.png)

_logo%201.svg)


AI Summary
- O3 Mini and Claude 3.7 lead at 84 percent overall accuracy, but domain-specific performance varies significantly across all eight models tested
- Mathematical reasoning shows the widest performance gap, ranging from 90 percent (O3 Mini) to 35 percent (Qwen2.5), revealing divergent training priorities
- Claude 3.7 achieved perfect follow-up accuracy, suggesting a breakthrough in iterative reasoning and metacognitive capabilities
- Reinforcement learning approaches like DeepseekR1 strengthen logical reasoning but degrade on iterative tasks, signaling a tradeoff in current RL methods
- Performance gaps widen dramatically at post-graduate complexity, making advanced task difficulty the sharpest differentiator among current LLMs
- No single model dominates all domains, making strategic model selection by use case essential rather than relying on aggregate rankings
When our team set out to evaluate the reasoning capabilities of leading Large Language Models (LLMs), we knew we were tackling one of the most critical questions in AI today: how well can these systems actually reason? Despite the impressive advances in LLMs, we noticed a significant gap in how these models were being systematically evaluated when it came to their reasoning abilities.
We decided to implement a comprehensive, multi-dimensional benchmark to assess eight prominent LLMs: OpenAI's O1, OpenAI's O3 Mini, Claude 3.5, Claude 3.7, Mistral, Qwen2.5, DeepseekR1, and QwQ-32B. Before diving in, we recognized that a traditional one-size-fits-all approach wouldn't capture the nuanced ways these models handle reasoning tasks.
After reviewing the literature, we built upon the methodological advances from Apple's GSM-Symbolic framework (Mirzadeh et al., 2024). This allowed us to create a more controlled assessment environment that goes beyond simple pattern matching. By incorporating questions rewritten and reworked from diverse sources, we crafted a framework that lets us peek under the hood of these AI systems and understand what's really happening when they tackle reasoning challenges.
The timing of our study couldn't be more crucial. Organizations are increasingly relying on LLMs for complex tasks requiring genuine reasoning rather than simple pattern recognition. We hope our findings will illuminate the current state of LLM reasoning capabilities and offer valuable insights for future research and development efforts in this rapidly evolving field.
Methodology
Building Our Evaluation Framework
After brainstorming how to best capture different dimensions of reasoning, we structured our benchmark across three distinct subject domains and five ascending proficiency levels. This multi-dimensional approach allowed us to dig deeper than traditional single-metric evaluations.
We divided our tasks across these domains:
- Language (16% of tasks): We challenged the models with linguistic understanding, semantic analysis, and complex text interpretation
- Mathematics (41.33% of tasks): Here we focused on numerical reasoning, algebraic manipulation, and application of mathematical principles
- Reasoning (42.67% of tasks): These tasks tested logical deduction, multi-step problem solving, and general reasoning capabilities
We then stratified these domains across five proficiency levels:
- Basics (30.67%): Foundational reasoning tasks requiring simple logical steps
- High School Level (6.67%): Intermediate challenges comparable to high school curriculum difficulty
- College Entrance Level (21.33%): Tasks reflecting college admissions exam complexity
- Pre-Graduate Level (28%): Advanced reasoning problems similar to undergraduate final-year coursework
- Post-Graduate Level (13.33%): Expert-level challenges requiring sophisticated reasoning
Before finalizing our approach, we studied Apple's GSM-Symbolic study (Mirzadeh et al., 2024), which demonstrated the importance of evaluating performance across different instantiations of the same fundamental question. This insight guided our decision to structure the evaluation across multiple domains and complexity levels.
Bringing in Human Expertise for Dataset Construction
We knew that a distinguishing feature of our benchmark needed to be the integration of expert human judgment. So we assembled a team of domain specialists who collaborated to develop challenging questions that would test genuine reasoning capabilities rather than pattern recognition or memorization.
Our question development process followed a rigorous multi-stage approach:
- Initial Question Design: Our domain experts created foundational questions targeting specific reasoning capabilities across different complexity levels.
- GSM-Symbolic Translation: Following Mirzadeh et al.'s (2024) framework, we translated questions into symbolic templates that allowed for controlled variation while preserving the underlying logical structure.
- Human-AI Collaborative Refinement: After creating initial questions, we put them through iterative refinement through a human-AI collaborative process. Our specialists analyzed model responses to identify and eliminate shortcuts that could be exploited through pattern matching.
- Cross-Domain Validation: Before finalizing our question set, we had specialists from different domains validate questions to ensure they genuinely tested reasoning capabilities rather than domain-specific knowledge.
- Distractor Engineering: For a subset of questions, we carefully crafted distractors to test models' ability to distinguish relevant from irrelevant information.
This human expertise-driven approach yielded questions that probe the boundaries of current LLM reasoning capabilities, enabling a more nuanced assessment of genuine logical deduction as opposed to sophisticated pattern matching.
Running Our Evaluation
We structured our evaluation in two phases:
- Initial Assessment: We evaluated all models on 66 single-prompt tasks across the three domains and five proficiency levels.
- Follow-up Assessment: After completing the initial evaluation, we further tested models on 9 follow-up prompts that required elaboration or refinement of initial responses, providing insights into iterative reasoning capabilities.
We used binary success metrics (correct/incorrect) across 75 total tasks, with results aggregated to calculate:
- Overall success rate per model
- Domain-specific success rates
- Level-specific success rates
This comprehensive approach gave us a more nuanced understanding of LLM reasoning capabilities than traditional single-point metrics, revealing important performance variations across different task types and complexity levels.
What We Discovered: Overall Performance Results
A Clear Performance Hierarchy Emerges
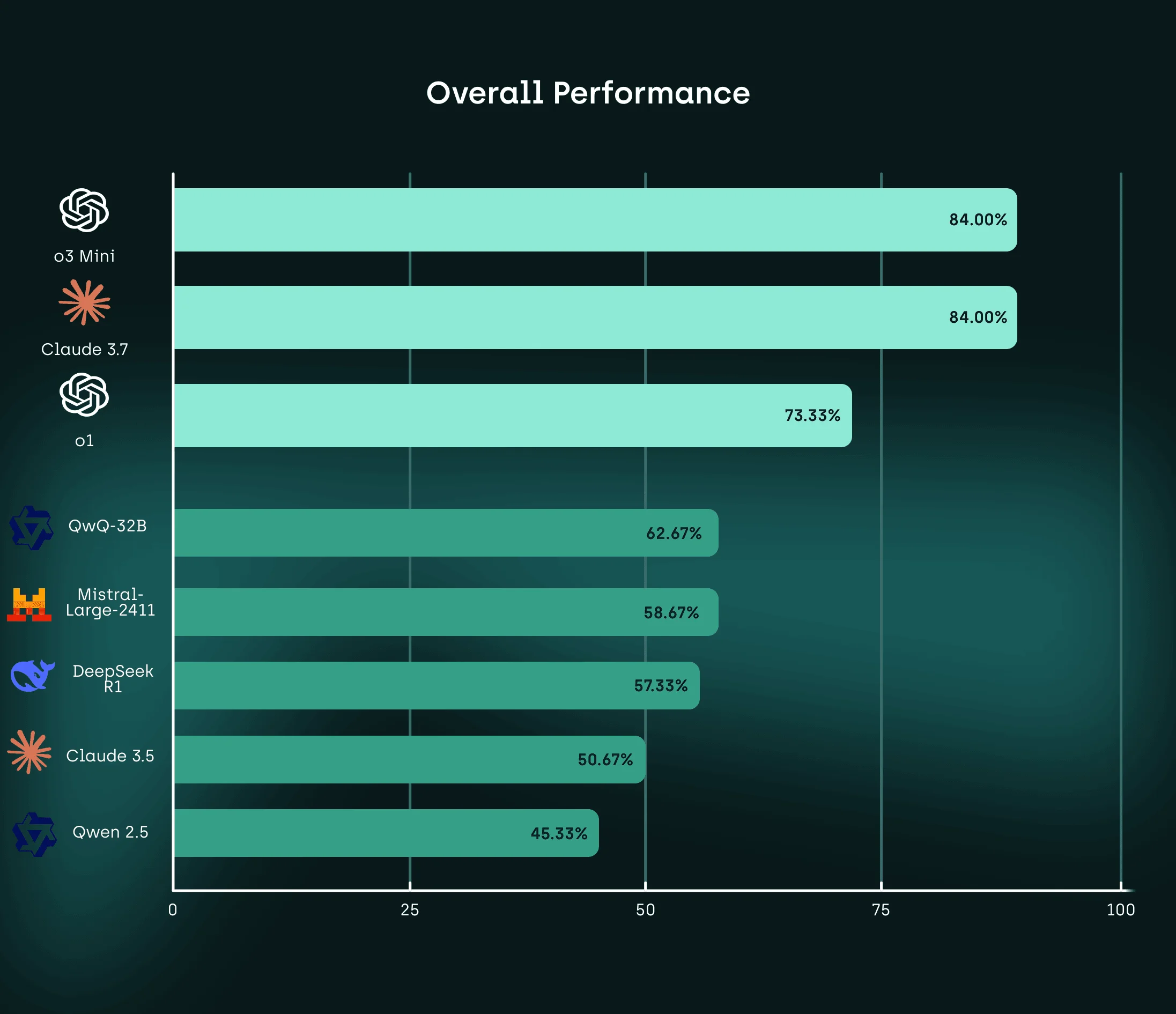
After crunching the numbers, we found substantial performance differentials across the evaluated models, establishing a clear hierarchy:
Top Performers (84% success rate):
- O3 Mini
- Claude 3.7
Middle Tier:
- O1 (73.33%)
- QwQ-32B (62.67%)
Lower Tier:
- Mistral (58.67%)
- DeepseekR1 (57.33%)
- Claude 3.5 (50.67%)
- Qwen2.5 (45.33%)
We were struck by the significant gap between leading and trailing models, with the top performers completing 84% of tasks successfully compared to just 45.33% for the lowest-performing model (Qwen2.5). The 38.67 percentage point difference between top and bottom performers reveals substantial variance in reasoning capabilities across current LLMs.
We found it particularly interesting that O3 Mini and Claude 3.7 achieved identical overall success rates at the top of the hierarchy, despite representing different architectural approaches and training methodologies. This convergence of performance may indicate emerging best practices in model development for reasoning tasks.
Follow-up Prompts Reveal Surprising Capabilities
When we tested the models' ability to refine their initial responses, we uncovered some fascinating insights about their iterative reasoning abilities—a capability critical for real-world applications requiring problem-solving.
Claude 3.7 blew us away with a perfect 100% success rate on follow-up prompts. This suggests superior metacognitive abilities—the capacity to reflect on and refine its own reasoning processes. O3 Mini also impressed us with a strong performance on follow-up tasks, achieving an 88.89% success rate.
In contrast, several models struggled significantly when asked to refine their initial analyses. We watched DeepseekR1's success rate plummet from 60.61% on initial prompts to only 33.33% on follow-ups, suggesting limitations in iterative reasoning capabilities. QwQ-32B and Mistral also showed notable decreases in performance on follow-up tasks.
These variations in follow-up performance have important implications for applications requiring extended reasoning dialogues or iterative problem-solving, where the ability to refine initial analyses based on additional context or feedback is essential.
Breaking It Down: Domain-Specific Performance Analysis
Language Domain:
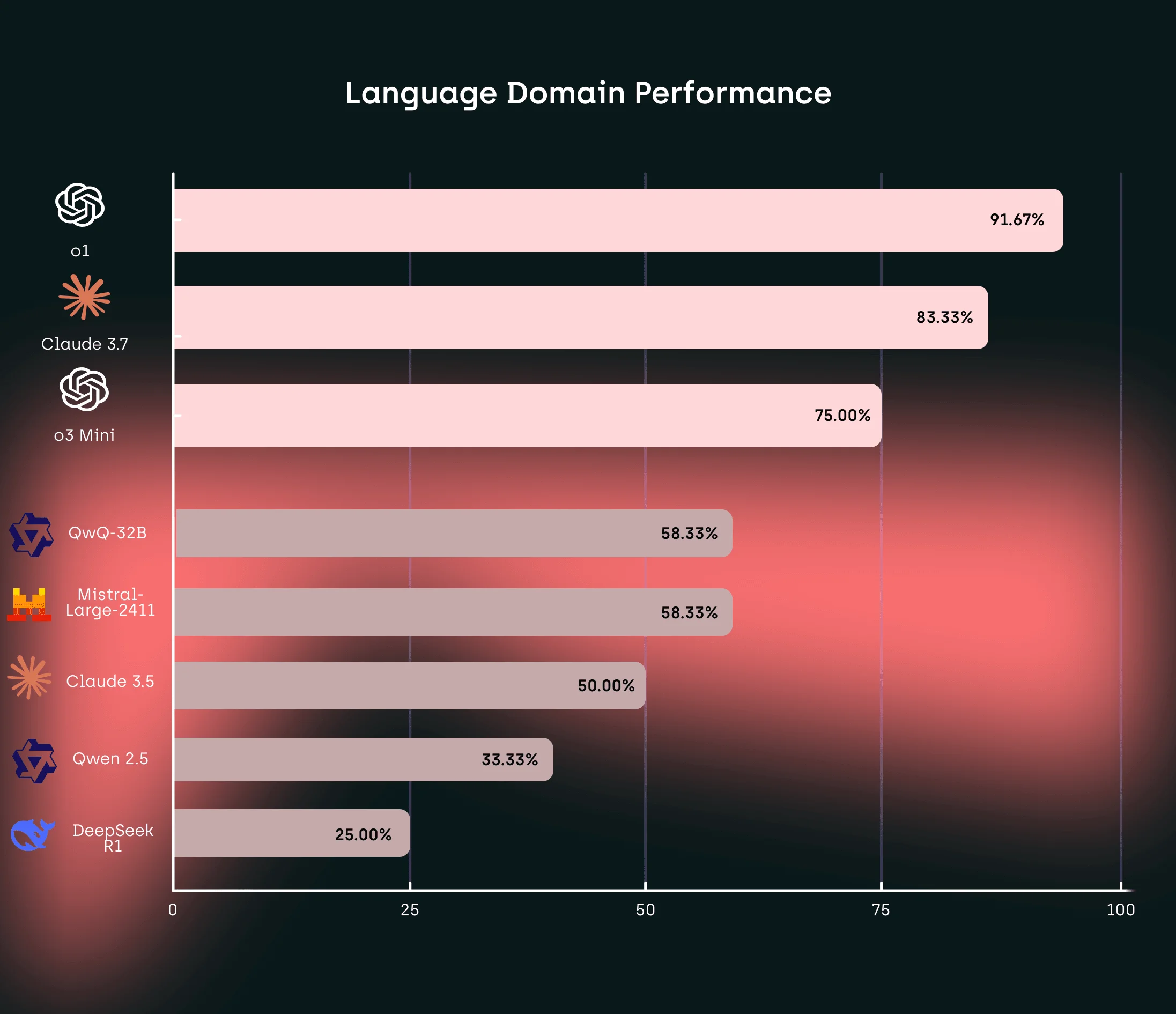
When examining the Language domain, we discovered that O1 performed exceptionally well at 91.67%, significantly outperforming all other models. Claude 3.7 followed with a strong showing at 83.33%. This domain revealed some of the most dramatic performance differentials, with DeepseekR1 and Qwen2.5 achieving substantially lower success rates at 25% and 33.33% respectively.
The nearly 70 percentage point gap between the top and bottom performers in this domain surprised us, suggesting that language understanding capabilities are developing at significantly different rates across model architectures. O1's superior performance in this area likely reflects OpenAI's particular emphasis on linguistic understanding in their training methodology, while the relatively weaker performance of DeepseekR1 might indicate a trade-off in training focus.
QwQ-32B and Mistral showed moderate capabilities with identical 58.33% success rates, positioning them in the middle tier for language tasks. We noticed this clustering of mid-tier performance around 60% suggests a common level of language understanding capability among several contemporary models, with a few achieving breakthrough performance.
Mathematics Domain:
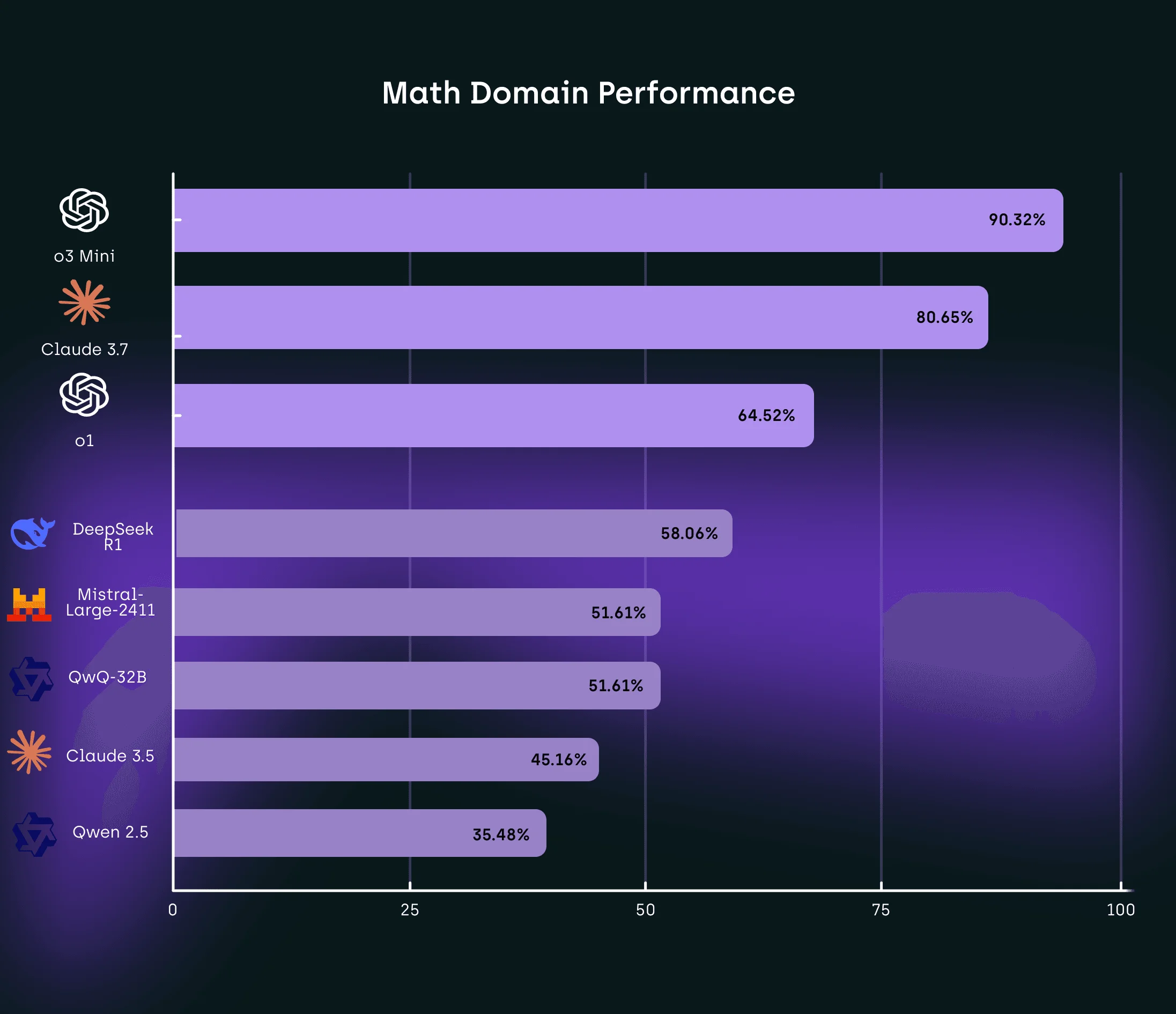
Mathematics revealed some of the most interesting performance variations across the evaluated models. We were impressed to see O3 Mini demonstrate exceptional mathematical reasoning capabilities with a 90.32% success rate, followed by Claude 3.7 at 80.65%. This stood out to us because mathematics has historically been a challenging domain for LLMs due to its requirement for formal reasoning rather than pattern matching.
O1, which performed strongly in the language domain, showed more moderate capabilities in mathematics at 64.52%, suggesting different specialization in its training or architecture. DeepseekR1 performed relatively well at 58.06%, while QwQ-32B and Mistral achieved identical scores of 51.61%.
We noticed Qwen2.5 struggled significantly in this domain, achieving only a 35.48% success rate, indicating particular challenges with mathematical reasoning tasks. The 54.84 percentage point differential between the top and bottom performers highlights the varying approaches to mathematical reasoning among current LLMs.
The strong performance of O3 Mini suggests significant progress in addressing the limitations identified by Mirzadeh et al. (2024), who observed that mathematical reasoning presents particular challenges for LLMs. This improvement likely stems from architectural innovations or training methodologies specifically targeting mathematical capabilities.
Reasoning Domain:
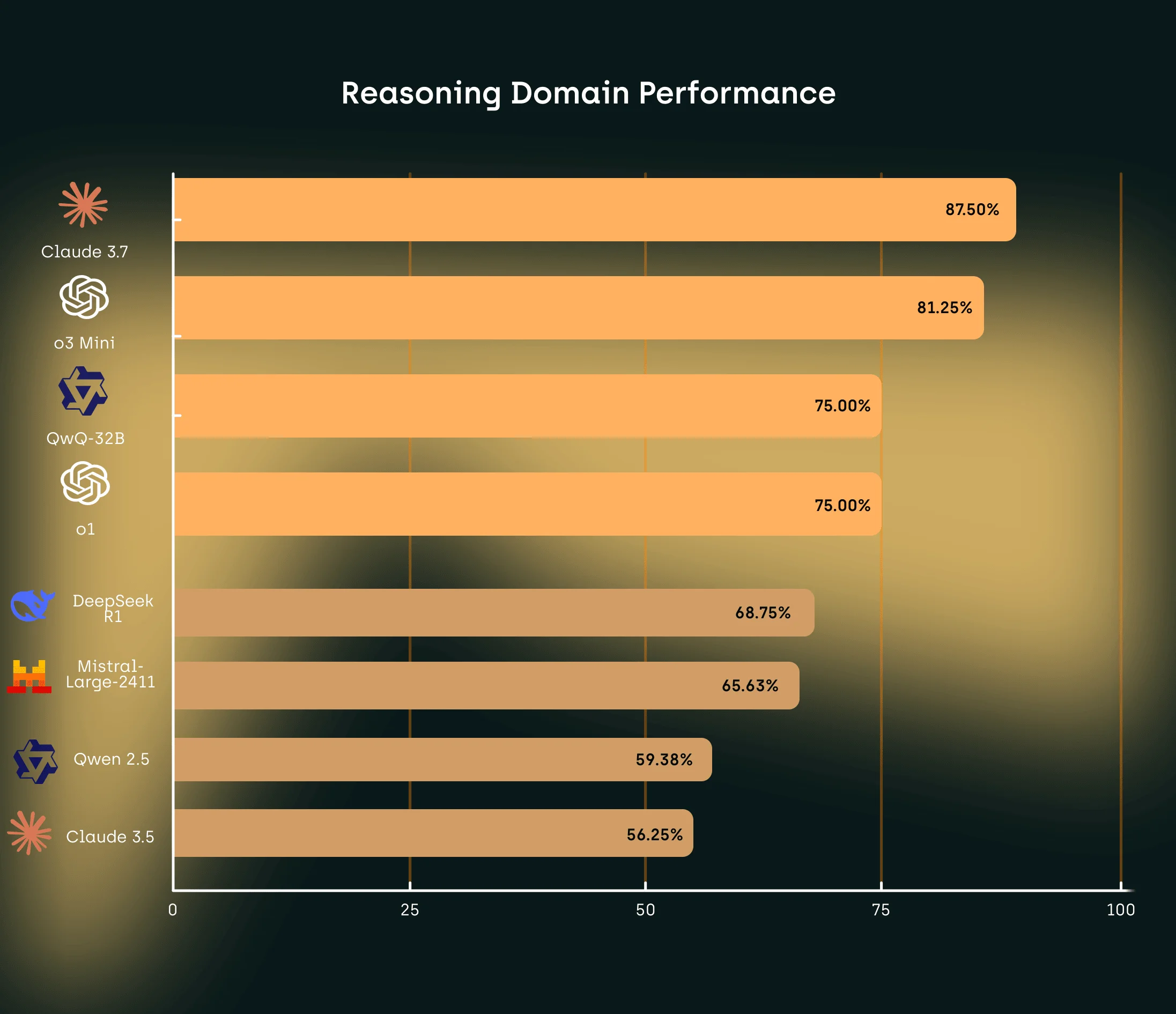
In the Reasoning domain, which assessed capabilities most directly related to logical deduction and inference, we found Claude 3.7 demonstrated superior performance with an 87.50% success rate, followed closely by O3 Mini at 81.25%. This domain showed less dramatic performance differential than others, with even lower-tier models achieving relatively better results.
QwQ-32B and O1 both showed strong capabilities with identical 75.00% success rates, despite their more varied performance in other domains. DeepseekR1 performed relatively well at 68.75%, followed by Mistral at 65.63%. Claude 3.5 showed more limited capabilities at 56.25%, while Qwen2.5 achieved a 59.38% success rate in this domain.
What caught our attention was the relatively strong performance of QwQ-32B in this domain (75.00%) despite more modest results in others, indicating potential specialization in logical reasoning capabilities. Similarly, DeepseekR1's stronger showing in reasoning compared to other domains suggests its reinforcement learning approach may be particularly effective for logical reasoning tasks.
The narrower performance gap in this domain (31.25 percentage points between top and bottom performers) suggests that general reasoning capabilities may be developing more evenly across different model architectures than domain-specific skills like mathematical computation or linguistic analysis.
The Complexity Challenge: How Models Handle Increasing Difficulty
Performance Patterns Across Increasing Task Complexity
After analyzing performance across our five ascending levels of task complexity, we uncovered significant insights into how model performance changes as tasks become more challenging:
Most Consistent Performers: Claude 3.7 maintained remarkably consistent performance across all complexity levels, never dropping below 80%, demonstrating exceptional resilience to increasing task difficulty. O3 Mini achieved perfect performance (100%) at the College level and maintained strong 80% success rates at Pre-Graduate and Post-Graduate levels.
Variable Performance Patterns: O1 showed exceptional performance at the High School level (100%) but we watched its performance drop significantly at higher complexity levels (down to 60% at Post-Graduate level). QwQ-32B similarly displayed strong performance at the Basics (86.96%) and High School (80%) levels, but showed substantial degradation at higher complexity levels.
Complexity-Related Degradation: Most models showed declining performance as complexity increased, with Claude 3.5 exhibiting the steepest decline from College (68.75%) to Post-Graduate levels (30%). This pattern suggests that maintaining logical coherence across extended reasoning chains remains challenging for many models.
Widening Performance Gap: The performance differential between top and bottom performers widened significantly at higher complexity levels. This became particularly evident in the Post-Graduate category where we observed the gap between Claude 3.7/O3 Mini (80%) and Claude 3.5 (30%) reached a staggering 50 percentage points.
High Variance at Intermediate Levels: The High School level showed the greatest performance variance across models, with scores ranging from 20% (Claude 3.5, DeepseekR1) to 100% (O1), despite having the smallest sample size. This suggests that intermediate complexity levels may be particularly effective at distinguishing between model capabilities.
Key Insights from Our Complexity Analysis
Our complexity level analysis provided several key insights into the current state of LLM reasoning capabilities:
- Basic Reasoning Maturity: We found that basic reasoning tasks appear increasingly manageable for contemporary LLMs, with all models achieving at least 47% success at the Basics level. This suggests that foundational reasoning capabilities are becoming a standard feature across most advanced LLMs.
- Advanced Reasoning Differentiation: Despite the maturing of basic reasoning capabilities, we discovered that advanced reasoning remains significantly differentiated across models. The substantial performance gap at higher complexity levels indicates that the ability to maintain logical consistency across extended reasoning chains represents a frontier of LLM development.
- Architectural Significance: The remarkable resilience of Claude 3.7 and O3 Mini to increasing task complexity suggests significant architectural advances in these models. Their ability to maintain performance across complexity levels likely indicates improved mechanisms for tracking logical dependencies and maintaining coherence in multi-step reasoning processes.
- Developmental Trajectories: The varying patterns of performance degradation across complexity levels provided us with insights into different models' developmental trajectories. Models with steeper degradation curves may benefit from training approaches that specifically target performance on complex, multi-step reasoning tasks.
Before moving forward with our analysis, we recognized these insights have important implications for the development and application of LLMs in contexts requiring varying levels of reasoning complexity, from straightforward analytical tasks to advanced problem-solving scenarios requiring extended chains of logical deduction.
Evolution in Action: Comparing Model Generations
OpenAI: From O1 to O3 Mini
When comparing O1 to O3 Mini, we witnessed a significant advancement in OpenAI's model architecture and training methodology. While O1 demonstrated exceptional language capabilities (91.67% in the Language domain), O3 Mini shows a more balanced performance profile with significant improvements in mathematical reasoning:
- Mathematical Reasoning: O3 Mini achieved a 90.32% success rate in mathematics compared to O1's 64.52%, representing a 40% relative improvement. This suggests substantial architectural or training enhancements specifically targeting mathematical capabilities.
- Reasoning Consistency: O3 Mini demonstrates superior consistency across proficiency levels, maintaining high performance even at advanced complexity levels (80% at Post-Graduate level compared to O1's 60%).
- Task Adaptability: O3 Mini shows particular strength in College Entrance Level tasks (100% success rate compared to O1's 87.50%), suggesting improved capabilities in handling structured educational content.
After analyzing these improvements, we believe they likely stem from several key architectural and training innovations:
- Enhanced numerical representation within the model's embedding space
- Improved integration of Chain-of-Thought (CoT) reasoning into the model architecture
- More sophisticated training methodologies that emphasize multi-step logical reasoning
What we found particularly noteworthy is that O3 Mini achieves these improvements despite being positioned as a smaller, more efficient model than O1, suggesting significant architectural refinements rather than simply scaling up model parameters.
Anthropic: Claude 3.5 to Claude 3.7
The progression from Claude 3.5 to Claude 3.7 represents one of the most dramatic performance improvements we observed in our study, with Claude 3.7 outperforming its predecessor by 33.33 percentage points overall (84.00% vs. 50.67%). This substantial improvement spans all evaluation dimensions:
- Cross-Domain Enhancement: We saw Claude 3.7 improve significantly across all three domains—Language (83.33% vs. 50.00%), Mathematics (80.65% vs. 45.16%), and Reasoning (87.50% vs. 56.25%).
- Complexity Resilience: While Claude 3.5 showed steep performance degradation at higher complexity levels (from 60.87% at Basics to 30% at Post-Graduate), we were impressed to see Claude 3.7 maintain consistent performance across all levels (never falling below 80%).
- Iterative Reasoning: Most remarkably, Claude 3.7 achieved a perfect 100% success rate on follow-up prompts (compared to Claude 3.5's 55.56%), indicating exceptional capability in refining and elaborating on initial analyses.
After seeing these dramatic improvements, we suspect they represent a fundamental shift in Anthropic's approach to model training. Based on our analysis, they've likely incorporated several key innovations:
- Enhanced deliberative alignment techniques that explicitly incorporate reasoning quality into model training
- Sophisticated reward modeling for multi-step logical processes
- Advanced integration of code-based training data to enhance mathematical reasoning capabilities
- Improved capability to maintain coherence across extended reasoning chains
Before moving on to other models, we noted that Claude 3.7's exceptional performance on follow-up prompts suggests particular advances in meta-cognitive capabilities—the ability to reflect on and refine its own reasoning processes, a capability critical for complex problem-solving applications.
Reinforcement Learning Approaches: DeepseekR1
In our benchmark study, we found that DeepseekR1 represents an innovative approach to enhancing reasoning capabilities through reinforcement learning (RL) without heavy reliance on supervised fine-tuning. While its overall performance (57.33%) places it in the middle tier of evaluated models, its approach offers valuable insights into alternative pathways for developing robust reasoning capabilities:
- Self-Evolution Process: We were intrigued by DeepseekR1's distinct training methodology where the model autonomously develops reasoning behaviors through thousands of RL steps. This approach enables the model to discover effective reasoning strategies without explicit supervision.
- Domain-Specific Strengths: After analyzing the results across domains, we noticed DeepseekR1 shows particular strength in the Reasoning domain (68.75%), outperforming its results in Mathematics (58.06%) and especially Language (25.00%). This suggests that RL-based approaches may be particularly effective for logical reasoning tasks.
- Improvement from Minimal Supervision: By integrating a small set of cold-start Chain-of-Thought (CoT) examples before reinforcement learning, we observed that DeepseekR1 achieves enhanced readability and structured reasoning outputs.
- Reward Modeling: The RL-based optimization uses both accuracy rewards (for correct outputs) and format rewards (for structured reasoning processes), refining logical consistency and coherence in generated responses.
However, we also noticed DeepseekR1 shows limitations in follow-up tasks (33.33% success rate), suggesting challenges in iterative reasoning processes. Before concluding our assessment, we realized this indicates that while RL-based approaches show promise for initial reasoning tasks, they may require further refinement to achieve the iterative reasoning capabilities demonstrated by models like Claude 3.7.
QwQ-32B vs. Qwen2.5: Adapting Reinforcement Techniques
When comparing these two models, we found the performance differential between QwQ-32B (62.67%) and Qwen2.5 (45.33%) highlights the impact of incorporating reinforcement learning techniques similar to those pioneered by DeepseekR1. QwQ-32B's adoption of these approaches has yielded substantial improvements:
- Broad Performance Enhancement: Our analysis shows QwQ-32B outperforms Qwen2.5 across all domains—Language (58.33% vs. 33.33%), Mathematics (51.61% vs. 35.48%), and especially Reasoning (75.00% vs. 59.38%).
- Basic Task Proficiency: After testing foundational reasoning tasks, we discovered QwQ-32B demonstrates particular strength in basic tasks (86.96% success rate compared to Qwen2.5's 47.83%), suggesting that reinforcement learning approaches may be especially effective at enhancing foundational reasoning capabilities.
- High School Level Tasks: QwQ-32B achieves 80% success on High School Level tasks compared to Qwen2.5's 40%, indicating improved capabilities in structured educational reasoning.
Based on our evaluation, the implementation of reinforcement learning techniques in QwQ-32B appears to have focused on:
- Development of self-verification and reflection mechanisms
- Integration of structured reasoning processes through reward-based optimization
- Enhancement of pattern recognition capabilities for basic and intermediate reasoning tasks
Before moving on to our theoretical analysis, we noted that QwQ-32B still exhibits limitations at higher complexity levels, achieving only 40% success at the Post-Graduate level—the same as Qwen2.5. This suggests that while RL techniques have significantly enhanced basic and intermediate reasoning capabilities, additional innovations may be required to address advanced reasoning challenges.
What It All Means: Theoretical Implications for LLM Reasoning
Evolution of Performance Hierarchy
After analyzing benchmarks from earlier generations of LLMs that often showed a consistent performance hierarchy across all domains and levels, our results reveal a more nuanced landscape. While O3 Mini and Claude 3.7 demonstrate superior overall performance, we found domain-specific excellence varies significantly across models. For instance, O1 excels in language tasks, O3 Mini in mathematics, and Claude 3.7 in reasoning. QwQ-32B shows particular strength in basic tasks but performs less consistently at higher complexity levels.
This suggests to us that the frontier of LLM development is becoming increasingly specialized, with different architectural or training approaches conferring advantages in specific domains. The relatively strong performance of newer models like O3 Mini and Claude 3.7 across all domains points to significant recent advances in general reasoning capabilities.
Domain-Specific Variations
The performance variations across domains revealed interesting patterns about current LLM capabilities. We were particularly struck by the results in Mathematics, historically a challenging domain for LLMs, which shows remarkable improvement in top-performing models like O3 Mini and Claude 3.7, with success rates of 90.32% and 80.65% respectively. This suggests significant progress in addressing the limitations identified by Mirzadeh et al. (2024), who observed that mathematical reasoning presents particular challenges for LLMs due to their reliance on pattern matching rather than formal reasoning.
The reasoning domain results merited our special attention, as they assess capabilities most directly related to logical deduction and inference. The strong performance of Claude 3.7 (87.50%) suggests particular effectiveness in handling tasks requiring multi-step logical processes. Before concluding our domain analysis, we noted the relatively strong performance of QwQ-32B in this domain (75.00%) despite more modest results in others indicates potential specialization in logical reasoning capabilities.
Resilience to Complexity
After running our complexity level tests, we found the relationship between task complexity and performance degradation varies significantly across models. While all models show some decline in performance as task complexity increases, Claude 3.7 and O3 Mini demonstrate remarkable resilience, maintaining 80% success rates even at the Post-Graduate level. This contrasts sharply with Claude 3.5, which shows a dramatic decline from 60.87% at the Basics level to only 30% at the Post-Graduate level.
This pattern suggests that recent advances in model architecture and training methodologies may be addressing the limitations observed by Mirzadeh et al. (2024), who found that LLM performance degradation increases with task complexity. The ability to maintain reasoning coherence across extended logical chains appears to be improving, particularly in the latest generation of models we tested.
Impact of Reinforcement Learning on Reasoning Paradigms
The emergence of reinforcement learning-based approaches, as exemplified by DeepseekR1 (DeepSeek-AI, 2025) and adopted by QwQ-32B, introduces new dimensions to LLM reasoning capabilities. While DeepseekR1's overall performance in our benchmark (57.33%) positions it in the middle tier of evaluated models, its relatively stronger performance in the reasoning domain (68.75%) suggests that reinforcement learning may be particularly effective for developing logical reasoning capabilities.
After studying these models, we found the reinforcement learning approach differs fundamentally from traditional supervised learning by:
- Enabling models to develop reasoning strategies through exploration rather than imitation
- Prioritizing logical consistency through reward optimization
- Developing self-verification mechanisms that can identify and correct reasoning errors
However, DeepseekR1's weak performance on follow-up tasks (33.33%) indicates potential limitations in iterative reasoning processes. This suggests that while RL-based approaches show promise for enhancing initial reasoning capabilities, they may need to be complemented by other techniques to achieve robust iterative reasoning.
Before concluding our analysis of reinforcement learning approaches, we noted that QwQ-32B's adoption of similar techniques has yielded substantial improvements over Qwen2.5, particularly in basic reasoning tasks. This suggests that reinforcement learning approaches can be effectively transferred across different model architectures, potentially representing a generalizable advancement in LLM reasoning methodology.
Evolutionary Advances in Reasoning Integration
The dramatic improvement from Claude 3.5 to Claude 3.7 and from O1 to O3 Mini suggests significant evolutionary advances in how reasoning capabilities are integrated into model architectures. After analyzing their performance patterns, we believe these improvements likely stem from several key developments:
- Enhanced integration of Chain-of-Thought reasoning directly into model architecture rather than relying solely on prompting techniques
- Improved balancing of code and text data during training to enhance mathematical reasoning capabilities
- More sophisticated reward modeling that explicitly incorporates reasoning quality into model optimization
- Advanced techniques for maintaining coherence across extended reasoning chains
Before moving to practical implications, we recognized these evolutionary advances suggest a shift from models that primarily rely on pattern matching toward architectures that more closely approximate logical deduction, though the underlying probabilistic foundation of LLM reasoning remains a fundamental constraint.
So What? Implications for Model Development and Application
Specialized Applications
After observing the domain-specific performance variations, we realized that model selection should be tailored to application requirements. For language-centric applications, O1 offers particular advantages, while mathematics-focused use cases might benefit more from O3 Mini's capabilities. Applications requiring multi-step logical reasoning might be best served by Claude 3.7.
This nuanced understanding of model capabilities enables more strategic deployment decisions. We suggest potentially combining different models for different aspects of complex applications rather than relying on a single model for all tasks.
Value of Iterative Reasoning
Claude 3.7's exceptional performance on follow-up prompts caught our attention as being particularly valuable for applications requiring iterative refinement of analyses, such as complex problem-solving or decision support systems. This capability appears to be a distinguishing feature of the latest Claude model, representing significant advancement over its predecessor.
After analyzing these results, we believe the ability to refine initial analyses based on additional context or feedback is critical for many real-world applications, from scientific research to strategic planning, where initial conclusions often require adjustment as new information becomes available.
Development Priorities
The relatively weaker performance on mathematical reasoning by some models indicates that this remains a priority development area, despite significant progress by leading models. The substantial performance gap between top performers (O3 Mini, Claude 3.7) and others suggests that recent architectural and training advances have not yet been fully incorporated across the industry.
Similarly, the challenges many models face with higher complexity tasks highlight the need for continued focus on maintaining logical coherence across extended reasoning chains—a capability critical for advanced applications requiring sophisticated analysis of complex problems.
Evaluation Frameworks
After completing our multi-dimensional benchmark, we strongly believe the substantial variations in performance across domains and complexity levels underscore the importance of comprehensive, multi-dimensional evaluation frameworks that can capture the nuanced capabilities of different models. Single-metric evaluations risk obscuring significant performance variations across different task types and complexity levels.
We recommend future evaluation methodologies continue to expand on this multi-dimensional approach, incorporating additional domains and metrics to provide even more granular insights into model capabilities.
For teams looking to operationalize evaluation beyond internal benchmarks, our guide on how to choose an AI model evaluation service covers what to look for in expert-driven evaluation partners.
Training Strategy Recommendations
Based on the performance patterns we observed across models, several training methodologies show particular promise for enhancing reasoning capabilities:
- Reinforcement Learning with Minimal Supervision: As demonstrated by DeepseekR1, we found reinforcement learning approaches with minimal cold-start examples can develop strong reasoning capabilities, particularly for basic and intermediate tasks.
- Deliberative Alignment: The exceptional performance of Claude 3.7, particularly on complex and follow-up tasks, suggests that deliberative alignment approaches that explicitly incorporate reasoning quality into model training can yield substantial improvements in both reasoning capability and iterative refinement.
- Code-Enhanced Training: The strong mathematical performance of O3 Mini suggests that incorporating code data during training can significantly enhance reasoning capabilities, particularly for structured mathematical tasks. This aligns with findings from multiple researchers regarding the impact of code on model reasoning.
- Balanced Multi-Domain Training: The consistently strong performance of Claude 3.7 across all domains and complexity levels suggests that carefully balanced training across multiple domains may be more effective than specialized training for developing general reasoning capabilities.
Before concluding our analysis, we recognized these methodological insights offer valuable guidance for future model development, suggesting that a combination of reinforcement learning, deliberative alignment, code-enhanced training, and balanced multi-domain exposure may represent the optimal approach for developing robust reasoning capabilities.
Room for Improvement: Limitations and Future Directions
Task Selection Considerations
While our benchmark includes a diverse range of tasks across multiple domains and complexity levels, we recognize the distribution remains somewhat uneven, with mathematics and reasoning tasks predominating. In future iterations, we plan to aim for more balanced task allocation across domains, with particular attention to underrepresented subcategories within each domain.
Additionally, our current benchmark focuses primarily on academic-style reasoning tasks. After reviewing our results, we believe expanding to include more real-world reasoning scenarios would provide additional insights into practical application capabilities.
Binary Evaluation Limitations
The binary success metric (correct/incorrect) we used may obscure nuanced performance differences, particularly in tasks with multiple components or degrees of correctness. In future work, we aim to consider more granular evaluation metrics that can capture partial successes and reasoning quality. This would provide more detailed insights into the specific strengths and limitations of different models.
Before our next benchmark iteration, we'll explore potential approaches including multi-point scoring systems, process evaluation metrics that assess the quality of the reasoning process independent of the final answer, and confidence-calibrated evaluations that consider models' expressed uncertainty.
Model Selection Constraints
Our benchmark focuses on eight leading LLMs, but we acknowledge the rapidly evolving landscape of AI capabilities means that this selection represents only a snapshot of the current state of the art. After completing this study, we plan for future evaluations to incorporate a wider range of models, particularly those employing novel architectural or training approaches.
Additionally, we recognize that evaluating multiple versions of the same model family would provide valuable insights into the trajectory of capability development within specific architectural paradigms.
Temporal Considerations
We understand LLM capabilities evolve rapidly with new training methodologies and data. This benchmark represents a snapshot of capabilities that may not reflect future performance. After completing our analysis, we believe longitudinal studies tracking capability development over time would provide valuable insights into the trajectory of LLM reasoning.
Before planning our next benchmark, we're considering establishing regular benchmark intervals which would enable the field to track progress systematically, identifying areas of rapid advancement and persistent challenges.
Recommendations for Future Research
After completing this comprehensive benchmark, we believe future research should address these limitations while expanding the evaluation framework to include:
- More granular performance metrics that can capture nuanced differences in reasoning quality
- Evaluation of reasoning transparency and explicability to assess not just whether models reach correct conclusions but whether their reasoning processes are coherent and interpretable
- Assessment of reasoning robustness against adversarial inputs to evaluate the stability of reasoning capabilities under challenging conditions
- Longitudinal analysis of capability development across model iterations to identify developmental trajectories and persistent challenges
Recent methodological advances offer promising directions for enhancing LLM reasoning capabilities. As highlighted by Guan et al. (2024), deliberative alignment approaches that explicitly incorporate reasoning quality into model training can lead to significant improvements in both safety and task performance. Similarly, reinforcement learning-based approaches like those developed by DeepSeek-AI have demonstrated the potential for autonomous development of reasoning capabilities through iterative reinforcement (DeepSeek-AI, 2025).
Wrapping Up: Key Takeaways and Future Outlook
Our benchmark study provides comprehensive insights into the reasoning capabilities of eight leading LLMs across diverse domains and complexity levels. After analyzing all the data, we found substantial performance differentials, with O3 Mini and Claude 3.7 exhibiting superior capabilities across most dimensions of evaluation.
The patterns we observed suggest significant progress in developing LLM reasoning capabilities, particularly in mathematical reasoning and advanced complexity levels. The consistent performance of top models across varying complexity levels indicates important advances in maintaining logical coherence in extended reasoning chains. Claude 3.7's exceptional performance on follow-up tasks points to notable improvements in iterative reasoning capabilities.
Our analysis of model evolution reveals several key insights:
- The progression from O1 to O3 Mini demonstrates significant advancement in mathematical reasoning capabilities while maintaining strong performance across all domains.
- The dramatic improvement from Claude 3.5 to Claude 3.7 represents one of the most substantial performance leaps we observed, with particular advances in consistency across complexity levels and exceptional capability in follow-up tasks.
- The reinforcement learning approach pioneered by DeepseekR1 and adapted by QwQ-32B offers a promising alternative pathway for developing reasoning capabilities, particularly effective for basic and intermediate reasoning tasks.
- The varying impact of different training methodologies suggests that optimal reasoning development may require a combination of approaches, including reinforcement learning, deliberative alignment, code-enhanced training, and balanced multi-domain exposure.
However, we also acknowledge that substantial challenges remain, with considerable performance variations across models, domains, and complexity levels. The significant gap between top performers and other models suggests that recent advances have not yet been uniformly adopted across the industry. Lower-performing models continue to struggle with complex reasoning tasks, particularly at advanced complexity levels.
After completing our study, we believe these findings have important implications for model selection in applications requiring specific reasoning capabilities and highlight critical areas for further development. The multi-dimensional evaluation framework we employed offers a valuable template for future assessments, enabling more nuanced understanding of LLM reasoning capabilities.
Looking ahead, we're convinced that as LLM technology continues to evolve, systematic benchmarking will remain essential for tracking progress, identifying limitations, and guiding development efforts toward more robust and comprehensive reasoning capabilities. Our team plans to continue refining our benchmark methodology and expanding our evaluation to track the rapid progress in this exciting field.
References
Aryabumi, V., Chen, Z. Z., Ye, X., Yang, X., Chen, L., Wang, W. Y., & Petzold, L. (2024). Unveiling the impact of coding data instruction fine-tuning on large language models reasoning.
DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv. https://arxiv.org/abs/2501.12948
Guan, M. Y., Joglekar, M., Wallace, E., Jain, S., Barak, B., Heylar, A., Dias, R., Vallone, A., Ren, H., Wei, J., Chung, H. W., Toyer, S., & Heidecke, J., & Beutel, A., & Glaese, A. (2024). Deliberative alignment: Reasoning enables safer language models. arXiv preprint arXiv:2412.16339.
McCoy, R. T., Yao, S., Friedman, D., Hardy, M. D., & Griffiths, T. L. (2024). Embers of autoregression show how large language models are shaped by the problem they are trained to solve. Proceedings of the National Academy of Sciences, 121(41), e2322420121.
Mirzadeh, I., Alizadeh, K., Shahrokhi, H., Tuzel, O., Bengio, S., & Farajtabar, M. (2024). GSM-Symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229.
Prabhakar, R., Dua, D., & Agrawal, R. (2024). Deciphering the Factors Influencing the Efficacy of Chain-of-Thought: Probability, Memorization, and Noisy Reasoning. arXiv preprint arXiv:2407.01687v2.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv:2201.11903.
Zhang, X., Su, Y., Ma, R., Morisot, A., Zhang, I., Locatelli, A., Fadaee, M., Üstün, A., & Hooker, S. (2024). To code, or not to code? Exploring impact of code in pre-training.