
.png)


_logo%201.svg)


AI Summary
- A smaller model trained on high-quality open source data can outperform a larger model trained on noisy, poorly curated datasets.
- Major open source datasets for LLMs include RefinedWeb (5T+ tokens), The Pile (800 GB), Red Pajama (1.2T tokens), and FineWeb2 for multilingual coverage.
- Preprocessing pipelines — deduplication, URL filtering, tokenization, contamination detection — determine whether raw data becomes reliable training signal.
- Bias typically originates from underrepresentation in training data, making systematic data governance and human-in-the-loop review essential.
- Kili Technology enables teams to build trustworthy, high-quality datasets for training, fine-tuning, and evaluating LLMs with a free trial.
Large language models have catalyzed transformation across industries. ChatGPT demonstrated emergent capabilities in creative writing; specialized models now power neural information processing systems for healthcare diagnostics, financial risk assessment, and defense intelligence analysis.
The benefits that LLMs like GPT, LLaMA, and Falcon bring promise efficiency, cost-reduction, and collaborative-friendly business environments. Yet, few question the factors that enable large language models to perform exceptionally in text generation and other natural language processing tasks; or to excel in other respective domains they are deployed in.
We know that in LLM development, a deep learning model is only as capable as the datasets it trains on. The processing pipeline—how raw data is collected, filtered, deduplicated, and tokenized—often matters more than architectural innovations. Additionally, the data's annotation quality and curation are key components of a well-performing dataset. Organizations seeking to fine-tune models for domain-specific purposes must prioritize high-quality, well-annotated datasets. Otherwise, they encounter the predictable disappointments of bias, hallucination, and incoherent outputs.
In this article, we’ll explore the importance of datasets that AI companies use to train their models. We will also discuss data pre-processing techniques and the ethical challenges of choosing a large language model dataset for training AI models.
Why Training Datasets Determine Model Performance
The relationship between dataset quality and model capability follows predictable patterns—ones that research has quantified with remarkable precision.
Scaling Laws: The Mathematical Foundation
It's established that model quality improves predictably across multiple orders of magnitude when scaling compute, parameters, and data in concert. It's an empirical measurement showing power-law relationships between training resources and downstream performance.
Later on, the industry refined this understanding, demonstrating that parameter count and dataset size should be scaled proportionally for optimal performance. The implication: a 70-billion-parameter model trained on insufficient data underperforms a 7-billion-parameter model trained on appropriately scaled, high-quality corpora.
These scaling laws provide a means to calculate the ideal number of model parameters and training dataset size for any given compute budget. Every frontier model appears to operate according to its own scaling law parameters, but the underlying principle holds: data curation is pivotally important because most interventions to improve LLM quality are data-related.
Why Data Quality Matters
LLMs consist of multiple hidden layers of deep neural networks that extract and embed patterns from training data sources. If you train with questionable datasets—containing noise, redundancy, bias, or toxic content—the model learns and reproduces those pathologies. Conversely, training with high-quality datasets enables more accurate, coherent, and reliable outputs. As the old adage goes, garbage in: garbage out.
This explains why leading organizations have realized that effective language modeling requires more than state-of-the-art machine learning architectures. Curating and annotating diverse training datasets that fairly represent the model's intended domain is equally critical for deploying neural network AI solutions.
For example, Bloomberg trained a transformer architecture from scratch with decades-worth of carefully curated financial data. The resulting BloombergGPT allows the financial company to empower its clients and perform existing financial-specific NLP tasks faster and with more accuracy. Likewise, HuggingFace has developed a programmer-friendly model StarCode, by training it on code in different programming languages gathered from GitHub.
Common Challenges in Training Data Preparation
Machine learning teams encounter substantial obstacles when preparing datasets for LLM training. Understanding these challenges illuminates why systematic data curation platforms have become essential infrastructure.
Data scarcity in specialized domains creates imbalanced datasets that compromise the model's ability to infer appropriately. Medical imaging, legal reasoning, and industrial quality inspection all suffer from insufficient diverse examples—particularly edge cases that matter most for production reliability.
Scale requirements exceed intuition. OpenAI trained GPT-3 on 45 TB of textual data curated from diverse sources. Managing, filtering, and quality-controlling corpora at this scale requires systematic tooling, not ad-hoc scripts.
Privacy and security constraints multiply complexity. Industries managing sensitive data—healthcare records, financial transactions, classified intelligence—must secure datasets from adversarial threats while complying with regulations like GDPR and HIPAA.
Annotation bottlenecks emerge when fine-tuning LLMs for downstream tasks. Manual annotation requires coordinating large teams of human labelers, managing inter-annotator agreement, and factoring in the inevitable errors that accumulate across millions of labeled examples.
The data requirements for instruction tuning and preference tuning are fundamentally different, necessitating distinct dataset formats, collection strategies, and quality validation approaches. Organizations that treat all training data as interchangeable encounter systematic failures in model behavior.
Modern data labeling platforms like Kili Technology address these challenges by providing automated labeling tools, collaborative annotation workflows, and quality metrics that improve efficiency while reducing human-generated errors. The result: enterprises can embed domain experts throughout the AI development lifecycle—from initial labeling through validation and iteration—ensuring models are built on domain expertise rather than solely on technical assumptions.
Open-Source Datasets Powering Modern LLMs
These open-source datasets are pivotal in training or fine-tuning many LLMs that ML engineers use today. Each represents distinct tradeoffs in scale, quality, domain coverage, and curation methodology.
Pre-Training Corpora
1. Common Crawl
The Common Crawl dataset comprises petabytes of raw web data extracted from billions of web pages, releasing new crawl snapshots monthly. GPT-3, LLaMA, OpenLLaMA, and T5 all incorporated Common Crawl in their pre-training mixtures.
- Dataset: commoncrawl.org
- Research: Language Models from Common Crawl
- HuggingFace: commoncrawl
Quality & reliability insight: Common Crawl is raw web content. For production training, teams build reproducible filtering pipelines encompassing language identification, boilerplate removal, quality scoring, deduplication, and safety filters. Distribution shifts between monthly crawls introduce real risks—SEO spam spikes, toxic content clusters—requiring version-controlled snapshots and human-reviewed audit sets to detect changes before they contaminate training.
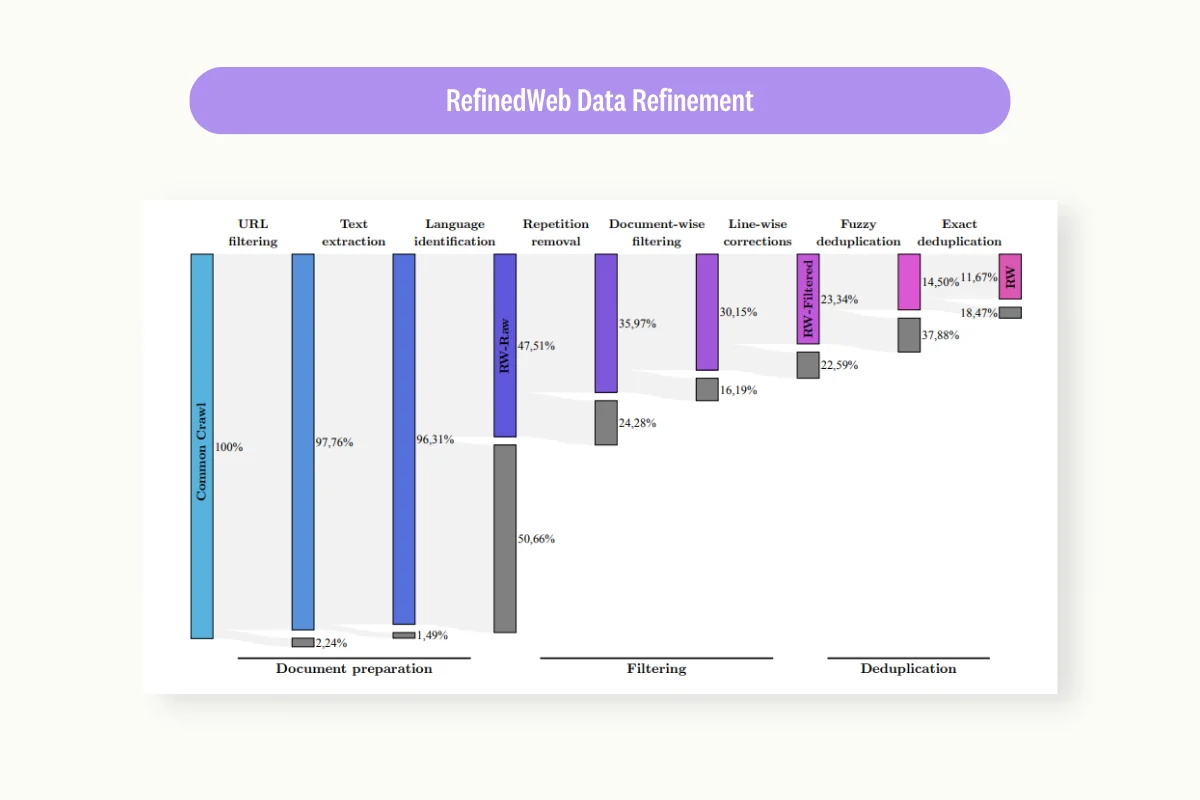
2. RefinedWeb
RefinedWeb represents a massive corpus of deduplicated and filtered tokens derived from Common Crawl. With over 5 trillion tokens (600 billion publicly available), it was developed to train the Falcon-40B model with smaller but higher-quality datasets—demonstrating that careful data curation can substitute for raw scale.
- Dataset: falcon-refinedweb
- Paper: arXiv:2306.01116
Quality & reliability insight: While already filtered and deduplicated, RefinedWeb remains web-derived. Before training, validate behavior on your target domain: run contamination checks against evaluation sets, sample and review high-perplexity outliers, and enforce source-level governance—blocking domains that repeatedly introduce boilerplate, scraped content, or policy-violating text.
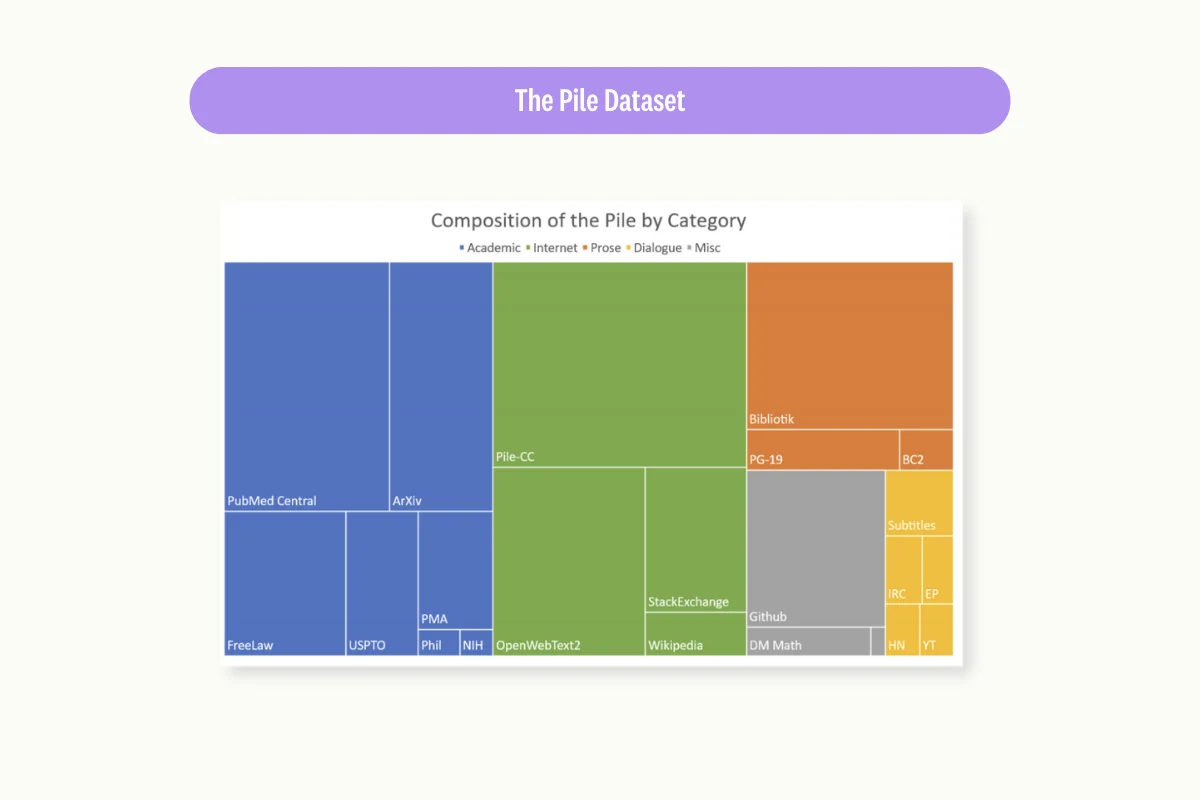
Source: The Pile
3. The Pile
The Pile is an 800 GB corpus designed to enhance model generalization across broader contexts. Curated from 22 diverse datasets—mostly academic and professional sources—it was instrumental in training GPT-Neo, LLaMA, and OPT.
- Dataset: EleutherAI/pile
- Paper: arXiv:2201.07311
- Pipeline: GitHub
Quality & reliability insight: Multi-source mixtures require mixture governance. Track per-component contribution (tokens, domains, dates), deduplicate across components (not only within), and document removals for reproducible training runs. For fine-tuning, consider using only relevant components rather than the full blend.
4. C4
C4 is a 750 GB English corpus derived from Common Crawl using heuristic methods to extract natural language while removing gibberish text. Heavy deduplication improves quality. MPT-7B and T5 were pre-trained on C4.
- Dataset: TensorFlow Datasets
- Paper: T5 Paper, arXiv:1910.10683
- Analysis: C4 Documentation
Quality & reliability insight: C4's "cleaning" is heuristic-based, so quality varies by domain. Modern usage benefits from additional language-ID and encoding checks, stronger boilerplate removal, and explicit evaluation of filtered content—ensuring you don't inadvertently remove underrepresented dialects or valuable domain-specific text.
Source: HuggingFace
5. FineWeb2 (Multilingual Web Pre-Training)
FineWeb2 is a large-scale, multilingual pre-training corpus built with an open curation pipeline designed to adapt across languages. The associated research emphasizes evaluating pipeline choices across languages rather than assuming English-centric filters work everywhere.
- Dataset: HuggingFaceFW/fineweb-2
- Paper: arXiv:2506.20920
- Pipeline: GitHub
Quality & reliability insight: Treat FineWeb2 as a starting point, not production-ready. Teams typically add domain allowlists/blocklists, stronger deduplication, and language-specific quality thresholds. Periodic human review of random samples per language detects systematic issues—boilerplate, template spam, wrong-language text—before they scale into training.
6. FineWeb2-HQ (Model-Based Selection)
FineWeb2-HQ is a quality-filtered subset produced via model-based data selection, released for 20 languages. The research studies how much data can be discarded while maintaining or improving downstream performance—useful for "smaller but better" training mixtures.
- Dataset: epfml/FineWeb2-HQ
- Paper: arXiv:2502.10361
- Code: GitHub
Quality & reliability insight: "HQ" designation doesn't guarantee fitness for your objective. Contamination checks against held-out evaluation sets remain essential, as do targeted human spot checks on safety-sensitive topics, minority languages, and high-perplexity outliers.
7. HPLT 3.0 (Multilingual Pre-Training Resources)
HPLT 3.0 is a large multilingual dataset initiative emphasizing open pipelines and rich metadata/annotations supporting filtering and analysis across many languages.
- Dataset: HPLT/HPLT3.0
- Paper: arXiv:2511.01066
Quality & reliability insight: Prefer datasets shipping rich metadata—language ID confidence, deduplication info, quality signals. These signals enable auditing changes over time and explaining regressions after data refreshes.
8. Red Pajama
Red Pajama is an open-source effort to replicate the LLaMA dataset composition. With 1.2 trillion tokens extracted from Common Crawl, C4, GitHub, books, and other sources, its transparent approach enables training MPT-7B and OpenLLaMA with documented provenance.
- Dataset V1: RedPajama-Data-1T
- Dataset V2: RedPajama-Data-V2
- Paper: arXiv:2411.12372
- Pipeline: GitHub
Quality & reliability insight: RedPajama's value lies in exposed quality signals and metadata—use them. Build curated subsets by combining signals (toxicity filters + quality scores + dedup IDs) and validate with contamination checks, language/domain audits, and human review of high-impact slices.
Domain-Specific and Specialized Corpora
9. StarCoder Data
StarCoder Data is a programming-centric dataset built from 783 GB of code in 86 programming languages, plus 250 billion tokens from GitHub and Jupyter Notebooks. Salesforce CodeGen, StarCoder, and StableCode train on this corpus for program synthesis capabilities.
- Dataset: bigcode/starcoderdata
- Paper: arXiv:2402.19173
- Governance: BigCode
Quality & reliability insight: Code corpora require license and provenance governance. Maintain allowlists of permissive licenses, respect opt-out mechanisms, and validate executability (parse/compile/test) on samples. Run leakage checks against evaluation tasks—popular coding interview problems are highly duplicated across repositories.

Source: Jack Bandy
10. BookCorpus
BookCorpus transformed scraped data from 11,000 unpublished books into a 985-million-word dataset. Originally created to align storylines in books with movie interpretations, it trained RoBERTa, XLNet, and T5.
- Paper: Skip-Thought, arXiv:1506.06726
- Analysis: NeurIPS Datasheet
- Reproduction: GitHub
- Variant: BookCorpusOpen
Quality & reliability insight: BookCorpus has documented distribution, provenance, and documentation issues—modern replicas are community reconstructions. Treat it as high-risk: verify licensing expectations, document which variant you used, remove duplicates aggressively, and perform human review for boilerplate and low-quality artifacts.
11. ROOTS
ROOTS is a 1.6 TB multilingual dataset curated from text in 59 languages to train BLOOM. It uses heavily deduplicated and filtered data from Common Crawl, GitHub Code, and crowdsourced initiatives, with notable emphasis on data governance, ethics, and documentation.
- Paper: arXiv:2303.03915
- Pipeline: GitHub
- Hub: bigscience-data
Quality & reliability insight: ROOTS pioneered systematic data governance practices. Copy its approach: keep data per-source for later removal of problematic components, perform cross-source deduplication, and log inclusion/exclusion decisions. For multilingual training, run language-ID audits—mistakes disproportionately harm low-resource languages.
12. Wikipedia
The Wikipedia dataset provides cleaned text data from Wikipedia across all languages. The English subset contains 19.88 GB of complete articles useful for language modeling tasks. RoBERTa, XLNet, and LLaMA incorporated Wikipedia in pre-training.
- Official dumps: dumps.wikimedia.org
- HuggingFace: wikimedia/wikipedia
- Structured: structured-wikipedia
Quality & reliability insight: Wikipedia is comparatively high-quality but not "neutral ground truth." Treat it as encyclopedic-style data: excellent for factual tone and structure, weaker for dialogue and instructions. Pin dump dates, filter non-prose sections consistently, and consider expert review for sensitive domains (medical/legal) where Wikipedia quality varies by topic.
The Data Preprocessing Pipeline: From Raw Corpora to Training Data
Never assume open-source datasets are optimal for training deep neural networks without preprocessing. These corpora contain redundant, missing, or improperly formatted data that language models cannot process effectively—and worse, that models will learn and reproduce.
The first step in any LLM data preparation pipeline is to extract and collate data from various sources and formats. The entire data processing pipeline can then be achieved through a series of jobs to filter, deduplicate, and tokenize the data into coherent training corpora.
Cleaning and Normalization
Data cleaning removes noisy data and outliers from raw text. ML teams use techniques like statistical filtering and clustering to identify and remove content that doesn't belong. Technology Innovation Institute applied extensive data cleaning—URL filtering, boilerplate removal, deduplication—to create RefinedWeb and train the high-performing Falcon-40B model.
Normalization ensures features in datasets are uniformly structured. When normalizing text data, engineers apply techniques like Unicode normalization, whitespace standardization, and encoding fixes. Research demonstrates that systematic normalization improves downstream task performance measurably.
Tokenization and Vectorization
Tokenization segments text into discrete units—tokens—organized as n-grams that NLP models can process. An n-gram is a contiguous sequence of n items from text, enabling models to group words together and process them as units. This reduces the vocabulary complexity while preserving semantic relationships.
Vectorization assigns each token a unique numerical representation. Common techniques include bag-of-words, Term Frequency–Inverse Document Frequency (TF-IDF), and learned embeddings like Word2Vec. Research shows that applying TF-IDF improved sentiment analysis accuracy compared to naive frequency counting.
Handling Missing and Low-Quality Data
When datasets contain missing values or low-quality documents, teams must decide whether to remove or impute. Removal is straightforward but decreases available training data. Imputation techniques—mean substitution, regression prediction, or ML-driven approaches like missForest and k-nearest neighbor—can preserve data volume while addressing gaps.
For LLM training specifically, the goal is filtering data to retain high-quality documents while removing low-quality content. This requires defining quality heuristics appropriate to your domain: document length, perplexity scores, toxicity classifiers, and domain-relevance signals all contribute to effective filtering.
Data Augmentation
Data augmentation overcomes dataset scarcity by transforming existing data into new, realistic examples. This is particularly valuable for specialized domains where collecting additional data is expensive or impossible.
Text augmentation techniques include back-translation, synonym substitution, and sentence shuffling. For structured data like code, augmentation might involve variable renaming, comment addition/removal, or equivalent reformulations. Synthetic data generation using LLMs themselves has emerged as a powerful augmentation strategy—though it requires careful quality control to avoid amplifying model biases.
Reliability Validation Before Training
Validation extends beyond "cleaning" to ensuring the dataset can be used safely and consistently in training pipelines.
Parse/format validation: Ensure a high percentage of samples parse correctly into your training schema—instruction/response fields present, no empty responses, consistent formatting.
Contamination checks: Measure overlap against evaluation sets using exact and fuzzy matching to avoid inflated benchmark results.
Provenance and licensing review: Track sources and licenses per dataset component, especially when mixing corpora from different origins.
Human spot checks: Sample across languages and domains, having humans label issues—toxicity, nonsense, boilerplate, wrong-language content, factual errors. This catches failure modes that automated filters miss.
Manual inspection of training data remains a key contributor to success in training LLMs. Systematic human review helps identify and fix issues that automated pipelines cannot detect—subtle logical errors in reasoning data, culturally inappropriate content, or domain-specific quality problems.
Ethical Considerations and Data Governance
As LLM deployment becomes prevalent, ethical concerns around model behavior demand attention. Research has documented bias in AI-powered systems—automated captioning performing less accurately for certain accents, image models reproducing demographic stereotypes.
While bias can originate from model architecture, it equally often stems from underrepresentation in training data. European organizations face challenges creating sufficiently large and diverse datasets due to GDPR regulations limiting healthcare data collection. These constraints aren't obstacles to be circumvented—they're signals that data governance must be integral to AI development.
MIT researchers permanently removed a dataset that caused models to describe people using degrading terms. The failure originated in data curation: researchers failed to filter racist and sexist image labels when compiling the corpus. Such incidents demonstrate why systematic data quality control isn't optional—it's foundational to trustworthy AI.
Privacy protection compounds these challenges. Industries managing sensitive data—healthcare records, financial transactions, classified intelligence—must secure the entire ML pipeline from adversarial threats. Apple's prohibition on employee ChatGPT usage underscored concerns about confidential data leakage.
Preventing data breaches requires coordinated effort across policy compliance, security measures, and software development practices. Enterprise-grade platforms provide on-premise deployment options, complete audit trails, and security standards satisfying demanding regulatory environments. When your data is too sensitive for cloud processing, when compliance isn't optional, when security audits are routine—systematic data infrastructure becomes essential.
Many safety issues are fundamentally data issues: toxic content, privacy leaks, and harassment patterns enter through large-scale web collections. Datasets with open filtering pipelines and metadata enable auditing and policy enforcement. But teams should still maintain human-in-the-loop review processes to block recurring patterns and problematic sources before they reach training.
How Datasets Power Fine-Tuning and Evaluation
Open-source datasets contribute not only to pre-training but equally to fine-tuning and evaluation—the stages that transform general language models into production-ready AI systems.
Instruction Fine-Tuning
Pre-trained models cannot infer reliably beyond their training data distribution. Without further fine-tuning, you cannot deploy a general language model like GPT-3 for specialized downstream tasks.
Instruction fine-tuning enables models to learn domain-specific knowledge and follow particular instruction patterns while maintaining linguistic capabilities. Google AI used instruction fine-tuning to develop MedPaLM from PaLM, training on MultiMedQA—over 100,000 questions and answers from sources including the US Medical Licensing Examination, PubMed, and clinical trials.
Training LLMs on proprietary data requires systematic processing, model engineering, setup, testing, and iteration. Using proprietary data ensures sensitive, regulated, or proprietary information stays within organizational infrastructure while enabling customization to match brand voice and response strategies.
Preference Optimization
Beyond instruction following, preference tuning aligns models with human values and quality expectations. This requires datasets capturing human preferences—comparisons between two model responses indicating which is superior, along with the reasoning behind that judgment.
The data requirements for instruction tuning versus preference tuning differ fundamentally. Instruction data pairs user prompts with correct answers; preference data requires comparative judgments that capture human feedback about response quality, safety, and helpfulness.
Evaluation and Benchmarking
Annotated datasets enable objective model evaluation. Before deployment, ML teams compare performance against third-party benchmarks for insight into genuine capability versus benchmark saturation.
HaluEval provides 35,000 question-answer pairs for evaluating hallucination—the phenomenon where models generate incorrect, nonsensical, or unfounded text. BOLD measures fairness across demographic domains. IBEM evaluates mathematical expression recognition.
Using automatic evaluation metrics provides efficient proxy measures of model quality during training. But these proxies require validation: without ground-truth test datasets ensuring models replicate expected behavior, benchmark performance may not translate to production reliability.
Building Enterprise AI with Data-Centric Approaches
The datasets and techniques surveyed here represent the foundation of modern LLM development. But for enterprises building production AI systems, the challenge extends beyond selecting appropriate corpora to orchestrating the entire AI data workflow—from annotation and labeling through validation and model feedback.
Traditional AI development treats domain expertise as a final checkpoint—something to validate after the model is built. This approach systematically underutilizes the most valuable knowledge: the expertise of radiologists, underwriters, quality engineers, and other specialists who understand production realities, not just laboratory conditions.
Effective enterprise AI inverts this model. It enables domain experts to shape AI from the first annotation, embedding their expertise directly into training data. The result: models that understand your domain from the ground up, not through post-hoc corrections.
This requires infrastructure supporting:
Cross-functional collaboration between data science teams, domain experts, and business stakeholders—not as sequential handoffs, but as integrated workflows where expertise flows into training data continuously.
Quality validation throughout the development lifecycle, not as an afterthought. When experts validate early and often, organizations eliminate the costly iteration cycles that plague traditional approaches—achieving faster delivery without sacrificing data quality.
Scalability from pilot to portfolio, supporting hundreds of concurrent users across multiple models and modalities simultaneously. Enterprise AI isn't about building one model; it's about building an AI-capable organization.
Complete traceability for every data decision: who labeled each asset, who reviewed it, what consensus was reached, how quality evolved over time. When models behave unexpectedly in production, traceable data enables diagnosing whether the issue was labeling inconsistency, reviewer disagreement, or insufficient domain expert involvement.
Enterprise-grade security for environments where data breaches aren't an option. On-premise deployment, complete audit trails, and security standards satisfying intelligence agencies and healthcare compliance requirements.
Conclusion: You Reap What You Sow
As harsh as it sounds, a deep learning model is only as good as the datasets it trains on. Likewise, organizations seeking to fine-tune a model for domain-specific purposes must prioritize quality, well-annotated datasets, and avoid annotation errors. Otherwise, they will be disappointed by the inaccuracies the model displays.
Organizations pursuing domain-specific AI must prioritize data quality and systematic annotation workflows. The open-source datasets surveyed here provide foundations, but they require preprocessing, validation, and domain adaptation before deployment.
The path from raw data to production-ready AI systems demands more than ad-hoc scripts and one-time cleaning passes. It requires infrastructure that embeds quality validation throughout the development lifecycle, enables domain experts to contribute their knowledge directly to training data, and maintains the security and auditability that regulated industries demand.
The organizations succeeding with enterprise AI have recognized this reality. They're not just building models—they're building data capabilities that compound across use cases, turning domain expertise into AI that reflects decades of specialized knowledge rather than generic patterns from web crawls.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

