
.png)


_logo%201.svg)


AI Summary
- Microsoft Phi-3 includes phi-3-mini at 3.8B, phi-3-small at 7B, and phi-3-medium at 14B parameters, with phi-3-medium consistently outscoring GPT-3.5 on MMLU, HellaSwag, and GSM-8K.
- Training data combines heavily filtered web content with textbook-like synthetic data generated by larger models and reviewed by researchers for clarity.
- The data optimal regime prioritizes data quality and reasoning density over raw token count, challenging traditional scaling assumptions for small models.
- Phi-3-mini uses a two-phase initial training strategy that gradually increases data complexity to specialize the model across reasoning, code, and general knowledge.
- Compact, on-device performance opens new deployment surfaces for capable language AI without depending on cloud inference infrastructure.
Microsoft Phi-3 is a family of groundbreaking small language models (SLMs) developed by Microsoft. It is notable for its ability to operate efficiently on mobile devices while providing performance comparable to a large language model like GPT-3.5. These models represent a significant advancement in artificial intelligence (AI) and natural language processing (NLP), combining compact size with high capability, making it accessible for various practical applications.
In this article, we're doing a deep dive into these small language models, understand how they're trained, their datasets, and see what we can learn from their technical paper.
Phi -3 in action on an iPhone. Source: Phi-3's technical paper.
Overview of Microsoft Phi-3
Microsoft Phi-3 includes variants such as phi-3-mini (3.8B parameters), phi-3-small (7B parameters), and phi-3-medium (14B parameters). These capable small language models are designed to deliver robust performance across different benchmarks, rivaling popular large language models despite their reduced size. Phi-3-mini, in particular, stands out for its ability to run locally on devices like modern smartphones.
How the Phi-3 small language models perform
Despite their compact size, which enables deployment on devices like smartphones, Microsoft's Phi-3 language models demonstrate impressive reasoning and language understanding capabilities that are competitive with and often exceed those of much larger open-source and proprietary models. The strong benchmark results suggest Phi-3 punches well above its weight class.
The key benchmarks used to compare Microsoft's Phi-3 models with other competing models like Mistral and Llama include a variety of academic and standardized tests that measure different aspects of language understanding, reasoning, and performance. Here are the primary benchmarks mentioned in the Phi-3 Technical Report:
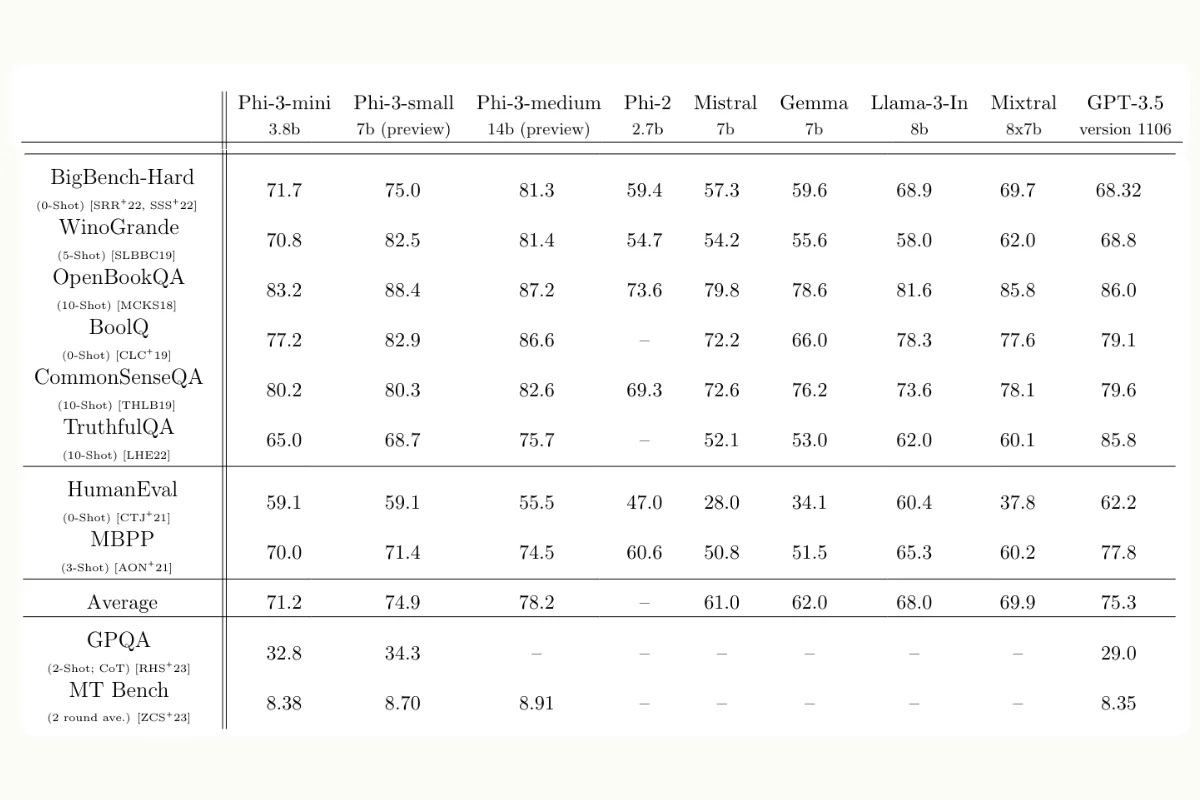
Source: Phi-3's technical paper.
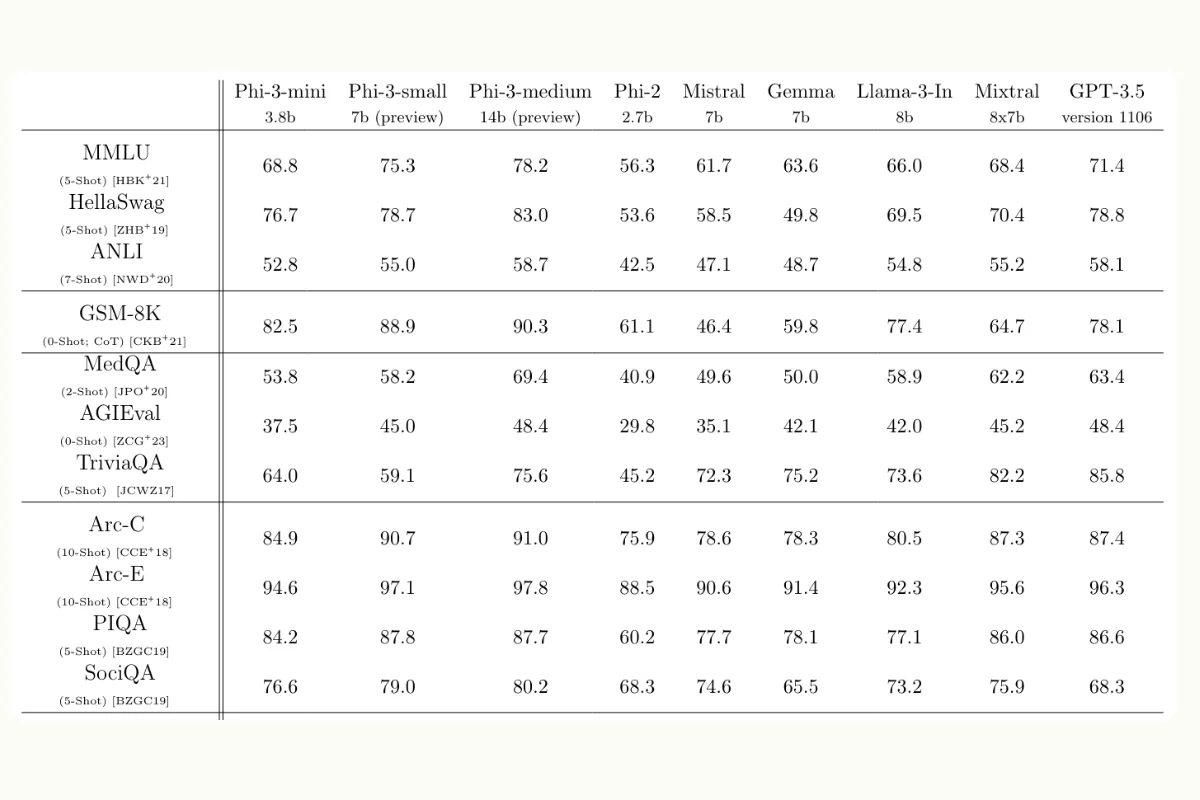
Phi-3-medium Leads the Pack:
- With 14 billion parameters, Phi-3-medium consistently scores higher than other models, including the popular GPT-3.5, on benchmarks such as MMLU, HellaSwag, and GSM-8K. This suggests that Phi-3-medium is highly effective in understanding and processing complex language tasks, potentially due to better training methodologies or more extensive datasets.
Phi-3-small as a Strong Contender:
- The 7-billion parameter Phi-3-small model performs exceptionally well, often surpassing or coming close to GPT-3.5. It balances computational efficiency with strong performance, making it an attractive option for applications needing robust language capabilities without the highest computational costs.
Phi-3-mini as a Competitive Mid-Range Model:
- Phi-3-mini, measuring 3.8 billion parameters, shows competitive performance across various tasks. While not always outperforming GPT-3.5, it provides a good balance for tasks where slightly lower performance is acceptable for the benefit of reduced computational requirements.
Training Microsoft Phi-3
Phi-3 was trained on a dataset of 3.3 trillion tokens and various data types to optimize the model's learning efficiency and effectiveness. The dataset includes:
- Heavily Filtered Web Data: High-quality web data is rigorously selected for its educational value to ensure that the content is reliable and informative.
- Curated Educational Data and Code: Carefully chosen educational resources and code datasets to enhance the model's understanding of structured and domain-specific knowledge.
- Synthetic Data: "Textbook-like" synthetic data created to teach subjects such as math, coding, common sense reasoning, and general world knowledge. This data was generated by larger language models and meticulously reviewed by researchers to ensure clarity and correctness.
This approach was an extension of the training recipe used for Microsoft's previous Phi-2 model. The training hypothesis was that by focusing on a meticulously curated, reasoning-dense dataset, a smaller model could achieve capabilities rivaling much larger models trained on standard web data. The model learns from clear, textbook-like material, making complex language understanding tasks more manageable.
Particularly, the phi-3-mini model underwent two distinct initial training phases as part of its development strategy to optimize its performance across a range of capabilities, specifically tailoring its learning process to gradually increase its complexity and specialization in handling various types of data. This phased approach allows for more controlled and effective model training. Here’s why the model was trained in two distinct phases:
- Foundation Building in Phase-1:
- General Knowledge and Language Understanding: The first phase focuses on broad knowledge and fundamental language skills. This involves training with a large variety of web sources to ensure that the model has a strong base in general comprehension and can understand and generate natural language effectively.
- Base Dataset: The data used in this phase is mostly unfiltered compared to the second phase, covering a wide range of topics and sources to give the model a comprehensive view of human language and knowledge.
- Specialization and Refinement in Phase-2:
- Advanced Reasoning and Niche Skills: Once the model has a solid foundation, the second phase introduces more specialized training with data that’s highly curated to enhance specific skills like logical reasoning, technical problem-solving, or domain-specific knowledge.
- Heavily Filtered and Synthetic Data: The use of more selectively filtered web data and synthetic data generated by other language models helps tailor the training process to overcome specific weaknesses or gaps identified during or after the first phase. This targeted approach helps in improving the model’s performance in complex cognitive tasks.
By separating the training into two phases, the learning process can be optimized to make more efficient use of computational resources. The model learns general concepts first, which are easier to acquire, before moving on to more complex and resource-intensive tasks.
This method also helps in preventing the model from overfitting on niche or complex data early in its training, which could hamper its ability to generalize across broader tasks.
The two-phase training can be seen as a form of incremental learning, where the model first acquires a broad ability to understand and process language and then sharpens its capabilities in more challenging and specialized areas.
It allows the model to adapt more robustly to a variety of inputs and tasks by building its capabilities in a structured way, ensuring that foundational skills are well-established before introducing more advanced challenges.
Microsoft's "data optimal regime"
This level of performance was achieved thanks to Microsoft's focus on data quality. Source: Microsoft's Phi-3 announcement.
.webp)
In Microsoft's technical paper for Microsoft Phi-3, they shared the concept of the "data optimal regime." The concept, as demonstrated in the model's training phases, revolves around optimizing the quality and appropriateness of training data to enhance the performance of a language model, especially smaller models, rather than merely increasing the size of the model or the quantity of data.
Here are the key points and rationale behind this approach:
Quality Over Quantity:
- Traditional approaches often focus on scaling models by increasing their size (number of parameters) and the amount of training data (tokens).
- The "data optimal regime" emphasizes the quality of the training data. High-quality, well-filtered data can significantly improve the model's performance without the need for massive scaling in terms of parameters or data volume.
Selective Data Filtering:
- The approach involves filtering web data to ensure it contains the appropriate level of knowledge and reasoning capabilities necessary for the model.
- For instance, trivial or highly specific data points (e.g., the result of a particular sports game) might be excluded to make room for more universally useful information that enhances the model's reasoning abilities.
Synthetic Data Generation:
- The training regime incorporates synthetic data generated by other large language models (LLMs). This synthetic data is designed to bolster the model's logical reasoning and niche skills, which are critical for small models.
- This method allows for the creation of highly relevant training datasets that are specifically tailored to improve the model's performance in desired areas.
Comparison with Other Regimes:
- The "compute optimal regime" focuses on balancing computational resources (e.g., time, hardware) with the scale of the model and data.
- The "over-train regime" involves extensive training beyond the typical convergence point to eke out minor performance gains, often leading to diminishing returns.
- The "data optimal regime" seeks to find an optimal mixture of training data that maximizes performance for a given model size, aiming for an efficient and effective use of data.
Results and Findings:
- The phi-3-mini model, despite being relatively small (3.8 billion parameters), achieves performance levels comparable to much larger models (e.g., Mixtral 8x7B with 56 billion parameters) due to its superior data quality.
- Empirical results show that models trained in a data optimal regime can match or exceed the performance of models trained with a more extensive but less curated dataset.
Challenges and Ongoing Research:
- While the data optimal regime shows promise, finding the provably "optimal" data mixture is complex due to the need to balance diverse and evolving data requirements, the subjective nature of data filtering, the empirical basis of determining effectiveness, and the challenges in scaling and generalizing across different model sizes and applications.
- The phi-3 model's training data mixture, while effective for its size, may require adjustments for larger models (e.g., phi-3-medium with 14 billion parameters) to achieve similar gains.
Post-training and fine-tuning the Phi-3 language model
The fine-tuning process for the phi-3-mini model is a crucial stage in its development, designed to refine the model's capabilities and align it more closely with desired performance characteristics. This process involves several stages and methodologies that are tailored to enhance specific aspects of the model. Here’s an in-depth look at the fine-tuning stages described in the technical report:
Supervised Fine-Tuning (SFT):
- Diverse Domains: The model undergoes supervised fine-tuning using high-quality data from a variety of domains such as mathematics, coding, reasoning, conversation, model identity, and safety. This diverse data set ensures the model can handle a wide range of topics and improves its generalization capabilities.
- English-Only Examples: Initially, the SFT process primarily uses English-only examples. This focus helps in optimizing the model's performance in English, which is crucial for ensuring high accuracy and effectiveness in its primary language.
Direct Preference Optimization (DPO):
- Chat Format Data: DPO is used to fine-tune the model specifically for chat interactions. This involves training the model to generate responses that are not only accurate but also appropriate and engaging in conversational contexts.
- Reasoning and Responsible AI: The DPO stage also includes data that enhances the model's reasoning abilities and aligns it with principles of responsible AI. This helps in steering the model away from unwanted behaviors by using examples of inappropriate outputs as negative examples.
Post-Training Safety Alignment:
- Automated and Manual Testing: After SFT and DPO, the model undergoes rigorous testing, including automated tests and manual evaluations by a "red team". This team attempts to identify and mitigate potential safety issues, ensuring the model adheres to ethical guidelines and does not produce harmful content.
- Refinement Based on Feedback: Based on the testing feedback, additional fine-tuning is conducted to address any identified issues. This iterative process helps in continuously improving the model's safety and effectiveness.
Long Context Extension:
- Extended Context Capabilities: As part of the post-training process, the model's context length is extended to 128K from the standard 4K. This allows the model to handle longer conversations or documents without losing track of earlier content, significantly enhancing its usability in real-world applications.
- Mid-Training and Post-Training Adjustments: The extension involves adjustments during both mid-training and post-training stages. This ensures that the model can effectively integrate and utilize the extended context without a drop in performance.
This comprehensive fine-tuning approach ensures that phi-3-mini is not only technically proficient but also safe and effective for user interactions. By combining diverse training data, focused optimization, and rigorous safety evaluations, the fine-tuning process significantly enhances the overall quality and reliability of the model.
Leveraging Microsoft Phi-3 for Organizational Needs
Custom fine-tuning small language models for domain-expertise and narrower tasks
When pre-trained on large datasets, small language models already possess a basic understanding of language patterns, structures, and sometimes domain-specific knowledge. Fine-tuning these models on a more focused dataset allows them to retain this broad knowledge while adapting to specific tasks or niches. This is particularly efficient because it uses pre-existing knowledge as a foundation, reducing the need for learning from scratch.
Smaller models have fewer parameters than larger ones, inherently reducing the risk of overfitting. Overfitting occurs when a model learns the underlying patterns and the noise and anomalies specific to a training dataset. By fine-tuning, small models adapt to specific tasks without the high risk of fitting excessively to the training data's idiosyncrasies, which is a common issue with larger models when not appropriately controlled.
Training a small model from scratch to perform well on specific tasks can be resource-intensive and may not always yield the desired results due to the limited capacity to learn complex patterns. Fine-tuning allows these models to improve performance without the extensive computational resources required for training larger models. This makes fine-tuning a cost-effective solution for many applications, particularly for startups and medium-sized enterprises with limited AI budgets.
Smaller models can also quickly adapt to new domains or tasks through fine-tuning. Since the fine-tuning process requires less computational time and data than training a large model, organizations can swiftly deploy models tailored to new challenges or evolving business needs.
📚 Additional reading
Learn the whys, whens, and how to fine-tune your large language models for your chatbot in the first episode of our LLM webinar series!
Combining Phi-3 with Retrieval-Augmented Generation (RAG)
According to the technical paper of the phi-3-mini model, while it achieves a similar level of language understanding and reasoning ability as much larger models, it is fundamentally limited by its size for certain tasks. The paper notes that the model does not have the capacity to store extensive “factual knowledge,” which shows on tasks like TriviaQA. To address this limitation, the paper recommends the use of search to enhance the model’s performance.
RAG systems enhance a generative model like Phi-3 by integrating it with a retrieval component. This setup enables the model to pull in external knowledge from a database or corpus when generating responses, thus providing more accurate and contextually relevant outputs.
The integration of Phi-3 with a RAG system could be particularly beneficial in applications requiring detailed or expert knowledge that exceeds the model's pre-trained information. Benefits include:
- Enhanced Accuracy: By retrieving information during the generation process, the system ensures that the outputs are not only contextually relevant but also factually accurate.
- Increased Relevance: Outputs consider the latest information and specific data pertinent to the query, improving the model's usefulness in dynamic environments.
Implementing RAG with Phi-3 involves several steps:
- Selecting a Knowledge Source: Choose a database or knowledge corpus that is relevant to the tasks at hand. This source needs to be well-organized and accessible by the model.
- Integration: The retrieval system must be seamlessly integrated with Phi-3, allowing the model to query the knowledge source and use the retrieved data to inform its responses.
- Training and Tuning: The combined system may require additional training or fine-tuning to optimize performance across the generative and retrieval components.
- Testing and Iteration: Before full deployment, the system should be thoroughly tested in controlled and real-world settings to refine its capabilities and address any shortcomings.
📚 Additional reading
Make sure your RAG stack is impactful. We provide workflows and insights on evaluating LLM and RAG powered chatbots in one of our latest articles.
.webp)
Explore the Future of AI with Microsoft Phi-3: Taking the first step
Ready to transform your AI capabilities with Microsoft Phi-3? Whether you're looking to enhance mobile applications, improve natural language understanding, or implement sophisticated AI systems with Microsoft's new batch of small language models, the first step is always about having a solid dataset. LLM-builders and companies looking to leverage LLMs will need datasets for specific benchmarking, supervised fine-tuning, training, RLHF, red-teaming, and more.
However, creating a proprietary dataset for the use cases we just mentioned can be challenging, even for the most experienced data science teams. Kili Technology provides an end-to-end solution for building high-quality datasets that accelerates your development process. Our solution includes a state-of-the-art tool renowned for its speed, flexibility, and quality, dedicated project management to ensure seamless delivery, and an extensive network of experts and data labelers to scale while maintaining the highest quality standards.
Our expert team is eager to discuss your needs and help identify the best strategies for your AI initiatives. We recognize that a reliable and well-curated dataset is crucial to the success of AI projects, and our services are designed to meet these essential requirements effectively. Whether you are just starting to explore AI's potential or seeking to enhance an existing system, our tailored solutions offer the support you need to achieve your goals.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
