
.png)


_logo%201.svg)


AI Summary
The landscape of artificial intelligence is currently undergoing a significant transformation, with a shift towards smaller, more efficient models that can be deployed directly on local devices. Apple's introduction of OpenELM, or Open-source Efficient Language Models, aligns with this industry-wide trend toward minimizing the computational footprint of AI technologies. Additionally, Apple has open-sourced their model in the hopes of advancing open research even further.
This article will explore OpenELM's specifics, focusing on its architecture, training methodologies, and the diverse datasets it has been trained on. The aim is to provide a comprehensive overview of how OpenELM is engineered to enhance privacy, reduce operational latency, and facilitate broader research and development within the AI community.
What are the main features of the Apple OpenELM models?
Apple's efficient language model family includes eight models with four different parameter sizes. These models are categorized into two types: standard models and "Instruct" models, which are fine-tuned to better understand and respond to direct instructions. The parameter sizes for these models are 270 million, 450 million, 1.1 billion, and 3 billion, providing a range of capabilities tailored to different computational needs and applications.
On-device Processing
Optimized for on-device processing, OpenELM models are designed to run efficiently on local hardware of consumer devices such as iPhones and Macs. This capability means that Apple is prioritizing user privacy and security by processing data locally rather than on cloud servers. It also reduces latency and the operational costs associated with cloud computing, making OpenELM particularly well-suited for mobile applications and IoT devices where immediate processing is crucial.
Layer-wise Scaling Strategy
The models use a sophisticated layer-wise scaling strategy to allocate parameters within each layer of the transformer model. The fundamental idea behind their layer-wise scaling strategy is to vary the size and capacity of the transformer layers based on their position within the model. Specifically, layers closer to the input have smaller latent dimensions in both the attention mechanisms and the feed-forward networks. As the layers progress towards the output, their size and capacity gradually increase. This approach contrasts with prior practices in traditional transformer models where each layer typically has a uniform size and capacity.
Open-source Framework
OpenELM is fully open-source, which is a significant shift from traditional practices where companies might only release certain components like model weights or inference code. Apple provides their complete framework with comprehensive resources including training logs, multiple checkpoints, pre-training configurations, and even the specific code needed to adapt models for inference and fine-tuning on Apple devices. This level of transparency is designed to foster collaboration and innovation within the open research community.
How does Apple OpenELM perform against other models?
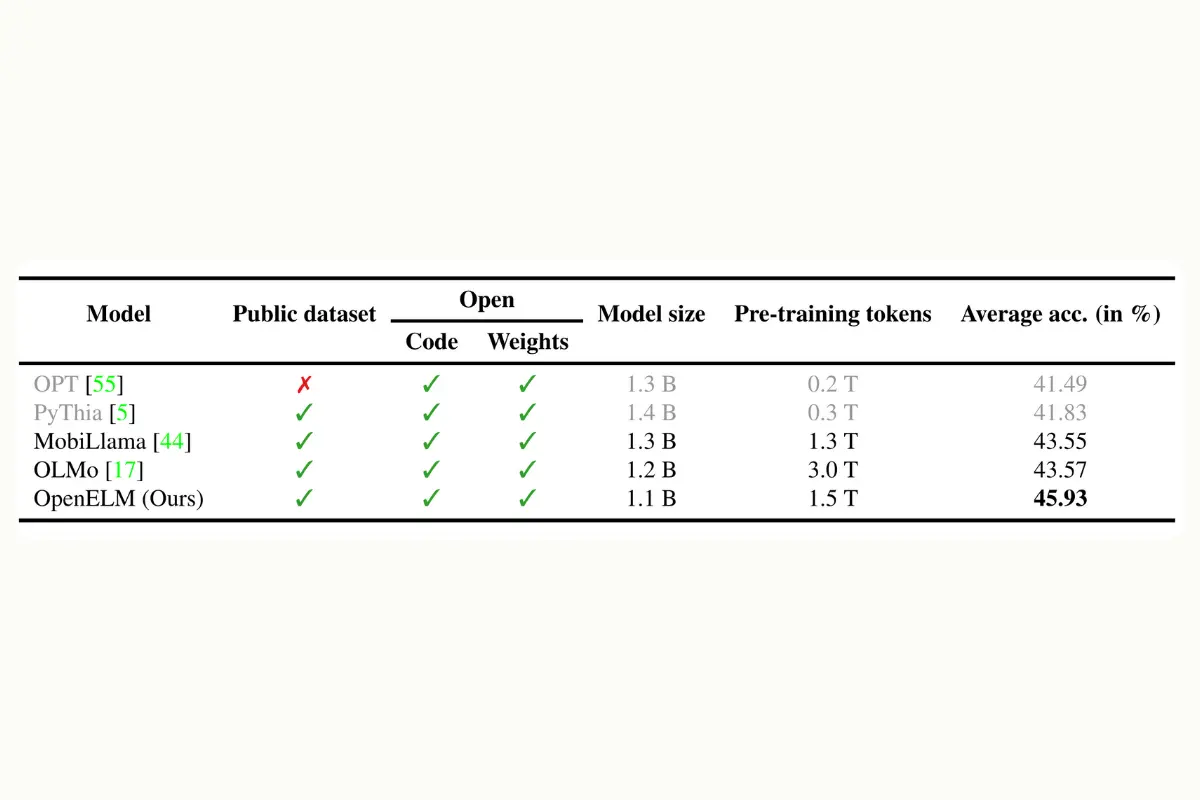
OpenELM models have demonstrated a 2.36% improvement in accuracy over similar models like OLMo, while requiring only half the pre-training tokens. This efficiency highlights a robust learning process and effective utilization of training data.
OpenELM models perform competitively on various NLP benchmarks such as Multitask Prompted Training Regimes (MMLU), Adversarial NLI (ANLI), Commonsense Reasoning (HellaSwag), Physical Interaction QA (PIQA), and Open-Domain Question Answering (TruthQA) along with similarly sized models. These benchmarks assess the models' language understanding, reasoning, and practical knowledge application across different domains.
Open efficient language model family benchmarks
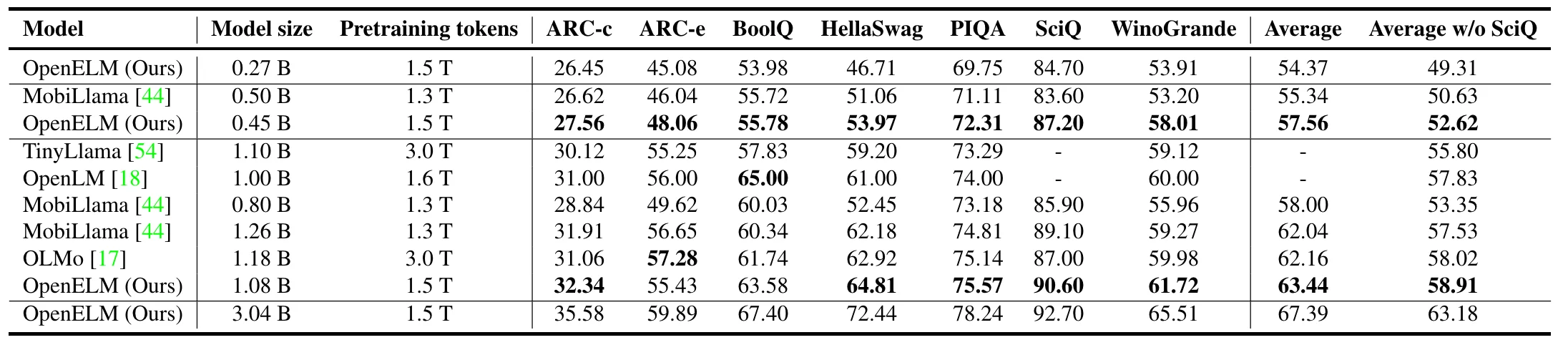
Let's get a more detailed look into the benchmarks and what they're for, as well as how each language model has performed:
- MMLU (Multitask Prompted Training Regimes): This benchmark assesses the model's ability to handle a wide range of tasks by prompting it to perform specific tasks within a multitask learning framework.
- ANLI (Adversarial NLI): Adversarial Natural Language Inference is a benchmark designed to test the model's understanding of language and its ability to reason about the content robustly against adversarially crafted inputs.
- HellaSwag (Commonsense Reasoning): This benchmark evaluates the model's commonsense reasoning capability, requiring it to complete sentences or paragraphs in a way that makes sense given the context.
- PIQA (Physical Interaction Question Answering): Physical Interaction QA tests the model's understanding of physical interactions in the real world, requiring it to predict the outcomes of physical processes or the steps needed to achieve certain physical tasks.
- TruthQA (Open-Domain Question Answering): This benchmark involves answering questions based on general knowledge or specific information, testing the model's ability to retrieve and synthesize information accurately.
Which model should you choose?
The four parameter sizes of OpenELM models are designed to cater to different computational needs and applications, allowing for flexible deployment across devices with varying processing capabilities. Here are the differences between the four parameter sizes:
- OpenELM-270M: This model has 270 million parameters. It is the smallest model in the OpenELM family, making it ideal for devices with limited computational resources. It can handle basic language processing tasks efficiently without requiring extensive computing power.
- OpenELM-450M: With 450 million parameters, this model offers a middle ground between the smallest and larger models. It provides more computational power than the 270M model, allowing for more complex language processing tasks while still being efficient enough for relatively modest hardware.
- OpenELM-1.1B: This model has 1.1 billion parameters. It is significantly more powerful than the 270M and 450M models, enabling it to handle more complex and demanding language processing tasks. This model is suitable for devices that can afford more computational overhead.
- OpenELM-3B: The largest model in the OpenELM family, with 3 billion parameters, is designed for the most demanding language processing tasks. It offers the highest level of performance in the OpenELM series and is suitable for high-end devices with substantial computational resources.
Balancing model size and speed: why smaller could be better
Balancing performance and compute power in small language models like OpenELM is crucial for several reasons, primarily relating to practicality, efficiency, and broader accessibility. Here’s a detailed explanation of why this balance is important:
1. Enhancing Practicality for On-Device Use
Small language models are often designed to run directly on local devices (like smartphones, laptops, or IoT devices) rather than through centralized servers. This shift demands models that are not only powerful enough to handle complex tasks but also lightweight enough not to overburden the device’s processing capabilities. By balancing performance with computational demand, models like OpenELM can deliver sophisticated AI functionalities directly on a user's device, ensuring smoother user experiences and instantaneity in applications such as virtual assistants, language translation, or real-time content recommendation.
2. Optimizing Energy Efficiency
Compute power directly correlates with energy consumption. More computationally intensive models require more power, which can drain device batteries rapidly or increase operational costs in data centers. Efficient models that balance performance with computing demands contribute to sustainability by reducing the energy footprint of running AI applications, which is crucial as digital technologies increasingly impact our energy resources.
3. Enabling Wider Accessibility
When AI models are optimized to use less computing power while maintaining high performance, they become accessible to a broader range of users. Developers and businesses that may not have access to cutting-edge hardware or extensive cloud computing budgets can still deploy advanced AI capabilities. This democratizes access to AI technologies, allowing smaller entities to compete with larger organizations and fostering innovation across a more diverse landscape.
4. Reducing Costs
Computational resources are expensive. Training and running large models require significant investments in both hardware and ongoing operational costs (like electricity and cooling). Smaller, more efficient models can drastically cut these costs, making it economically viable for more companies to integrate AI into their products and services.
5. Maintaining User Privacy and Data Security
Models that process data directly on the device help maintain user privacy by minimizing data transmission to external servers. Efficient models that can operate within the constraints of local processing power support these privacy-enhancing features without compromising on performance, which is increasingly important as data privacy concerns grow among consumers.
6. Supporting Real-Time Applications
Many applications of language models require real-time or near-real-time responses. Models that can deliver high performance with constrained computing power are crucial in scenarios where delay can diminish the user experience or effectiveness of the application, such as in real-time translation or interactive educational tools.
How the Apple OpenELM family was trained
Let’s dive into how this model is trained, the unique methods it employs, and its application areas, making this information accessible to both non-technical and technical audiences.
Diverse Data Sources for Robust Learning
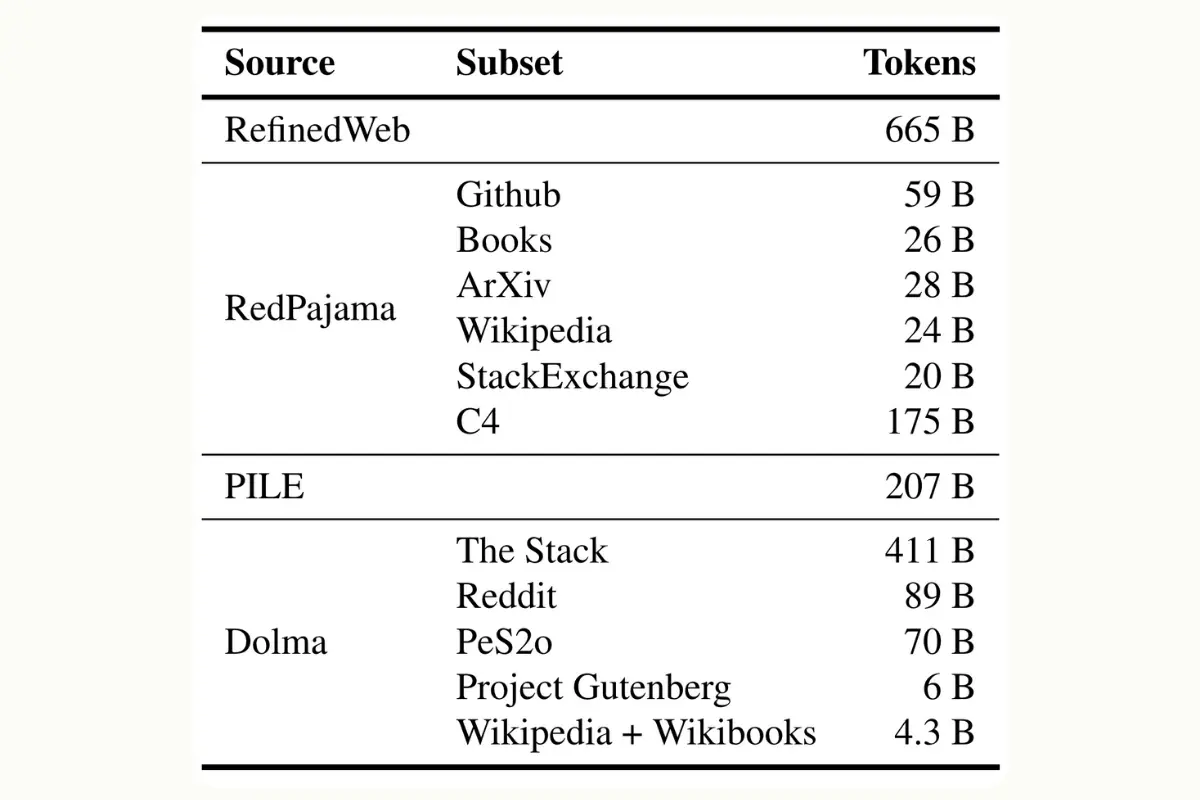
Training a language model to understand and generate text accurately requires vast amounts of diverse data. Apple’s OpenELM model uses a massive dataset totaling approximately 1.8 trillion tokens (as a reminder, a token can be a word or part of a word).
Sources of Data:
- RefinedWeb: RefinedWeb is a large-scale English web dataset designed for the pretraining of large language models. It is built on top of CommonCrawl data, leveraging stringent filtering and extensive deduplication processes.
- PILE: The Pile is an 825 GiB diverse, open-source dataset of English text created as a training dataset for large language models (LLMs). It was developed by EleutherAI and consists of 22 smaller, high-quality datasets combined together.
- RedPajama: RedPajama is a project aimed at creating leading open-source models, starting by reproducing the LLaMA training dataset of over 1.2 trillion tokens. It includes data from CommonCrawl, GitHub, books, arXiv, Wikipedia, and StackExchange.
- Dolma v1.6: Dolma v1.6 is part of a series of datasets released under the Dolma project, which includes a total of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The v1.6 update involved some deduplication of documents with too few tokens or too many repeated n-grams.
These diverse datasets enable the OpenELM model to handle everything from casual conversations to complex scientific explanations.
Real-time Tokenization and Adaptive Filtering
On-the-Fly Tokenization: Unlike traditional methods where data is pre-processed and tokenized (broken down into manageable pieces) before training, OpenELM processes data 'on-the-fly'. This means the model can dynamically tokenize and filter text as it trains. This approach allows for rapid experimentation with different tokenization methods, which can significantly streamline research and development.
Adaptive Filtering: OpenELM uses dual filters to maintain quality control of the data it learns from:
- Character-level Filtering: This method skips over text sequences that are shorter than 200 characters, ensuring the model does not focus on overly brief and potentially uninformative text snippets.
- Token-level Filtering: Similar to character-level, this filter bypasses sequences with fewer than 256 tokens, which helps in focusing on richer and more complex sentence structures.
Focused Instruction Tuning
Instruction Tuning Using UltraFeedback: To further enhance the model's ability to follow instructions and generate useful responses, OpenELM is fine-tuned using the UltraFeedback dataset.
The UltraFeedback dataset is a comprehensive set of preferences gathered from humans, specifically designed to improve language models through reinforcement learning using human feedback (RLHF). This dataset is meant to address the limitations of existing preference datasets, which are often proprietary, limited in size, and lack diversity.
UltraFeedback aims to foster the development of RLHF by providing a robust and scalable source of human feedback on language model outputs. The dataset contains 64k prompts, each with four model completions, which are evaluated and scored based on criteria such as helpfulness and honesty, mainly using GPT-4.
The dataset includes a "chosen" completion, which scored the highest, and a "rejected" completion, selected randomly from the remaining three. This setup is used to train models using techniques such as reward modeling and preference modeling.
Optimization Methods: The model employs sophisticated methods like statistical rejection sampling and direct preference optimization. These methods help refine the model’s outputs, ensuring they align well with human expectations and instructions.
- Statistical rejection sampling is a method used in probability and statistics to generate observations from a distribution. It is particularly useful when the distribution is complex and not straightforward to sample from directly. In the context of machine learning models like OpenELM, rejection sampling can be used to selectively refine outputs based on predefined criteria. For example, after generating several possible responses, the model might use rejection sampling to choose the response that best fits a desired characteristic, ensuring higher quality or more relevant outputs.
- Direct preference optimization is a technique used to directly optimize a model's preferences or choices based on feedback or desired outcomes. This method focuses on adjusting the model parameters or decision processes to align more closely with specific goals or preferences. This method is particularly useful in scenarios where the model needs to adapt to user-specific needs or when fine-tuning the model on tasks like instruction following content generation, or personalized recommendations.
Leveraging OpenELM for Handling Specific Tasks
OpenELM is optimized for on-device processing, making it ideal for integration into smartphones, laptops, and potentially wearable devices like AR glasses. This allows for real-time AI applications such as voice assistants, predictive text, and other interactive features that operate directly on the device, enhancing user privacy and reducing latency.
Potential Use Cases:
Patient Data Processing: OpenELM can be used in mobile health applications to process patient data directly on devices. This on-device processing can help maintain patient confidentiality as sensitive data does not need to be sent to the cloud. Healthcare providers can fine-tune OpenELM with medical datasets to improve their understanding and generation of medical documentation and patient interaction.
Support for Remote Diagnostics: In telemedicine, OpenELM can be fine-tuned to provide diagnostic support by analyzing symptoms described by patients and offering preliminary advice. This can make telemedicine services faster and more reliable, especially in remote areas with limited connectivity.
Secure Transactions: OpenELM can be implemented in banking apps to enhance the security and speed of on-device processing for transactions. Banks can fine-tune the model with financial terminology and regulatory requirements to ensure that the AI adheres to industry standards while providing real-time assistance to users.
Customer Service Automation: Retailers can use OpenELM to power on-device customer service chatbots. These AI-driven bots can handle a multitude of customer queries in real-time, directly on the customer’s device, enhancing the shopping experience. Retailers can fine-tune the model with specific product information and customer service scenarios.
Fine-tuning to build a domain-specific SLM:
For SLMs to be effective in your specific use cases, fine-tuning them on private datasets or publicly available datasets is essential. Demonstrating the adaptability of small language models to diverse domains, we delve into a case study focused on fine-tuning an SLM for application in the financial sector. This sector, characterized by intricate data and nuanced decision-making, poses unique challenges to artificial intelligence applications. Through domain adaptation, we transformed a small Llama language model into a specialized agent focused on the financial domain and trained to keep its answers short and to the point.

Watch video
Additionally, when fine-tuning small language models (SLMs), the most important factor is the quality, relevance, and variety of the data you use. This data is crucial because it shapes how well the model performs and adapts to different tasks.
The data used for fine-tuning needs to closely match the specific task or area the model is intended for. This ensures that the model learns from examples that are relevant, making it better at producing accurate and appropriate responses.
It's also vital that the data covers a wide range of situations, dialects, and details that the model might encounter in real-world applications. This variety helps the model handle different scenarios effectively.
For best results, you need a lot of data that is both diverse and detailed, covering as many potential situations as possible. This approach helps small language models work well across the specific tasks and environments.
Get hands-on 🙌
Check out our fine-tuning recipe where we fine-tuned a small Llama model to adapt it for financial domain use cases.
Using RAG with Apple OpenELM
Retrieval-augmented generation (RAG) is a method that enhances language model performance by combining the generative capabilities of a transformer-based model with a retrieval component, typically a document store or database, that provides relevant contextual information during the generation process.
Applying Retrieval-Augmented Generation (RAG) can be effective with small language models (SLMs), although specific considerations and potential trade-offs must be considered.
While SLMs are efficient, their smaller size may limit the breadth of knowledge they can handle compared to larger models. This could affect the depth of responses generated even when RAG is used, as the SLM's inherent capabilities still play a critical role in overall performance.
The effectiveness of a RAG system also heavily depends on the quality and relevance of the information in the retrieval database. The model's performance can be negatively affected if the database is not comprehensive, outdated, or contains low-quality information. Ensuring the database is well-curated and up-to-date is crucial but can be resource-intensive.
There is a risk of over-reliance on the external data fetched by RAG, which might constrain the SLM's ability to generate creative or highly nuanced responses. This is particularly relevant in scenarios where the external data may not fully capture the complexity or subtlety of the query.
Integrating RAG involves technical implementation and model training and tuning to optimize how the retrieved information is used. This can involve complex training regimes to ensure the model effectively incorporates the retrieved data into its responses.
A robust evaluation and continuous monitoring strategy is essential to maximize RAG systems' efficacy. Regular evaluations allow fine-tuning the integration between retrieved data and generated content, ensuring the system responds accurately to user queries across various scenarios.
Leverage the efficiency of small language models with high quality datasets
Implementing SLMs like OpenELM effectively requires thorough planning, from preparing the dataset to ongoing evaluation and monitoring. Organizations need to actively manage these models to ensure they continue to meet changing needs and align with business objectives.
The first and crucial step in deploying successful AI applications is managing high-quality training data—used for training, fine-tuning, evaluating, or monitoring.
Creating a custom dataset for specific use cases can be a complex task, even for experienced data science teams. Kili Technology offers a complete solution for building high-quality datasets that can speed up your development process. This solution includes an advanced tool known for its speed, flexibility, and quality, comprehensive project management to ensure smooth implementation, and access to a wide network of experts and data labelers committed to maintaining the highest standards.
Our expert team is ready to discuss your specific requirements and identify the most effective strategies for your AI projects. We understand the critical importance of reliable and carefully curated datasets in AI success, and our services are designed to efficiently meet these key needs. Whether you are just beginning to explore AI or looking to improve an existing system, our customized solutions are here to support you in achieving your goals.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

