.png)


_logo%201.svg)


AI Summary
Artificial Intelligence and Computer Vision are everywhere around us today: asking Siri to schedule the next financial meeting, using facial recognition to unlock our phone, etc. Artificial intelligence, together with Computer Vision, are prominent topics of the Tech Industry. AI relies on many different tools and techniques to imitate Human Intelligence and recreate it with various algorithms applied on different devices. Computer vision is a field of IT that focuses on machines’ ability to analyze and understand images and videos, and it goes through the task of image recognition in machine learning.
What is image recognition?
Image recognition is a mechanism used to identify an object within an image and to classify it in a specific category, based on the way human people recognize objects within different sets of images.
How does image recognition work for humans?
When we see an object or an image, we, as human people, are able to know immediately and precisely what it is. People class everything they see on different sorts of categories based on attributes we identify on the set of objects. That way, even though we don’t know exactly what an object is, we are usually able to compare it to different categories of objects we have already seen in the past and classify it based on its attributes. Let’s take the example of an animal that is unknown to us. Even if we cannot clearly identify what animal it is, we are still able to identify it as an animal.
People rarely think about what they are observing and how they can identify objects, it completely happens subconsciously. People aren’t focused on everything that surrounds them all the time. Our brain has been trained to identify objects quite easily, based on our previous experiences, that is to say, objects we have already encountered in the past. We do have an extraordinary power of deduction: when we see something that resembles an object we have already seen before, we are able to deduce that it belongs to a certain category of items. We don’t necessarily need to look at every part of an image to identify the objects in it. As soon as you see a part of the item that you recognized, you know what it is. We usually use colors and contrasts to identify items.
For humans, most image recognition works subconsciously. But it is a lot more complicated when it comes to image recognition with machines.
How does image recognition work with machines?
Machines only recognize categories of objects that we have programmed into them. They are not naturally able to know and identify everything that they see. If a machine is programmed to recognize one category of images, it will not be able to recognize anything else outside of the program. The machine will only be able to specify whether the objects present in a set of images correspond to the category or not. Whether the machine will try to fit the object in the category, or it will ignore it completely.
For a machine, an image is only composed of data, an array of pixel values. Each pixel contains information about red, green, and blue color values (from 0 to 255 for each of them). For black and white images, the pixel will have information about darkness and whiteness values (from 0 to 255 for both of them).
Machines don’t have a look at the whole image; they are only interested in pixel values and patterns in these values. They simply take pixel patterns of an item and compare them with other patterns. If two patterns are close enough, the machine will associate them and recognize the second pattern as something it has already encountered in the past. In that sense, what is happening is the machine will look for groups of similar pixel values across images and will try to place them in specific image categories.
It is very rare that a program recognizes an image at 100%. Pixel patterns are very rarely 100% the same when comparing them. Solving these problems and finding improvements is the job of IT researchers, the goal being to propose the best experience possible to users.
Practicing Image recognition with machine learning
The goal of image recognition is to identify, label and classify objects which are detected into different categories.
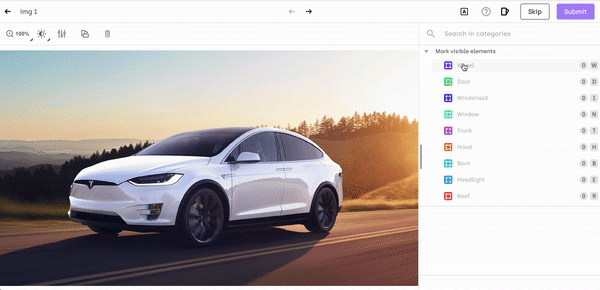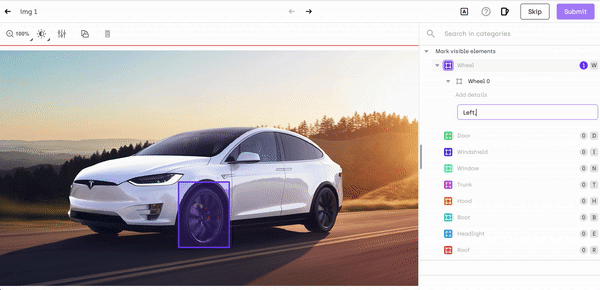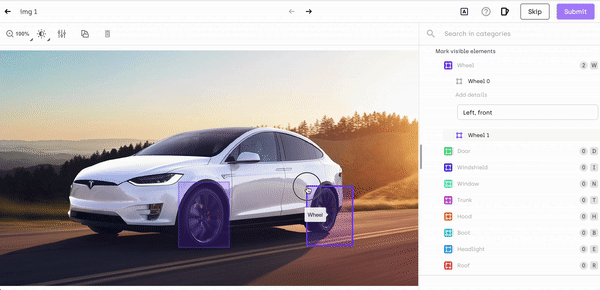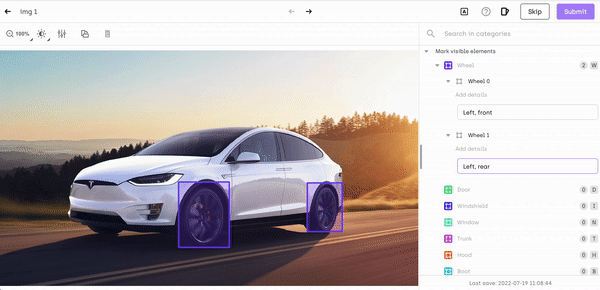
Object or image recognition is a whole process that involves various traditional computer vision tasks:
- Image classification: labeling an image and creating categories.
- Object localization: identifying the location of an object in an image, by surrounding it with a bounding box.
- Object Detection: determining the presence of objects with the help of bounding boxes and categorizing it within the class it belongs to.
- Object Segmentation: distinguishing the various elements. Identify and locate each and every item of the picture. Segmentation doesn’t use bounding boxes but highlights the contour of the object in the image.
For the past few years, this computer vision task has achieved big successes, mainly thanks to machine learning applications.
Training Process of Image Recognition Models
In order to go through these 4 tasks and to complete them, machine learning and image recognition systems do require going through a few important steps.
Set up, Training and Testing
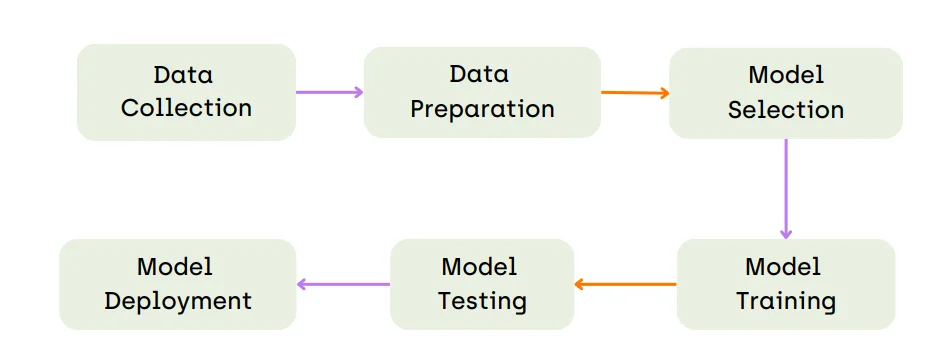
- Data Collection
- At the heart of any potent image recognition system lies a well-constructed dataset. The data collection step involves sourcing a diverse range of images representing the objects, scenes, or patterns the system will learn to recognize. A comprehensive dataset contributes to the system's ability to generalize its understanding across various scenarios and variations
- Data Preparation
- Raw data seldom fits seamlessly into machine learning models. Data preparation is the process of transforming and refining the collected data to make it suitable for training. This may involve tasks such as removing inconsistencies, resizing images to a consistent format, and normalizing pixel values. Effective data preparation contributes to the model's ability to learn meaningful patterns from the data.
- Model Selection
- Choosing the right model architecture is a pivotal decision. The model architecture determines how the system will process and interpret the input data. Depending on the complexity of the recognition task, different architectures such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), or transformer models might be suitable. The choice of architecture should align with the task's requirements and computational resources.
- Model Training
- Model training is the process of teaching the selected architecture to recognize patterns and features in the training data. This is achieved through iterative optimization, where the model's parameters are adjusted to minimize the difference between predicted and actual outputs. Training continues until the model achieves a level of accuracy and generalization that makes it proficient in recognizing objects in images.
- Model Testing
- Testing the trained model is essential to evaluate its performance on new, unseen data. The model is presented with images it hasn't encountered during training, allowing assessment of its ability to generalize. Metrics such as accuracy, precision, recall, and F1-score provide insights into the model's strengths and weaknesses. Rigorous testing aids in fine-tuning the model for better performance.
- Model Deployment
- Once the model demonstrates satisfactory performance in testing, it can be deployed for practical use. Deployment involves integrating the trained model into real-world applications, enabling it to perform image recognition tasks in real time. Continuous monitoring is essential post-deployment to ensure the model maintains accuracy and adapts to evolving data patterns.
Hereafter are some of the most popular Image Recognition with Machine Learning Models and how they work.
Fine-tune your Image Recognition model with the best data
Complete any image labeling task up to 10x faster and with 10x fewer errors. Try out our platform today!
Traditional and Deep Learning Image Recognition Machine Learning Models
Support Vector Machines (SVM)
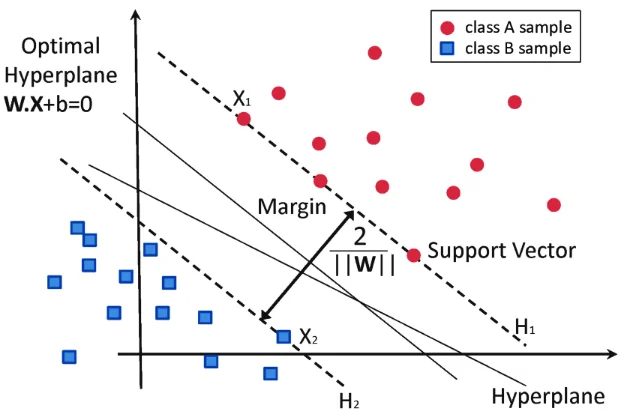
Support Vector Machines (SVM) are a class of supervised machine learning algorithms used primarily for classification and regression tasks. The fundamental concept behind SVM is to find the optimal hyperplane that effectively separates data points belonging to different classes while maximizing the margin between them. SVMs work well in scenarios where the data is linearly separable, and they can also be extended to handle non-linear data by using techniques like the kernel trick. By mapping data points into higher-dimensional feature spaces, SVMs are capable of capturing complex relationships between features and labels, making them effective in various image recognition tasks.
Bag of Features Models
This method represents an image as a collection of local features, ignoring their spatial arrangement. It's commonly used in computer vision for tasks like image classification and object recognition. The bag of features approach captures important visual information while discarding spatial relationships.
Histogram of Oriented Gradients
The Histogram of Oriented Gradients (HOG) is a feature extraction technique used for object detection and recognition. HOG focuses on capturing the local distribution of gradient orientations within an image. By calculating histograms of gradient directions in predefined cells, HOG captures edge and texture information, which are vital for recognizing objects. This method is particularly well-suited for scenarios where object appearance and shape are critical for identification, such as pedestrian detection in surveillance systems.
Local Binary Patterns
Local Binary Patterns (LBP) is a texture analysis method that characterizes the local patterns of pixel intensities in an image. It works by comparing the central pixel value with its neighboring pixels and encoding the result as a binary pattern. These patterns are then used to construct histograms that represent the distribution of different textures in an image. LBP is robust to illumination changes and is commonly used in texture classification, facial recognition, and image segmentation tasks.
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are a class of deep learning models designed to automatically learn and extract hierarchical features from images. CNNs consist of layers that perform convolution, pooling, and fully connected operations. Convolutional layers apply filters to input data, capturing local patterns and edges. Pooling layers downsample feature maps, retaining important information while reducing computation. Fully connected layers make decisions based on the learned features. CNNs excel in image classification, object detection, and segmentation tasks due to their ability to capture spatial hierarchies of features.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are a type of neural network designed for sequential data analysis. They possess internal memory, allowing them to process sequences and capture temporal dependencies. In computer vision, RNNs find applications in tasks like image captioning, where context from previous words is crucial for generating meaningful descriptions. However, traditional RNNs suffer from vanishing gradient problems. Variants like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) were developed to mitigate these issues.
Faster Region-based CNN (Faster RCNN)
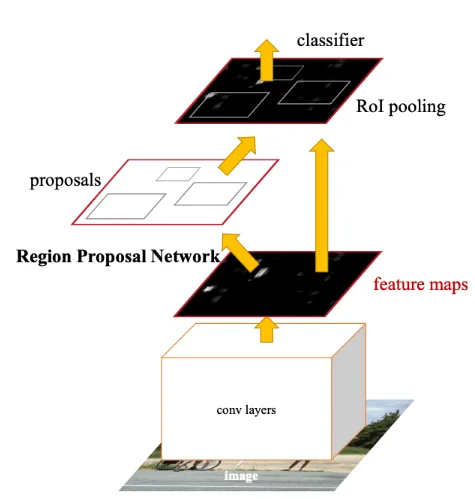
Faster Region-based CNN (Faster RCNN) is an advancement in object detection. It combines a region proposal network (RPN) with a CNN to efficiently locate and classify objects within an image. The RPN proposes potential regions of interest, and the CNN then classifies and refines these regions. Faster RCNN's two-stage approach improves both speed and accuracy in object detection, making it a popular choice for tasks requiring precise object localization.
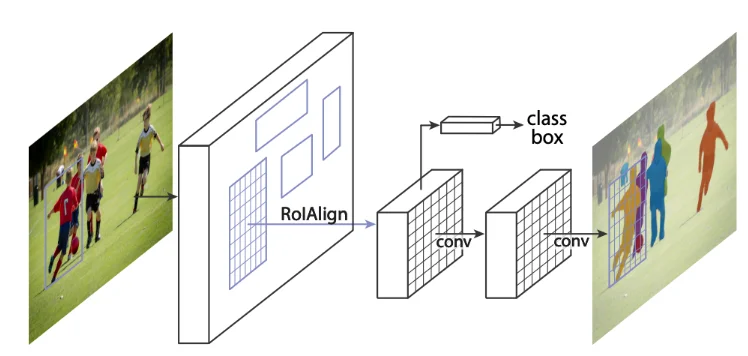
Mask R-CNN
Mask R-CNN builds upon Faster RCNN by adding a segmentation branch. In addition to detecting objects, Mask R-CNN generates pixel-level masks for each identified object, enabling detailed instance segmentation. This method is essential for tasks demanding accurate delineation of object boundaries and segmentations, such as medical image analysis and autonomous driving.
Single Shot Detector (SSD)
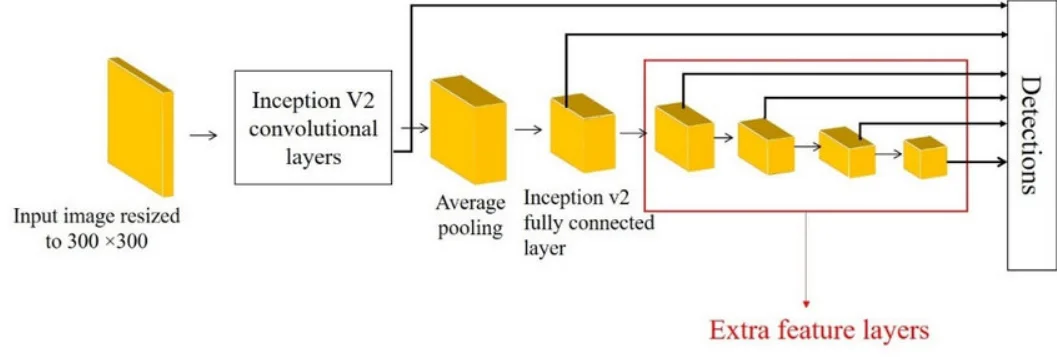
SSD is a real-time object detection method that streamlines the detection process. Unlike two-stage methods, SSD predicts object classes and bounding box coordinates directly from a single pass through a CNN. It employs a set of default bounding boxes of varying scales and aspect ratios to capture objects of different sizes, ensuring effective detection even for small objects.
You Only Look Once (YOLO)
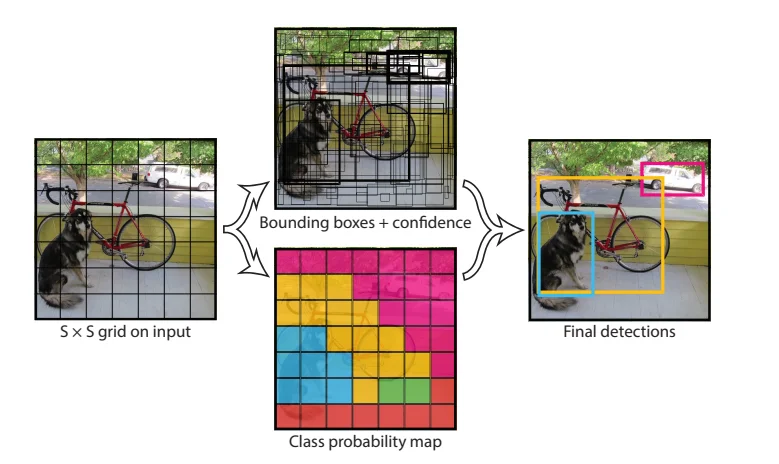
YOLO is a groundbreaking object detection algorithm that emphasizes speed and efficiency. YOLO divides an image into a grid and predicts bounding boxes and class probabilities within each grid cell. This approach enables real-time object detection with just one forward pass through the network. YOLO's speed makes it a suitable choice for applications like video analysis and real-time surveillance.
ViT (Vision Transformer)
ViT is a novel approach that applies transformers, originally designed for natural language processing, to image classification. It divides an image into patches and processes them through transformer layers to capture global context for classification tasks.
DeiT (Decoupled Image Transformer)
DeiT is an evolution of the Vision Transformer that improves training efficiency. It decouples the training of the token classification head from the transformer backbone, enabling better scalability and performance.
Swin Transformer
Swin Transformer is a recent advancement that introduces a hierarchical shifting mechanism to process image patches in a non-overlapping manner. This innovation improves the efficiency and performance of transformer-based models for computer vision tasks.
Segment Anything Model (SAM)
The Segment Anything Model (SAM) is a foundation model developed by Meta AI Research. It is a promptable segmentation system that can segment any object in an image, even if it has never seen that object before. SAM is trained on a massive dataset of 11 million images and 1.1 billion masks, and it can generalize to new objects and images without any additional training. SAM is also effective on image recognition. It has been shown to be able to identify objects in images, even if they are partially occluded or have been distorted.
Programming Image Recognition
Some accessible solutions exist for anybody who would like to get familiar with these techniques. An introduction tutorial is even available on Google on that specific topic.
Various methods are used to detect items in a picture and classify them. But how do we apply them to our devices?
Programming with Python language
Python is an IT coding language, meant to program your computer devices in order to make them work the way you want them to work. One of the best things about Python is that it supports many different types of libraries, especially the ones working with Artificial Intelligence. Image detection and recognition are available with Python.
To start working on this topic, Python and the necessary extension packages should be downloaded and installed on your system. Some of the packages include applications with easy-to-understand coding and make AI an approachable method to work on. It is recommended to own a device that handles images quite effectively. We are talking about good quality graphics cards for instance. The next step will be to provide Python and the image recognition application with a free downloadable and already labeled dataset, in order to start classifying the various elements. Finally, a little bit of coding will be needed, including drawing the bounding boxes and labeling them.
Pro tip 💡
Discover how to automate your data labeling to increase the productivity of your labeling teams! Dive into model-in-the-loop, active learning, and implement automation strategies in your own projects.

Application Programming Interface (API)
An API is an application meant to create a link between two different software, in order to exchange data and/or functionalities. Regarding image recognition, this solution is mainly used to get picture data from a Cloud API such as AWS Cloud from Amazon. That way, you can get a wide library of image references.
Programming item recognition using this method can be done fairly easily and rapidly. That way, you can deploy the program within a short period of time. But, it should be taken into consideration that choosing this solution, taking images from an online cloud, might lead to privacy and security issues. This process should be used for testing or at least an action that is not meant to be permanent.
Edge AI
Contrarily to APIs, Edge AI is a solution that involves confidentiality regarding the images. The images are uploaded and offloaded on the source peripheral where they come from, so no need to worry about putting them on the cloud.
Edge AI is very often used with real-time videos. In most cases, it will be used with connected objects or any item equipped with motion sensors.
AI Platform
Some online platforms are available to use in order to create an image recognition system, without starting from zero. If you don’t know how to code, or if you are not so sure about the procedure to launch such an operation, you might consider using this type of pre-configured platform.
The different fields of application for image recognition with ML
Nowadays, Computer Vision and recognition are always around us. From unlocking your phone with your face in the morning to coming into a mall to do some shopping. Many different industries have decided to implement Artificial Intelligence in their processes.
Facial recognition
Face analysis is a major recognition application. It is used by many companies to detect different faces at the same time, in order to know how many people there are in an image for example. Face recognition can be used by police and security forces to identify criminals or victims. Face analysis involves gender detection, emotion estimation, age estimation, etc.
The need for businesses to identify these characteristics is quite simple to understand. It allows them to analyze precisely who their customers are. That way, a fashion store can be aware that its clientele is composed of 80% of women, the average age surrounds 30 to 45 years old, and the clients don’t seem to appreciate an article in the store. Their facial emotion tends to be disappointed when looking at this green skirt. Acknowledging all of these details is necessary for them to know their targets and adjust their communication in the future.
Face analysis is also very much used for identification. Apple recently developed a way to unlock your phone with your face. They even developed a method to do it without taking off your surgical mask.
Health and Medicine
Treating patients can be challenging, sometimes a tiny element might be missed during an exam, leading medical staff to deliver the wrong treatment. To prevent this from happening, the Healthcare system started to analyze imagery that is acquired during treatment. X-ray pictures, radios, scans, all of these image materials can use image recognition to detect a single change from one point to another point. Detecting the progression of a tumor, of a virus, the appearance of abnormalities in veins or arteries, etc.
Smart Farming
Farmers’ daily lives are far from being easy. To keep taking good care of both their animals and their plantations, they need to monitor them both.
Monitoring their animals has become a comfortable way for farmers to watch their cattle. With cameras equipped with motion sensors and image detection programs, they are able to make sure that all their animals are in good health. They can also monitor animal births. Farmers can easily detect if a cow is having difficulties giving birth to its calf. They can intervene rapidly to help the animal deliver the baby, thus preventing the potential death of two animals.
Farmers also grow their own plants, mainly to feed their cattle. To see if the fields are in good health, image recognition can be programmed to detect the presence of a disease on a plant for example. The farmer can treat the plantation rapidly and be able to harvest peacefully.
Security and Safety
Security and safety are two major concerns in today’s society. Thanks to image recognition and detection, it gets easier to identify criminals or victims, and even weapons. In an airport for example, where safety is crucial. All-day long, security agents are scrutinizing screens. Helped by Artificial Intelligence, they are able to detect dangers extremely rapidly. When a piece of luggage is unattended, the watching agents can immediately get in touch with the field officers, in order to get the situation under control and to protect the population as soon as possible. When a passport is presented, the individual's fingerprints and face are analyzed to make sure they match with the original document.
Insurance companies are also using recognition technologies. When somebody is filing a complaint about the robbery and is asking for compensation from the insurance company. The latter regularly asks the victims to provide video footage or surveillance images to prove the felony did happen. And very often, the thief is caught on camera and can be identified. Sometimes, the guilty individual gets sued and can face charges thanks to facial recognition.
Ecommerce
Online stores are experiencing a boom since the beginning of the COVID-19 pandemic. They managed to develop their activities exponentially thanks to various elements.
One of the recent advances they have come up with is image recognition to better serve their customer. Many platforms are now able to identify the favorite products of their online shoppers and to suggest them new items to buy, based on what they have watched previously.
On another note, some new applications propose their users simply snap a picture of an item found on somebody they have met in the street, in order to find a store that has a similar or the same item available for purchase. The algorithm is then able to give a list of places where you can buy the shoes your friend was wearing today.
Improvements made in the field of AI and picture recognition for the past decades have been tremendous. There is absolutely no doubt that researchers are already looking for new techniques based on all the possibilities provided by these exceptional technologies.
ViT (Vision Transformer)
ViT is a novel approach that applies transformers, originally designed for natural language processing, to image classification. It divides an image into patches and processes them through transformer layers to capture global context for classification tasks.
DeiT (Decoupled Image Transformer)
DeiT is an evolution of the Vision Transformer that improves training efficiency. It decouples the training of the token classification head from the transformer backbone, enabling better scalability and performance.
Swin Transformer
Swin Transformer is a recent advancement that introduces a hierarchical shifting mechanism to process image patches in a non-overlapping manner. This innovation improves the efficiency and performance of transformer-based models for computer vision tasks.
Segment Anything Model (SAM)
The Segment Anything Model (SAM) is a foundation model developed by Meta AI Research. It is a promptable segmentation system that can segment any object in an image, even if it has never seen that object before. SAM is trained on a massive dataset of 11 million images and 1.1 billion masks, and it can generalize to new objects and images without any additional training. SAM is also effective on image recognition. It has been shown to be able to identify objects in images, even if they are partially occluded or have been distorted.
The simplest way to build high-quality datasets
Our professional workforce is ready to start your data labeling project in 48 hours. We guarantee high-quality datasets delivered fast.
Programming Image Recognition Software
Some accessible solutions exist for anybody who would like to get familiar with these techniques. An introduction tutorial is even available on Google on that specific topic.
Various methods are used to detect items in a picture and classify them. But how do we apply them to our devices?
Programming with Python language
Python is an IT coding language, meant to program your computer devices in order to make them work the way you want them to work. One of the best things about Python is that it supports many different types of libraries, especially the ones working with Artificial Intelligence. Image detection and recognition are available with Python.
To start working on this topic, Python and the necessary extension packages should be downloaded and installed on your system. Some of the packages include applications with easy-to-understand coding and make AI an approachable method to work on. It is recommended to own a device that handles images quite effectively. We are talking about good quality graphics cards for instance. The next step will be to provide Python and the image recognition application with a free downloadable and already labeled dataset, in order to start classifying the various elements. Finally, a little bit of coding will be needed, including drawing the bounding boxes and labeling them.
Application Programming Interface (API)
An API is an application meant to create a link between two different software, in order to exchange data and/or functionalities. Regarding image recognition, this solution is mainly used to get picture data from a Cloud API such as AWS Cloud from Amazon. That way, you can get a wide library of image references.
Programming item recognition using this method can be done fairly easily and rapidly. That way, you can deploy the program within a short period of time. But, it should be taken into consideration that choosing this solution, taking images from an online cloud, might lead to privacy and security issues. This process should be used for testing or at least an action that is not meant to be permanent.
Edge AI
Contrarily to APIs, Edge AI is a solution that involves confidentiality regarding the images. The images are uploaded and offloaded on the source peripheral where they come from, so no need to worry about putting them on the cloud.
Edge AI is very often used with real-time videos. In most cases, it will be used with connected objects or any item equipped with motion sensors.
AI Platform
Some online platforms are available to use in order to create an image recognition system, without starting from zero. If you don't know how to code, or if you are not so sure about the procedure to launch such an operation, you might consider using this type of pre-configured platform.
The different fields of computer vision application for image recognition
Nowadays, Computer Vision and recognition are always around us. From unlocking your phone with your face in the morning to coming into a mall to do some shopping. Many different industries have decided to implement Artificial Intelligence in their processes.
Facial recognition
Face analysis is a major recognition application. It is used by many companies to detect different faces at the same time, in order to know how many people there are in an image for example. Face recognition can be used by police and security forces to identify criminals or victims. Face analysis involves gender detection, emotion estimation, age estimation, etc.
The need for businesses to identify these characteristics is quite simple to understand. It allows them to analyze precisely who their customers are. That way, a fashion store can be aware that its clientele is composed of 80% of women, the average age surrounds 30 to 45 years old, and the clients don't seem to appreciate an article in the store. Their facial emotion tends to be disappointed when looking at this green skirt. Acknowledging all of these details is necessary for them to know their targets and adjust their communication in the future.
Face analysis is also very much used for identification. Apple recently developed a way to unlock your phone with your face. They even developed a method to do it without taking off your surgical mask.
Health and Medicine
Treating patients can be challenging, sometimes a tiny element might be missed during an exam, leading medical staff to deliver the wrong treatment. To prevent this from happening, the Healthcare system started to analyze imagery that is acquired during treatment. X-ray pictures, radios, scans, all of these image materials can use image recognition to detect a single change from one point to another point. Detecting the progression of a tumor, of a virus, the appearance of abnormalities in veins or arteries, etc.
Smart Farming
Farmers' daily lives are far from being easy. To keep taking good care of both their animals and their plantations, they need to monitor them both.
Monitoring their animals has become a comfortable way for farmers to watch their cattle. With cameras equipped with motion sensors and image detection programs, they are able to make sure that all their animals are in good health. They can also monitor animal births. Farmers can easily detect if a cow is having difficulties giving birth to its calf. They can intervene rapidly to help the animal deliver the baby, thus preventing the potential death of two animals.
Farmers also grow their own plants, mainly to feed their cattle. To see if the fields are in good health, image recognition can be programmed to detect the presence of a disease on a plant for example. The farmer can treat the plantation rapidly and be able to harvest peacefully.
Security and Safety
Security and safety are two major concerns in today's society. Thanks to image recognition and detection, it gets easier to identify criminals or victims, and even weapons. In an airport for example, where safety is crucial. All-day long, security agents are scrutinizing screens. Helped by Artificial Intelligence, they are able to detect dangers extremely rapidly. When a piece of luggage is unattended, the watching agents can immediately get in touch with the field officers, in order to get the situation under control and to protect the population as soon as possible. When a passport is presented, the individual's fingerprints and face are analyzed to make sure they match with the original document.
Insurance companies are also using recognition technologies. When somebody is filing a complaint about the robbery and is asking for compensation from the insurance company. The latter regularly asks the victims to provide video footage or surveillance images to prove the felony did happen. And very often, the thief is caught on camera and can be identified. Sometimes, the guilty individual gets sued and can face charges thanks to facial recognition.
Ecommerce
Online stores are experiencing a boom since the beginning of the COVID-19 pandemic. They managed to develop their activities exponentially thanks to various elements.
One of the recent advances they have come up with is image recognition to better serve their customer. Many platforms are now able to identify the favorite products of their online shoppers and to suggest them new items to buy, based on what they have watched previously.
On another note, some new applications propose their users simply snap a picture of an item found on somebody they have met in the street, in order to find a store that has a similar or the same item available for purchase. The algorithm is then able to give a list of places where you can buy the shoes your friend was wearing today.
Improvements made in the field of AI and picture recognition for the past decades have been tremendous. There is absolutely no doubt that researchers are already looking for new techniques based on all the possibilities provided by these exceptional technologies.
Wrap-up
This journey through image recognition and its synergy with machine learning has illuminated a world of understanding and innovation. From the intricacies of human and machine image interpretation to the foundational processes like training, to the various powerful algorithms, we've explored the heart of recognition technology.
We've Delved into the practical realm of programming with Python, harnessing APIs, venturing into Edge AI, and embracing AI platforms. The applications are boundless: from bolstering security through facial recognition to revolutionizing sectors like healthcare, agriculture, security, and e-commerce.
As we finish this article, we're seeing image recognition change from an idea to something real that's shaping our digital world. This blend of machine learning and vision has the power to reshape what's possible and help us see the world in new, surprising ways.