
.png)


_logo%201.svg)


AI Summary
Advanced artificial intelligence (AI) and natural language processing (NLP) applications are reshaping numerous industries at a blazing pace. Recent launches of ChatGPT and its rival Bard marked a revolutionary milestone of conversational AI in the consumer space. As remarkable as they are, AI technologies rely on accurate information extraction, particularly those processing linguistic data at scale.
This article will explore popular information extraction types, techniques, and challenges that machine learning engineers (MLE) face. More importantly, we share best practices to build accurate information extraction models for practical applications ranging from the health industry to the biomedical domain.
What is information extraction?
Information extraction is an approach for identifying and retrieving specific information from unstructured data sources. It helps organizations and businesses derive valuable insights from increasingly large data pools online and offline. For example, companies extract information from survey forms and analyze them to determine if their customers are happy, unhappy, or indifferent.
Conventionally, information extraction uses rigid and limited approaches, such as template matching. Such techniques struggle to cope with fast-changing information structures and a vast amount of data introduced by digitalization. Hence, machine learning has become the preferred method for extracting useful data at scale and with better accuracy.
Types of Information Extraction and Natural Language Processing
In Natural Language Processing techniques, information extraction follows specific steps to turn unstructured data into machine-understandable forms. Before extracting information from PDFs, emails, or other textual sources, NLP systems must preprocess them via tokenization and part-of-speech tagging.
- Tokenization breaks down a sentence into smaller phrases called ‘tokens’. An NLP system can’t process raw sentences. Instead, it uses ‘tokens’ to derive the semantic and contextual meaning of the text.
- Part of speech tagging is a process that associates each token with grammatical representations, such as verbs, nouns, adjectives, and pronouns.
These preprocessing steps prepare the data for subsequent processing and extraction.
We share three popular types of information extraction used in subsequent stages below.
Named Entity Recognition
Named Entity Recognition (NER) is an NLP task that identifies and classifies specific information, termed ‘entity’, in textual data. Entities can be categorized as people, places, time, organizations, or other categories specific to a particular application. NLP programs extract entities to form a basic understanding of the text.
For example, consider the following sentence.
“Elon Musk is the founder of Tesla, an automotive company headquartered in Texas, United States.”
With NER, you can extract the following entities and categorize them accordingly.
- Elon Musk - Person
- Tesla - Organization
- Texas, United States - Location
Some NER tasks might face challenges when categorizing ambiguous entities. For example, “orange” might suggest a color or a fruit. In such circumstances, the NER system uses advanced machine learning algorithms to determine the entity’s context by analyzing the entire sentence.
Speaking of NER tasks... Did you know that ChatGPT could help you with these? If not yet, take a look at our article on how to use ChatGPT to Pre-annotate Named Entities Recognition Labeling Tasks.
LLMs
Large Language Models (LLMs) like GPT-4 and ChatGPT can be used for various natural language processing tasks, including information extraction. These models can be used to do a specific task in zero or few-shot with the right prompt. To improve their performance on specific information extraction tasks – ie tasks for short, such as named entity recognition, relation extraction, and event extraction, these models can also be fine-tuned. One way or another, by leveraging the pre-trained language models’ knowledge of language patterns, these models can help extract structured information from unstructured data with high accuracy.
Learn More
Interested in speeding up your data labeling? Make sure to check out our webinar on how to slash your data labeling time in half using ChatGPT! Access your on-demand session now.

Coreference Resolution
Coreference resolution is a linguistic approach to identifying all occurrences of the same entity in different textual expressions. Once identified, the NLP system replaces all mentions and pronouns of the entity with nouns. Here’s an example of coreference resolution.
“Mike is good at chess, and he won in a recent tournament”.
The NLP system would resolve the above sentence as:
“Mike is good at chess, and Mike won in a recent tournament”.
As the system might encounter vague entity representations, coreference resolution is a considerably challenging task in NLP. The presence of more than one entity in a sentence further complicates the task.
For example,
“Mike is better than me at chess, but I have beaten him once,” thought Tom.
In the above example, the NLP system must resolve the entities as follow:
“Mike is better than Tom at chess, but Tom have beaten Mike once,” thought Tom.
Relationship Extraction
Relationship extraction allows NLP programs to understand how entities relate to each other in the text. It analyzes the text structure to determine the contextual and semantic relationship between multiple entities. Depending on the complexity, MLEs can establish the relationship between entities with simple word-sequence detection or complex machine learning models.
For example, it is considerably easy to determine the relationship between Bob and Fred with the following sentence.
“Bob and Fred are neighbors.”
However, natural human language is complex, and not all entity relationships are explicitly expressed. The following sentence implies the same relationship without mentioning the term neighbor.
“Bob lives next to Fred’.
In varying sentence constructs bearing the same relationship, applying a trained machine learning model will deliver better results.
Information Extraction Techniques
The principles of information extraction were well-established, but the information extraction techniques for achieving better accuracy, efficiency, and scalability have evolved over the years. We share several common linguistic extraction techniques and their corresponding advantages and limitations.
Dictionary-based Information Extraction
Dictionary-based extraction relies on a list, table, or collection of matching words predefined by humans. The extraction algorithm searches the text to find occurrences of keywords or phrases as defined in the dictionary. While dictionary-based extraction is straightforward, it lacks flexibility when applied in different contexts or domains.
Rule-based Information Extraction
Rule-based extraction uses a more sophisticated approach than dictionary matching. It allows data scientists to compile a set of patterns, which the system uses as a guide to analyze and categorize specific words in a broader context. Instead of comparing individual words, this approach considers the relationship between tokens in textual data.
For example, you can identify mentions of companies in a publication with the following rule.
If a word starts with a capital letter and is followed by verb forms like ‘is’, ‘was’, or ‘will’, it is likely the name of a company.
Despite its flexibility, the rule-based approach entirely depends on predefined rules and can’t automatically adapt to different use cases.
Machine-learning-based Information Extraction
Machine learning-enabled information extraction overcomes the limitations faced by its dictionary and rule-based counterparts face. Instead of defining the extraction criteria manually, the machine learning approach trains the extraction algorithm with labeled datasets. There, the machine learning model learns how to discern specific patterns from the given input and expected output.
Machine learning models are more accurate in interpreting ambiguous words, sarcasm, incomplete sentences, cultural nuances, and other linguistic irregularities than conventional extraction methods. This makes machine learning-enabled extraction more robust in real-life applications. For example, a machine learning model would tag a customer review below as moderately negative.
“I’m unhappy with the product but don’t want a refund”.
The machine learning model can concur that a refund is not needed, while a dictionary-based approach will categorize it as outright negative based on the term ‘unhappy’ and ‘refund’.
Over the years, various machine learning models focusing on NLP applications have been developed. Amongst them, these are models widely used for information extraction.
Support Vector Machines
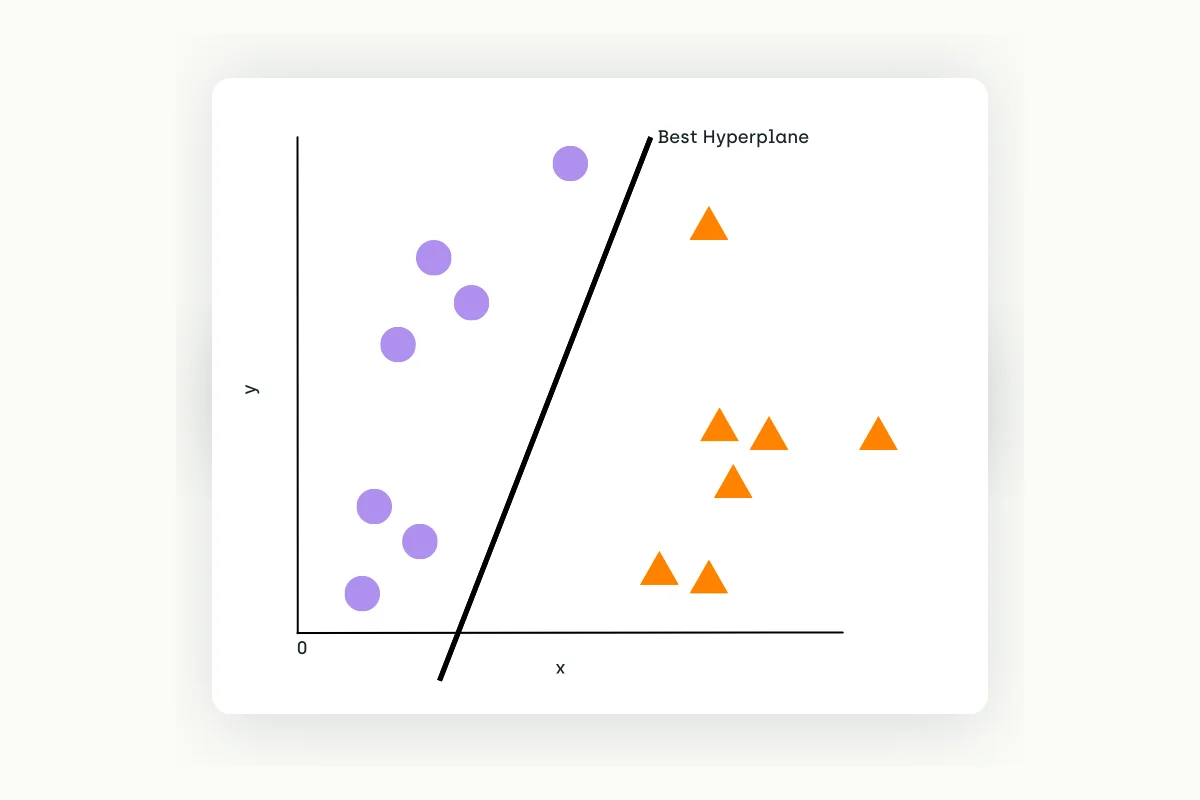
Support Vector Machines (SVM) is a supervised machine learning algorithm capable of classifying text with limited sample data. It analyzes and draws a hyperplane to provide a decision boundary on a multidimensional space. Once establishing the hyperplane, the SVM model can tag data with their respective categories.
Naive Bayes

Naive Bayes Formula
Naive Bayes is a probabilistic algorithm that evaluates specific entities independently of other related entities. It considers phrases like ‘democrats’, ‘constitutions’, ‘chair the cabinet meetings’, and ‘dignitaries’ individually to determine if a particular news article falls into politics. Naive Bayes can categorize large numbers of textual data efficiently, making it suitable for real-time multi-classifications tasks. Compared to other classifiers, Naive Bayes uses far less training data.
Deep Learning-based Information Extraction
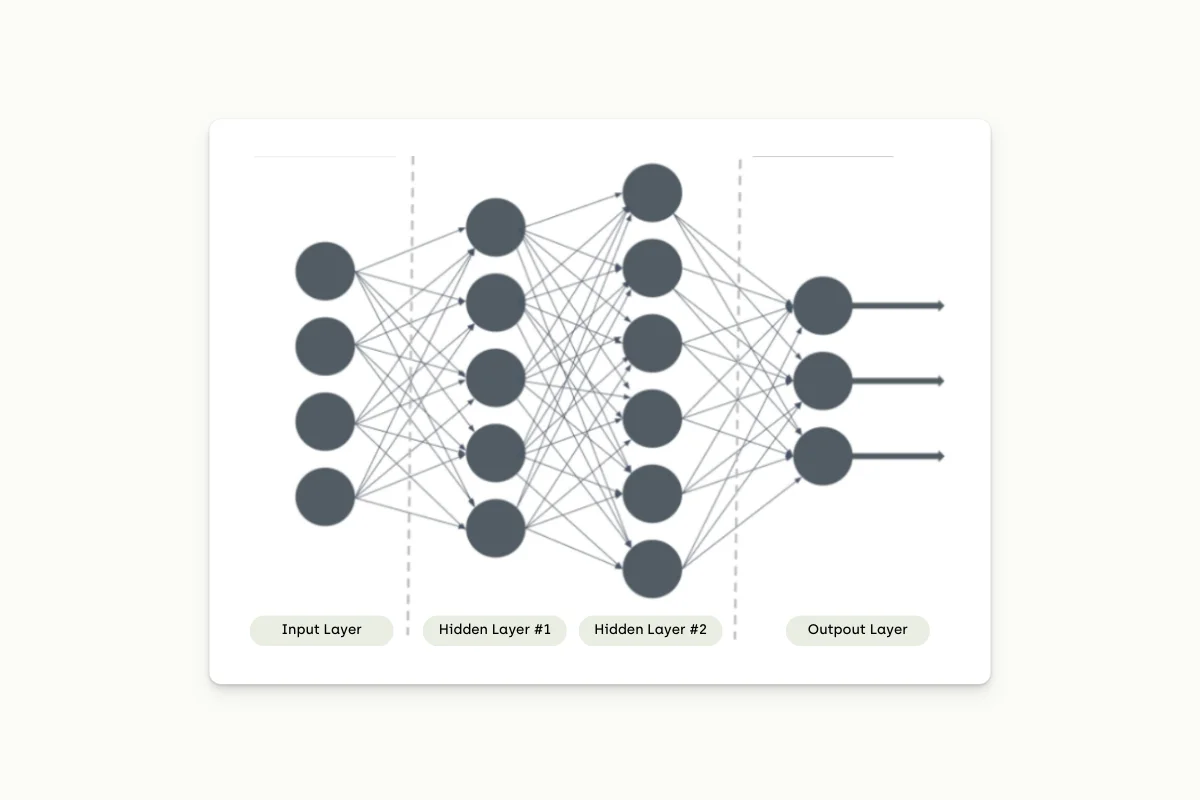
Deep Learning explained with layers
Deep learning is a subset of machine learning that allows the underlying model to analyze, extract, process and predict text like a human does. Its applications use neural networks, a structural representation of the human brain with several hidden layers. Neural networks are the state-of-the-art technology in NLP and can process data at a larger scale.
With deep learning, MLEs can train the underlying model with labeled or unlabeled datasets. As such, these models can ingest unstructured data with no or minimal annotations. This allows the model to extract data at a more complex level, often without human intervention.
For example, deep learning models can extract complex relationship entities and subpatterns that basic machine learning models never could. The downsides are – it takes enormous resources to train these models, and there are concerns about overfitting when applied with real word data.
Spacy
Spacy is an open-source NLP library that helps MLEs with language processing and extraction. It lets you train NLP models to extract information from large datasets efficiently with the GPU pipeline. Written in Python, Spacy provides MLEs with easy-to-use language extraction components, such as NER, part-of-speech tagging, lemmatization, and text classifications.
Transformers by Hugging Face
Hugging Face provides various pre-trained transformer models to shorten development time and reduce computing costs when building deep learning applications. MLEs can download and access hundreds of large language models via API, including Bert, RoBERTa, GPT, and Transformer-XL.
NLTK
Natural Language Took Kit (NLTK) consists of Python libraries for building linguistic-driven applications. It provides the necessary text extraction features, such as classification, stemming, and tokenization, which prepare the textual data for further extractions in neural networks.
Challenges in Information Extraction
NLP models have grown a long way to provide more accurate and efficient information extraction. Still, MLEs grapple with several challenges that might impact the linguistic model’s performance.
Overcoming Ambiguity in Information Extraction
Human language is complicated and sometimes difficult to understand, even by humans. Homonyms and synonyms are common issues affecting information extraction and the information extraction model), and this is because some words or phrases bear different meanings or interpretations in different contexts. When faced with ambiguous terms, NLP models might fail to categorize the entities accurately.
For example, less-advanced linguistic algorithms need help with semantic ambiguity. To further understand the problem, consider the following sentence.
‘I saw her duck’
The word ‘duck’ is correct as a noun or verb but has different meanings in both cases. Without a contextual understanding of preceding or succeeding sentences, the Natural Language Processing model cannot comprehend the sentence’s intended meaning.
Likewise, sarcasm and irony are common obstacles in extracting and classifying textual data. They involve phrases that imply the opposite meaning of what’s stated.
For example,
“The ad claims this product is waterproof. Yeah right!”
With sufficient training, NLP models can interpret sarcasm as humans do, but not without difficulties.
Variability
Languages are spoken and written differently around the world. Even within the same language domain, variance in grammar, spelling, cultural references, nuances, and other elements may affect an NLP model’s ability to understand the text accurately.
Besides general variations, MLEs must also address domain-specific terms and language. For example, a large language model trained with a generic dataset needs further training before it is suitable for healthcare applications. Likewise, a healthcare linguistic model is unsuitable for extracting and classifying documents in the legal industry without additional training or retraining.
Natural Language Processing models also perform below par for languages that lack training resources. For example, Africans speak more than 3,000 languages, but there are insufficient data online to train linguistic models accurately. While multilingual models like BERT seek to overcome this issue, they may need certain adaptations to overcome data scarcity in some languages.
Noise
Noise is irrelevant data or the presence of irregularities that affect an NLP system’s performance. For example, some documents contain spelling, idiomatic slang, or grammar errors, which complicate data extraction. MLEs use several approaches to overcome this issue, including training the Natural Language Processing model with noisy labels to increase its robustness and accuracy.
Reliability
Language extraction models may perform differently in real-world applications or demonstrate bias when processing gender-specific data. For example, a study in 2020 found substantial gender bias in the Neural Relation Extraction model when tested against a dataset of 45,000 sentences. As such, the language model is unreliable when scaled across large data sources.
NLP models might also experience high false positive rates where they incorrectly classify large numbers of data. This is a major concern in mission-critical healthcare, finance, and legal applications. The implication reverberates across the organization as erroneous classification might result in improper treatment, transaction denials, and injustice to the public.
“I’m unhappy with the product but don’t want a refund”.
Scalability
Besides reliability concerns, information extraction with deep learning models is limited by computational resources. The model requires immense computing resources and costs to extract data from vast, complex, and unstructured sources.
For example, training BERT with 1.5 billion parameters might cost up to$1.6m, putting such endeavors beyond small organizations. To reduce cost and development time, they use pre-trained models, such as Transformers by Hugging Face, and fine-tune them for specific applications.
Best Practices for Information Extraction
Information extraction needs continuous research and studies to efficiently produce accurate and reliable results. These are some recommended practices that help MLEs build better information extraction models.
Information Extraction Step 1: Define your goal
Every feature extraction system serves different purposes. Therefore, outline your project goals before gathering data samples and building an extraction pipeline. For example, healthcare software aims to extract specific patient information from medical records automatically.
Information Extraction Step 2: Use large and diverse datasets
A Natural Language Processing model’s accuracy depends on the training samples' quality and quantity. Therefore, gather datasets from various sources, such as emails, CRM software, scanned documents, and feedback forms, to improve training results. The question is, how much data do you need to train an extraction model?
BERT, a large language model capable of various NLP tasks, including extraction, is trained on 3.3 billion words of data. However, simple business-specific extraction models might not require enormous datasets as general models. Often, MLEs use pre-trained language models and finetune them with domain-specific data sources. For example, you can finetune the pre-trained XLNet for sentiment analysis tasks.
Information Extraction Step 3: Evaluate models regularly
Before deploying a Natural Language Processing model for production, evaluate it to ensure it meets the desired performance metrics. Common metrics that determine a model’s readiness are accuracy, precision, recall, and F1-score. These metrics indicate how the model would perform in actual applications. For example, a high recall rate means the model can extract relevant transaction details from financial records with strong confidence.
Information Extraction Step 4: Incorporate human feedback
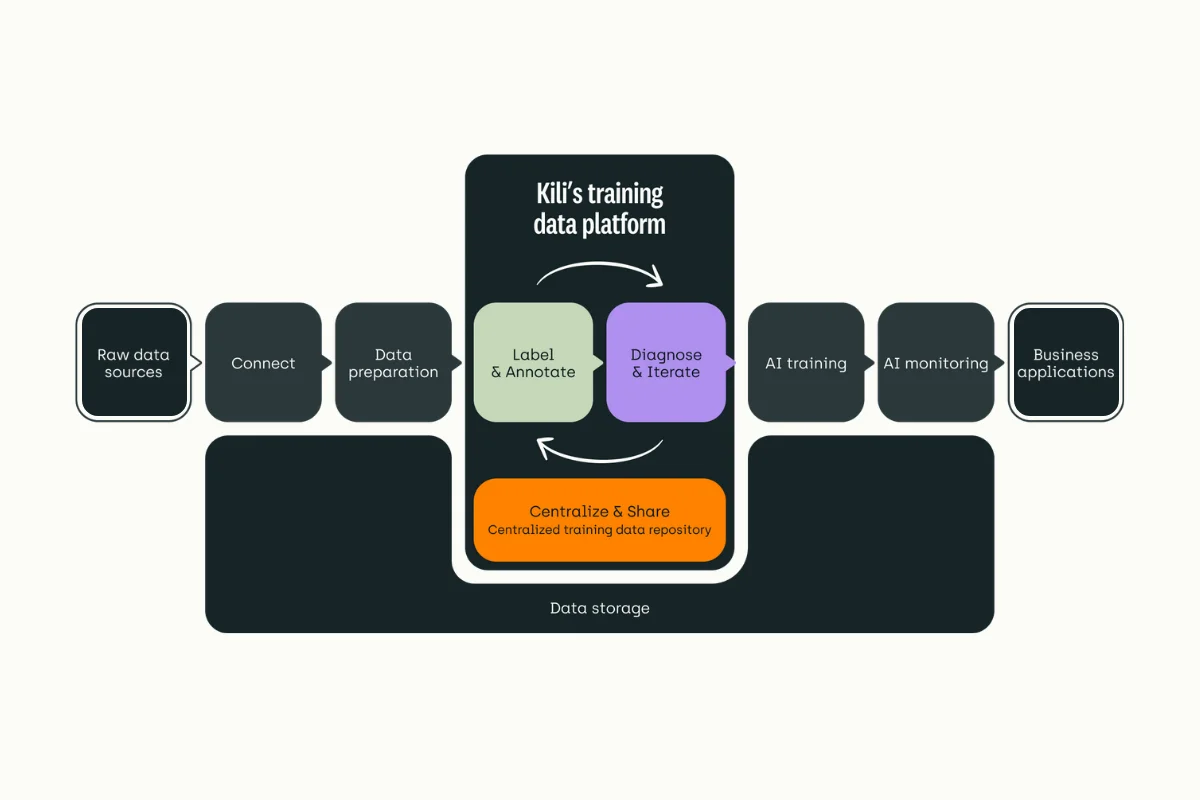
Human Feedback Loop illustrated with Kili Technology's Platform
Despite the autonomous nature of certain extraction pipelines, involving human reviewers or annotators help increase the model’s performance. For example, MLEs can retrain models with manually-labeled samples for better accuracy. Meanwhile, human reviewers help spot bias and ensure the extracted results are relevant. For example, around 2,500 human annotators were involved in creating the Stanford Natural Language Inference (SNLI) corpus.
Information Extraction: Final Thoughts
Information extraction is the foundation of NLP systems and determines how linguistic models perform. Over the years, various techniques, machine algorithms, and deep-learning models have been introduced to enable accurate and efficient entity extraction. Despite their advancement, MLEs continue to strive to produce more reliable and scalable extraction models.
We shared several challenges that MLEs face that need further addressing. Besides, We listed best practices that help create and deploy extraction pipelines for domain-specific applications. Ultimately, human annotators and reviewers still play a pivotal role in propelling Natural Language Processes developments, particularly information extraction, to the next level.
Talk to us to learn more about information extraction and how to apply it in your work.
Just so you know, Kili Technology does provide professional services designed to help you speed up your data labeling process. They notably include on-demand trained labelers and seasoned ML experts.
FAQ on Information Extraction
What do you mean by information extraction?
Information extraction (IE) is the process of identifying and extracting structured data from unstructured or semi-structured sources, such as text documents, web pages, or social media content. This process involves using various techniques and algorithms to identify and organize relevant information so it can be used effectively in different applications.
Is automatic annotation recommended for information extraction?
Let's be honest: when dealing with large-scale datasets or when getting high-quality labeled data is challenging, automatic annotation can be a tempting approach.
Nonetheless, this approach isn't the one we'd recommend for information extraction (or any other purposes).
As a Data-Centric AI (DCAI) enthusiast, Kili Technology firmly believes that high-quality data is key to training effective machine learning models. We always advocate for human labeling rather than automatic annotation.
As our customers' stories illustrate it: excellent-quality labeling is a key factor of success. Training your model on a more restricted dataset yet finely annotated leads to better results than employing a larger yet poorly annotated dataset.
Note that our platform comes with pre-annotation capabilities that can help to speed up your labeling process.
What are the most frequent use cases of information extraction in machine learning?
Information extraction plays a vital role in various machine learning applications by transforming unstructured or semi-structured data into structured information. Here are some of the most frequent use cases of information extraction:
- Named Entity Recognition (NER): Identifies and classifies entities in unstructured text, e.g., people, organizations, and locations. It supports further analysis and is often used for identifying relationships.
- Sentiment Analysis: Allows to extract of meaningful information such as sentiments, opinions, or emotions from text data. Extracted concepts can be useful for social media monitoring or customer feedback analysis.
- Relation Extraction: Identifies and extracts relationships between entities detected in human language texts (unstructured data) ranging from biomedical literature and medical records to legal documents.
Is automatic annotation recommended for information extraction?
Let’s be honest: when dealing with large-scale datasets or when getting high-quality labeled data is challenging, automatic annotation can be a tempting approach.
Nonetheless, this approach isn’t the one we’d recommend for information extraction (or any other purposes). As a Data-Centric AI (DCAI) enthusiast, Kili Technology firmly believes that high-quality data is key to training effective machine learning models.
We always advocate for human labeling rather than automatic annotation. As our customers’ stories illustrate it: excellent-quality labeling is a key factor of success. Training your model on a more restricted dataset yet finely annotated leads to better results than employing a larger yet poorly annotated dataset.
Note that our platform comes with automation capabilities that can help to speed up your labeling process.
Resources on Information Extraction
8 NLP Techniques to Extract Information
Hands-on NLP Project: A Comprehensive Guide to Information Extraction using Python
Information Extraction: Methodologies and Applications
What is Information Extraction?
Information Extraction as a Stepping Stone toward Story Understanding
Information Extraction With NLP And Deep Learning
What is named entity recognition (NER) and how can I use it?
What is named entity recognition (NER) and how can I use it?
Different ways of doing Relation Extraction from text
Machine learning vs keyword tagging: Why ML is best
Naive Bayes Classifier Explained: Applications and Practice Problems of Naive Bayes Classifier
Understanding Naive Bayes Classifier
Deep Learning vs. Machine Learning – What’s The Difference?
AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the Difference?
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

