
.png)

_logo%201.svg)


AI Summary
What are foundation models, and how do they work?
Foundation models are AI neural networks extensively trained on vast amounts of data. While some of these models, such as GPT-3, are trained on large-scale unlabeled datasets using unsupervised learning, others, like BERT, also employ supervised learning methods, leveraging labeled datasets for training. These large-scale models have the capability to perform a wide range of tasks, from text translation to medical image analysis. By leveraging these complex algorithms, foundation models have been able to facilitate applications in various tasks, such as facial recognition and natural language processing.
As we know, foundation models have had an immense impact on the progress of artificial intelligence. Each powerful foundation model launched advances new discoveries and technologies faster. And applying them correctly, companies can quickly develop meaningful AI applications, boosting business productivity and innovation.
What's interesting about these new systems is that foundation models act as large pre-trained models that can be used for many other AI applications. Simply put, they can use what they've learned from one situation to figure out another, thanks to self-supervised learning and transfer learning. For a basic example, learning a second language within the same family will be much easier when you've learned a new language for the first time. The only difference is these foundation models need much more data than an average person would need to switch between contexts.
How foundation models have contributed to artificial intelligence
Foundation models have significantly contributed to the advancement of various areas within artificial intelligence. Their ability to learn from vast amounts of data and generalize this learning to a wide range of tasks has made them a cornerstone of modern AI. Here are some specific areas where foundation models have made notable progress:
Generative AI: Foundation models have been instrumental in the development of generative AI, which involves creating new content, such as text, images, or music. For instance, DALL-E, a model by OpenAI built upon the GPT-3 architecture, can generate images from textual descriptions, opening up new possibilities in fields like graphic design and advertising.
Generative Models: In the broader field of generative models, foundation models like variational autoencoders have demonstrated great prowess. An example of this is OpenAI's DVAE, which uses a foundation model (a variational autoencoder) to learn to generate high-quality images.
Computer Vision: Foundation models have also made significant strides in computer vision, the field of AI that enables computers to understand and interpret visual information. Vision Transformer (ViT) is an example of how the transformer architecture, which underpins foundation models like GPT-3 and BERT, is used for tasks like object detection, image segmentation, and image classification.
Natural Language Processing (NLP): Foundation models have revolutionized NLP, the branch of AI that deals with the interaction between computers and human language. Models like GPT-3 and BERT have been used for a wide range of NLP tasks, including text generation, translation, sentiment analysis, and question answering.
Reinforcement Learning: Foundation models, especially large language models, can aid reinforcement learning in several ways. For instance, they can be used to generate a more human-readable interpretation of the policy or reward function.
What are some examples of foundation models?
An example of such AI models is the large language model GPT-3 (Generative Pre-trained Transformer 3) by OpenAI. This model excels at text generation tasks such as summarization, question answering, and translation. It is also capable of language modeling and has been used extensively in natural language processing (NLP) applications.
Another example is BERT (Bidirectional Encoder Representations from Transformers), which has been used in various NLP tasks such as sentiment analysis and classification.
SAM, developed by Meta, is a foundation model designed for instance and semantic segmentation tasks in images and videos. It alleviates the burden of performing these complex tasks, providing efficient and accurate results.
What are the strengths of foundation models?
Generalization: Foundation models are trained on a wide range of data, which allows them to generalize across many different tasks. They can generate human-like text, answer questions, translate languages, and even write code.
Scalability: These models can be scaled up to handle large amounts of data and complex tasks. As the size of the model and the amount of training data increases, the performance of the model generally improves.
Versatility: Foundation models can be fine-tuned for specific tasks, making them versatile tools that can be adapted for various applications.
Cost-Efficiency: While the initial training of these models can be expensive, once trained, they can be used to perform a wide range of tasks that would otherwise require separate models. This can be more cost-effective in the long run.
What are the weaknesses of foundation models?
Lack of Understanding: A foundation model does not truly understand the content it's processing. It generates responses based on patterns it has learned during training, not on a deep understanding of the content. This can lead to outputs that are nonsensical, irrelevant, or contradictory.
Inconsistency: A foundation model can sometimes provide different answers to slightly rephrased versions of the same question or even the question asked multiple times. This inconsistency can be a significant issue in applications where reliability is crucial.
Difficulty with Long Contexts: While foundation models can handle a certain amount of context, they can struggle with very long or complex contexts. They may lose track of important details or fail to maintain coherence over a long piece of text.
Difficulty with Specific Tasks: Foundation models are generalists, trained on a wide variety of data. While this allows them to handle a broad range of tasks, they may struggle with tasks that require specialized knowledge or skills.
How do we adapt a foundation model for our specific AI needs?
Across industries, businesses and enterprises have been experimenting with foundation models to enhance and innovate their products and services further. But of course, with these strengths and weaknesses in mind, we know that shaping a foundation model for our ML or AI needs will still require considerable work. In our previous webinar, we discussed three different ways to adapt ai foundation models to our needs. In this article, we are going to delve deeper into these three topics:
Downstream filtering
Let's start with downstream filtering, a technique that fine-tunes the model to provide the most relevant responses. This approach was employed in training ChatGPT and can be replicated to ensure the model's high specificity. The training process involves collecting demonstration data using a supervised policy, generating various model outputs, ranking them based on human raters, and optimizing the policy using reinforcement labeling.
.webp)
Here's a simplified explanation of how it works:
Training the Foundation Model: The first step is to train a large-scale language model (the foundation model) on a diverse range of internet text. However, this model might generate outputs that are inappropriate or unsafe because it learns from the biases in the data it was trained on.
Fine-Tuning: The foundation model is then fine-tuned on a narrower dataset with human supervision. This process adapts the model to specific tasks and helps it to generate more useful and safe outputs. The fine-tuning process involves providing the model with examples of correct outputs for a given input, and then adjusting the model's parameters to minimize the difference between its outputs and the correct outputs.
Downstream Filtering: After fine-tuning, an additional layer of filtering is applied to the model's outputs. This is the downstream filtering. It involves checking the model's outputs against a set of rules or guidelines and filtering out any outputs that violate these rules. For example, the filter might remove outputs that contain hate speech, personal information, or other inappropriate content.
Downstream filtering is a crucial part of ensuring the safety and usefulness of foundation models. It helps mitigate some of the risks associated with these models, such as generating harmful or biased content. However, it's not a perfect solution, and it's typically used in combination with other techniques, such as improving the fine-tuning process and developing better methods for user feedback and control.
Fine-tuning a general model to a specific use case
Fine-tuning is a common practice in machine learning where a pre-trained model is further trained, or "fine-tuned," on a smaller, specific dataset. This process adapts the general model to a specific task or use case.
Here's a breakdown of the process:
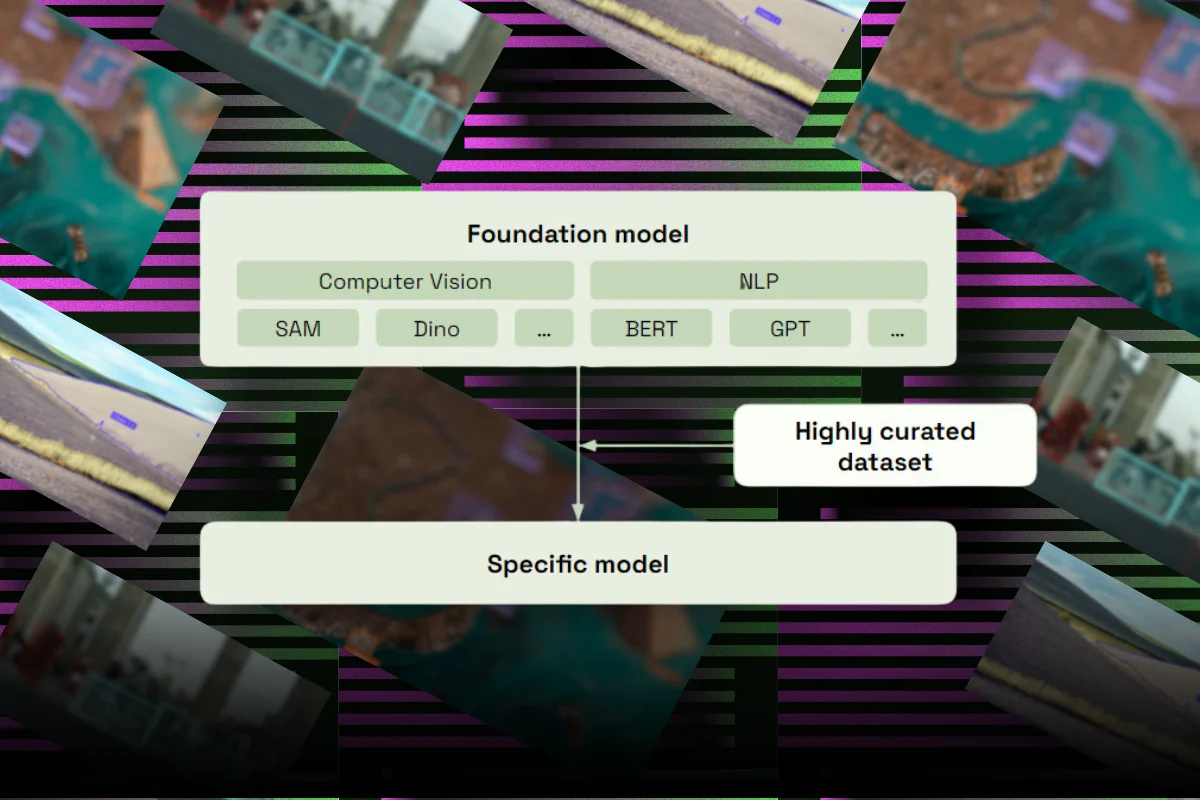
Choose a Foundation Model: The first step is to choose a foundation model. This could be any large-scale model that has been pre-trained on a diverse range of data. Examples include SAM, Dino, BERT, GPT, and others. These models have learned a wide range of features from their training data, making them a good starting point for various tasks.
Prepare a Specific Dataset: Next, you need a dataset that is specific to the task you want the model to perform. This dataset should be highly curated and relevant to the task. For example, if you want the model to identify a specific object type in images, you would need a dataset of images containing that object.
Fine-Tune the Model: The pre-trained model is then fine-tuned on the specific dataset. This involves running the model on the new data and adjusting the model's parameters to minimize the difference between the model's predictions and the actual outcomes. The goal is to ensure that the model has optimal performance in accuracy.
The fine-tuning process also helps avoid a "catastrophic forgetting." This is a phenomenon where a neural network forgets how to perform a previously learned task after learning a new one. By fine-tuning the model on a specific dataset, you're helping the model retain its general knowledge while also becoming proficient at a specific task.
The whole idea of fine-tuning is training a general model to be better at a specific task, so remember that it can also make the model less effective at other tasks. This is a trade-off that comes when deciding to fine-tune a model.
Fine-tuning a foundation model in action
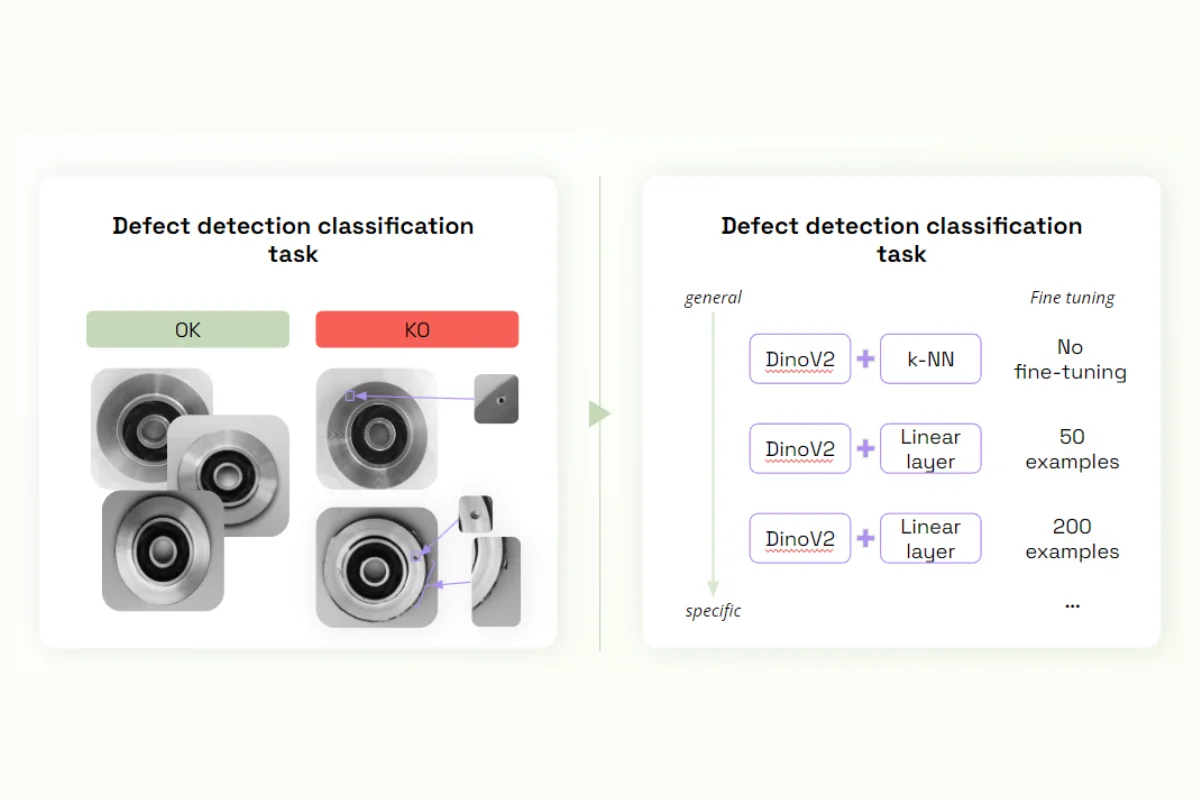
In our previous webinar, we demonstrated the adaption of foundation models in a specific use case. We used the Dino V2 model for defect classification in casting products.
Initially, a generic approach was employed using the model's embeddings directly along with a nearest-neighbor algorithm, achieving an accuracy of 83%. While this might have seemed satisfactory, in an industry like aviation where high precision was required, it may have been insufficient.
Therefore, the Dino V2 model was fine-tuned using 200 examples of labeled data, significantly improving the model's accuracy to over 95%. This demonstrated that while foundation models could perform with limited examples, fine-tuning with curated data could significantly enhance their performance in industry-specific contexts.
This shared notebook contains all the steps needed to replicate this process, from project creation in Kili to model training.
Using retrieval-augmented generation
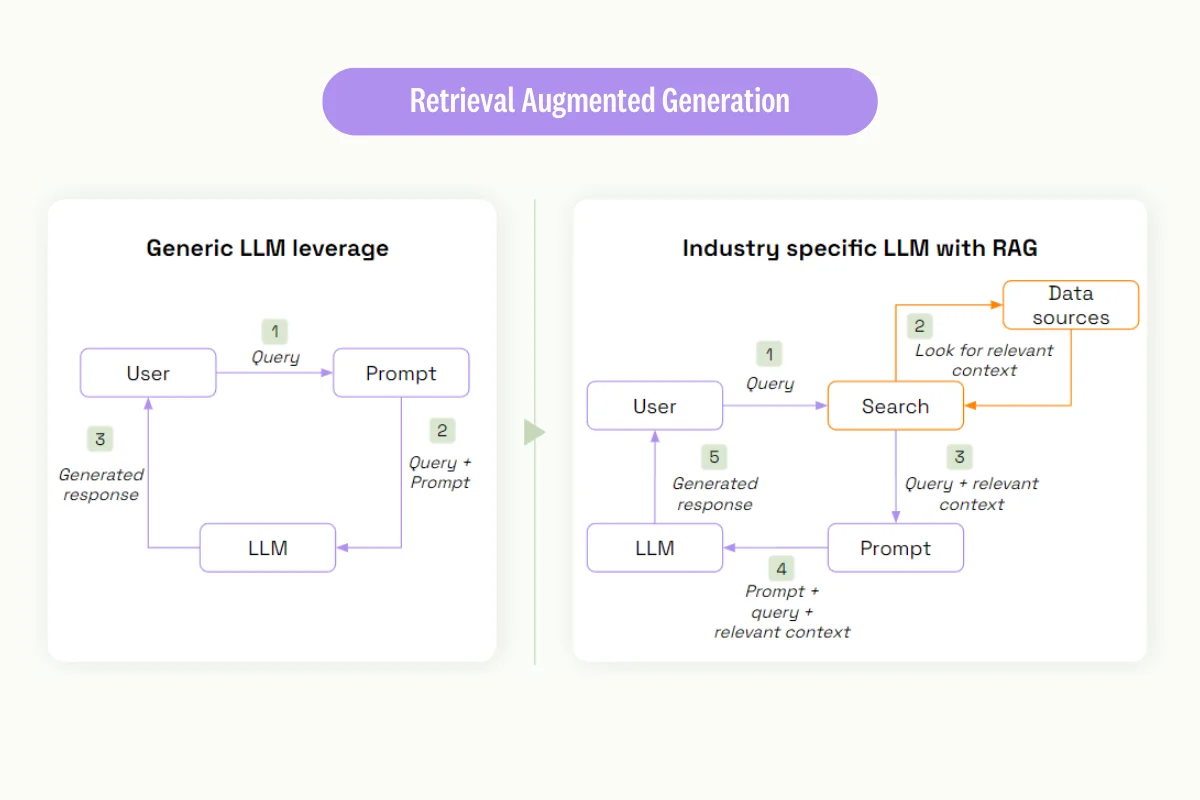
Lastly, a part of fine-tuning involves relying on embeddings to learn faster. To do this, we'll introduce the retrieval-augments-generation (RAG).
Retrieval-Augmented Generation (RAG) is a powerful approach in the field of Natural Language Processing (NLP) that combines the strengths of pre-trained language models with information retrieval systems. It is designed to address the limitations of traditional language models, particularly their inability to incorporate real-time, external, or industry-specific knowledge.
RAG operates by integrating a retrieval step into the generation process of a language model. When presented with a query, instead of generating a response based solely on pre-trained knowledge, the model first retrieves relevant documents or data from an external source. This retrieved information is then used to augment the generation process, providing context-specific or real-time information that the base language model may not have.
The process can be broken down into three main steps:
Query: The model receives a prompt or question.
Retrieve: The model searches an external database or document collection for relevant information.
Generate: The model uses the retrieved information and pre-trained knowledge to generate a response.
RAG's strength lies in its ability to adapt to industry-specific needs. Organizations can tailor the model's responses to their specific requirements by selecting an external source of information. For example, a medical organization could use a database of medical research papers as the retrieval source, enabling the model to provide responses based on the latest medical research.
Moreover, RAG can help overcome the limitations of large language models like GPT-3, which, while powerful, may lack the ability to provide real-time or context-specific information. For instance, if you ask GPT-3 about the current inflation rate in the U.S., it won't be able to provide an accurate answer as its training data only goes up until a certain point in the past. However, with access to an external database of economic indicators, a RAG model could retrieve the current inflation rate and incorporate it into its response.
If you're finding that your foundation model isn't delivering the desired results, there are several strategies you can employ to enhance its performance.
Firstly, you can refine the prompt, evaluate it using custom metrics, manage the templates, experiment with different versions, or add a few shots to the prompt to provide more context.
Secondly, you can adjust the model itself. This could involve evaluating and comparing the outputs of different models, tweaking the parameters, or fine-tuning the model to make it more industry-specific.
If these strategies don't yield the desired improvements, you can then focus on the retrieval component of the RAG model. This could involve using generic embeddings to conduct a vector search for relevant documents within your data sources. This vector search is performed in a vector database and can be customized for more advanced strategies using a supervised approach.
Finally, we provide examples and training for the model, diagnose its performance, and iterate on this model to ensure it effectively incorporates the additional elements we provide to our prompt. This iterative process is crucial for optimizing the model's performance and ensuring it meets the specific needs of your industry.
The future of foundation models: Bringing the focus toward high-quality data
As we look to the future, the proliferation and advancement of foundation models herald a new era in artificial intelligence. With their ability to generalize learning from vast amounts of data, these models are poised to become the basis for a wide range of applications across various sectors. Therefore, the emphasis is shifting from model development to creating and curating high-quality datasets.
This changing landscape means enterprises can now focus on delivering superior applications by leveraging these pre-existing, powerful models, thus reducing the time and resources spent on building complex models from scratch. The key lies in fine-tuning these models using industry or application-specific datasets. The better the quality of these datasets, the more accurate and reliable the application.
In addition, it's important for businesses to consider the legal and ethical implications of using foundation models. As these models have the potential to greatly impact society, organizations need to ensure that they are using high-quality datasets that are free from biases and adhere to ethical standards. By doing so, businesses can become more aware of the potential biases and risks associated with the use of foundation models.
The future of AI development will likely involve a symbiotic relationship between advanced foundation models and high-quality, tailored datasets. By being conscious of the legal and ethical considerations and striving for the highest quality datasets, businesses can harness the full potential of these advanced models while promoting fairness and accountability.
We're excited to see the rise of foundation models. These AI models are reshaping the AI development landscape and presenting new opportunities for enterprises to deliver innovative, high-performing, and dynamic applications. The future promises exciting possibilities as we explore and harness the full potential of these advanced models.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
