
.png)

_logo%201.svg)


AI Summary
If you're familiar with artificial intelligence and machine learning, you probably already know it: data labeling tools are the unsung heroes of any successful ML models or artificial intelligence-powered apps. Data annotation software enables you to label data efficiently and accurately, freeing time to focus on building better models and delivering value to your organization.
In this article, we'll explore the definition of such a tool, how it works, and why it is crucial to the success of machine learning projects.
Keep reading to learn how data labeling software can help you unlock the power of your machine-learning workflow.
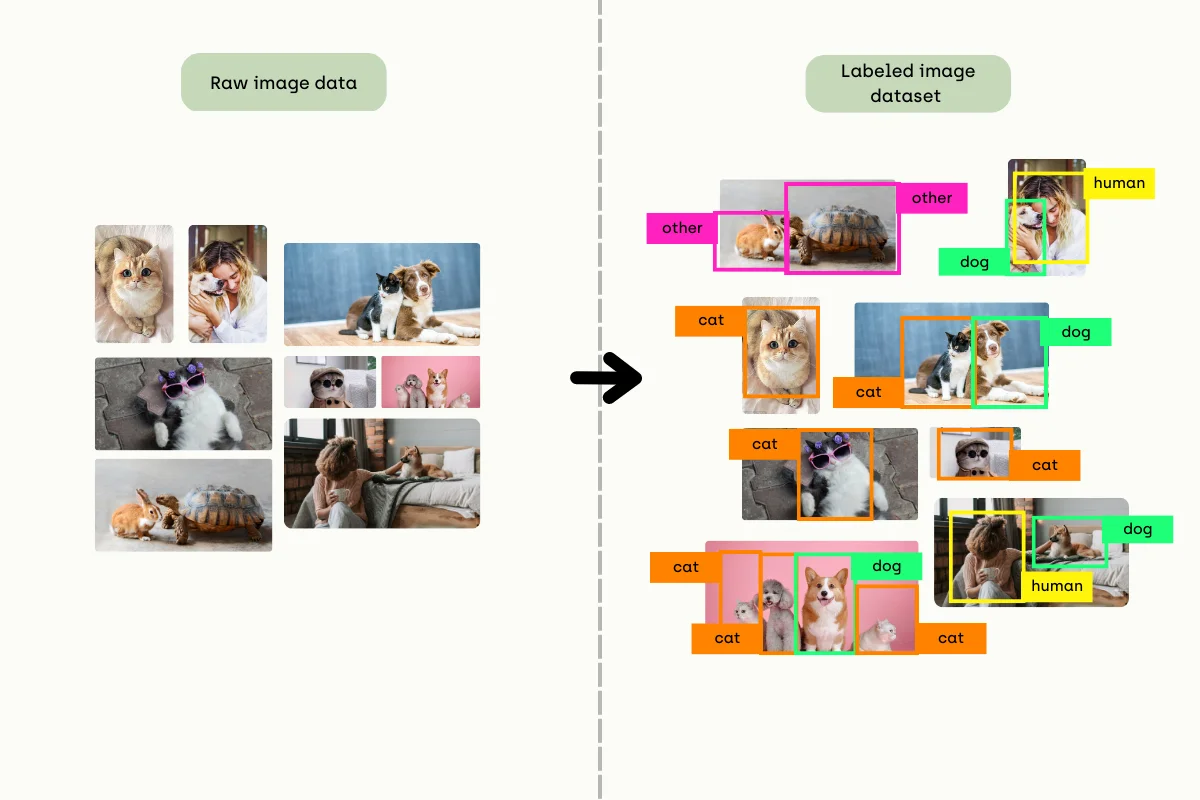
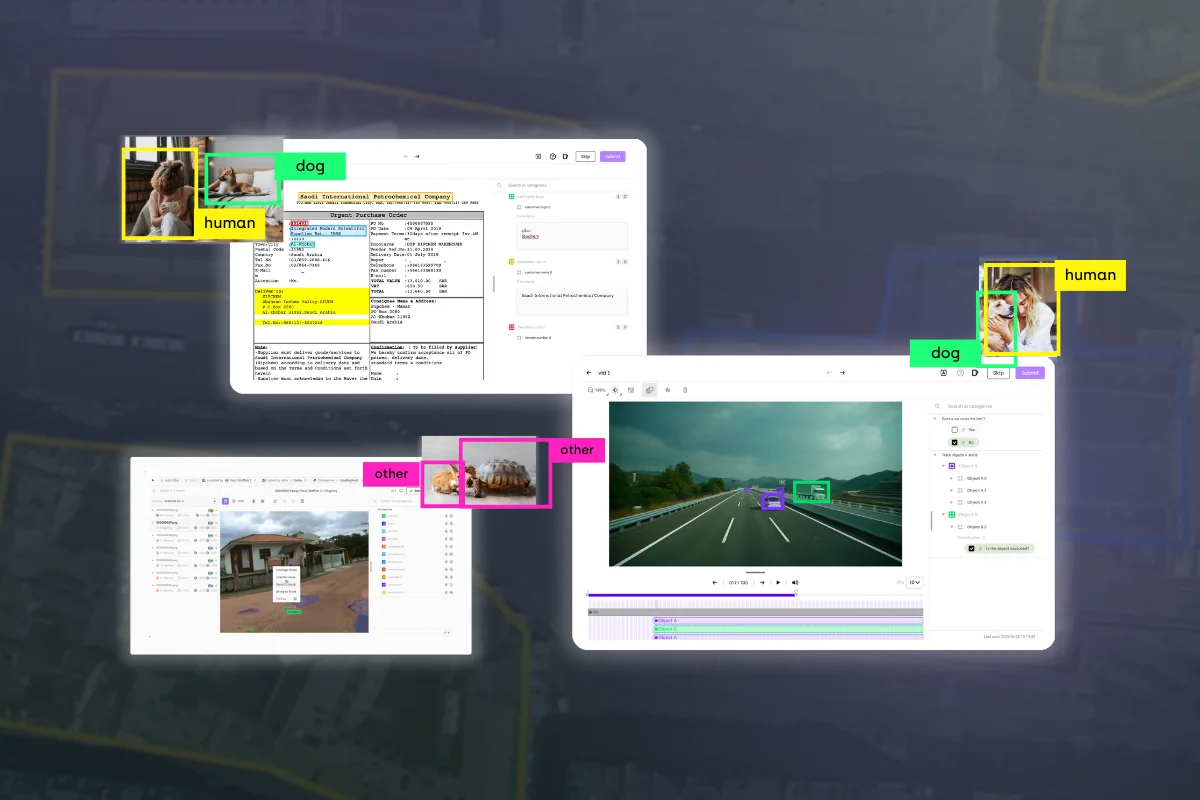
Labeling image: from raw data to accurate dataset
Data Labeling Tools: Definition and Types
Data labeling tools are software platforms that streamline the manual annotation of data that will then be used for ML model training. It's an essential tool that turns raw data (most often, unstructured data) into accurate datasets. Data labeling tools enable us to perform data labeling, making it faster, more accurate, and more scalable.
There are several types of data labeling tools, from general-purpose tools that enable you to annotate text, images, and videos to specialized tools for specific use cases like speech recognition, geospatial annotation, or computer vision research. data labeling software is particularly important for image and video data annotation.
How to Work with Data Labeling Tools?
Data labeling tools are essential to machine-learning models' success. What does it take to make the best out of them, whether you annotate audio files or image and video files? Knowing how data labeling software works. Let's take a look!
Step 1: Preparing Your Data
Before you can label your data, you need to prepare it for labeling. This involves organizing it into a format that your data labeling tool can process, such as CSV, JSON, or XML. You may also need to clean your data and remove duplicates or irrelevant data.
Step 2: Uploading Your Data to the Data Labeling Software
Once your data is prepared, you can upload it to your data labeling software. Most data annotation tools enable you to upload data in bulk, either by dragging and dropping files or by importing them from a cloud storage service like Amazon S3 or Google Cloud Storage.
Step 3: Defining Your Annotation Types
Before you start labeling your data, you need to define the types of annotations required for your machine-learning model. This could include text classification or image segmentation, among others. Data labeling tools you consider should provide a range of annotation types.
Step 4: Labeling Your Data in your Data Labeling Software
Now it's time to label your data. Using your data labeling software's interface, you can select the type of annotation required and start labeling your data. Some tools enable you to collaborate with other annotators and label your data faster and more accurately.
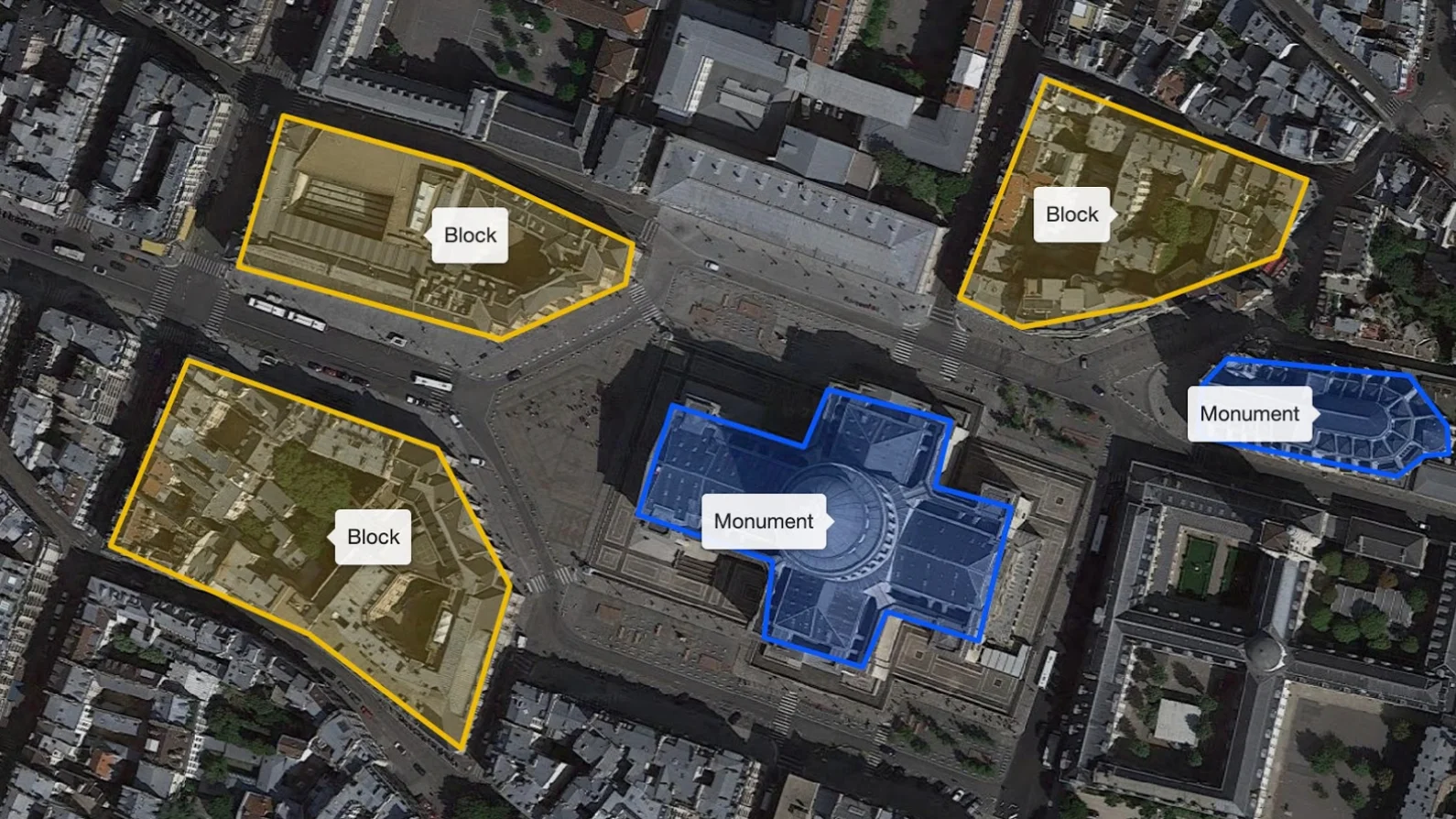
Geospatial image annotation performed using Kili Technology
Step 5: Reviewing Your Labels from your Data Labeling Software
Once your data is labeled, you must review your labels to ensure their quality and accuracy. Your data labeling software should provide tools for reviewing and correcting labels, such as visualizations, quality control metrics, and auditing tools.
Step 6: Exporting Your Labels from your Data Labeling Software
Last step: export your labels in a format your ML model can process. Your tool should enable you to export your labels in various formats, such as JSON, XML, or CSV.
Features and Capabilities of Data Labeling Tools
Data labeling software comes with various features that help streamline the labeling process and improve the accuracy of machine learning models.
Collaboration is another essential element that enables multiple annotators to work on the same dataset, reducing the workload and improving accuracy, which is beneficial for large or complex annotation tasks.
Quality assurance features are also essential elements of labeling software since they ensure the quality and the accuracy of annotated data and help detect errors and inconsistencies that can impact model accuracy.
Additionally, data management is another salient feature to look for. This feature helps organizations organize and manage their datasets.
Last but not least: customization. This feature is oh so critical, for it allows organizations to tweak their solution in order to fit the annotation types, labels, and workflows to meet the specific needs of a machine learning project. Speaking of customization, if you want to leverage it for your labeling, Kili Technology's plugins will probably interest you. You can also take a look at how it works in the video below.

Watch video
5 Best Practices for Using Data Labeling Software Effectively
Here are five best practices to use your data labeling software at its most:
- Define clear labeling guidelines to outline the annotation types, labels, and workflows required for your ML model, ensuring the quality and accuracy of your labeled data, reducing errors and inconsistencies, and speeding up the labeling process.
- Use multiple annotators to improve accuracy, reduce errors and inconsistencies, and speed up the labeling process by enabling collaborative annotation features.
- Leverage auto-annotation to label faster and more efficiently using pre-trained ML models, especially for image recognition tasks.
- Implement quality control processes, including visualizations, metrics, and auditing tools, to detect errors and inconsistencies and improve the performance of your ML model.
- Integrate your data annotation tool with your workflow to streamline the entire machine learning process, from data collection to model deployment, using available integrations with popular ML platforms like TensorFlow, PyTorch, and Scikit-learn.
Learn More
Did you know that 85% of all machine learning projects never reach real-world deployment – most often due to a lack of excellent-quality training data? If you want to be part of the 15% left, some insider tips on data annotation project management will likely help. Learn how to streamline your processes now.

Data Types Supported by Data Labeling Tools
Depending on data labeling tools' capabilities, data types can include the following data types:
- Text:
- Data labeling software can be used to annotate text data, such as documents, emails, chat logs, and social media posts. Common annotation types for text include sentiment analysis, Named Entity Recognition (NER), and text classification.
- Images:
- A data labeling solution can also be used for image annotation, such as photographs, diagrams, and maps. Common annotation types for images include image segmentation and image classification.
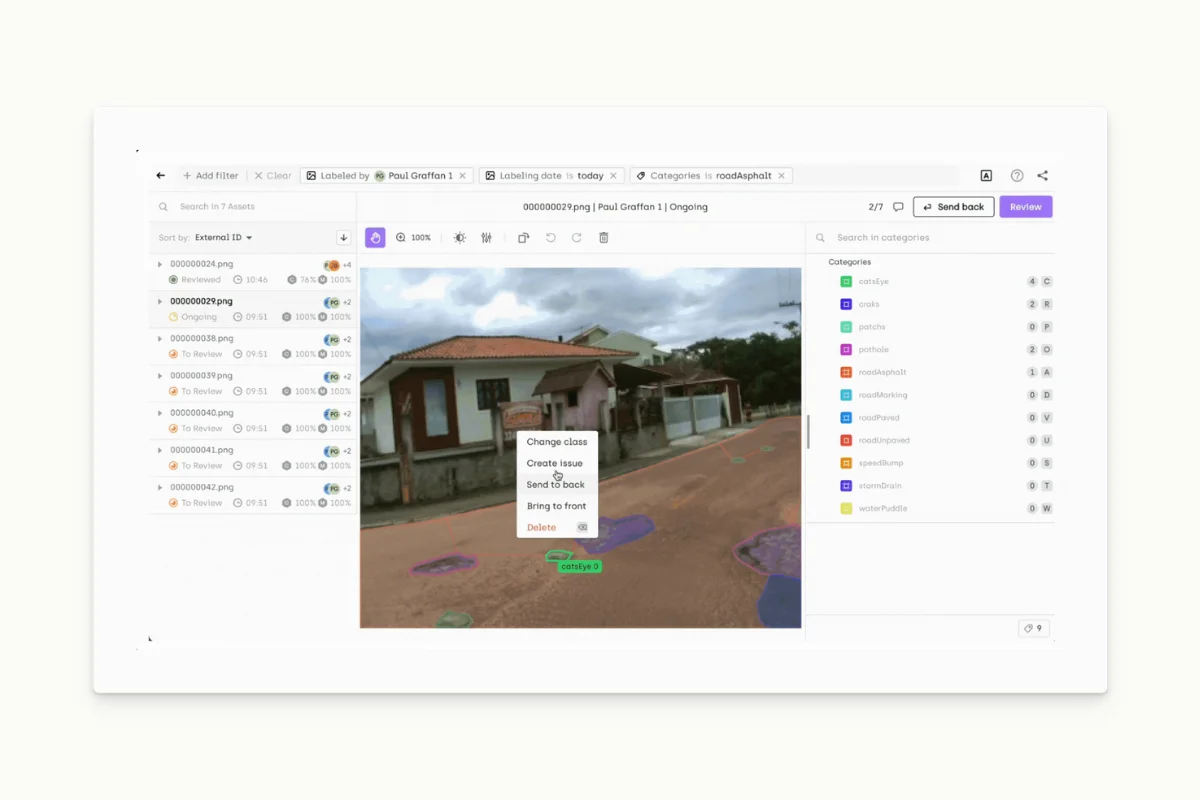
- Perform labeling on images using Kili Technology's labeling platform
- Audio:
- Data labeling software can annotate audio files, such as speech, music, and sound effects. Common annotation types for audio files include speaker diarization and music genre classification.
- Video:
- Annotation tools can annotate video data, such as movies, TV shows, and surveillance footage. Common annotation types for video include action recognition, object tracking, and facial recognition.
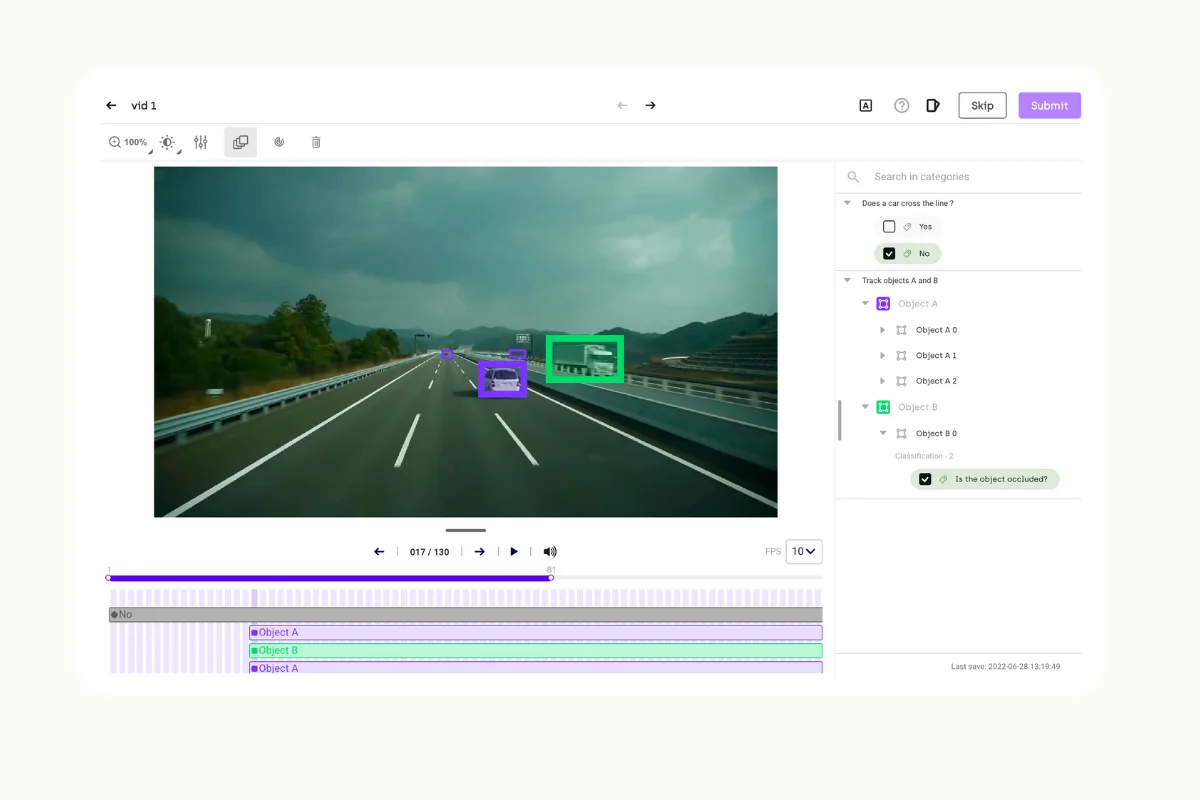
- Video annotation screen of Kili Technology
- Sensor data:
- Data labeling software can be used to annotate sensor data, such as GPS data, accelerometer data, and environmental sensor data. Common annotation types for sensor data include activity recognition, location tracking, and environmental monitoring.
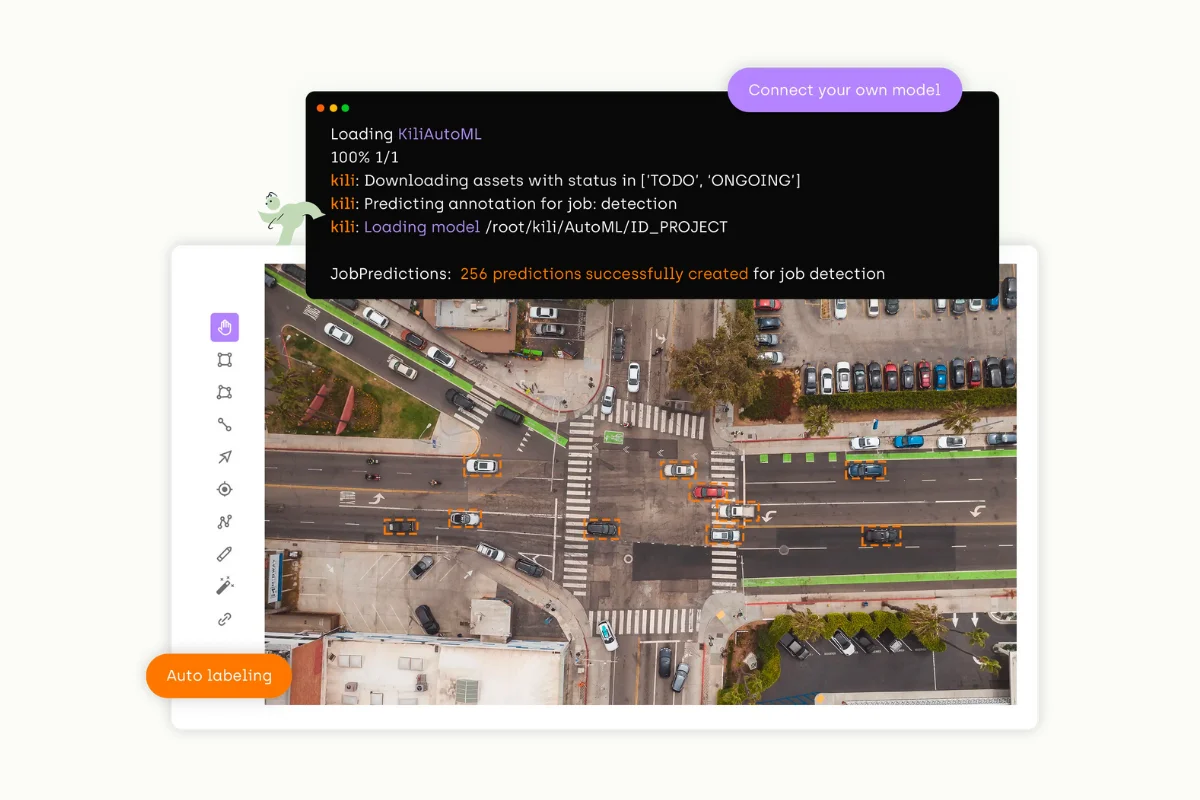
Automation Tools offered by Kili Technology's platform for accurate data labeling
Labeling Tasks supported by Data Labeling Tools
Data labeling tools can typically support a variety of data labeling tasks, depending on the specific device and its capabilities. Here are some of the most common labeling tasks that data labeling software can support:
- Classification:
- Classification tasks involve labeling data into pre-defined categories or classes. Data labeling tools can support binary classification tasks (e.g., spam vs. non-spam) or multi-class classification tasks (e.g., sentiment analysis with positive, negative, and neutral categories).
- Entity recognition:
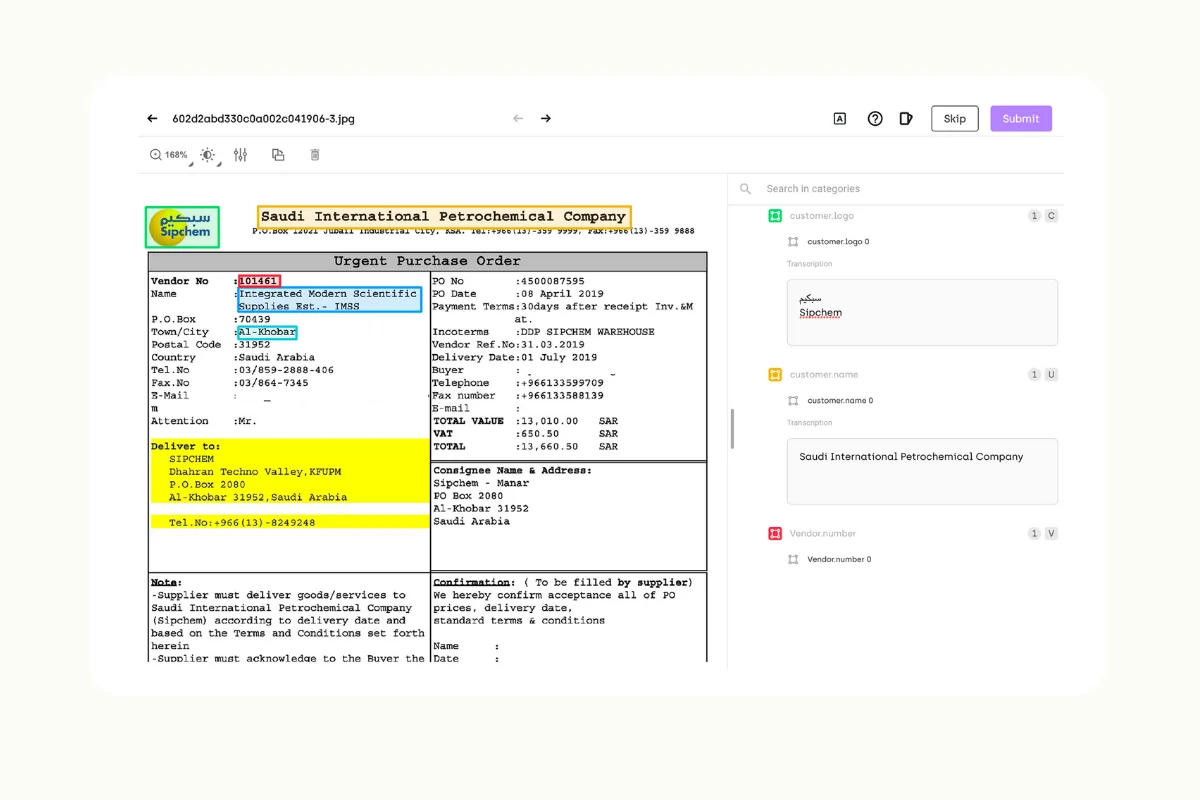
- These tasks involve identifying and labeling specific entities within text data, such as people, organizations, or locations. Data labeling tools supporting this task allow for pinpointing entities with specific names and general entity recognition, which involves identifying entities with specific attributes (e.g., dates or numbers).
- OCR labeling tasks being performed using in Kili Technology
- Sentiment analysis:
- Sentiment analysis tasks involve labeling text data with a sentiment score, indicating whether the text expresses a positive, negative, or neutral sentiment.
- Object detection:
- This task involves identifying and labeling specific objects within image or video data. Data labeling software can help detect different types of objects, such as bounding box annotation, polygon annotation, or semantic segmentation.
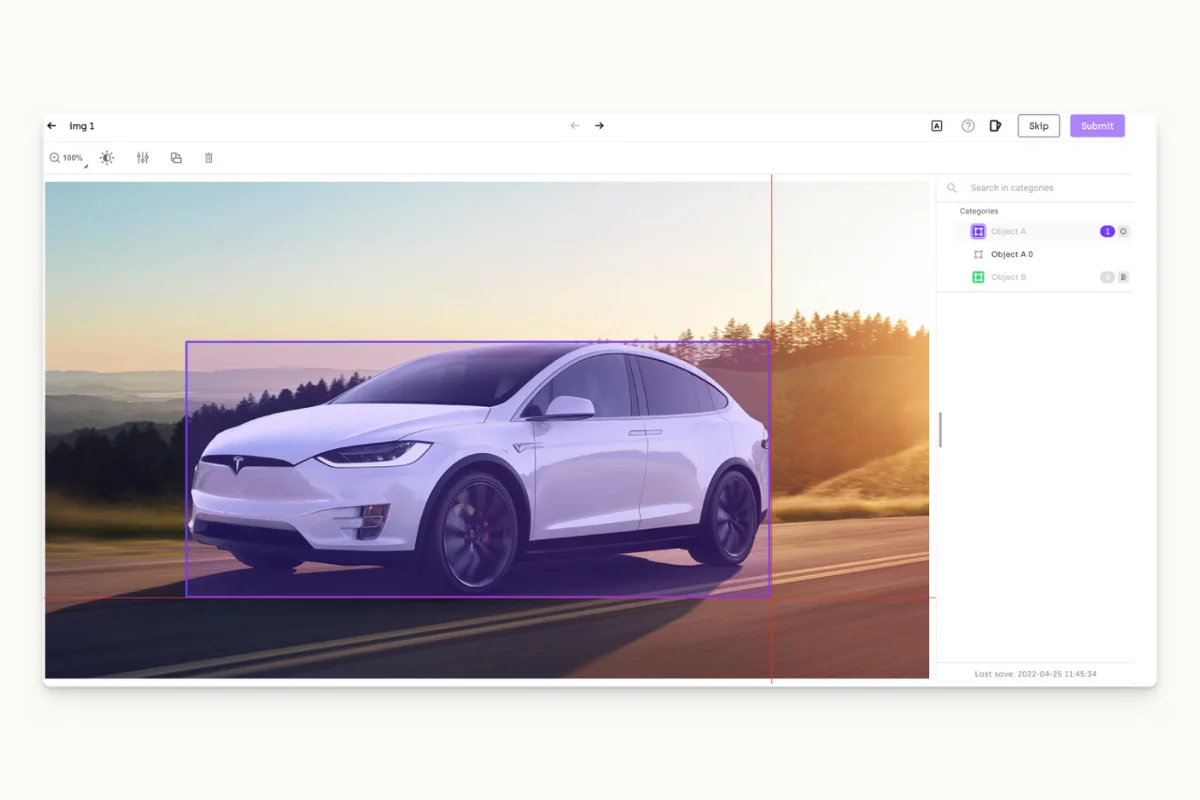
- A bounding box is performed during a data labeling process
- Speech recognition:
- This task involves transcribing spoken language into text data. Data labeling tools can support speech recognition by allowing users to listen to audio data and manually transcribe it into text.
Why are Data Annotation Tools Crucial for Machine Learning Projects?
Working with high-quality datasets is critical for achieving accurate and reliable ML models. Here are a few reasons why:
- Garbage in, garbage out:
- The saying "garbage in, garbage out" also applies to models. If the data used to train a model is low-quality or contains errors, the resulting model will also be low-quality and prone to errors.
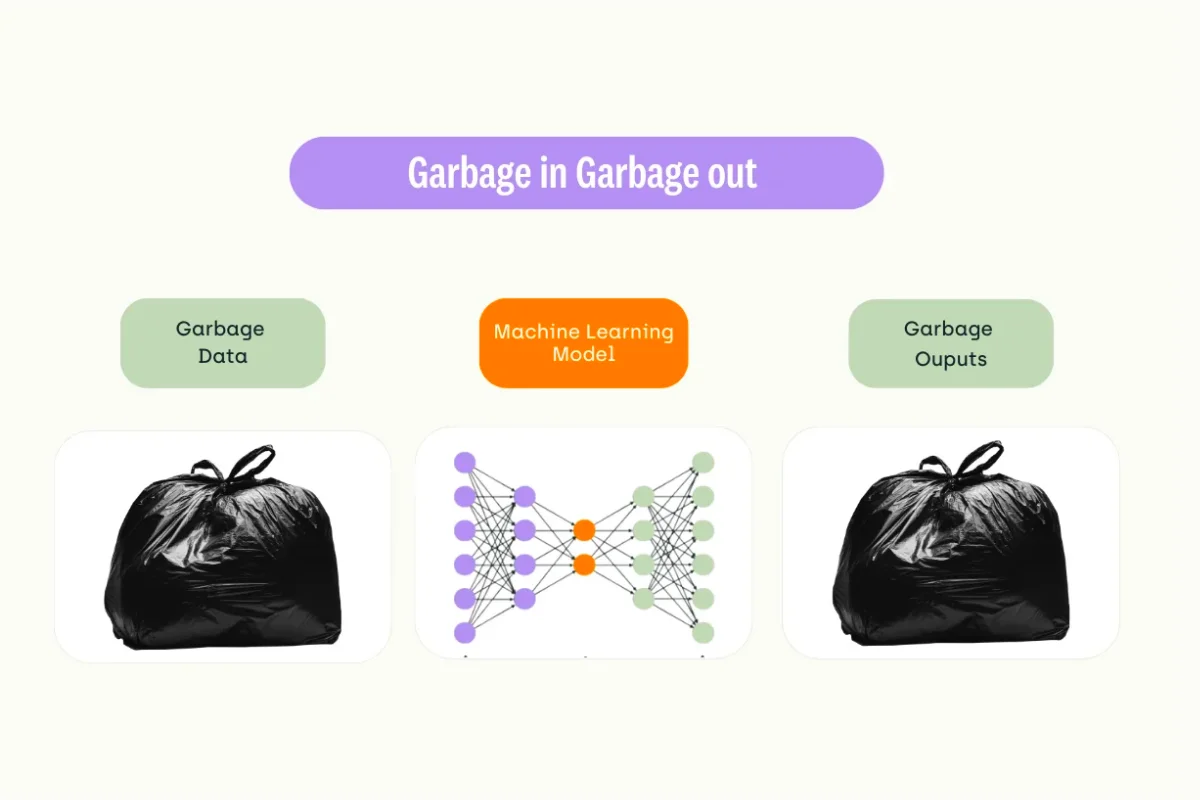
- Regardless data types, garbage in is still giving garbage out
- Human bias:
- Humans are prone to bias, which can be introduced into data if not careful. Biased data can lead to models that perpetuate or even amplify that bias. Ensuring high-quality labeled data can help reduce the impact of human bias on the model.
- Scaling:
- ML models are designed to work at scale, meaning they can process massive amounts of data quickly and accurately. However, if the annotated data used to train the model is of poor quality, the model's accuracy will suffer as the data scales.
- Robustness:
- High-quality data can help improve the robustness of ML models. Models trained on high-quality datasets are likelier to perform well on new and unseen data sets, making them more reliable in real-world scenarios.
Final Thoughts on Data Labeling Tools
Accurate data labeling, and to do so: data labeling software is essential for accelerating the development of machine learning models giving a boost to your models' performance.
By streamlining the labeling process, data scientists, data engineers, and machine learning engineers can focus on building better models and delivering value to their organizations.
When you label data with the right data labeling platform, your organization can improve its operational efficiency, reduce costs, and gain a competitive advantage in its respective markets by leveraging excellent training data for its model training.
References
Image and Video Data
- Xiao, T., Xia, T., Yang, Y., Huang, C., & Wang, X. (2019). Video-Based Object Detection and Tracking: A Survey.
- Katti, H., & Singhal, V. (2021). Efficient algorithms for annotation and querying of video event sequences. Multimedia Tools and Applications
- Zhang, Y., Zou, Y., Song, J., & Yang, J. (2019). A survey on image annotation. Neurocomputing
Computer Vision
- Ruder, S. (2017). An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098. Retrieved from https://arxiv.org/abs/1706.05098
Accurate Training Datasets
- Dror, I., Reichart, R., & Saxe, J. (2018). Acritical review of benchmarks for machine learning models.
- Xie, B., Xing, L., & Ai, Q. (2021). A survey of evaluation metrics for natural language generation systems.
Natural Language Processing:
- Hirschberg, J., & Manning, C. D. (2015). Advances in natural language processing.
Labeling Process:
- Yan, Y., Jain, P., & Kosecka, J. (2018). DeepLabel: A Multi-Task Learning Approach for Fine-Grained Labeling. arXiv preprint arXiv:1805.07200. Retrieved from https://arxiv.org/abs/1805.07200
- Scale AI. (n.d.). Data Labeling Platform. Retrieved from https://scale.com/platform/data-labeling
Active Learning:
Deep Learning models :
- 1. "Deep Learning" by Ian Goodfellow, Yoshua Bengio, and Aaron Courville http://www.deeplearningbook.org/.
FAQ on Data Labeling Tools
Is there a Difference between Data Labeling Software, Data Labeling Tool, and Data Labeling Platform?
These terms are often used interchangeably, but their meanings differ a tad. Generally speaking, "data labeling tool" or "data annotation tool" is a piece of software used for labeling in an artificial intelligence context. A "platform" may refer to a collection of tools and resources for data labeling and management.
Is Data Labeling The Same As Data Annotation?
In practice, data labeling and annotation are often used interchangeably. However, they differ slightly.
Data labeling refers to assigning one or more labels to an asset, indicating what each piece of data represents or how it should be categorized.
Data annotation, however, refers to the broader process of adding information to a dataset beyond just simple labels.
Is My Data Safe When Using Data Labeling Software?
Like most reputable data labeling software providers, Kili Technology takes data security very seriously. Kili Technology provides secure cloud storage and is SOC2, ISO, HIPAA, and GDPR compliant. Our data security measures include data encryption, access controls, and regular security audits.
However, it's always a good idea to do your due diligence and research the data security practices of any software provider you're considering.
Curious to learn more about how Kili Technology ensures data security? You can learn more by reading our data security measures.
Is Using Data Labeling Software Likely To Boost Model Performance?
Yes, using data labeling software can often improve model performance by providing accurate, high-quality training data. The accuracy of your dataset is a critical factor in determining the performance of your model, and using data labeling software can help ensure consistency and reduce errors in labeling.
How To Implement Quality Assurance When Working With Data Labeling Software?
In data annotation, quality assurance is the process of ensuring that the data generated by a data labeling software meets the required standards of accuracy and consistency.
Note that in Kili Technology's platform, you'll find different quality assurance capabilities. these quality assurance capabilities will help you to speed up your processes drastically while allowing you to achieve high-quality training datasets.
How To Structure My Data Labeling Operations?
The structure of your data labeling process will depend on various factors, including the size and complexity of your dataset, the types of annotations required, and the resources available to you.
Generally speaking, it's a good idea to have a clear set of labeling guidelines in place, use multiple annotators to reduce errors and inconsistencies and implement quality control processes to ensure the accuracy and consistency of the data.
Why Are Accurate Datasets Essential To Machine Learning?
Accurate training datasets are essential to machine learning because the accuracy of your model depends on the quality of your data. Your model's performance will be limited by the accuracy and consistency of the dataset used to train it. Using inaccurate or inconsistent data can lead to poor model performance and, in some cases, make the model unusable. Therefore, ensuring the accuracy and consistency of your labeled data is essential to achieving the best possible model performance.
In a nutshell: more accurate datasets equals more precise ML models.
What's the impact of Data Labeling Software on a Machine-Learning Pipeline?
Tool labeling can significantly impact the overall efficiency and accuracy of a machine learning (ML) pipeline. By streamlining the labeling process and ensuring the accuracy of labeled data, a data labeling solution can help improve the performance of an ML model.
Overall, using an annotation tool can help accelerate the entire ML pipeline, from data labeling to model deployment, by ensuring the quality and accuracy of labeled raw data, reducing errors and inconsistencies, and improving the overall performance of the ML model.
To learn more about the impact of unstructured data on your machine-learning pipeline, learn our dedicated article Unstructured Data vs. Structured Data: differences and Impact on Your ML Pipeline.

What are the Top Data Labeling Tools? / What is Data Labeling Software?
If you're into artificial intelligence, data science, or machine learning, you probably know it: finding the right data labeling software is quite a conundrum. Many stakeholders and criteria are implied, and scoring can sometimes take longer than we'd like.
In any case, to save you time, we've prepped a bunch of comparisons of top data labeling tools with Kili Technology. In a hurry? Here's a list of some of these:
- Azure Machine Learning
- Amazon Ground Truth
- Snorkel AI
- Datasaur
- LabelStudio
- Roboflow
- Clarifai
- v7labs
- Labelbox
- Prodigy
What are the ML fields that Data Annotation Platforms can Help With?
Labeling data and, to further extend, data labeling software can be used in many different ML fields:
- computer vision models;
- image annotation;
- text annotation (notably for natural language processing tasks);
- active learning;
- document classification;
- and many more.
What are the ML Models Data Labeling Software can Help With?
Data labeling software can help with various machine learning (ML) models including:
- Supervised Learning;
- Unsupervised Learning:
- Reinforcement Learning
- Transfer Learning.
What is Automated Labeling, and Which Approach is Used for Automatic Labelling?
Automated data labeling is a process that uses ML models to automatically assign labels to data, rather than relying on humans to label the data manually. Although far from being 100% successful in its mission to speed up the labeling process and reduce human error, this process is often used for larger datasets.
Several techniques are used in this type of data labeling, including weak supervision, transfer learning, and rule-based labeling.
What is Active Learning?
Active learning is a machine learning technique that involves selecting and labeling the most informative examples in a dataset for labeling by a human annotator or an automated labeling system. Instead of labeling all examples in a dataset, active learning selects a subset of examples that are predicted to be most helpful in improving the model's accuracy. By iteratively selecting examples for labeling and retraining the model on the newly labeled data, this type of learning can reduce the amount of labeled data required to achieve the desired level of accuracy compared to traditional supervised learning methods. This can be particularly useful in situations where labeled data is scarce or expensive to obtain. Active learning can be applied to a wide range of machine learning tasks, including image classification, object detection, natural language processing, and more.
Note that thanks to our Python API, our platform enables you to manage the priority of samples to annotate manually or programmatically. Coupled with our query mechanism, which allows importing labels into your scripts, it allows the use of active learning algorithms and helps you to create datasets efficiently.
Should I use Automated Labeling?
While automated labeling, also called automated data annotation, can be a powerful tool for reducing the cost and time required for data annotation, it's important to note that automated annotation may not always be as accurate or reliable as human labeling, especially for complex or nuanced annotation tasks. Regardless of the data type at stake, Kili Technology recommends using a smaller but adequately annotated dataset. Indeed, according to the Data-Centric AI (DCAI) philosophy and our customer's success, automated labeling will likely damage the accuracy of the dataset labeling and, ultimately, your ML model's performance.
What is NLP in Data Labeling?
NLP stands for Natural Language Processing, and it refers to a branch of artificial intelligence that focuses on understanding and processing human language. In data labeling, NLP is often used to label and annotate text data, such as customer reviews, social media posts, or news articles.
NLP-based data labeling can involve several tasks, including:
- Text classification: Text classification involves assigning one or more labels to a piece of text data based on its content. For example, a news article might be labeled as "politics," "sports," or "entertainment."
- NER: NER involves identifying and labeling specific entities in text data, such as names, locations, or organizations.
- Sentiment analysis: Sentiment analysis involves determining the emotional tone or sentiment of a piece of text data, such as whether a customer review is positive, negative, or neutral.
- Topic modeling: Topic modeling involves identifying the underlying themes or topics in a collection of text data, such as news articles or social media posts.
NLP-based data labeling can be performed manually by human annotators. Still, a range of tools and techniques can be used to automate or semi-automate the process. These include machine learning models trained on labeled data, rule-based systems that use pre-defined criteria to mark your raw data or a combination of both approaches.
Overall, NLP-based data labeling can be a powerful tool for analyzing and extracting insights from extensive collections of text data. Still, it requires specialized skills and tools to do so effectively.
How can a Data Labeling Platform Improve my Training Data Quality?
A data labeling tool can improve the quality of your training data in several key ways. A data labeling tool can significantly improve the quality of your training data by improving consistency, speed, accuracy, collaboration, flexibility, and, to some extent, your dataset management. This can ultimately lead to better machine learning model performance and improved outcomes for your organization.
Can I use Data Labeling Software for Sensor Fusion Annotation?
Yes, it is possible to use data labeling tools for this purpose. Data labeling software can improve sensor fusion accuracy. Labeling data from multiple sensors enables ML models to predict better. Annotating software can label GPS, accelerometer, and environmental sensor data for activity recognition, location tracking, and environmental monitoring.
Can Data Labeling Software Support Fixing Dataset Errors?
Data labeling software may be able to support fixing dataset errors, depending on the specific software and its capabilities.
Suppose the errors impacting your dataset involve incorrect or inconsistent labeling. In that case, data labeling software may be able to support fixing those errors by providing tools for quality control and error detection.
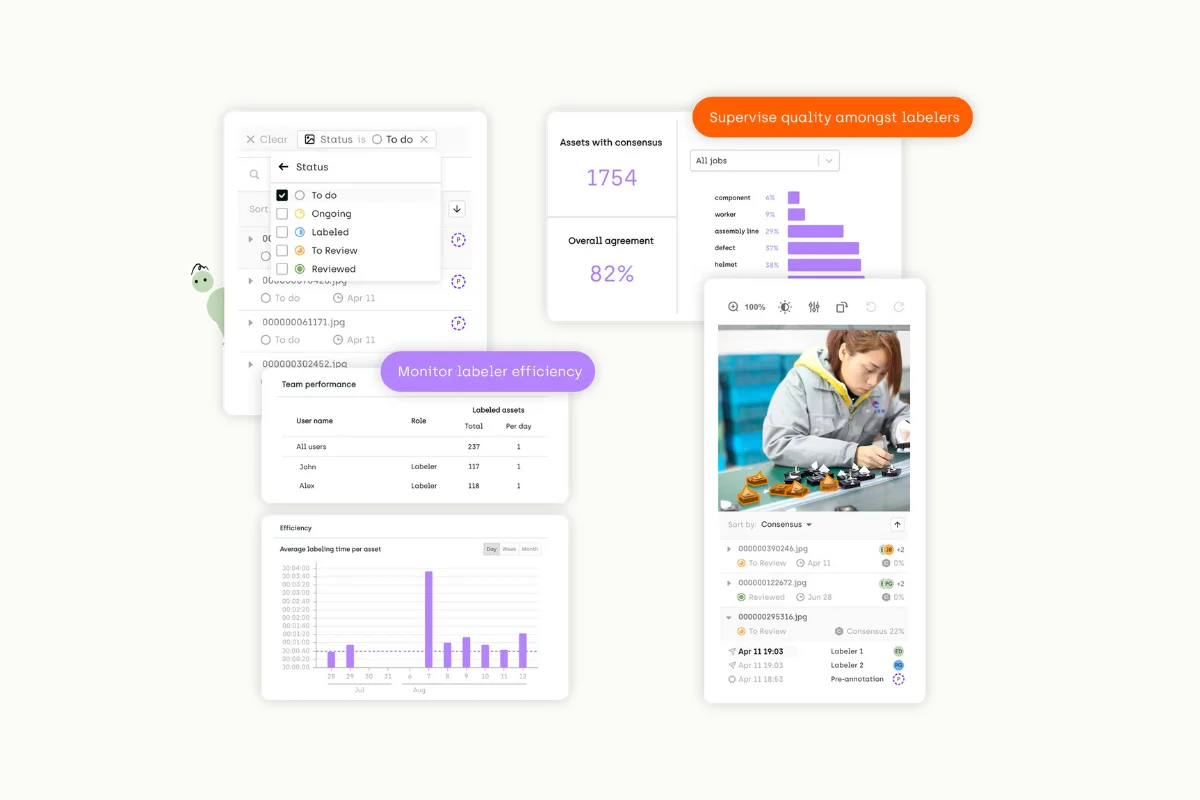
Kili Technology helps you monitor your data-labeling quality with various metrics and capabilities, such as review queue automation, consensus, or honeypot, as well as custom-coded quality workflows.
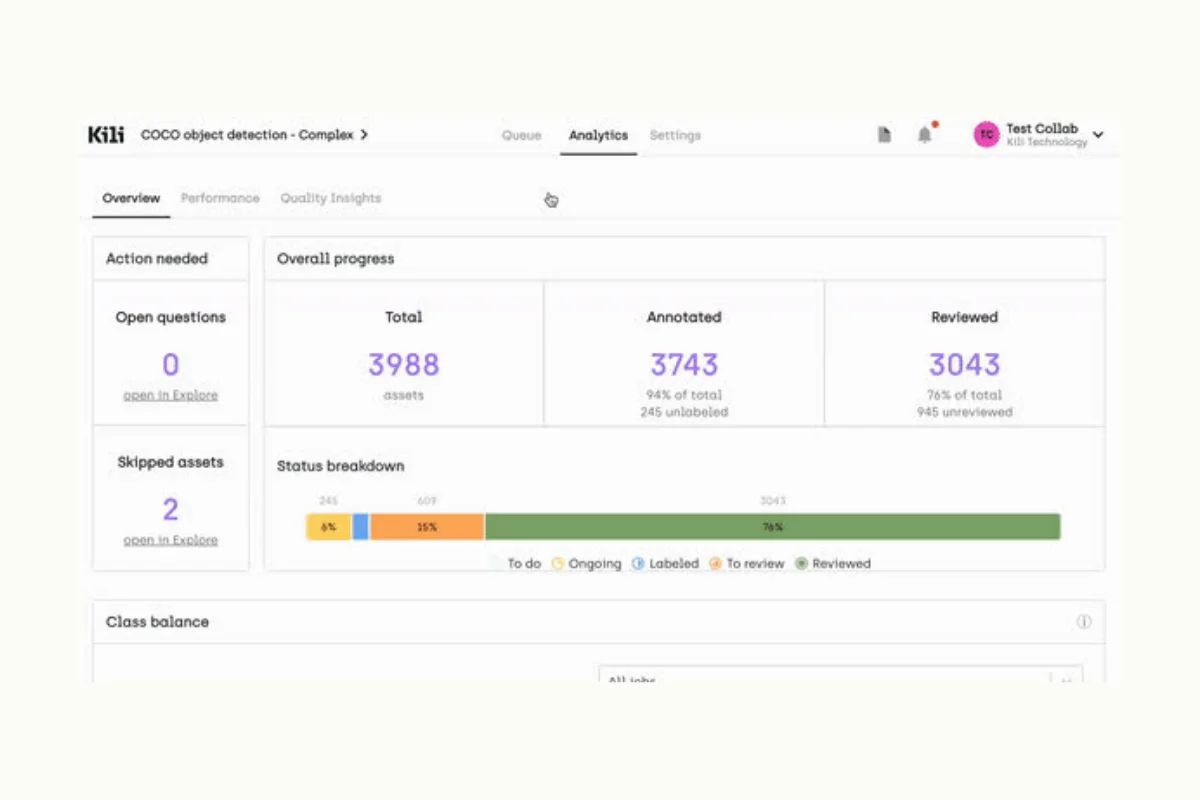
Does Kili Technology offer a Labeling Instruction Builder?
Although Kili Technology's data labeling software doesn't have an in-app labeling instruction builder yet, Kili Technology provides an in-app Q&A section enabling labelers to ask questions. Kili Technology also allows you to add your labeling instructions from your project's settings. You can write instructions in a public web document (e.g., a Google Doc, a Notion page, an Office 365 document, a web page, etc.) and add the link.
Does Kili Technology offer Centralized Project Management?
Kili Technology allows you to label, find and fix issues, simplify DataOps, and dramatically accelerate the build of reliable artificial intelligence, all in one place. That's why it offers centralized project management, with capabilities such as:
- project overview;
- asset management;
- customization of the project interface;
- user permissions management;
- analytics.
What are the Plans Offered by Kili Technology?
Kili Technology offers three plans: Free, Grow (from USD$83 a month), and Enterprise.
Note that all these plans support image, video, and many other formats and are suitable for computer vision research applications.


![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
