
.png)


_logo%201.svg)


AI Summary
Introduction
Named Entity Recognition (NER) is a crucial task in Natural Language Processing (NLP) that involves identifying and categorizing named entities in text. These named entities can include people, organizations, locations, dates, or numerical values. NER is important for information extraction and retrieval, text tagging, and chatbot implementation. In this blog post, we will show you how to use the GPT-3 DaVinci model, a Large Language Model (LLM), which powers ChatGPT, to improve labeler productivity when working on Named Entity Recognition annotation tasks.
What are Large Language Models?
Large language models are pre-trained language models that can perform a wide range of NLP tasks, including question-answering, text classification, and named entity recognition, without training or fine-tuning. These models are trained on massive amounts of text data and can understand the context and meaning of words, phrases, and sentences. One of the most popular zero-shot language models is GPT-3 or Generative Pre-trained Transformer 3, which is a neural network-based language model developed by OpenAI. GPT-3 has been trained on a massive dataset of more than 45 terabytes of text data and can perform a wide range of NLP tasks, including text generation, summarization, and translation, among others.
By using large language models, we can perform NER on any named entity category without the need for task-specific training data by using zero-shot predictions. Zero-shot predictions refer to the ability of a machine learning model to make accurate predictions on tasks it has not been trained for, using a concept named prompting. Prompting means that a user needs to design a sentence that contains precise instructions for the model to execute.
What are the benefits of using a Large Language Model for Named Entity recognition?
Using a Large Language Model in a zero-shot setting has several advantages:
- 1. No need for training data: By using pre-trained language models, we can perform NER on any named entity category without needing training data.
- 2. Flexibility: they can be used for a wide range of NER problems. By changing the prompt, you are able to extract new entities without having to retrain the model. For example, to extract symptom names from medical reports, simply specify that in the prompt.
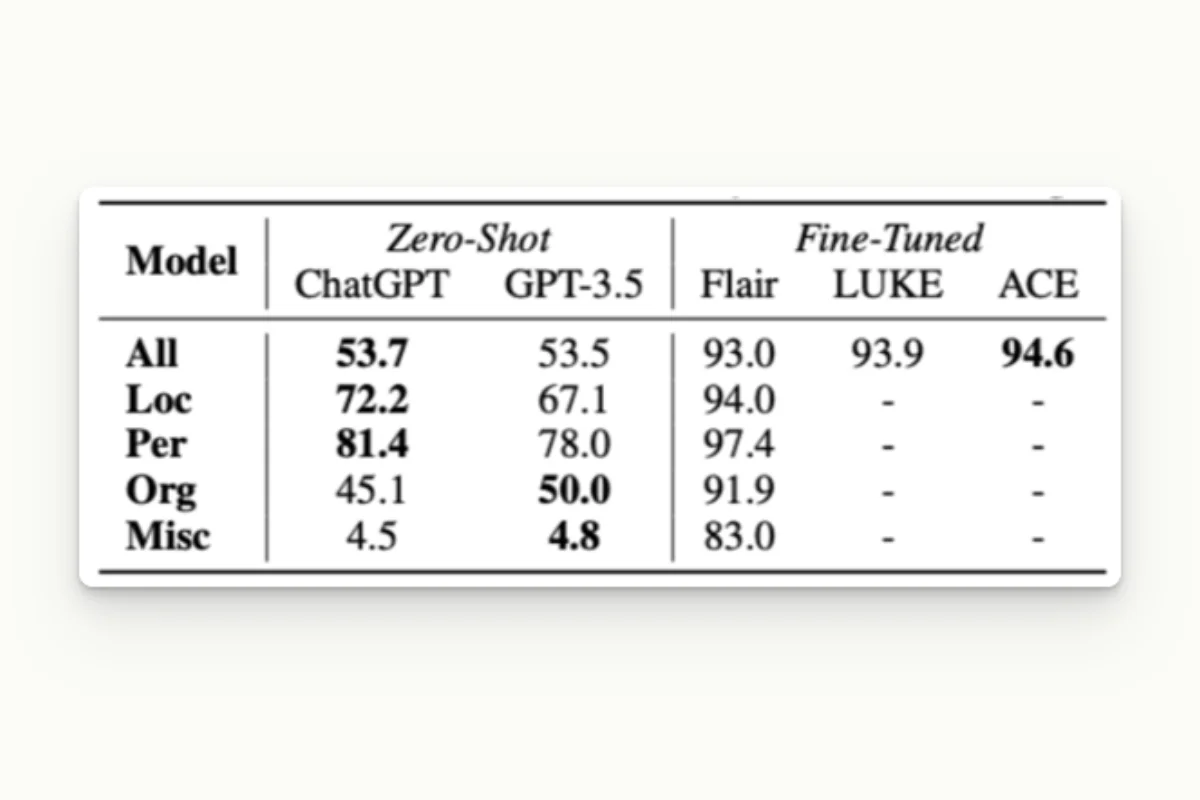
- 3. Accuracy: even if they do not provide the accuracy of a fine-tuned language model, they offer a good starting point for text pre-annotation. In the article “Is ChatGPT a General-Purpose Natural Language Processing Task Solver?”, it is shown that GPT reaches 53% F1-score on the CONLL2033 dataset, while the fine-tuned models reach more than 90%.
Learn More
Interested in speeding up your data labeling? Make sure to check out our webinar on how to slash your data labeling time in half using ChatGPT! Access your on-demand session now.

Extracting Named Entities using ChatGPT
To extract named entities from text using zero-shot large language models, we first need to identify the named entity categories we are interested in. We can use popular named entity categories like PERSON, ORGANIZATION, and LOCATION or create our own custom categories. Once we have identified the categories, we can prompt a large language model like GPT-3 or T5 to extract these named entities.
The following sections explain the steps to follow. You can also refer to this notebook which describes how to perform this operation end to end and, additionally, how to load these predictions into the Kili annotation platform.
Data preparation
We will work with the famous NER dataset named CONLL2003. We can simply import it using Hugging Face’s dataset package:
dataset = load_dataset("conll2003", split="train")Here is an example data row we can obtain after reconstructing the sentence from the tokens and replacing the ner_tags with the string tags:
{
'id': '0',
'tokens': ['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.'],
'ner_tags': ["B-ORGANIZATION", "O", "B-MISCELLANEOUS", "O", "O", "O", "B-MISCELLANEOUS", "O", "O"],
'sentence': 'EU rejects German call to boycott British lamb.'
}GPT-3 setup
You can setup OpenAI this way:
import openai
openai.api_key = OPENAI_API_KEYand implement the call to the model with the appropriate settings:
openai_query_params = {
"model": "text-davinci-003",
"temperature": 0,
"max_tokens": 1024
}
def ask_openai(prompt: str, openai_query_params=openai_query_params) -> str:
response = openai.Completion.create(
prompt=prompt,
**openai_query_params,
)
return response["choices"][0]["text"]The model is set to text-davinci-003, which is the most accurate model available on Open AI as of today. The temperature parameter makes the system behave as follows: the higher the temperature, the more random the text. The lower the temperature, the more likely it is to predict the next word. The default value is 0.7. It should be between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. And finally, the max_tokens the parameter indicates roughly the number of words the model will generate.
At this stage, you can already talk with OpenAI:
>>> print(ask_openai("Hello, are you here?"))
Yes, I am here. How can I help you?Prompt design
After several iterations, we came up with this prompt:
base_prompt = """In the sentence below, give me the list of:
- organization named entity
- location named entity
- person named entity
- miscellaneous named entity.
Format the output in json with the following keys:
- ORGANIZATION for organization named entity
- LOCATION for location named entity
- PERSON for person named entity
- MISCELLANEOUS for miscellaneous named entity.
Sentence below:
"""We can then append a sentence to the prompt this way and get the result:
>>> test_sentence = (
"Elon Musk is the CEO of Tesla and SpaceX. He was born in South Africa and now lives in the"
" USA. He is one of the founders of OpenAI."
)
>>> print(ask_openai(base_prompt + test_sentence))
{
"ORGANIZATION": ["Tesla", "SpaceX", "OpenAI"],
"LOCATION": ["South Africa", "USA"],
"PERSON": ["Elon Musk"],
"MISCELLANEOUS": []
}Pre-annotation creation
We now have a system able to identify the named entities in a text. To build the pre-annotations, we simply have to locate these named entities in the input text, and shape them into the Kili annotation format:
json_response_array = []
for datapoint, sentence_annotations in zip(dataset, openai_answers):
full_sentence = datapoint["sentence"]
annotations = [] # list of annotations for the sentence
for category, _ in ENTITY_TYPES:
sentence_annotations_cat = sentence_annotations[category]
for content in sentence_annotations_cat:
begin_offset = full_sentence.find(content)
assert (
begin_offset != -1
), f"Cannot find offset of '{content}' in sentence '{full_sentence}'"
annotation = {
"categories": [{"name": category}],
"beginOffset": begin_offset,
"content": content,
}
annotations.append(annotation)
json_resp = {"NAMED_ENTITIES_RECOGNITION_JOB": {"annotations": annotations}}
json_response_array.append(json_resp)Note: the notebook also explains how to configure the Kili project and load the assets into the project.
Then, let’s upload them into Kili:
kili.create_predictions(
project_id,
external_id_array=external_id_array,
json_response_array=json_response_array,
model_name=openai_query_params["model"],
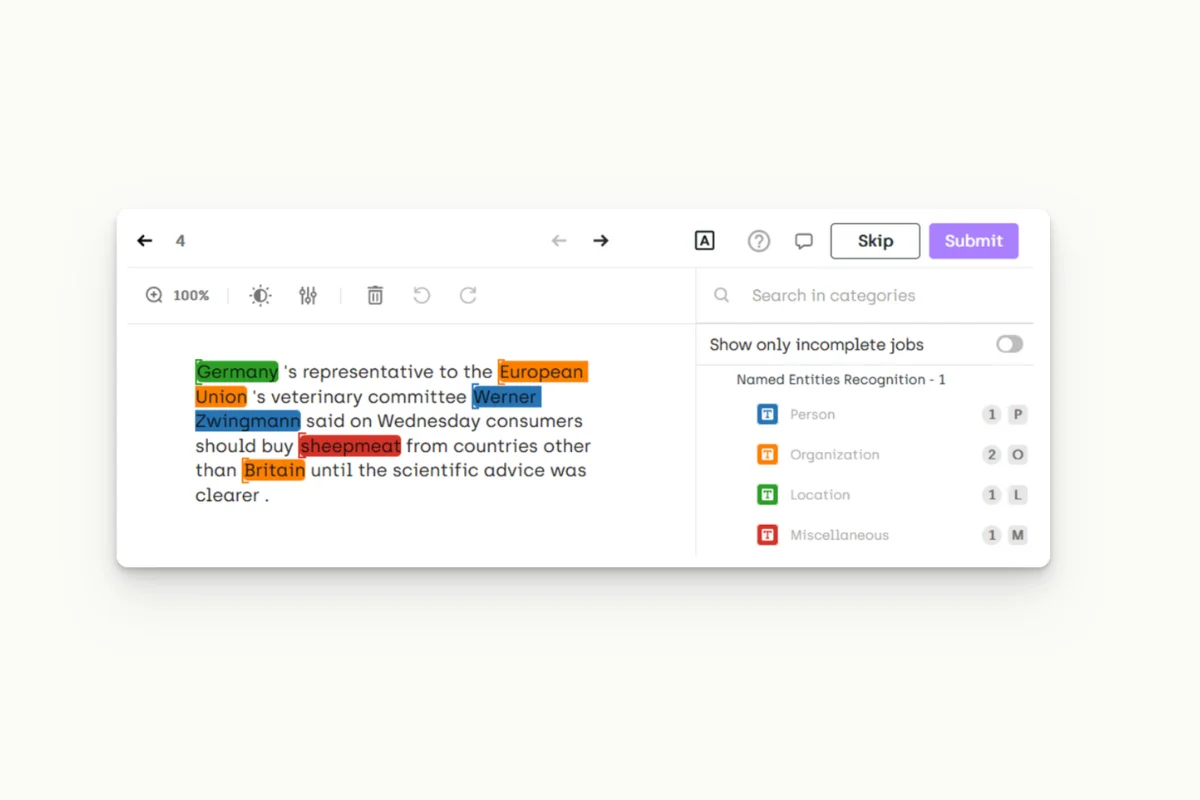
)And you’re done! Here are the assets that have been labeled:

Is it worth it?
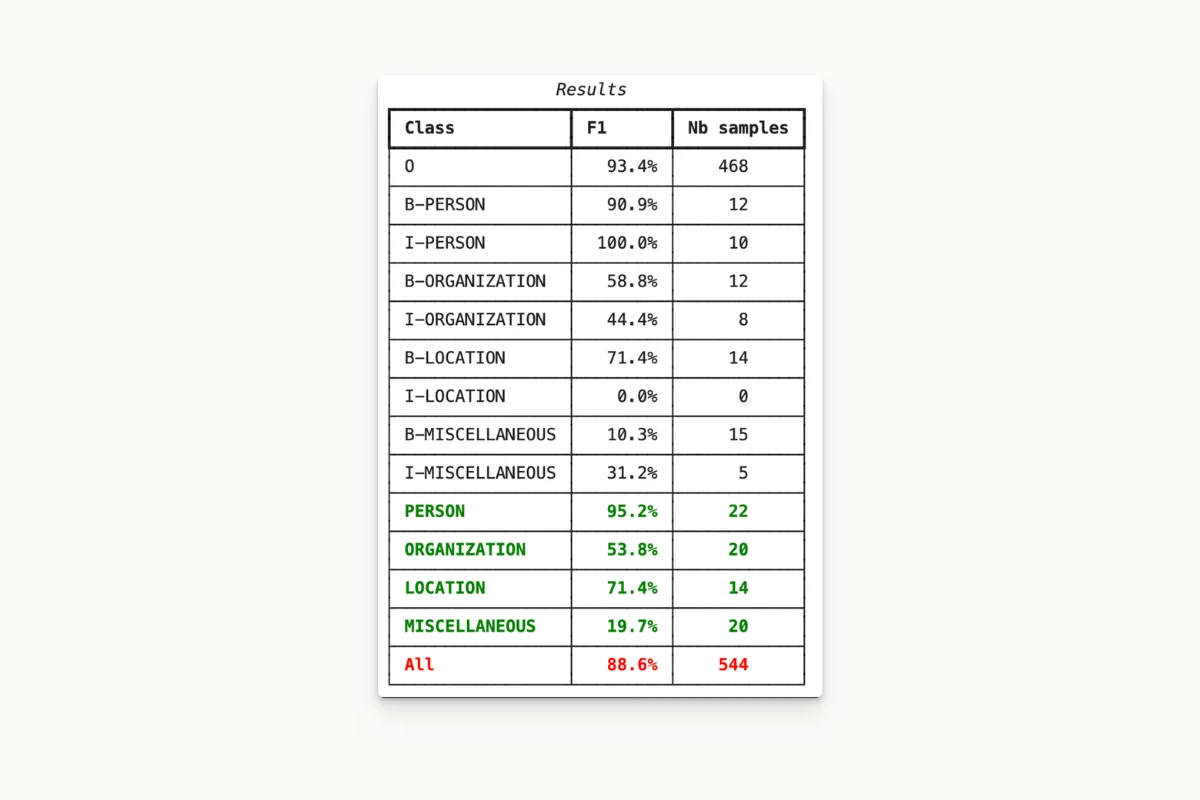
We also performed a quality evaluation on a CONLL2003 subset. We computed the F1 score for each named entity class. Here is what we obtained from a small sample:
This is a very good starting point to pre-annotate, and especially impressive for a method that did not involve training! The evaluation code is also in the notebook.
Learn More
Don't miss out! Secure your spot at our sizzling webinar and learn how to slash your data labeling time in half using ChatGPT! Mark your calendars: Thursday, March 30th, 5:00 PM CEST / 11:00 AM EDT
Wrapping up
In conclusion, using Large Language Models for named entity recognition is a powerful tool that can save time and resources. By leveraging the power of pre-trained language models and appropriate prompt design, we can perform NER on any named entity category without requiring task-specific training data.
This is not the only thing you can do with the GPT models when you are dealing with dataset creation:
- Data augmentation, or labeled asset creation: you can ask the model to generate texts with the same meaning as some assets but with a different style or tone. You may have to ask for a human review to ensure that the label is correct. See, for example, the work done in ChatAug: Leveraging ChatGPT for Text Data Augmentation .
- Data generation, or unlabeled asset creation: you can ask to generate assets that are similar to existing ones to increase the size of your unlabeled dataset, then ask annotators to annotate them.
- GPT fine-tuning: like for the other LLMs, it is possible to fine-tune the GPT models: https://platform.openai.com/docs/guides/fine-tuning . However, the Bert-style models, and … , are better designed for finetuning.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

