
.png)


_logo%201.svg)


AI Summary
- The YOLO algorithm processes entire images in a single forward pass, making it faster than region-based object detection methods like R-CNN.
- YOLO's evolution from v1 to v7 added anchor boxes, feature pyramids, and focal loss — each version trading accuracy-speed balance differently.
- Single-shot object detection sacrifices some precision for real-time capability, while two-stage detectors like Mask R-CNN prioritize accuracy.
- Standard evaluation metrics for YOLO object detection include Mean Average Precision (mAP), Average Precision (AP), and Intersection over Union (IoU).
- Kili Technology offers video annotation and professional data labeling services for fast, high-quality dataset creation.
Introduction
Computer vision is a rapidly advancing field that aims to enable computers to interpret and understand visual information in the same way that humans do. It involves the development of algorithms, models, and systems that can analyze and understand images and videos, as well as extract useful information from them.
One of the most important subfields of computer vision is object detection, which involves detecting instances of semantic objects of a certain pre-defined class(es), such as humans, cars, and animals, in images or frames of videos. In this article, we will delve into the technical details of object detection, including one of the most famous object detection models with their respective strengths and weaknesses.
What is Object Classification?
First of all, let’s start by understanding the concept of object classification, which is a task that aims to identify and categorize objects within an image into pre-defined classes. Object classification is typically performed using machine learning techniques, where a model is trained on a labeled dataset of images and their associated class labels. The trained model can then be used to classify new images by assigning them a class label based on their learned features. Some examples of object classification include recognizing a traffic sign or identifying the type of plant in an image.

Object Classification Pipeline
What is Object Detection?
As we understand the task of object classification, let’s dive into our main focus, which is object detection; Object detection is a computer vision task that deals with identifying and locating objects of certain pre-defined classes within input images.
With the development of deep learning, object detection has achieved very promising results. There are several algorithms and models, such as R-CNN, Faster R-CNN, YOLO, and SSD, that have been developed for object detection. These algorithms and models are being used in various applications, such as self-driving cars, surveillance systems, and object tracking.
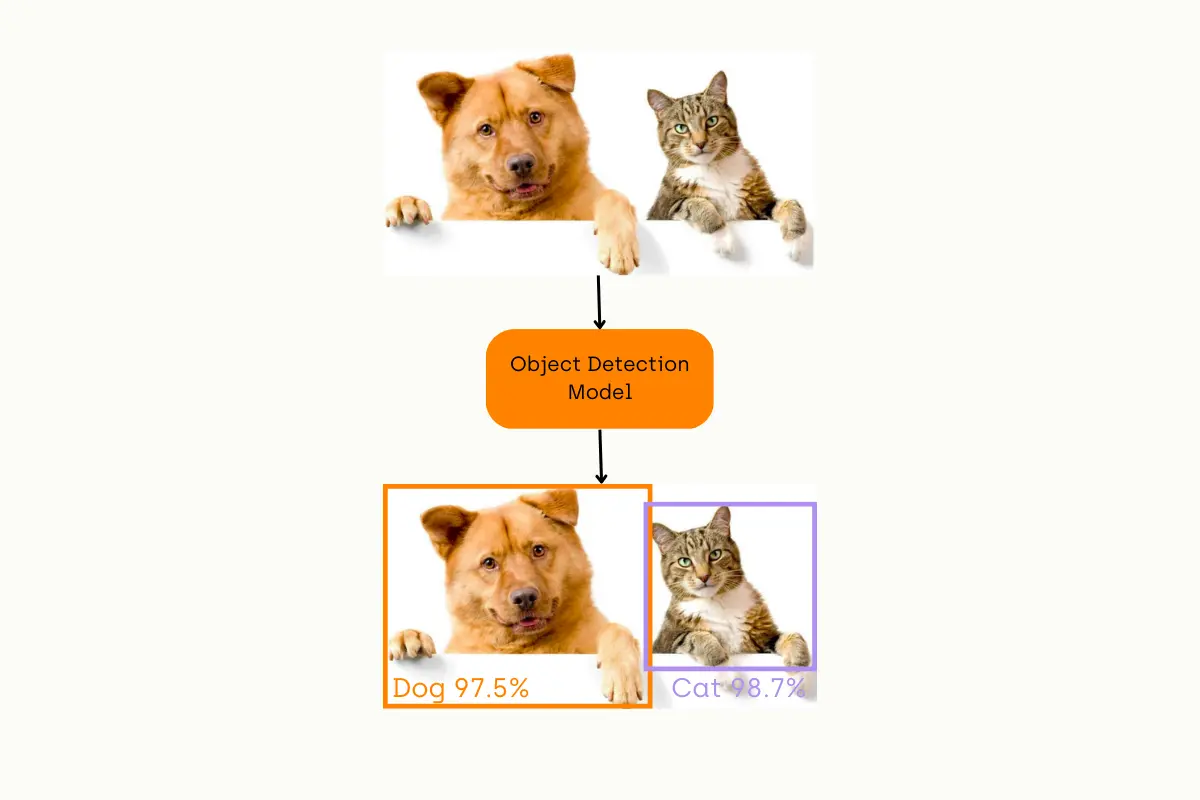
Object Detection Pipeline
Build high-quality video datasets fast
Ready to revolutionize your video annotation process? Try our top-tier video data labeling product now!
What Is Region-Based CNN?
Region-Based CNN (Convolutional Neural Network) is an object detection algorithm that uses CNNs to detect objects in images. The basic idea behind region-based CNNs is to first generate a set of candidate regions or "region proposals" within the image or video and then use a CNN to classify each region as containing an object or not. The regions that are classified as containing an object are then further processed to refine the object's location and classify it into a specific class. This concept is also known as Two-shot Object Detection.
One of the most famous examples of region-based CNN is R-CNN (Regional CNN) and its variants, such as Fast R-CNN, Faster R-CNN, and Mask R-CNN, which all have been proposed to improve the speed and accuracy of the object detection process. These methods use a combination of selective search or other region proposal methods to generate candidate regions and CNNs to classify and refine regions that contain objects.
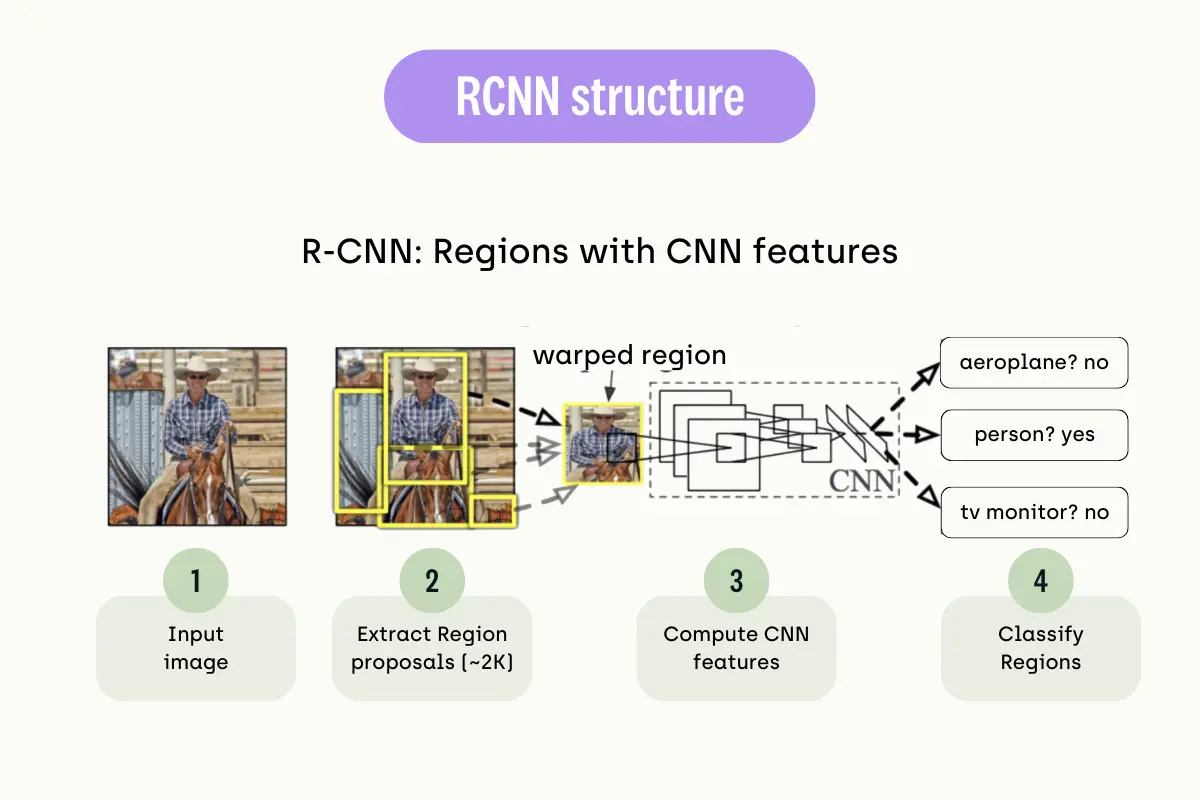
Weaknesses of Region-based CNNs
Even though region-based CNNs can solve the task of object detection with relatively satisfactory accuracy, they have several weaknesses. Some of these weaknesses are; high computational cost, inefficiency, limited generalization, and lack of context. They are computationally expensive and inefficient, making them impractical for real-time object detection on low-powered devices. Additionally, they require large labeled datasets, which can be costly and time-consuming to obtain. These factors make them less suitable for certain applications.
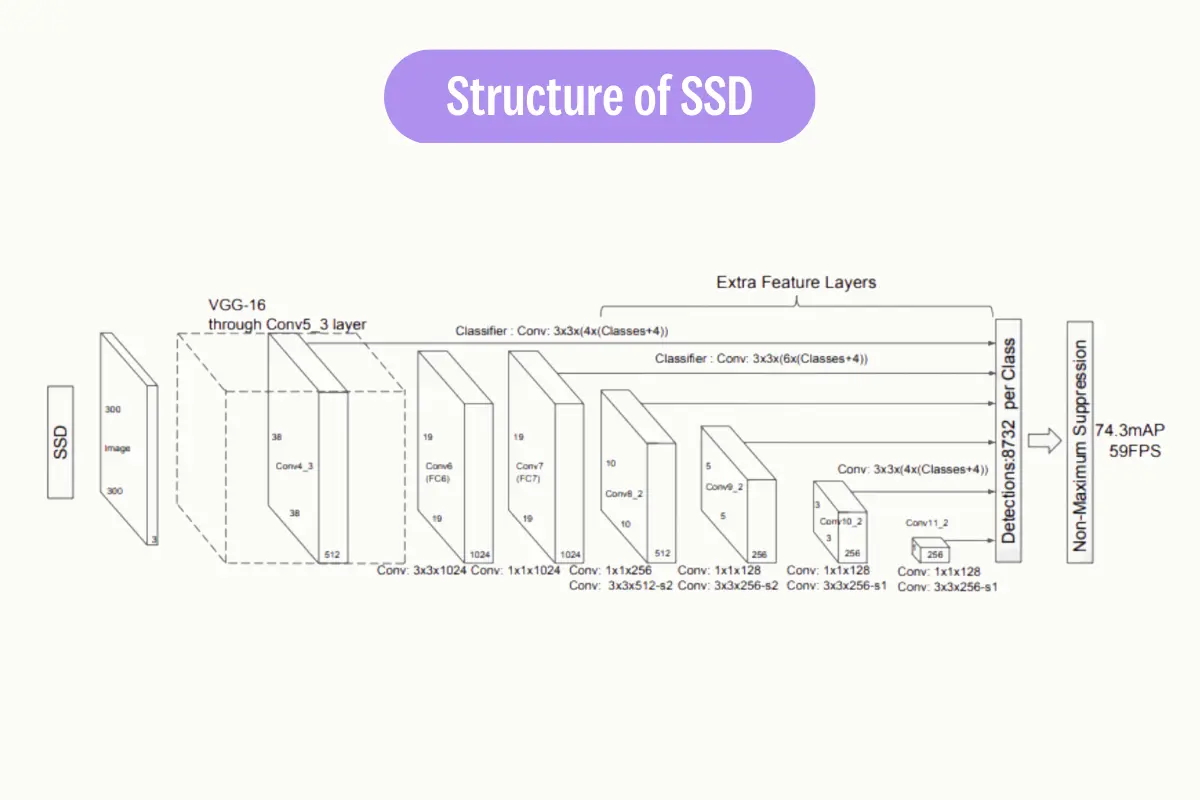
Single Shot Object Detection
Single-shot object detection is a type of object detection algorithm that is able to detect objects within an image or video in a single pass without the need for multiple stages or region proposals.
Single-shot object detectors, such as YOLO (You Only Look Once) and SSD (Single Shot MultiBox Detector), use a single convolutional neural network (CNN) to directly predict the class labels and bounding boxes of objects within an image or video. These models are trained end-to-end using a large dataset of labeled images and their associated object-bounding boxes.
Single-shot object detection is considered faster and more efficient than two-shot object detection methods, as it eliminates the need for multiple stages and can be run in real time on even low-powered devices. However, it may not have the same level of accuracy as the multi-stage methods.
Object Detection Evaluation Metrics
There are several metrics commonly used to evaluate the performance of object detection models:
- 1. Mean Average Precision (mAP): The precision of a model is defined as the number of true positives divided by the number of true positives plus false positives. The mAP metric takes into account both the precision and recall of the model and is calculated as the mean of the average precision for each class. A higher mAP value indicates a better performance of the model.
- 2. Average Precision (AP): It is a measure of the precision of the model at different recall levels. The precision is defined as the number of true positives divided by the number of true positives plus false positives. The recall is defined as the number of true positives divided by the number of true positives plus false negatives. AP is calculated as the area under the precision-recall curve. A higher AP value indicates a better performance of the model.
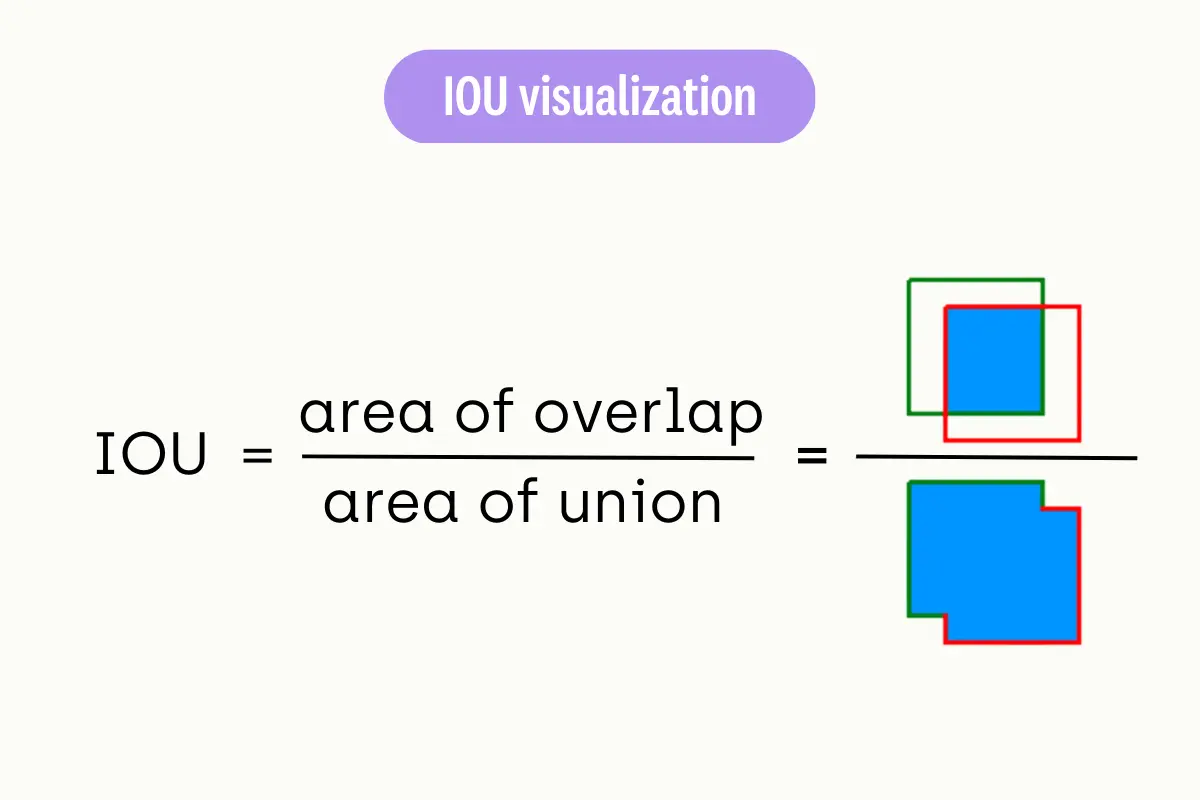
- 3. Intersection over Union (IoU): IoU is a measure of the overlap between the predicted bounding box and the ground-truth bounding box. It is calculated by taking the intersection areas of the two boxes and dividing it by the area of their union. A higher IoU value indicates a better match between the predicted and ground-truth bounding boxes.
There are also several metrics that evaluate the accuracy too. For example, True Positive Rate (TPR), False Positive Rate (FPR), F1-score, and Log Average Miss Rate (MR). In addition to these metrics, object detection models can also be evaluated based on their computational efficiency.
What is YOLO?
YOLO (You Only Look Once) is a real-time object detection algorithm developed by Joseph Redmon and Ali Farhadi in 2015. It is a single-stage object detector that uses a convolutional neural network (CNN) to predict the bounding boxes and class probabilities of objects in input images. YOLO was first implemented using the Darkent framework.
The YOLO algorithm divides the input image into a grid of cells, and for each cell, it predicts the probability of the presence of an object and the bounding box coordinates of the object. It also predicts the class of the object. Unlike two-stage object detectors such as R-CNN and its variants, YOLO processes the entire image in one pass, making it faster and more efficient.
YOLO has been developed in several versions, such as YOLOv1, YOLOv2, YOLOv3, YOLOv4, YOLOv5, YOLOv6, and YOLOv7. Each version has been built on top of the previous version with enhanced features such as improved accuracy, faster processing, and better handling of small objects.
YOLO is widely used in various applications such as self-driving cars and surveillance systems. It is also widely used for real-time object detection tasks like in real-time video analytics and real-time video surveillance.`
YOLO Algorithm: How Does it Works?
The basic idea behind YOLO is to divide the input image into a grid of cells and, for each cell, predict the probability of the presence of an object and the bounding box coordinates of the object. The process of YOLO can be broken down into several steps:
- 1. Input image is passed through a CNN to extract features from the image.
- 2. The features are then passed through a series of fully connected layers, which predict class probabilities and bounding box coordinates.
- 3. The image is divided into a grid of cells, and each cell is responsible for predicting a set of bounding boxes and class probabilities.
- 4. The output of the network is a set of bounding boxes and class probabilities for each cell.
- 5. The bounding boxes are then filtered using a post-processing algorithm called non-max suppression to remove overlapping boxes and choose the box with the highest probability.
- 6. The final output is a set of predicted bounding boxes and class labels for each object in the image.
One of the key advantages of YOLO is that it processes the entire image in one pass, making it faster and more efficient than two-stage object detectors such as R-CNN and its variants.

YOLOV2
YOLO v2, also known as YOLO 9000, is an improved version of the original YOLO object detection algorithm. It builds upon the concepts and architecture of YOLO, but addresses some of the limitations of the original version.
One of the main differences between YOLO v2 and the original YOLO is the use of anchor boxes. In YOLO v2, CNN predicts not only the bounding box coordinates but also the anchor boxes. Anchor boxes are pre-defined boxes of different aspect ratios and scales, which are used to match the predicted bounding boxes with the actual objects in the image. This allows YOLO v2 to handle objects of different shapes and sizes better.
Another key difference is the use of a multi-scale approach. In YOLO v2, the input image is fed through CNN at multiple scales, which allows the model to detect objects at different sizes. This is achieved by using a feature pyramid network (FPN), which allows the model to extract features at different scales from the same image.
Additionally, YOLO v2 uses a different loss function than the original YOLO, called the sum-squared error (SSE) loss function. The SSE loss function is more robust and helps the model to converge faster.
In terms of architecture, YOLO v2 uses a slightly deeper CNN than YOLO, which allows it to extract more powerful features from the image. The CNN is followed by several fully connected layers, which predict class probabilities and bounding box coordinates.
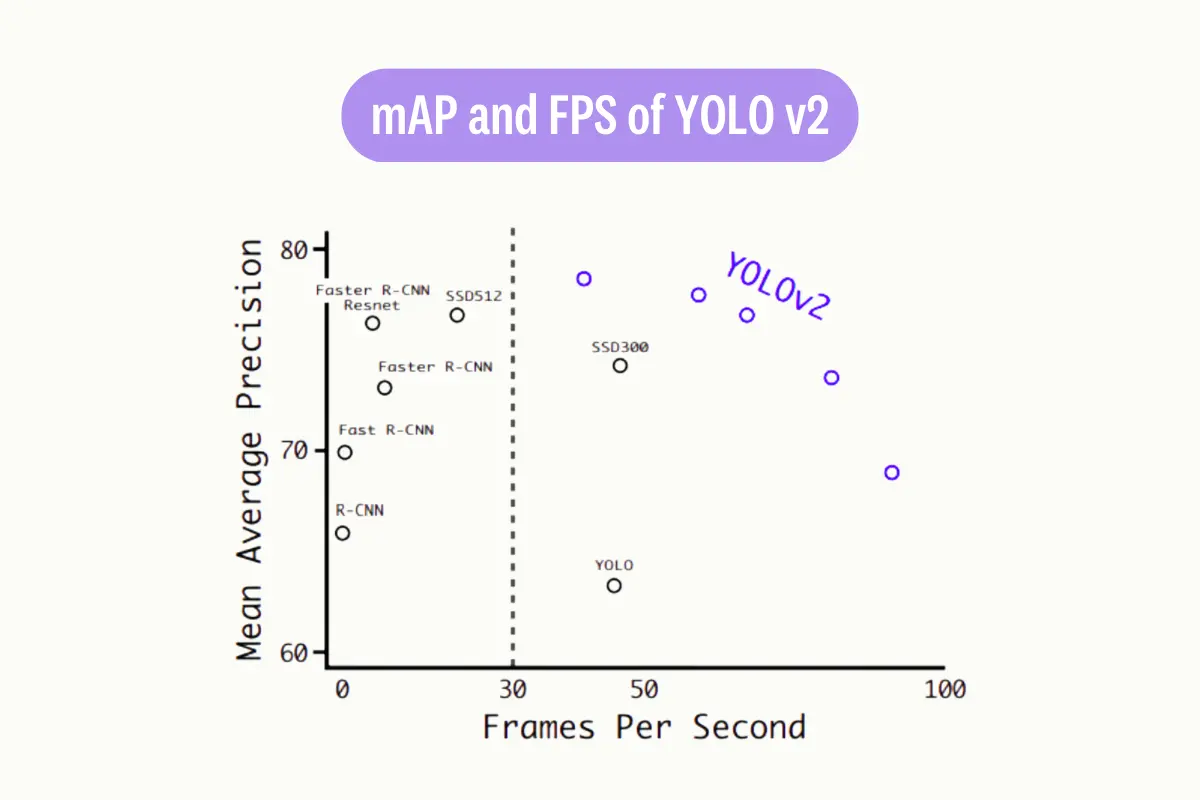
YOLO v3
YOLO v3 is the third version of the YOLO object detection algorithm. The first difference between YOLO v3 and previous versions is the use of multiple scales in the input image. YOLO v3 uses a technique called "feature pyramid network" (FPN) to extract features from the image at different scales. This allows the model to detect objects of different sizes in the image.
Another important difference is the use of anchor boxes. In YOLO v3, anchor boxes are used to match the predicted bounding boxes with the actual objects in the image. Anchor boxes are pre-defined boxes of different aspect ratios and scales, and the model predicts the offset of the anchor boxes relative to the bounding boxes. This helps the model to handle objects of different shapes and sizes better.
In terms of architecture, YOLO v3 is built on a deep convolutional neural network (CNN) that is composed of many layers of filters. The CNN is followed by several fully connected layers, which predict class probabilities and bounding box coordinates.
YOLO v3 also uses a different loss function than previous versions. It uses a combination of classification loss and localization loss, which allows the model to learn both the class probabilities and the bounding box coordinates.

YOLO v3 speed and mAP compared with other detectors
YOLO v4
Now, let’s take a look at one of the most important versions of YOLO. A key distinction between YOLO v4 and previous versions is using a more advanced neural network architecture. YOLO v4 uses a technique called "Spatial Pyramid Processing" (SPP) to extract features from the image at different scales and resolutions. This allows the model to detect objects of different sizes in the image.
Additionally, YOLO v4 also uses a technique called "Cross-stage partial connection" (CSP) to improve the model's accuracy. It uses a combination of multiple models with different architectures and scales and combines their predictions to achieve better accuracy.

YOLO v4 accuracy and FPS compared with other detectors
YOLO v5
YOLO v5 was introduced in 2020 with a key difference from the previous versions, which is the use of a more efficient neural network architecture called EfficientDet, which is based on the EfficientNet architecture. EfficientDet is a family of image classification models that have achieved state-of-the-art performance on a number of benchmark datasets. The EfficientDet architecture is designed to be efficient in terms of computation and memory usage while also achieving high accuracy.
Another important difference is the use of anchor-free detection, which eliminates the need for anchor boxes used in previous versions of YOLO. Instead of anchor boxes, YOLO v5 uses a single convolutional layer to predict the bounding box coordinates directly, which allows the model to be more flexible and adaptable to different object shapes and sizes.
YOLO v5 also uses a technique called "Cross mini-batch normalization" (CmBN) to improve the model's accuracy. CmBN is a variant of the standard batch normalization technique that is used to normalize the activations of the neural network.
Regarding training, YOLO v5 uses transfer learning, which allows it to be pre-trained on a large dataset and then fine-tuned on a smaller dataset. This allows the model to learn from a wide range of data and generalize better to new data.

Speed of YOLO v5 compared with EfficientDet [repository]
YOLO v6
A notable contrast between YOLO v6 and previous versions is the use of a more efficient and lightweight neural network architecture; this allows YOLO v6 to run faster and with fewer computational resources. The architecture of YOLO v6 is based on the "EfficientNet-Lite" family, which is a set of lightweight models that can be run on various devices with limited computational resources.
YOLO v6 also incorporates data augmentation techniques to improve the robustness and generalization of the model. This is done by applying random transformations to the input images during training, such as rotation, scaling, and flipping.
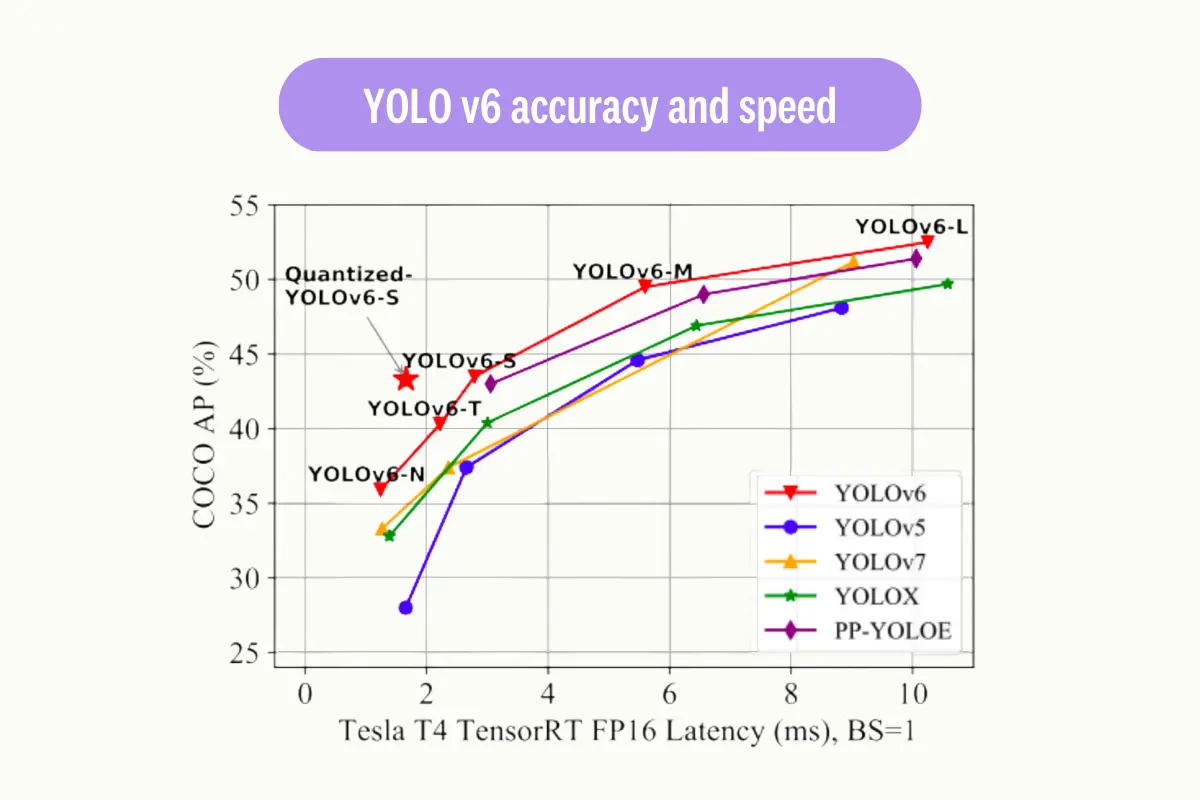
YOLO v7
YOLO v7, on the most recent stable iterations of the YOLO algorithm. It boasts a number of enhancements compared to previous versions. A key enhancement is the implementation of anchor boxes. These anchor boxes, which come in various aspect ratios, are utilized to identify objects of various shapes. The use of nine anchor boxes in YOLO v7 enables it to detect a wider range of object shapes and sizes, leading to a decrease in false positives.
In YOLO v7, a new loss function called "focal loss" is implemented to enhance performance. Unlike the standard cross-entropy loss function used in previous versions of YOLO, focal loss addresses the difficulty in detecting small objects by adjusting the weight of the loss on well-classified examples and placing more emphasis on challenging examples to detect.

YOLO Algorithms: Fortes
YOLO is widely used in real-world projects because of its accuracy and speed; its main powerful sides can be listed like the following:
- 1. Real-time object detection: YOLO is able to detect objects in real-time, making it suitable for applications such as video surveillance or self-driving cars.
- 2. High accuracy: YOLO achieves high accuracy by using a convolutional neural network (CNN) to predict both the class and location of objects in an image.
- 3. Single-shot detection: YOLO can detect objects in an image with just one forward pass through the network, making it more efficient than other object detection methods that require multiple passes.
- 4. Good performance on small objects: YOLO is able to detect small objects in an image because of its grid-based approach.
- 5. Efficient use of GPUs: YOLO uses a fully convolutional network architecture, which allows for the efficient use of GPUs during training and inference.
- 6. Ability to handle multiple scales: YOLO uses anchor boxes, which allows the model to handle objects of different scales, thus allowing the model to detect objects of different sizes in the same image.
YOLO Algorithm: Limitations
Even though YOLO is a powerful object detection algorithm, it also has some limitations. Some of these limitations include:
- 1. Limited to object detection: YOLO is primarily designed for object detection and may not perform as well on other tasks such as image segmentation or instance segmentation.
- 2. Less accurate than some other methods: While YOLO is accurate, it may not be as accurate as two-shot object detection methods, such as RetinaNet or Mask R-CNN.
- 3. Struggles with very small objects: YOLO's grid-based approach can make it difficult to detect tiny objects, especially if they are located close to other objects.
- 4. No tracking capability: YOLO does not provide any tracking capability, so it may not be suitable for video surveillance applications that require tracking of objects over time.
The simplest way to build high-quality datasets
Our professional workforce is ready to start your data labeling project in 48 hours. We guarantee high-quality datasets delivered fast.
Yolo Algorithm: Final Thoughts
In conclusion, object detection is a computer vision task that uses deep learning techniques to detect objects in images and videos. YOLO is a popular and fast object detection algorithm that uses a single neural network to predict bounding boxes and class probabilities for objects in an image. While it has its own limitations, such as being less accurate than some other methods and struggling with small objects, its speed and accuracy make it a valuable tool for object detection tasks.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
