
.png)

_logo%201.svg)


AI Summary
- Structured data carries meaning in each value, while unstructured data like images, audio, and text derives meaning from patterns across neighboring elements.
- Pre-deep-learning pipelines for unstructured data relied on feature extraction steps such as MFCC coefficients in speech, while deep learning now learns features directly.
- Evaluation metrics for unstructured tasks like object detection combine multiple criteria including location, missed detections, and class accuracy, making them more elaborate than classification or regression.
- Both data types follow the same high-level ML pipeline of collect, train, evaluate, and deploy, but the tools and validation strategies differ substantially.
- Embeddings replace handcrafted features for unstructured data, and a single validation dataset often replaces cross-validation when training deep models at scale.
Machine learning can handle structured data and unstructured data. Yet, the main steps remain the same: you collect training data, you train a model, then you can evaluate it and eventually deploy it in production. Depending on if you process structured or unstructured data, the methods you will need to use may look really different. What is the difference between structured and unstructured data? And how does it impact the building of your Machine Learning pipeline?
What is Structured Data
Structured Data: Definition
Structured data is organized data, like a spreadsheet or a database. Each data point (or row, record) is composed of features, which are values that have an identified meaning, like name, country, age, size… The data points may relate to each other: they can be organized in tables, sequences, graphs, or trees.

Example of a structured dataset: a list of earthquakes with several measurements (source: Kaggle)
Structured Data: Example
If the data you handle is coming from an Excel spreadsheet or a CSV file, there is a good chance it is structured data.
Here are examples of structured data:
- the daily price statistics of financial assets;
- a log of the user actions on an e-commerce website;
- the sale events of cars with their characteristics in a given country.
Several kinds of structure
Elements of structured data can be organized in several ways:
- Tabular data: the data is organized into tables (rows and columns). That’s the most frequent type of structured data organization processed with Machine Learning. There are many algorithms or toolboxes available that allow one to train a model quickly (i.e., in a matter of seconds) and obtain state-of-the-art results, like XGBoost or Scikit-learn.
- Network data: the data is organized in a graph-like structure. Each element of the data (a node or a vertex) is linked to one or several other nodes. The predictions made on social networks are typically done on data organized that way.
- Hierarchical data: the data is organized in a tree-like structure.
- Time-series data: the data is organized in an ordered sequence of observations. It may look like tabular data, but the addition of a timestamp has crucial importance and imposes an order between each sample.
- Geospatial data: the data is composed of elements with spatial coordinates (generally latitude, longitude, and altitude) and sometimes a time component when studying trajectories. The elements are points, lines, polygons, etc.
Unstructured data: what is it, again?
Unstructured data: definition
Unstructured data is data where individual data points do not carry any meaning when taken in isolation. When unstructured data is generated, there is no explicit relationship between the data points and their location in the content data layout. However, this kind of data is not purely random; structure emerges from the values of neighboring data point carries. For example, in images, one of the most popular instances of unstructured data, objects materialize when neighboring pixels carry close values or exhibit regular patterns like a texture. In contrast, each value of a medical record, which is a structured data example, carries its own meaning.

Example of an unstructured dataset: a sample of the MNIST dataset (source: Wikipedia)
Unstructured data: content types
The content that can be considered unstructured data are:
- Images;
- Text;
- Videos;
- PDF documents;
- Lidar.
A human being can immediately infer the meaning of such content in cases it is meant for human perception (like in audio, images, text), except in some fields where experts are needed, like in medical imagery. However, it is way more difficult for a computer to infer the meaning without Machine Learning.

Different types of structured data.
Unstructured data: how to process it?
Each content type has historically been the topic of an entire research field, like:
- Computer Vision for images and videos;
- Natural Language Processing for text;
- Document Processing for documents;
- Speech Processing for audio files or streams containing speech…
Moreover, the involved Machine Learning tasks are more diversified than on structured data, where classification and regression are the most common tasks. Tasks on unstructured data can exhibit more complexity. For example:
- In Computer Vision, tasks like object detection, semantic segmentation, and panoptic segmentation require extracting and structuring the objects from the image data.
- In Natural Language Processing, tasks like Summarization, and Question Answering, require outputting possibly long text from the input text.
Historically, the methods that process unstructured data have relied on a preliminary feature computation step. The role of this preliminary step was to extract or qualify the underlying structure of the unstructured data. For example, in Speech Recognition, the MFCC coefficients were computed to qualify the shape of the spectral envelope, which helps a lot in identifying the phonemes.
But nowadays, the latest research advances from academic and mostly corporate laboratories like Deepmind, OpenAI, Microsoft, and Meta yielded tremendous progress on unstructured data, most notably through the developments of Deep Learning techniques. The feature extraction step is not necessary anymore, and performances for all the ML tasks have considerably increased.

Machine Learning Model on unstructured data before the deep learning era

Machine learning on unstructured data in the deep learning era
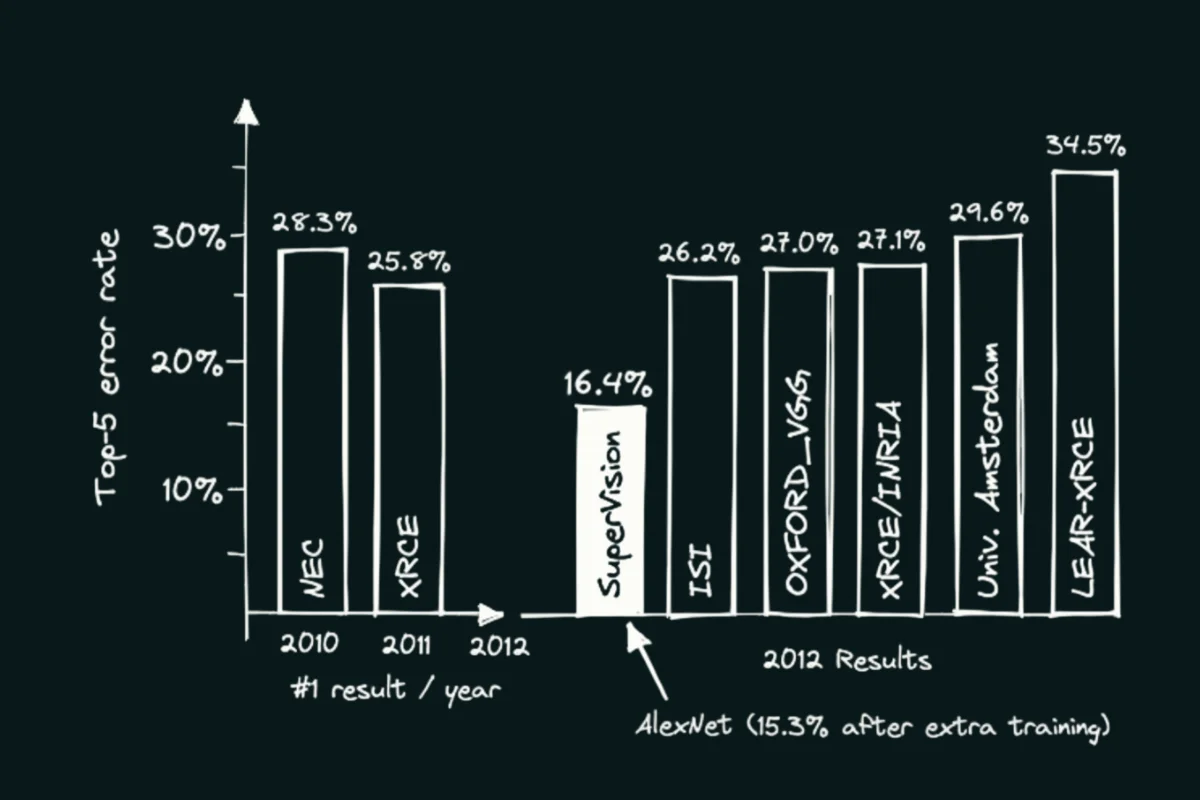
If we take, for example, the Image classification task, here is the improvement brought by the first “deep learning” model:

Evolution of the Image Classification results in the Imagenet challenge until AlexNet, the first practical “deep learning” approach (source: Pinecone)
Unstructured data: its impact on an ML pipeline
Feature engineering versus embeddings
As said in the previous section, modern approaches to processing unstructured data do not require feature engineering. This is a benefit: this is one step less to engineer, deploy and monitor. Feature engineering also often requires domain expertise or craftsmanship. But there is also a drawback of abandoning features: they can help diagnose data issues and data drifts.
To circumvent that, embeddings can be leveraged. Embeddings are a compact representation of the content in the shape of a vector of numbers (typically hundreds or thousands of elements) that have interesting properties:
- two items with close semantic properties will have close representations in the embedding space.
- two items that are dissimilar will have embedding representations distinct from each other.
- operations can sometimes be done in the embedding space to convert an item to one another.
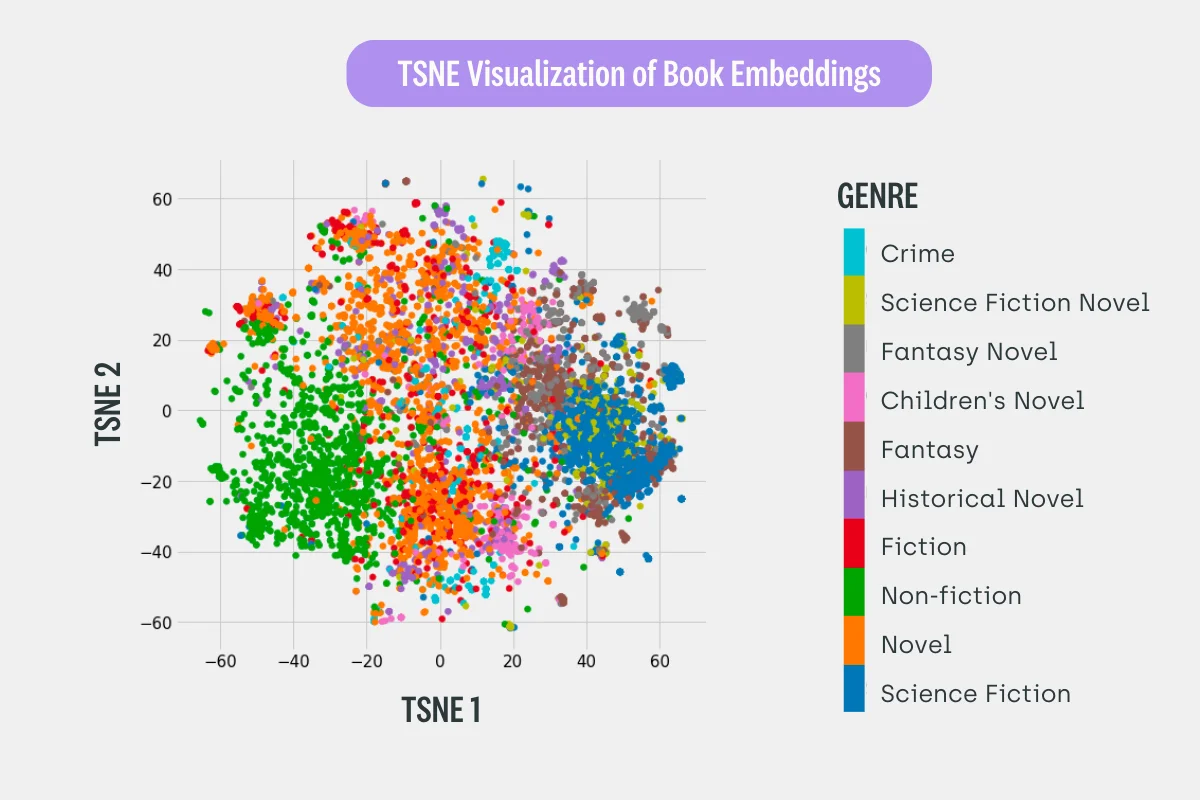
Books on Wikipedia are clustered by genre in just two dimensions from an initial embedding representation.
Source: Koehrsen 2018, via https://devopedia.org/word-embedding
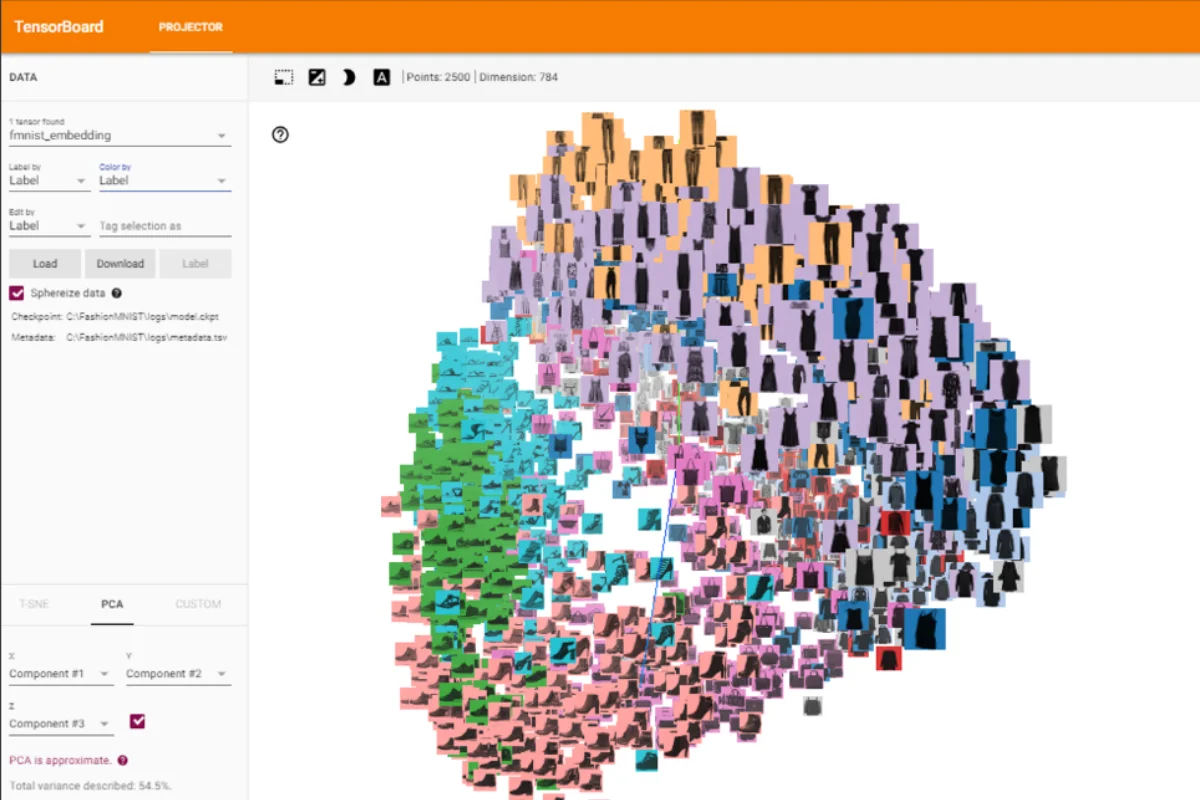
FashionMNIST dataset visualization in Tensorboard in an embedding space project in 2D. (Source: kaggle)
So in practice, despite the absence of features, embeddings can help you to spot issues like outliers or confusing examples, and measuring the distribution of your dataset in this space can help you detect data drifts. This approach has been adopted by Arize, for example.
Unstructured Data and Annotations
An important first step before doing supervised training on unstructured data is to build an annotated dataset. You need to:
- 1. Obtain the data through sourcing techniques. For practical tips, read our dedicated blog post on how to create datasets.
- 2. Annotate it. For that purpose, you can leverage an annotated data platform like Kili Technology, that lets you ingest your raw data sources (in the image, video, text, and document formats you need) and have it annotated by one or a team of annotators with configurable quality requirements. You can then use this dataset to build your Machine Learning model.

Process of turning unstructured data into business outcomes by using the Kili Technology's Labeling Platform.
Unstructured Data and Algorithms
Unstructured data differs from structured data. As pointed out in the previous section, Deep Learning algorithms are nowadays the standard methods to deal with unstructured data. These algorithms are typically more complex and require more computing power and storage, more training data, and, most of the time, dedicated processors like GPUs (Graphical Processing Units) or TPUs (Tensor Processing Units). These additional computation requirements make some processes often used in the case of structured data less used in practice for unstructured data:
- Because of the training costs, you may not use cross-validation on unstructured data. Generally, only a separate validation set is used to optimize the model hyperparameters and architecture.
- These training costs may also prevent you from retraining the model on fresh new data. However, this may be circumvented by using transfer learning which lets you train a model for a fraction of the cost of the training on a big dataset. Few-shot and zero-shot learning can also be applied, but these methods are still experimental today.
If you want to work with transfer learning on text content, the Hugging Face transformers can be a good starting point. If you deal with object detection, you may have a look at Ultralytics.
Unstructured Data, Monitoring, and Evaluation
Monitoring and evaluation can be more complex in the case of unstructured data. While classification and regression tasks have a well-established set of evaluation metrics, the evaluation of complex unstructured data tasks can be more elaborated. For example, for the object detection task, evaluation metrics may combine metrics about the object locations, the object missed detections, and also the object classes (see mean average precision, for example). Acting on the model or the data to improve the metrics that truly impact the business value in a good way can be a difficult art.
Unstructured Data: Key Takeaways
In this article, we introduced structured and unstructured data and inspected the key differences. The machine learning pipelines look quite different, but you can apply the same machine learning operations on the two categories of data by using different tools. You can work with embeddings instead of features, with a single validation dataset instead of cross-validation.
Ressources
Bibliography/webography
- Chapter 3, “Data engineering fundamentals” from Designing Machine Learning Systems by Chip Huyen, released May 2022, publisher(s): O'Reilly Media, Inc., ISBN: 9781098107963
- “Deep Learning” https://www.deeplearningbook.org/ by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
- Embeddings crash course by Google https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
