
.png)
AI Summary
In this article, we delve into the critical aspects of data quality and evaluation in the Gemma 2 model, an advanced large language model from Google. Ensuring high data quality is essential for the success of any AI model, influencing both its performance and reliability. We will explore the diverse data sources used for training Gemma 2, the preprocessing techniques applied to maintain data integrity, and the evaluation metrics that assess the model's effectiveness. Readers will gain a comprehensive understanding of how data quality impacts AI outcomes and the ethical considerations involved in deploying such powerful models.
Overview of Gemma 2

Gemma 2 is engineered to excel in numerous text generation tasks such as question answering, summarization, and reasoning. Despite their advanced capabilities, the models are compact enough to be deployed on devices with limited resources, including laptops, desktops, and personal cloud infrastructures. This democratizes access to cutting-edge AI technology, fostering innovation across different fields.
Gemma 2 is available in two distinct sizes to cater to different needs:
- gemma-2-9b: A base model with 9 billion parameters.
- gemma-2-9b-it: An instruction fine-tuned version of the 9 billion parameter model.
- gemma-2-27b: A larger base model with 27 billion parameters.
- gemma-2-27b-it: An instruction fine-tuned version of the 27 billion parameter model.
These models are designed for high performance and efficiency, enabling their use in a broad spectrum of AI applications. By offering both base and instruction-tuned versions, Gemma 2 provides flexibility for various deployment scenarios, ensuring optimal performance, whether for basic tasks or more complex, instruction-specific applications.
Types of Data Used in Gemma 2's Training
According to their model card, the Gemma 2 large language models are trained on extensive datasets comprising various types of text data, which are pivotal for their wide-ranging capabilities:
- Web Documents: A comprehensive collection of English-language web texts exposes the model to diverse linguistic styles, topics, and vocabulary, enhancing its ability to understand and generate a wide array of text.
- Code: Including programming code in the training data enables the model to grasp the syntax and structures of various programming languages, improving its proficiency in generating and comprehending code-related text.
- Mathematics: Mathematical texts help the model develop logical reasoning and symbolic representation skills, essential for addressing mathematical queries and logical problems.
By integrating these diverse data sources, we can expect that Gemma 2 can perform a wide variety of tasks with high accuracy and reliability, demonstrating its broad applicability in different domains.
Struggling with data quality in your large language models?
Our emphasis on customisation, quality, and flexibility allows us to tailor data and workflows to meet your specific needs. Focus on what matters most – improving your model's performance with high-quality data from Kili Technology.
Learn more
Prioritizing safety: Filtering harmful content during data preprocessing
To ensure the integrity and safety of the training data for Gemma 2, Google employs a series of rigorous data preprocessing and filtering techniques. These steps are essential to maintain high data quality, ensuring that the model is trained on ethically sound and reliable data. Here are the key methods used:
CSAM Filtering
One of the most critical filtering processes involves the exclusion of Child Sexual Abuse Material (CSAM). This filtering is rigorously applied at multiple stages in the data preparation process to prevent any harmful and illegal content from being included in the training data.
Sensitive Data Filtering
Automated techniques are used to filter out personal information and other sensitive data from the training sets. This includes personal identifiable information (PII) such as Social Security Numbers and other data that could compromise user privacy and security. By doing so, the models are made safer and more reliable for deployment.
Additional Content Quality and Safety Filters
Beyond CSAM and sensitive data filtering, additional filters are applied based on content quality and safety guidelines. This includes:
- Offensive and Low-Quality Content: Leveraging Google's experience with conversational products like Google Assistant, models are trained to minimize the generation of offensive and low-quality answers.
- Harmful Content: The models are also filtered to prevent the generation of harmful content, such as hate speech, harassment, violence, gore, obscenity, profanity, and dangerous content that could facilitate harmful activities.
Ethical Evaluation and Adversarial Testing
Google's AI Principles guide the overall framework for responsible AI development. This includes:
- Human Rights Impact Assessments: External experts are engaged to conduct human rights impact assessments.
- Feedback from Diverse Users: Feedback from a diverse group of over 1,000 Googlers worldwide helps in automating adversarial testing.
Policies and Practices for Responsible AI Development
Google has established a standardized policy framework for all generative AI products to ensure they do not create harmful content. This framework also emphasizes product inclusion, equity, and product safety, addressing issues such as misinformation, unfair bias, and ensuring that answers are grounded in authoritative, consensus-based facts.
Gemma 2 Post-Training
Supervised Fine-Tuning (SFT)
The first step in post-training is Supervised Fine-Tuning (SFT). This process involves teaching the model using a teacher's guide, where it is trained on a set of example questions and answers or tasks that have been correctly solved by humans. These examples can be both synthetic data, generated by algorithms, and human-generated prompts. By learning from these correctly labeled data sets, the model improves its ability to generate accurate and relevant responses in similar future tasks.
Reinforcement Learning from Human Feedback (RLHF)
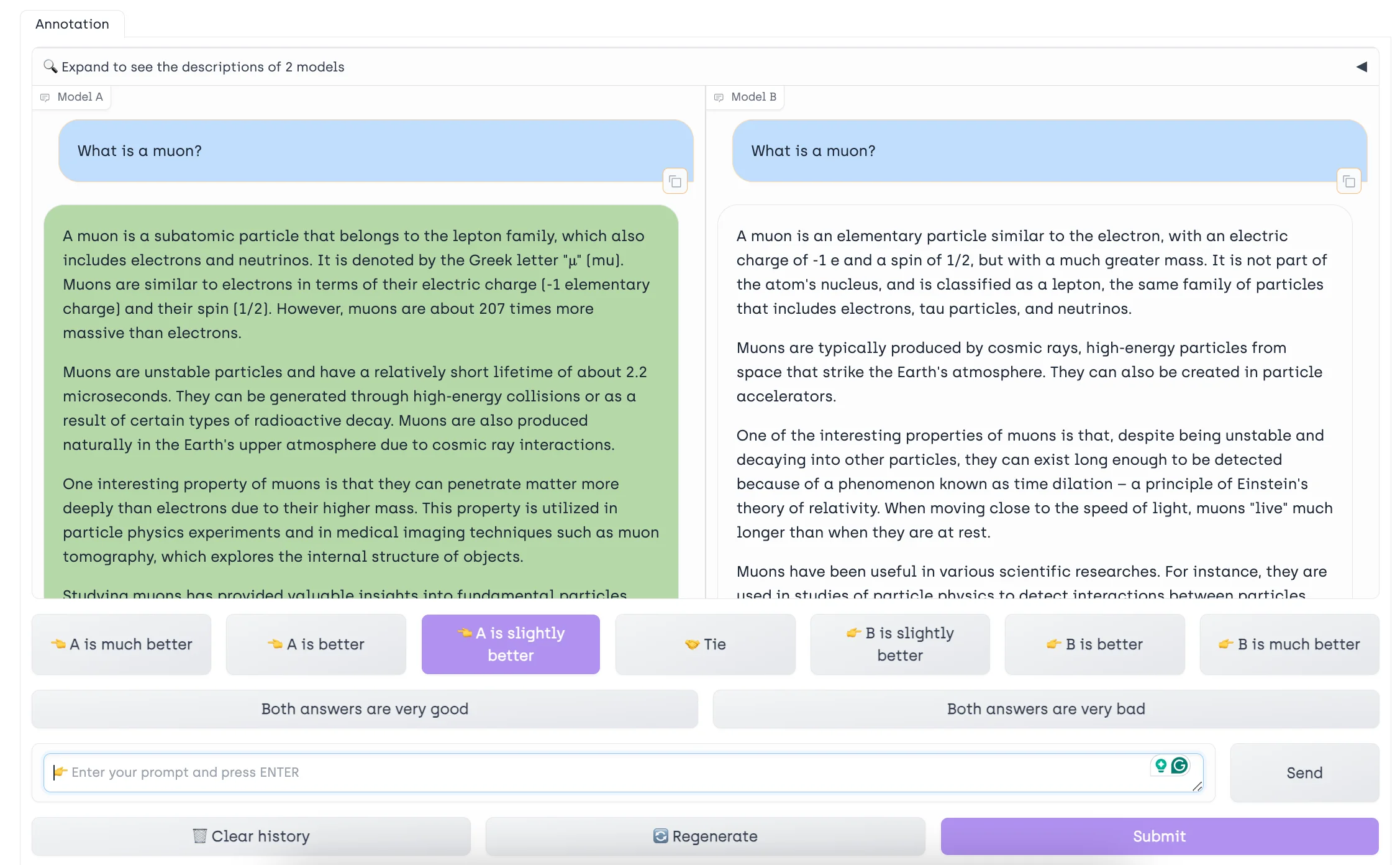
After SFT, the model undergoes Reinforcement Learning from Human Feedback (RLHF). This step is akin to a trial-and-error learning process with human guidance. Once the model provides an answer, human evaluators give feedback on the quality of the response. The model uses this feedback to refine its future outputs, aligning more closely with human preferences and expectations. This continuous feedback loop helps the model adapt and improve over time.
Data Used for Post-Training
The data used in post-training Gemma 2 is diverse and meticulously curated. It includes:
- Synthetic Data: Automatically generated data to simulate various scenarios.
- Real Prompts: Actual user inputs and queries.
- Responses from the Teacher Model: High-quality outputs from a pre-established model.
- Public and Internal Datasets: Sources like LMsYS-chat-1M enrich the model's understanding and capabilities.
Ensuring Data Quality
Maintaining high data quality is paramount. Google employs several filtering techniques to ensure the integrity and safety of the post-training data:
- Toxic Output Filtering: Removing harmful content to prevent the model from learning or generating offensive material.
- Error Correction: Eliminating mistaken self-identification and duplicated examples.
- Factuality and Hallucination Minimization: Including data subsets that improve the model's accuracy and reduce incorrect information.
Google's framework for responsible AI development underpins these efforts, ensuring that the models are trained on data that adheres to ethical standards and safety guidelines. This comprehensive approach to data quality helps in developing robust and reliable AI models capable of performing a wide range of tasks effectively.
The use of knowledge distillation in Gemma 2
In Google's technical paper for the Gemma 2 large language models, they shared the use of knowledge distillation in particular, along with several other techniques to efficiently train these foundation models.
What is knowledge distillation?
Knowledge Distillation is a process where a smaller model (the student) learns from a larger, pre-trained model (the teacher). The student model is trained to mimic the teacher model by minimizing the differences between their outputs. This is achieved by having the student model learn from the probability distributions produced by the teacher model, essentially transferring the knowledge from the larger model to the smaller one.
How did it help improve Gemma 2's performance?
Knowledge Distillation aids in the training of Gemma 2 by enabling the creation of smaller, yet highly efficient models. By learning from the outputs of a larger model, the student model can achieve high performance with fewer parameters and reduced computational resources. This approach allows the distilled models to maintain a high level of accuracy and effectiveness, making them suitable for deployment in resource-constrained environments without significant loss in performance. This process helps in optimizing model size and inference time while preserving the model's capabilities.
Gemma 2's pre-training and post-training evaluations
In Google's technical report, they shared results from evaluating models after the pre-training phase and the post-training phase. Evaluating models, both pre-training and post-training, ensures a comprehensive understanding of their strengths and weaknesses, guiding further improvements and validating their readiness for real-world use.
Pre-training LLM evaluation
The purpose of evaluating models after pre-training is to assess their initial performance and robustness. This evaluation helps in identifying how well the models have learned from the training data and their ability to generalize across different tasks and domains. It provides a baseline measurement of the model's capabilities before any further fine-tuning or optimization is applied.
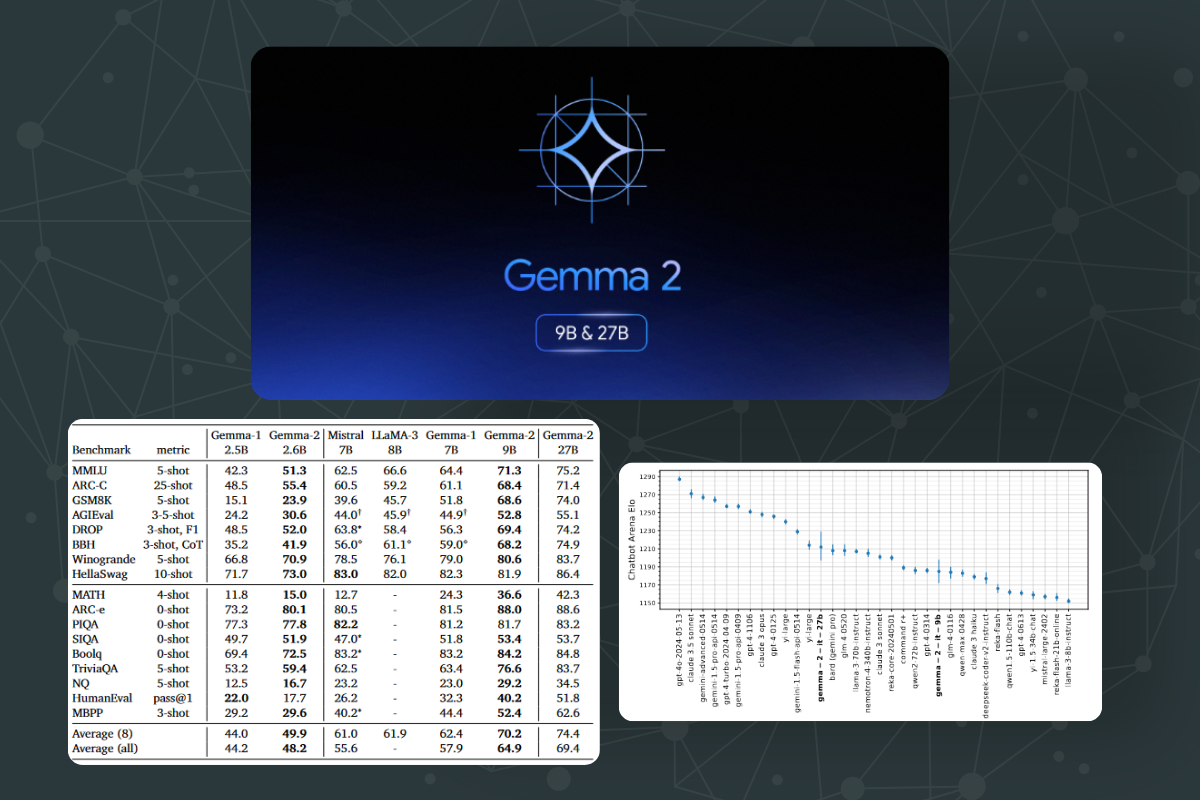
Performance was measured on several academic benchmarks and known LLM evaluation metrics to assess the model's capabilities and robustness.
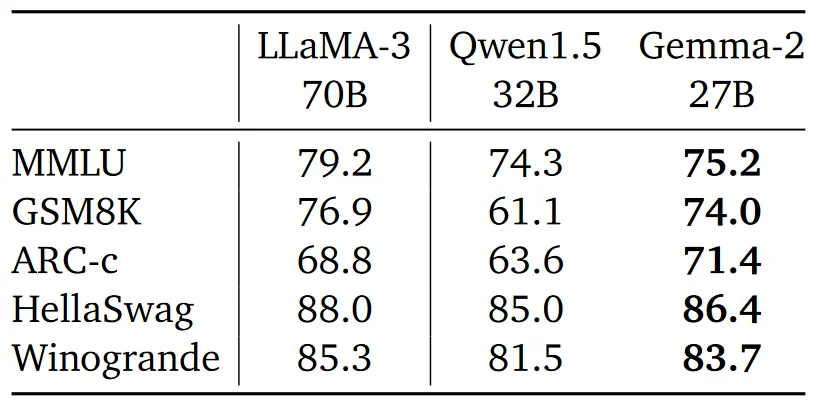
Gemma 2 models showed competitive performance against other leading models such as LLaMA-3 and Qwen1.5. Specifically, the 27B model achieved higher scores on benchmarks like MMLU and GSM8K, indicating strong general performance and robustness.
Google also confirmed that the distilled models performed significantly better than their predecessors. The improvements were particularly notable in terms of efficiency, where smaller models achieved high performance comparable to larger models, thereby confirming the effectiveness of the distillation process.
What is the MMLU Benchmark?
The MMLU (Massive Multitask Language Understanding) benchmark is a comprehensive evaluation tool designed to assess the capabilities of language models across a wide range of subjects and difficulty levels. The benchmark includes approximately 16,000 multiple-choice questions spanning 57 subjects. These subjects cover diverse fields such as STEM (Science, Technology, Engineering, Mathematics), humanities, social sciences, law, ethics, and more.
MMLU can be used to evaluate custom language models by specifying the subjects and the number of shots (examples) for few-shot learning. The overall score ranges from 0 to 1, where 1 indicates perfect performance.
What is the GSM8K benchmark?
The GSM8K (Grade School Math 8K) benchmark is a dataset designed to evaluate the problem-solving capabilities of large language models in the context of grade school math word problems. The dataset consists of 8,500 high-quality, linguistically diverse math word problems created by human problem writers. It is divided into 7,500 training problems and 1,000 test problems.
The dataset is particularly valuable for improving and testing the reasoning skills of language models. Researchers have developed various verification techniques to evaluate the correctness of generated solutions, which have shown promising results in enhancing model performance.
Post-training LLM evaluation
Gemma 2 performed well on various benchmarks in post-training evaluations, including MMLU, ARC-C, and HumanEval.
Gemma 2 IT (Instruction-tuned) models were evaluated through several methods:

- Chatbot Arena Evaluations: These evaluations were conducted on the LMSYS Chatbot Arena platform, where the models were assessed in blind side-by-side evaluations by human raters against other state-of-the-art models. Each model received an Elo score based on these evaluations. High Elo scores indicate strong performance in dynamic conversational contexts, suggesting the model's robustness and versatility.
- Gemma 2 27B model slightly surpassed larger models like Llama3-70B-Instruct and Nemontron-4-340B-Instruct, setting a new state of the art for open-weights models. Gemma 9B also outperformed other models in the same parameter range.
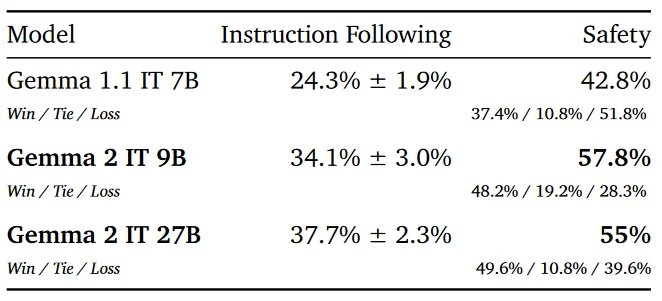
- Human Preference Evaluations: Gemma IT models were evaluated using held-out collections of single-turn prompts focusing on target safety and instruction following. This evaluation used the model gpt4o-2024-05-13 as a base model and measured win rates and preference scores. These assessments focus on how well models follow instructions and generate safe outputs, critical for applications where user safety and adherence to instructions are paramount, such as customer support and educational tools.
- Instruction Following: Gemma 2 27B achieved 37.7% success, while Gemma 2 9B achieved 34.1%.
- Safety: Gemma 2 27B had a safety score of 55%, and Gemma 2 9B scored 57.8%.
- Both models produced safer and more appropriate prompts than GPT4o on held-out safety prompt sets.
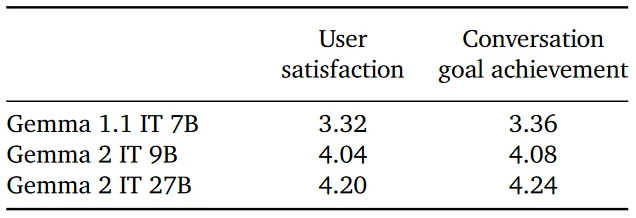
- Human Multi-Turn Evaluations: The multi-turn capabilities of the models were assessed using 500 diverse scenarios. Human raters had conversations with the models to measure various aspects such as brainstorming, making plans, and learning new information. Metrics such as user satisfaction and conversation goal achievement were recorded.
- Measuring user satisfaction and conversation goal achievement in multi-turn scenarios indicates the model's capability to handle complex interactions and maintain engagement over extended conversations, valuable for applications like virtual assistants and chatbots.
- User Satisfaction: Gemma 2 models (both 9B and 27B) received higher satisfaction scores compared to the older Gemma 1.1 7B model.
- Conversation Goal Achievement: Gemma 2 models achieved higher scores, indicating better conversation quality and consistency.
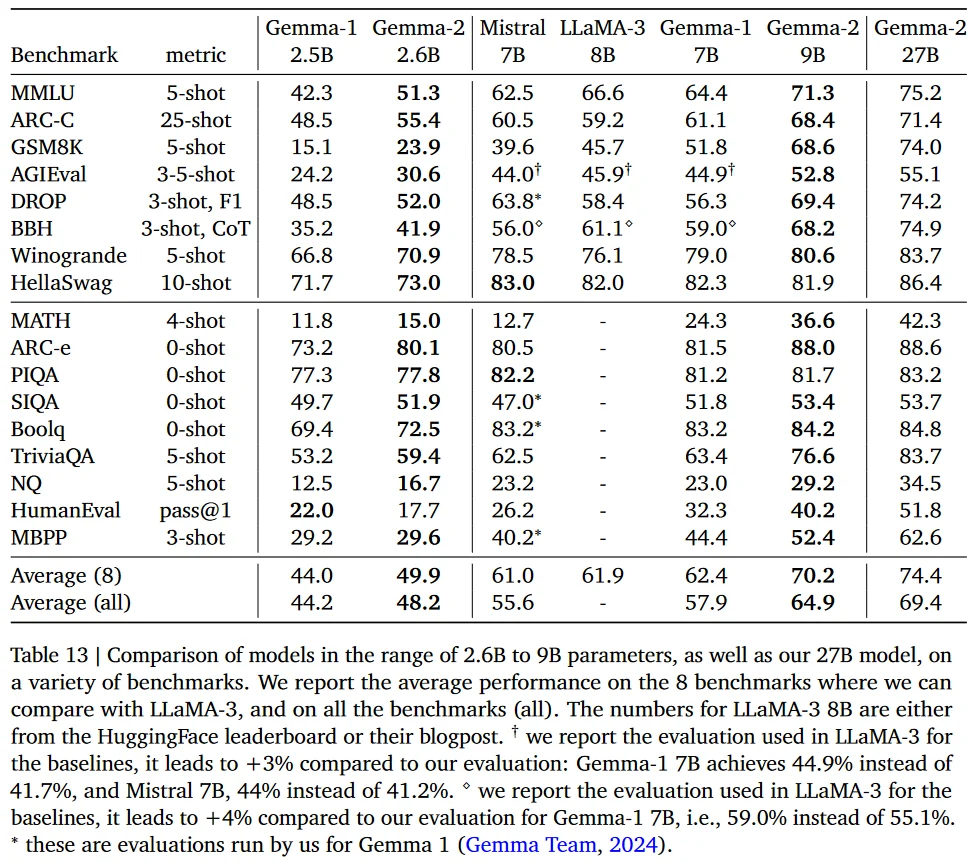
- Standard Benchmarks: The models were also evaluated on few-shot benchmarks using datasets like MMLU and MBPP. These benchmarks compared pre-trained (PT) and instruction fine-tuned (IT) models.
- Improvements in few-shot learning benchmarks highlight the model's ability to generalize from limited examples, a crucial capability for tasks requiring quick adaptation to new topics or minimal training data.
- On few-shot benchmarks, instruction fine-tuning improved the performance of both 9B and 27B models. For instance, the 27B model's MMLU score improved from 75.2 to 76.2, and the MBPP score from 62.6 to 67.4 with instruction fine-tuning.
Overall, these evaluations demonstrate that Gemma 2 IT models are powerful in structured benchmark tests and excel in practical, user-interactive scenarios, making them suitable for a wide range of real-world applications where reliability, safety, and user satisfaction are critical.
Gemma 2's safety and security evaluations
Performance and quality benchmarks are important, but Google shares another layer to their evaluations by putting focus on the safety and security of their large language models.
Google integrated enhanced internal safety processes that span the development workflow, ensuring comprehensive safety measures similar to those used in recent Google AI models.
There's much to explore in Google's Gemma 2 Technical report, but it is this rigorous testing and comprehensive evaluations that ensure that AI models like Gemma 2 are reliable, ethical, and safe for public use.
These evaluations are foundational for integrating AI into various applications responsibly and effectively.
Academic Benchmarks: These benchmarks provide quantitative measures of the model's propensity to generate harmful or biased content. Lower scores in RealToxicity, for instance, indicate less toxic output, which is crucial for maintaining safe and inclusive AI interactions.
External Benchmark Evaluations: These evaluations ensure the model meets public safety and ethical standards, demonstrating transparency and robustness in real-world applications. The detailed performance on public benchmarks affirmed the robustness and transparency of Gemma 2, aligning with industry standards for safe AI development.
Assurance Evaluations: Assurance evaluations are essential to understand and mitigate the extreme risks that AI models might pose. These evaluations focus on specific high-risk capabilities to ensure the model's safe and responsible deployment.
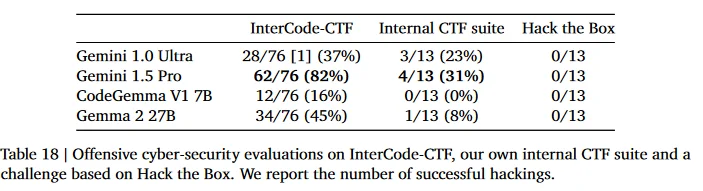
Assurance evaluations for offensive cyber-security, code vulnerability detection, CBRN knowledge, and self-proliferation are critical for understanding and mitigating the extreme risks posed by AI models like Gemma 2 IT. These evaluations help ensure the model is safe, secure, and reliable, preventing potential harm and misuse while promoting responsible deployment in various high-stakes applications.
- CBRN Knowledge: Ensures the model does not spread dangerous misinformation about critical safety domains.
- Offensive Cyber-Security: Tests the model's ability to resist being used for malicious hacking, ensuring it cannot be easily exploited for cyber-attacks.
- Code Vulnerability Detection: Evaluates the model's capacity to identify security flaws, enhancing its use in secure software development.
- Self-Proliferation: Assesses the risk of the model autonomously spreading without control, ensuring it can be safely managed.
- Persuasion: Examines the ethical implications of the model's ability to influence users, preventing misuse in social engineering.
- Charm Offensive: Measures the model's effectiveness in building user trust and rapport, important for applications requiring human-like interaction.
- Money Talks: Evaluates the ethical considerations of the model influencing financial decisions.
- Web of Lies: Ensures the model's responses align with truthfulness and do not propagate misinformation.
Gemma 2's performance across various safety and security evaluations demonstrates a well-balanced combination of robustness, ethical behavior, and controlled capabilities. In academic benchmarks, Gemma 2 showed moderate to strong performance in reducing toxic content and mitigating biases, which is essential for ensuring safe and inclusive interactions. The model's contextual understanding and truthfulness are commendable, although there is room for improvement in generating consistently accurate information. Evaluations in charm offensive and persuasion reveal that Gemma 2 is capable of building positive rapport with users while maintaining ethical standards, minimizing the risk of manipulative or deceptive behavior.
In assurance evaluations, Gemma 2's capabilities in offensive cybersecurity, code vulnerability detection, CBRN knowledge, and self-proliferation highlight the model's limitations and strengths.
While Gemma 2 demonstrated moderate success in cybersecurity challenges, its performance in identifying code vulnerabilities and handling CBRN knowledge was limited, suggesting areas for further enhancement. The evaluations also ensured that Gemma 2 does not possess uncontrolled autonomous replication capabilities, reinforcing the importance of human oversight.
Overall, these comprehensive assessments affirm that Gemma 2 is a safe, reliable, and ethical AI system, suitable for public deployment with a strong focus on minimizing risks and maximizing benefits in real-world applications.
Ensure your models perform at their best with Kili Technology's evaluation reports
We provide advanced and custom evaluation reports to improve the quality and effectiveness of your large language models. Our expert teams and customised workflows are here to address your unique challenges, giving you the insights needed to refine and enhance your models for optimal performance.
Start a POC
The importance of high quality data and robust evaluations combined
Gemma 2 represents a sophisticated, well-evaluated AI model that leverages diverse, high-quality data and rigorous preprocessing and post-training techniques to ensure reliability, safety, and ethical behavior. The development of Gemma 2 and the technical report that Google shared reinforces the value of transparency when releasing foundation models to the public.
The preprocessing techniques employed by Google include rigorous filtering for Child Sexual Abuse Material (CSAM), personal identifiable information (PII), and other sensitive or offensive content. By eliminating such data, Google ensures that the training dataset is free from material that could lead to the generation of harmful or unethical outputs. This proactive filtering is essential for creating an AI model that respects user privacy, adheres to legal standards, and promotes safe and inclusive interactions.
Pre-training and post-training evaluations, including academic benchmarks like MMLU and GSM8K, and practical tests like Chatbot Arena and Human Preference Evaluations, provide a holistic view of the model's capabilities. These evaluations ensure that Gemma 2 not only excels in structured benchmark tests but also performs reliably in dynamic, user-interactive contexts. They also highlight the model's strengths and areas for improvement, guiding further development and optimization.
Balancing performance with safety and ethical considerations is a critical aspect of Gemma 2's development. High performance is necessary for the model to be useful and effective in practical applications, but it must not come at the expense of safety and ethical standards. Google has implemented a dual approach to achieve this balance: using robust evaluation metrics to ensure top-tier performance while simultaneously enforcing ethical guidelines and safety protocols. For instance, offensive cybersecurity evaluations ensure that the model cannot be exploited for malicious activities, while assessments of code vulnerability detection help in identifying potential flaws in software generated or reviewed by the AI. These steps are crucial for fostering trust and compliance in AI technology, making Gemma 2 a reliable tool for both developers and end-users.

_logo%201.svg)




