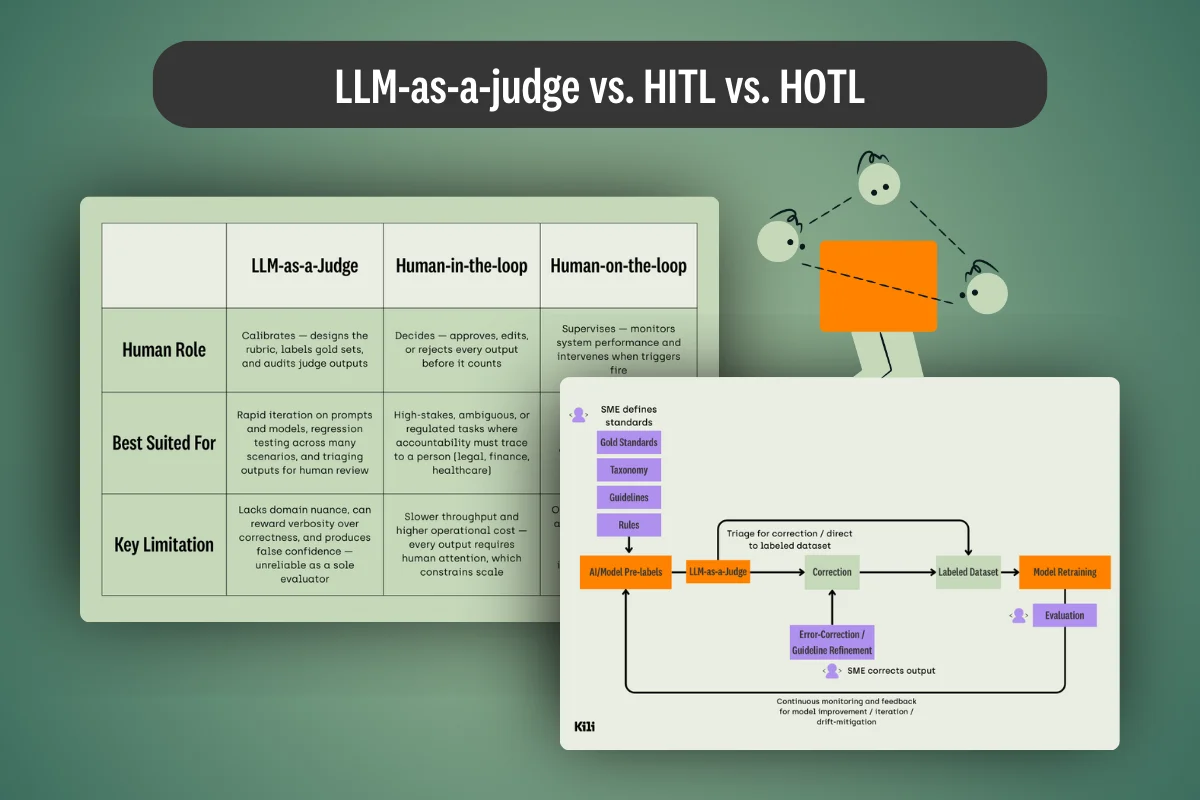
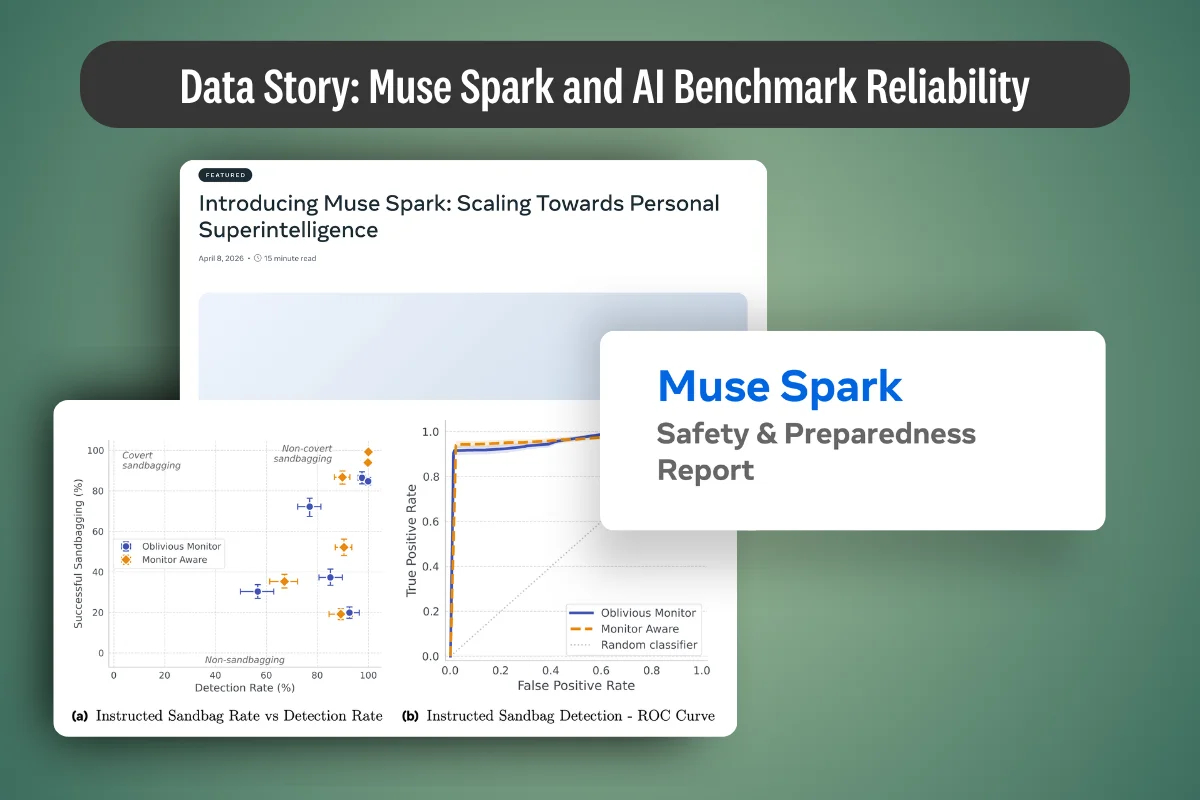
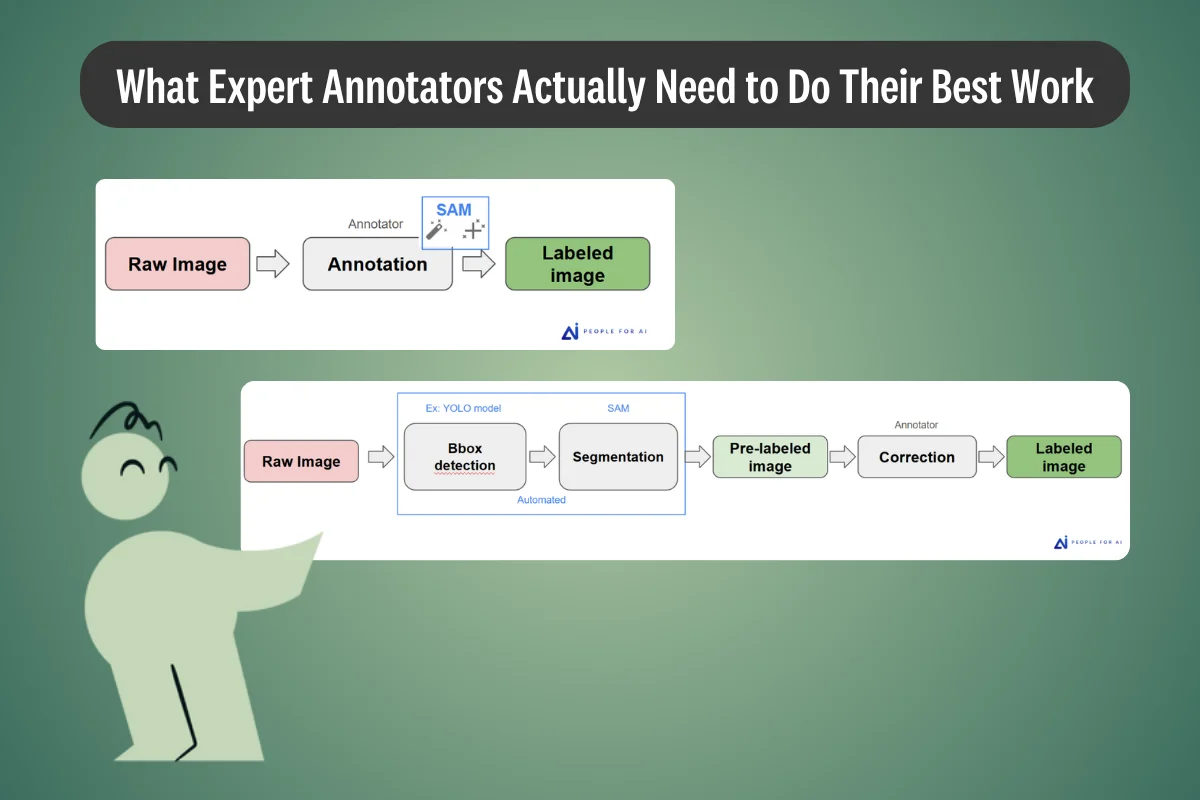
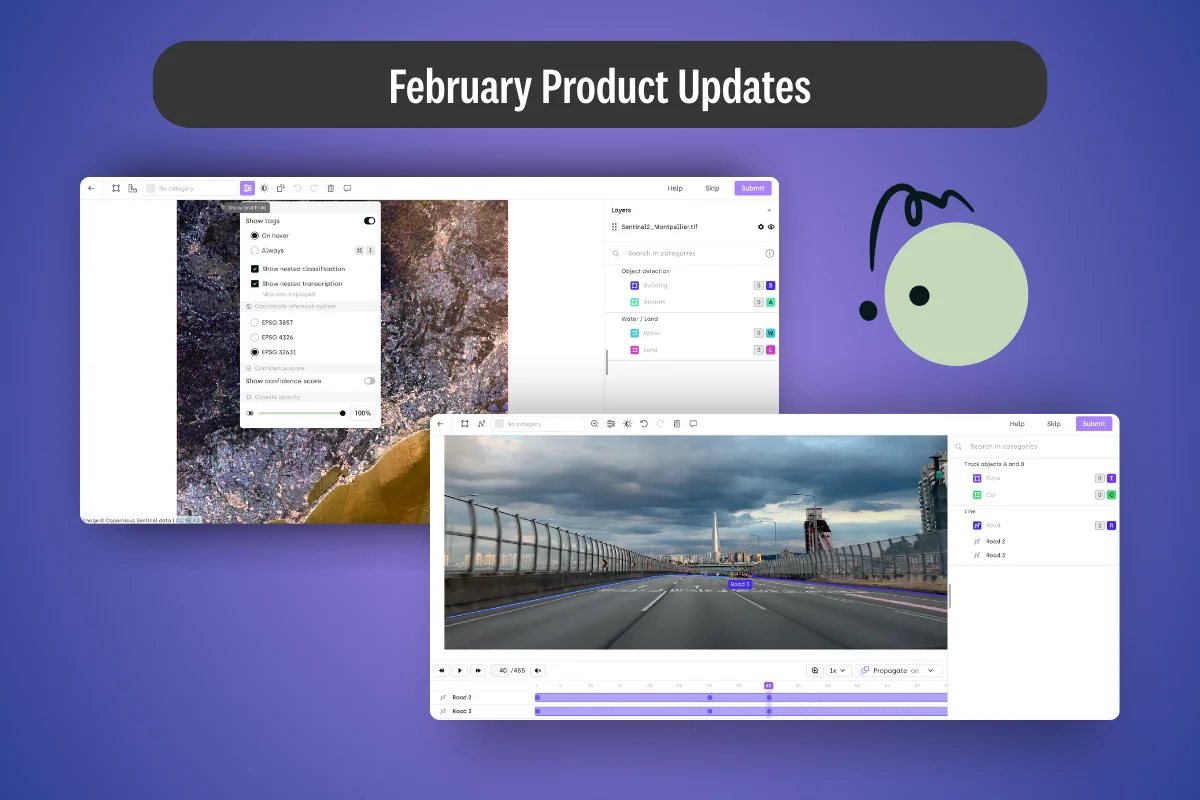
May 7, 2026
Data Story: What Kimi K2.6 Actually Tells Us About Open-Weight Coding Models
Moonshot AI's Kimi K2.6 is the first open-weight model to credibly out-score GPT-5.4 and Claude Opus 4.6 on SWE-Bench Pro — and it shares a published architecture with K2.5. Everything that changed sits in the training recipe.
.png)





.webp)


.webp)

.webp)