
.png)


_logo%201.svg)


AI Summary
Introduction to protecting unstructured data during the data labeling process
Businesses are increasingly exploring ways to leverage advancements in generative AI (GenAI), large language models (LLMs), and foundation models to improve productivity and gain value. However, building trustworthy AI applications is a significant challenge that requires processing and labeling unstructured data—data that can be considered sensitive and must be protected.
This article dives into the complexities of safeguarding unstructured data during labeling and provides a comprehensive guide for data scientists, ML engineers, and AI project directors.
Understanding unstructured data protection in data labeling
Data labeling is the process of identifying raw unstructured data files (such as images, text files, videos, etc.) and adding one or more meaningful and informative labels to provide context so that a machine learning model can learn from it.
Unstructured data can provide valuable information for machine learning models. However, this data often contains sensitive information that can pose significant privacy and security risks if not appropriately managed.
Protecting unstructured data during the data labeling process is crucial for several reasons:
- Privacy Concerns: Unstructured data often contains sensitive information. For example, images and videos may inadvertently capture personal details, and text data might include private conversations or personally identifiable information (PII). Ensuring privacy involves masking or removing sensitive information to prevent misuse or compliance violations.
- Security Risks: If unstructured data falls into the wrong hands, it can lead to security risks such as identity theft, financial fraud, or even corporate espionage. Protecting data helps prevent unauthorized access and protects individuals' and organizations' security.
- Compliance with Regulations: Various laws and regulations, such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA), require the protection of personal data. These regulations often include specific guidelines about handling unstructured data, and non-compliance can result in hefty fines and legal issues.
- Data Integrity: Protecting data also means ensuring its accuracy and consistency over its lifecycle. In machine learning, data integrity is crucial for training reliable and effective models. Any alteration or corruption of data can lead to biased or inaccurate models.
- Ethical Considerations: Beyond compliance and security, there's an ethical obligation to protect individuals' privacy and respect their rights over their data. Ethical data use promotes trust and confidence among data subjects and the wider community.
Examples of use cases that handle sensitive unstructured data
To go into detail, there are specific use cases that require cautious handling due to the sensitivity of the information involved. Here are some of them:
1. Medical Image Analysis
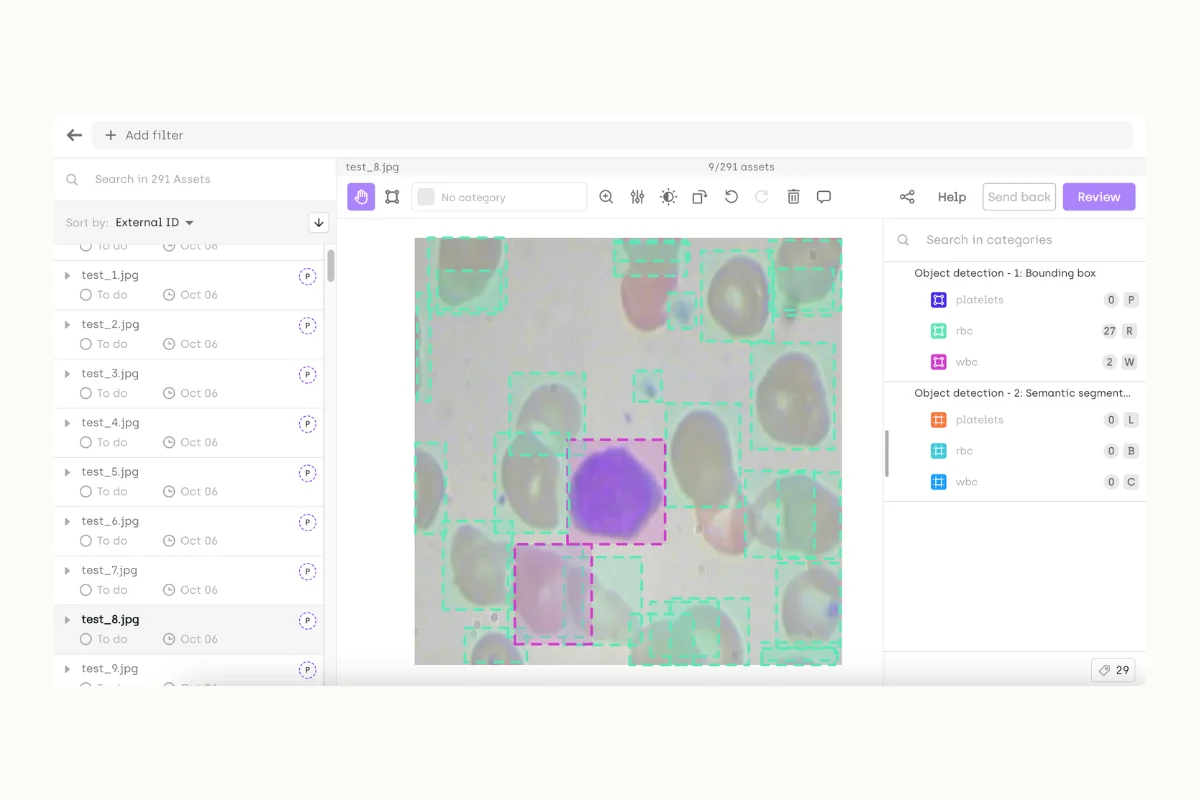
- Use Case: Computer vision in the medical industry involves labeling X-rays, MRI scans, and other medical images for conditions or anomalies.
- Sensitivity: These images contain personal health information that could be used to identify patients and reveal sensitive health conditions.
2. Financial Document Processing
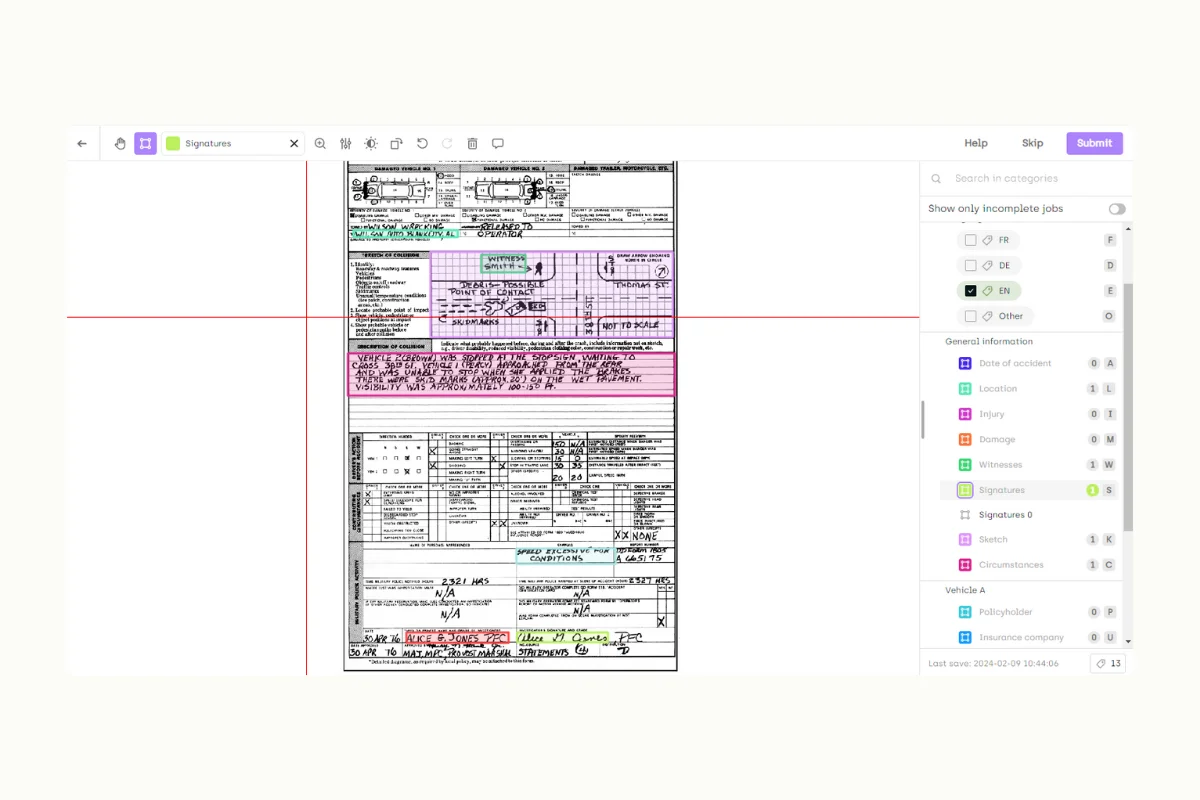
- Use Case: Optical character recognition, extracting, and classifying information from bank statements, tax documents, and loan applications for automation and analysis.
- Sensitivity: Financial documents contain confidential information like social security numbers, account details, and financial status.
3. Personal Data Extraction from Text
- Use Case: In natural language processing, identifying and categorizing personal information in text data, such as emails or social media posts, for customer service or sentiment analysis.
- Sensitivity: Text data may include names, addresses, phone numbers, and other personally identifiable information (PII) that must be protected.
4. Facial Recognition in Images and Videos
- Use Case: Computer vision use cases that require annotating images and videos for facial recognition technologies used in security, marketing, and entertainment.
- Sensitivity: Facial data is a highly sensitive and personally identifiable form of biometric data, raising privacy and ethical concerns.
5. Autonomous Vehicle Training
- Use Case: Labeling video and sensor data from vehicle cameras for object detection, such as pedestrians, other vehicles, and road signs.
- Sensitivity: This data can inadvertently capture individuals, license plates, and potentially sensitive locations, requiring careful handling to respect privacy.
6. Voice and Sentiment Analysis
- Use Case: Transcribing and annotating audio recordings for voice and speech recognition, sentiment analysis, or conversational AI.
- Sensitivity: Audio recordings can contain sensitive personal information, conversations, and background noises that may identify individuals or private activities.
7. Legal Document Analysis
- Use Case: Analyzing and categorizing legal documents for case research, discovery processes, or compliance monitoring.
- Sensitivity: Legal documents can contain confidential information about individuals, corporations, or ongoing legal matters, requiring strict confidentiality.
8. Employment and Education Records Processing
- Use Case: Digitizing and categorizing resumes, application forms, and academic records for recruitment or admission processes.
- Sensitivity: These documents contain personal history, contact information, and other personal details that are private and sensitive.
Challenges for balancing quality and data security
Balancing data labeling quality with security presents several challenges, especially when handling sensitive or unstructured data.
Achieving high-quality data labeling is crucial for the development of accurate and reliable machine learning models, but it must be done without compromising the security and privacy of the data involved. Here are a couple of challenges:
1. Access vs. Anonymity
- Challenge: Data labeling often requires access to detailed information to ensure accurate and meaningful labels. However, providing the anonymity and privacy of individuals’ information, especially in sensitive datasets, can limit the information available to labelers.
Implement role-based access control (RBAC) and use data anonymization techniques to ensure that data labelers have access only to the information necessary for their tasks while maintaining individuals' anonymity.
2. Detailed Labels vs. Privacy Preservation
- Challenge: High-quality data labeling may require fine-grained distinctions that can inadvertently reveal sensitive information. For example, labeling medical images with specific conditions or outcomes requires access to potentially sensitive health information, which must be handled securely.
Utilize privacy-preserving data labeling tools that enable detailed annotations without exposing sensitive information.
3. Expertise vs. Security Risk
- Challenge: Certain domains, like healthcare or finance, require domain-specific knowledge to ensure high-quality labeling. This often means granting experts or third parties access to sensitive data, increasing the risk of data breaches or misuse. Balancing the need for expertise with the imperative to secure data is complex.
With sophisticated data bucket management strategies, organizations can ensure that only the necessary data is accessible to individuals or systems with the required expertise, thereby minimizing security risks.
4. Collaboration vs. Data Protection
- Challenge: Data labeling is frequently a collaborative effort involving multiple annotators, reviewers, and subject matter experts. Facilitating effective collaboration while enforcing strict data access controls and protection policies can be challenging, as it may impede workflow efficiency and labeling speed.
Employ secure collaboration platforms that provide end-to-end encryption and strict access controls. Ensuring data is encrypted both in transit and at rest can protect it during collaborative efforts.
5. Use of Automation and AI vs. Security Vulnerabilities
- Challenge: Automating parts of the data labeling process using AI can enhance efficiency and quality. However, these systems themselves may introduce new vulnerabilities, especially if they require access to large datasets for training and operation. Ensuring these systems are secure and do not expose sensitive data is crucial.
Integrate security by design in AI systems used for data labeling. Regular security assessments, including penetration testing and vulnerability scanning of AI systems, can help identify and mitigate potential risks.
6. Regulatory Compliance vs. Operational Efficiency
- Challenge: Complying with data protection regulations (e.g., GDPR, HIPAA) necessitates strict data handling and security measures, which can add complexity and reduce operational efficiency. Organizations must find ways to remain compliant without excessively hindering the data labeling process.
Conduct regular audits to ensure that the data labeling platform complies with relevant data protection regulations (e.g., GDPR, HIPAA). This may involve third-party security assessments and compliance certifications.
7. Data Volume vs. Security Scalability
- Challenge: The sheer volume of data needing labeling for large machine-learning projects can strain security measures. Ensuring that security scales effectively with the increasing amount and sensitivity of data without compromising labeling quality or speed is a significant challenge.
If the data labeling platform is third-party, conduct regular security assessments of the vendor, including reviews of their security policies, compliance certifications, and security practices to ensure they meet your organization's standards.
Balancing these challenges requires a multifaceted approach, including implementing robust data protection measures, employing secure data labeling platforms, training staff on data security best practices, using a VPN, such as Proton VPN or NordVPN, to secure remote data access, and possibly leveraging synthetic data or advanced anonymization techniques.
Additionally, constant vigilance and adaptation to new security threats and regulatory changes are essential to maintain this balance over time.
The right deployment to ensure data security for data labeling tools
With the criticality of ensuring security in data labeling, it's no wonder some companies have opted to build their own tool or keep data labeling work in-house. However, choosing to develop an in-house data labeling tool can incur significant technical debt that can be difficult to eliminate as data labeling needs grow.
Such is the experience of enterprises such as major insurance companies that regularly face the balancing act of data privacy and data quality.
Third-party data labeling tools can be considered in this case, but candidates must be chosen carefully to ensure the security of the raw and processed data. Data labeling tools must have the right deployment options to ensure security and compliance. Here's a comparative overview to help a machine learning team make an informed decision:
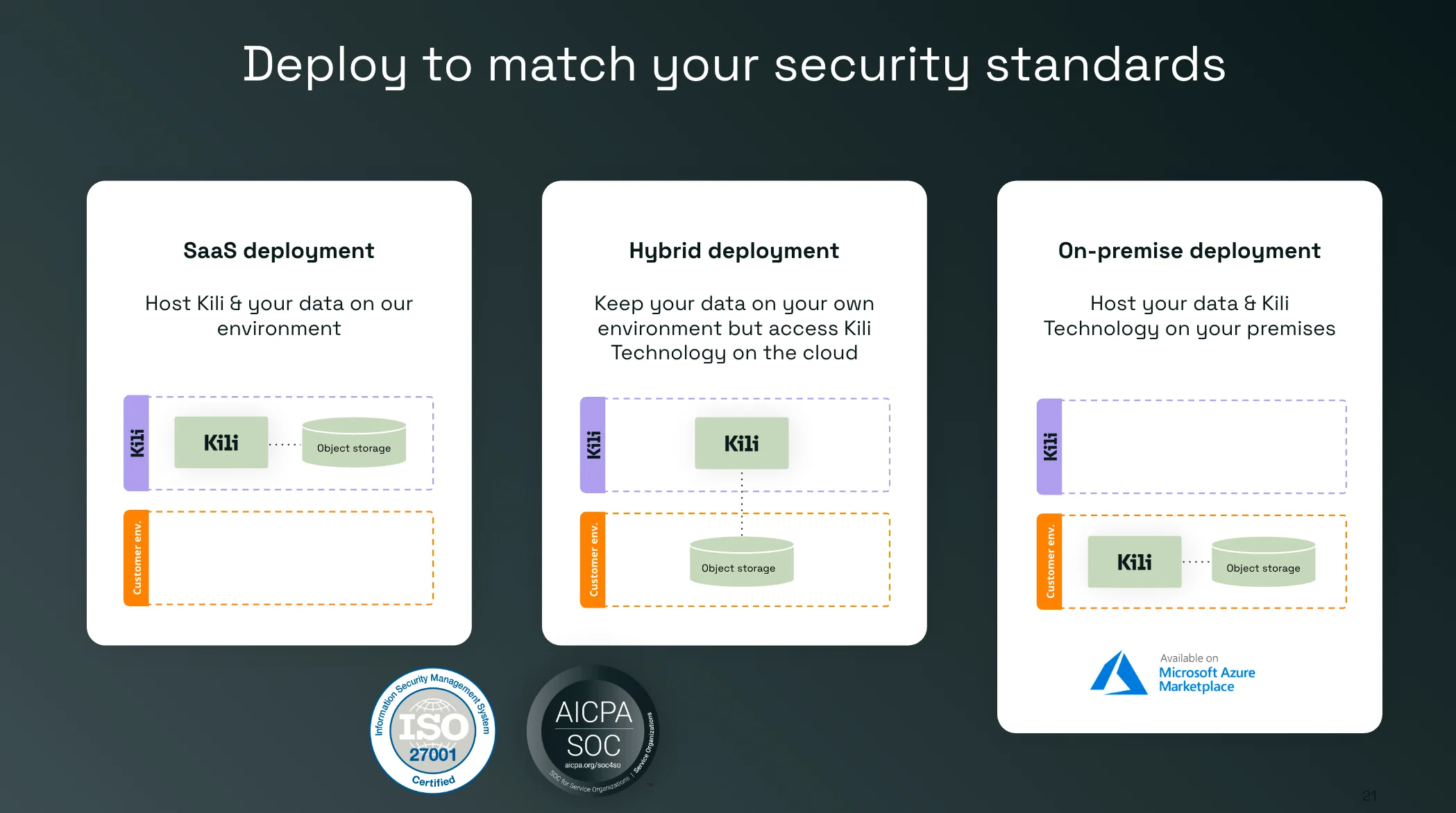
1. SaaS Deployment
- Description: This software-as-a-service model hosts the data labeling tool and the customer's data on the provider's environment.
- Considerations: Machine learning teams that want a quick setup without managing infrastructure might choose SaaS. It's usually cost-effective and scalable, and the service provider handles maintenance. However, teams must trust the provider to secure their data and ensure it meets compliance standards.
2. Hybrid Deployment
- Description: In a hybrid deployment, the customer's data remains in their environment (ensuring data privacy and control) while they access the data labeling platform on the cloud. With this type of deployment, it’s possible to avoid any transit of your raw data on the platform’s infrastructure.
- Considerations: Teams that handle sensitive data, like medical or financial records, may prefer this. It allows leveraging the cloud's scalability and the service's features while maintaining stricter control over the actual data. This can be crucial for compliance with regulations like GDPR or HIPAA.
3. On-Premise Deployment
- Description: The customer's data and the data annotation tool are hosted on the customer's premises.
- Considerations: Teams with the highest security needs and those required to comply with strict data sovereignty laws often opt for on-premise solutions. It offers maximum control over security protocols and data storage. However, it also requires a larger upfront investment and resources for infrastructure and maintenance.
How we meet your security standards
Discover why enterprises choose Kili Technology for data labeling solutions that don't compromise on security or flexibility.

Schedule a quick demo
Why Consider Each Option:
- SaaS Deployment: Choose if you want lower costs, less complexity in setup and maintenance, and if the service provider's capabilities satisfy your security and compliance needs.
- Hybrid Deployment: This is a middle ground, useful if your organization wants to maintain control over data storage for security or compliance reasons but still wants to take advantage of the scalability and features offered by a cloud service.
- On-Premise Deployment: This option is recommended if your organization must keep data in-house due to regulatory requirements, security policies, or specific business needs and is willing to invest in the necessary infrastructure.
Choosing one of these deployment options depends on various factors, including the organization's regulatory compliance needs, security requirements, scalability demands, resource availability, and preference for control over the data and infrastructure.
Kili Technology offers these three options. On Kili Technology, the SaaS version is deployed with two providers: Azure and GCP. It has the proper certifications, so ML teams can spend less time building their own data labeling tool and more time focusing on creating the best training datasets for their model training.
Best practices for dealing with unstructured sensitive data during the labeling process

Adopting a structured approach to data bucket management is paramount to ensure the integrity and security of sensitive unstructured data during the labeling process. Below are best practices centered around this approach:
Data Bucket Management for Enhanced Data Protection
1. Utilization of Data Buckets: Organize and store data within specific containers, known as data buckets, within your cloud or on-premises infrastructure. Assign each bucket to a distinct project, team, or data type to maintain organized and segregated data storage. This setup facilitates controlled access and minimizes risk.
2. Deployment of an Applicative Layer: Implement a platform, like Kili Technology, that serves as the applicative layer interfacing with the data buckets. Whether hosted on the cloud or on-premises, this layer is where data labeling tools and services are accessed and managed, ensuring a secure and controlled environment for sensitive data handling.
3. Project-Specific Data Storage: Allocate designated object storage buckets for projects such as "Geospatial analysis" or "Claim processing." This organization allows for project-specific data management, enhancing security and access control measures.
4. Delegated Access for Teams: Provide access to data buckets based on team or project needs. For instance, a "real estate" team would have access to specific projects and their associated data buckets, distinct from those accessible to a "life insurance" team. This practice ensures that teams only access data relevant to their projects, significantly reducing unnecessary exposure.
Why This Is a Best Practice for Data Protection:
- Delegated and Controlled Access: Organizations can implement effective access control strategies by segmenting data storage and access on a per-project or per-team basis. This minimizes the risk of data breaches by ensuring that individuals only have access to the data necessary for their specific tasks.
- Physical and Logical Separation of Data: Keeping data physically and logically separated by project or team helps prevent unauthorized access and cross-contamination between datasets. This separation ensures that access privileges in one project do not imply access to another, maintaining strict data access boundaries.
- Micro-Management of Access Rights: Tailoring access rights within teams according to the principle of least privilege allows organizations to finely control who can view, edit, or label data. This granularity in access management further secures sensitive information against unauthorized manipulation.
Advantages of Data Bucket Management in Data Protection
- Containment of Breaches: Should a data breach occur, its impact is limited to the compromised bucket, significantly reducing potential damage.
- Simplified Compliance: Managing data in organized buckets with strict access controls makes it easier to comply with regulations such as GDPR or HIPAA, as data handling and privacy measures are clearly defined and implemented.
- Improved Data Governance: This structured approach supports robust data governance, assigning clear responsibility for data sets and ensuring that data handling practices meet organizational standards.
- Enhanced Audit and Oversight: Monitoring and auditing data access and manipulation become more straightforward with defined boundaries and access patterns for each project and team. This clarity aids in more efficiently detecting and addressing unauthorized activities.
Incorporating data bucket management into the data labeling process represents a strategic approach to safeguarding sensitive unstructured data.
Organizations can significantly enhance the security and integrity of their data labeling endeavors by enforcing precise access controls, reducing unauthorized access risks, and facilitating compliance and governance.
Demonstration
Watch video
Conclusion: Building a robust framework for protecting your data and building trustworthy AI
Businesses are increasingly using generative AI, and foundation models to develop AI applications. However, it is crucial to prioritize the privacy and security of sensitive information while building trustworthy AI applications. Data labeling is a complex process, and managing sensitive unstructured data poses significant challenges. This article provides insights into best practices for managing such data to ensure data security and privacy.
It is vital to stay informed and adaptable as threats and regulatory landscapes evolve. By adopting a comprehensive and proactive approach, businesses can ensure the integrity of their AI projects and build trust among stakeholders.
The ultimate goal is to create a secure foundation for AI applications that respect privacy, comply with regulations, and uphold ethical standards. Achieving this requires collaboration, innovation, and adherence to best practices in data management. By doing so, organizations can unlock the full potential of their AI initiatives while safeguarding the invaluable asset of unstructured data.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
