
.png)


_logo%201.svg)


AI Summary
Introduction
Current state-of-the-art Machine Learning and Deep Learning is based on data. In fact, without large amounts of good data, sophisticated algorithms would probably perform worse than traditional linear statistical methods. As an example, Neural Networks were first proposed in 1944. Still, because of a lack of computational power and ability to process large amounts of data, the field stagnated until the mid-90s in two AI winters.
At this point in time, computing power is instead relatively cheap, and the development of optimized hardware (e.g., GPUs, TPUs, IPUs) and cloud computing made it relatively easy for anyone to train large deep learning models. Most Deep Learning models are open-sourced and packaged in libraries such as Hugging Face transformers, TensorFlow and PyTorch. Therefore, what provides a competitive edge to organizations is the quality of data they can feed into their models (which is not generally available instead to individuals and small organizations).
To try to bridge this gap, throughout the years, different approaches, such as data augmentation and synthetic data, have been developed. Data Augmentation is the process of creating new training data by modifying existing ad-hoc samples. With Synthetic Data, instead, the data is generated without using the training set as a base (which can therefore result in more varied and unexpected results). By 2030, according to a report by Gartner, Synthetic Data is predicted to overshadow Real Data in AI models.

If you want to learn more, additional info is available in our article on data augmentation.
Let’s now dive into what actually constitutes synthetic data.
A Brief Overview Of Synthetic Data
Synthetic data refers to artificially generated data that imitate real-world data. It can be useful when real data is sensitive or confidential or where there is insufficient real data available for analysis. Synthetic data is sometimes used in machine learning and data science applications to train models or test hypotheses.
The usage of synthetic data is advantageous because it enables people and businesses to use data that is almost equivalent to real-world data without violating data privacy rules. Data developed using software and models eliminates the risks of data leakage, corruption, and inaccurate results. It's a cheap alternative to manual data collection that can be used to gather massive volumes of information. Effective artificial intelligence (AI) model training requires a large quantity of data, and synthetic data may be used for this purpose.

Images of a medusa and of an astronaut, created by MidJourney
Importance of Synthetic Data in Machine Learning
Synthetic data plays an important role in machine learning by providing additional data to train models. Synthetic data can help overcome issues with data privacy and availability and also allows for more diverse and complex datasets to be generated. In some cases, this can lead to more accurate and robust machine learning models. Here are some reasons synthetic data is crucial in machine learning:
Data Privacy
Synthetic data can be used as an alternative to real data when privacy concerns arise. For example, healthcare data containing sensitive patient information can be replaced with synthetic data to protect patient privacy while allowing machine learning algorithms to be trained.
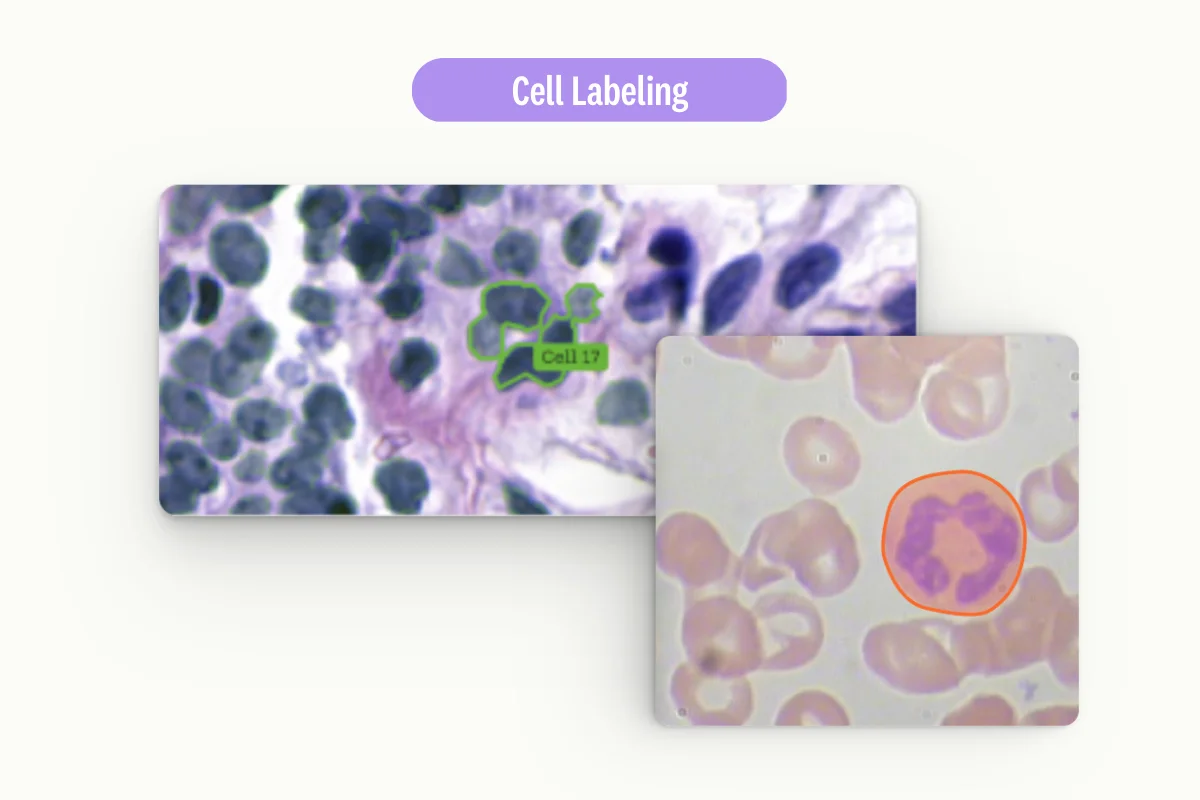
Data Scarcity
Sometimes, there may be insufficient actual data to train an accurate machine-learning model. Synthetic data can augment the limited genuine data, allowing for more comprehensive and accurate models.
Cost-Effectiveness
Synthetic data can be generated at a lower cost than collecting and labeling real data, making it a more cost-effective solution for training machine learning models. In the banking industry, synthetic data can be used to train machine learning models to detect fraudulent transactions. Synthetic data can mimic fraudulent behaviors, allowing for more accurate detection and prevention of fraud.
“The global synthetic data generation market size garnered USD 123.3 million in 2021 and is expected to expand at a compound annual growth rate (CAGR) of 34.8% from 2022 to 2030. An uptick in synthetic data generation following the rising penetration of Artificial Intelligence (AI) has spurred the industry’s growth. For Instance, in August 2020, the White House reportedly announced an infusion of USD 1 billion in AI and quantum computing. Demand for data has become pronounced with a growing footfall of connected devices and IoT, further expediting the need for synthetic data to generate on-demand data. Industry players are expected to seek synthetic data to address the gap in data provision.”
Grand View Research
Synthetic data is becoming increasingly important in machine learning, allowing for more cost-effective models.
What We'll Cover on Synthetic Data
The objective of this blog post is to demonstrate how synthetic data can be applied to machine learning, as well as to outline the pros and cons of this approach. We will mainly focus on text and image data since they’re two of the most common data types synthetically generated. For this reason, we won’t tackle other existing approaches, notably enabling to augment tabular and other unstructured formats (e.g., audio, video).
For text, synthetic data generation can be used in tasks such as summarizing key points from articles/books, paraphrasing sentences without altering their meaning, etc. For images, synthetic data can provide more variation from learned characteristics. For example, we could generate faces of people that don’t exist in reality by providing our model with many images of real people.

Digital painting of a futuristic city created by an AI
Synthetic Data for Machine Learning: How to Generate it?
In the case of structured data, one of the most traditional approaches to generating synthetic data is to fit the real data available for distribution using techniques such as the Monte Carlo method (which uses repeated sampling to create variations of the original data). Although nowadays, synthetic data can be generated with several methods.
Generative models
Generative models are a type of technique used to create synthetic data for machine learning. They work by learning the underlying distribution of the input data and generating new samples that closely resemble the real data. In the past, generative models used to create synthetic data included:
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a type of machine learning algorithm that can create synthetic data by learning to generate new examples that look similar to a given dataset. They consist of two neural networks working in opposition - the generator and the discriminator. The generator creates new data samples based on random inputs, while the discriminator tries to distinguish between real and fake data. As the generator improves, it becomes harder for the discriminator to differentiate between the two, resulting in more realistic synthetic data.
Autoencoders (VAEs)
VAEs are constituted by an encoder, a decoder, and a loss function. The encoder's job is to compress our input data into a lower dimensional space while still trying to preserve as much as possible of the information. Additionally, throughout the training process, the encoding distributions are regularized to avoid overfitting the input data using the negative log-likelihood as a loss function. For this reason, the output of the Encoder is commonly referred to as latent space or bottleneck. At this point, the latent space is fed into the decoder, which then tries to reconstruct the input data as much as possible. Following this mechanism, VAEs are trained to understand just the key components of the input data and then generate new samples from them, which by design will be similar to the original data but never the same. VAEs are, in fact, probabilistic models, and each latent-space attribute is represented by a probability distribution rather than a single value (like in the case of a Vanilla Autoencoder model).
Diffusion models
Diffusion Models are designed to corrupt the training data by adding Gaussian noise and then understand how to undo the noising procedure. In the case of a Diffusion Model, a fixed Markov chain is used as the latent variable model.
Large Language Models
Large Language models (LLMs) are a special form of Transformer-based architecture focused on language understanding and generation. As VAEs, also transformers use an encoder-decoder paradigm but also use a self-attention-based mechanism to determine which parts of text are relevant or not for the model to learn. Some examples of Large Language Models are GPT-4, LaMDA, and PaLM.
Learn More
Did you know that Large Language Models such as ChatGPT and GPT can be used to reduce your data labeling time by 50%? Or that they can be leveraged for asset creation or QA engineering? Enroll in our on-demand session to explore the potential of these models for data labeling.

Simulation
Physical simulation is a method used to generate synthetic data for machine learning. It involves modeling real-world systems and using mathematical or physical simulations to generate artificial yet realistic data points. Some examples of use cases for synthetic machine learning data generated by physical simulation include the following.
Autonomous vehicle simulation and training
Synthetic data can be used to train autonomous vehicle systems in various scenarios, such as avoiding obstacles or navigating complex environments.
Medical imaging and diagnosis
Synthetic data can be used to simulate medical conditions and generate realistic images for training and validation of machine learning models used for diagnosis.
Robotics
Synthetic data can simulate robotic systems and generate data for training machine learning models for control and navigation.
Applications of Synthetic Data in Machine Learning
Increase domain coverage
One way to improve the training of models is by using synthetic data to supplement existing real datasets. Synthetic data is typically used to fill in gaps in the data distribution that may not be well-represented in the real dataset, to reduce dataset bias.
Privacy preservation
Using synthetic data can help resolve privacy or legal issues that make using real data impossible or prohibitively difficult. This is especially relevant in certain fields, including Healthcare, where synthetic data can be used for just medical imaging and also medical reports.
Overcoming Data Scarcity
Healthcare and medical imagery
Concerns related to patients’ data privacy, plus the rarity of certain conditions, contribute to data scarcity in this field. Synthetic data can help train models for medical diagnosis, treatment planning, and drug discovery.
Autonomous vehicles and robotics
Autonomous systems training requires vast amounts of diverse data to ensure safe operation in various conditions. Synthetic data can provide valuable information for training robotic systems, path planning, and computer vision.
Rare events prediction
In fields like fraud detection, natural disaster prediction, and equipment failure analysis, the rarity of the events makes it challenging to collect enough data. Synthetic data can be used to train models to recognize these rare occurrences.
Finance and economics
Financial data are often proprietary, confidential, and subject to regulatory constraints. Synthetic data can help train models for risk analysis, credit scoring, and market predictions without compromising sensitive information.
Privacy-sensitive applications
In domains such as surveillance, cybersecurity, and biometrics, privacy concerns make data collection and sharing challenging. Synthetic data can be used for training models while protecting the privacy of individuals.
Earth and climate sciences
Data scarcity in remote sensing, weather forecasting, and geological analysis can limit the effectiveness of machine learning models. Synthetic data can help improve these models by providing additional training data.
Cultural Heritage and Archaeology
High-quality data in these fields is often limited due to the rarity of artifacts and the delicate nature of preservation. Synthetic data can help train models to recognize and analyze historical objects or structures.

Wildlife Conservation and Ecology
Monitoring endangered species and understanding their habitats can be challenging due to their scarcity and remote locations. Synthetic data can help train models for species recognition and habitat analysis.
Materials science
Experimental data in this field can be expensive and time-consuming to generate. Synthetic data can help train models for material property prediction and materials discovery.
Astrophysics and space exploration
The vastness of space and the limitations of observational technology can lead to data scarcity. Synthetic data can help train models for galaxy classification, exoplanet detection, and other astronomical applications.
Edge Case Testing and Robustness
As Artificial Intelligence becomes increasingly embedded across different industry sectors, it is now being applied not just for optimization tasks but also in high-security and risk applications. As a result of this, through examination of any possible input data, edge cases must be carefully examined.
Edge cases constitute a series of infrequent and unlikely events that a model might present during its lifespan once deployed. Because of the sporadicity of these kinds of events, they can then be quite difficult to capture in the real world in all possible variations. If faced with these kinds of situations, using synthetic data could then result in a perfect match to complement our training data.
For example, when implementing a self-driving car model, it can be quite easy to gather lots of driving recordings in everyday life situations. However, it might be extremely difficult to get data during abnormal activities (e.g., operating close to tornados, high floods, low luminosity, etc.). Especially in the case of open-ended problems such as driving scenarios, edge cases might, in fact, not be just a small part of the possible outcomes but actually represent a good part of the spectrum of possible outcomes (therefore creating a distribution with very long tails).
To equip our model to react promptly also in these sorts of scenarios, we could then either use generative AI techniques or implement physics simulations to cover all these edge cases (in the same way as test-driven development is used to ensure good code quality). Finally, when working with synthetic data, it can be crucial to create automatic data quality checks to flag anomalies in the generated data for humans to review can be really important. Taking this approach would then result in highly robust models able to perform adequately in any sort of environment.
To recap, Synthetic Data can be a really powerful tool in the Data Science toolkit as it can be used to complement and enhance our own sets of data. Although, as Uncle Ben always said, “With great power comes great responsibility,” and therefore, misuse of Synthetic Data can potentially lead to some possible drawbacks.
Cons of Using Synthetic Data in Machine Learning
While synthetic data has gained some attention as a solution to the scarcity of real-world data, it's essential to be aware of its potential limitations. Here are some cons of using synthetic data in machine learning:
To start with, synthetic data lacks realism and accuracy compared to real-world data, resulting in models that are not representative of the real world.
Additionally, there is a domain transfer problem, meaning the synthetic data may not accurately reflect the characteristics of the data in the target domain, which can lead to models with poor generalization performance.
Generating high-quality synthetic data can be challenging, depending on the data generation techniques. Poorly generated synthetic data can lead to overfitting, where the model performs well on the training data but fails to generalize to new data.
Synthetic data can also lead to a lack of rare events in the sample data generated, deprecating the model’s efficiency. Indeed, this lack of rare events during the model’s training stage will likely result in a lack of performance in the production stage.
Furthermore, the limited applicability of synthetic data in certain domains makes it unsuitable for some use cases. Moreover, ethical considerations surrounding the use of synthetic data cannot be ignored, such as the potential biases that synthetic data generation techniques could introduce.
Contrary to what one could have assumed, synthetic data doesn’t always create a more balanced and unbiased dataset, leading to more accurate machine-learning algorithms. It can also be biased, leading to inaccurate predictions and models.
Although synthetic data can be useful in certain cases, it's important to know its ethical and qualitative potential drawbacks. Due to its inherent limitations, it is crucial to consider the characteristics of the target domain, the quality of the synthetic data, and ethical considerations before choosing to use synthetic data.

In light of the potential drawbacks associated with synthetic data mentioned above, wise machine learning engineers would be well-inspired to prefer a small but very well-labeled dataset over a larger yet less qualitative dataset for training their model.
Real-World Examples of Synthetic Data Usage
Synthetic data has several use cases in various industries, and here are some real-world examples.
Autonomous vehicle simulation and training is where synthetic data has proved effective. The use of synthetic data enables the creation of a diverse range of virtual scenarios, allowing autonomous vehicles to be trained in a controlled environment. The use of synthetic data in training allows for the testing of autonomous vehicles in dangerous or rare scenarios that are unlikely to occur in real-world driving.
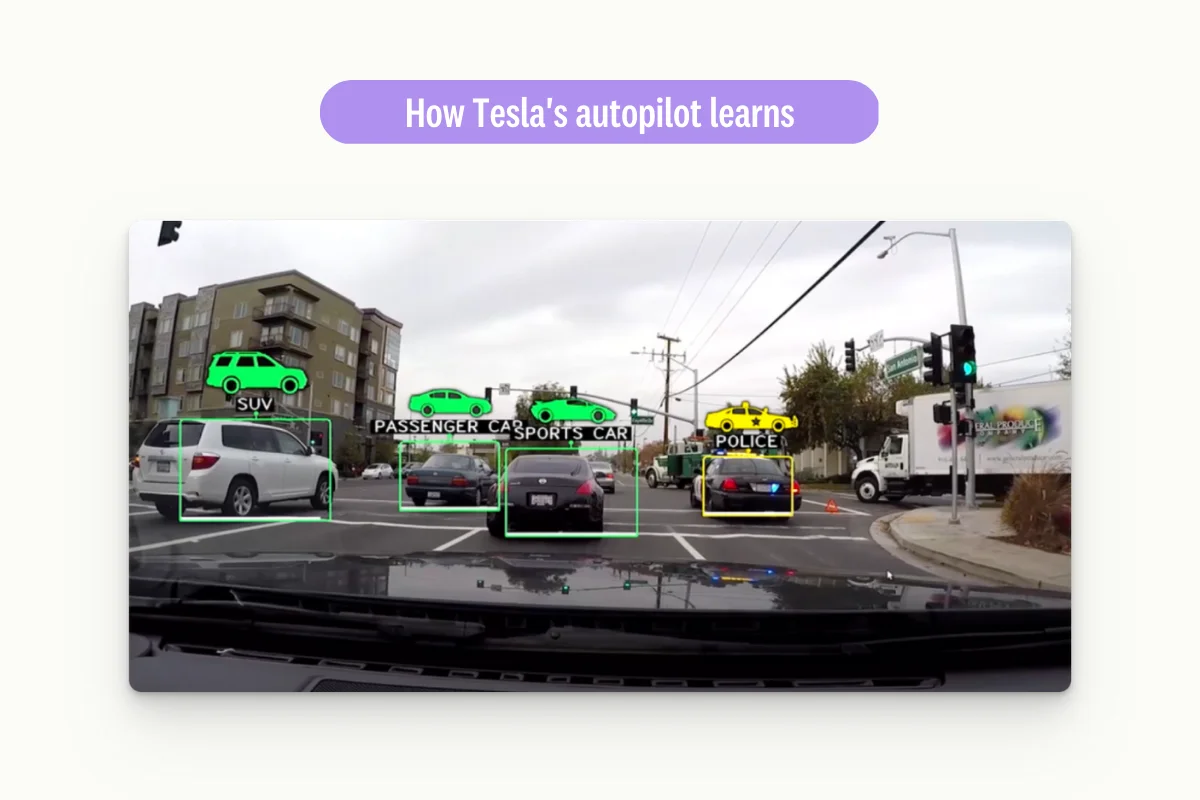
Another example of synthetic data usage is financial fraud detection. By generating synthetic data, machine learning algorithms can be trained to identify patterns of fraudulent behavior, and this can help in the detection and prevention of financial fraud. Synthetic data is particularly useful in this domain, as it allows for creating large datasets that contain diverse examples of fraudulent behavior.
In medical imaging and diagnosis, synthetic data augment the limited real-world data available. The use of synthetic data in this context allows for the training of machine learning models to recognize and diagnose rare or complex medical conditions that are difficult to identify in real-world data.
In summary, synthetic data has a range of real-world applications, and its versatility makes it an increasingly popular tool in several industries. From training autonomous vehicles to financial fraud detection and medical imaging, synthetic data provides a valuable solution to many machine-learning data problems across different fields.
FAQ on Synthetic Data and Data Labeling
When should we use it in our ML Pipeline?
Once created, synthetic data can then be incorporated with existing training sets. The synthetic data should, in fact, go through all the same preprocessing steps used for the rest of the pre-existing training data to ensure they both follow exactly the same properties (e.g., image size, normalization, etc.).
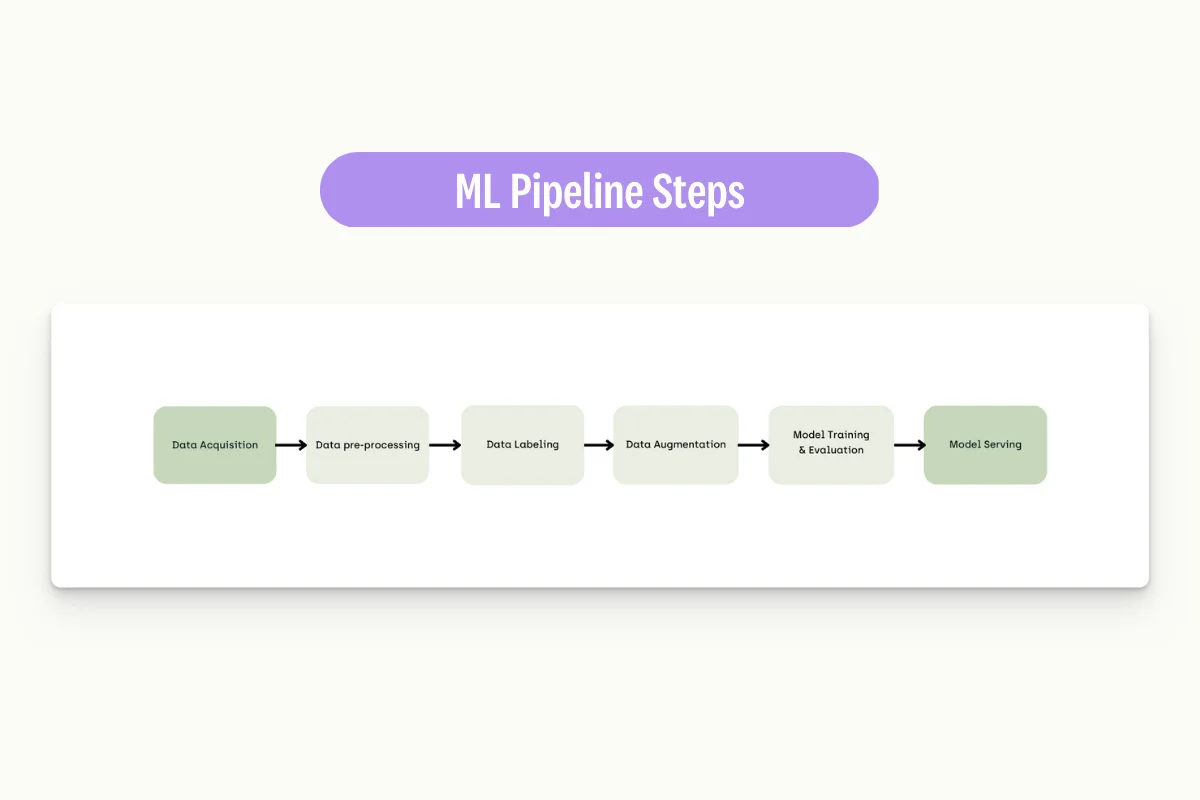
How will it impact the volume (increase/decrease/zero) of annotations needed?
In the same way, the original training dataset had to go through a data labeling process, and synthetic data would have to be accurately annotated.
The annotation process can, of course, be aided by using large pre-trained models. However, validation from subject matter experts is still vital to ensure good data quality levels can be met and the data can be used to create the best model possible.
Moreover, any model trained on synthetic data must be evaluated against real data. For those looking for a solution to streamline their data labeling experience, Kili Technology might be exactly what you are looking for. Kili offers, in fact, a user-friendly, user interface-based data annotation platform that integrates with most common data lifecycle workflows and platforms.
Will it help us create test data?
The use of synthetic data in a test set should be carefully evaluated as synthetic data is, in the first place, created by summarizing and varying information stored in the data used to train your generative models. Using synthetic data as part of a test set could result in possible data leakage (spilling training data information in the test set, making the two not independent of each other). The presence of data leakage would then result in overfitting and enhanced performance during training times at the expense of worse results during inference.
Is synthetic data fake data?
Synthetic Data is not fake data. Synthetic data is, in fact, designed to be a realistic representation of the real-world environment and not to provide misleading information. For example, if we train a generative model to create images of dogs, we would expect to get as outputs new variations of dog images but not images of dolphins, giraffes, etc.
What is the difference between synthetic data vs. real data?
The key difference between synthetic and real data is that synthetic data is algorithm generated and derived from real data. Real data is instead generated from some form of computer external event (e.g., human interaction, weather updates, etc.), which is then ingested and processed by a computer system.
A small amount of real data is mandatory to evaluate the models in realistic operational conditions.
Synthetic Data: Final Thoughts
Overall, synthetic data can be an incredible tool to make complex AI application development more accessible to everyone and preserve the privacy of individuals. At the same time, it is always important to keep a human in the loop to assess the realism of the generated data and strike a good balance between generating images too similar to the original input (therefore risking to overfit) and creating unrealistic data.
According to Gartner research, about 60% of the data used to power AI projects will be synthetically generated by 2024. Further advancements in technologies, such as diffusion-based models and transformers, could significantly power this leap.
Given this scenario, being able to master synthetic data generation could not only results in a decrease in the costs of data generation but also provide, in the long term, a real edge against competitors.
Learn More
Interested in speeding up your data labeling? Make sure to check out our webinar on how to slash your data labeling time in half using ChatGPT! Access your on-demand session now.
Resources
Books and Papers
- "Generative Adversarial Networks" by Ian Goodfellow et al.
- "Auto-Encoding Variational Bayes" by Diederik P. Kingma and Max Welling
- "Deep Learning" by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
- "Artificial Intelligence: A Modern Approach" by Stuart Russell and Peter Norvig
Online Articles and Tutorials
- NVIDIA Developer Blog: Introduction to GANs
- TensorFlow: Generating Images with Variational Autoencoders
- Medium: An Introduction to Synthetic Data
- Python Data Science Handbook: In-Depth: Decision Trees and Random Forests
GitHub Repositories
- NVIDIA StyleGAN2: High-quality image synthesis using GANs
- TextGAN: GAN-based text generation framework
- SDV: Synthetic Data Generation toolkit
- Pyro: Deep universal probabilistic programming with Python and PyTorch
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

