
.png)

_logo%201.svg)


AI Summary
Machine learning applications are only as accurate as the data they are trained on. Data scientists train the underlying model with labeled data to build a robust machine-learning application. Data labeling is a vital process where human annotators tag training data or assets with descriptions to help machine learning models identify patterns and make predictions with better accuracy.
Traditionally, companies rely entirely on human annotators to label data when producing training datasets. However, growing complexities and other factors have encouraged companies to use data labeling tools to augment human labelers. Sole dependent on human annotators is no longer sufficient to produce high-quality training data at the desired pace and cost.
In this article, we’ll explore how labeling tools benefit companies in various areas and their common applications. More importantly, we’ll dispel certain myths and misassumptions often associated with labeling.
What is a Data Labeling Tool?
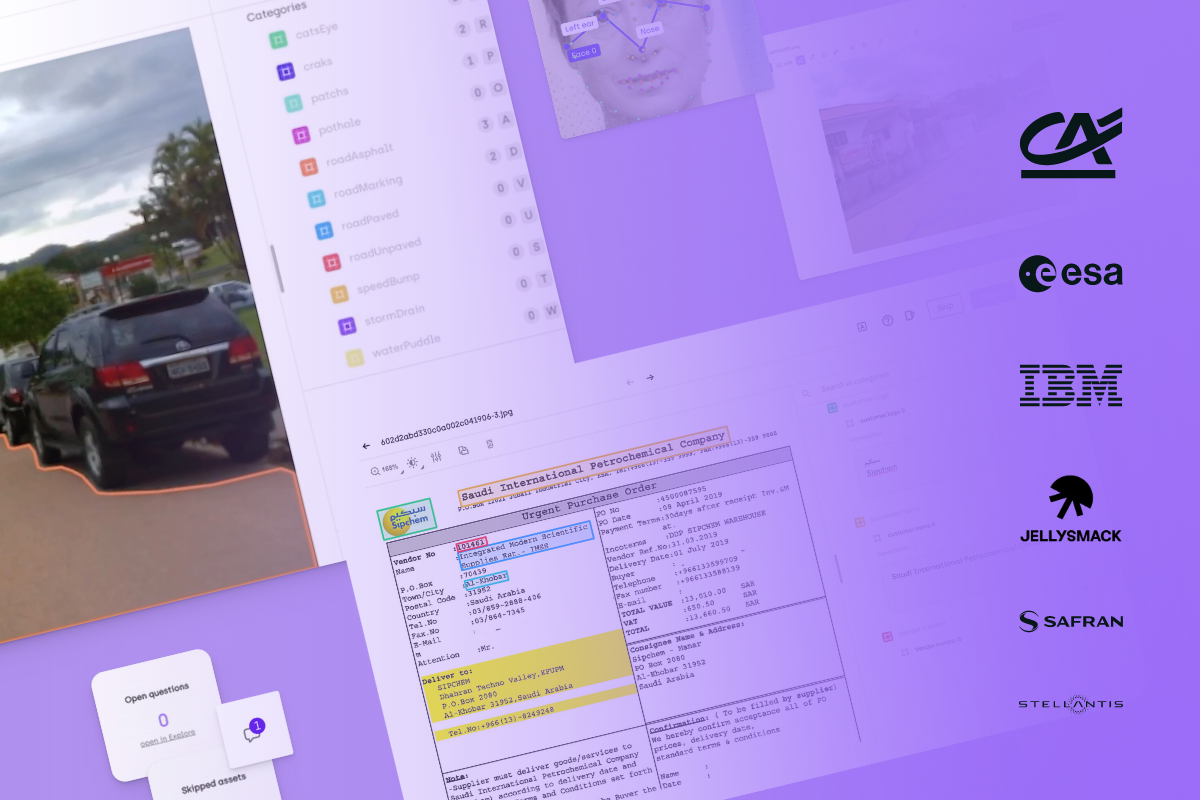
A data labeling tool is software that allows human annotators to tag raw data with labels for training ML models. Subject matter experts use data labeling tools to assist them in creating large volumes of training data reliably. Then, data scientists inspect the labeled data for accuracy before training the models. They can do so with automated workflows that advanced data labeling tools provide.
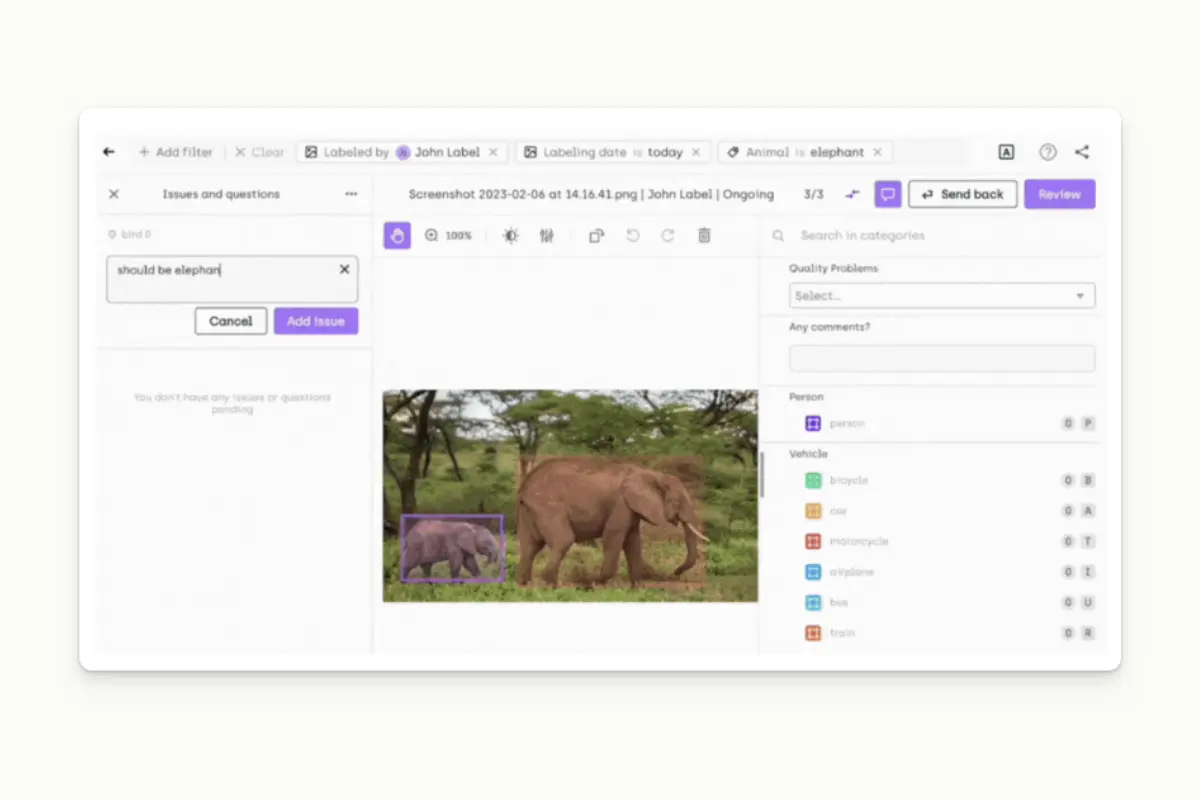
Labelers can ask questions directly from the interface
Data labeling tools are not designed to replace human annotators. Instead, such tools put humans in the driving seat to overcome common challenges in data labeling. Data labeling tools allow labelers to be more accurate when tagging different types of raw data. They play pivotal roles in training ML models for natural language processing (NLP), computer vision modeling, image recognition, and other advanced applications.
Over the years, data labeling tools have evolved to meet changing dynamics in artificial intelligence (AI) applications. With larger machine learning models, there are demands for more accurate, user-friendly, and integration-friendly data labeling tools. For example, Kili Technology is a powerful data labeling software that lets you annotate text, video, images, and conversations with interactive segmentation, AI-assisted pre-labeling, analytics, and other capabilities.
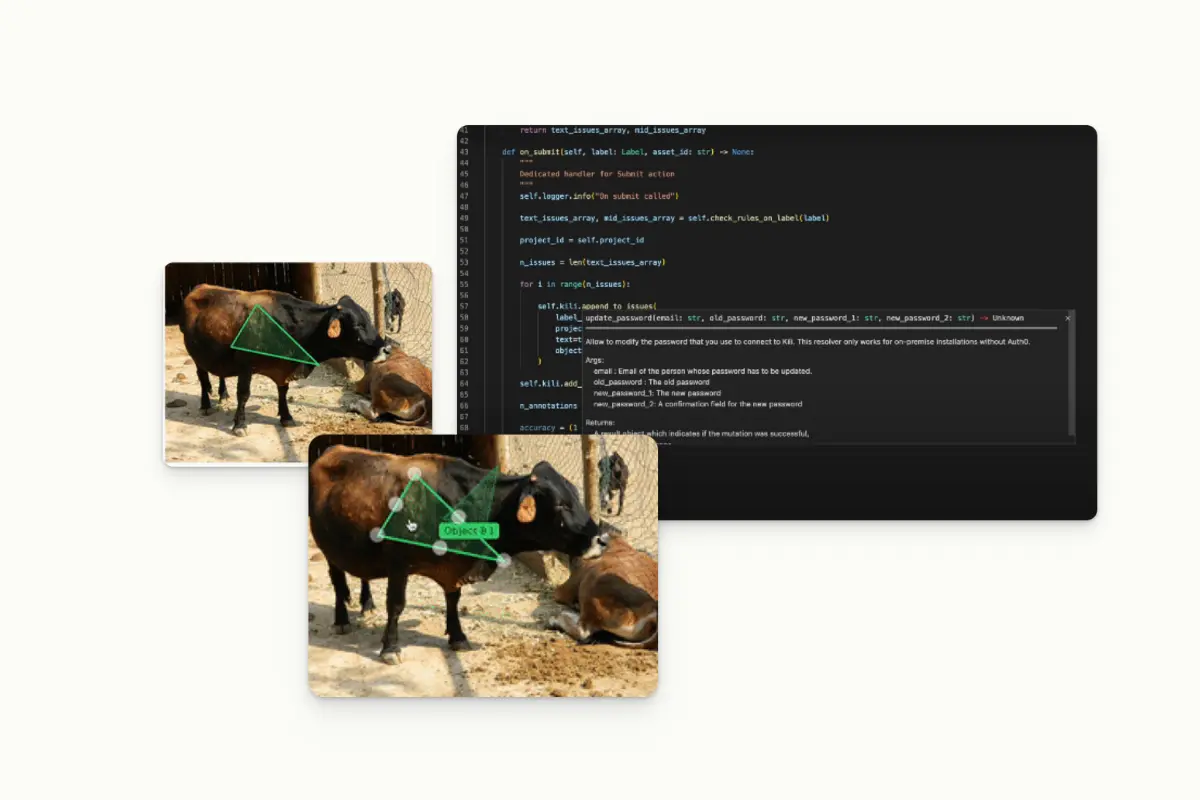
Programmatically spotting error using Kili Technology platform
Note that if you want to deepen your understanding of data labeling software, you can refer to our in-depth data labeling tool guide.
Frequent Use Cases for Data Labeling Tools
Data labeling tools allow data scientists to prepare training data from unstructured data without being constrained to conventional restrictions. In machine learning, high-quality training datasets take enormous effort to produce at scale. Data scientists often need help ensuring accurate, bias-free, consistent, and time-produced data. Also, companies grapple with increasing people cost, scalability, efficiency, and privacy concerns, particularly when handling sensitive datasets.
We share several common tasks that data labeling software can undertake to provide a more efficient, robust, and accurate data labeling workflow.
Managing Annotation Tasks
Each labeler might be required to perform different annotation tasks when preparing training samples. For example, they transcribe an audio asset to generate the textual data. Then, they perform tasks like named entity recognition, named entity relation, or classification before submitting the labeled data for review.
With a data labeling tool, you can organize labeling tasks systematically and assign them to respective labelers. Some data labeling tools allow you to add nested tasks by asking secondary questions to improve labeling precision.

Nested tasks
Coordinating Data Labelers at Scale
Data labeling is a labor-intensive chore that requires the effort of a large group of human annotators. Such tasks overwhelm companies if they rely on manual coordination. Instead, companies use data labeling tools to distribute raw data assets more systematically to human labelers.
Data labeling tools provide flexibility in determining how labelers receive their tasks from the project manager. For example, you can queue labeling tasks on a first-in, first-out basis or assign them to specific labelers. Some data labeling tools allow you to set priorities where higher-priority jobs take precedence during distribution.
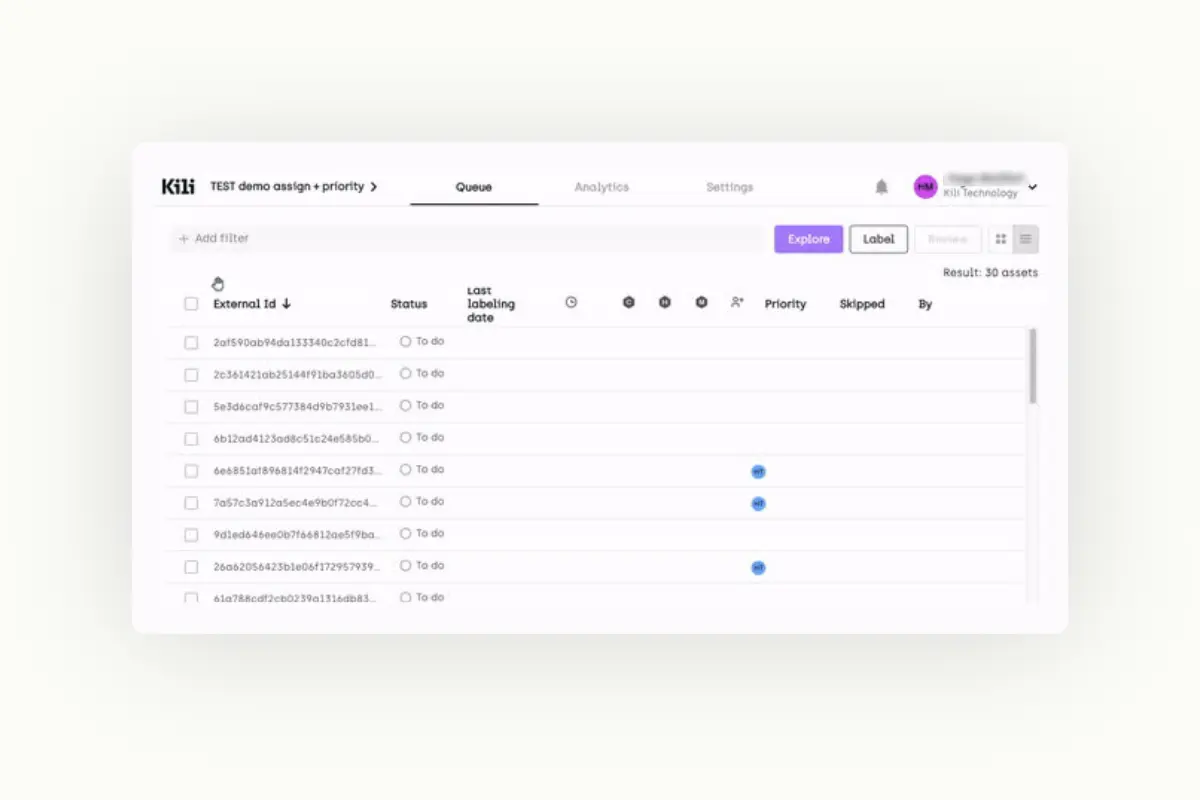
Assigning priorities on Kili Technology platform
Reducing Data Labeling Duration
Data labeling is a tedious process that consists of repetitive tasks. With strictly human labelers, companies risk consuming too much time and resources they couldn’t afford, particularly when annotating images and videos. Therefore companies turn to top data labeling tools like Kili Technology for a more efficient approach.
Data labeling software assists human labelers in completing complex and laborious tasks. For example, labelers use interactive tools for semantic segmentation when masking specific objects for training computer vision models. Likewise, they use tracking tools to pinpoint object boundaries for object detection systems.
Facilitating Review Process
Reviewers play essential roles in the data labeling workflow. They are gatekeepers responsible for ensuring the labeled data passes specific requirements before approving them for training models. Using a data labeling platform allows them to manage their tasks better.
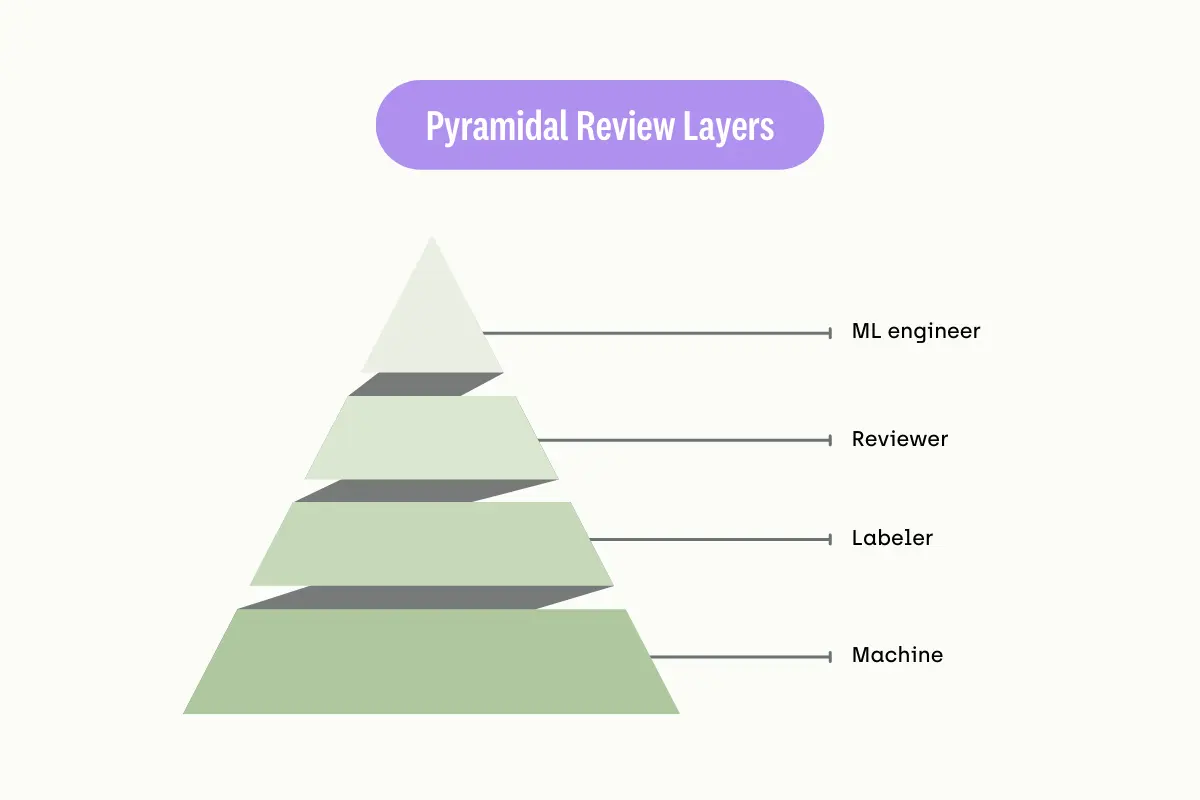
For example, an advanced labeling platform allows reviewers to filter the labeled assets with different criteria. Then, it displays the results in a well-organized table. This enables the reviewers to inspect the data, approve it manually, or return it to the queue for relabeling.

Filtering assets' metadata
Improving Data Labeling Quality
We’ve stressed that the data quality of labeled samples directly affects the machine learning model that trains on it. Therefore, companies use data labeling tools to improve consistency and reduce human errors. In this respect, data labeling solutions help companies achieve better quality control in several ways.
- Automated distribution minimizes human intervention when assigning tasks to reviewers. Moreover, data labeling tools ensure reviewers do not receive overlapping tasks unless specified explicitly.
- Project managers can append instructions to tasks, while labelers raise questions within the labeling dashboard to clarify doubts. Likewise, reviewers can provide feedback to reviewers more transparently to resolve issues.
- Data labeling platforms provide analytics, which helps project managers to identify shortcomings and improve on them.
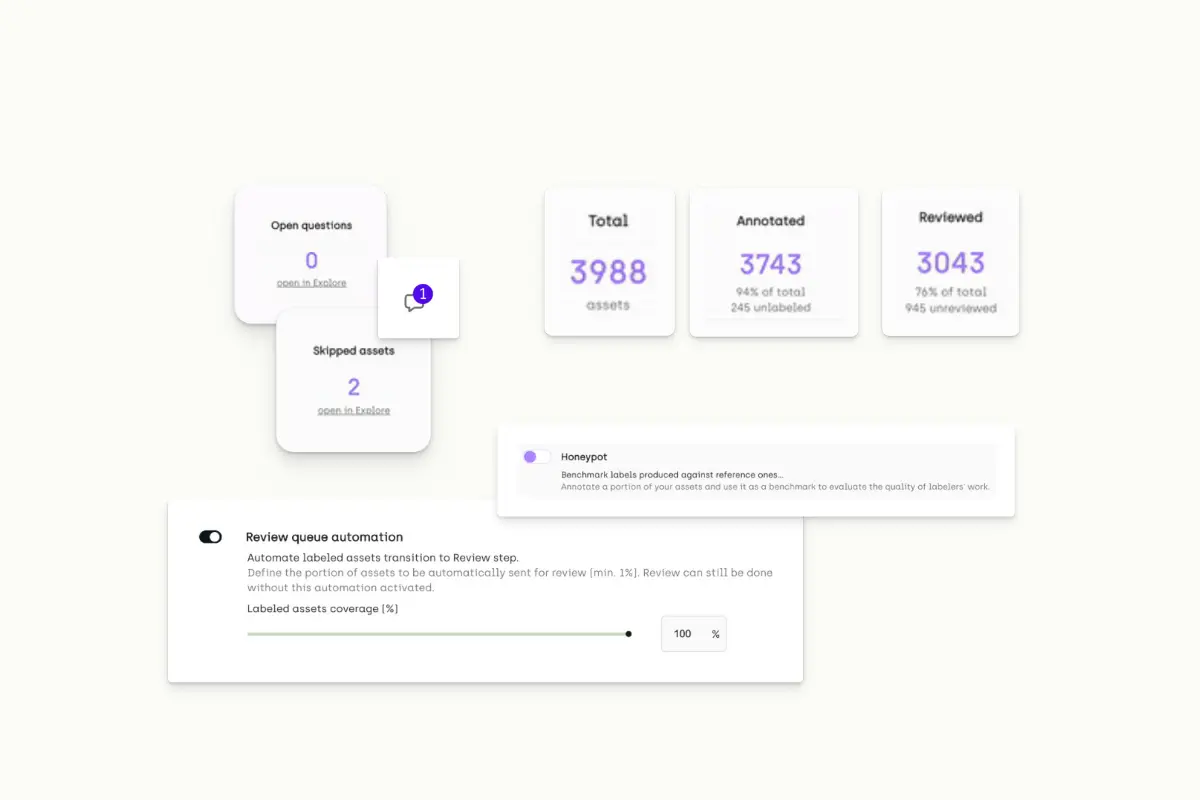
Data quality monitoring capabilities of Kili Technology platform
Securing Data Labeling Pipeline
Security is a primary concern for many company, notably those working with sensitive data or proprietary technology. HGH, a security industry player, is a good example of this. As Axel Davy, Image Processing Engineer, outlined it: "Data security is critical to HGH. We are dealing with all types of data, some that are classified. We also need to protect our R&D as this is what puts us ahead of the competition.”
In a machine learning context, security includes data labeling, where manual storage, distribution, and collection of training data expose organizations to data risks. Robust data labeling solutions are designed to secure the entire machine learning pipeline from unauthorized access.
Some data labeling platforms provide role-based access control to ensure labelers, reviewers, project managers, and administrators are granted different access rights. Moreover, such platforms enforce strict security measures, such as encryption and multi-factor authentication, to prevent privacy breaches.
Kili Technology was one of the few actors able to provide us with the level of security and data governance we needed.

Axel Davy
Image Processing Engineer at HGH
Kili Technology ensures your data safety and privacy
Streamlining Data Movement
Data labeling often involves collecting and distributing raw data to multiple parties. Large data movement is complex and requires tight coordination that conventional workflow couldn’t provide. Modern data labeling tools come with integration-friendly features that abstract the underlying complexities of human operators.
For example, organizations can store raw data in cloud storage and automate retrieval to the data labeling platform. Once labeled, they can export the training samples to the appropriate machine learning stack in the supported format.
Export data from Kili Technology platform
Misunderstanding of the Complexity Of Labeling
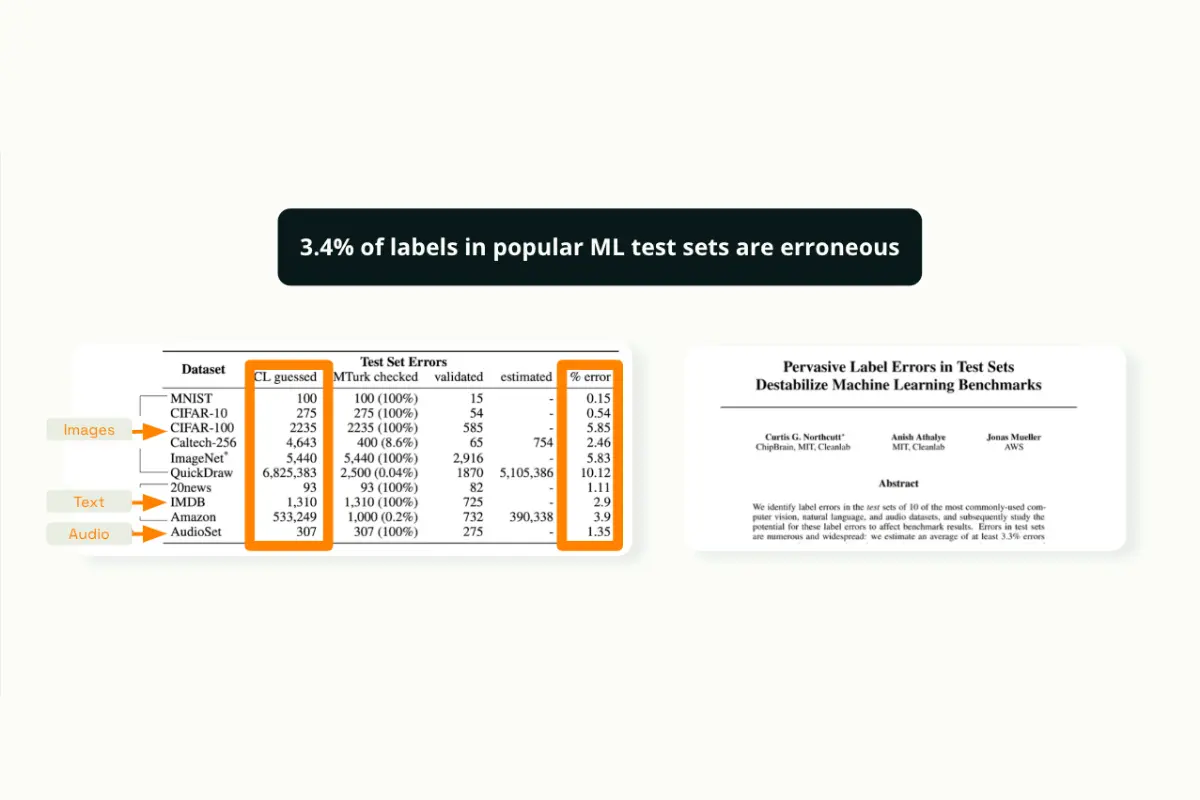
Did you know that even the famous MNIST Dataset has 3,4% errors? As you might imagine, if such a popular and quoted dataset can carry these errors, organizations are also likely to underestimate or misunderstand what data labeling entails. Similarly, they might overlook its role in developing machine learning applications.
Such tendencies often lead to project delays, cost overruns, or performance degradation of the deployed model. We share several common misunderstandings that affect business stakeholders below.
Machine Learning Models are smart enough on their own
Machine learning models are designed to mimic how humans make decisions. However, assuming they are naturally intelligent once these machine-learning models are built is a mistake. Generative Pre-Trained Transformer (GPT-3), a base model for many generative AI applications, was trained with more than 175 billion parameters and possibly terabytes of data before it could converse like humans.
Learn More
Did you know that Large Language Models such as ChatGPT and GPT can be used to reduce your data labeling time by 50%? Or that they can be leveraged for asset creation or QA engineering? Enroll in our on-demand session to explore the potential of these models for data labeling.

Therefore, companies must do away with the assumption that base models are proficient in predicting, analyzing, or classifying data with little or no training. While data scientists can apply different base models to identify tiny objects, similar objects, and abstract objects, they must first train the models with high-quality data.
Today, most organizations use pre-trained models to shorten development time. Even so, you must train the models with sufficient business data to fit your industry and business goals. For example, Eidos-Montréal fine-tuned an NLP model to analyze customers' sentiments by picking up nuances specific to gamers.
In-house Data Labeling Tools are sufficient
Some companies perform data labeling with their in-house tools. While such move grants companies more control of the development pipeline, relying on in-house data labeling solutions may not be enough. Your AI application might expand to include other machine-learning tasks as your business grows.
JellySmack is an excellent example of this phenomenon. The company uses machine learning technology to analyze its performance on Facebook. When the social video company scales its presence to YouTube, Instagram, and other platforms, it must train its language model for more use cases. JellySmack realizes the limits of in-house data labeling tools and how committing more resources to develop them is untenable. That’s how they chose to partner with a dedicated data labeling provider. Note that if you face a similar situation, you can refer to our dedicated article: Build. vs. Buy. your data labeling platform.
Minimum Data Labeling is Required
Understandably, data labeling is an arduous process if companies rely on conventional methods. Hence, some companies might choose to reduce the training sample size to save time and cost. In doing so, they risk the machine learning model to performance issues. Besides failing to categorize data accurately, the model might be subjected to sampling bias because it was not trained with adequate data.
Model accuracy is vital when companies deploy AI applications to streamline business processes. For example, a computer vision model must be able to identify different damaged car parts to assess damage claims accurately. That’s why a global insurance company insisted on a data labeling solution capable of annotating different types of cars, body parts, damages, and severity.
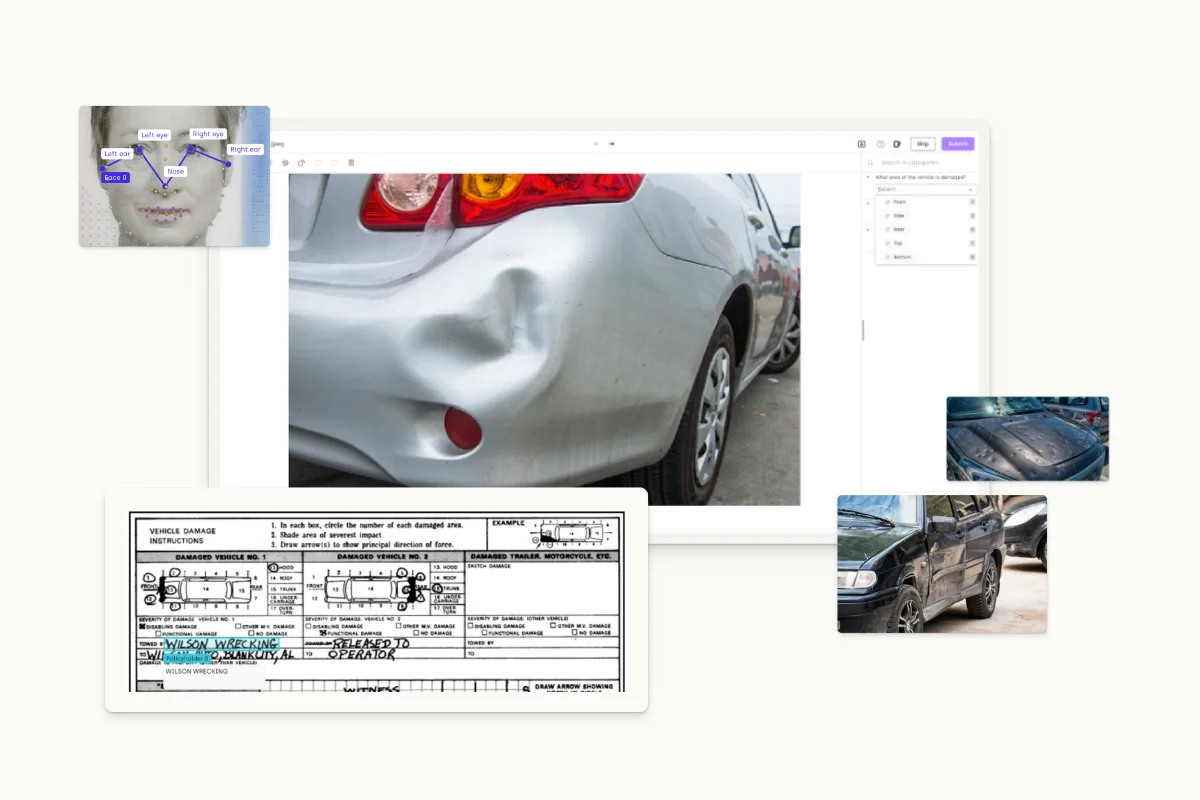
Data labeling tasks performed by an insurance company
Few Collaborators Involved
Another equally devastating practice is to limit the size of labelers and reviewers when labeling data. This might be driven by cost concerns or overlooking the impact of human feedback on machine-learning models. Reducing the size of collaborators often leads to undetected human errors, which make their way to the production model and affect the system it powers.
For example, human bias might arise if the team of collaborators is too small to represent the demographics of banking customers. As a result, the model will be unfair in approving or rejecting financial applications based on the skewed training sample it trained on. A large European bank is keen to avoid such incidents by prioritizing collaboration between large groups of data scientists and annotators to create datasets in various languages.

Results achieved by a bank using Kili Technology for its data labeling
Reducing Costs is a Top Priority
Deploying advanced deep learning applications is expensive, and companies strive to minimize costs, especially considering the current economic context. Unfortunately, some companies take the wrong approach when they reduce their efforts to produce quality training data. With questionable training sample quality, the AI model will naturally produce disappointing results.
Rather than sacrificing quality for cost, companies like HGH turned to intelligent data labeling solutions to do more with less. They used a data labeling platform to produce 30% more quality training data in 2 months instead of 2 years. Moreover, their team spent half the time than expected when reviewing the labeled data, leading to better use of people resources.
Why do Companies Decide to Use Data Labeling Tools?
Companies seeking to scale their machine-learning capabilities eventually turn to data labeling solutions. Undertaking such laborious chores manually or without intelligent tools is not feasible in the long run. If they insist on the status quo, companies risk losing out in a competitive marketplace where speed, cost, and performance dominate AI offerings.
If you need more motivation to switch to data labeling tools, consider these factors.
Increase Productivity
Data labeling tools help companies increase productivity when preparing training samples and managing their internal workforces. Imagine if companies delegate data labeling to their data scientists and machine learning engineers. This would occupy the expert’s valuable time and prevent them from doing what matters – innovating next-generational AI solutions.

Results obtained by a global insurance company using Kili Technology to annotate data for NLP purposes
Besides, the benefits of an accurate AI model produced from quality datasets trickle down to the business processes.
In practice, productivity achieved through data labeling platforms such as Kili Technology can be striking. A global insurance company using Kili Technology to annotate data for a natural language processing (NLP) model that supports real-time claim processing illustrates this very well. By using data labeling software, the company is rewarded with at least 5 times yearly FTEs savings and a significant productivity boost. Thomas, Chief of Operating Officer of the company, recalls what it was like before using a data labeling platform when customers demanded "speed and transparency on the status of their documents – but [his team] couldn’t provide it". Quickly after his company decided to employ data labeling software, the positive impact on satisfaction spoke for itself:
(...) It’s the impact that matters. We don’t only scale up our processes to be extremely efficient and reduce our costs, but we also increase the satisfaction of both customers and employees towards the bank.
Thomas
Chief of Operating Officer
User friendly-interface
Without an intuitive interface, reviewers and labelers face a steep learning curve navigating the data labeling software. Every additional step or confusion when tagging or classifying data accumulates into considerable delays for companies. On the other hand, helpful features, such as the bounding box, semantic segmentation, and tracking, allow labelers to process video samples or other formats effortlessly.
On Kili Technology, these features are arranged to support the data labeling process. According to Vincent, the Artificial Intelligence Director of a global insurance company, these features, in addition to complementary capabilities such as shortcuts, dramatically enhance the labeling experience.
It was very easy to iterate the labeling process to correct the work of our AI when it was wrong. We were able to import predictions by the AI very quickly to the labeling interface, and the features and the shortcuts within Kili allowed us to modify them easily."
Vincent
Artificial Intelligence Director of a global insurance company
Accurate Data Labeling
Companies are aware that strictly relying on human labelers subjects the training dataset to errors. The solution is to apply human-in-the-loop labeling, where human collaborators work closely with AI-assisted software to produce more accurate samples. A French banking institution, which took this approach, increased its AI model’s accuracy by 5%. On top of this, Guillaume, Director of Technology and Innovation of the bank, also witnessed positive effects on cost and customer satisfaction.
"(...) We don’t only scale up our processes to be extremely efficient and reduce our costs, but we also increase the satisfaction of both customers and employees towards the bank."
Guillaume
Director of Technology and Innovation
Improve the Quality Of The Output Dataset
Several factors influence the training sample's quality, including data size, diversity, labeling accuracy, consistency, and other human-induced processes. Companies use data labeling platforms to minimize variance in factors affecting output quality.
Labeling Guidelines and QA Processes
Collaborators can work cohesively and guided by consistent guidelines, metrics, and tools when working with data labeling software designed with simplicity.
For example, a global manufacturing company chose Kili Technology because of our ability to provide a customizable interface while keeping workflows simple. This helped the manufacturer to streamline the data labeling process to their business needs. Moreover, Kili Technology delivers online learning to ensure all collaborators start with a common understanding of the labeling workflow.
Outsourcing Options
Companies might consider contracting data labeling to external agencies when they sign up for a data labeling platform. Rather than undertaking the resource-consuming task alone, stakeholders consider partnering with a reliable data labeling provider. By opting for a collaborative-friendly solution, companies can work with third-party labelers and experts in various disciplines.
Labeling Workforce Network
Some companies might turn to crowdsourcing labelers to create training datasets. Unfortunately, this approach has some glaring disadvantages. For example, each labeler might stick to their respective workflow, which leads to inconsistent output quality. Besides, in-house managers face challenges in coordinating the annotation tasks without a reliable platform. For such reasons, VitaDX, a healthcare company, used Kili Technology to oversee and streamline collaborations between project managers, labelers, reviewers, and healthcare professionals.
In contexts as delicate as medical diagnosis, labeling discrepancies due to processes or workforce cannot be allowed. As Abderrahmane, Data Project Manager of VitaDX, explains it: building an artificial intelligence model that will determine whether a person is sick [and] will impact the life of a human being.” As he words it, in such context, the model (and therefore, the underlying data annotation that will build the dataset) must “be accurate."
Quality should be the first to prioritize since the beginning – data preparation.
Abderrahmane
Data Project Manager of VitaDX
Note that if your company needs let its ML team focus on the model rather than on the labeling, professional services can be an excellent option. These services notably provide data labeling project management and access to a network of trusted data labeling partners.
On-Demand Project Management
Data labeling is an unfamiliar discipline for many companies, particularly those in non-technological industries. Therefore, partnering with data labeling providers allow companies to engage labeling teams on demand. Instead of assembling reviewers and labelers independently, companies can request such collaborations from labeling providers like Kili Technology.
Scalability
Cloud capabilities enable organizations to scale their presence across regions quickly. Likewise, they must expand their AI capabilities as they acquire and store more data from the cloud. This means training or retraining evolving models with high-quality datasets. However, conventional or on-premise data labeling software proves to be a bottleneck that hampers growth.
Instead, companies seek cloud-agnostic data labeling solutions capable of transferring raw data from major cloud providers. At the same time, they place importance on security measures embedded in such tools to safeguard corporate data. Marion Beaufrère, Head of Product at Luko, testifies how automation features proved helpful for scaling its solution for hundreds of thousands of policyholders in various countries:
"Kili Technology allows us to label every invoice we receive from our customers, including the veterinary invoices for our insured dogs and cats. This labeling has resulted in a significant improvement in the accuracy of our data model. Therefore, we’re more efficient in our automation. Not having to do this annotation ourselves – internally – made our improvement of automation accuracy much faster. Thanks to this, we can now quickly absorb a growing volume of claims”
Marion Beaufrère
Head of Product @ Luko
Cost-effectiveness
Naturally, organizations seek to reduce costs to remain competitive and increase profitability. As mentioned, taking the wrong approach can compromise the output dataset’s reliability. Instead, companies use data labeling tools to achieve cost-effectiveness in the long run. Kili Technology is one of the best data labeling tools engineered to produce high-quality training data for machine learning. By choosing Kili Technology's data labeling software, a European healthcare institution reduced operational costs by 40% with a more precise AI-powered eye screening system. As Alexander, CTO of the company sums it up:
"[Kili Technology is] very convenient and simple to use. And when it’s simple to use, you get to be extremely more productive. No more headaches.”
Alexander
CTO
Final Thoughts
At this point, you might still be second-guessing whether or not you should use a data labeling tool. As a company that helps ML teams daily, we understand where you stand. Given the current economic context and the constant pressure to deploy your models faster, it can be tough to decide. if you’re currently assessing different data labeling software vendors, feel free to steal our free Excel template.
Learn More
Download our free excel template on how to choose your data labeling platform, and get instant access to the features checklist that will help to accelerate your data labeling.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
