
.png)

_logo%201.svg)


AI Summary
Retrieval-augmented generation (RAG) has represented a significant advancement in the field of natural language processing (NLP), combining the strengths of Large Language Models (LLMs) with external knowledge retrieval, including internal company data, to enhance their understanding and response capabilities. With this technique, RAG provides a robust and dynamic approach to AI conversations and information processing, enabling more accurate, contextual, relevant, and up-to-date responses.
This interesting synergy sees applications in numerous domains, from customer service to internal knowledge chatbots, primarily to facilitate users' interaction with data.
To ensure widespread adoption and long-term value delivery of your RAG application, following best practices when deploying such use cases is essential. By doing so, we can maximize the potential value that they offer.
This article will begin with a brief introduction to RAG, the factors that affect the performance of a RAG stack and includes an emphasis on the importance of creating a benchmark dataset to ensure the proper functioning of the stack. Finally, we will tackle the monitoring best practices for continuous value delivery.
What is RAG?
RAG is an advanced technique in the field of natural language processing (NLP) and machine learning, particularly in the context of language models like ChatGPT. It's a methodology that combines the strengths of neural network-based language models and external knowledge retrieval systems to generate more informative, accurate, and contextually relevant responses. Let's break down why it's important to get it right, and how it works:
Why Getting RAG Right is Important
In the modern business landscape, where data-driven decision-making and customer-centric approaches are key to success, the importance of Retrieval-Augmented Generation (RAG) cannot be overstated. However, it’s not just about implementing RAG; it’s about implementing it correctly. Here’s why getting RAG right is vital for businesses:
- Accurate and Relevant Information
By pulling in the latest and most pertinent information from various external sources, RAG ensures that businesses aren't making decisions based on outdated or incomplete data. This is particularly crucial in fast-moving sectors like finance, where market dynamics can change rapidly, or in tech, where the latest research can pivot the direction of product development.
- Improving Customer Experience with Richer Responses
RAG enables the generation of responses that are not only accurate but also detailed and tailored to the customer’s specific query. This capability can transform customer service interactions from generic to personalized, enhancing the overall customer experience.
- Reducing Biases
RAG can help mitigate biases by sourcing information from a diverse range of data, leading to more balanced and objective insights. This is particularly important in areas like market research and HR, where unbiased information is critical for fair and effective practices.
- Streamlining Operations and Reducing Workloads
RAG can automate and enhance various business processes, from data analysis to report generation, by providing quick and relevant information retrieval. This not only streamlines operations but also reduces the workload on staff, allowing them to focus on more strategic tasks.
How Retrieval-Augmented Generation Works
For an effective RAG evaluation, let's first understand what the RAG pipeline looks like. Below is a common workflow for the use of RAG to support an LLM-powered chatbot.
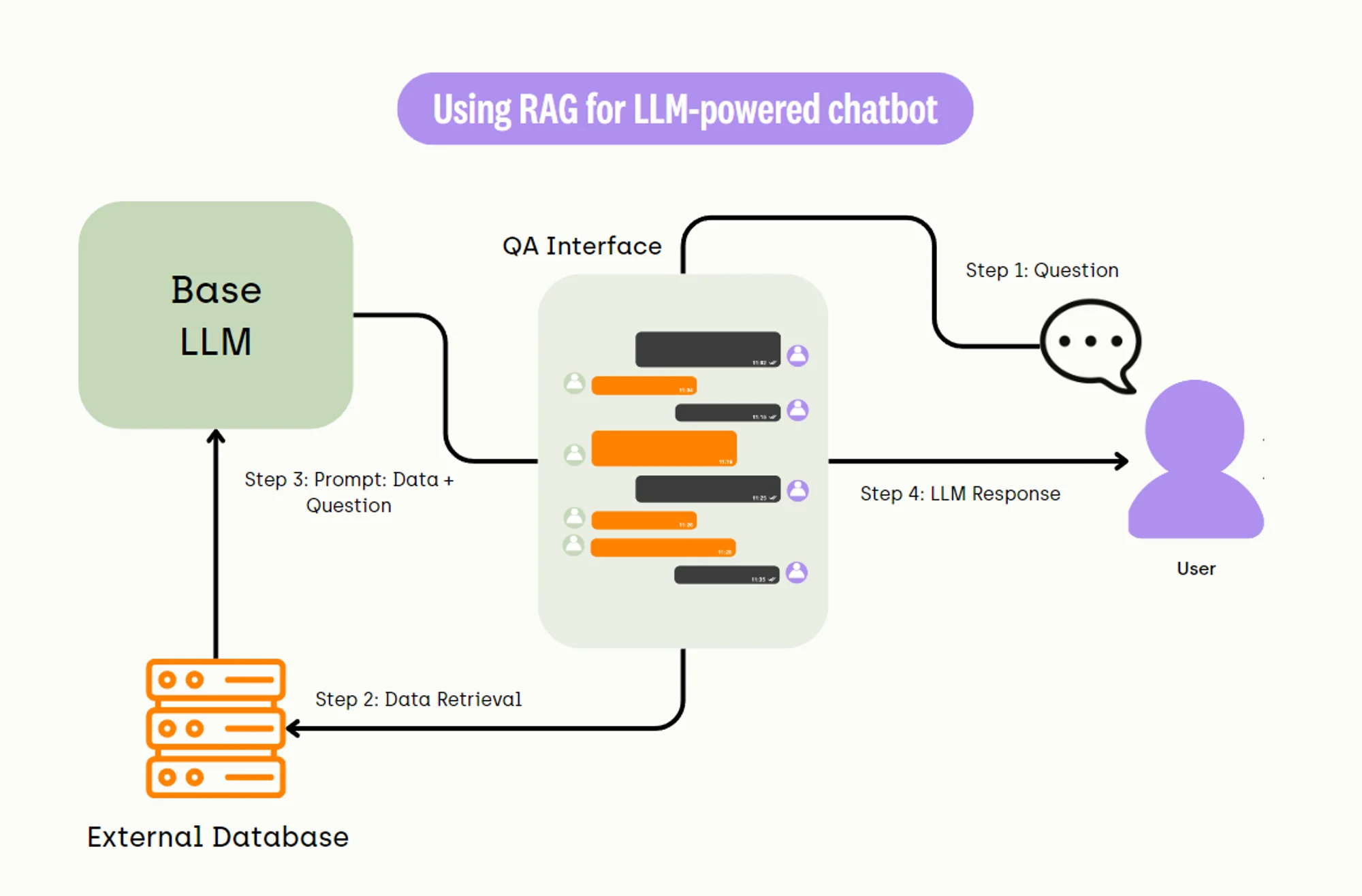
Combining Language Models with Information Retrieval:
- Traditional language models (like earlier versions of GPT) generate text based solely on the patterns they've learned during training. They don't have access to external information during inference (the process of generating text).
- RAG introduces an additional step where the language model queries an external database or corpus of documents to retrieve relevant information. This process is known as information retrieval.
Query Generation:
- When a prompt is given, the RAG system first uses its language model component to understand the query and generate potential search queries.
- These queries are designed to find the most relevant information in the external knowledge source.
Information Retrieval:
- The generated queries are used to search a large database or set of documents. This database could be a curated corpus, the internet, or any large-scale repository of text.
- The system retrieves a set of documents or passages that are likely to contain information relevant to the original query.
Response Generation:
- The retrieved documents are then fed back into the language model.
- The model synthesizes the information from these documents with its pre-existing knowledge (gained during its initial training) to generate a response.
- This allows the model to provide answers that are not only based on its training data but also enriched with up-to-date and specific information from the retrieved documents.
Retrieval-Augmented Generation (RAG) key drivers
Four key parameters impact the performance of a deployed RAG stack:
- The LLM chosen plays a pivotal role in shaping the final output. It determines how effectively the context information is synthesized and integrated into the response.
- The prompt will be critical for the LLM to correctly follow the task. Well-designed prompts can significantly enhance the model's ability to produce relevant and accurate responses by providing clear direction and scope.
- The context search will enable to find the information that makes sense for a given question. The precision of this search directly impacts the applicability and usefulness of the information retrieved for answer generation.
- Raw data quality will impact the relevance of the final output following the garbage-in / garbage-out principle: Poor-quality data will generate poor-quality answers. High-quality, well-curated, and regularly updated data sources are essential for ensuring the reliability and validity of the answers generated by the RAG system.
The RAG pipeline's performance is not solely dependent on any single element but is a function of the harmonious interplay between the quality of the LLM, the design of the prompts, the precision of the contextual search, and the integrity of the source data. Each of these parameters needs to be carefully optimized to harness the full potential of RAG in generating accurate, relevant, and contextually rich responses.
RAG Evaluation: Building gold standard datasets
When developing RAG stacks, performance evaluation is critical to compare models, prompting, and context.
Creation process
This is tackled by creating a benchmark dataset or evaluation dataset of examples (question, context, answer). This dataset is a tool for assessing the stack's performance throughout its development cycle. Benchmark datasets are particularly advantageous for evaluating Retrieval-Augmented Generation systems in business contexts because they provide an objective and customizable means of measuring performance against specific industry-relevant scenarios. These datasets allow businesses to assess the accuracy and relevance of RAG systems' responses in a controlled manner, ensuring the AI's outputs meet the high-quality standards required for real-world applications.
Steps in Dataset Creation:

- Initial Question Formulation: Subject Matter Experts (SMEs) are engaged to formulate pertinent questions based on a specific document or a set of documents. This step ensures the questions are relevant and challenging, reflecting real-world scenarios.
- Context Identification: SMEs then delineate the relevant sections or context within the documents that pertain to each question. This step is crucial in ensuring that the context is accurately identified and is representative of the information needed to generate an appropriate response.
- Answer Drafting: Based on the identified context, SMEs draft precise answers. These answers form the 'gold standard' or ground truth answer against which the RAG stack's responses are compared.
- Benchmarking: The answers generated by the RAG stack are benchmarked against these SME-crafted answers to evaluate the stack's accuracy and relevance in real-world scenarios. During benchmarking, the responses generated by the RAG stack data annotation are used in comparison with the SME-crafted gold standard answers. Annotations may include categorizing responses based on accuracy, relevance, completeness, and even linguistic quality. This comparative annotation is fundamental to quantitatively and qualitatively assess the RAG system's performance.
Tooling
Creating an evaluation dataset often involves various data types (PDFs, text, images…) and requires the collaboration of multiple stakeholders (SMEs, MLEs, LLM engineers). Tools like Kili Technology can facilitate their job with the correct user interface and collaboration features. They provide interfaces and features that streamline the annotation process, whether tagging text, categorizing responses, or linking questions to answers and contexts.
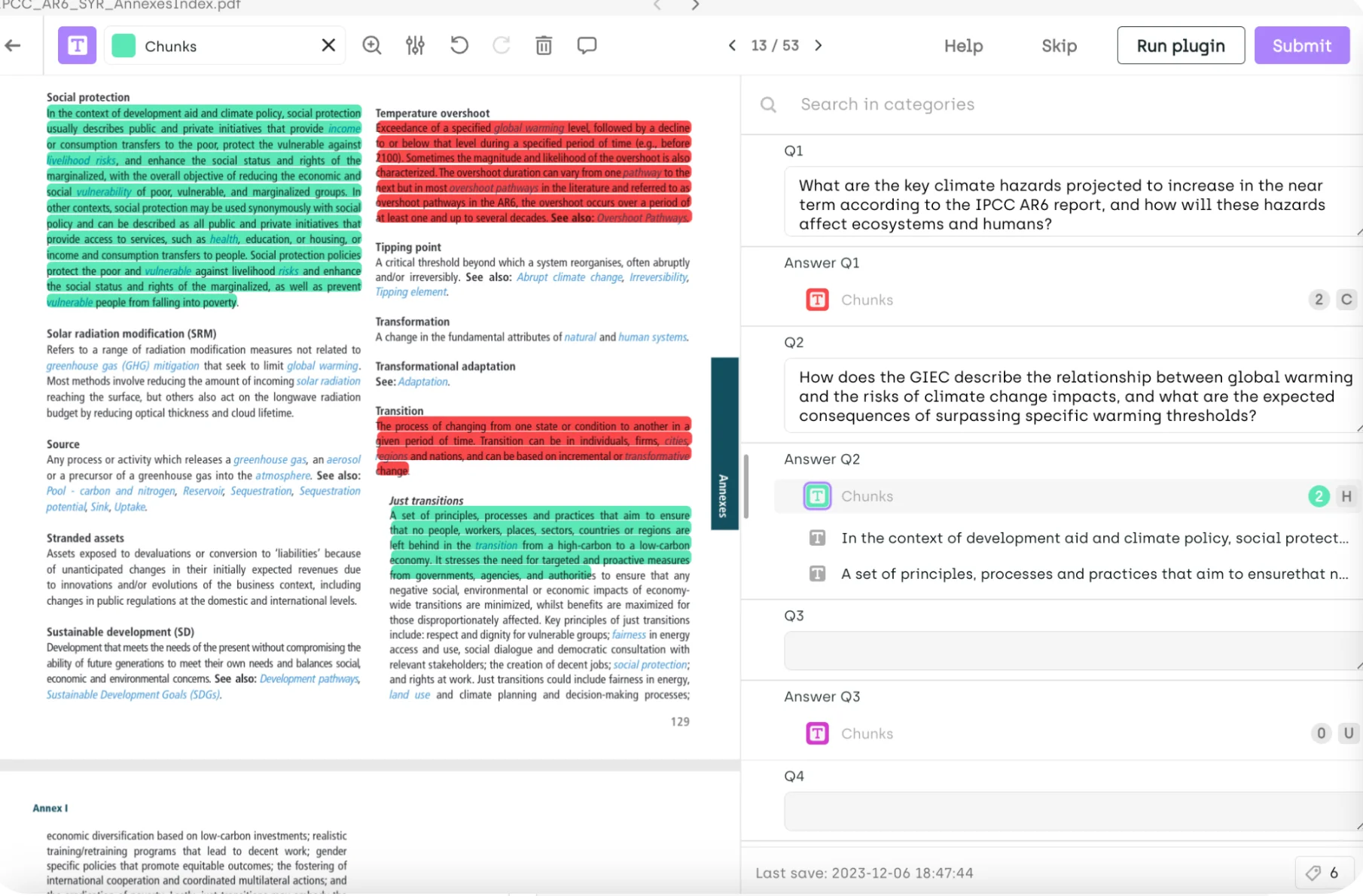
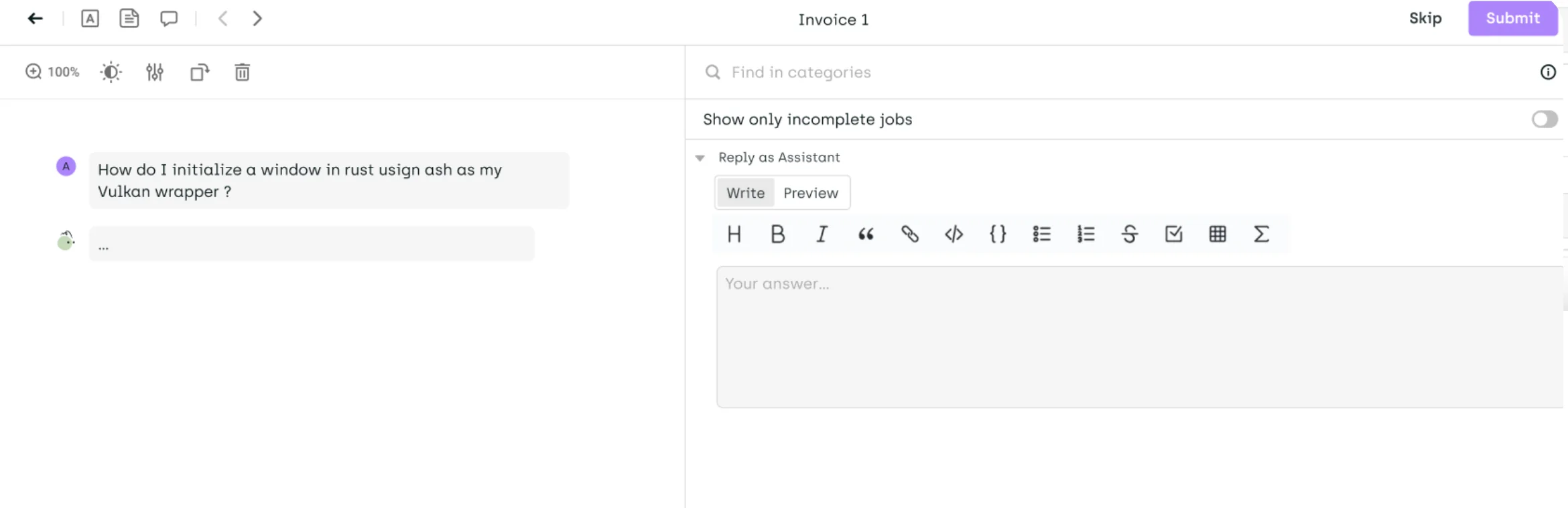
Automating RAG evaluation
To streamline the development and evaluation of Retrieval-Augmented Generation (RAG) systems, an optimized workflow that incorporates both automated pre-labeling and meticulous user review can be established.
Question Creation: Users begin by crafting questions within the Kili interface. This step is pivotal as it sets the foundation for the types of information the RAG system will need to retrieve and generate answers for.
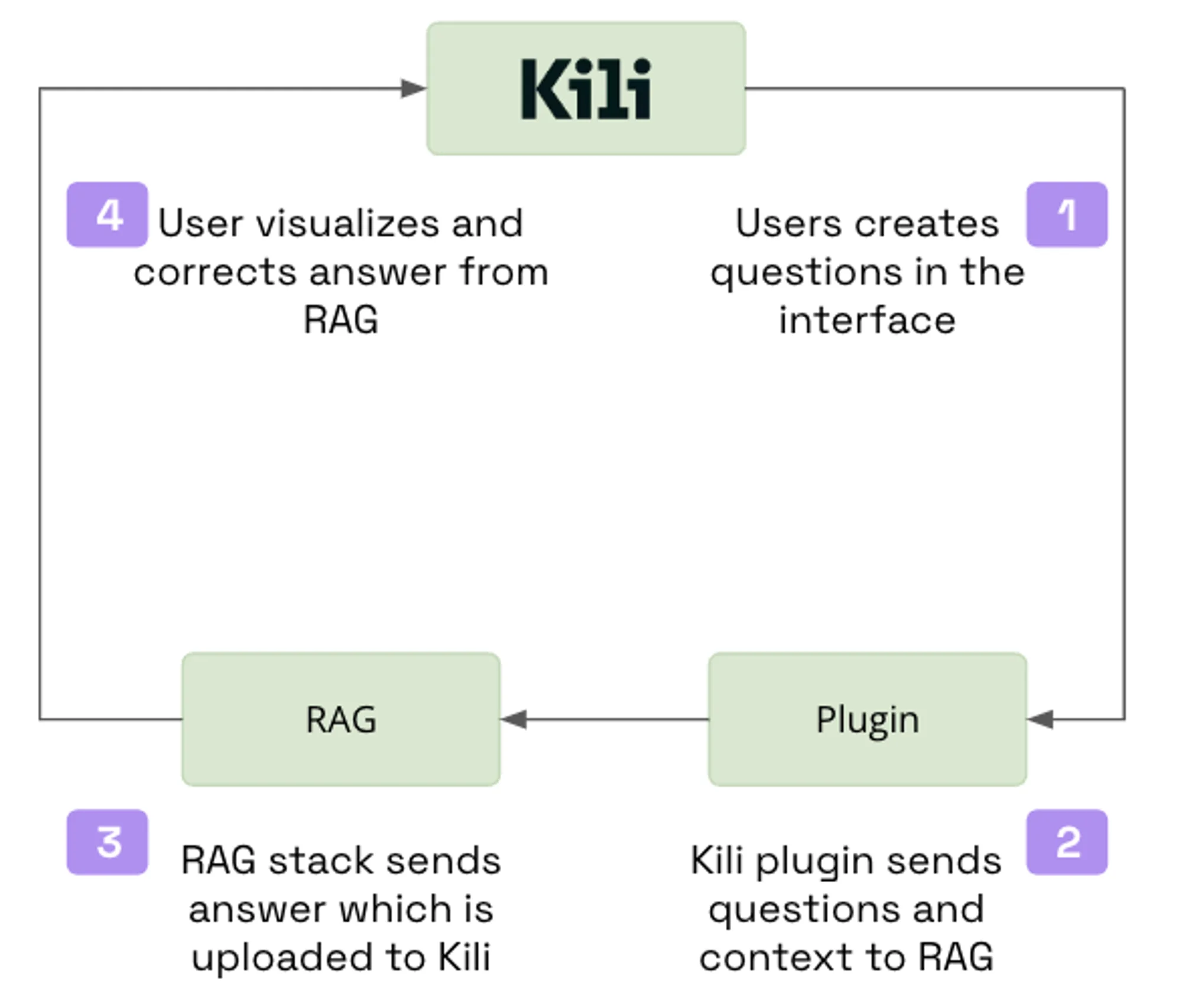
- Automated Context Retrieval: A Kili plugin then takes these questions and communicates with the RAG stack, which intelligently identifies and retrieves the relevant context from the database. This pre-labeling step is where the Large Language Model (LLM) or the RAG stack itself automatically annotates the data with the necessary context, significantly reducing the initial manual workload.
- Answer Generation: The RAG stack processes the questions and their associated context to generate potential answers. These answers are then sent back to Kili, where they are stored and made ready for review.
- User Review and Correction: Finally, users interact with the Kili interface to review and, if necessary, correct the answers generated by the RAG stack. This step is crucial as it ensures the quality and accuracy of the RAG system's outputs. Users can visualize the context and the proposed answers side by side, making it easier to spot discrepancies and refine the answers.
By leveraging such a workflow, creating a gold standard dataset for RAG evaluation is more efficient and ensures a high degree of accuracy in the annotated data. Integrating automated pre-labeling with human oversight creates a synergy that balances speed and precision, enhancing the overall quality of the RAG system's training and evaluation phases.
See a concrete illustration in the Kili interface leveraging the existing RAG stack being developed to provide a first answer to the question. The user can then validate that the output matches.
Monitoring - Validate your RAG stack's quality continuously
When the target performance level is reached, the bot can be released for end-users to interact with it. Nevertheless, it remains important to combine human review & automation to master the outputs.
Process
In production mode, it is required to carefully select the valuable outputs to review by human experts. This can typically be prioritized in an app with thumbs up/down or rely on a model to prioritize data to be reviewed.
A tool like Kili Technology can then be leveraged for experts to provide feedback on the deceptive answers. In this case, reviewers are provided with 3 key interesting elements:
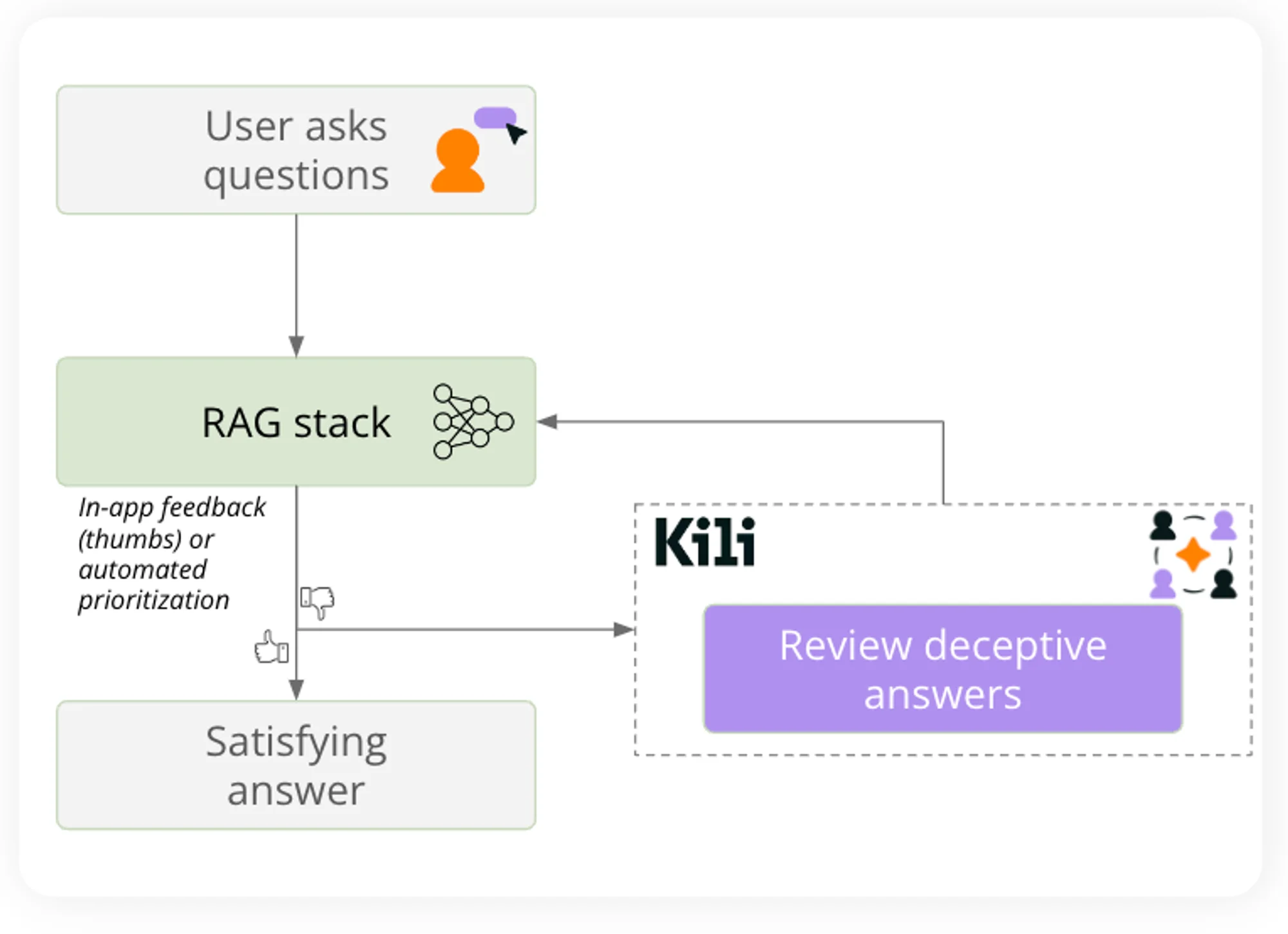
- The context leveraged by the RAG stack
- The question asked by the end user
- The associated answer
The task can then be adapted depending on the project, starting with a classification task to flag specific behaviors, up to more advanced tasks where you would flag specific parts of the answer or even modify the content (typically to work on the raw data).

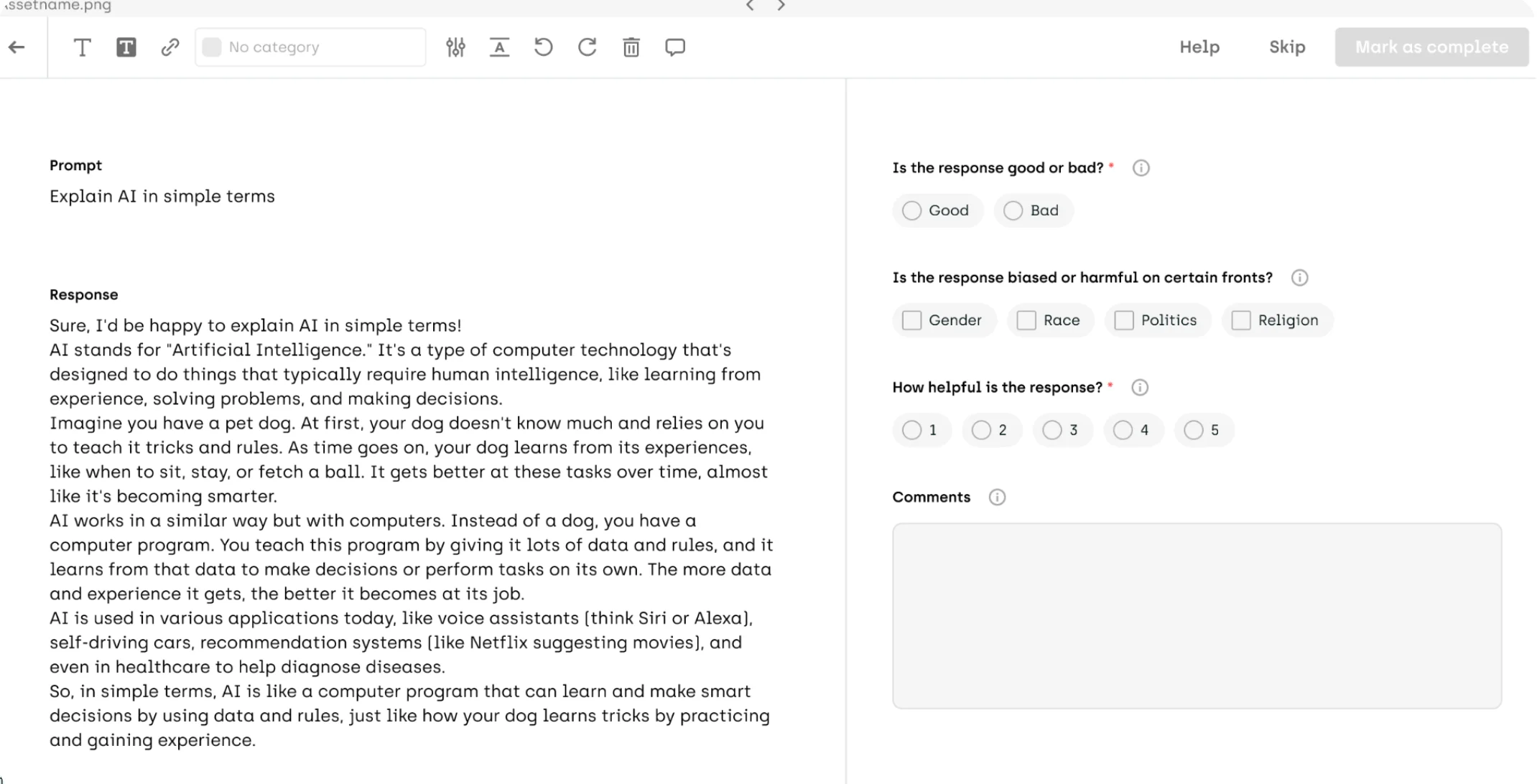
Workflow for automating RAG stack evaluation
Advanced workflows in RAG systems can significantly enhance output verification by incorporating an additional layer of evaluation. This is depicted in the diagram below and can be described as follows:
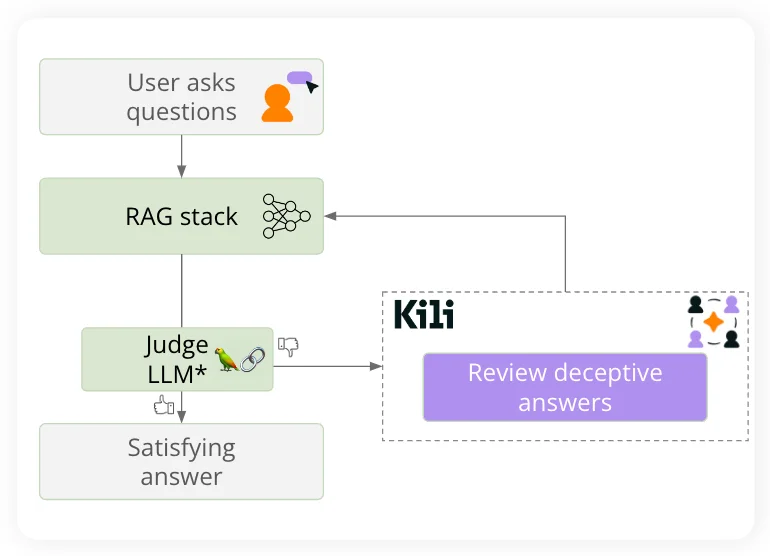
- Initial Question Processing:
- Users input their queries into the system, which serves as the starting point for the RAG stack to generate potential answers.
- RAG Stack Response Generation:
- The RAG stack processes the user's questions, retrieves relevant information, and produces initial answers based on the gathered context.
- Validation by a Judge LLM:
- An auxiliary Large Language Model (LLM), the Judge LLM, is then employed to evaluate the validity of the RAG stack's outputs. This Judge LLM acts as a quality control mechanism, scrutinizing the generated answers for their accuracy and reliability.
- Error Detection and Feedback Integration:
- When the Judge LLM detects errors or identifies answers as potentially deceptive, these instances are flagged for further review.
- Review of Deceptive Answers via Kili Technology:
- This is where Kili Technology comes into play, providing a platform for human reviewers to assess and correct the flagged answers. Leveraging the model's feedback directly, reviewers can focus their attention on problematic responses, ensuring that only high-quality, verified answers are accepted.
- Delivery of Verified Answers:
- Once the answers have been reviewed and any necessary corrections have been made, the system then delivers satisfying and verified answers back to the user.
By following this enhanced workflow, the RAG system not only automates the initial answer generation but also incorporates a sophisticated validation loop. This loop, which integrates both machine learning models and human review, ensures a higher standard of accuracy and reliability in the final responses provided to users. The addition of Kili Technology in this workflow facilitates a more efficient review process, allowing for the seamless correction of errors and the continuous improvement of the RAG system.
Demonstration:

Watch video
Conclusion
LLM applications are further bettered with the support of RAG. RAG application systems merge the analytical prowess of Large Language Models with the specificity of real-time data retrieval, creating a potent tool for delivering precise and contextually relevant responses.
Developing a RAG evaluation framework involves critical steps: crafting relevant questions, identifying and annotating contextual data, generating and refining answers, and benchmarking these against a ground truth answer. The role of data annotation is particularly significant, providing the necessary human judgment, structure, and quality assurance to train and test the RAG system effectively.
Tools like Kili Technology streamline this process, enabling teams to collaboratively annotate data, refine machine-generated answers, and ensure the RAG system's outputs are of the highest quality. By using such tools, businesses can ensure their RAG systems are accurately tuned to deliver reliable and relevant information to their users.
FAQ on Retrieval-Augmented Generation (RAG) Systems
What is context relevance, and how does it affect RAG outputs?
Context relevance refers to how well the RAG system’s response aligns with the specific details and nuances of the query. A high degree of context relevance means the system can understand and incorporate the subtleties of the question into its response, leading to more accurate and satisfactory answers.
What is a Retrieval-Augmented Generation (RAG) system?
A RAG system is an AI-driven solution that combines the capabilities of Large Language Models (LLMs) with real-time document retrieval to provide accurate and contextually relevant responses. It leverages vast datasets and external knowledge to enhance the depth and relevance of its answers.
How does document retrieval work within RAG systems?
Document retrieval in RAG systems involves querying a database or knowledge base to find documents that contain information relevant to a user's query. This process ensures that the generated response is enriched with the most current and pertinent data.
Why is the evaluation metric critical in RAG system development?
Using evaluation metrics are crucial in RAG system development as they provide quantifiable measures of the system’s performance. They help in assessing the accuracy, context relevance, and the overall effectiveness of the RAG in answering queries.
Can the evaluation of RAG systems be automated?
Yes, automated evaluation is a part of advanced RAG systems, where machine learning models, such as Judge LLMs, pre-screen the generated responses for accuracy before human experts review them. This helps in scaling the evaluation process and maintaining high-quality outputs.
How do tools like Kili Technology facilitate RAG system evaluation?
Kili Technology facilitates RAG system evaluation by providing a collaborative platform for data annotation and review. It allows teams to work together to annotate data, refine responses, and ensure the system’s outputs meet quality standards. This support is essential for the continuous improvement of RAG systems.
What steps are involved to evaluate a RAG system?
To evaluate a RAG system, one must first create a benchmark dataset, then use this dataset to assess the system’s responses. The evaluation includes comparing the system's answers to a set of SME-crafted gold standard answers, and using evaluation metrics to measure context relevance and the accuracy of document retrieval.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
