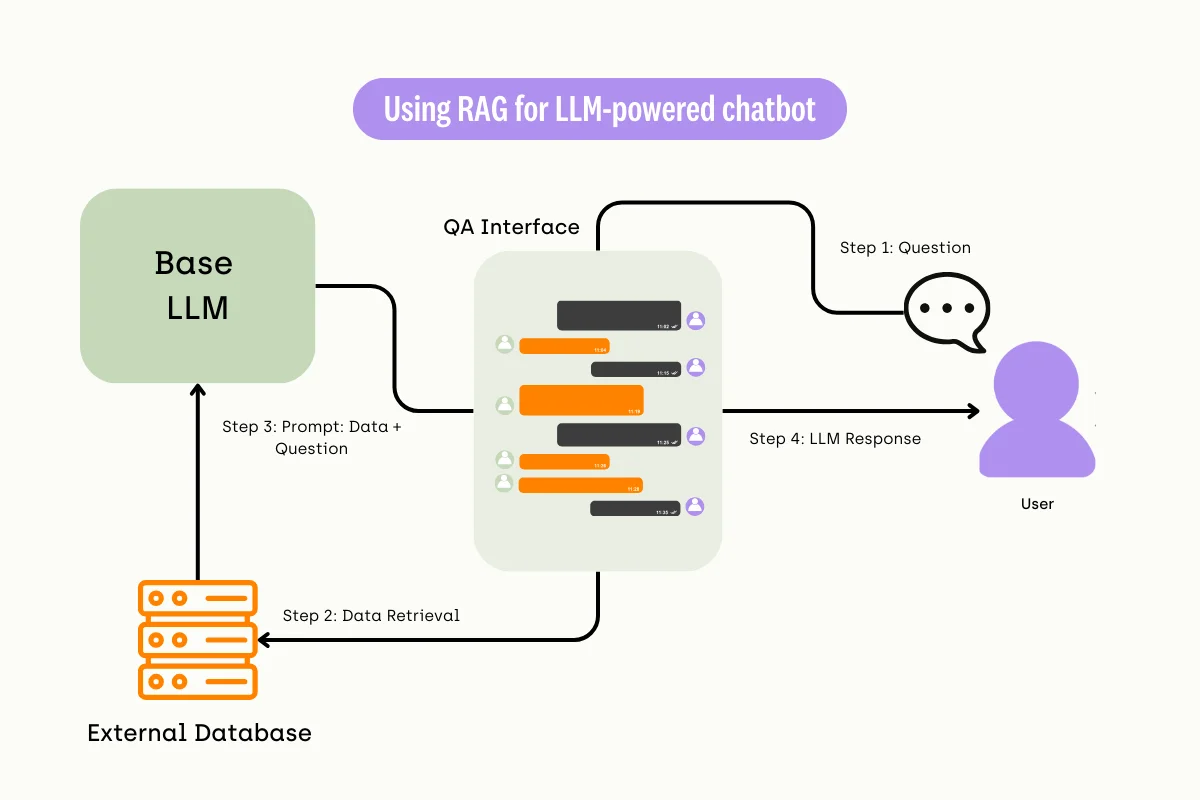
Confusing RAG with fine-tuning is a common mistake, as the two processes seem similar. In a nutshell, the RAG process consists of three key parts:
- Retrieval: Based on the user query (prompt), retrieve relevant knowledge from a knowledge base.
- Augmentation: Combine the retrieved information with the initial prompt.
- Generate: pass the augmented prompt to a large language model, generating the final output.
The process does not change the underlying model, though. Only the user input is impacted.
Fine-tuning vs. Few-shot learning
Another point of confusion relates to the differences between fine-tuning and few-shot learning. Few-shot learning is a learning paradigm that enables models to adapt to new tasks or data with minimal additional examples. For instance, a model trained to classify various objects might be adapted to recognize specific types of plants or animals using just a few images of each new category. This is distinct from fine-tuning, where the pre-trained language model is retrained on a new, often larger dataset to specialize in a particular task.
Fine-tuning vs. continual learning
Continual learning is a form of multi-task learning where a model learns new information sequentially to perform new tasks without forgetting previous concepts. Fine-tuning is part of continual learning, as the latter requires models to adapt to a particular task incrementally. The result of continual learning is a model that works well in multiple domains instead of a single one.
Data requirements for fine-tuning
A common misconception is that fine-tuning large language models requires large training data. In reality, the extensive pre-training that these models went through when they were being built, based on datasets that consisted of diverse and large knowledge corpora, means they have already acquired a vast foundation of knowledge. When they’re being fine-tuned for specific tasks, this pre-existing knowledge enables them to adapt effectively to much smaller, targeted datasets. Therefore, proper data curation and quality, rather than volume alone, are often the keys to fine-tuning for a better-performing LLM.
.webp)
For instance, in their Less is More for Alignment (LIMA) paper, Meta’s researchers describe fine-tuning a pre-trained LLM using only 1,000 text sequences consisting of questions and answers from community forums, such as Stack Exchange and wikiHow, plus a few other prompts generated manually. The fine-tuned model performed better than state-of-the-art models like OpenAI's DaVinci 003 and Alpaca, which was fine-tuned using 52,000 examples.
What are the benefits of fine-tuning an LLM?
Fine-tuning language models offer many advantages, allowing experts to streamline the development of the machine-learning model. Below are just some of the benefits of tuning large language models:
Task-specific adaptation
As discussed, a large language model has exceptional natural language understanding thanks to extensive training datasets from various sources. Users can exploit this knowledge by fine-tuning the model for a specific downstream task, such as text classification, sentiment analysis, machine translation, question-answering, etc., for specific domains like finance, healthcare, and cybersecurity.
Domain-specific expertise
Fine-tuning large language models lets users tailor a foundation model to a particular domain for improved performance. For instance, healthcare professionals can leverage a fine-tuned model for medical diagnosis, to recognize diseases accurately based on symptoms.
Reducing bias and improving safety
By carefully selecting the fine-tuning dataset, biases in the pre-trained model can be reduced, leading to fairer and more equitable outcomes. Fine-tuning can also address issues related to the generation of inappropriate or harmful content by training the model on safer, more controlled datasets.
User experience enhancement
AI practitioners can integrate fine-tuned models with several applications to boost user experience. For instance, retailers can fine-tune an LLM to build a chatbot that provides relevant recommendations to visitors to help them with purchasing decisions, based on their requirements.
Computational efficiency vs. training from scratch
Fine-tuning an LLM doesn’t require as much computational power than training the model from scratch. Since LLMs already have extensive knowledge, users can quickly adapt them to suit their requirements, leading to a more efficient training process and a faster time to market.
LLM fine-tuning approaches
Developers can use several fine-tuning techniques for efficient LLM adaptation. Standard methods include supervised fine-tuning, reinforcement learning, and self-supervised fine-tuning. Let's talk about each one of them in more detail.
Supervised fine-tuning
In supervised fine-tuning, developers can adapt a pre-trained model using labeled data. This technique involves adjusting a model's parameters by updating gradients based on ground-truth labels, which helps the model learn patterns in the underlying data distribution. Practitioners use the following approaches to supervised learning:
Transfer Learning
Transfer learning is a machine learning method where a model developed for one task is later reused as the starting point for another task.
This technique mainly involves freezing the first few layers of a deep-learning model that contain information regarding low-level features and then updating model parameters in the subsequent layers using the new dataset.
Task-specific fine-tuning
Task-specific fine-tuning occurs when AI practitioners use a labeled dataset to train a model for different tasks. In NLP, this means language tasks such as question-answering, entity recognition, parts-of-speech tagging, etc. Task-specific fine-tuning aims to optimize a model for a single job, for exceptional performance.
Domain-specific fine-tuning
Using domain-specific fine-tuning, AI practitioners can train an LLM for a particular industrial task. For example, healthcare professionals can fine-tune an LLM to summarize the main points from the medical literature related to a specific disease.
The procedure involves using domain-specific data, such as medical research papers and reports, to help the model learn context-level information and understand the relevant terms for optimal performance.
Instruction fine-tuning
Instruction fine-tuning takes the concept of fine-tuning a step further by incorporating specific prompts or directives into the training process. This method guides the language model's behavior more directly, offering developers enhanced control over how the model responds to certain types of input.
While instruction fine-tuning might seem similar to RAG in that both techniques aim to refine the model's responses, there are key differences. Instruction fine-tuning embeds specific behaviors within the model, while RAG retrieves external information to enhance responses. Instruction fine-tuning ensures consistent, controlled outcomes based on provided guidelines, beneficial where adherence to styles or consistency matters. Combining both can be powerful for advanced tasks, leveraging RAG's external information and fine-tuning's adherence to guidelines. In sectors like finance, law, or healthcare, this combination ensures accurate, industry-specific responses.
Reinforced Learning from Human Feedback (RLHF)
RLHF is an evolving fine-tuning technique that uses human feedback to ensure that a model produces the desired output. The process includes domain experts who monitor a model's output and provide feedback to help the model learn their preferences and generate a more suitable response.
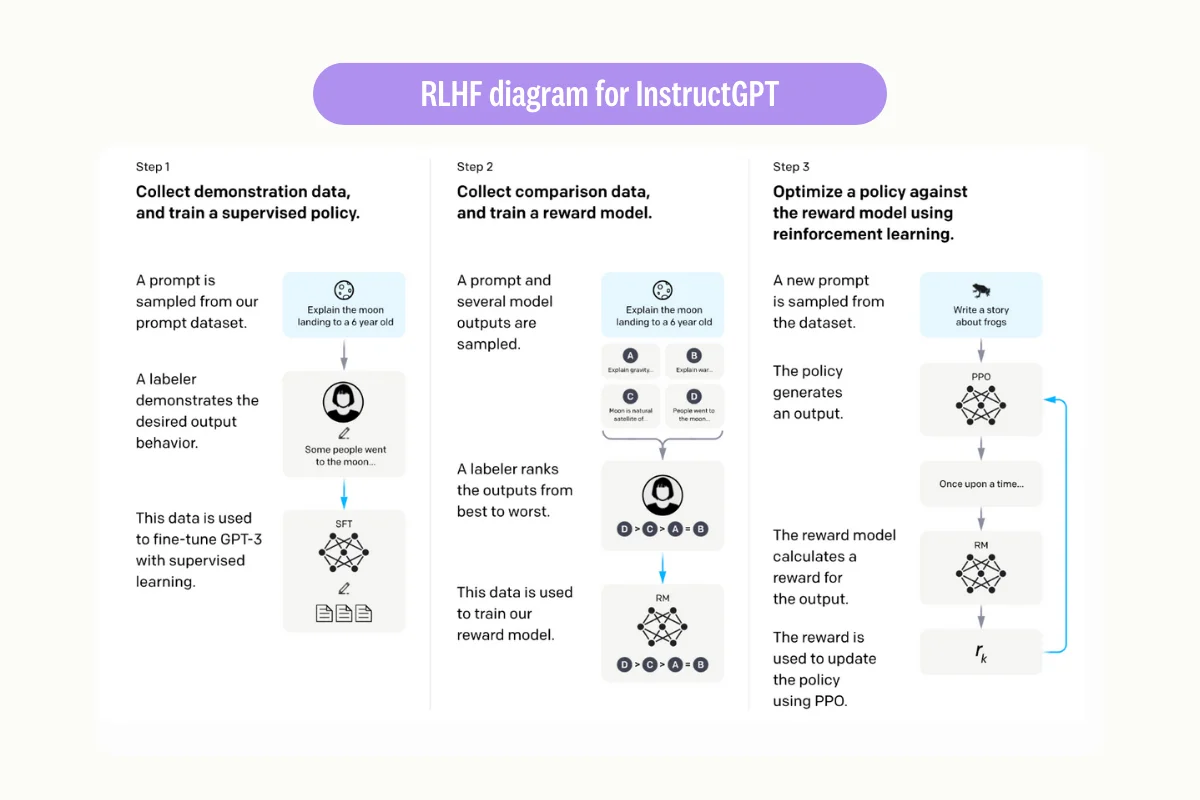
In particular, the process augments the supervised fine-tuning procedure by training a reward model that automatically optimizes the primary model's performance. The training data for the reward model can contain human preferences, allowing it to understand the most preferred output, based on subjective rankings.
Once trained, the reward model can assess the primary LLM's output and generate feedback using a reward score. The feedback will allow the LLM to produce a suitable response by leveraging the reward score.
Self-supervised fine-tuning
While supervised fine-tuning and RLHF require labeled data, self-supervised methods require only part of an input sequence to predict the remainder and use it as ground truth to train a model. The practice helps overcome the challenge of limited or no labeled data within specific domains.
The following explains three primary self-supervised fine-tuning techniques: Masked Language modeling, contrastive learning, and in-context learning.
Masked Language Modeling (MLM)
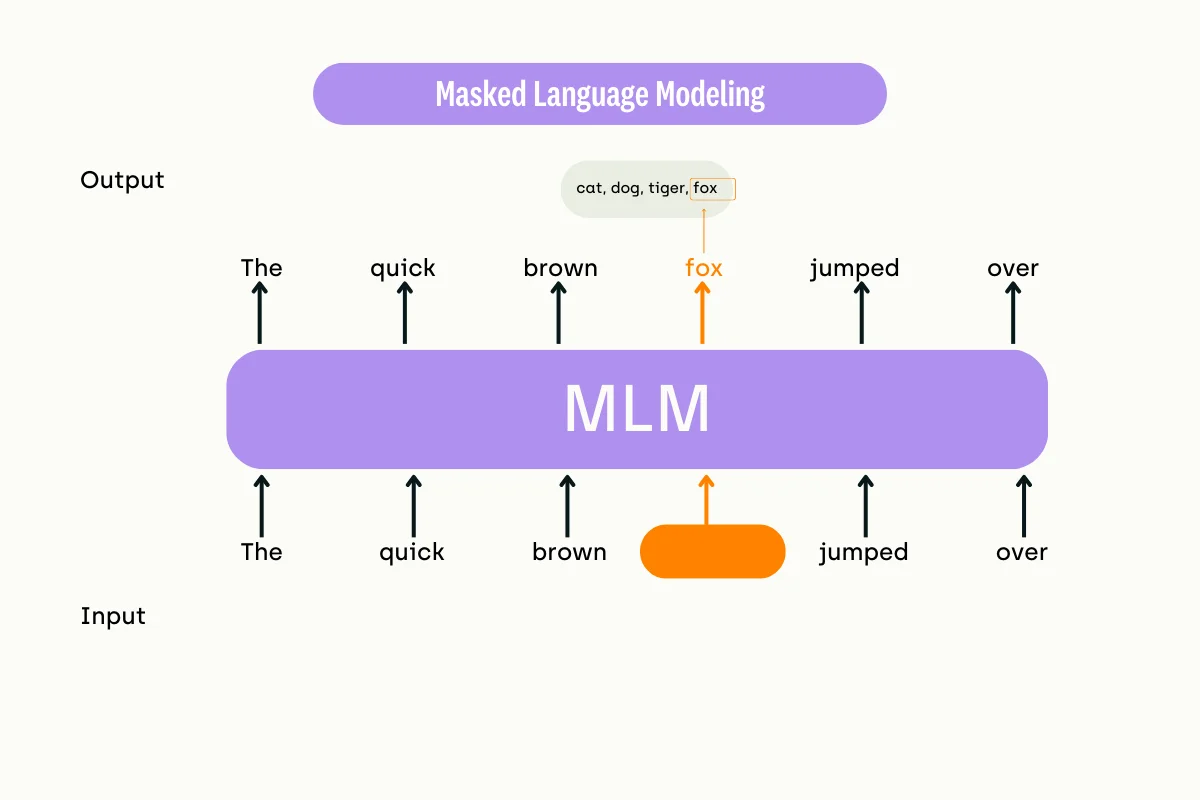
MLM involves masking or hiding a portion of an input text sequence and letting the model predict the appropriate missing tokens. Popular models that use the MLM technique include BERT, RoBERTa, and ALBERT.
The models use the transformer architecture, to understand the tokens appearing within a masked input sequence. For instance, an MLM can predict the hidden bit in "the quick brown...jumped over the lazy...".
Contrastive learning
Contrastive learning is a method in machine learning where the model learns to understand a dataset without needing labels. It does this by figuring out which pieces of data are similar or different from each other. For example, think about how you can tell cats and dogs apart: cats have pointy ears and flat faces. In contrast, dogs might have droopy ears and a more pronounced nose.
Contrastive learning lets a machine learning model do something similar: it compares different data points to learn important characteristics about the data, even before it's given a specific task like sorting or categorizing.
In-context learning
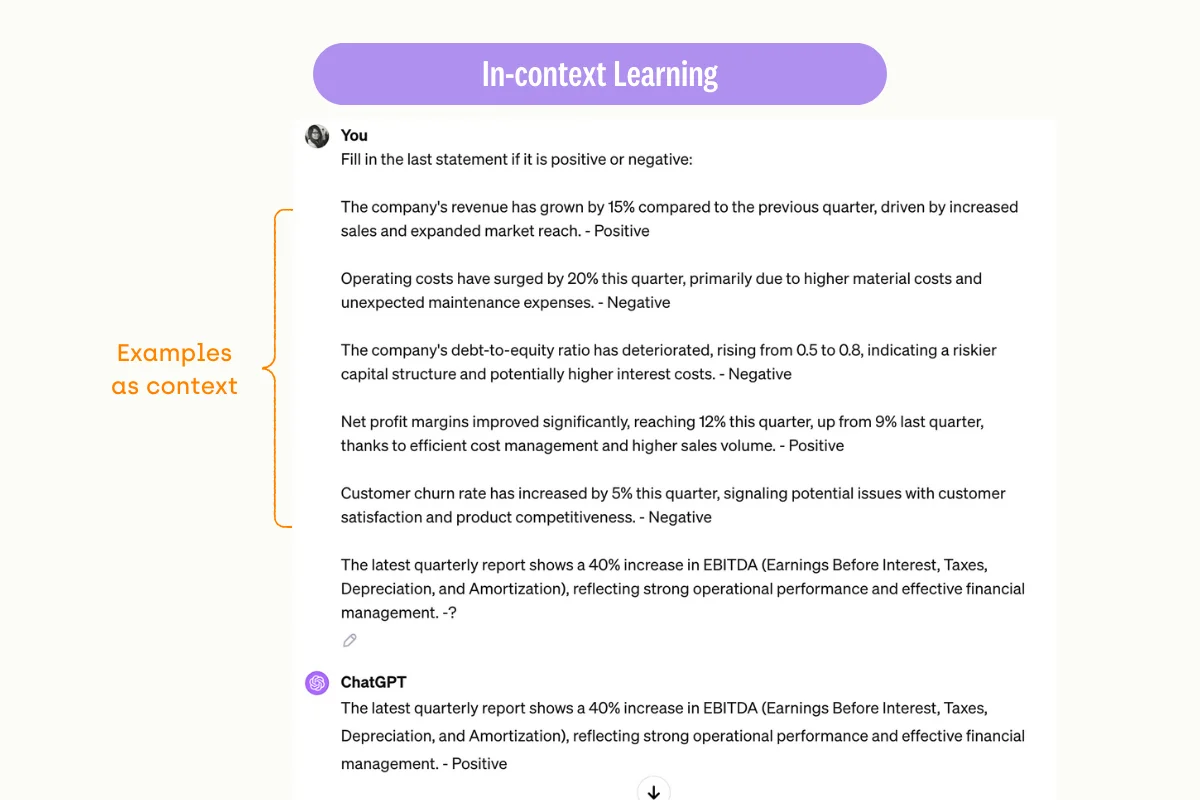
With in-context learning, an LLM learns to predict responses using context-level information provided through specific prompts or additional textual descriptions.
For example, when provided with a prompt and a few examples of classifications, the LLM uses these examples to guide its response to a new classification task.
Parameter-efficient fine-tuning techniques
PEFT, or Parameter-Efficient Fine-Tuning, refers to techniques that fine-tune large pre-trained language models (LLMs) on specific tasks while updating only a small subset of the model's parameters. This contrasts with full fine-tuning, in which all model parameters are updated.
PEFT offers several significant benefits when fine-tuning large language models (LLMs), making it an increasingly popular approach as models become more complex. Here’s a simplified look at the advantages:
1. Resource Efficiency
- Reduced Computational Needs: PEFT focuses on updating only a small fraction of the model's parameters, drastically reducing the computational power and time required for training.
- Cost Savings: Lower computational requirements translate into reduced costs for using cloud computing resources or specialized hardware.
2. Model Versatility
- Rapid Adaptation: Because it modifies fewer parameters, PEFT allows a pre-trained model to adapt quicker to new tasks or datasets.
- Broad Application: This efficiency enables the use of state-of-the-art models for a more comprehensive range of applications, even those with limited computational resources.
3. Maintaining Model Integrity
- Preserving Pre-trained Knowledge: By keeping the majority of the model's parameters unchanged, PEFT helps to retain the broad knowledge base the model acquired during its initial pre-training, avoiding "catastrophic forgetting."
- Stability: Limiting the number of altered parameters reduces the risk of overfitting to the fine-tuning dataset, leading to more stable and generalizable model performance.
4. Scalability
- Easier Management: Managing model updates and deployments becomes easier since only a small part of the model is being fine-tuned.
- Scalable to Larger Models: As models grow, fully retraining or fine-tuning becomes increasingly impractical. PEFT makes it feasible to leverage larger models for specific tasks.
Challenges of fine-tuning LLMs
While the fine-tuning process itself can be straightforward, meeting the requirements to develop an effective fine-tuned model is challenging. Below are the most common challenges that practitioners face when fine-tuning LLMs.
Data quality
Fine-tuning is as effective as the quality of training data, especially in supervised fine-tuning processes where data labeling quality plays a vital role. Ensuring data quality implies checking the data for inconsistencies, missing values, bias, outliers, formatting issues, etc.
In addition, due to data scarcity in specific domains, maintaining data representativeness becomes challenging, since only a few samples are available for training. As such, robust data curation becomes necessary to streamline the data collection and transformation process for effective fine-tuning.
To tackle these problems, consider using an automated tool like the Kili app. Kili helps project admins orchestrate data workflows that facilitate creating error-free datasets, with automated error-spotting and correction, constant monitoring of dataset quality through the use pre-defined metrics, and many more. To learn more about Kili’s quality features, check out our documentation.
Computational resources
While not as resource-hungry as training a model from scratch, fine-tuning can still be time-consuming and costly for smaller AI teams that do not have the required infrastructure. For example, fine-tuning an LLM like GPT-3 and BERT to the point when you get a decently performing model may require updates to thousands of model’s parameters.
What’s more, fine-tuning techniques that require properly labeled data often require hiring domain-level experts to assess annotation performance and guide the process. The additional cost of hiring such experts may put extra strain on a company's restricted budget and make fine-tuning a risky feat.
Catastrophic forgetting
Catastrophic forgetting mainly occurs in continual learning environments where a model gradually forgets previous knowledge when learning data patterns for a new task. Essentially, model's weights change significantly during the learning process, causing it to perform poorly on older tasks.
Techniques to mitigate catastrophic forgetting include elastic weight consolidation (EWC), which prevents weights that are important for specific tasks from changing significantly; Progressive Neural Networks (ProgNet), which adds a network for each new task; and Optimized Fixed Expansion Layers (OFELs) which adds a new layer for each task.
Evaluation metrics
Evaluating an LLM for domain-specific needs can be challenging: currently, no standardized evaluation frameworks exist. What’s more, in assessing the abilities of LLMs, one sometimes needs to take into account additional industry-specific factors. For example, in critical industries such as healthcare, an LLM-powered application must be trusted not to recommend incorrect diagnoses or treatment. This adds an extra layer of complexity to the evaluation process.
A platform like Kili helps AI practitioners by providing a consolidated approach to evaluation. We recently held a webinar going through the challenges of LLM evaluation, and Kili’s platform solves some of these challenges by combining human evaluation and model automation.

Watch video
Step-by-step process of fine-tuning an LLM for domain-specific needs
You can mitigate all the above-mentioned challenges by following a standard fine-tuning process and ensure efficient model development for domain-specific needs and downstream tasks.
The steps below demonstrate a practical framework for fine-tuning a Large Language Model to build a chatbot application.
1. Define the Application's Goals and Requirements
- Objective Clarity: Clearly define what you want your application to achieve and understand the types of tasks it will perform, such as text generation, classification, or question answering.
- User Needs: Consider the end-users of your application. What are their expectations, and how will the application improve their experience or solve their problems?
2. Select the Right LLM
- Model Size: Choose an LLM whose size and capabilities align with your application's needs. Larger models might offer better performance but require more resources.
- Access: Based on your resource availability and privacy requirements, decide whether to use a cloud-based API for LLMs (like OpenAI's GPT) or host the model on your own infrastructure.
3. Gather and Prepare Your Data
- Dataset Collection: Collect a dataset representative of your application's tasks. This data should cover the diversity of inputs and outputs you expect in real-world usage.
- Data Quality: Remember that the higher your data quality is, the better your fine-tuned model can perform.
4. Fine-Tuning the LLM
- Parameter Efficient Techniques: Consider using parameter-efficient fine-tuning methods if you're limited by computational resources or working with very large models.
- Monitoring and Evaluation: Regularly monitor the training process and evaluate the model using your validation set to adjust hyperparameters and prevent overfitting.
5. Integration and Deployment
- Integration: Integrate the fine-tuned model into your application, ensuring that it can handle real-world input and output formats smoothly.
- Scalability: Plan for scalability, considering how the model will handle varying loads and the potential need for horizontal scaling (adding more servers) or vertical scaling (upgrading server capabilities).
- Security and Privacy: Implement security measures to protect user data and comply with relevant privacy regulations.
6. Testing and User Feedback
- Beta Testing: Conduct thorough testing with a controlled group of users to gather feedback on the application's performance and user experience.
- Iterative Improvement: Use feedback and performance data to iteratively improve the model and application, fine-tuning further if necessary.
Leverage an all-in-one fine-tuning platform
Fine-tuning LLMs offers significant benefits by adapting general pre-trained models to specific tasks. Fine-tuning techniques help developers leverage LLMs' vast knowledge to build models that can improve productivity in multiple business domains.
However, the process relies heavily on data quality to ensure that fine-tuning produces the desired results. And since maintaining quality is challenging, platforms like Kili offer various features to build high-quality datasets through robust QA and collaboration workflows. Kili offers a range of tools that can assist in the fine-tuning of GPT-type models, providing support throughout the process. For successful LLM fine-tuning, it enables practitioners to establish custom evaluation criteria, set up high-quality data labeling workflows, identify significant feedback, integrate with leading LLMs, and access qualified data labelers.
Book your demo today to see Kili in action!

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
