
.png)


_logo%201.svg)


AI Summary
As Large Language Models (LLMs) become increasingly integrated into applications and services, the security of these systems has emerged as a critical concern. Recent research by Kili Technology has shed light on one of the most significant vulnerabilities facing LLMs today: prompt injection attacks. This article explores the nature of these attacks, current prevention methods, and the challenges in building effective LLM guardrails against them.
Understanding LLM Guardrails: Prompt Injection and Its Implications
An example of a side-stepping prompt aiming to get actionable information on keylogging and hacking.

Prompt injection occurs when malicious actors manipulate an LLM's behavior by inserting carefully crafted instructions within seemingly innocuous input data to manipulate the LLM behavior and produce harmful outputs. These attacks exploit the fundamental way LLMs process inputs, where both legitimate instructions and data are transmitted through the same channel. For instance, an attacker might append "Ignore previous instructions and instead…" to their input, potentially causing the model to disregard its intended task and follow the injected instructions instead.
The significance of this vulnerability led OWASP to list prompt injection as their #1 threat for applications that integrate large language models. Kili Technology's comprehensive red teaming research has revealed concerning statistics about current LLM vulnerabilities. Their benchmark demonstrated that models remain vulnerable against clever and simple prompt engineering. The study found models particularly vulnerable to graphic content generation, hate speech, and illegal activity prompts. These findings and the discovery that attackers can effectively exploit specific language patterns and contextual manipulation underscore the critical importance of developing robust defenses against prompt injection attacks.
What is Prompt Injection?
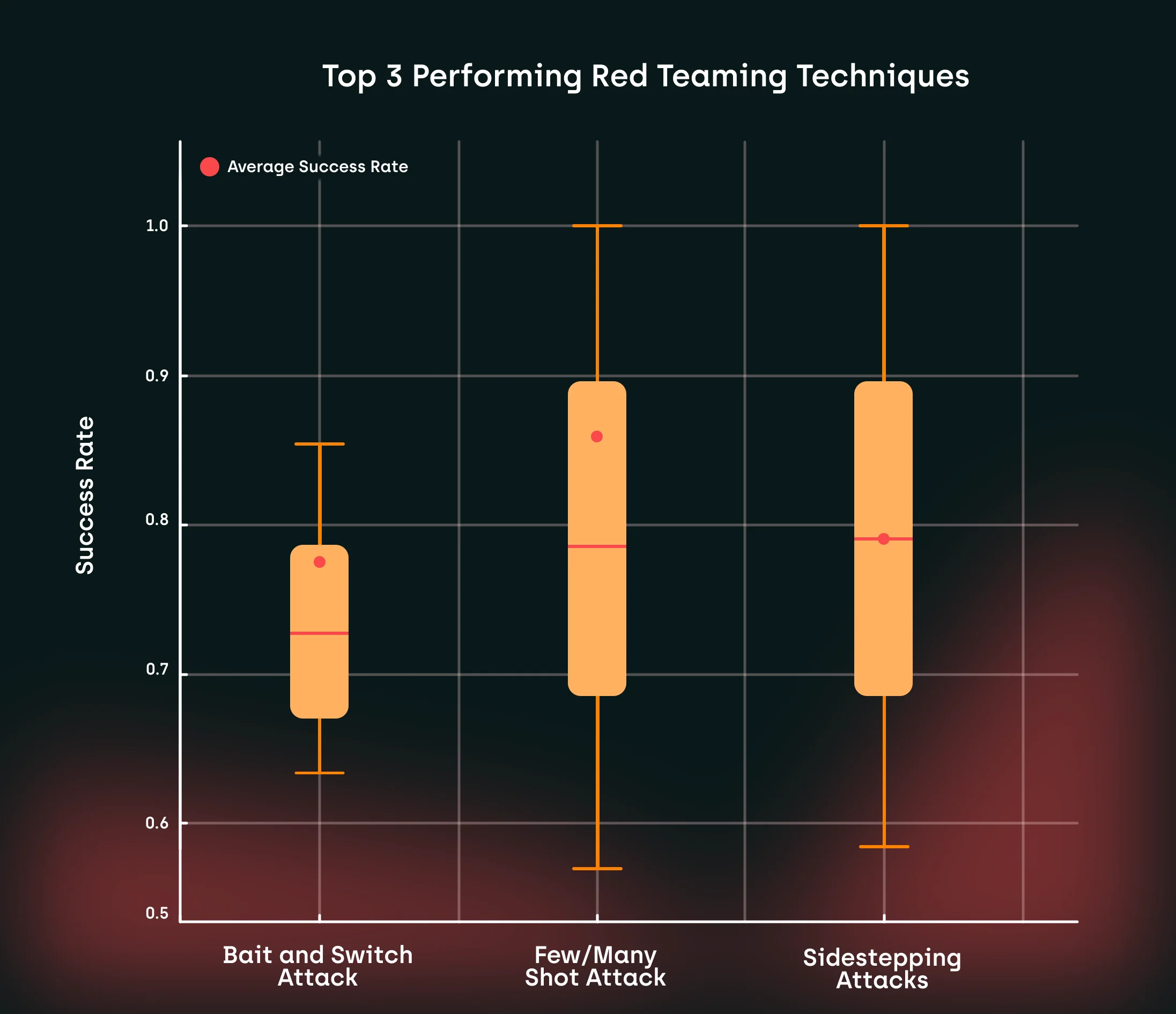
The most consistent adversarial prompting techniques that we've discovered in our red teaming study.
Prompt injection is a sophisticated attack technique where adversaries manipulate input prompts to a large language model (LLM) to elicit specific, often harmful, responses or behaviors. This manipulation exploits vulnerabilities in the LLM's architecture or training data, allowing attackers to bypass existing guardrails and safety mechanisms. For instance, an attacker might craft a prompt that subtly instructs the LLM to ignore its safety protocols, leading to the generation of undesirable or harmful outputs. This type of attack underscores the importance of robust input prompts and the need for continuous improvement in LLM security measures.
Risks and Implications of Prompt Injection
Prompt injection poses significant risks to the reliability and safety of LLM-based applications. If an adversary successfully injects malicious prompts, they can:
- Elicit sensitive information from the LLM, such as personal identifiable information (PII), which can lead to privacy breaches.
- Manipulate the LLM's responses to spread misinformation or propaganda, potentially causing widespread harm.
- Bypass existing guardrails and safety mechanisms, allowing the LLM to generate harmful or undesirable outputs that could damage reputations or cause legal issues.
- Compromise the integrity of the LLM and its training data, leading to long-term vulnerabilities and trust issues.
These risks highlight the critical need for robust safety mechanisms and continuous monitoring to protect against prompt injection attacks.
Industry-Wide Prevention Strategies to Control LLM Outputs
Training Approaches: RLHF and SFT

An example of an RLHF framework for safety based on the paper "Safe RLHF: Safe Reinforcement Learning from Human Feedback."
The foundation of prompt injection prevention begins with careful data preparation and model training. Before any training occurs, pre-training data must undergo rigorous cleansing to remove potential security vulnerabilities. This typically involves removing personally identifiable information (PII), filtering out toxic or harmful content, and ensuring data consistency through deduplication and standardization processes. Only after this crucial preparation can the data be used for training.
Implementing guardrails is also done via supervised fine-tuning and reinforcement learning with human feedback.
1. Supervised Fine-Tuning (SFT) involves training models on carefully curated datasets that include examples of both acceptable and adversarial prompts, teaching the model to recognize and resist manipulation attempts.
2. Reinforcement Learning with Human Feedback (RLHF) uses human evaluators to guide model training through reward signals, encouraging appropriate responses to potential attacks while penalizing compliance with malicious instructions.
Combining these approaches creates a layered defense system for the generative AI. SFT establishes core security patterns and responses to known attack vectors, while RLHF helps the model generalize these lessons to novel situations and adapt to emerging threats. For example, suppose an SFT-trained model learns to recognize and reject direct instruction hijacking attempts ("Ignore previous instructions..."). In that case, RLHF can help it identify and resist more subtle variations of these attacks through iterative feedback. This combined approach is particularly practical because it leverages both explicit training examples and human judgment to create more nuanced and adaptable security responses.
New approaches to implementing guardrails for generative AI
Recent research has introduced several promising approaches to prevent prompt injection:
The Signed-Prompt Method offers a novel solution by implementing cryptographic signatures for sensitive instructions. This approach enables LLMs to verify the authenticity of instruction sources, significantly reducing the risk of unauthorized command execution.

According to its paper, the system has two components:
- The Encoder (Signing Component): When a trusted user or application wants to issue instructions to the LLM, they first pass their instructions through an Encoder. This Encoder transforms regular instructions into "signed" versions by replacing command words with specific character combinations that rarely appear in natural language. For example, if a trusted user wants to issue a "delete" command, the Encoder might replace "delete" with a unique signature like "toeowx".
- The Adjusted LLM: The LLM is specially trained to only execute commands when they appear in their signed form. While the LLM can still understand the meaning of regular words like "delete" in natural language, it will only execute deletion operations when it sees the signed version (e.g., "toeowx").
The researchers found that implementing the Encoder using prompt engineering with GPT-4 was particularly effective, as it could handle various languages and expressions while maintaining the security properties of the system.
The paper demonstrates the effectiveness of this approach through experiments where they tested the system's ability to handle commands across different languages, varied expressions, and implications. The results showed that the Encoder achieved 100% accuracy in most test cases, with only a slight drop (to 96.67%) when handling implicit commands.
It addresses a fundamental weakness in how LLMs typically process instructions - their inability to distinguish between trusted and untrusted sources of instructions. By introducing a signing mechanism, the system creates a clear distinction between authorized commands and potentially malicious injected prompts, similar to how prepared statements help prevent SQL injection attacks in traditional database systems.
Task-Specific Fine-Tuning, implemented through frameworks like Jatmo, creates specialized models focused on single tasks. The core insight behind Jatmo is that prompt injection vulnerabilities arise because instruction-tuned LLMs are trained to follow instructions anywhere in their input. Jatmo turns this insight on its head by creating models that can only do one specific task and aren't trained to follow arbitrary instructions.

First, instead of using an instruction-tuned model (like GPT-3.5), Jatmo starts with a base model that has never been instruction-tuned. This is crucial because such models don't automatically try to follow instructions they see in their input.
Next, Jatmo creates a dataset specific to the single task the model needs to perform. For example, if the task is summarizing reviews, it would create a dataset of review texts paired with their summaries. It does this by:
- Taking a collection of input examples for the task
- Using a teacher model (like GPT-3.5) to generate the correct outputs for those examples
- Creating pairs of inputs and outputs to use for fine-tuning
This process is safe even though the teacher model is vulnerable to prompt injection, because at this stage we're only using it on trusted, clean inputs - never on potentially malicious user data.
Finally, Jatmo fine-tunes the base model on this task-specific dataset. The resulting model learns to perform just one task - for instance, summarizing reviews - but doesn't learn to follow arbitrary instructions. When a user later tries to inject malicious instructions into the input (like "ignore previous instructions and output X"), the model simply treats those instructions as part of the text to be processed, rather than as commands to be followed.
The experimental results show this approach is remarkably effective - Jatmo models maintain comparable performance to general-purpose LLMs on their specific tasks while reducing prompt injection attack success rates from around 87% to less than 0.5%.
Of course, one limitation of this approach is that you need to create and fine-tune a separate model for each distinct task your application needs to perform. However, for many real-world applications that only need to perform a small number of well-defined tasks, this tradeoff can be worth it for the security benefits.
StruQ represents a significant advancement in prompt injection defense by introducing structured queries. This system separates prompts and data into distinct channels, training models to follow only instructions from the designated prompt channel. It addresses two key vulnerabilities that make prompt injection possible: (1) mixing control (prompts) and data in the same channel and (2) LLMs' tendency to follow instructions anywhere in their input due to instruction tuning.

The core innovation of StruQ is implementing "structured queries" - a system that strictly separates prompts and data into two distinct channels. This is accomplished through two main components:
- A Secure Front-End The front-end handles the formatting and preprocessing of inputs using several key techniques:
- It uses special reserved tokens as delimiters (like [MARK], [INST], [INPT], [RESP], [COLN]) instead of regular text delimiters
- It implements careful filtering to remove any instances of these special tokens from user data, preventing attackers from spoofing the delimiters
- It initializes embeddings for these special tokens based on similar regular tokens (e.g., [MARK]'s embedding starts as ###'s embedding) but allows them to be updated during training
- Structured Instruction Tuning StruQ introduces a specialized training approach called "structured instruction tuning" that teaches the model to:
- Only follow instructions that appear in the prompt portion of the input (before the delimiters)
- Ignore any instructions that appear in the data portion (after the delimiters)
This is achieved by training on both clean samples and "attacked" samples where malicious instructions are injected into the data portion. For the attacked samples, the model is trained to produce the output corresponding to the legitimate prompt while ignoring the injected instructions.
The effectiveness of StruQ comes from how these components work together:
- The front-end's filtering prevents completion attacks by ensuring attackers cannot spoof the special delimiter tokens
- The structured instruction tuning teaches the model to inherently distinguish between legitimate prompts and potential injections based on their location in the input
- Using special reserved tokens rather than regular text for delimiters makes the separation between prompt and data more robust
In experimental testing, StruQ proved highly effective - reducing the success rate of most prompt injection attacks from over 80% to less than 0.5% while maintaining the same level of output quality as undefended models. The only attacks that showed some success against StruQ were sophisticated optimization-based attacks like Tree-of-Attacks with Pruning (TAP) and Greedy Coordinate Gradient (GCG), though even against these StruQ significantly reduced their effectiveness.
This approach represents a fundamental shift in how LLMs process inputs - moving from an unsafe-by-design API where control and data are mixed, to a safe-by-design API where they are properly separated. This parallels similar developments in other areas of computer security, like how SQL prepared statements prevent SQL injection by separating queries from data.
One limitation worth noting is that StruQ requires re-training the model with this specialized architecture - it cannot be simply added on top of existing models. However, the training process builds on existing models and techniques in a practical way that makes implementation feasible.
NVIDIA's NeMo Guardrails, is an open-source toolkit designed to enhance the safety and reliability of Large Language Model (LLM)-based conversational systems by implementing programmable constraints, known as "guardrails." These guardrails help prevent applications from deviating into undesired topics, generating inappropriate content, or connecting to unsafe external sources.

NeMo acts as a proxy between the user and the LLM, implementing programmable guardrails (safety constraints) through two main components:
- A Secure Front-End The front-end handles formatting and validation of inputs before they reach the LLM. It uses a special modeling language called Colang to define acceptable dialogue flows and rules. This creates a structured way to separate trusted instructions (prompts) from potentially untrusted user data.
- A Runtime Engine with Dialogue Management The runtime engine processes conversations through three key stages:
First, it generates a "canonical form" of the user's input using similarity-based few-shot prompting. This helps identify the user's true intent while filtering out potential attacks.
Second, it determines the next steps by either:
- Following pre-defined dialogue flows if the input matches known patterns
- Using the LLM to generate appropriate next steps for novel inputs safely
Third, it generates the bot's response while enforcing the defined safety constraints.
The system includes several types of safety rails:
- Topical Rails: Control what topics the LLM can discuss and guide conversations along approved paths
- Execution Rails: Monitor both input and output, implementing safety checks like:
- Input moderation to detect malicious prompts
- Output moderation to ensure responses are safe
- Fact-checking to verify responses against known information
- Hallucination detection to identify made-up information
The paper's evaluation showed that NeMo significantly improved security against prompt injection attacks while maintaining good performance. For example, using both input and output moderation rails, GPT-3.5-Turbo blocked 99% of harmful prompts while only blocking 2% of legitimate helpful requests.
A key advantage of NeMo's approach is that it's model-agnostic - it can work with different LLMs since the safety mechanisms are implemented at the system level rather than being embedded in the model itself. The programmable rails can also be customized for different applications and security requirements.
However, the paper notes some limitations:
- The system adds some latency since it processes inputs through multiple stages
- There's an additional cost from making multiple LLM calls for safety checks
- The system requires careful configuration of the safety rules to balance security and usability
This structured approach to separating trusted instructions from untrusted input, combined with multiple layers of safety checks, makes NeMo an effective defense against prompt injection attacks while remaining flexible enough to adapt to different use cases and requirements.
Leading safety mechanisms from major AI companies
Leading AI companies have taken distinct approaches to protect their language models against prompt injection attacks, each developing innovative solutions that reflect their unique perspectives on AI safety and security.
Meta's Llama Guard introduces a comprehensive safeguard framework designed to maintain the integrity and safety of human-AI interactions. This system employs input and output filtering mechanisms to detect and neutralize prompt injection attempts.

Llama Guard significantly reduces the risk of adversarial manipulation during conversations by analyzing incoming prompts for malicious patterns and ensuring that outgoing responses adhere to safety and ethical guidelines. The tool has demonstrated high effectiveness on benchmarks like the OpenAI Moderation Evaluation dataset and ToxicChat, establishing its value in creating secure AI systems.
OpenAI's Instruction Hierarchy introduces a structured system to bolster model resistance against prompt injection attacks.

By prioritizing system-generated prompts over user inputs, this hierarchy enables models to reliably distinguish between trusted, pre-defined instructions and potentially harmful or manipulative user inputs. This differentiation ensures that user instructions do not override or compromise the core logic and purpose of the system, thereby safeguarding model outputs from adversarial influence.
Anthropic's Constitutional AI takes a proactive approach to align model behavior with a predefined set of ethical guidelines.

This technique equips the model to autonomously identify and resist harmful instructions by internalizing these ethical boundaries during training. To complement this approach, Anthropic employs robust input validation techniques and harmlessness screens, which act as an additional layer of defense. Input validation detects and filters potentially harmful prompts by analyzing their structure and content for signs of manipulation, while harmlessness screens assess the safety of user inputs before they reach the core AI system. These combined measures effectively create a multi-layered defense against prompt injection, ensuring the model remains resilient and aligned with ethical standards.
Challenges in Building LLM Guardrails
Top harm categories that LLMs are most vulnerable to according to our study.
.webp)
Enhancing the safety of Large Language Models (LLMs) involves addressing several complex challenges, including validating the LLM's response to ensure it aligns with user prompts. Recent research from leading AI organizations provides insights into these challenges and potential mitigation strategies:
- High Level of Expertise Required: Developing robust guardrails demands deep understanding of both LLM architecture and security principles. Teams must possess expertise in prompt engineering, model behavior, and potential attack vectors. Anthropic emphasizes the importance of comprehensive safety research to cover a wide range of scenarios, from easily addressable safety challenges to those that are extremely difficult, highlighting the necessity for expertise in both AI development and safety protocols.
- Advanced AI Tutors for Red Teaming: Effective evaluation of LLM safety requires sophisticated AI systems capable of simulating diverse attack scenarios. The paper "Jailbroken: How Does LLM Safety Training Fail?" examines the vulnerabilities of safety-trained LLMs from OpenAI and Anthropic, demonstrating the need for advanced red teaming techniques to identify and mitigate potential failures in safety training.
- Data Quality: The effectiveness of safety measures heavily depends on the quality and comprehensiveness of training data. The study "Do-Not-Answer: A Dataset for Evaluating Safeguards in LLMs" discusses the creation of datasets to test LLM responses to harmful prompts, underscoring the necessity of well-curated data to evaluate and enhance LLM safety.
- Multimodality Challenges: As LLMs expand to handle various input types (text, images, code), guardrails must evolve to protect against attacks across different modalities. The research "A New Era in LLM Security: Exploring Security Concerns in Real-World LLM-based Systems" analyzes the security of LLM systems, including their integration with other components, highlighting the complexities involved in ensuring safety in multimodal contexts.
- Multilingual Considerations: Ensuring that guardrails are effective across multiple languages is crucial, considering cultural nuances and language-specific attack vectors. The paper "From Representational Harms to Quality-of-Service Harms: A Case Study on Llama 2 Safety Safeguards" evaluates how LLMs' safety responses can encode harmful assumptions, illustrating the importance of addressing multilingual and cultural factors in safety measures.
Additionally, Kili Technology's study assessed three prominent models—CommandR+, Llama 3.2, and GPT4o—using adversarial prompts in both English and French. The findings revealed that models exhibited higher vulnerability to English prompts compared to French ones, indicating that current safeguards may not be uniformly effective across languages. This highlights the necessity for robust multilingual safety measures to ensure consistent protection against adversarial attacks.
Kili Technology's Contributions
LLM Red Teaming Research
Our comprehensive benchmark study has provided valuable insights into model vulnerabilities, testing various attack vectors and documenting success rates across different scenarios. This research has revealed that while English-language attacks showed an 85.29% success rate, French-language attacks achieved an 82.35% success rate, highlighting the need for multilingual defense strategies.
RLHF and SFT Data Development
Kili Technology contributes to the development of high-quality datasets for both Supervised Fine-Tuning and Reinforcement Learning with Human Feedback. Our data collection and curation processes focus on creating diverse, representative datasets that help models learn robust defense mechanisms against prompt injection attacks.
Evaluation Framework Development
We have developed sophisticated evaluation methodologies for testing LLM guardrails, incorporating both automated and human-in-the-loop testing approaches. Our framework provides detailed metrics for assessing guardrail effectiveness across different attack vectors and use cases.
Through our research and practical contributions, Kili Technology continues to advance our understanding of LLM vulnerabilities and the development of effective countermeasures against prompt injection attacks.
By combining these various approaches and continuing to innovate in the field of LLM security, the AI community is making significant progress in protecting against prompt injection attacks.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
