
.png)


_logo%201.svg)


AI Summary
In an industry as dynamic and competitive as insurance, leveraging AI to streamline processes and enhance decision-making is no longer just an advantage—it's a necessity. The pace at which insurance companies can ship their models determines how quickly they can respond to market changes, personalize customer experiences, and optimize risk assessment. The agility to deploy AI models rapidly is crucial for maintaining a competitive edge, ensuring compliance, and driving innovation. Yet, the journey from concept to deployment is often hindered by several prevalent challenges.
Overcoming training data challenges with Kili Technology
The complexity, sensitivity, specificity, and time sensitivity of the insurance business bring about prevalent challenges for insurance AI models. Let us show you how we can help you securely achieve high-quality data to optimize the performance of your insurance AI model.
The Four Prominent Challenges in Insurance AI
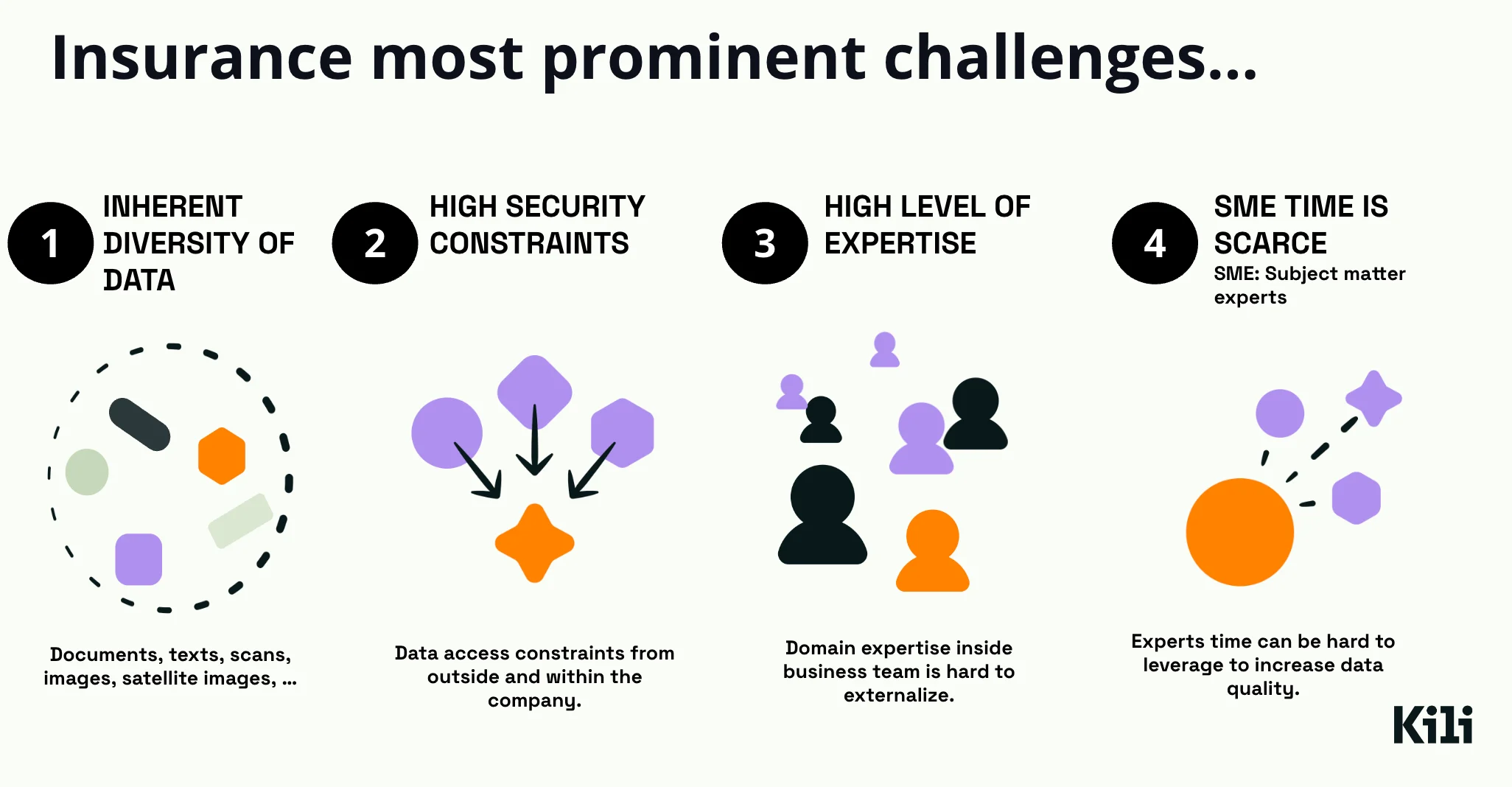
- Inherent Diversity of Data
- Insurance companies grapple with a myriad of data forms – from text in documents to images of assets. This diversity necessitates complex preprocessing and standardization to feed into AI models effectively. Insurance data isn’t just varied; it's also layered with context and nuances specific to the sector.
- High Security Constraints
- Given the sensitive nature of personal and financial information, insurance firms face stringent security protocols. Data access is heavily guarded, with rigorous checks both from outside and within the company. This creates a challenge for AI development, which requires vast amounts of data for training purposes.
- High Level of Expertise
- Developing AI in insurance isn't just a technical challenge; it requires a deep understanding of the domain. Domain expertise must be internalized within the AI teams to ensure models are accurate and relevant. However, such knowledge is Webinar Recap Draft 2 often tacit, residing in the minds of experienced personnel who may not have the time to contribute to AI projects.
- SME Time is Scarce
- Subject matter experts (SMEs) are vital for enhancing data quality and guiding AI model development. Their insights lead to more accurate, reliable, and applicable AI applications. Yet, their time is a limited resource. Balancing their primary responsibilities with AI initiatives is a significant bottleneck, as their involvement is crucial but difficult to secure. In the sections to follow, we will dive into strategies to overcome these challenges, ensuring that your AI deployment not only keeps pace with the industry but sets the standard for innovation and efficiency.
Overcoming Data Diversity in Insurance AI
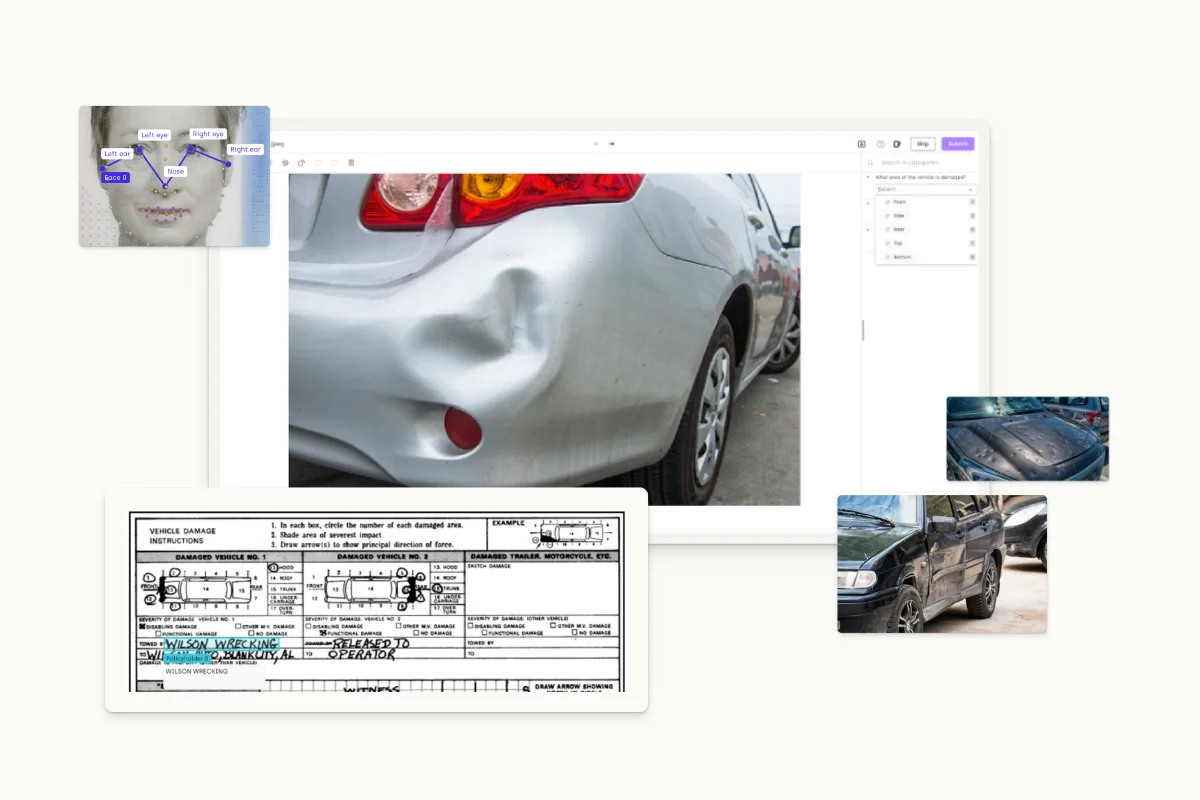
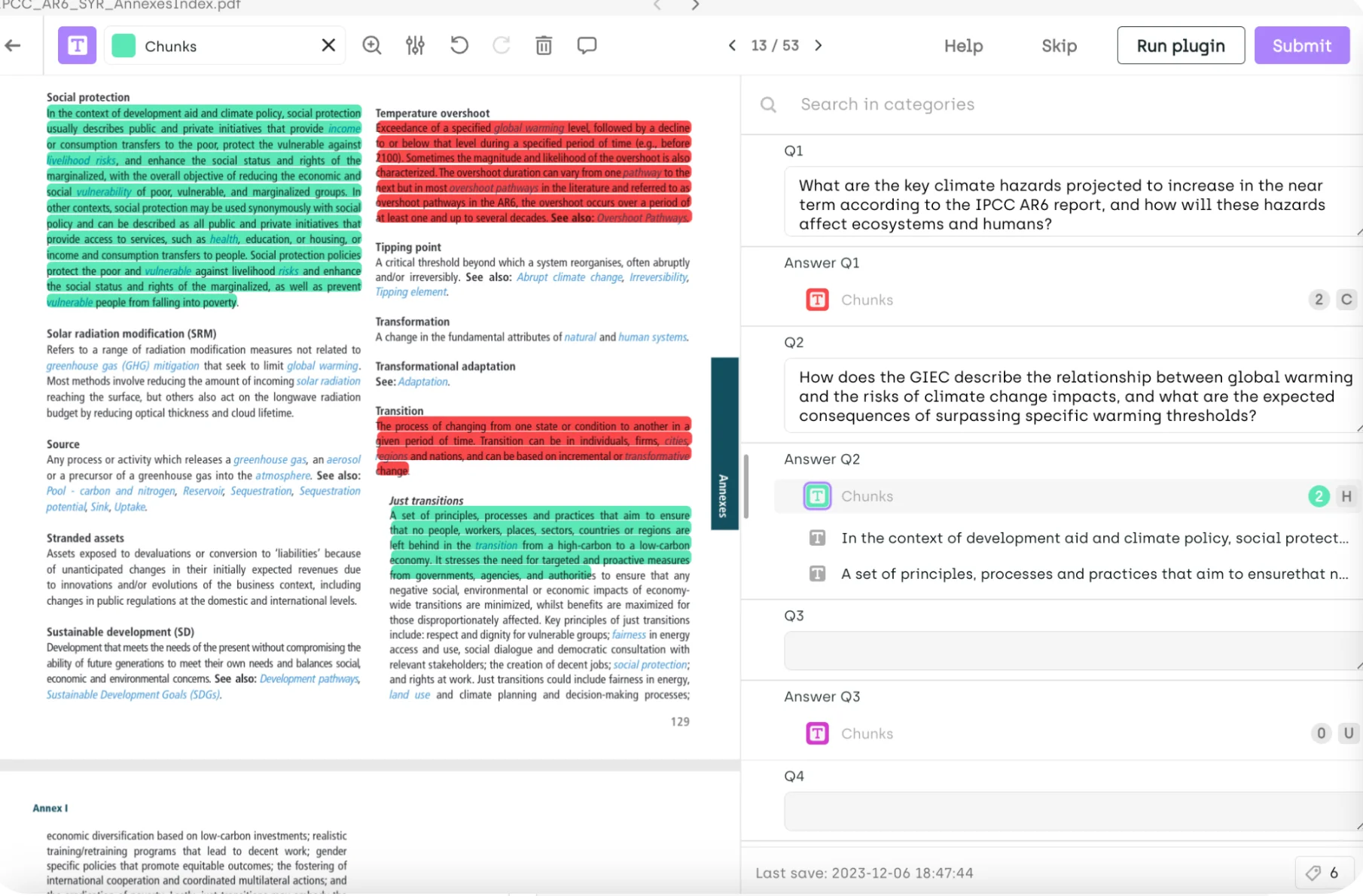
The insurance sector deals with a vast array of data types and each use case, such as verbatim classification from customer support, claims processing, and policy classification, comes with its own unique challenges. These challenges can be tackled through a robust data labeling platform that can provide the right interface to fit the needs of your use case.
- Building Custom Ontologies for Text: When dealing with simple texts like customer support verbatims, it is crucial to construct an ontology that allows classification of the sentiment and content and extraction of relevant information for named entity recognition, like product identification.
- Handling Complex PDFs: Larger documents, such as extensive PDF reports, require tools to classify document types and extract key sections. The complexity increases with the inclusion of unstructured data like images and graphs within the PDFs, necessitating a flexible tool to handle and extract information from these multifaceted documents.
- Text on Images: For text-based information on images, such as scanned documents in KYC processes, leveraging OCR models can enhance efficiency by automating the extraction and allowing annotators to categorize elements, integrating text and image processing.
- Segmenting Satellite Imagery: In more specialized cases, like assessing damage from natural disasters or labeling flood zones, the focus shifts to segmenting satellite imagery. This involves dealing with geolocalized polygons, adding another layer of complexity to the data labeling process.
- Image-Based Assessments: For damage assessment from mobile photos, semi-supervised segmentation models help rapidly categorize and segment the damage, which can extend beyond vehicles to buildings and other structures.
- RAG Stack Evaluation and Monitoring: With the growth of Generative AI, the utilization of interfaces for RAG stack—Retrieval Augmented Generation—becomes crucial. They involve interacting with databases using prompts from large language models, requiring datasets for benchmarking and real-time performance monitoring across various data types, including text, PDF, and images.
Demonstration: How to evaluate and monitor a RAG stack
Essentially, a RAG system first retrieves relevant pieces of information based on the input query and then uses this context to generate a coherent and contextually accurate output. This method has proven particularly beneficial in domains like insurance, where the precision of information and its applicability to a specific case are crucial.
1. Evaluation: Benchmarking Performance
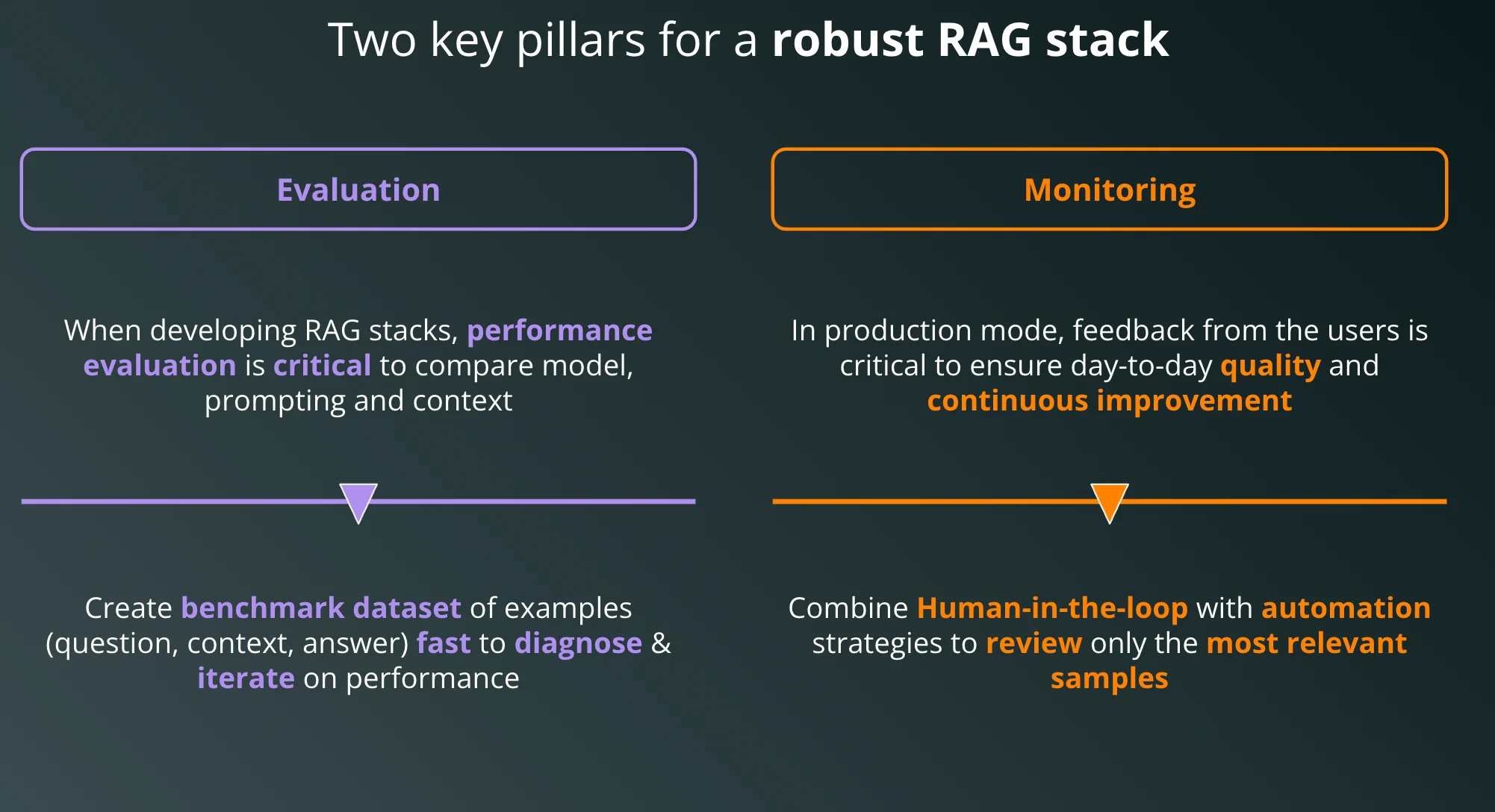
When developing RAG stacks, it is imperative to have a rigorous evaluation framework in place. This involves comparing the AI model’s output against a set of benchmark data that represents a variety of cases it will encounter in real-world scenarios. The performance evaluation process must critically analyze how well the model performs in different contexts and how effectively it integrates the retrieved information into its responses.
Creating a benchmark dataset is not just about having the right answers; it’s about mapping the whole journey from the question to the context and finally to the answer. The dataset should include examples that are representative of the various challenges the model will face, helping developers to quickly diagnose and iterate on the model's performance. This rapid iteration is vital for fine-tuning the RAG to deliver fast and accurate responses.
2. Monitoring: Ensuring Quality and Continuous Improvement
After deployment, the real test begins as the model encounters a continuous stream of user queries. Monitoring is about ensuring that the quality of the RAG stack's outputs remains high and is continuously improving over time. User feedback becomes a goldmine for this phase. Each piece of feedback is an opportunity to refine the model further, ensuring that it adapts to the evolving needs and nuances of the insurance domain.
To manage this effectively, a human-in-the-loop system is integrated. This strategic setup means that humans review the most relevant samples, especially in cases where the model's confidence level is low or the user feedback indicates a discrepancy. This synergy between human expertise and automated processing ensures that the RAG stack does not just maintain its performance, but also learns and evolves, enhancing its accuracy and reliability with each interaction.
Watch the demo:

Watch video
Webinar replay
Didn't get a chance to attend our insightful webinar on overcoming challenges in insurance AI? Watch the replay now to dive deep into strategies for data diversity, security constraints, and expertise shortages.
Tailoring Deployment to Insurance Security Standards
Insurance is data-sensitive. Security and compliance are not just priorities but mandates. The flexibility of deployment options in data labeling tools is paramount. Insurance companies demand the highest standards of data safety and security, and a one-size-fits-all solution simply doesn't suffice. A data labeling platform must offer a spectrum of deployment models to match the varied security needs and comfort levels of different insurers.
SaaS Deployment: Efficiency and Scalability
For insurers looking to capitalize on the efficiency and scalability of cloud solutions, a Software as a Service (SaaS) deployment is invaluable. It allows the hosting of the data labeling tool and data on the provider’s environment, which is often a more cost-effective and resource-efficient solution. With this model, insurance companies can leverage the advantages of the cloud's agility and lower upfront costs, all while adhering to strict security standards like ISO 27001 and AICPA SOC.
Hybrid Deployment: Balancing Control with Cloud Benefits
Hybrid deployment models offer a middle ground, catering to insurance companies that wish to keep their data in their own environment for enhanced control and security, yet still want to access the data labeling tool's capabilities on the cloud. This approach respects the insurer's need for security of sensitive data while still providing the elasticity and advanced features of a cloud solution.
On-Premises Deployment: The Gold Standard for Data Control
However, for many insurance companies, the gold standard for security and control is an on-premises deployment. This option places the data labeling tool and all data squarely within the insurer's own data center. By doing so, it gives insurers complete control over their sensitive data, aligning with stringent internal security policies and regulatory requirements. An on-premise solution is often deemed critical by insurers for whom data sovereignty and regulatory compliance are non-negotiable.
Granular access controls for extra security

Delegated Access Across Projects
A modern data labeling tool must offer granular access controls, allowing different teams within an insurance company to work on dedicated projects with data that is siloed and secure. This level of delegated access ensures that:
- There is a physical separation of data across various projects, which is crucial for maintaining data integrity and security.
- Teams can micro-manage access to data, providing the right people with the right level of access based on their role or project needs.
- Multiple object storage buckets can be used, with the possibility to assign each project its dedicated storage. This not only enhances security but also improves data organization and project management.
Tailored Access for Different User Groups
In a well-structured data management system, teams such as those handling real estate claims and life insurance policies can work concurrently on separate projects within the same platform without any risk of data overlap. For example:
- Team #1 (Real Estate): Focuses on projects like geospatial analysis for property insurance, where they need access to specific satellite imagery and related data.
- Team #2 (Life Insurance): Works on projects like personalized underwriting, requiring sensitive personal data that should not be accessible to other departments.
Additionally:
- Assigning access rights based on the roles of individual users or teams to control who can view or use resources in an organization.
- Defining access permissions based on attributes (such as department, data type, or sensitivity level) to provide a more nuanced and flexible access control.
The strategic organization and control of data access are as vital as the physical security measures of the data itself. By establishing clear and strict data access policies and combining them with sophisticated technology solutions, insurance companies can create an environment where data is not only secure but also primed for efficient and compliant use in AI-driven initiatives.
Mitigating Expertise Shortages Through SME Integration in the Labeling Process
The scarcity of subject matter experts (SMEs) in the insurance industry poses a significant challenge to AI model accuracy and relevance. To mitigate this, integrating the expertise of SMEs throughout the data labeling process is crucial. The approach hinges on a few pivotal strategies that enhance collaboration, streamline workflows, and maximize the impact of SME involvement.

Efficient Collaboration and Rapid Response
Synthesis for SMEs: To maximize efficiency, the labeling platform should have a dashboard that synthesizes labeling progress, highlights areas that require SME attention, and provides insights into data quality. This synthesis allows SMEs to quickly pinpoint and address issues without being bogged down by the full dataset.
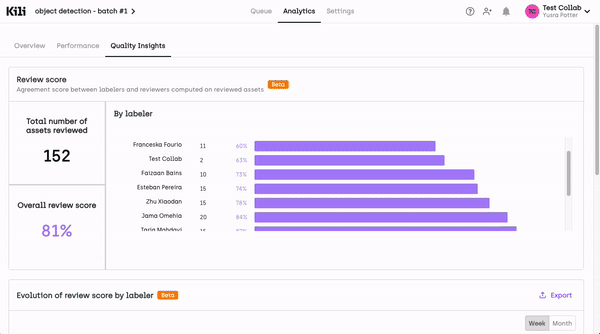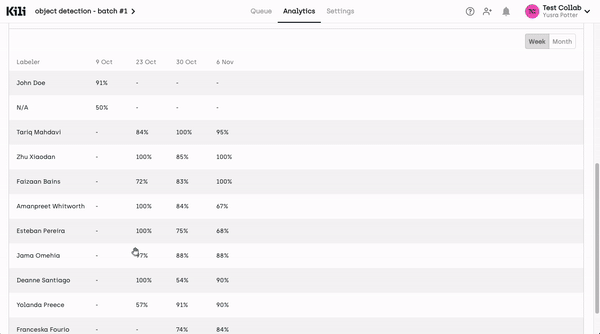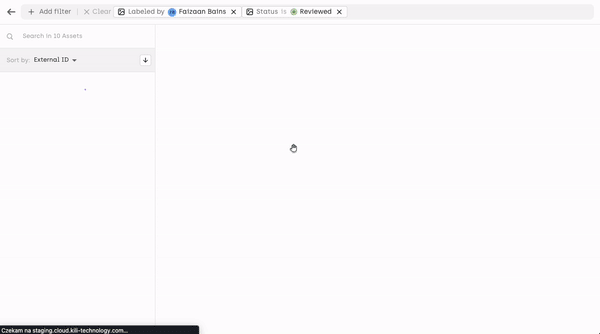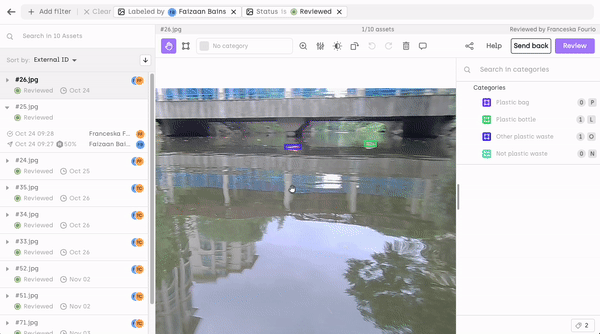
Focus on Collaboration Tools: Tools and features that facilitate effective collaboration between SMEs, ML engineers, and labelers are key. This might include annotation commenting systems, change tracking, and the ability for SMEs to provide feedback or add instructional notes.
Building an adapted workflow
Adapted Workflow Customization: Workflows should be tailored to different project needs, providing SMEs with a clear view of the processes they're influencing. A well-designed workflow could prioritize tasks for SMEs, streamline their review process, and ensure that their input directly improves the model's performance.

Extending SME Impact with Minimal Effort
Subject matter experts (SMEs) in insurance are crucial for their unparalleled insights, but their availability is often limited. Automation, when strategically applied, can greatly amplify their contribution to the data labeling process. The introduction of a labeling copilot—an AI-driven tool—promises to revolutionize this process, enabling SMEs to extend their expertise more efficiently.
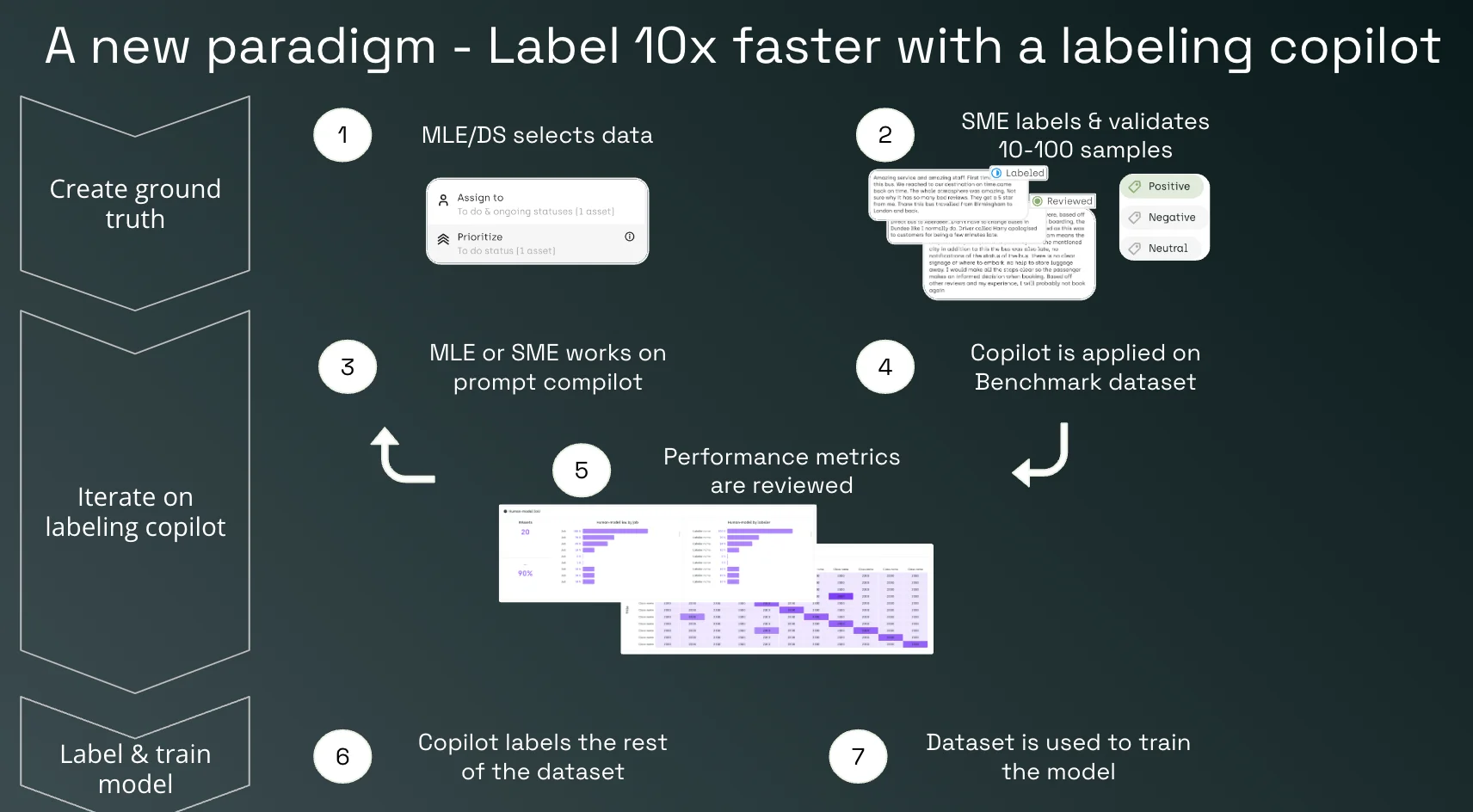
The Labeling Copilot Paradigm
1. Data Selection by ML Engineers/Data Scientists (MLE/DS): MLE/DS kickstart the process by selecting a representative subset of data. This set should be indicative of the larger dataset's variety and complexity.
2. Initial SME Labeling & Validation: SMEs label and validate a manageable number of samples (between 10 to 100). This initial effort sets the quality and accuracy benchmarks for the data labeling copilot to follow.
3. Collaborative Prompting: The SMEs or MLE then work on developing prompts for the copilot. These prompts guide the copilot in making decisions that align with expert judgment.
4. Copilot Application on Benchmark Dataset: The copilot, powered by predefined rules and machine learning algorithms, is applied to a benchmark dataset. This application is closely monitored to ensure the copilot's outputs meet set standards.
5. Reviewing Performance Metrics: Performance metrics of the copilot's labeling are reviewed to identify areas of strength and those needing refinement. These metrics provide insight into how well the copilot emulates the SME's expertise.
6. Full Dataset Labeling by Copilot: Once the copilot is fine-tuned, it labels the rest of the dataset. This approach significantly accelerates the labeling process while maintaining the quality set by the SMEs.
7. Training the Model: The labeled dataset, now enriched and verified by both SMEs and the copilot, is used to train the machine learning model, ensuring it is built on a foundation of high-quality data.
The Impact of Automation
The copilot does not replace the SME but rather extends their capabilities. It allows SMEs to focus their time on the most critical tasks while ensuring that their expertise is diffused throughout the entire dataset. The efficiency gained through this process is significant—what would take an SME days to label can be accomplished in a fraction of the time.
Furthermore, as the copilot continues to learn and improve, it can provide even greater accuracy and adapt to new types of data. The iterative process also means that SMEs can refine the copilot’s capabilities over time, ensuring that the data quality remains high and the model's performance continues to improve.
Conclusion: Enhancing Insurance AI through Strategic Data Labeling Approaches
Implementing AI in the insurance sector is paved with unique challenges stemming from the diverse nature of data, the high-security standards required, and the critical need for domain-specific expertise. Overcoming these challenges necessitates a multifaceted approach, focusing on three key areas: selecting the right interfaces, fostering collaboration, and embracing automation. Together, they create a dynamic environment where AI can be developed, trained, and deployed rapidly and effectively, all while adhering to the industry's stringent security and quality standards. These approaches ensure that insurance companies can harness the full potential of AI to improve efficiency, enhance customer service, and drive innovation in an increasingly data-driven landscape.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
