.png)
.svg)
.svg)
.svg)









.webp)
.webp)
.webp)

November 14, 2024
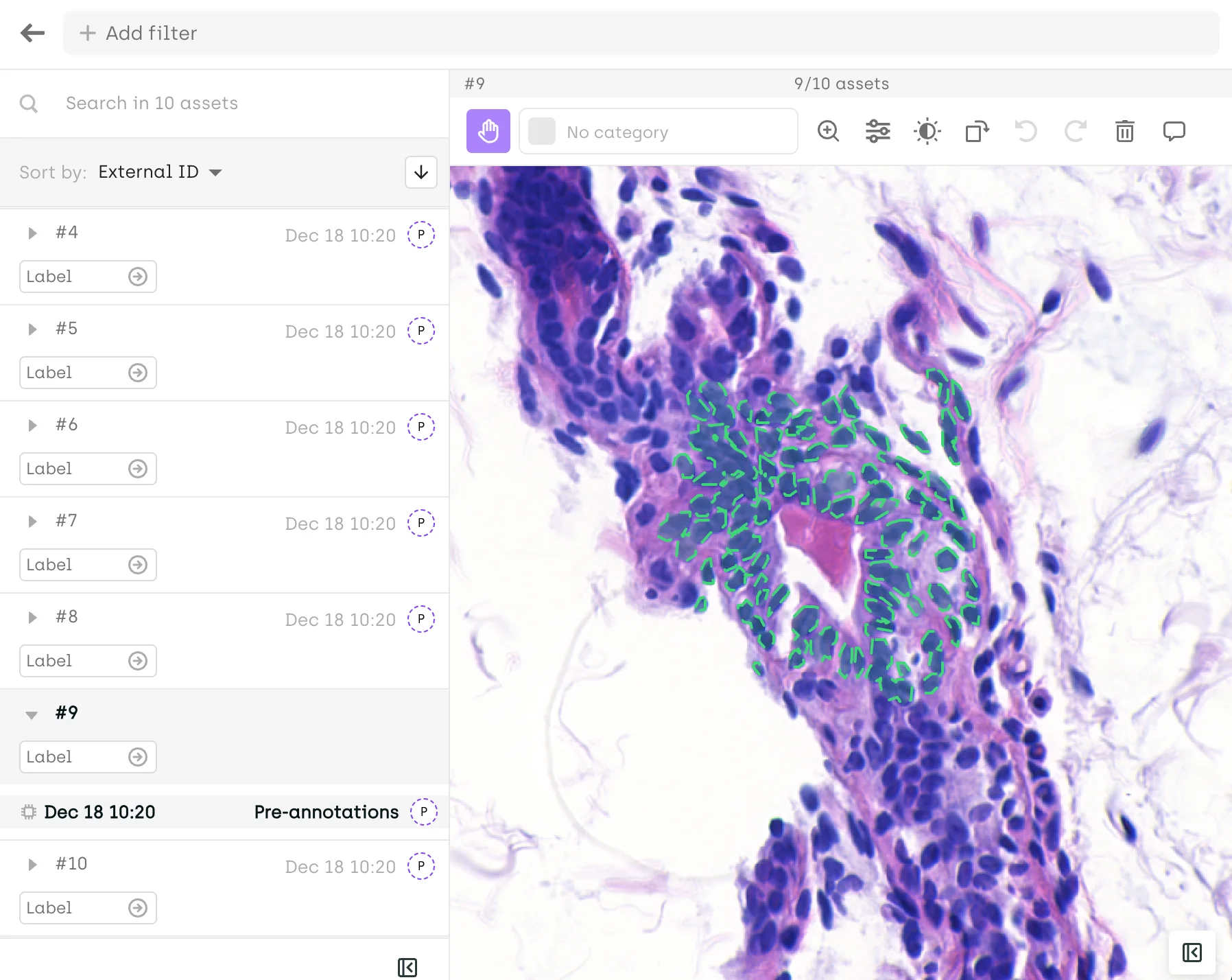
SAM 2 Update for Geospatial Imagery and Video Data Labeling
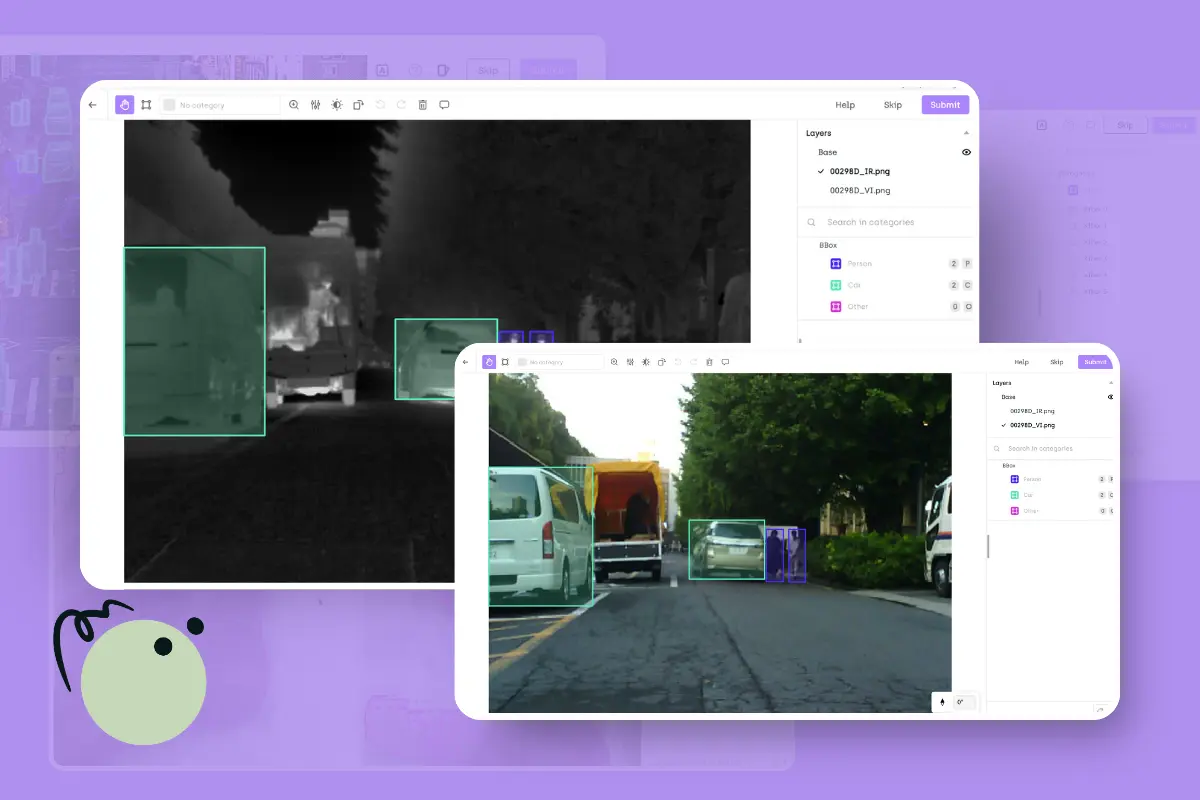
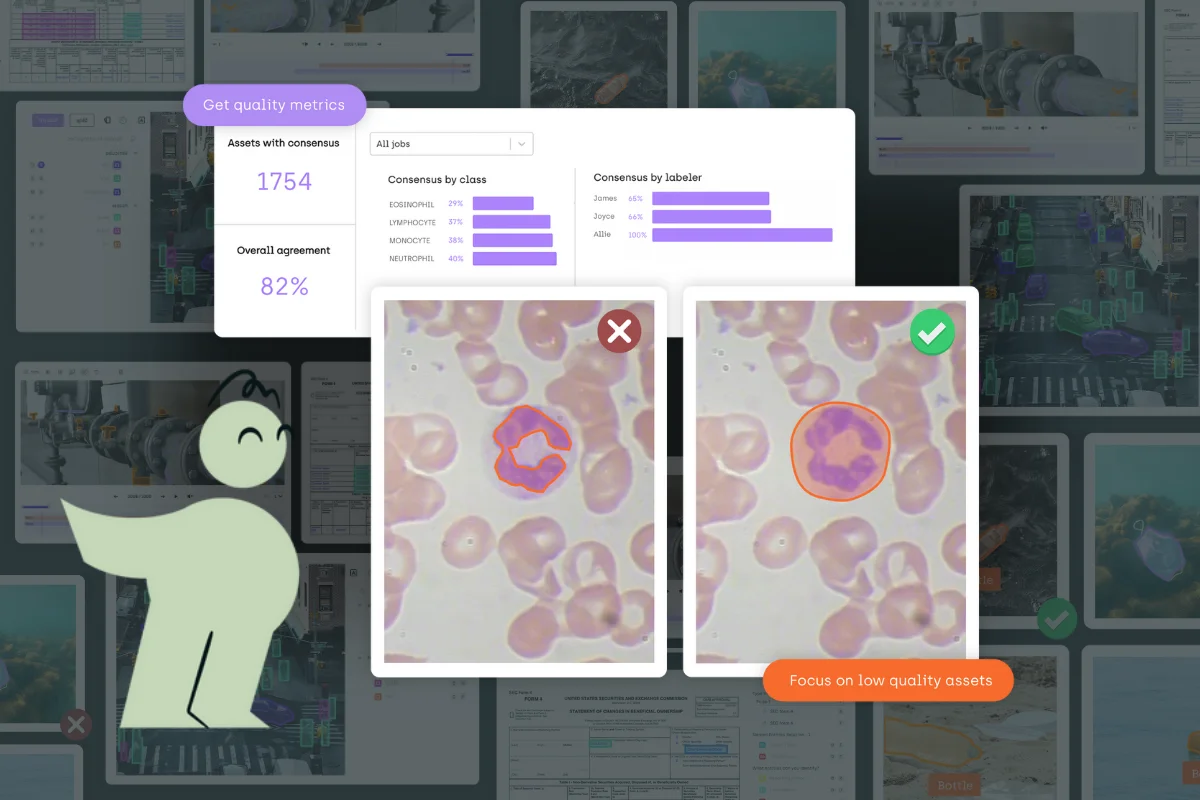
Today, Kili Technology addresses the fundamental challenges of computer vision data labeling with the integration of Meta's Segment Anything Model 2 (SAM2) into our annotation platform, bringing unprecedented efficiency to both geospatial and video annotation tasks.
.png)