
.png)


_logo%201.svg)


AI Summary
There a many tasks that a team of labelers on computer vision projects do every day: classification, bounding boxes, segmentation, pose estimation, and named entity recognition to name a few.
When compared to simpler annotation tasks, image segmentation requires a more detailed understanding of the content and context of an image. Let’s understand why.
In image segmentation, each pixel in an image must be assigned to a specific object or region. This requires the annotator to have a deep understanding of the image and the objects within it, as well as the ability to accurately identify and trace the boundaries of those objects. This can be especially challenging in images with complex backgrounds or where objects overlap, making it difficult to distinguish between different objects or to accurately trace their boundaries.

Moreover, segmentation requires a high level of consistency and accuracy, as even small errors or inconsistencies in the segmentation can significantly impact downstream tasks, such as object recognition or scene understanding. This means that the annotator must be highly skilled and experienced, as well as able to maintain focus and attention to detail over long periods of time.
Overall, image segmentation is a complex annotation task that requires a combination of deep understanding, skill, and attention to detail, making it one of the most challenging tasks in image annotation.
Introducing SAM, the Image Segmentation Model from Meta
What is a Foundation Model?
A foundation model is a large neural network that is pre-trained on a large dataset and can be used as a starting point for a wide range of tasks, such as text or image classification, question answering, or language translation.
The main difference between foundation models and traditional models is in their approach to learning. Traditional models are typically trained from scratch on a specific task and require large amounts of labeled data to achieve good performance. In contrast, to train segmentation models like SAM, massive amounts of unlabeled text data are used, with a unsupervised learning approach.
Although foundation models perform well in completing a wide range of tasks, they are adaptable and can be fine-tuned with a few more custom data to support more specific downstream tasks.
SAM, a Generalized Model For Computer Vision Segmentation Purposes
SAM is a foundation model built by Meta to address generalized image segmentation tasks.
SAM can output segmentation masks for computer vision in real-time for interactive use, which makes it a great productivity tool that can be leveraged in a comprehensive labeling process.
SAM can take various input prompts, such as bboxes or clicks, to specify what object to add or remove from the mask,
Because SAM is trained on a vast dataset (SA-1B) of 11 million input images and 1.1 billion segmentation high quality masks, it can detect a wide range of known objects and categories, as well as objects it has never seen before. Therefore SAM usually has great zero-shot performance on a wide range of segmentation tasks and can generate fully automatic annotation.
SAM can help with ambiguous computer vision cases (e.g. a shirt vs. the person wearing the shirt), by completing downstream tasks using the composition process: already at the first prompt, a click for instance, SAM will output at least one valid mask that can then be further reworked by adding/removing its parts.

The Limitations Of The Segment Anything Model (SAM)
As stated by Meta in the research paper that was released with the model's official launch, there are known limitations to SAM’s usage:
While SAM performs well in general, it is not perfect. It can miss fine structures, hallucinate small disconnected components, and does not produce boundaries as crisply as more computationally intensive methods that “zoom-in”. In general, we expect dedicated interactive segmentation methods to outperform SAM when a large number of points is provided. Unlike these methods, SAM is designed for generality and breadth of use rather than high IoU interactive segmentation.
For instance, SAM on its own is not good at detecting tiny objects on aerial imagery, nor does it perform well in segmenting images of low quality. Also, there are still a lot of industry-specific tasks and corner cases that will require additional fine-tuning to be properly supported.
Why Strapping SAM To Our Segmentation Tool Will Boost Your Productivity
To make sure that we provide our users with the smoothest and most efficient labeling tool, we’ve integrated SAM into Kili Technology’s image segmentation tool. This means that labelers working on Kili Technology will now be able to leverage SAM when annotating their image or computer vision datasets.
With SAM working in the background, annotators can now focus solely on understanding the image context and then interpreting it for the purpose of the labeling project, rather than spending time defining the boundaries of each target point-by-point.
Having a performant image segmentation tool where annotators can edit a valid segmentation mask by adding and removing objects in a matter of (very few) clicks is a great time saver, and will significantly help you gain productivity and competitiveness.
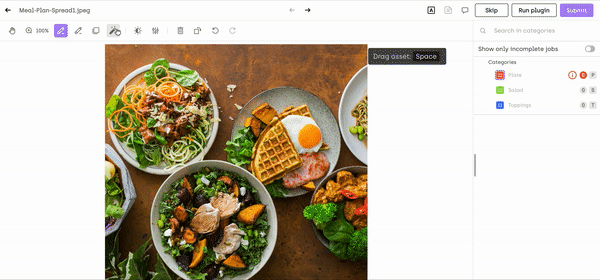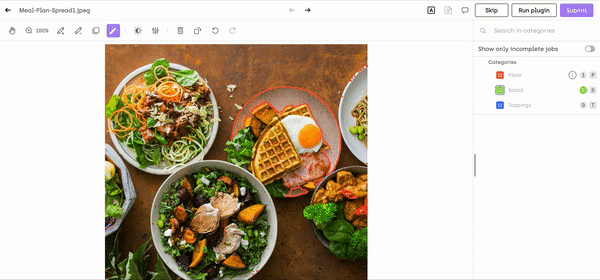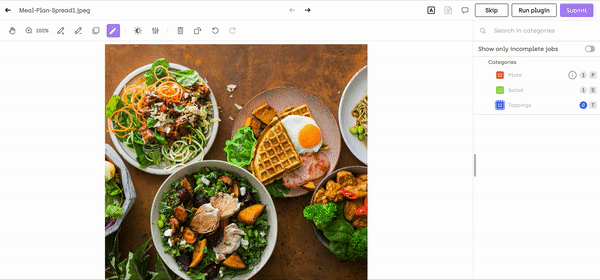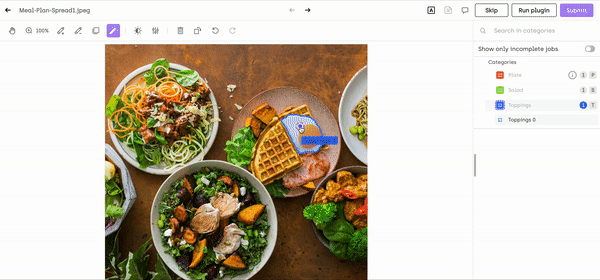
If you want to dive deeper into how to use our interactive segmentation tool, check our product documentation. And you can try the tool for yourself for free!
FAQ on SAM, Data Labeling and Segmentation Masks
What are the labeling formats supported by Kili Technology?
In addition to supporting image segmentation, the Kili Technology platform supports other computer vision tasks: image classification, video classification, bounding box, polygon, point, line, geospatial data annotation, object tracking, etc. It also supports natural language processing with text annotation (rich text, and conversation), and document annotation (documents, pdfs, OCR). On text and documents you can do classification, named entity recognition, and objects relations to name a few.
What is the integration between Kili Technology and SAM?
By integrating SAM into our semantic segmentation tool, we allow our users to benefit zero shot generalization to automatically generate multiple valid masks to segment objects in image datasets. SAM uses image embeddings to generate a reasonable and valid segmentation mask. You can use it on multiple objects and it predicts segmentation masks on unknown data. Overall it accelerates the annotation of object masks by a factor 2 compared to our previous segmentation tool. Game changer artificial intelligence!
Is Kili Technology free among image annotation tools?
Yes, you can use Kili Technology for free to do computer vision, video, text, document, or image annotation. Our free plan allows you to label small datasets, and our pricing plans will enable you to grow as your final dataset grows. It's an excellent starting point to try our platform for yourself and experiment with the power of a data engine with our different annotation types to create multiple valid masks (bounding boxes, semantic segmentation mask, segmentation mask, polygon, point, etc...) from different types of image assets (raw files of many formats, image size variations, even video editing results).
Is Kili Technology an open-source software?
Kili Technology is not an open-source software. However, you can use our free plan to do image annotation and computer vision tasks, use our geospatial tools & segmentation masks, and do everything needed to output multiple valid masks & training data into powerful datasets and in the end, powerful segmentation models. Note that when using our free plan, you may not benefit from all our various tools at 100% of their capacity.
How is Kili Technology different from other image annotation tools?
Kili Technology platform is different because we put quality at the core of our product. Many low-cost labeling tools focus on improving labeling productivity, which we do as well, but disregard the focus on creating quality data. For instance, you can inspect the data distributions of your annotation and detect mistakes. Kili is a data engine where the annotation process is dedicated to data quality.
At Kili Technology, we build our image annotation features to allow users to create high-quality datasets, and generate masks that yield the best machine-learning models' performance results.
When should I use Kili Technology?
When you want to create a new datasets (ex. benchmark dataset) or when you want to improve the quality of an existing dataset. To interactively annotate images, create object masks, run few shot learning, generating masks of any kind, polygon annotations, a bounding box, an object detector, all to create a trained model, Kili Technology is the right fit for you. If you're using an existing segmentation dataset that is not SAM, you can easily plug in your own model & data engine to run pre-annotation on Kili Technology. Both the model & the data engine have a impact on the pre-annotations you run. Even if you start with zero-shot transfer learning or zero shot generalization, at some point your fine-tuning will benefit of Kili.
How does Kili Technology ensure data security in my annotation process?
Kili Technology as an image annotation tool is fully secure with a SOC2, ISO 27001 & HIPAA certification. We put a high priority on privacy preserving images, as well as any kind of protection against bias (perceived gender presentation, cultural and racial representation, etc). We also provide different deployment options to fit the data security needs of our customers. Note that data management options may vary depending on your hosting mode (Cloud or On-premise).
Is Kili Technology providing automatic annotation?
Kili Technology's API is accessible to our users. Therefore, you can connect your machine-learning model to generate pre-annotations on computer vision, image annotation, object detection, semantic, segmentation task, video annotation, instance segmentation tasks, and more. We also support segmentation tasks augmented with the Segment Anything Model (SAM) and any other foundation model with prompt engineering or segmentation model based on input prompts. To learn more about prompt engineering, you can check our recent webinars here.
Does Kili Technology offer integrations?
Kili Technology has been designed to integrate seamlessly into your existing ML stack, easily import and export data, create and manage labeling projects, and manage your ML project's entire training data lifecycle on Kili Technology. It offers flexible integration with cloud storage. Use the CLI & our SDK to quickly upload and download vast amounts of data. You can also use Kili Technology with foundation models such as ChatGPT or Segment Anything Model (SAM) and leverage input prompts to run a promptable segmentation task to label your data.
What are concepts related to computer vision & segmentation that I need to know?
There are a few things that ML engineers should understand when working with segmentation masks and data labeling. Here is a list of definitions to help you.
- image embedding: An image embedding is a representation in lower dimensions of the image. It is a dense vector representation of the image that can be used for various ML tasks such as classification.
- image encoder: an image encoder writes image data to a stream. Encoders can encrypt, compress and alter the pixels of the image before writing them to the stream.
- embedding vector: an embedding vector is a series of numbers to be considered as a matrix with multiple columns and one unique row. It includes data representing the characteristics of an object, such as RGB (red-green-blue) color descriptions.
- prompt encoder, mask decoder & lightweight mask decoder: the encoder consists of encoding layers that process the input iteratively one layer after another, while the decoder consists of decoding layers that do the same thing to the encoder's output.
- prompt embeddings: prompt embeddings are strings of numbers that distills knowledge from the larger model.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
