
.png)


_logo%201.svg)


AI Summary
In April 2024, Meta released Llama 3, a large language model touted to be more powerful and diverse than its predecessors, Llama 1 and 2. The family of models has a 70b parameter and a smaller 8b parameter version, both of which have instruction-tuned versions as well. One way Llama 3 is set apart from other large language models, like Claude, Gemini, and GPT, is that Meta has released the model as open source - which means it is available for research and commercial purposes. However, the license is custom and requires that users adhere to specific regulations to avoid misuse.
Let's deep dive into Llama 3. This article will provide a breakdown of what Meta has released about I ts training data so we can better understand how it was trained and what processes were used to build the high-performing LLM.
Llama 3, an overview
Llama 3 is a large language model developed by Meta AI, positioned as a competitor to models like OpenAI's GPT series. It's designed to be a highly capable text-based AI, similar to other large language models, but with notable improvements and unique features.
Llama 3 excels in text generation, conversation, summarization, translation, and more. Its performance is on par with other leading models in the industry, making it a versatile tool for various applications in natural language processing.
Both Llama 3 8B and 70B models outperformed other open-source models like Mistral 7B and Google's Gemma 7B on standard benchmarks like MMLU, ARC, DROP, GPQA, HumanEval, GSM-8K, MATH, AGIEval, and BIG-Bench Hard. These demonstrate strong general capabilities across language understanding, reasoning, coding, and mathematical problem-solving.
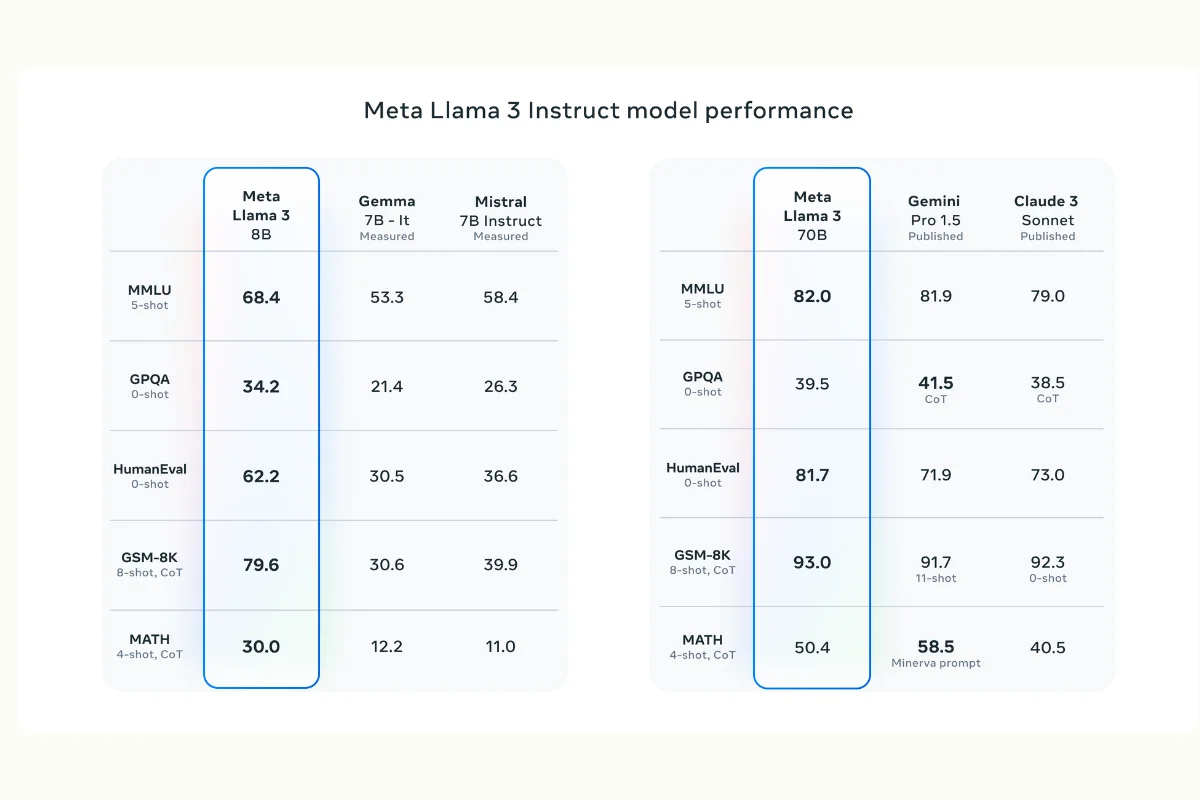
What makes Llama 3 different?
In addition to Llama 3's impressive performance compared to other models, Meta developed a cybersecurity evaluation benchmark to give users confidence that the LLM is trained against adversarial attacks. The benchmark CYBERSECEVAL 2 was built to assess the cybersecurity capabilities and vulnerabilities of Llama 3 and other LLMs. This benchmark includes tests for prompt injection attacks across ten categories to evaluate how the models may be used as potential tools for executing cyber attacks.
Compared to its predecessors, Llama 3 has also been trained on a much larger dataset, the details of which we'll explore in a bit. Llama 3 is multilingual compared to Llama 2, and Meta claims it covers over 30 languages. Llama 3 uses a context length of 8,192 tokens, double the context length of Llama 2.
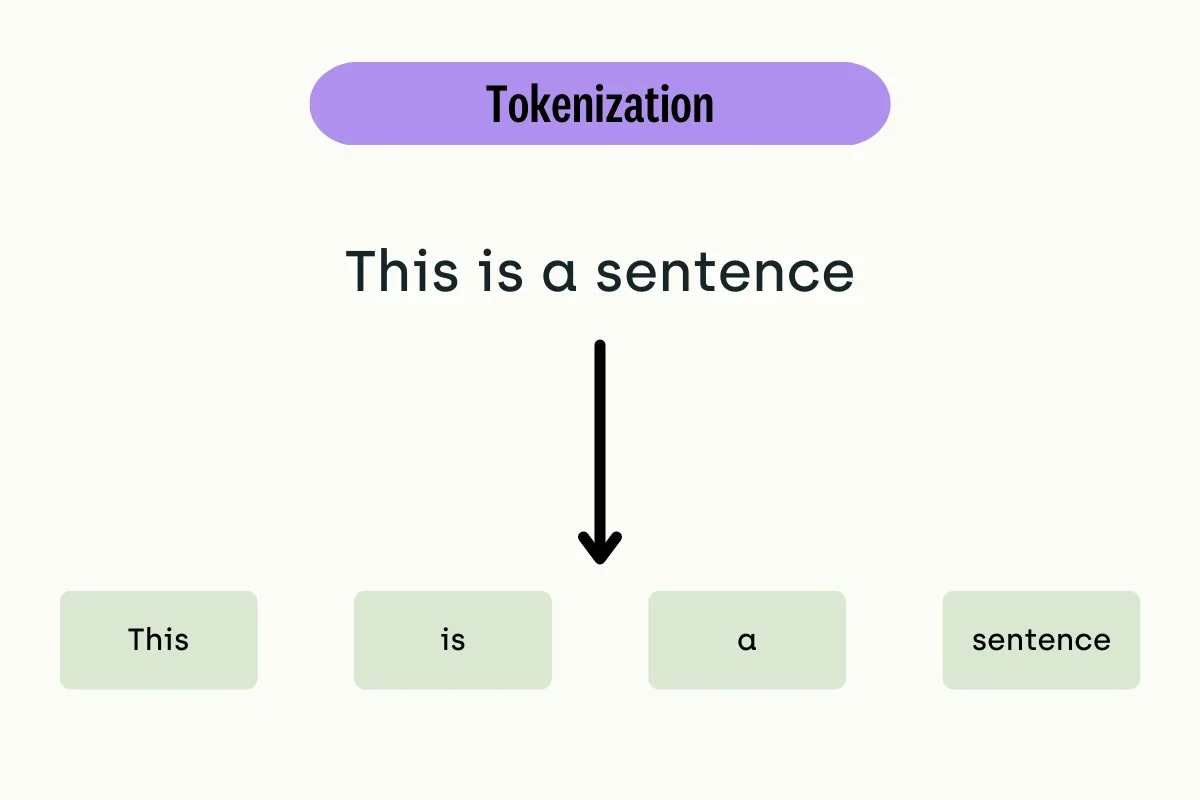
To explain: Tokens are the basic building blocks of text in natural language processing (NLP). A token can be a word, part of a word (like a suffix or prefix), or even punctuation. The term "context tokens" refers explicitly to the tokens that provide context to the model. This context is crucial for the model to generate relevant and coherent text.
How was Llama 3 trained?
Meta took significant steps in training Llama 3. As we mentioned earlier, Llama 3 was trained on more pretraining data. But of course, there's more to training a model than just having more input data than the previous model. As of writing, Meta has not yet released its official paper. However, their blog post and model card give us a better idea of their actions to ensure that Llama 3 performed better than Llama 2 and to be competitive against other models.
We'll update this article when the official paper is released to provide more information and insights, but here's what we've learned for now.
Training dataset: quality and quantity
According to their blog, Llama 3 was pre-trained on over 15 trillion data tokens from publicly available sources, seven times larger than the dataset used to train Llama 2. Meta was also rigorous when it came to pre-processing this large dataset. Meta used heuristic and NSFW filters, semantic deduplication, and text classifiers to predict quality and ensure the model would ingest a high-quality training dataset.
Historically, Meta has been known to focus on and invest heavily in the data quality used to train its models. Data scientists know the adage of Garbage In: Garbage Out, and Meta's researchers have provided papers to support this point further. Meta AI's LIMA paper showed that through thoughtful and strategic data curation, a model can learn from less training data without reinforcement learning or human preference modeling.

Interestingly, Meta used a combination of human annotators and Llama 2 to build this training dataset. Meta discovered that Llama 2 was proficient at identifying high-quality data. Therefore, they leveraged Llama 2 to generate training data for the classifiers used in Llama 3.
Meta also shared that they "performed extensive experiments" to discover the best way to curate the data mix at scale. A series of scaling laws guided them even before training the model so they could find the balance between the optimal data mix and effective training compute. The idea is to use these scaling laws to tailor the training process specifically to the strengths and needs of their models, ensuring that they perform strongly in general and, in specific, real-world scenarios relevant to the users' needs.
Regarding data freshness, Llama 3's 7B and 80B models use different knowledge cutoff dates. The 7B model has a knowledge cutoff from March 2023, while Llama 3's 80B model has a knowledge cutoff from December 2023.
Meta is reportedly developing more capable versions of Llama 3, which will support multiple languages and modalities, exceeding 400 billion parameters.
Data diversity: Multilingual capabilities
Meta has shared that 5% of the pretraining data used on Llama 3 is multilingual and covers 30 languages. This shows that while the model can perform in different languages, it may not be as effective as in English. That being said, the deliberate inclusion of these languages implies future improvements in multilingual capabilities. It can also make it easier for LLM fine-tuners to further train the model in specific languages.
Alignment techniques through human preferences: 10 million human annotations
Meta's model card on Github also states that the fine-tuning data used on Llama 3 included 10 million human-annotated assets on top of publicly available instruction datasets. With or without any AI-assisted labeling, annotating 10 million examples takes a significantly long time to complete.
To achieve Llama 3's performance level, Meta did five things:
- Supervised Fine-tuning (SFT) - Briefly, SFT, involves training the model on examples that have specific desired outputs, where the quality of these examples (curated by humans) directly affects how well the model learns to produce correct and contextually appropriate answers.
- Rejection Sampling - Helps in refining the model’s output by filtering out less desirable responses based on predefined criteria.
- Proximal policy optimization (PPO) - To keep it simple, in PPO, the model learns by trying different actions and seeing which ones lead to the best outcomes, much like learning through trial and error. This is done through gradual changes to make sure the model doesn't change too drastically in between training steps. It also puts a limit on how the model's decision making can change after every training round.
- Direct preference optimization (DPO) - DPO is more explicit. DPO is a more direct approach to using human feedback in model training. It involves optimizing the model's parameters directly based on human preferences between pairs of outputs. Essentially, it's a form of learning that directly targets the alignment of the model's outputs with human judgments.
- Multiple quality assurance iterations - Here, we see a classic data-centric artificial intelligence (DCAI) approach. Iterative refinement in data quality helps correct errors and inconsistencies in the training data. According to Meta, this practice of several iterations has led to great improvements in the Llama 3's quality and performance.

How to leverage Llama 3 for your organization
For organizations wanting to leverage Llama 3, one of the first critical steps to success is testing and validating the model on a simple use case. While evaluating leaderboards is good, creating an evaluation dataset can more concretely provide a first step to understanding how well the model can perform on your unseen data.
From there, you have the following options or examples:
Custom fine-tuning Llama 3 8B
Depending on the specific needs and the available data and resources, consider fine-tuning Llama 3 on your proprietary datasets to align its outputs with your business requirements better. Fine-tuning can be a costly endeavor, depending on a few factors. Primarily, the size of the base model is a huge cost driver, with larger models requiring more computing resources and training time. Fine-tuning may also cost more depending on the required data to fine-tune the model and improve the model's accuracy in more specific tasks and domains.
This is why we recommend fine-tuning the smaller Llama 3 8B model to lessen the costs. Starting with a large dataset for fine-tuning may also be detrimental. Much like Meta's approach to finding the correct data mix, beginning with a small amount of data for fine-tuning and then scaling depending on its initial performance is the most efficient step forward.
For example, we have demonstrated a simple fine-tuning process in one of our previous webinars. We used 800 data points to fine-tune the small Llama 2 7B base model for an AI agent that assists with financial analysis. We wanted our agent to provide consistent, correct answers with a specific, straightforward tone and message format. With the 800 data points, we found that it consistently provided us with the answers we needed. If we were to train it for more complex tasks, we may require more data depending on the task needed.
Llama 2 Fine-tuning Demonstration:

Watch video
Combining Llama 3 with RAG
Combining Llama 3 with retrieval-augmented generation (RAG) can be another approach for organizations looking to implement the LLM. RAG is a technique that enhances the responses of an LLM by incorporating external information. It works by first retrieving relevant documents or data from a large corpus or database and then using this information to inform the model's generation process. This allows the LLM to produce answers that are not only contextually relevant but also factually accurate and up-to-date.
In this case, RAG's effectiveness depends heavily on the quality and relevance of the information sources it accesses. Organizations must ensure these data sources are credible, well-maintained, and aligned with their needs.
Organizations can also combine fine-tuning with RAG by incorporating human feedback and corrections on the outputs of the LLM. For example, if an organization were to evaluate the performance of their RAG and LLM stack using human feedback, they can use the rankings, categorizations, and corrections of human annotators as input data to fine-tune Llama 3 for better alignment.
Llama 3 as a data labeler
If organizations are hesitant to apply language models to their applications, then LLMs like Llama 3 can still be leveraged for training more classical machine learning models. LLMs have been known to help augment the labeling process, making it faster for data scientists to obtain the training datasets they need to build their machine learning model. In Kili Technology's case, GPT's adeptness in natural language understanding has made batch classifying texts 10x faster. Human annotators only need to review the predictions made by the model and correct any mistakes found.
Taking the first step
We hope this article has been helpful and provided you with key insights into the data side of training, fine-tuning, and leveraging a large language model like Llama 3. The organizations we're working with are in different stages of their processes, but eliminating the bottleneck of building and managing the quality of a dataset, whether for training, fine-tuning, evaluating, or monitoring, is the first and one of the most significant steps in developing a genuinely impactful AI application.
Creating a proprietary dataset for any use cases we've shared and discussed can be daunting, even for the most established data science teams. Kili Technology offers an end-to-end solution for building high-quality datasets that can help speed up your development: a cutting-edge tool known for its speed, flexibility, and quality, dedicated project management to ensure smooth delivery, and an extensive network of experts and data labelers for scaling that maintains the highest standards of quality.
Our expert team is happy to discuss your needs and help determine the best strategies for your AI initiatives. We understand the importance of a reliable and well-curated dataset in the success of AI projects, and our services are designed to address these critical needs effectively. Whether you are just beginning to explore the possibilities of AI or are looking to enhance an existing system, our tailored solutions can provide the necessary support to achieve your goals.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
