.png)

_logo%201.svg)


AI Summary
Artificial intelligence (AI), specifically its subfield of deep learning, is poised to reshape the insurance industry in the coming years. 65% of insurance companies plan to invest $10 million or more into AI technologies in the next three years. Whether expanding health insurance coverage or disbursing regular unemployment insurance benefits, AI will augment insurance companies licensed in their respective regions to enable better customer satisfaction.
However, insurance AI models will only be as effective as the datasets they are trained on. This underscores the importance of annotation best practices and tools to enable high-performing AI models.
Throughout the years, insurance providers have used Kili to annotate datasets, enabling AI systems capable of automating risk assessment and claim processing, leading to better customer experience. In this article, you'll discover the importance of building high-quality datasets for insurance AI, the challenges you may face, and strategies to use for building impactful AI models.
The Importance of High-Quality Data Sets
Insurance companies, use deep learning models to build AI systems that learn from massive datasets. However, the efficacy of these models is directly related to the quality of the datasets they are trained on. Poorly compiled datasets can yield biased or inaccurate results, affecting critical operations like underwriting and claims processing.
A dataset's quality is characterized by its volume, diversity, presence of noise, and labeling accuracy. High-quality datasets are pivotal to training consistent, accurate, and reliable AI models in insurance use cases. We share several proven benefits that high-quality datasets offer when training insurance AI systems.
Better customer experience
Customers expect timely responses throughout their entire journey when interacting with insurers. Whether signing up for a new policy, submitting initial claims, or following up with a premium payment, consumers prefer insurance companies that consistently meet their expectations.
A data-rich and balanced training dataset can enable deep learning models to learn different customer behavior patterns. Once deployed, the trained AI system can then adapt to each customer's preferences and behaviors, personalizing interactions and improving customer satisfaction. An accurate, well-rounded dataset is a prerequisite for training a model that generates actionable predictions for insurance providers and their customers.
Make sense of data
Unlike structured data like tables or spreadsheets, unstructured data lacks a predefined format, making it challenging for deep learning models to process directly. However, through careful annotation, these unstructured data sources can be converted into structured, labeled datasets that AI systems can learn from. From industry reports to customer feedback forms, the quality and comprehensiveness of data labeling directly impacts the model's ability to extract meaningful insights.
Reduce risk and operational costs
Insurance AI systems trained on high-quality datasets are equipped to identify patterns and detect anomalies that might be missed by traditional methods. These capabilities not only improve risk assessment but also reduce operational costs by automating complex decision-making processes. Moreover, by accurately reflecting diverse scenarios through comprehensive data labeling, these models help insurers minimize financial risks associated with incorrect predictions.
Reliable and accurate outcomes
The foundation of any reliable AI system lies in the quality of its training data. High-quality datasets enable deep learning algorithms to produce consistent, accurate outputs that insurers can depend on. Without such datasets, models may exhibit unpredictable behavior, undermining trust in AI-driven processes and potentially exposing companies to regulatory risks.
The Impact of AI and High-Quality Training Data on Insurance Operations
Within the insurance landscape, there are several areas where the impact of AI and high-quality training data is most significant. These include:
Claims processing
Traditionally, claims processing involves humans going through the claims and verifying its authenticity, which can be slow and error-prone. AI-powered claims processing systems can analyze documents and images to verify and expedite claims more efficiently.
To illustrate, a homeowner files an insurance claim for hurricane damage. Trained computer vision models can assess the damage extent from photos the homeowner submits. Meanwhile, natural language processing (NLP) models extract details from the homeowner's written damage report. These capabilities enable faster claims processing.
Still, the effectiveness of such AI-powered claims processing relies heavily on training data accuracy. For instance, AI claims processing for water damage requires training data covering various scenarios—from minor leaks to severe flooding. The model also needs properly labeled images showing damage to different materials (drywall, wood, carpet) under different conditions. Without comprehensive, accurately labeled training data, the model might consistently undervalue damage to specific materials or miss subtle signs of secondary damage like mold.
Risk assessment
A common application of AI in the insurance industry is for assessing risks. Insurance companies use machine learning models to evaluate and predict the risks associated with policyholders. For example, auto insurance companies use machine learning to evaluate driving behaviors, vehicle conditions, and demographic factors to assess an individual's risk level for insurance coverage.
The quality of training data directly impacts the reliability of these predictions. In auto insurance, ML models need accurate labels across multiple dimensions—driving behavior categories (aggressive braking, speeding patterns), vehicle condition assessments (tire wear, engine health), and environmental factors (road conditions, weather patterns). Without precise data labeling across these categories, the model might incorrectly classify a cautious rural driver as high-risk simply because their driving patterns differ from the urban data that dominates the training set.
Policy customization
A well-trained AI model can develop unique, individualized risk profiles that lead to more tailored and precise insurance plans. Instead of a one-size-fits-all approach, AI can enable personalized plans based on unique risk factors and individual needs.
For example, in health insurance, an AI model could use a customer's medical history, lifestyle habits, and genetic predispositions to suggest personalized coverage options that closely match their health risks. This approach leads to better customer satisfaction and more accurate pricing. But this level of customization demands comprehensive, well-labeled training data. The model needs accurate annotations linking diverse health data—medical records, lifestyle surveys, and medical imagery—to specific risk categories and coverage recommendations. Poor data quality could lead to inappropriate coverage suggestions, potentially leaving customers vulnerable.
Fraud detection
Insurance fraud costs the industry billions annually. AI systems can detect fraudulent claims by analyzing patterns and inconsistencies across large amounts of data. High-quality datasets help deep learning models learn to distinguish between legitimate and fraudulent claims, improving the accuracy of fraud detection systems. These models can identify subtle indicators of fraud that human reviewers might miss.
A real-world example of AI fraud detection in insurance is when machine learning algorithms analyze historical claims data, such as past claim amounts, types, and patterns, to spot anomalies. The models can flag unusual patterns, such as someone submitting multiple similar claims within a short period or claims that deviate significantly from the norm.
However, to build a competent fraud detection AI system, the model needs training data with accurately labeled examples of both legitimate and fraudulent claims. The fraudulent examples must cover a wide range of tactics—from simple exaggeration to sophisticated staged claims. Without detailed labeling, the model might either flag too many legitimate claims as fraudulent (causing customer frustration) or miss genuine fraud.
Challenges of Building AI Data Sets for Insurance
While the benefits of high-quality training data for insurance AI are clear, building such datasets presents significant challenges. Understanding these obstacles is crucial for developing effective strategies to overcome them.
Dealing with data complexities
Insurance data often comes in various formats and structures—from structured databases to unstructured text documents and images. Handling this diversity requires robust data labeling tools and processes. Additionally, insurance data typically contains specialized terminology, complex relationships between data points, and domain-specific nuances that general-purpose labeling tools may not adequately address.
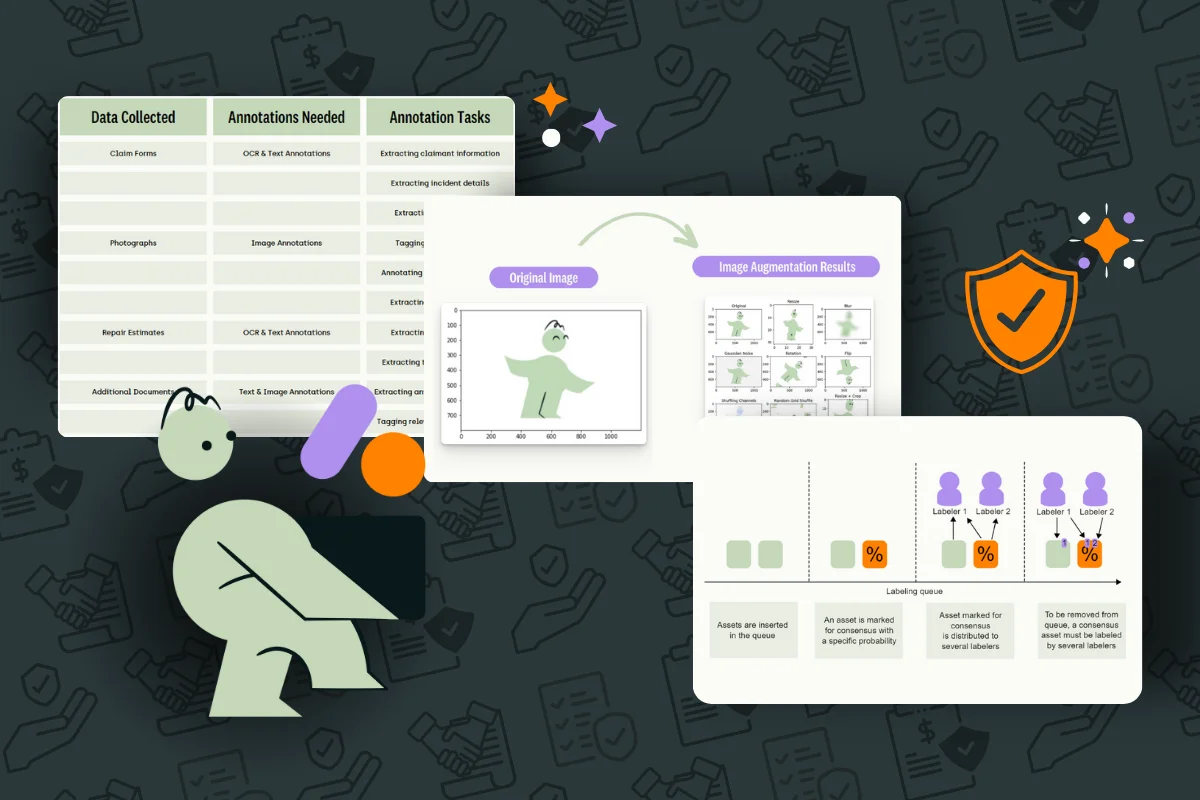
For example, property damage reports might include technical architectural terms, repair estimates, and photographs. Labeling this data accurately requires not just text annotation but also computer vision capabilities to assess property images and cross-referencing between text and visual data.
Moreover, insurance datasets grow continuously, requiring labeling solutions that can scale accordingly without compromising quality or increasing costs.
Meeting industry data compliance standards
Insurance is a heavily regulated industry, and data handling must comply with privacy laws like HIPAA, GDPR, and state-specific regulations. These regulations dictate how data is collected, stored, processed, and shared. Training data that inadvertently reveals personally identifiable information (PII) or fails to comply with privacy standards can expose companies to legal and reputational risks.
Model explainability
Regulatory bodies and customers alike expect AI systems to explain their decisions. For example, when a claim is denied, insurers must be able to explain why. Training datasets need to be labeled in ways that help AI models trace their decision-making process. This means going beyond basic labels to include annotations that provide context, reasoning, and relevant criteria for each data point.
Key Strategies for Building AI Training Data for Insurance

The effectiveness of AI models in insurance fundamentally depends on the quality and organization of their training data. Here are some key strategies to consider:
Selecting the right data labeling tool
A robust data labeling tool is essential for managing the complexities of insurance data. When evaluating tools, key features to look for include native support for diverse data types (text, images, documents), as insurance data often spans multiple formats. Kili Technology, for instance, offers native support for various data types while providing specialized tools for document annotation, making it particularly well-suited for insurance workflows where claims often include both written reports and photographic evidence.
Additionally, if the insurance company lacks a large labeling team, AI-assisted labeling features are important to consider. Kili Technology's Smart Tools can intelligently speed up the annotation process by up to 10x—allowing a smaller team to accomplish what would typically require a much larger workforce while maintaining high-quality standards.
Data collection and annotation
Collecting the right data is the first step. Insurance companies should focus on gathering data from real-world scenarios that the AI system will encounter in production. This includes historical claims data, customer interactions, and relevant external data sources. The collection process should prioritize diversity and representation to ensure the AI model can handle the full range of scenarios it will face.
Once collected, data must be meticulously labeled. For insurance AI, this often involves multi-layered annotation that goes beyond simple categorization. For example, a claim document might need labels for the type of claim, the severity of damage, the relevant policy sections, and any indicators of potential fraud. Quality control measures should be implemented at every stage to maintain high-quality labeled data.
Maintaining Data Quality
Data quality maintenance is an ongoing process, not a one-time task. Regular audits help ensure that training datasets remain accurate and relevant over time. This includes checking for labeling inconsistencies, updating labels to reflect changing insurance products or regulations, and removing outdated data points.
Moreover, data quality extends beyond accuracy. Datasets must be balanced and representative to avoid biased AI models. In insurance, bias in training data can lead to unfair pricing or discriminatory claim processing. Regular bias audits and dataset diversity checks should be incorporated into the data management process.
Ensuring data compliance and security
Insurance datasets contain highly sensitive information. Therefore, insurers use a robust data labeling tool to simplify complex workflows and enable document annotation at scale. Deep learning models train and feed on massive datasets for risk assessment, policy underwriting, and other insurance-related tasks. Security negligence might subject the AI system to data breaches and non-compliance with regulations like HIPAA and GPDR. Ensure your data labeling tool complies with these standards to maintain consumer trust.
Build a Solid Quality-Focused Data Strategy
Deep learning algorithms hold tremendous potential to redefine the insurance space positively. The key lies in mitigating the challenges we describe. Here's how:
Define the project clearly. Understand your objectives as it sets the foundation for data collection, annotation types, and resource allocation. For example, you have to develop an AI model to automate claim processing. If that is the case, your requirements may look like this:
Determine your stakeholders, collaborators, their roles, and their needs.
- What task type is required? Document classification, NER, etc. or a combination.
- Is there data or not? If yes, what format is it in, and how much is there?
- What performance metrics to use: precision, recall, etc.
Focus on quality over quantity. Quality data is better than merely large amounts of training data. To achieve this, determine the right data labeling tool with robust QA features, especially those that maintain labeling accuracy while scaling their operations. Kili Technology provides an accessible platform to label, train, and continuously improve ML models. It features an accessible Python SDK that allows data scientists to integrate labeling operations with their ML workflows.
Leveraging Kili Technology for Insurance AI Development
At Kili Technology, we have first-hand experience partnering with insurance providers to build AI datasets. Through these collaborations, we've developed specialized approaches for data annotation that address the unique challenges of the insurance industry.
One notable example involves partnering with an insurer to develop a computer vision model for property damage assessment. By using our labeling and annotation platform to annotate thousands of property damage images accurately, the trained AI model achieved a high degree of accuracy in identifying damage types and estimating repair costs.
Key takeaways from our approach include:
Collaboration between data scientists and insurance domain experts leads to more refined and accurate datasets.
Iterative labeling processes, where models are regularly retrained on newly annotated data, lead to continuous improvement. Active learning speeds up this cycle by identifying the most valuable data points for annotation.
Our comprehensive annotation tools—ranging from text to image annotation, including bounding boxes, named entity recognition, and more—cater specifically to the varied needs of insurance data.
Conclusion
Never compromise dataset quality when developing AI systems for insurance use cases. Customers deserve the responsiveness, integrity, and value-added protection insurance promises and upholds in their day-to-day service.
As AI systems become more prominent in the strictly regulated industry, preparing clean, well-annotated, high-quality datasets is essential. It starts with finding a reliable data labeling tool. Make sure that the platform covers your data types, has efficient annotation tools, enables team collaboration, and scales up as your AI projects require.
If the annotation company or labeling task is outsourced, then choosing a data labeling service provider with experience handling sensitive data across industries is essential. Going through different insurance case studies and studying the security and compliance policies and practices put in place can help you decide on which data labeling tool to go with.
Conclusion
Never compromise dataset quality when developing AI systems for insurance use cases. Customers deserve the responsiveness, integrity, and value-added protection insurance promises and upholds in their day-to-day service.
As AI systems become more prominent in the strictly regulated industry, preparing clean, well-annotated, high-quality datasets is essential. It starts with finding a reliable data labeling tool. Make sure that the platform covers your data types, has efficient annotation tools, enables team collaboration, and scales up as your AI projects require.
If the annotation company or labeling task is outsourced, then choosing a data labeling service provider with experience handling sensitive data across industries is essential. Going through different insurance case studies and studying the security and compliance policies and practices put in place can help you decide on which data labeling tool to go with.