
.png)

_logo%201.svg)


AI Summary
Recent advancements in large language models (LLMs) have increasingly focused on improving reasoning capabilities, moving beyond mere linguistic fluency. DeepSeek R1 is a breakthrough in this domain, specifically designed to enhance structured problem-solving and logical reasoning through reinforcement learning (RL). Unlike traditional models that heavily rely on supervised fine-tuning, DeepSeek R1 adopts a reinforcement learning-only (RL-only) approach to develop its reasoning capabilities.
DeepSeek R1 builds upon the architecture and methodologies of its predecessor, DeepSeek V3, but with a more refined focus on structured reasoning and self-improvement. DeepSeek R1 achieves performance comparable to leading closed-source models, highlighting its efficacy in both open-source frameworks and competitive benchmarks. Key contributions of DeepSeek R1 include:
- Reinforcement learning without supervised fine-tuning (RL-only), enabling self-evolution through trial and error.
- The emergence of sophisticated reasoning behaviors, such as self-reflection and verification.
- Exceptional performance in mathematical and logical reasoning tasks.
Throughout the entire training process, DeepSeek R1 demonstrated robustness, encountering no irrecoverable loss spikes or required rollbacks.
DeepSeek R1: How it works
What is DeepSeek R1?
DeepSeek R1 is a reasoning-specialized LLM that prioritizes structured problem-solving, employing advanced techniques like self-reflection and verification to improve its reasoning accuracy. Unlike general-purpose models, R1 is fine-tuned to excel in logic-driven domains such as mathematics, coding, and scientific analysis. Its innovative load balancing strategy helps achieve efficient inference, making it both powerful and cost-effective.
DeepSeek R1 Architecture
The architecture of DeepSeek R1 is meticulously designed to facilitate efficient reasoning and problem-solving. At its core, the model employs a unique combination of techniques, including multi-head latent attention and innovative load balancing strategies. These features enable the model to achieve high performance across a variety of tasks. The multi-head latent attention mechanism allows DeepSeek R1 to focus on different parts of the input simultaneously, enhancing its ability to learn complex patterns and relationships. Additionally, the innovative load balancing strategy ensures that computational resources are optimally utilized, which is crucial for achieving efficient inference and managing subsequent training stages. This architectural sophistication makes DeepSeek R1 an effective and powerful tool for structured reasoning and problem-solving.
Core Mechanism: Reinforcement Learning with Minimal Supervised Fine-Tuning
One of DeepSeek R1's most notable features is its reinforcement learning-first training process. Unlike traditional LLMs that heavily rely on supervised fine-tuning (SFT), R1 primarily develops its reasoning capabilities through reinforcement learning. However, to stabilize early training phases, R1 still required a small batch of labeled data for its cold start. This hybrid approach allows the model to iteratively refine its problem-solving strategies while leveraging initial structured guidance, leading to emergent reasoning behaviors akin to human-like self-improvement.
Performance and Evaluations
Benchmark Comparisons
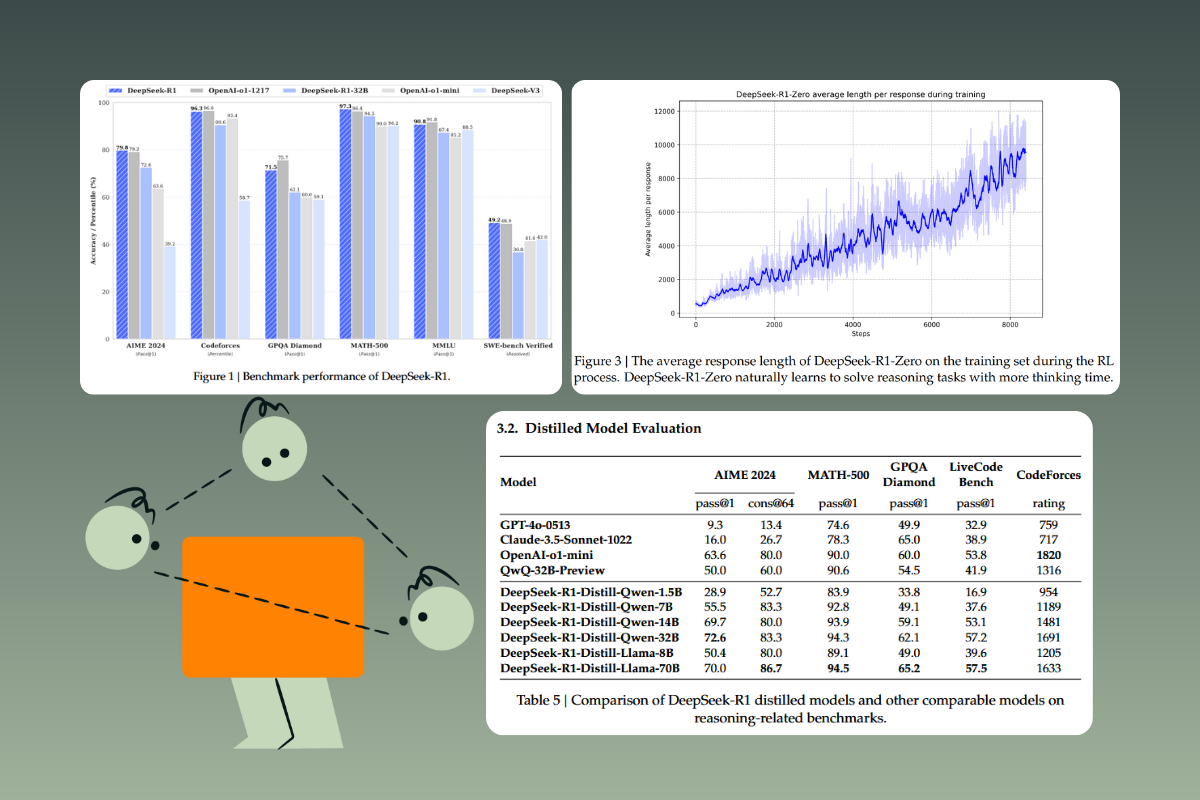
DeepSeek R1 has been rigorously evaluated for model performance against leading models such as OpenAI’s o1, GPT-4o, and Claude-3.5. Key benchmarks include:
- MATH-500: R1 achieved a Pass@1 score of 90.2%, outperforming most open-source alternatives.
- AIME 2024: With a 39.2% Pass@1 score, R1 demonstrated strong mathematical reasoning.
- Codeforces: Achieved a competitive percentile ranking of 51.6%, highlighting its advanced coding abilities.
- GPQA Diamond: Outperformed many competitors with a 59.1% Pass@1 score.
Self-Evolution Process and "Aha Moments"
During training, DeepSeek R1 exhibited self-improvement patterns, often discovering new reasoning strategies through trial and error. One of the most remarkable aspects of its development was its ability to self-correct and refine its logic. The model demonstrated an emergent ability to recognize when an answer path was incorrect or suboptimal and adjust accordingly, even within the same computation process.
These moments, termed "aha moments," occurred when R1 detected inconsistencies or inefficiencies in its reasoning steps. Instead of persisting with incorrect logic, it would pause, reassess prior steps, and generate a revised solution. This capacity for mid-calculation reevaluation significantly improved its accuracy and problem-solving efficiency. Notably, R1 exhibited this ability across various domains, including mathematics, logic puzzles, and programming challenges, where structured reasoning is critical.

Furthermore, this self-evolution process was not pre-programmed but emerged organically through reinforcement learning. The model iteratively improved its decision-making strategies by continuously interacting with problem sets, receiving feedback, and refining its approach. This dynamic learning cycle allowed DeepSeek R1 to develop a nuanced and adaptable reasoning framework, distinguishing it from conventional LLMs reliant on static training data.
Comparison with DeepSeek V3
While DeepSeek V3 serves as a general-purpose LLM, DeepSeek R1 is optimized for structured reasoning capability. Key distinctions include:
- R1 utilizes refined Chain-of-Thought (CoT) techniques, whereas V3 is more conversationally oriented.
- V3 incorporates supervised fine-tuning and RLHF, while R1 relies purely on reinforcement learning.
Training Process: Reinforcement Learning for Enhanced Reasoning
A reminder of how reinforcement learning works:
Reinforcement Learning (RL) is a framework that enables Large Language Models (LLMs) to optimize their performance by interacting with an environment, receiving feedback, and refining their strategy (policy) to maximize expected rewards. This dynamic and iterative process allows the model to continuously improve its responses, ensuring that its outputs become more coherent, accurate, and aligned with human expectations.
Reinforcement Learning as a Markov Decision Process (MDP)
At its core, RL in LLMs can be framed as a Markov Decision Process (MDP), which provides a mathematical framework for decision-making under uncertainty. The MDP formulation consists of the following components:
1. Agent: The Language Model (LLM)
- The agent in this context is the LLM itself (e.g., DeepSeek-R1).
- It generates responses to user queries or predefined prompts by sampling tokens sequentially.
- Unlike reinforcement learning in traditional robotics or gaming environments, where agents physically interact with an external world, LLMs operate in a textual space, navigating linguistic and logical structures to optimize response quality.
2. Environment: The Task Domain
- The environment refers to the domain in which the LLM operates, such as:
- Mathematical problem-solving
- Coding assistance
- Natural language understanding and reasoning
- Creative writing and dialogue generation
- The environment is defined by the text-based interactions the model undergoes. Unlike physical environments, this is an abstract environment where the model must generate coherent and useful responses.
3. State: The Context of Generated Text
- The state represents the current context in which the model is generating text.
- It includes:
- The prompt provided to the model.
- The text the model has generated so far.
- Any external memory (in some architectures) that provides long-term context.
- Since LLMs generate responses in an autoregressive manner, the state evolves sequentially as new tokens are generated.
4. Action: The Next Token(s) Generated
- The action in RL for LLMs corresponds to selecting and generating the next token(s).
- LLMs typically generate responses using probabilistic sampling, meaning each token is chosen based on learned probability distributions.
- The action space is vast, as models must select from thousands or millions of possible tokens at each step.
5. Reward: Feedback on the Model’s Output
- The reward serves as the primary training signal for the reinforcement learning agent, guiding the model to improve its responses.
- Unlike supervised learning, where models are trained on explicit labeled examples, RL allows feedback to be provided after full sequences are generated.
- Reward signals can be obtained from various sources:
- Human feedback: Humans score responses based on correctness, coherence, and alignment with user intent (e.g., Reinforcement Learning from Human Feedback - RLHF).
- Rule-based evaluation: Mathematical or syntactical rules verify correctness (e.g., in math and code generation).
- AI-generated reward models: A separate model predicts the quality of generated text based on past human preferences.
6. Policy: The Decision-Making Strategy
- The policy represents the strategy the LLM follows to generate responses.
- It defines how the model chooses the next token given the current state.
- There are different types of policies in RL for LLMs:
- Deterministic Policy: Always selects the highest probability token.
- Stochastic Policy: Samples tokens based on learned probability distributions.
- The policy is continuously refined using reward-based optimization techniques such as Proximal Policy Optimization (PPO) or Group Relative Policy Optimization (GRPO).
How Deepseek R1 was trained
Step 1: Reward-Based Training
DeepSeek R1 employs rule-based reward models to reinforce accuracy in math and coding tasks. Unlike human-labeled datasets, these reward models allow for scalable, automated feedback mechanisms that guide the model toward improved logical consistency. The model is continuously rewarded for correct intermediate steps, ensuring it develops a structured reasoning approach. Additionally, an adaptive reward mechanism adjusts based on task complexity, allowing R1 to refine its understanding of more intricate problems. Model weights play a crucial role in this training process, as they are adjusted to optimize performance and accuracy.
Step 2: Cold Start Strategy
To ensure stability, R1 begins training with a small curated dataset, unlike its predecessor DeepSeek-R1-Zero, which relied solely on reinforcement learning. This dataset provides initial labeled examples to help the model establish fundamental reasoning structures before transitioning entirely to reinforcement learning. The cold start data includes carefully selected examples spanning mathematics, programming logic, and general problem-solving, enabling a smoother RL adaptation. This strategy significantly enhances the model's readability and usability in real-world applications.
Step 3: Multi-Stage RL Optimization

DeepSeek R1 undergoes thousands of RL iterations, refining its reasoning techniques through structured feedback loops. The training process is divided into multiple reinforcement learning stages: an initial phase focused on basic problem-solving accuracy, an intermediate phase emphasizing self-correction and logical consistency, and an advanced phase aimed at refining multi-step reasoning and self-verification mechanisms. Additionally, language consistency rewards are integrated to minimize unintended multilingual output blending. The final optimization phase fine-tunes the balance between accuracy, coherence, and efficiency, ensuring a model that performs robustly across various reasoning tasks.
PPO vs. GRPO: Understanding Their Differences and Applications in DeepSeek-R1
What is PPO?
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm that improves upon traditional policy gradient methods. PPO works by constraining policy updates to prevent overly large steps in policy space, which can destabilize training. It achieves this using a clipped objective function, ensuring that updates stay within a certain range to maintain stability while still allowing efficient learning. PPO is widely used in reinforcement learning from human feedback (RLHF) to fine-tune language models, as it balances exploration and exploitation effectively.
What is GRPO?
Group Relative Policy Optimization (GRPO) is a variant of PPO designed to optimize large-scale models efficiently without requiring a critic model. Instead of estimating value functions, GRPO compares a batch of generated responses against each other and assigns rewards based on their relative ranking. This allows GRPO to optimize reinforcement learning using relative scores rather than absolute value estimates, reducing computational overhead and improving scalability.
Application of GRPO in DeepSeek-R1
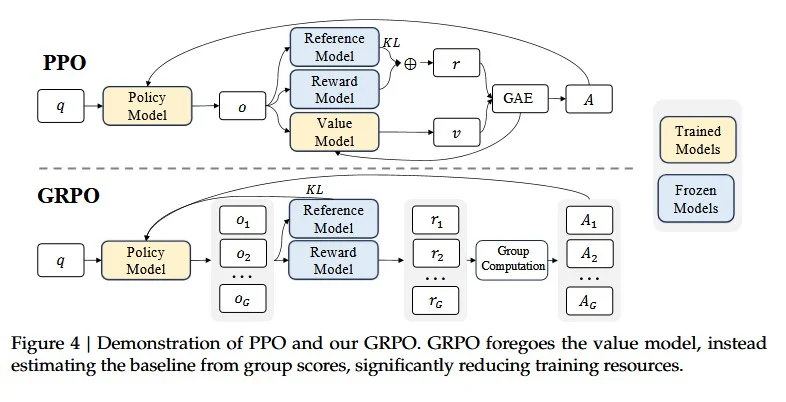
DeepSeek-R1 was trained using GRPO instead of PPO, as it allowed reinforcement learning on a large-scale language model without requiring a critic network. GRPO was particularly useful in DeepSeek-R1 because:
- It streamlined optimization: PPO’s reliance on a critic model would have increased computational costs significantly.
- It leveraged group-based scoring: Instead of relying on absolute rewards, DeepSeek-R1’s training used relative rankings to determine which responses were better.
- It aligned model outputs more effectively: By directly comparing different responses within a batch, DeepSeek-R1 could refine its reasoning capabilities through reinforcement learning
DeepSeek-R1 underwent two stages of reinforcement learning with GRPO:
- DeepSeek-R1-Zero: Applied GRPO directly on a base model without prior supervised fine-tuning (SFT). This resulted in emergent reasoning capabilities but also introduced issues like poor readability and language mixing.
- DeepSeek-R1: Incorporated a small amount of supervised data for a "cold start," followed by another round of GRPO to refine its reasoning skills further.
While PPO is a general-purpose RL algorithm, GRPO was specifically chosen for DeepSeek-R1 due to its efficiency and suitability for large-scale language models. By using grouped relative rankings instead of value function estimation, DeepSeek-R1 managed to achieve strong reasoning capabilities without the overhead of training a critic network.
Insights from DeepSeek V3’s Development
V3’s Role in R1’s Creation
DeepSeek R1 leverages DeepSeek V3 as its foundational model before undergoing reinforcement learning. The reasoning capabilities of R1 were largely cultivated through this iterative refinement process. V3 served as a base with strong linguistic and problem-solving abilities, while R1’s RL training further specialized these capabilities toward structured reasoning tasks. The development of R1 was heavily influenced by the insights gained from V3, particularly in optimizing efficiency, improving logical consistency, and refining decision-making heuristics.
Comparing Training Strategies
- DeepSeek V3: Utilizes supervised fine-tuning and reinforcement learning from human feedback (RLHF). This approach allows it to learn from curated datasets and user preferences, balancing knowledge acquisition with conversational adaptability.
- DeepSeek R1: Relies primarily on RL while incorporating a small amount of supervised data for initial stability. This method proves that high-level reasoning abilities can emerge through reinforcement learning, bypassing the need for extensive human-labeled data.
One of the major insights from V3’s training was that supervised fine-tuning significantly improves general linguistic capabilities but is not always necessary for reasoning-specific tasks. DeepSeek R1 builds on this by demonstrating that reinforcement learning alone can drive sophisticated problem-solving skills, particularly in structured domains like mathematics and programming.
Architectural Improvements
DeepSeek V3 introduced several architectural innovations that contributed to R1’s efficiency and reasoning abilities:
- Mixture-of-Experts (MoE) Model: V3’s MoE architecture optimized computational efficiency by selectively activating relevant model components. This allowed the model to dynamically allocate processing power to complex reasoning tasks, which was further refined in R1.
- Multi-Token Prediction (MTP): V3 employed multi-token prediction to accelerate text generation without compromising accuracy. This technique informed R1’s reasoning processes by enabling it to plan several steps ahead in problem-solving scenarios.
- Enhanced Context Window Management: V3's ability to handle long-context inputs influenced R1's approach to stepwise reasoning, ensuring logical consistency across extended problem-solving sessions.
Lessons from V3’s Post-Training Improvements
DeepSeek V3 underwent several refinements in post-training, including supervised fine-tuning on diverse datasets and iterative reinforcement learning adjustments. These refinements highlighted key principles that were applied to R1:
- Structured Problem-Solving Enhancements: While V3 demonstrated general knowledge comprehension, R1’s development emphasized the need for structured problem-solving methodologies, leading to a focus on logical chain-of-thought reasoning.
- Self-Correction Mechanisms: V3’s iterative learning process provided insights into integrating self-correction mechanisms, allowing R1 to refine its outputs dynamically during reasoning tasks.
- Data Efficiency Strategies: V3’s training revealed that models could achieve high performance with fewer labeled examples when reinforcement learning was effectively applied. This principle was central to R1’s RL-first approach.
By learning from DeepSeek V3’s evolution, DeepSeek R1 was able to push the boundaries of reinforcement learning-driven reasoning, achieving state-of-the-art performance in complex problem-solving tasks while maintaining computational efficiency.
Distillation: Bringing R1’s Reasoning Capabilities to Smaller Models
Transferring Reasoning Abilities to Compact Models
To broaden accessibility and enhance efficiency, R1’s sophisticated reasoning capabilities have been distilled into smaller models of various sizes (7B, 14B, 32B, 70B). This approach ensures computationally efficient deployment without substantially compromising performance. By distilling knowledge from a larger model into a smaller one, we enable high-quality inference at lower resource costs, making advanced reasoning more accessible across different hardware configurations.
Why Distillation Works Better for Small Models
Knowledge distillation has proven to be a highly effective method for transferring reasoning capabilities from large models to smaller ones. This process works by having a smaller model learn from the outputs of a more powerful teacher model, capturing not just final answers but also intermediate reasoning patterns.
- Large Models Discover, Small Models LearnLarge models like R1 naturally discover and refine reasoning patterns due to their extensive parameter space and computational resources. These models can leverage reinforcement learning, supervised fine-tuning, and self-evolutionary techniques to develop powerful reasoning behaviors. Smaller models, on the other hand, benefit by learning from these distilled insights rather than having to independently acquire reasoning abilities from scratch.
- Distillation vs. Reinforcement Learning on Small ModelsStudies indicate that directly training smaller models via reinforcement learning does not yield the same level of reasoning performance as distillation. When reinforcement learning is applied directly to a small model, it struggles to develop the same depth of reasoning patterns that emerge in larger models. In contrast, knowledge distillation allows small models to inherit high-quality reasoning strategies from larger models without the need for extensive reinforcement learning.
- Efficiency Gains Without Performance LossExperiments comparing distilled models with smaller models trained solely through reinforcement learning show that distilled models outperform the latter in reasoning tasks such as AIME 2024, MATH-500, and GPQA-Diamond. For instance, DeepSeek-R1 distilled models (14B and 32B variants) exhibit substantial improvements over baseline models trained with reinforcement learning alone, demonstrating that distilled knowledge from R1 enhances generalization and problem-solving capabilitiesdeepseek-r1. Additionally, incorporating verification and reflection patterns into the distillation process further enhances the reasoning performance of these models.
- Maintaining Structure and Verification MethodsOne of the key aspects of successful distillation is the ability to transfer not just answers but structured reasoning methods, including self-verification and reflection techniques. By embedding these patterns into smaller models, distilled versions of R1 can perform well in structured problem-solving scenarios, even with significantly fewer parameters.
Empirical Performance of Distilled Models
Empirical results support the effectiveness of distillation over standalone training methods:
- DeepSeek-R1-Distill-Qwen-14B achieves 69.7% pass@1 on AIME 2024, outperforming many standalone models.
- DeepSeek-R1-Distill-Qwen-32B achieves 94.3% on MATH-500, rivaling significantly larger models in mathematical reasoning tasks.
- Distilled models perform significantly better on coding and competition-level tasks, bridging the gap between massive models and efficient deployment.
The success of R1’s distillation pipeline underscores the effectiveness of leveraging powerful teacher models to train smaller, highly capable models. Distilled models ensure efficient, high-quality performance across diverse domains by capturing the reasoning structure of large models.
Conclusion
DeepSeek R1 represents a paradigm shift in reinforcement learning-driven reasoning models, proving that logical self-improvement can emerge without supervised fine-tuning. Key takeaways include:
- The reinforcement learning-first approach leads to superior structured reasoning abilities.
- DeepSeek V3 provided the foundation, but R1 independently developed self-reflection and verification mechanisms.
- Distillation ensures these advancements are accessible to smaller models without performance trade-offs.
- Future improvements will explore broader reasoning applications and enhanced long-form understanding.
With the advancement of reinforcement learning in AI reasoning, DeepSeek R1 emerges as a pivotal example of autonomous self-improvement systems.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
