
.png)


_logo%201.svg)


AI Summary
- LLM reasoning is constrained by next-word prediction training, making models reliant on pattern matching rather than genuine logical deduction.
- Chain-of-thought prompting improves LLM reasoning by decomposing problems into steps, but does not overcome fundamental probabilistic biases.
- DeepSeek-R1-Zero demonstrates that reinforcement learning alone can produce emergent LLM reasoning without supervised fine-tuning.
- GSM-Symbolic benchmarks reveal up to 65% accuracy drops when numerical values change, exposing fragile reasoning in current models.
- High-quality hybrid training data — combining code, math, and natural language — remains the binding constraint for advancing LLM reasoning.
- Kili Technology combines human expertise and AI-powered workflows to build complex reasoning datasets for foundation model builders.
Introduction to LLM Reasoning
Large Language Models (LLMs) have revolutionized the field of natural language processing, enabling machines to understand and generate human-like language. However, LLMs still struggle with logical reasoning, a crucial aspect of human intelligence. Reasoning involves processing existing knowledge to make new conclusions, and it is a complex task that requires the ability to understand context, identify patterns, and make connections between ideas. Despite their impressive capabilities, LLMs often fall short in this area, primarily because their training focuses on predicting the next word in a sequence rather than understanding the underlying logic of the text.

An example of GPT4 struggling on some simple tasks from the paper: "Embers of autoregression show how large language models are shaped by the problem they are trained to solve."
The current state of LLM reasoning reveals significant limitations. While these models can perform well on tasks that involve pattern recognition and statistical correlations, they often fail when faced with problems requiring genuine logical deduction. This gap highlights the need for advanced techniques to enhance LLM reasoning capabilities. Researchers are actively exploring various methods to bridge this gap, aiming to develop models that can reason more like humans. In this section, we will delve into these efforts and the progress being made to improve LLM reasoning.
The Foundation of Logical Reasoning in LLM
At their core, LLMs are trained through next-word prediction over vast corpora of text data. This training paradigm creates systems that are highly sensitive to probabilistic patterns in language, fundamentally shaping how they approach reasoning tasks (McCoy et al., 2024). While this can lead to impressive performance in many scenarios, it also results in important limitations that developers must understand.
While this can lead to impressive performance in many scenarios, it also results in important limitations that developers must understand. Recent research has shown that the effectiveness of reasoning in LLMs, especially with Chain-of-Thought prompting, is influenced by factors such as probability, memorization, and noisy reasoning (Prabhakar et al., 2024).
An example of CoT prompting from the paper: "Deciphering the Factors Influencing the Efficacy of Chain-of-Thought: Probability, Memorization, and Noisy Reasoning".

Mirzadeh et al. (2024) highlight a critical distinction between reasoning behavior and reasoning performance. While performance metrics might show high accuracy on specific tasks, examining the underlying reasoning behavior often reveals that LLMs are not employing the kind of systematic, logical reasoning we might expect. Instead, they frequently rely on pattern matching and statistical correlations from their training data.
A schematic overview of reasoning tasks from the paper: Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models - A Survey.
Background: Training and In-Context Learning
LLMs are typically trained on vast amounts of text data using a process called masked language modeling. During training, the model is presented with a sequence of text and asked to predict the missing words. This process enables the model to learn the patterns and structures of language, including grammar, syntax, and semantics. However, this training process does not explicitly teach the model to reason. Instead, the model learns to reason through a process called in-context learning, where it is presented with a prompt and asked to generate a response based on the context.
In-context learning allows LLMs to adapt to new tasks by leveraging the context provided in the prompt. This method is particularly useful for tasks that the model has not explicitly been trained on, as it can infer the necessary steps to generate a coherent response. However, the reasoning abilities developed through in-context learning are often limited by the model’s reliance on patterns and correlations from its training data. This limitation underscores the need for more sophisticated training techniques that can enhance the model’s reasoning capabilities.
The Probabilistic Nature of LLM Reasoning
Recent studies have demonstrated that LLM reasoning is heavily influenced by probability in ways that might not be immediately obvious. Even when handling deterministic tasks, these models show higher accuracy when:
- The correct answer is a high-probability sequence
- The task itself is frequently represented in training data
- The input follows common patterns (McCoy et al., 2024)
Examples of the performance of language models depending on probability and frequency.

This probabilistic foundation, combined with the fact that LLMs exhibit both probabilistic and memorization-based behaviors, leads to particular challenges in out-of-distribution scenarios, where models must generalize beyond their training data. As Guan et al. (2024) note in their work on deliberative alignment, this can manifest as both accuracy degradation and increased susceptibility to adversarial attacks.
The Role of Pattern Matching
Rather than employing true logical reasoning, LLMs often engage in sophisticated pattern matching, searching for similarities between current inputs and patterns encountered during training. This approach can be highly effective when dealing with familiar patterns but may fail in novel situations or when faced with problems requiring genuine logical deduction (Mirzadeh et al., 2024). Understanding this limitation is crucial for machine learning engineers, as it impacts both model development and deployment decisions.
Example of data in the GSM NoOP dataset where the majority of models failed.

For instance, Mirzadeh et al. (2024) demonstrated this limitation through their GSM-NoOp dataset, where they added seemingly relevant but ultimately irrelevant mathematical information to word problems. In one revealing example, when asked about calculating the total cost of kiwis picked over three days, where five kiwis were noted to be “smaller than average,” models consistently subtracted these five kiwis from the total - despite size being irrelevant to the counting task. This error persisted even when models were provided with multiple examples of the same question or similar problems containing irrelevant information, suggesting that rather than understanding the core mathematical concept, the models were pattern-matching based on training data where numerical modifications typically indicated necessary operations.
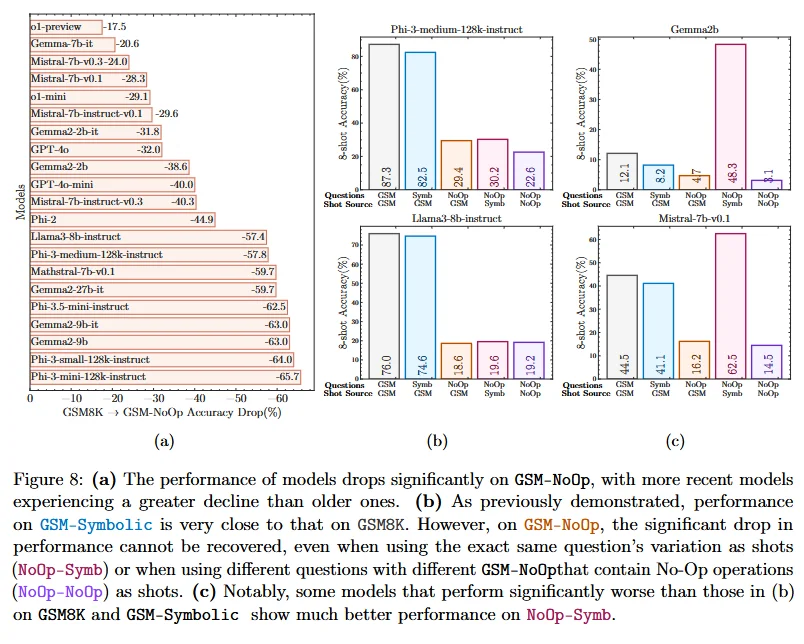
Evaluation of models on GSM-NoOP.
This pattern-matching behavior becomes particularly problematic in mathematical reasoning tasks. When evaluating models on the GSM-Symbolic benchmark, performance dropped significantly when numerical values were altered in otherwise identical problems. Furthermore, when testing models on the GSM-NoOp dataset, which included irrelevant information, some models showed dramatic decreases in performance, with Phi-3-mini experiencing over a 65% drop in accuracy (Mirzadeh et al., 2024). This demonstrates how LLMs may appear to understand mathematical concepts when operating within familiar patterns but fail to generalize this understanding to novel presentations of the same fundamental problems.
Techniques and Methods for Enhancing LLM Reasoning
The evolution of LLM reasoning capabilities has been driven by several key methodological advances, each addressing different aspects of the reasoning challenge. Here we examine the most significant techniques that have emerged from recent research. Multi-step reasoning plays a crucial role in enhancing LLM capabilities, particularly through methods like beam search and chain-of-thought prompting, which optimize reasoning chains to solve complex problems.
Chain-of-Thought (CoT) Prompting and Integration
Chain of thought prompting from the paper: "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models"
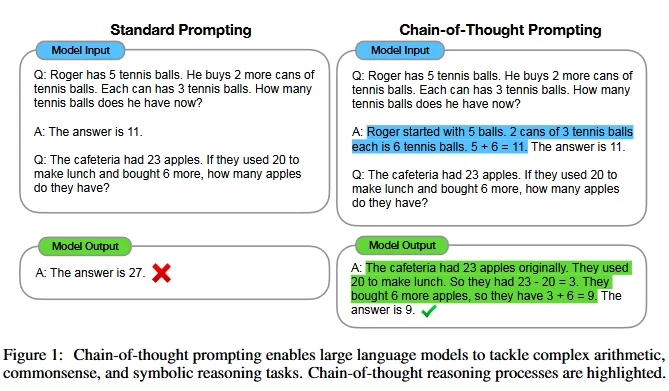
Chain-of-Thought prompting represents a fundamental advancement in how LLMs approach complex reasoning tasks. Rather than generating answers directly, CoT encourages models to decompose problems into intermediate reasoning steps, making the thought process explicit and verifiable (Wei, 2022).
Each reasoning step in the Chain-of-Thought methodology is crucial, as the order and length of these steps can significantly impact the outcomes of LLM analyses, both positively and negatively. The effectiveness of CoT reasoning is influenced by factors like probability, memorization, and noisy reasoning (Prabhakar et al., 2024), and it's important to encourage the generation of informative and relevant intermediate steps to enhance the reasoning process (Prabhakar et al., 2024). Recent implementations, particularly in models like OpenAI’s o1, have moved beyond simple prompting to integrate CoT reasoning directly into the model architecture (Guan et al., 2024).
This architectural integration has yielded significant improvements. For example, when evaluating mathematical reasoning capabilities, o1 models demonstrate substantially higher accuracy on complex word problems compared to previous approaches, with performance improvements of up to 65% on certain tasks (Mirzadeh et al., 2024). The transparency of the reasoning process also enables better error detection and correction.
Challenges of CoT Integration
While CoT can improve performance, research shows it doesn't fully overcome the fundamental limitations of LLMs. Guan et al. (2024) found that even with CoT prompting, models exhibit significant variance in performance when handling different versions of the same question. The effectiveness of CoT is particularly limited in cases involving low-probability outputs or unfamiliar patterns, as the model's reasoning process remains heavily influenced by the statistical patterns learned during training (McCoy et al., 2024). Additionally, the validity of the demonstration or examples provided in CoT prompting does not appear to significantly impact performance, suggesting that the structure and format of the reasoning steps are more critical (Prabhakar et al., 2024). For instance, when using CoT prompting on cipher decoding tasks, GPT-4's accuracy varied dramatically based on the probability of the correct output, demonstrating that explicit reasoning steps don't fully overcome the model's underlying probabilistic biases (McCoy et al., 2024). It is also crucial to recognize the importance of the surface-level text generated in these intermediate steps, as it directly influences the effectiveness of the CoT reasoning process (Prabhakar et al., 2024).
Enhanced RLHF Integration
Recent refinements to Reinforcement Learning from Human Feedback (RLHF) have focused on incorporating reasoning quality into the reward structure. Rather than solely evaluating final outputs, these enhanced RLHF implementations consider the quality and coherence of intermediate reasoning steps. This approach represents a significant advancement over traditional RLHF by:
- Evaluating the quality of reasoning paths
- Rewarding logical consistency between steps
- Encouraging adaptability in reasoning strategies based on task requirements
These methodological advances collectively represent significant progress in enhancing LLM reasoning capabilities. However, as recent evaluations using benchmarks like GSM-Symbolic and GSM-NoOp demonstrate, challenges remain in achieving truly robust and generalizable reasoning (Mirzadeh et al., 2024). Understanding both the strengths and limitations of these techniques is crucial for machine learning engineers working to improve LLM reasoning capabilities.
Deliberative Alignment
A particularly promising advancement in LLM reasoning comes from the deliberative alignment approach. This technique fundamentally differs from traditional training methods by explicitly teaching models to reason about safety specifications before generating outputs. The process involves two key stages: symbolic reasoning is integrated into the deliberative alignment approach to enhance the model's ability to navigate through intermediate steps and improve overall reasoning capability.
- Supervised Fine-Tuning (SFT): Models are trained on examples that demonstrate safety reasoning within their chain-of-thought, creating a strong prior for policy-aware reasoning.
- Reinforcement Learning: High-compute reinforcement learning is used to refine the model’s thinking process, with rewards provided by a judge LLM that has access to safety specifications.
The results of this approach are compelling. Guan et al. (2024) report that deliberative alignment achieves a notable Pareto improvement, simultaneously:
- Increasing resistance to jailbreak attempts
- Reducing overrefusal rates on legitimate queries
- Improving out-of-distribution generalization
The Role of Code in Enhancing Model Reasoning
Recent research has demonstrated that incorporating code during model training can significantly enhance both general reasoning capabilities and specific programming abilities. Studies have found that including code data in pre-training mixtures, even for models not explicitly designed for code generation, can lead to meaningful improvements across multiple reasoning domains (Aryabumi et al., 2024).
When examining the impact of code during pre-training, researchers found that models initialized with code pre-training showed improved performance on natural language reasoning tasks. Specifically, models that underwent continued text pre-training after code initialization achieved up to an 8.8% relative improvement in natural language reasoning tasks compared to text-only baselines (Aryabumi et al., 2024).
Zhang et al. (2024) conducted extensive experiments examining how code impacts reasoning across different domains during instruction fine-tuning. Their research evaluated performance across three key areas: symbolic reasoning (including tasks like letter concatenation and sequence reversal), logical reasoning (testing capabilities in areas like induction and deduction), and arithmetic reasoning (focusing on mathematical word problems). Their findings revealed that code data had varying impacts across these domains.
For symbolic reasoning tasks, Zhang et al. (2024) found that increasing the proportion of code in training led to consistent improvements in performance compared to text-only models. In logical reasoning, they observed that performance gains were maintained up to including 75% code data in the training mix, though benefits began to diminish at higher proportions. However, for arithmetic reasoning tasks, they noted that models performed better with a more balanced mix of code and text data, suggesting that diverse training data is important for real-world mathematical problem-solving.
The quality and properties of the code data also matter significantly. High-quality synthetic code data, even in relatively small proportions, can have an outsized impact on model performance. Studies showed that replacing just 10% of web-based code data with synthetically generated high-quality code led to a 9% improvement in natural language reasoning tasks and a 44.9% improvement in code benchmarks (Aryabumi et al., 2024).
Zhang et al. (2024) also investigated the impact of different code data sources, including markup-style programming languages and code-adjacent data like GitHub commits and Jupyter notebooks. Their research showed that incorporating diverse code sources led to gains in natural language performance, though only synthetically generated code improved performance on code benchmarks. This suggests that while different types of code data can enhance general reasoning capabilities, high-quality synthetic code may be particularly valuable for developing robust coding abilities.
These findings suggest that thoughtful incorporation of code during both pre-training and instruction fine-tuning can serve as a valuable tool for enhancing model reasoning capabilities across diverse tasks, extending well beyond just code-specific applications. The benefits appear to be most pronounced when using high-quality code data in carefully balanced proportions with other training data, with particular attention paid to the specific reasoning domains being targeted.
Math and Coding Combined
At Kili Technology, a foundation model builder is using Lean4, a functional programming language for proving theorems, to train its reasoning model. We sourced expert Lean4 mathematicians worldwide for this builder to translate and solve complex math word problems using Lean4, where each step is extracted for reasoning/chain of thought training.
While the model is yet to be completed, the method is believed to combine the impact of coding and mathematics with CoT prompting to expand the reasoning capabilities of LLMs.

Reinforcement Learning-Based Reasoning (DeepSeek-R1)
Recent advances, particularly from DeepSeek-AI, have demonstrated the potential of reinforcement learning (RL) without supervised fine-tuning (SFT) to develop reasoning capabilities in LLMs. DeepSeek-R1-Zero is an LLM trained purely through RL, exhibiting self-evolution in reasoning performance. The model achieves remarkable results in reasoning benchmarks without relying on traditional supervised learning, marking a shift in training methodologies.

- Self-Evolution Process: Through thousands of RL steps, DeepSeek-R1-Zero autonomously develops reasoning behaviors such as self-verification and reflection, significantly improving accuracy in complex problem-solving tasks.
- Cold-Start Data Fine-Tuning: The refined model, DeepSeek-R1, integrates a small set of cold-start Chain-of-Thought (CoT) examples before reinforcement learning. This hybrid approach leads to enhanced readability and structured reasoning outputs.
- Reward Modeling: The RL-based optimization uses accuracy rewards (for correct outputs) and format rewards (for structured reasoning processes) to refine logical consistency and coherence in generated responses.
Distillation of Large Model Reasoning into Smaller Models
DeepSeek-R1 further advances distillation techniques, enabling small-scale models to inherit reasoning capabilities from larger models. This is achieved by fine-tuning dense models such as Qwen and Llama with the reasoning data generated by DeepSeek-R1. Key takeaways from this process include:
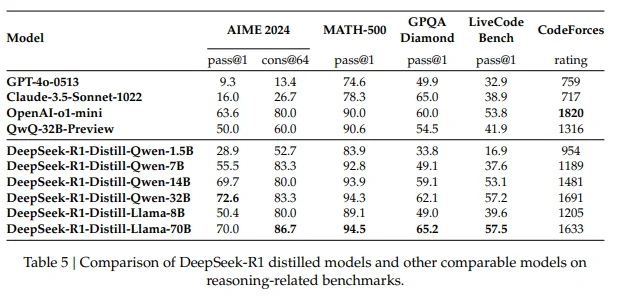
- Distillation Outperforms Direct RL on Small Models: Training small models from scratch using RL alone is computationally expensive and less effective compared to distillation from a larger model trained via RL.
- High-Performance Small Models: The distilled models, including DeepSeek-R1-Distill-Qwen-32B, achieve state-of-the-art reasoning benchmarks, surpassing many existing open-source models in math and logical reasoning tasks.
- Potential for Further Optimization: While RLHF and reinforcement learning can be applied to further enhance these distilled models, simple fine-tuning of distilled models already yields significant performance gains.
Reasoning-Oriented Reinforcement Learning (RL for All Scenarios)
DeepSeek-R1 applies reinforcement learning across multiple reasoning domains, making it more adaptable to various problem-solving tasks:
- Mathematical and Logical Tasks: Reinforcement learning is optimized for structured reasoning problems such as mathematics, coding, and logic-based challenges.
- General-Purpose Adaptability: RL is extended to more abstract domains, such as general question-answering and creative writing, ensuring that reasoning abilities are applicable beyond formal problem-solving contexts.
- Language Consistency Reward: Unlike earlier RL models that suffered from language mixing, DeepSeek-R1 includes a language alignment reward, ensuring responses remain within the user’s preferred language.
Comparison to Traditional Chain-of-Thought (CoT) Methods
While Chain-of-Thought (CoT) prompting has been the dominant method for enhancing reasoning, DeepSeek-R1’s reinforcement learning-based approach surpasses traditional CoT prompting in several ways:
- CoT prompting relies on explicit demonstrations, while DeepSeek-R1 allows models to learn structured reasoning through self-generated exploration and reinforcement.
- CoT models exhibit performance degradation with question format changes, whereas DeepSeek-R1 maintains robustness by optimizing logical structures through iterative reinforcement learning.
- Error Propagation in CoT: Chain-of-thought models may reinforce incorrect intermediate steps, whereas DeepSeek-R1’s reward modeling mechanism minimizes faulty reasoning chains.
Future Directions for LLM Reasoning with RL-Based Methods
The reinforcement learning-based techniques introduced by DeepSeek-AI pave the way for more sophisticated reasoning frameworks in LLMs. Key future developments include:
- Expanding RL Optimization to More Domains: Applying RL training beyond STEM fields to areas such as law, philosophy, and multi-turn dialogue reasoning.
- Enhancing Distillation Techniques: Combining reinforcement learning with advanced distillation techniques to further improve efficiency and reasoning depth in smaller models.
- Hybrid Models with Deliberative Alignment: Incorporating deliberative alignment and reward-guided reasoning strategies to refine LLM decision-making capabilities.
These new techniques establish DeepSeek-R1 as a milestone in the evolution of LLM reasoning, marking a potential shift from pattern-matching-based logic to genuinely emergent reasoning abilities through reinforcement learning.
Recap: Current Findings and Evaluations of LLM Reasoning
Recent research has produced increasingly sophisticated methods for evaluating LLM reasoning capabilities, revealing both promising advances and concerning limitations. This section examines key findings across specialized datasets and evaluation frameworks.
Specialized Datasets and Evaluation Frameworks
Mathematical reasoning has emerged as a crucial testing ground for LLM capabilities, spawning several specialized evaluation frameworks. Math word problems present significant challenges and serve as key benchmarks in evaluating LLM performance. The GSM8K (Grade School Math 8K) benchmark initially provided valuable insights but suffered from two key limitations: a fixed question set and potential data contamination issues that could artificially inflate performance metrics (Mirzadeh et al., 2024).
To address these limitations, GSM-Symbolic introduced a more rigorous evaluation methodology using symbolic templates to generate diverse variants of mathematical problems. This approach enables more granular analysis of model behavior under controlled variations. Significantly, when evaluating models on GSM-Symbolic, researchers observed that performance could drop by up to 65% compared to the original GSM8K, even when only numerical values were altered in otherwise identical problems (Mirzadeh et al., 2024).
The GSM-NoOp dataset further probes LLM reasoning limitations by introducing seemingly relevant but ultimately irrelevant information to problems. For example, when presented with problems containing extraneous numerical information (such as noting that “five kiwis were smaller than average” in a counting problem), models consistently incorporated these irrelevant numbers into their calculations, revealing a fundamental weakness in distinguishing crucial information from distractors (Mirzadeh et al., 2024).
Meanwhile DeepSeek-R1 has demonstrated performance surpassing prior benchmarks like GSM8K and GSM-Symbolic. By applying RL-based reasoning optimization, DeepSeek-R1 maintains robust performance even when numerical values are altered, mitigating the pattern dependency seen in prior evaluations.
While the GSM-NoOp dataset was not explicitly referenced in DeepSeek-R1's paper, its broader findings align with the idea of reducing susceptibility to distractors. DeepSeek-R1’s evaluation suite introduces language-controlled problem-solving tests that help the model correctly distinguish relevant from irrelevant information, addressing a key limitation of prior LLM reasoning benchmarks.
Performance Variability and Pattern Dependency
Analysis of model behavior across these datasets has revealed several critical insights:
- Performance Variance: LLMs exhibit significant inconsistency when responding to different instantiations of the same fundamental problem. McCoy et al. (2024) demonstrated that even state-of-the-art models show marked performance degradation when handling low-probability sequences, even in deterministic tasks where probability should be irrelevant.
- Pattern Matching Limitations: The observed performance patterns strongly suggest that LLMs rely more on sophisticated pattern matching than true logical deduction. This becomes particularly evident in cases where:
- Numerical values are altered while maintaining the same logical structure
- Problem presentation deviates from common training patterns
- Multiple reasoning steps must be coordinated
On the other hand analysis of DeepSeek-R1’s performance has revealed key improvements over earlier models:
- Reduced Performance Variability: Unlike prior models that showed significant degradation on low-probability sequences, DeepSeek-R1 exhibits consistent problem-solving ability across diverse prompts, thanks to its reinforcement learning-driven self-evolution.
- Enhanced Logical Deduction: Traditional models often relied on pattern matching and failed when problems were presented in uncommon formats. DeepSeek-R1 prioritizes reasoning-based optimization over memorization, making it more adaptable.
- Complexity Resilience: Unlike earlier models whose accuracy declined as problem complexity increased, DeepSeek-R1 sustains high accuracy even in multi-step logical reasoning tasks.
Sensitivity to Task Complexity and Irrelevant Information
Research has identified two key dimensions of fragility in LLM reasoning:
- Complexity Sensitivity: Performance consistently degrades as task complexity increases, particularly when problems require multiple logical steps. Mirzadeh et al. (2024) found that accuracy decreases substantially with each additional clause in mathematical word problems, indicating limitations in maintaining logical consistency across extended reasoning chains.
- Distractor Susceptibility: The GSM-NoOp evaluations reveal a concerning tendency for models to incorporate irrelevant information into their reasoning processes. This susceptibility persists even when models are provided with multiple examples demonstrating the irrelevance of certain information, suggesting a fundamental limitation in conceptual understanding rather than merely inadequate training.
Probability Effects in Reasoning
Perhaps most significantly, research has uncovered a pervasive influence of probability on LLM reasoning behavior. McCoy et al. (2024) demonstrated that even in deterministic tasks, model performance is strongly influenced by:
- Answer Probability: Models achieve higher accuracy when the correct answer is a high-probability sequence, even in cases where probability should be irrelevant to the solution.
- Task Frequency: Performance improves markedly on tasks that appear frequently in training data, even when compared to logically equivalent but less common task variants.
- Input Probability: While less pronounced than output effects, models also show sensitivity to the probability of input sequences, further supporting the hypothesis that their reasoning processes are fundamentally shaped by the probabilistic nature of their training.
These findings collectively suggest that current LLM reasoning capabilities, while impressive in certain contexts, remain fundamentally constrained by their training paradigm and exhibit significant limitations in achieving truly robust, generalizable reasoning.
That said, DeepSeek-R1 mitigates this effect through reinforcement-driven reasoning refinement, ensuring:
- Improved Accuracy on Low-Probability Outputs: Traditional models perform best when solutions follow high-probability distributions. DeepSeek-R1 corrects for this bias by rewarding correct reasoning chains rather than probabilistic tendencies.
- Better Handling of Rare and Uncommon Tasks: Unlike previous models, DeepSeek-R1 does not over-rely on task frequency during training, allowing it to generalize more effectively to uncommon and out-of-distribution tasks.
Challenges and Future Directions in LLM Reasoning
Bridging the Gap with Human and Commonsense Reasoning
A fundamental challenge in advancing LLM capabilities lies in moving beyond sophisticated pattern matching toward more robust and generalizable reasoning that better approximates human cognitive processes. Current research demonstrates that even state-of-the-art models exhibit significant limitations in their ability to perform consistent logical reasoning across varying contexts (McCoy et al., 2024).
The gap between human and LLM reasoning becomes particularly apparent in several key areas:
- Generalization beyond training patterns
- Consistent application of logical principles
- Handling of novel or out-of-distribution scenarios
- Integration of multiple reasoning steps
As Mirzadeh et al. (2024) demonstrate through their GSM-Symbolic evaluations, current models show marked performance degradation when faced with even minor variations in problem presentation, suggesting fundamental limitations in their conceptual understanding.
Addressing Evaluation Limitations
The challenge of effectively evaluating LLM reasoning capabilities extends beyond simple accuracy metrics. Current research highlights several critical areas requiring attention:
Data Contamination: Popular benchmarks like GSM8K face potential contamination issues, necessitating more robust evaluation frameworks. The development of frameworks like GSM-Symbolic represents progress in this direction, but further work is needed to ensure reliable assessment of model capabilities (Mirzadeh et al., 2024).
Comprehensive Evaluation Metrics: Moving beyond single-point accuracy measurements toward metrics that capture reasoning behavior, robustness, and performance across varying difficulty levels is crucial. This shift is exemplified by recent work on deliberative alignment, which considers multiple aspects of model performance simultaneously (Guan et al., 2024).
Enhancing Safety and Reliability
As LLMs become increasingly integrated into critical applications, ensuring their safe and reliable operation becomes paramount. Recent advances in deliberative alignment demonstrate promising progress in this direction, achieving improvements in both safety and task performance (Guan et al., 2024). However, significant challenges remain in:
- Ensuring consistent adherence to safety specifications
- Maintaining performance while implementing safety constraints
- Developing robust defenses against adversarial attacks
- Building systems that can reliably distinguish relevant from irrelevant information
Sourcing High-Quality Data
The challenge of sourcing appropriate training data for reasoning capabilities remains one of the key bottlenecks in advancing LLM capabilities. The importance of code data, the need for high-quality complex data, and the challenges of verification all contribute to making this a challenging problem requiring careful consideration and continued research.
The findings from recent research suggest that future work should focus on:
- Developing better methods for generating high-quality hybrid data
- Creating more efficient verification processes
- Understanding the optimal balance between different types of training data
- Investigating new sources of reasoning-focused training data
These challenges represent significant opportunities for advancement in machine learning, particularly as we continue to push the boundaries of what's possible with large language models. At Kili Technology, we combine human expertise and AI-powered workflows to build complex data that answers the needs of foundation model builders to deliver next-level AI.
Want to explore new approaches in building reasoning datasets? Send us a message!
Contact Us
Citations
Aryabumi, V., Chen, Z. Z., Ye, X., Yang, X., Chen, L., Wang, W. Y., & Petzold, L. (2024). Unveiling the impact of coding data instruction fine-tuning on large language models reasoning.
Zhang, X., Su, Y., Ma, R., Morisot, A., Zhang, I., Locatelli, A., Fadaee, M., Üstün, A., & Hooker, S. (2024). To code, or not to code? Exploring impact of code in pre-training.
Guan, M. Y., Joglekar, M., Wallace, E., Jain, S., Barak, B., Heylar, A., Dias, R., Vallone, A., Ren, H., Wei, J., Chung, H. W., Toyer, S., & Heidecke, J., & Beutel, A., & Glaese, A. (2024). Deliberative alignment: Reasoning enables safer language models. arXiv preprint arXiv:2412.16339.
McCoy, R. T., Yao, S., Friedman, D., Hardy, M. D., & Griffiths, T. L. (2024). Embers of autoregression show how large language models are shaped by the problem they are trained to solve. Proceedings of the National Academy of Sciences, 121(41), e2322420121.
Mirzadeh, I., Alizadeh, K., Shahrokhi, H., Tuzel, O., Bengio, S., & Farajtabar, M. (2024). GSM-Symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229.
Prabhakar, R., Dua, D., & Agrawal, R. (2024). Deciphering the Factors Influencing the Efficacy of Chain-of-Thought: Probability, Memorization, and Noisy Reasoning. arXiv preprint arXiv:2407.01687v2.
DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv. https://arxiv.org/abs/2501.12948
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv:2201.11903.
Frequently Asked Questions
What is LLM reasoning?
LLM reasoning refers to the ability of large language models to perform multi-step logical inference, draw conclusions from premises, solve problems that require planning, and maintain coherent chains of thought. It's one of the most studied and debated capabilities in modern AI research.
Can LLMs actually reason, or do they just pattern-match?
This is an active debate. LLMs can produce outputs that look like reasoning — solving math problems, writing code, making logical deductions — but research shows they often rely on learned patterns rather than generalizable reasoning. Performance degrades on novel problem structures that differ from training data, suggesting current reasoning is more interpolation than genuine inference.
What is chain-of-thought reasoning?
Chain-of-thought (CoT) is a prompting technique where the model is encouraged to produce intermediate reasoning steps before arriving at a final answer. Research has shown that CoT significantly improves performance on math, logic, and multi-step reasoning tasks. Variants include zero-shot CoT ("let's think step by step") and few-shot CoT with worked examples.
What are reasoning models like o1 and DeepSeek-R1?
Reasoning models are LLMs specifically trained to produce extended chains of thought before answering. They use reinforcement learning to develop internal reasoning processes, often generating long "thinking" traces. Models like OpenAI's o1 series and DeepSeek-R1 have achieved significant improvements on math and coding benchmarks, though at higher inference cost and latency.
What are the main limitations of LLM reasoning?
Key limitations include brittle performance on out-of-distribution problems, sensitivity to problem framing and wording, difficulty with true logical deduction (especially negation and counterfactuals), inability to reliably self-verify, and the tendency to produce confident but incorrect reasoning chains. Performance also degrades as problem complexity increases beyond training distribution.
How do you evaluate LLM reasoning?
Common benchmarks include GSM8K (math word problems), MATH (competition mathematics), ARC (abstract reasoning), GPQA (graduate-level questions), and HumanEval (code generation). However, benchmark contamination is a growing concern — models may be trained on similar problems. Domain-specific evaluation with novel problems remains the most reliable approach.
How does training data quality affect LLM reasoning?
Reasoning capability is heavily influenced by the quality and diversity of reasoning examples in training data. Models trained on high-quality step-by-step reasoning traces (mathematical proofs, code with explanations, logical arguments) develop stronger reasoning skills. This is why synthetic data generation for reasoning — producing verified step-by-step solutions — has become a key focus for frontier labs.
Build the Evaluation Data Your Reasoning Models Need
Kili Technology helps teams create domain-specific evaluation datasets for testing LLM reasoning in production contexts. Whether you're evaluating chain-of-thought outputs, scoring multi-step problem solving, or building custom reasoning benchmarks, the platform provides the annotation tools, multi-reviewer workflows, and quality controls that rigorous evaluation requires.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
