

Any provider can claim domain experts. Kili delivers production-ready, high-quality datasets through a fully managed, data science-led service where every labeling decision — from annotator consensus scores to quality metrics — is visible in real time through one auditable platform.
.svg)
.svg)
.svg)







Our team of data scientists and domain experts delivers high-quality datasets and evaluation frameworks across finance, defense, law, life sciences, mathematics, and voice AI — with full traceability at every stage.
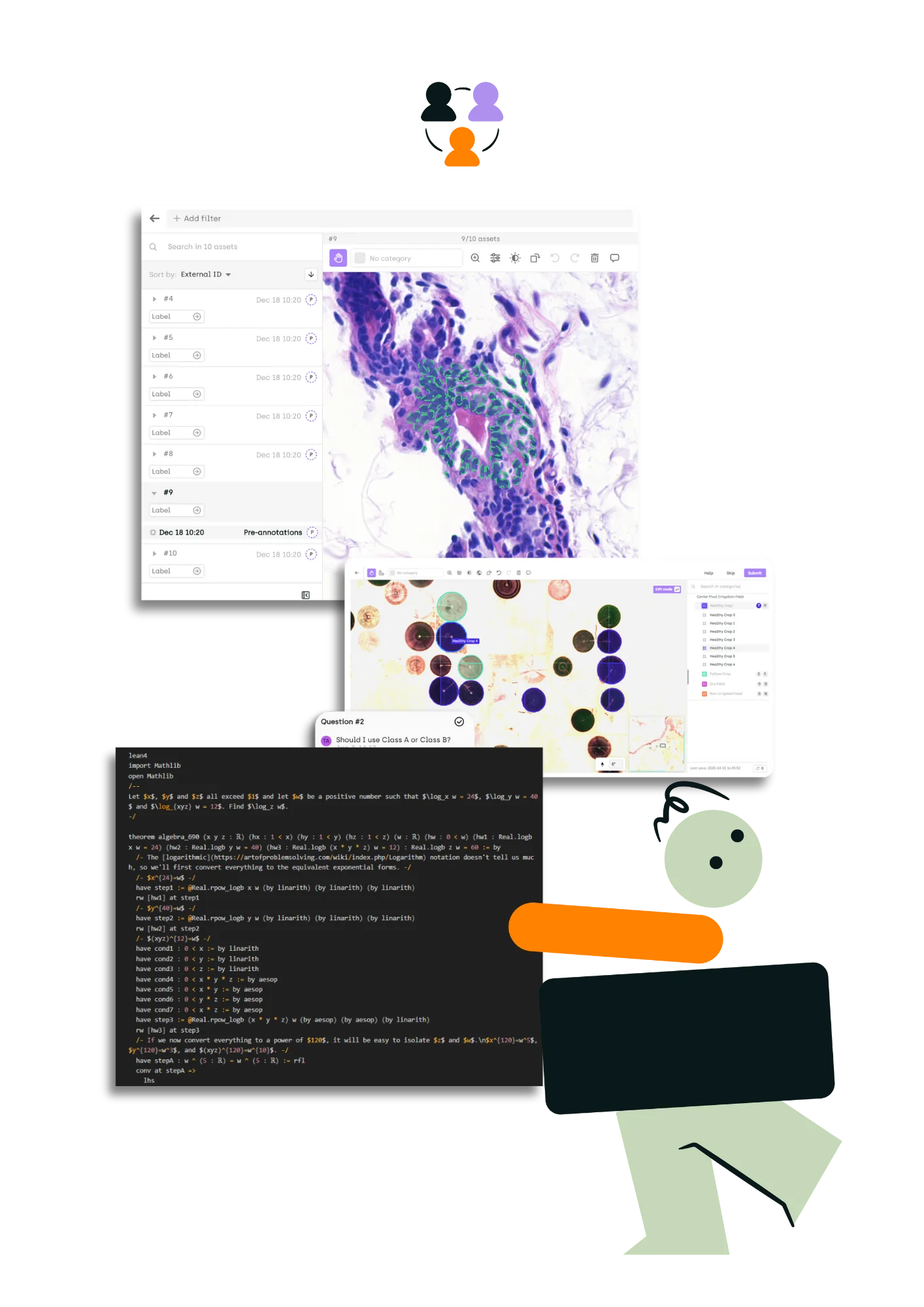
Access experts traditional providers can't source — from Lean 4 programmers and senior finance professionals to patent attorneys and biosciences researchers — across 40+ languages. Every expert's performance is tracked and visible to you through the platform.
Many teams aren't blocked on training data volume — they're blocked on evaluation confidence. Kili designs custom evaluation rubrics, sources the domain specialists qualified to judge model outputs, and delivers benchmark datasets with full annotator-level provenance.
Your project lead advises on annotation ontology, selects quality metrics, and debugs labeling inconsistencies at the data level. The work runs through Kili's platform with real-time dashboards — so you never have to wonder what's happening inside your data pipeline.
Datasets delivered in your preferred format, ready for immediate pipeline integration. Full documentation and audit trails included for compliance and reproducibility.
From frontier model training to enterprise fine-tuning, Kili delivers the data that makes AI work — with the transparency to prove it.

An AI lab needed large-scale multilingual conversational training data across diverse NLP task types but couldn't maintain labeling consistency beyond a few hundred annotators. Kili recruited, onboarded, and managed an optimized workforce, implementing multi-round quality workflows with real-time consensus scoring and annotator-level performance tracking through the platform. The lab shipped its multilingual model with full visibility into every labeling decision at scale.

A European defense contractor needed AI training data for image recognition — but the project required dedicated on-site hardware, and full controlled-environment compliance. Kili deployed local machines, sourced and cleared the annotation team, and ran the project through its platform under strict security constraints. The contractor received a production-ready dataset with complete audit trails, built entirely within a sovereign, controlled environment.

An AI research company needed training data for formal mathematical reasoning — but the task required Lean 4 theorem provers, an expertise so niche that the global pool of qualified contributors numbers in the hundreds. Kili identified, recruited, and vetted Lean 4 specialists through targeted outreach and academic networks, onboarded them with project-specific proof validation rubrics, and managed the workflow through the platform with full quality tracking. The company delivered a formal proof dataset built by the only people qualified to write it — with every proof validated and every contributor's performance auditable.

An IP technology company needed to benchmark its patent-drafting AI agents — but couldn't find a provider capable of sourcing practicing patent lawyers and designing a rigorous evaluation framework. Kili recruited IP attorneys, co-designed the evaluation rubric with the client's team, and managed the expert review process with full annotator-level provenance. The company used the resulting benchmark dataset for both model improvement and product positioning, with every reviewer decision auditable.
Everything you need to know about how we source experts, manage quality, and deliver datasets for regulated industries.
Trusted by data scientists, subject matter experts, and annotation teams to build high-quality, expert-level datasets securely.

